概述
从文本等非结构化数据中提取结构化信息并非新鲜事物,但大语言模型(LLMs)为该领域带来了重大变革。以往需要机器学习专家团队策划数据集并训练自定义模型,如今只需访问LLM即可实现,显著降低了技术门槛,让曾仅限领域专家使用的技术对非技术人员也更加友好。
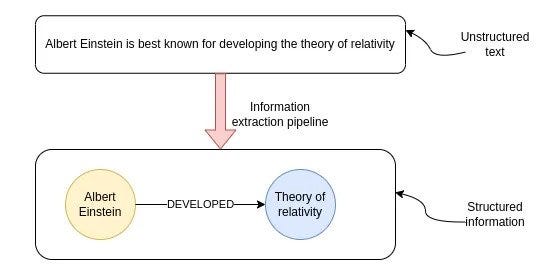
/* 信息提取管道的目标是从非结构化文本中提取结构化信息。*/
上图展示了非结构化文本转换为结构化信息的过程,该过程被称为信息提取管道,最终得到信息的图形表示。其中,节点代表关键实体,连接线表示实体之间的关系。知识图谱在多跳问答、实时分析,或者需要在单个数据库中结合结构化和非结构化数据等场景中非常实用。
尽管借助LLMs,从文本中提取结构化信息变得更加容易,但这绝非已解决的问题。在本文中,我们将结合OpenAI函数与LangChain,从示例维基百科页面构建知识图谱,同时探讨最佳实践以及当前LLMs的一些局限性。
Neo4j环境设置
要跟随本文示例操作,需先设置Neo4j环境。最简单的方法是在Neo4j Aura上启动免费实例,获取Neo4j数据库的云实例;也可下载Neo4j Desktop应用程序,创建本地数据库实例。
以下代码用于实例化LangChain包装器,以连接到Neo4j数据库:
from langchain.graphs import Neo4jGraphurl = "neo4j+s://databases.neo4j.io"
username = "neo4j"
password = ""
graph = Neo4jGraph(url=url,username=username,password=password
)
信息提取管道
典型的信息提取管道包含以下步骤:
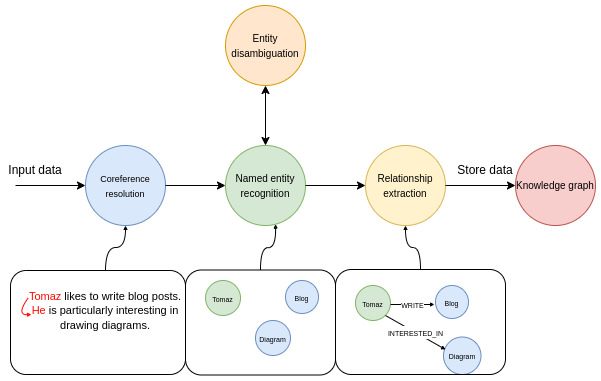
信息提取管道的多个步骤。
第一步,将输入文本通过共指消解模型处理。共指消解的任务是找出所有指向特定实体的表达式,简单来说,就是将所有代词与所指代的实体关联起来。在管道的命名实体识别部分,我们会尝试提取所有提及的实体。例如,某个文本中包含Tomaz、Blog和Diagram三个实体。
下一步是实体消歧,这是信息提取管道中重要却常被忽视的环节。实体消歧是准确识别和区分具有相似名称或引用的实体的过程,确保在特定上下文中识别出正确的实体。
最后一步,模型会尝试识别实体之间的各种关系。比如,可确定Tomaz和Blog实体之间存在LIKES关系。
使用OpenAI函数提取结构化信息
OpenAI函数非常适合从自然语言中提取结构化信息。其核心思路是让LLM输出一个预定义的JSON对象并填充值,该JSON对象可作为其他函数的输入(如在所谓的RAG应用程序中),或用于从文本中提取预定义的结构化信息。
在LangChain中,可将Pydantic类作为OpenAI函数特性所需JSON对象的描述传递。因此,我们首先定义要从文本中提取的信息的结构。LangChain已提供节点和关系的定义,作为可重用的Pydantic类:
class Node(Serializable):"""表示图中具有关联属性的节点。属性:id (Union[str, int]): 节点的唯一标识符。type (str): 节点的类型或标签,默认为"Node"。properties (dict): 与节点关联的附加属性和元数据。"""id: Union[str, int]type: str = "Node"properties: dict = Field(default_factory=dict)class Relationship(Serializable):"""表示图中两个节点之间的有向关系。属性:source (Node): 关系的源节点。target (Node): 关系的目标节点。type (str): 关系的类型。properties (dict): 与关系关联的附加属性。"""source: Nodetarget: Nodetype: strproperties: dict = Field(default_factory=dict)
但遗憾的是,OpenAI函数目前不支持字典对象作为值,因此我们必须重写properties的定义以符合函数端点的限制:
from langchain.graphs.graph_document import (Node as BaseNode,Relationship as BaseRelationship
)
from typing import List, Dict, Any, Optional
from langchain.pydantic_v1 import Field, BaseModelclass Property(BaseModel):"""由键和值组成的单个属性"""key: str = Field(..., description="键")value: str = Field(..., description="值")class Node(BaseNode):properties: Optional[List[Property]] = Field(None, description="节点属性列表")class Relationship(BaseRelationship):properties: Optional[List[Property]] = Field(None, description="关系属性列表")
在这里,我们将properties值重写为Property类的列表而非字典,以克服API限制。由于只能向API传递单个对象,我们需要将节点和关系组合到一个名为KnowledgeGraph的单个类中:
class KnowledgeGraph(BaseModel):"""生成具有实体和关系的知识图谱。"""nodes: List[Node] = Field(..., description="知识图谱中的节点列表")rels: List[Relationship] = Field(..., description="知识图谱中的关系列表")
接下来只需进行一些提示工程即可开始操作。我进行提示工程的通常方式如下:
- 用自然语言迭代提示并改进结果
- 若某些内容未按预期工作,让ChatGPT使指令更便于LLM理解任务
- 最后,当提示包含所有必要指令时,让ChatGPT以markdown格式总结指令,以节省令牌并使指令更清晰
我特意选择markdown格式,是因为曾了解到OpenAI模型对提示中的markdown语法响应更佳,从我的经验来看,这似乎是合理的。
通过迭代提示工程,我为信息提取管道设计了以下系统提示:
llm = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)def get_extraction_chain(allowed_nodes: Optional[List[str]] = None,allowed_rels: Optional[List[str]] = None):prompt = ChatPromptTemplate.from_messages([("system",f"""# GPT-4的知识图谱指令
## 1. 概述
你是一个顶级算法,专为以结构化格式提取信息以构建知识图谱而设计。
- **节点**代表实体和概念。它们类似于维基百科节点。
- 目标是在知识图谱中实现简单性和清晰度,使其对广大受众可访问。
## 2. 标记节点
- **一致性**:确保你为节点标签使用基本或基础类型。- 例如,当你识别代表人的实体时,始终将其标记为**"person"**。避免使用更具体的术语,如"mathematician"或"scientist"。
- **节点ID**:永远不要使用整数作为节点ID。节点ID应该是在文本中找到的名称或人类可读的标识符。
{'- **允许的节点标签:**' + ", ".join(allowed_nodes) if allowed_nodes else ""}
{'- **允许的关系类型**:' + ", ".join(allowed_rels) if allowed_rels else ""}
## 3. 处理数值数据和日期
- 数值数据,如年龄或其他相关信息,应作为相应节点的属性或特性合并。
- **不为日期/数字创建单独节点**:不要为日期或数值创建单独的节点。始终将它们作为节点的属性或特性附加。
- **属性格式**:属性必须采用键值格式。
- **引号**:在属性值中永远不要使用转义的单引号或双引号。
