目录
一、前言
二、pytest安装
2.1、安装
2.2、验证安装
2.3、pytest文档
三、pytest框架的约束
3.1、 python的命名规则
3.2、 pytest的命名规则
四、pytest的运行方式
4.1、主函数运行
4.2、命令行运行
五、pytest配置文件pytest.ini文件
六、前置和后置
七、assert断言
八、pytest中conftest.py文件
8.1、conftest.py的特点
九、pytest中fixtrue装饰器
9.1、基本使用
9.2、yield(后置)
9.3、带参数fixtrue
9.3.1、scope
9.3.2、autouse
9.3.3、params
9.3.4、ids
9.3.5、name
十、logging日志模块
10.1、介绍
10.2、使用
十一、测试报告allur
11.1、介绍
11.2、安装
10.3、使用
一、前言
pytest是一个非常成熟的全功能的Python测试框架,主要有以下几个特点:
1、简单灵活,非常方便的组织自动化测试用例;
2、支持参数化,可以细粒度地控制要测试的测试用例;
3、能够支持简单的单元测试和复杂的功能测试,比如web端selenium/移动端appnium等自动化测试、request接口自动化测试
4、pytest具有很多第三方插件,并且可以自定义扩展,比如测试报告生成,失败重运行机制
5、测试用例的skip和fail处理;
6、结合业界最美的测试报告allure+Jenkins,持续集成
二、pytest安装
2.1、安装
pip install -U pytest2.2、验证安装
pytest --version # 会展示当前已安装版本2.3、pytest文档
官方文档:https://docs.pytest.org/en/latest/contents.html
三、pytest框架的约束
3.1、 python的命名规则
1)py文件全部小写,多个英文用_隔开
2)class名首字母大写,驼峰
3)函数和方法名小写,多个英文用_隔开
4)全局变量,前面要加global
5)常量字母必须全大写,如:AGE_OF_NICK
3.2、 pytest的命名规则
1)模块名(py文件)必须是以test_开头或者_test结尾
2)测试类(class)必须以Test开头,并且不能带init方法,类里的方法必须以test_开头
3)测试用例(函数)必须以test_开头
四、pytest的运行方式
4.1、主函数运行
import pytestdef test_01():print("啥也没有")if __name__=='__main__':pytest.main()main中可使用的参数有:
| 参数 | 描述 | 案例 |
|---|---|---|
| -v | 输出调试信息。如:打印信息 | pytest.main([‘-v’,‘testcase/test_one.py’,‘testcase/test_two.py’]) |
| -s | 输出更详细的信息,如:文件名、用例名 | pytest.main([‘-vs’,‘testcase/test_one.py’,‘testcase/test_two.py’]) |
| -x | 只要有一个用例执行失败,就停止执行测试 | pytest.main([‘-vsx’,‘testcase/test_one.py’]) |
| – maxfail | 出现N个测试用例失败,就停止测试 | pytest.main([‘-vs’,‘-x=2’,‘testcase/test_one.py’] |
| –html=report.html | 生成测试报告 | pytest.main([‘-vs’,‘–html=./report.html’,‘testcase/test_one.py’]) |
| -n | 多线程或分布式运行测试用例 | |
| -m | 通过标记表达式执行 | |
| -k | 根据测试用例的部分字符串指定测试用例,可以使用and,or |
4.2、命令行运行
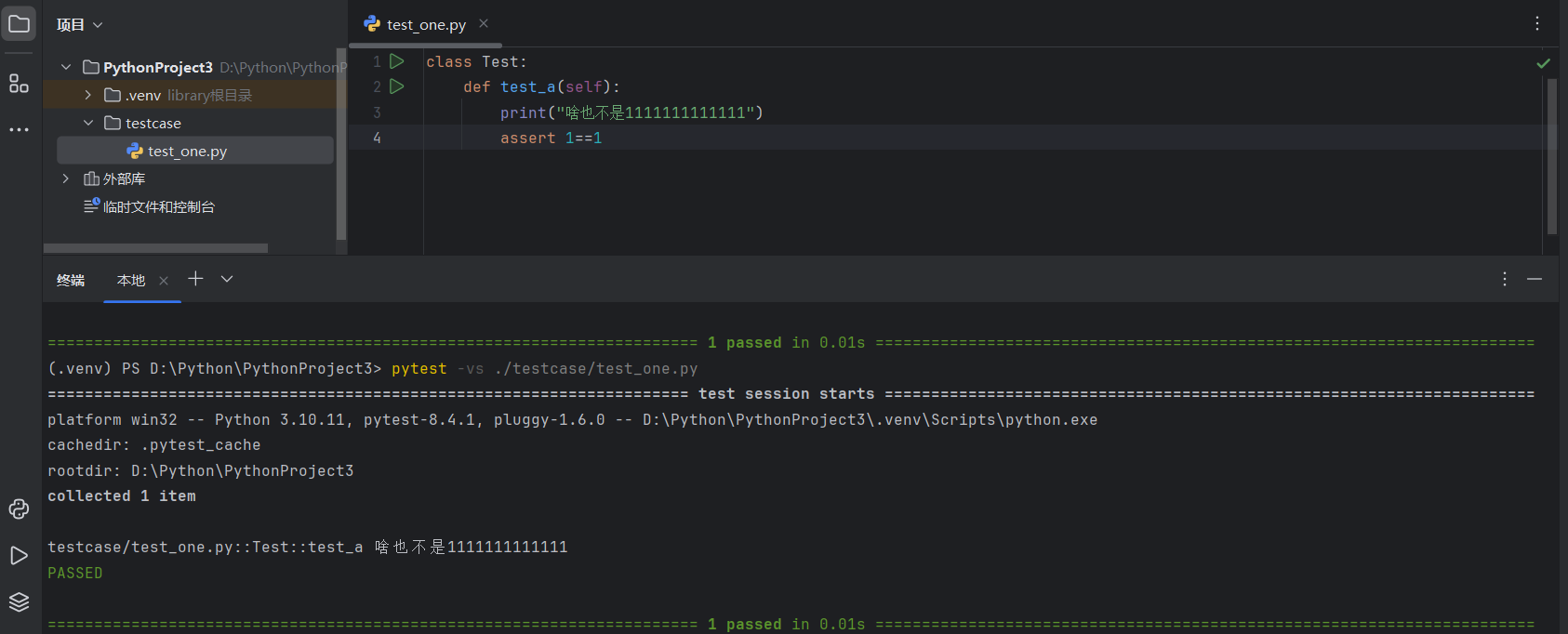
文件路径:testcase/test_one.py
def test_a():print("啥也不是1111111111111")assert 1==1#终端输入:pytest -vs| 参数 | 描述 | 案例 |
|---|---|---|
| -v | 输出调试信息。如:打印信息 | pytest -v ./testcase/test_one.py |
| -q | 输出简单信息。 | pyets -q ./aaa/test_a.py |
| -s | 输出更详细的信息,如:文件名、用例名 | pytest -s ./aaa/test_a.py |
| -n | 多线程或分布式运行测试用例 | |
| -x | 只要有一个用例执行失败,就停止执行测试 | pytest -x ./testcase/test_one.py |
| – maxfail | 出现N个测试用例失败,就停止测试 | pytest --maxfail=2 ./testcase/test_one.py |
| –html=report.html | 生成测试报告 | pytest ./testcase/test_one.py --html=./report/report.html |
| –html=report.html | 生成测试报告 | pytest ./testcase/test_one.py --html=./report/report.html |
| -k | 根据测试用例的部分字符串指定测试用例,可以使用and,or | pytest -k “MyClass and not method”,这条命令会匹配文件名、类名、方法名匹配表达式的用例,这里这条命令会运行 TestMyClass.test_something, 不会执行 TestMyClass.test_method_simple |
五、pytest配置文件pytest.ini文件
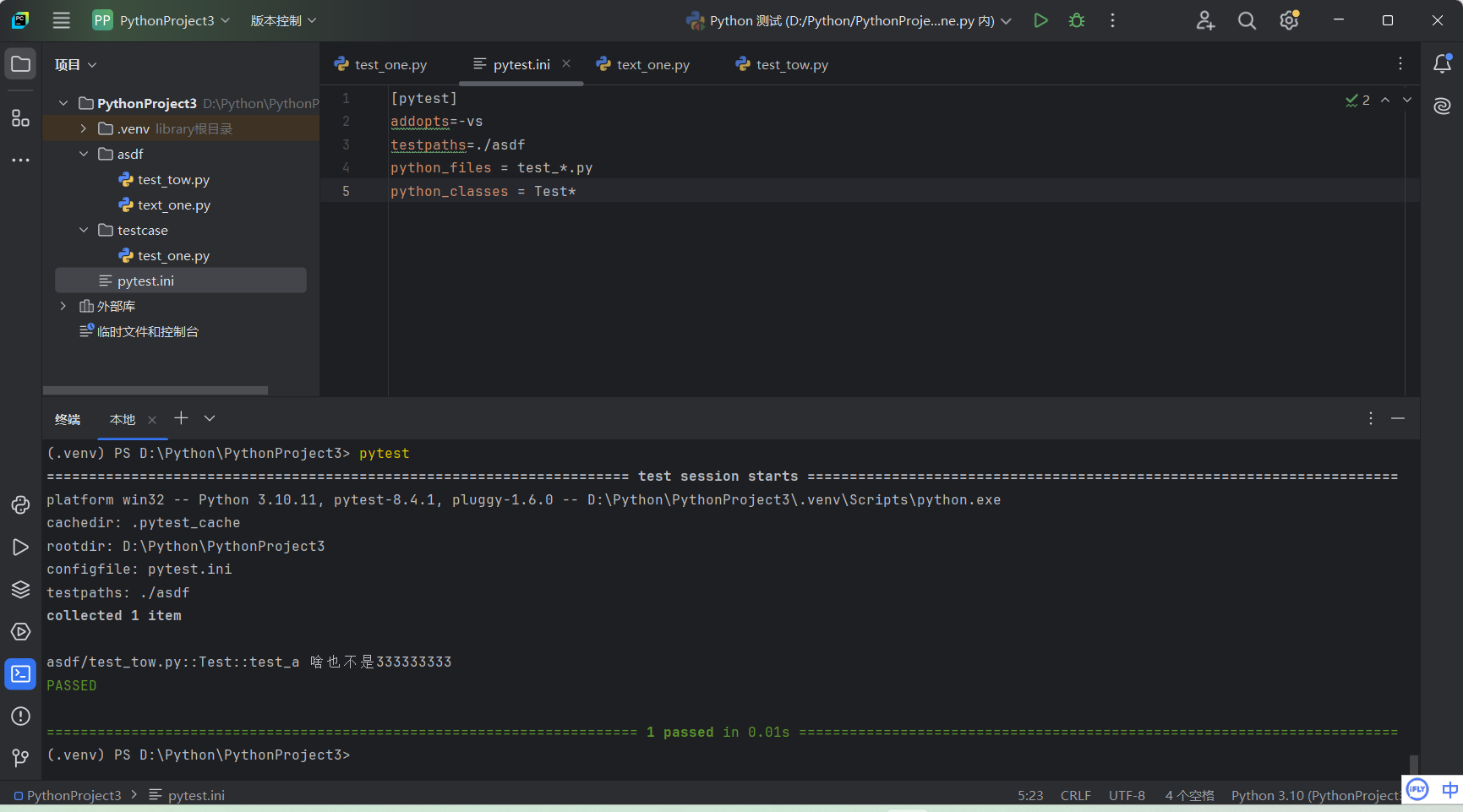
pytest的配置文件通常放在测试目录下,名称为pytest.ini,命令行运行时会使用该配置文件中的配置.
在项目的根目录下创建pytest.ini文件,pytset.ini文件尽可能不要出现中文。
| 参数 | 作用 |
|---|---|
| [pytest] | 用于标志这个文件是pytest的配置文件 |
| addopts | 命令行参数,多个参数之间用空格分隔 |
| testpaths | 配置搜索参数用例的范围 |
| python_files | 改变默认的文件搜索规则 |
| python_classes | 改变默认的类搜索规则 |
| python_functions | 改变默认的测试用例的搜索规则 |
| markers | 用例标记,自定义mark,需要先注册标记,运行时才不会出现warnings |
六、前置和后置
遗 留问题:使⽤pytest框架,测试类中不可以添加init()⽅法,如何进⾏数据的初始化?
在测试框架中,前后置是指在执用测试用例前和测试用例后执行⼀些额外的操作,这些操作可以用于 设置测试环境、准备测试数据等,以确保测试的可靠性
pytest 框架提供三种⽅法做前后置的操作:
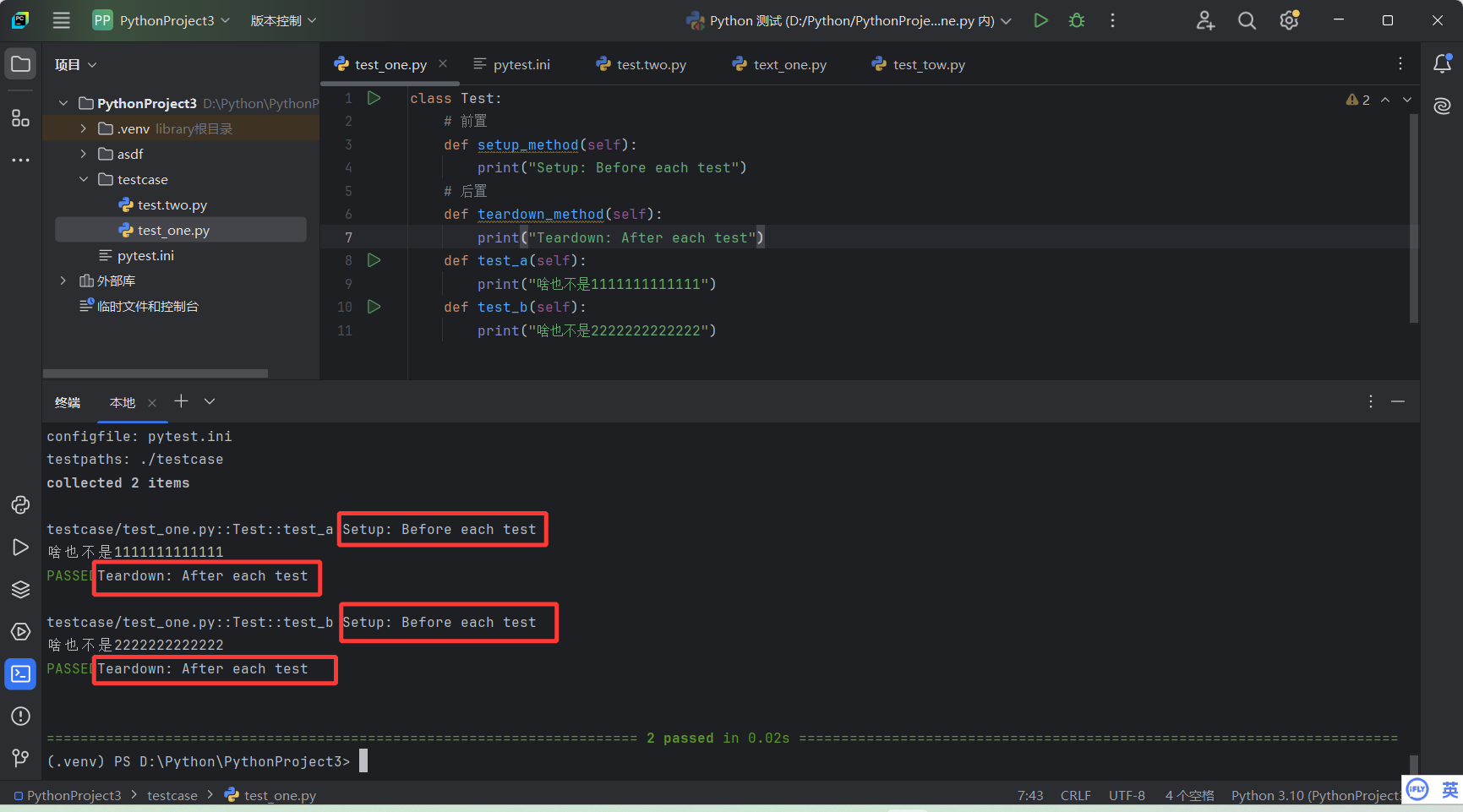
setup_method 和 teardown_method :这两个⽅法⽤于类中的每个测试⽅法的前置和后置操 作。
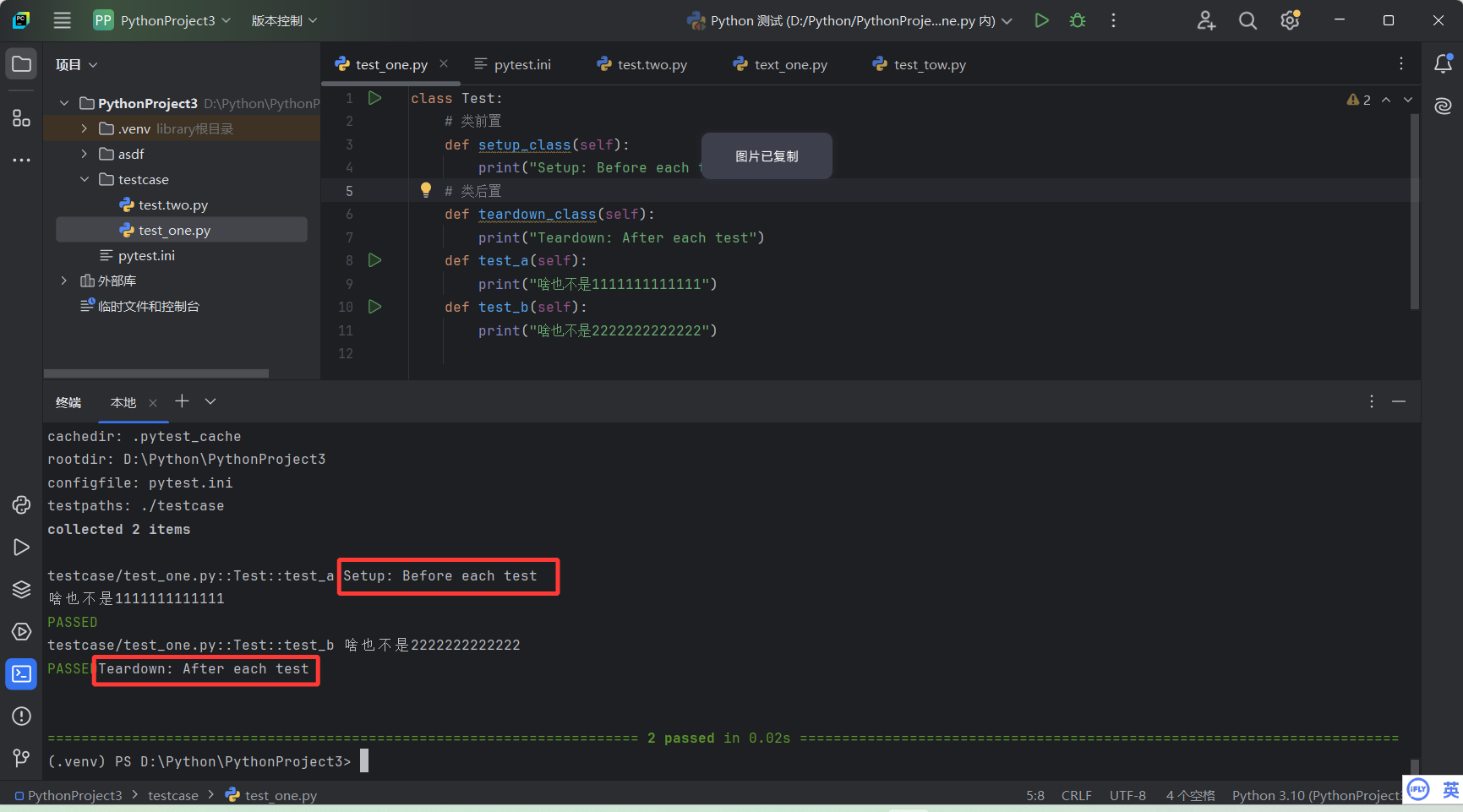
setup_class 和 teardown_class :这两个⽅法⽤于整个测试类的前置和后置操作。
fixture :这是 pytest 推荐的⽅式来实现测试⽤例的前置和后置操作。 灵活的控制和更强⼤的功能。(后面会对他进行单独介绍)
setup_method 和 teardown_method
在每个测试用例之前都会,先执行前置函数,每个测试用例之后,执行后置函数
setup_class 和 teardown_class
只会在每个类之前或之后,才会执行前后置函数
七、assert断言
断⾔( assert )是⼀种调试辅助⼯具,⽤于检查程序的状态是否符合预期。如果断⾔失败(即条件 为假),Python解释器将抛出⼀个 AssertionError 异常。断⾔通常⽤于检测程序中的逻辑错误。 pytest 允许你在Python测试中使⽤标准的Python assert 语句来验证预期和值。
基本语法:
assert 条件, 错误信息-
条件:必须是⼀个布尔表达式。