- **命名约定**:对属性键使用驼峰命名法,例如`birthDate`。
## 4. 共指消解
- **保持实体一致性**:在提取实体时,确保一致性至关重要。
如果一个实体,如"John Doe",在文本中被多次提及,但被不同的名称或代词引用(例如,"Joe","he"),
在整个知识图谱中始终使用该实体最完整的标识符。在这个例子中,使用"John Doe"作为实体ID。
记住,知识图谱应该是连贯且易于理解的,因此在实体引用中保持一致性至关重要。
## 5. 严格遵守
严格遵守规则。不遵守将导致终止。"""),("human", "使用给定格式从以下输入中提取信息:{input}"),("human", "提示:确保以正确格式回答"),])return create_structured_output_chain(KnowledgeGraph, llm, prompt, verbose=False)
我们使用的是GPT-3.5模型的16k版本,主要原因是OpenAI函数输出为结构化的JSON对象,而结构化JSON语法会给结果增加大量令牌开销。本质上,我们是为结构化输出的便利性付出了增加令牌空间的代价。
除一般指令外,我还添加了限制从文本中提取的节点或关系类型的选项,通过后续示例你会了解其用处。
现在,我们已准备好Neo4j连接和LLM提示,可将信息提取管道定义为单个函数:
def extract_and_store_graph(document: Document,nodes:Optional[List[str]] = None,rels:Optional[List[str]]=None) -> None:# 使用OpenAI函数提取图数据extract_chain = get_extraction_chain(nodes, rels)data = extract_chain.run(document.page_content)# 构建图文档graph_document = GraphDocument(nodes = [map_to_base_node(node) for node in data.nodes],relationships = [map_to_base_relationship(rel) for rel in data.rels],source = document)# 将信息存储到图中graph.add_graph_documents([graph_document])
该函数接收LangChain文档以及可选的节点和关系参数,这些参数用于限制我们希望LLM识别和提取的对象类型。大约一个月前,我们向Neo4j图对象添加了add_graph_documents方法,可在此处利用该方法无缝导入图。
评估
我们将从沃尔特·迪士尼的维基百科页面提取信息并构建知识图谱,以测试该管道。在此过程中,会利用LangChain提供的维基百科加载器和文本分块模块:
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import TokenTextSplitter# 读取维基百科文章
raw_documents = WikipediaLoader(query="Walt Disney").load()
# 定义分块策略
text_splitter = TokenTextSplitter(chunk_size=2048, chunk_overlap=24)# 只取前三个原始文档
documents = text_splitter.split_documents(raw_documents[:3])
你可能已注意到我们使用了相对较大的chunk_size值,这是因为我们希望在单个句子周围提供尽可能多的上下文,以便共指消解部分能更好地发挥作用。请记住,只有当实体及其引用出现在同一块中时,共指步骤才能正常工作;否则,LLM没有足够信息来链接两者。
现在,我们可以继续让文档通过信息提取管道处理:
from tqdm import tqdmfor i, d in tqdm(enumerate(documents), total=len(documents)):extract_and_store_graph(d)
该过程大约需要5分钟,速度相对较慢。因此,在生产环境中,你可能希望通过并行API调用来处理此问题,以实现一定的可扩展性。