-
错误信息:当条件为假时显⽰的错误信息,可选。
基本数据类型的断⾔
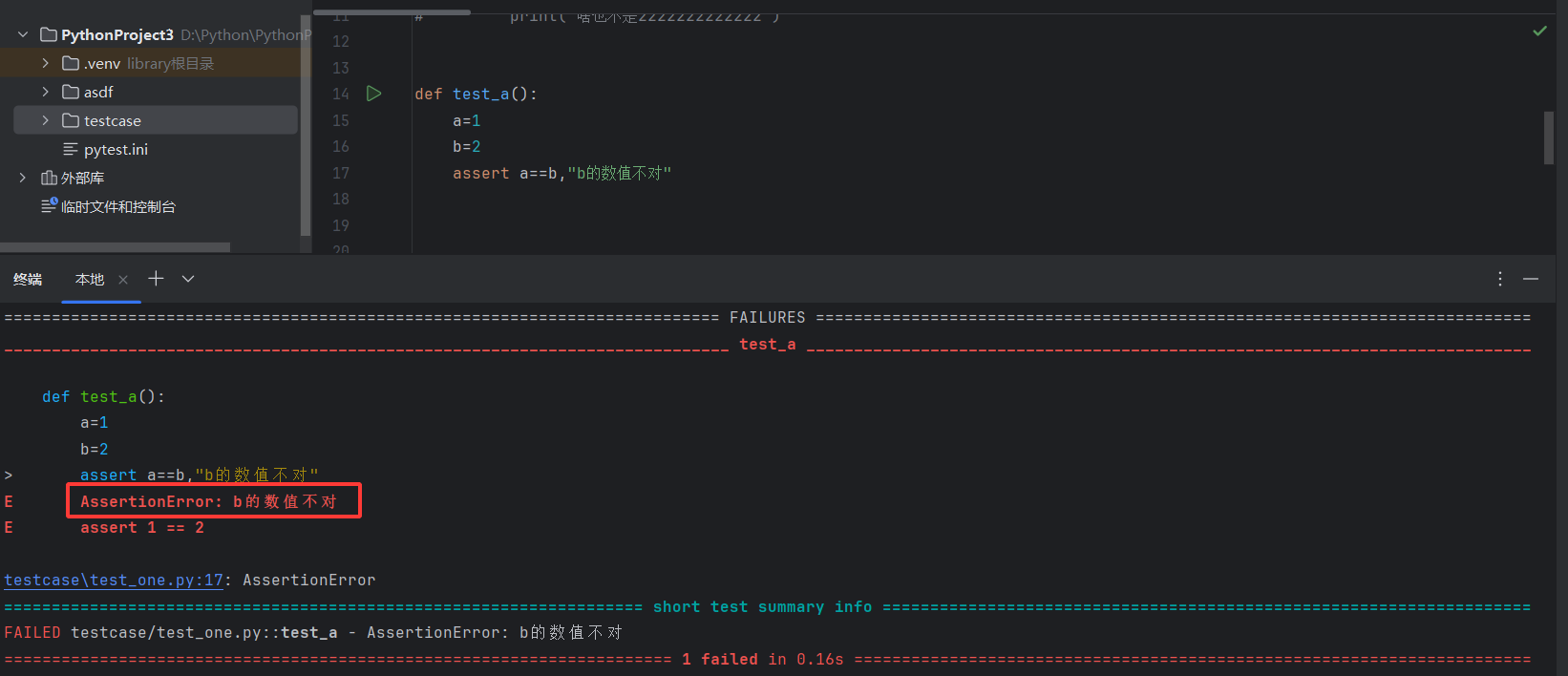
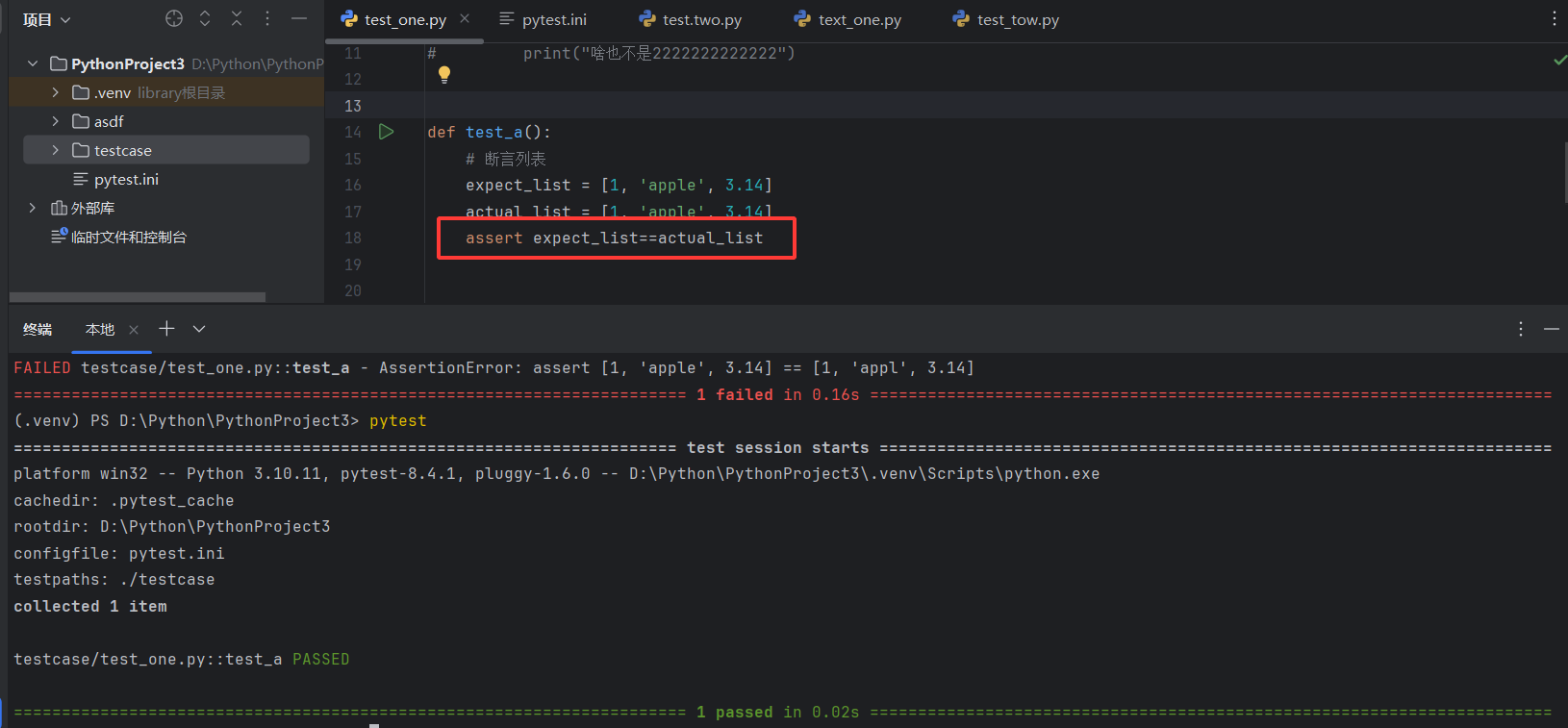
数据结构断⾔
接⼝返回值断言
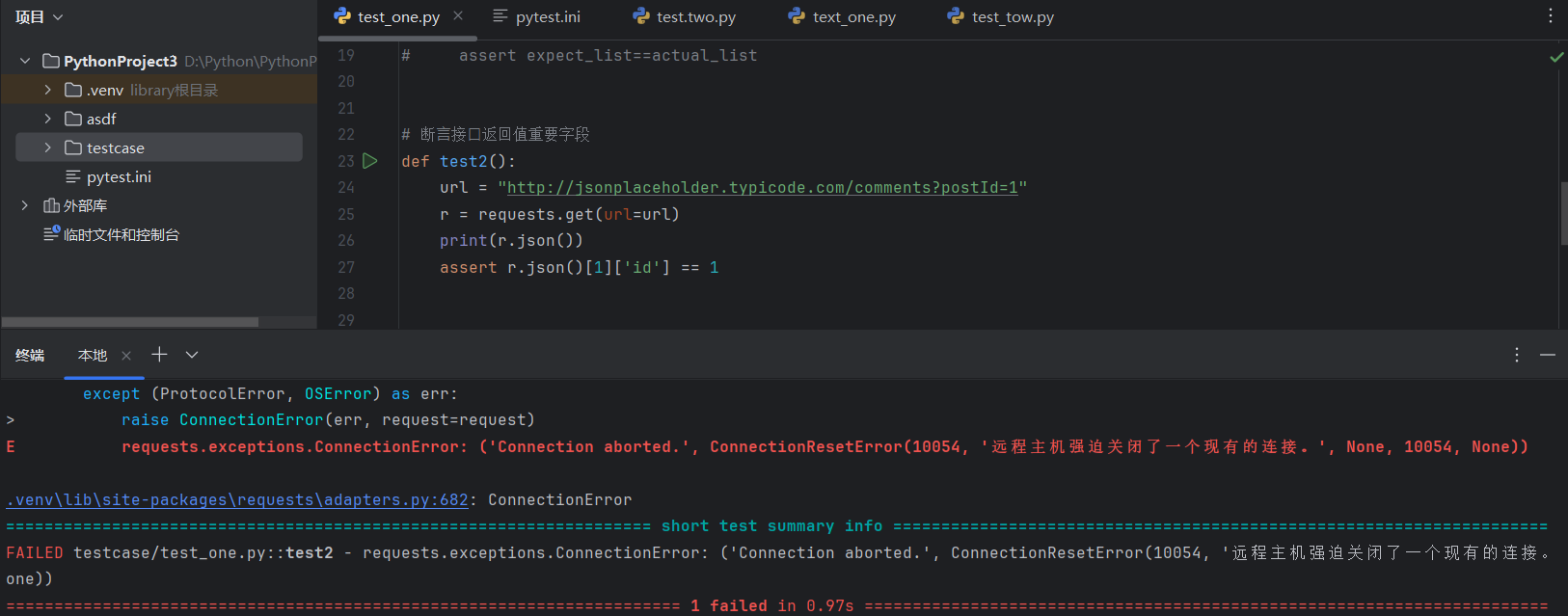
由于之前的网址关了,所以拿不到返回值
八、pytest中conftest.py文件
8.1、conftest.py的特点
pytest 会默认读取 conftest.py里面的所有 fixture
conftest.py 文件名称是固定的,不能改动
conftest.py 只对同一个 package 下的所有测试用例生效
不同目录可以有自己的 conftest.py,一个项目中可以有多个 conftest.py
测试用例文件中不需要手动 import conftest.py,pytest 会自动查找
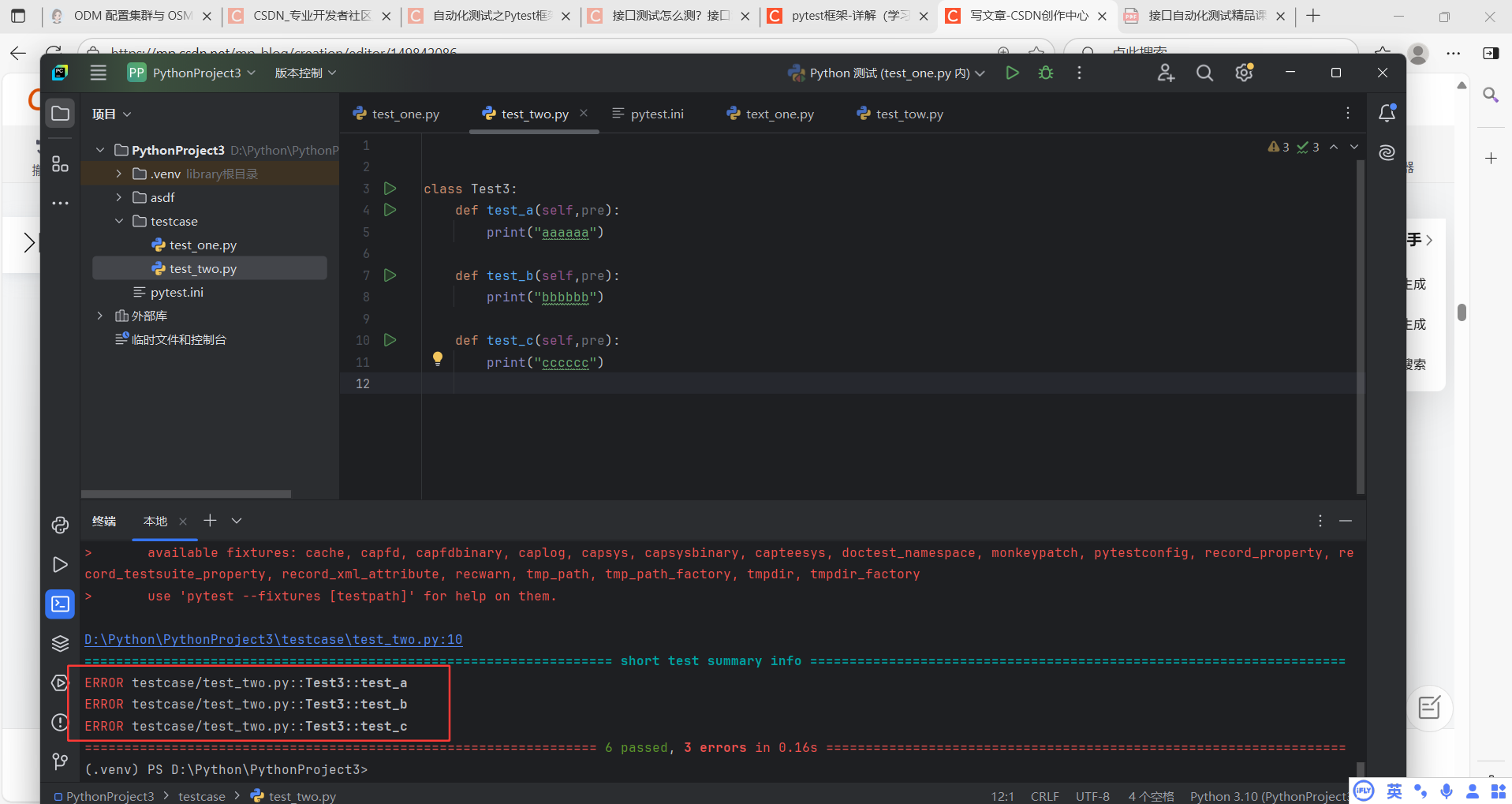
如果有两个文件,其中一个文件中没有@pytest.fixture,但是我们的执行用例中却有前置参数,则pytest在执行时,无法在当前文件中找到@pytest.fixture时,则会报错
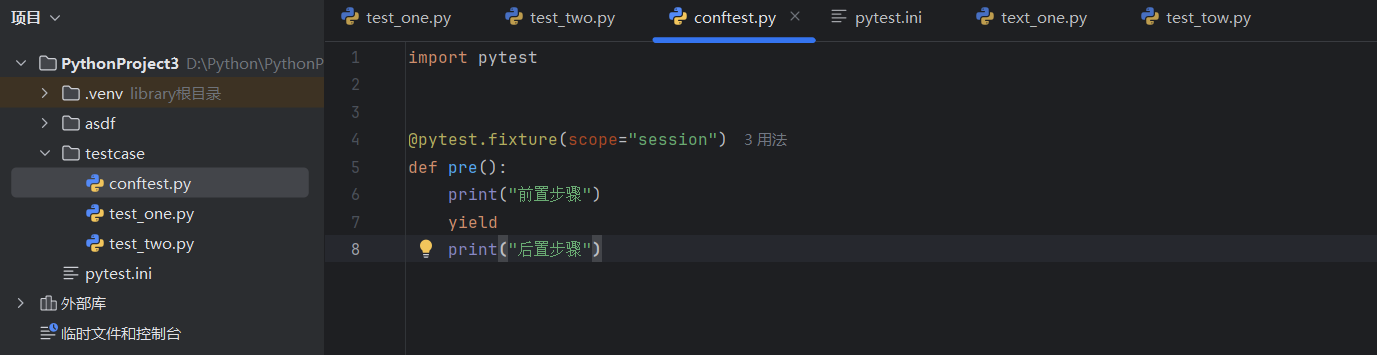
如果我们将前置函数放入conftest.py中,则其他.py文件都可以执行前置函数
九、pytest中fixtrue装饰器
虽然setup和teardown可以执行一些前置和后置操作,但是这种是针对整个脚本全局生效的
如果有以下场景:1.用例一需要执行登录操作;2.用例二不需要执行登录操作;3.用例三需要执行登录操作,则setup和teardown则不满足要求。fixture可以让我自定义测试用例的前置条件
9.1、基本使用
-
场景一:做为参数传入
# fixture函数(类中) 作为多个参数传入
@pytest.fixture()
def login():print("打开浏览器")@pytest.fixture()
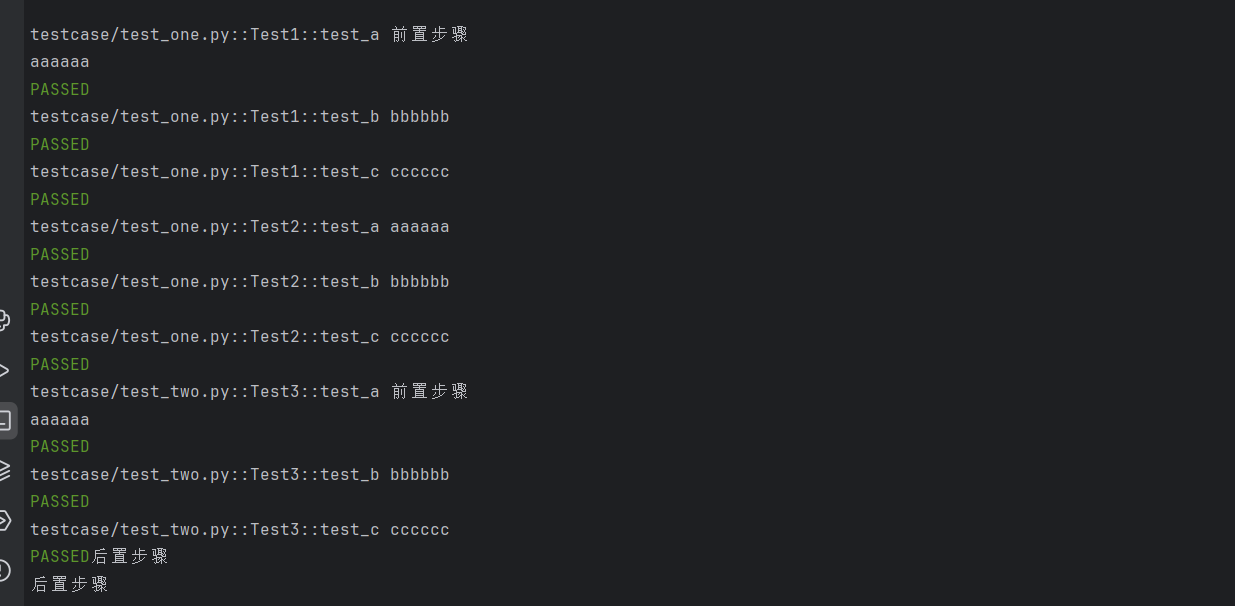
def logout():print("关闭浏览器")class TestLogin:# 传入lonin fixturedef test_001(self, login):print("001传入了loging fixture")# 传入logout fixturedef test_002(self, logout):print("002传入了logout fixture")def test_003(self, login, logout):print("003传入了两个fixture")def test_004(self):print("004未传入仍何fixture哦")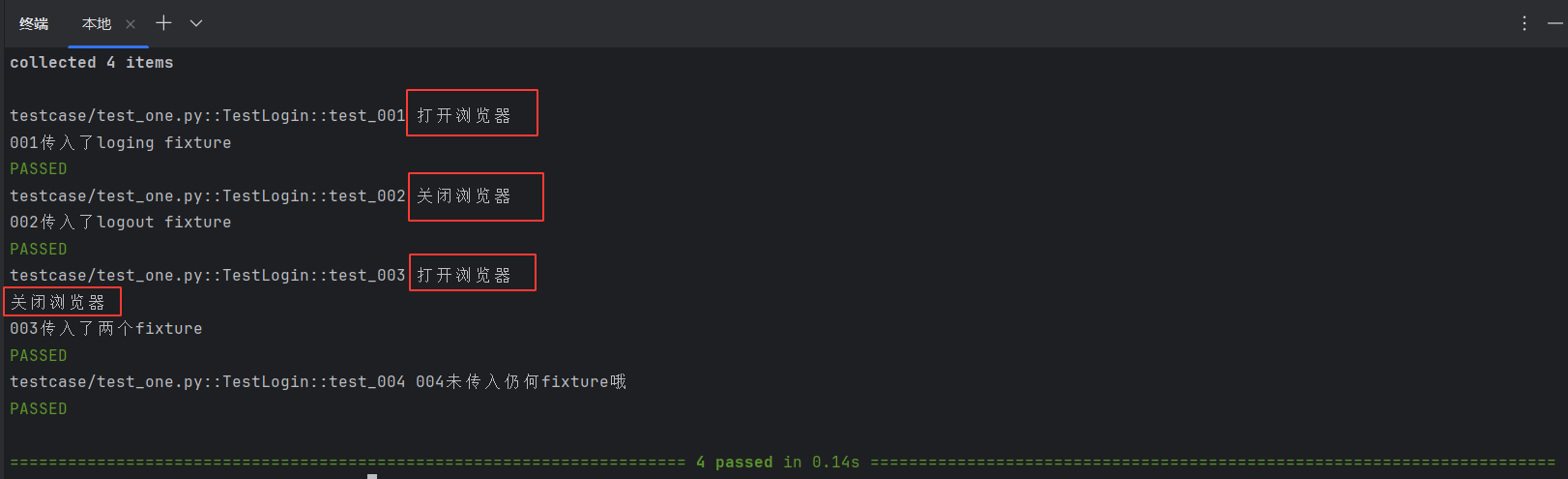
从运行结果可以看出,fixture做为参数传入时,会在执行函数之前执行该fixture函数。再将值传入测试函数做为参数使用,这个场景多用于登录
-
场景二:Fixture的相互调用
# fixtrue作为参数,互相调用传入
@pytest.fixture()
def account():a = "account"print("第一层fixture")return a
# Fixture的相互调用一定是要在测试类里调用这层fixture才会生次,普通函数单独调用是不生效的
@pytest.fixture()
def login(account):print("第二层fixture")class TestLogin:#若没有返回值,则默认形参为Nonedef test_1(self, login):print("直接使用第二层fixture,返回值为{}".format(login))#如果@pytest.fixture()的函数中有返回值,则1会将返回值作为参数传给account(形参)def test_2(self, account):print("只调用account fixture,返回值为{}".format(account))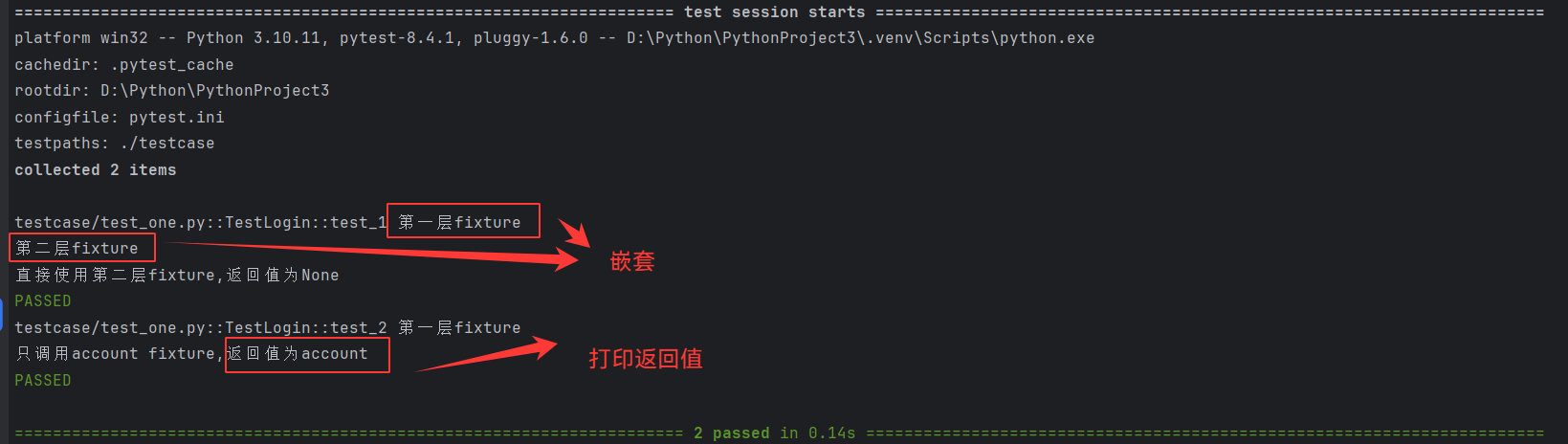
即使fixture之间支持相互调用,但普通函数直接使用fixture是不支持的,一定是在测试函数内调用才会逐级调用生效
有多层fixture调用时,最先执行的是最后一层fixture,而不是先执行传入测试函数的fixture
上层fixture的值不会自动return,这里就类似函数相互调用一样的逻辑
9.2、yield(后置)
当我们运⾏测试时,我们希望确保它们能够⾃我清理,以便它们不会⼲扰其他测试(同时也避免留下⼤量测试数据来膨胀系统)。pytest中的 个 fixture 定义具体的清理步骤。