首先,我们来看LLM识别的节点和关系类型:
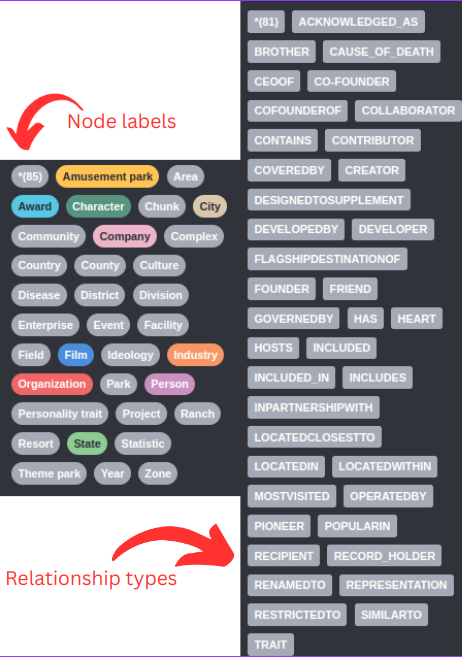
由于未提供图模式,LLM会即时决定使用的节点标签和关系类型。例如,我们可以看到存在Company和Organization节点标签,这两个在语义上可能相似或相同,所以我们希望只用一个节点标签来表示两者。关系类型的问题更为明显,例如存在CO-FOUNDER和COFOUNDEROF关系,以及DEVELOPER和DEVELOPEDBY关系。
对于任何更严谨的项目,你都应该定义LLM应提取的节点标签和关系类型。幸运的是,我们已经添加了通过传递附加参数在提示中限制类型的选项:
# 指定LLM应该提取哪些节点标签
allowed_nodes = ["Person", "Company", "Location", "Event", "Movie", "Service", "Award"]for i, d in tqdm(enumerate(documents), total=len(documents)):extract_and_store_graph(d, allowed_nodes)
在这个例子中,我仅限制了节点标签,你也可以通过向extract_and_store_graph函数传递另一个参数轻松限制关系类型。
提取的子图的可视化结构如下:
放大图像将被显示
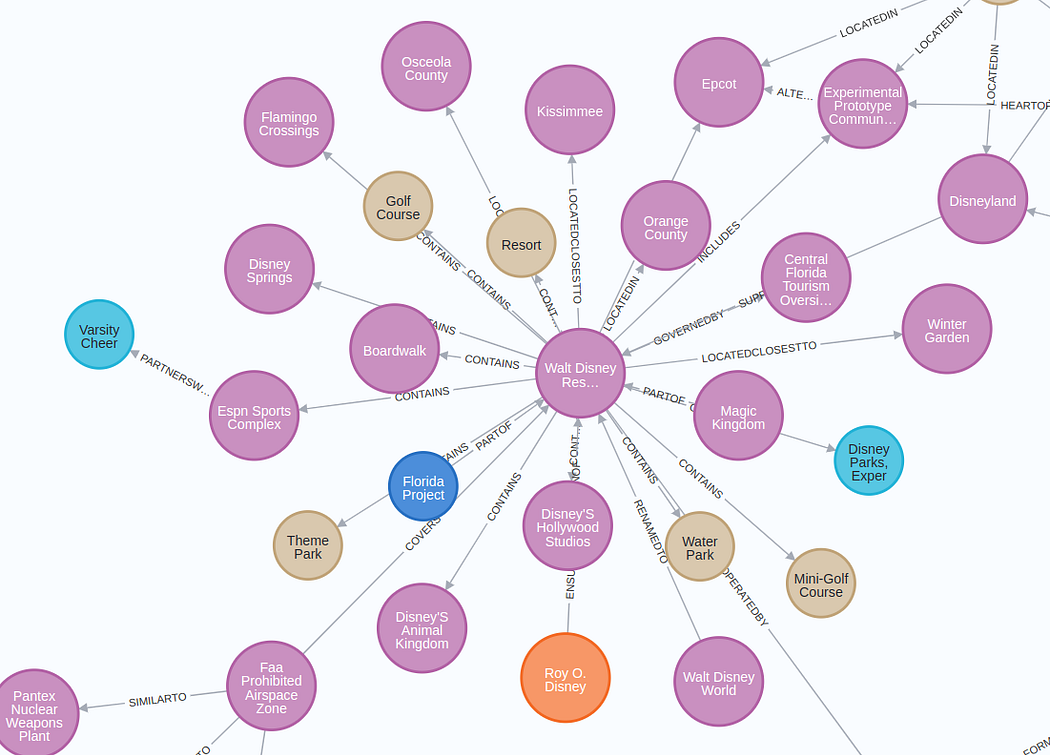
图表结果比预期的要好(经过五次迭代后 😃 )。我无法在可视化中很好地呈现整个图,但你可以在Neo4j浏览器或其他工具中自行探索。
实体消歧
需要说明的是,我们部分跳过了实体消歧环节。我们使用了较大的块大小,并在系统提示中添加了共指消解和实体消歧的具体指令。但由于每个块都是单独处理的,无法确保不同文本块之间实体的一致性。例如,可能会出现两个代表同一个人的节点:
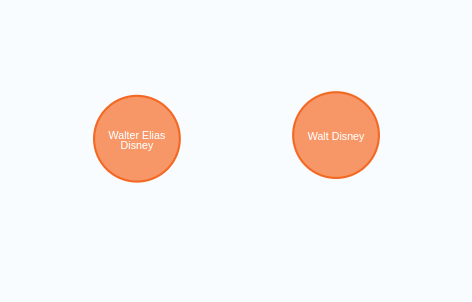
代表同一实体的多个节点。
在这个例子中,Walt Disney和Walter Elias Disney指的是同一个现实世界中的人。实体消歧问题并非新问题,已有多种解决方案:
- 使用实体链接或实体消歧 NLP模型
- 通过LLM进行第二次传递,要求其执行实体消歧
- 基于图的方法
你应根据所在领域和具体用例选择合适的解决方案。但请记住,实体消歧步骤不容忽视,因为它可能对RAG应用程序的准确性和有效性产生重大影响。
RAG应用程序
最后,我们将展示如何通过构建Cypher语句在知识图谱中浏览信息。Cypher是用于处理图数据库的结构化查询语言,类似于关系数据库中的SQL。LangChain有一个GraphCypherQAChain,它能读取图的模式,并根据用户输入构建相应的Cypher语句:
# 在RAG应用程序中查询知识图谱
from langchain.chains import GraphCypherQAChaingraph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(graph=graph,cypher_llm=ChatOpenAI(temperature=0, model="gpt-4"),qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),validate_cypher=True, # 验证关系方向verbose=True
)
cypher_chain.run("Walter Elias Disney是什么时候出生的?")
结果如下:
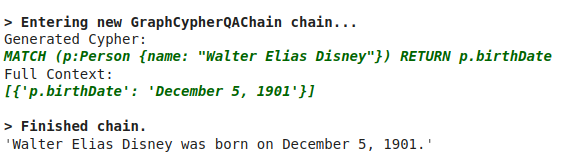
总结
当需要结合结构化和非结构化数据来支持RAG应用程序时,知识图谱是一个不错的选择。在本文中,你学习了如何使用OpenAI函数在任意文本上在Neo4j中构建知识图谱。OpenAI函数提供了整洁的结构化输出,使其成为提取结构化信息的理想选择。为了在使用LLMs构建图时获得良好效果,请确保尽可能详细地定义图模式,并在提取后添加实体消歧步骤。
,上传文件,后端插入数据,将文件保存到数据库)
)
——pinctrl GPIO)



)





)


一个博客带你了解所有问题)