在 pytest 中,yield是 fixture 机制的核心语法之一,用于在测试前后实现资源的初始化与清理,替代了传统测试框架中的
setup/teardown结构,且更加灵活。
-
yield之前的代码:作为前置操作(如创建数据库连接、启动服务、生成测试数据等)。
-
yield之后的代码:作为后置操作(如关闭连接、停止服务、清理临时文件等),无论测试是否成功,都会执行。
-
yield 关键字本身可以返回一个值,供测试函数使用(类似
return)。
@pytest.fixture()
def pre():print("开始计算")yield 100print("计算完毕")def test_add(pre):a=100+preprint(a)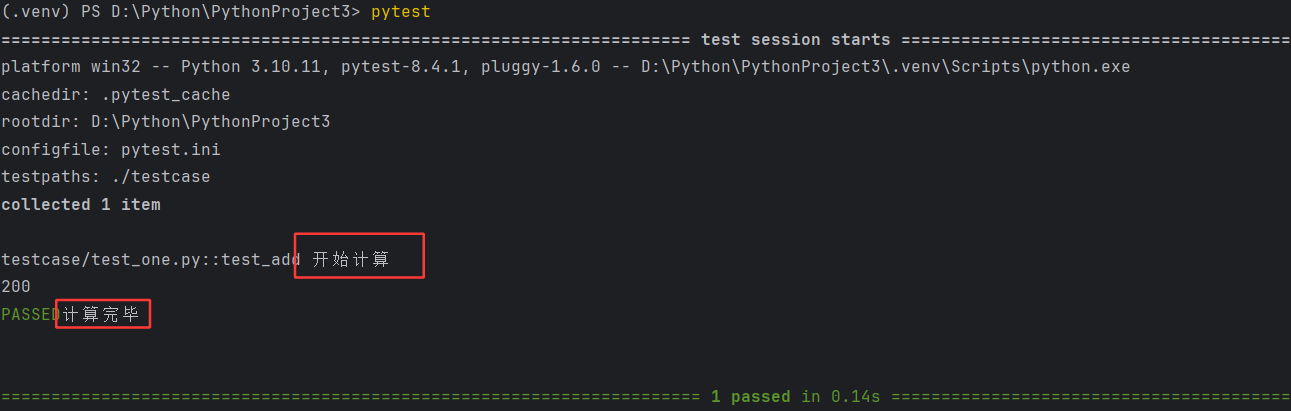
创建⽂件句柄与关闭⽂件
@pytest.fixture()
def file():print("打开文件句柄")fo=open("./testcase/test_b.txt","r",encoding="utf-8")yield foprint("关闭文件句柄")fo.close()def test_a(file):r=filestr=r.read(20)print(str)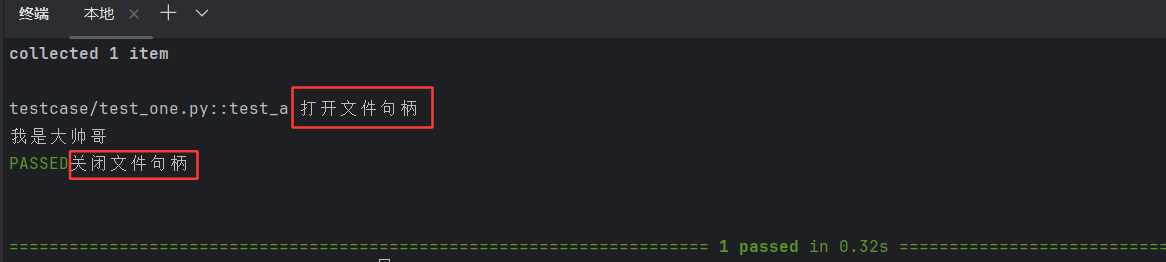
9.3、带参数fixtrue
格式:
pytest.fixture(scope='', params='', autouse='', ids='', name='')参数详解:
1. scope参数⽤于控制fixture的作⽤范围,决定了fixture的⽣命周期。可选值有:
function (默认):每个测试函数都会调⽤⼀次fixture。
class :在同⼀个测试类中共享这个fixture。
module :在同⼀个测试模块中共享这个fixture。(⼀个⽂件⾥)
session :整个测试会话中共享这个fixture。
2. autouse 参数默认为False 。如果设置为True ,则每个测试函数都会⾃动调⽤该fixture,⽆需显式传⼊
3. params 参数⽤于参数化fixture,⽀持列表传⼊。每个参数值都会使fixture执⾏⼀次,类似于for循环
4. ids 参数与 params 配合使⽤,为每个参数化实例指定可读的标识符(给参数取名字)
5. name 参数⽤于为fixture显式设置⼀个名称。如果使⽤了 名称来引⽤ name ,则在测试函数中需要使⽤这个 fixture (给fixture取名字)
9.3.1、scope
function (默认):每个测试函数都会调⽤⼀次fixture。
@pytest.fixture(scope="function")
def pre():print("前置步骤")class Test:def test_a(self,pre):print("aaaaaa")def test_b(self,pre):print("bbbbbb")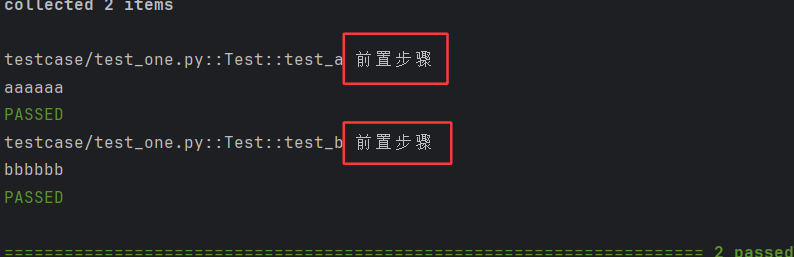
class :在同⼀个测试类中共享这个fixture。
当测试类内的每一个测试方法都调用了fixture,fixture只在该class下所有测试用例执行前执行一次
@pytest.fixture(scope="class")
def pre():print("前置步骤")yieldprint("后置步骤")class Test:def test_a(self,pre):print("aaaaaa")def test_b(self,pre):print("bbbbbb")def test_c(self,pre):print("cccccc")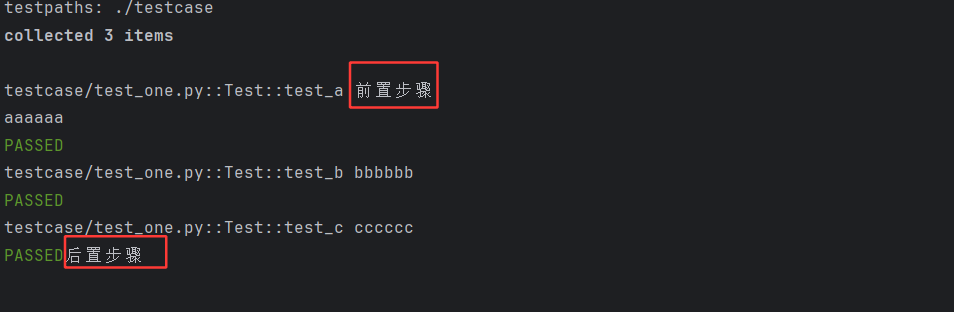
module :在同⼀个测试模块中共享这个fixture。(⼀个⽂件⾥)(与class相同,只从.py文件开始引用fixture的位置生效)
@pytest.fixture(scope="session")
def pre():print("前置步骤")yieldprint("后置步骤")class Test1:def test_a(self,pre):print("aaaaaa")def test_b(self,pre):print("bbbbbb")def test_c(self,pre):print("cccccc")class Test2:def test_a(self,pre):print("aaaaaa")def test_b(self,pre):print("bbbbbb")def test_c(self,pre):print("cccccc")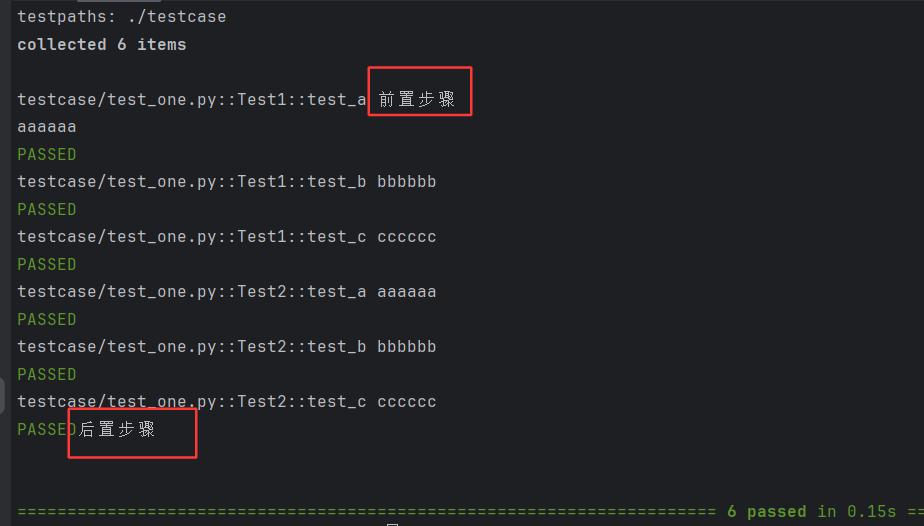
session :整个测试会话中共享这个fixture。
-
session的作用范围是针对.py级别的,module是对当前.py生效,seesion是对多个.py文件生效
-
session只作用于一个.py文件时,作用相当于module
-
所以session多数与contest.py文件一起使用,做为全局Fixture
9.3.2、autouse
默认False
若为True,刚每个测试函数都会自动调用该fixture,无需传入fixture函数名
由此我们可以总结出调用fixture的三种方式:
1.函数或类里面方法直接传fixture的函数参数名称
2.autouse=True自动调用,无需传仍何参数,作用范围跟着scope走(谨慎使用)
让我们来看一下,当autouse=True的效果:
@pytest.fixture(autouse=True)
def pre():print("前置步骤")yieldprint("后置步骤")class Test1:def test_a(self):print("aaaaaa")def test_b(self):print("bbbbbb")def test_c(self):print("cccccc")class Test2:def test_a(self):print("aaaaaa")def test_b(self):print("bbbbbb")def test_c(self):print("cccccc")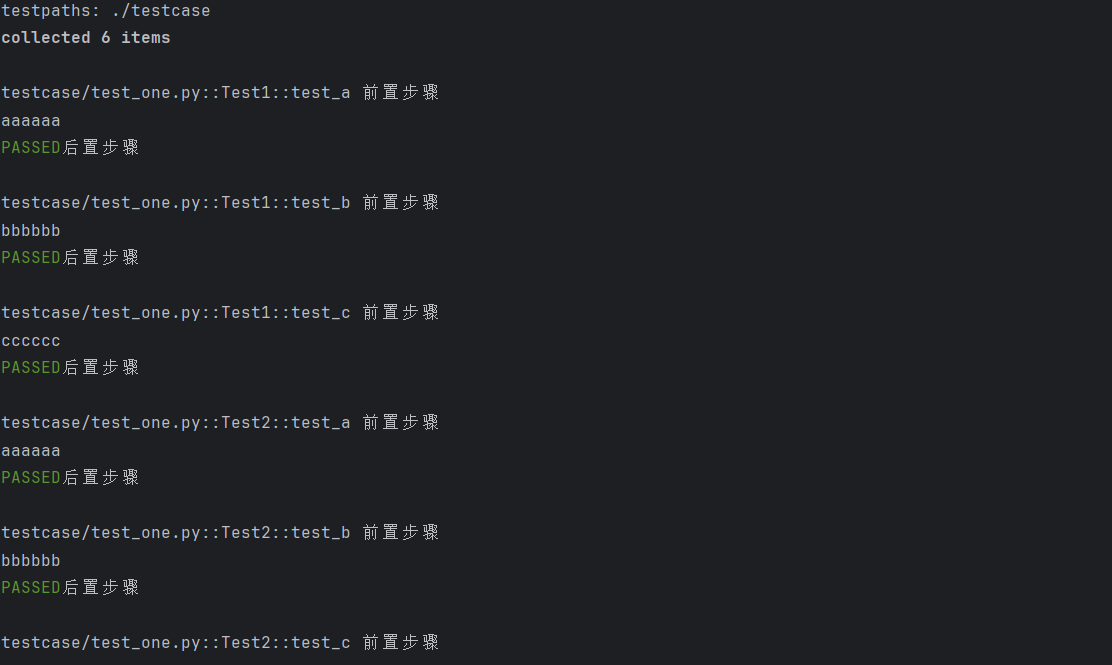
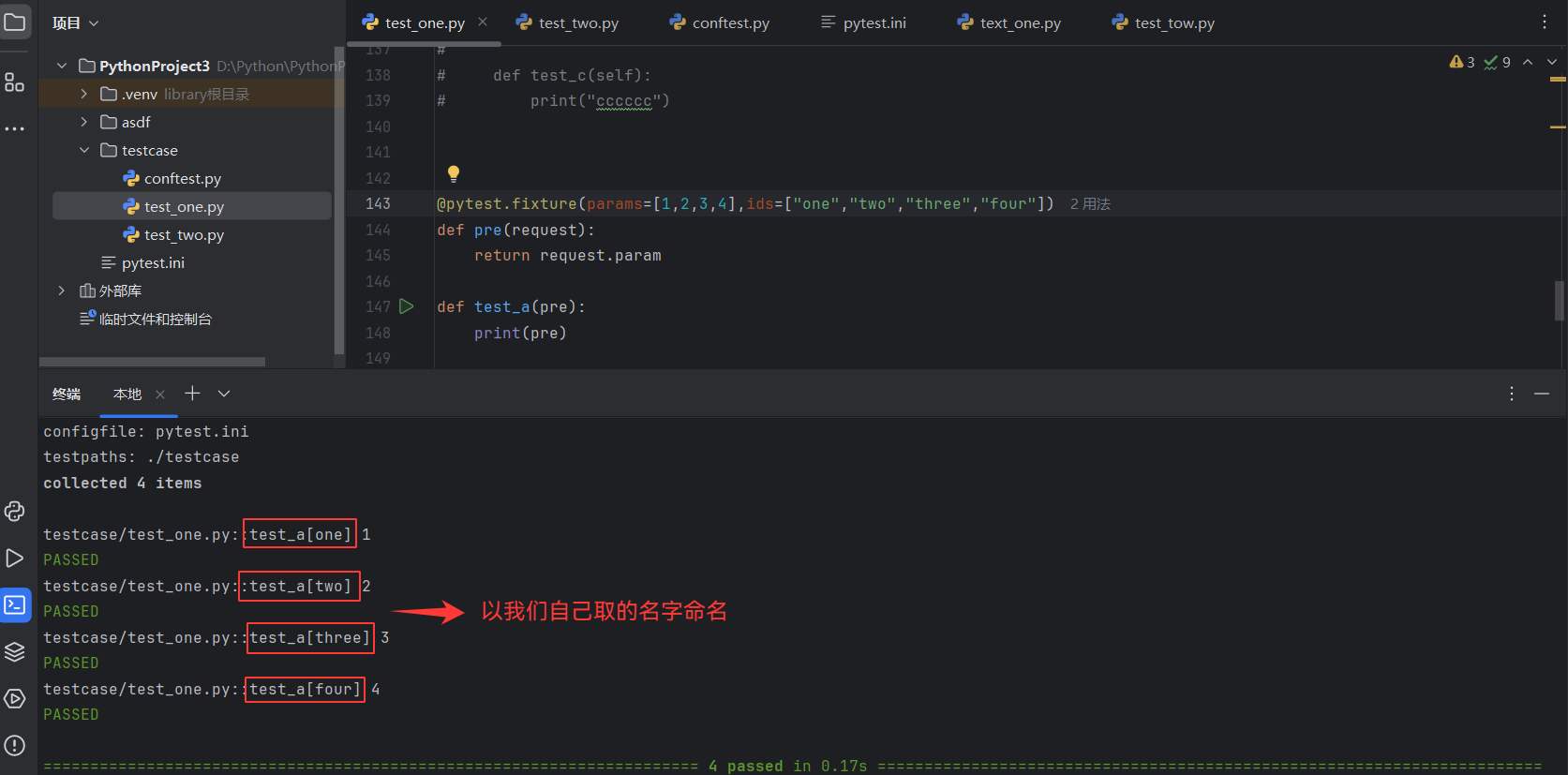
9.3.3、params
Fixture的可选形参列表,支持列表传入
默认None,每个param的值
fixture都会去调用执行一次,类似for循环
可与参数ids一起使用,作为每个参数的标识,详见ids
被Fixture装饰的函数要调用是采用:Request.param(固定写法,如下图)
@pytest.fixture(params=[1,2,3,4])
def pre(request):return request.paramdef test_a(pre):print(pre)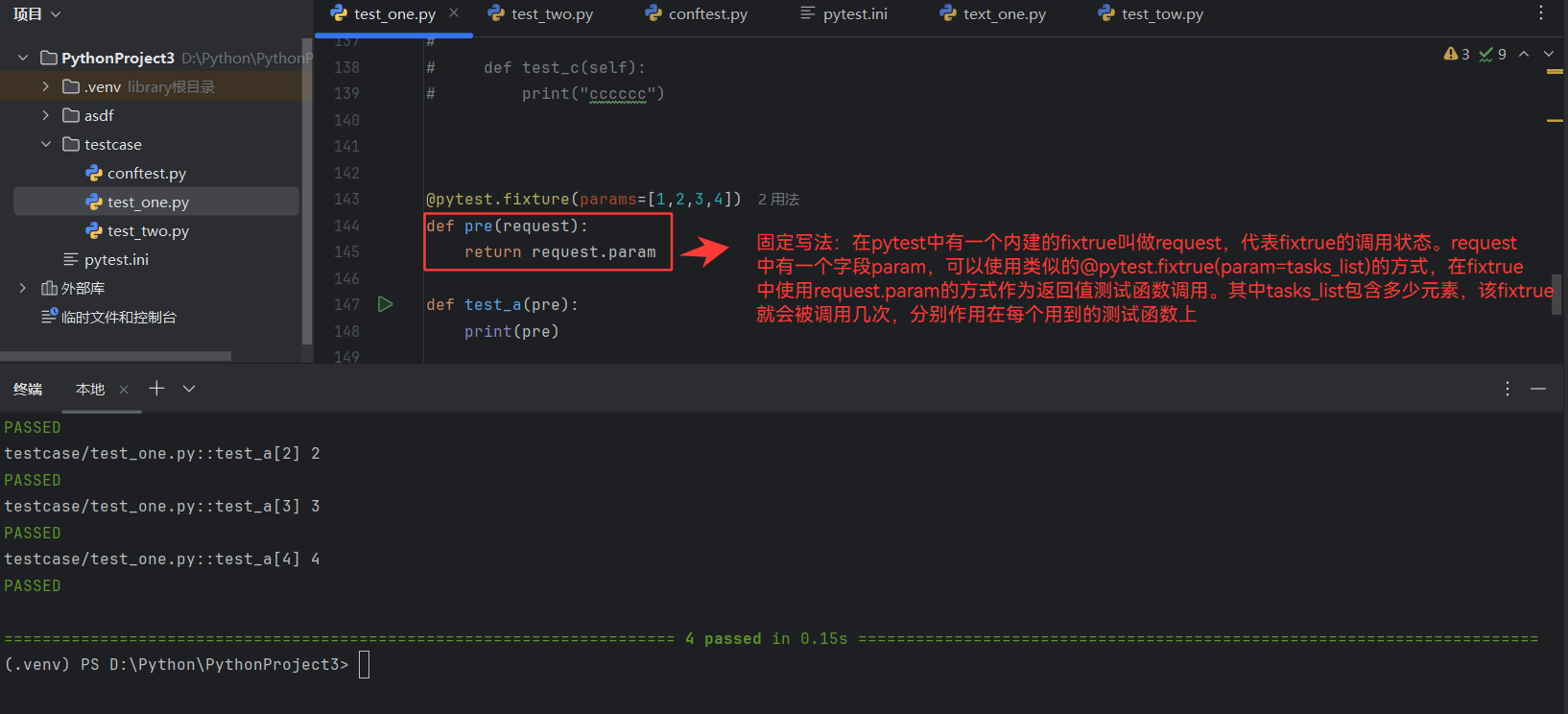
9.3.4、ids
用例标识ID与params配合使用,一对一关系
未配置ids之前,用例:
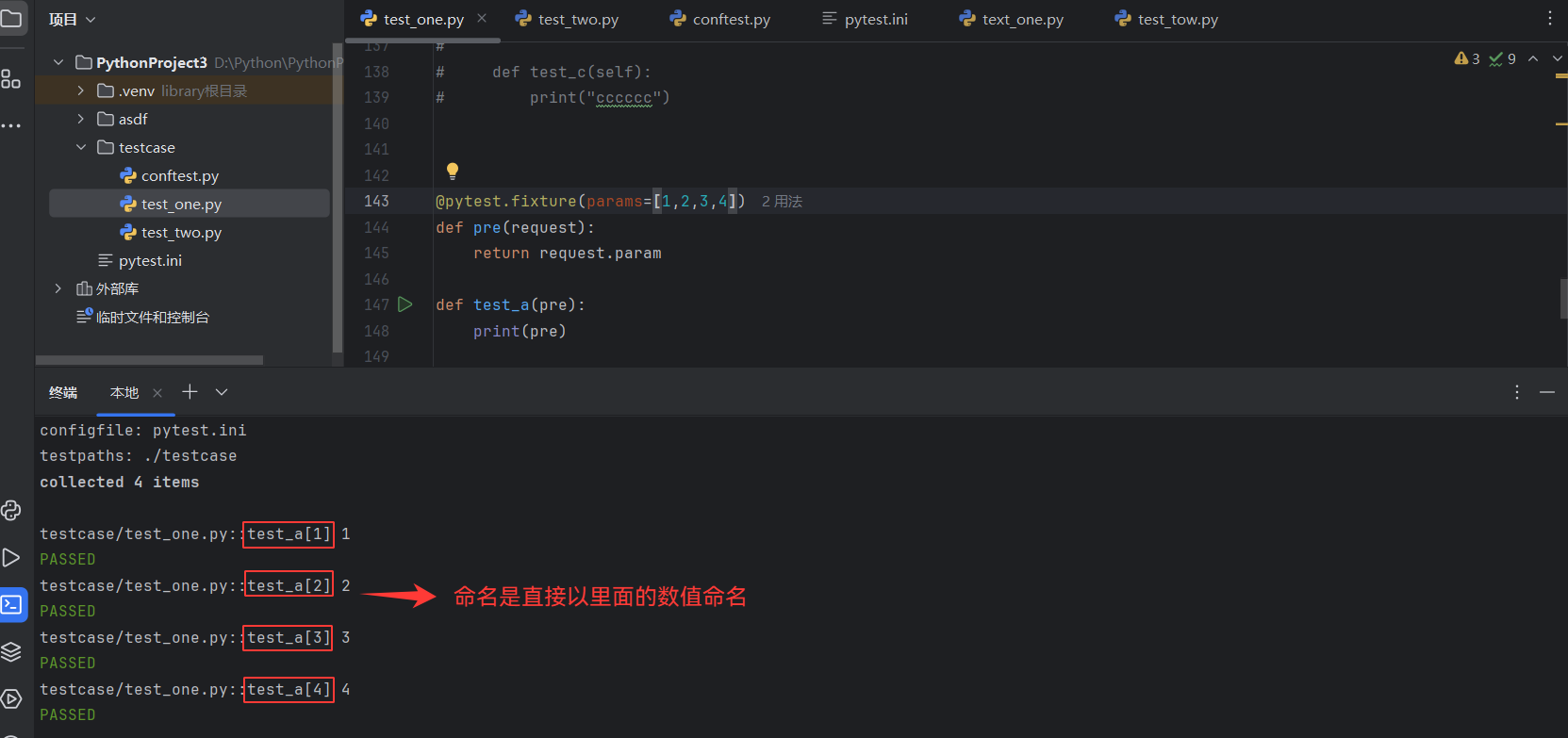
配置了ids后:
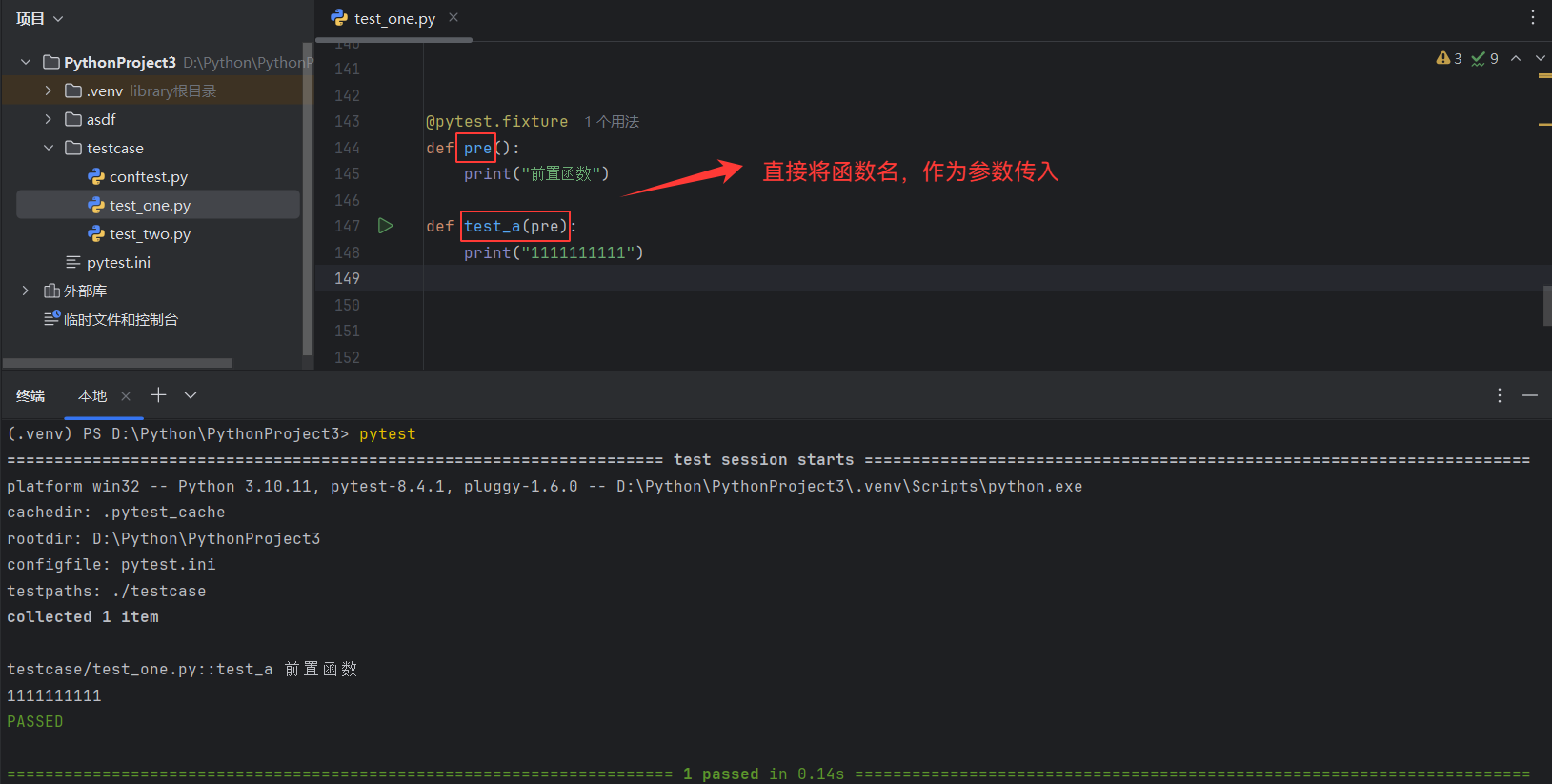
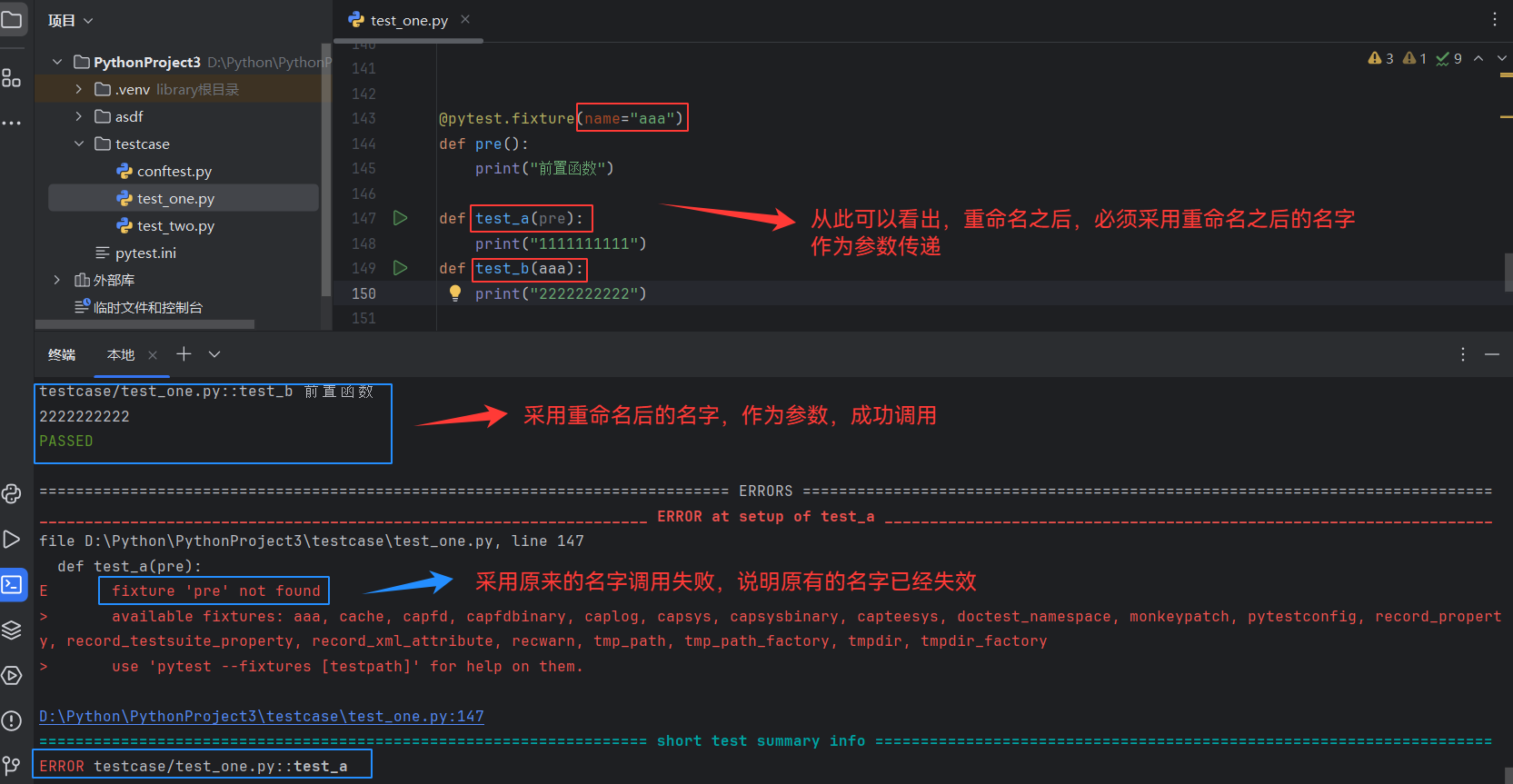
9.3.5、name
fixture的重命名
通常来说使用 fixture 的测试函数会将 fixture 的函数名作为参数传递,但是 pytest 也允许将fixture重命名
如果使用了name,那只能将name传如,函数名不再生效
举例:没有name
有name
十、logging日志模块
10.1、介绍
logging 是Python标准库中的⼀个模块,它提供了灵活的⽇志记录功能。通过 logging ,开发者可以⽅便地将⽇志信息输出到控制台、⽂件、⽹络等多种⽬标,同时⽀持不同级别的⽇志记录,以 满⾜不同场景下的需求。
10.2、使用
全局使用
import logginglogging.debug("This is a debug message")
logging.info("This is a info message")
logging.warning("This is a warning message")
logging.error("This is a error message")
logging.critical("This is a critical message")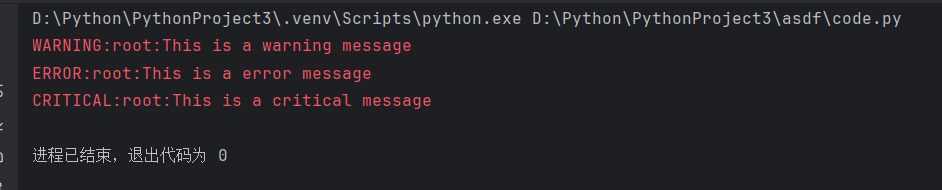
自定义logger的名字并输出到日志文件
import logging# 获取一个日志记录器对象,并且可以设置其名字
logger=logging.getLogger("log")# 设置日志器的输出等级,只有大于这个等级的才会被输出
logger.setLevel(logging.DEBUG)# 创建⼀个FileHandler对象,指定⽇志⽂件的名称为"test.log"
# 这个处理器会将⽇志信息写⼊到指定的⽂件中
handler=logging.FileHandler(filename="aaa.log")# 将这个处理器添加到⽇志记录器中
# 这样,⽇志记录器就会使⽤这个处理器来处理⽇志信息
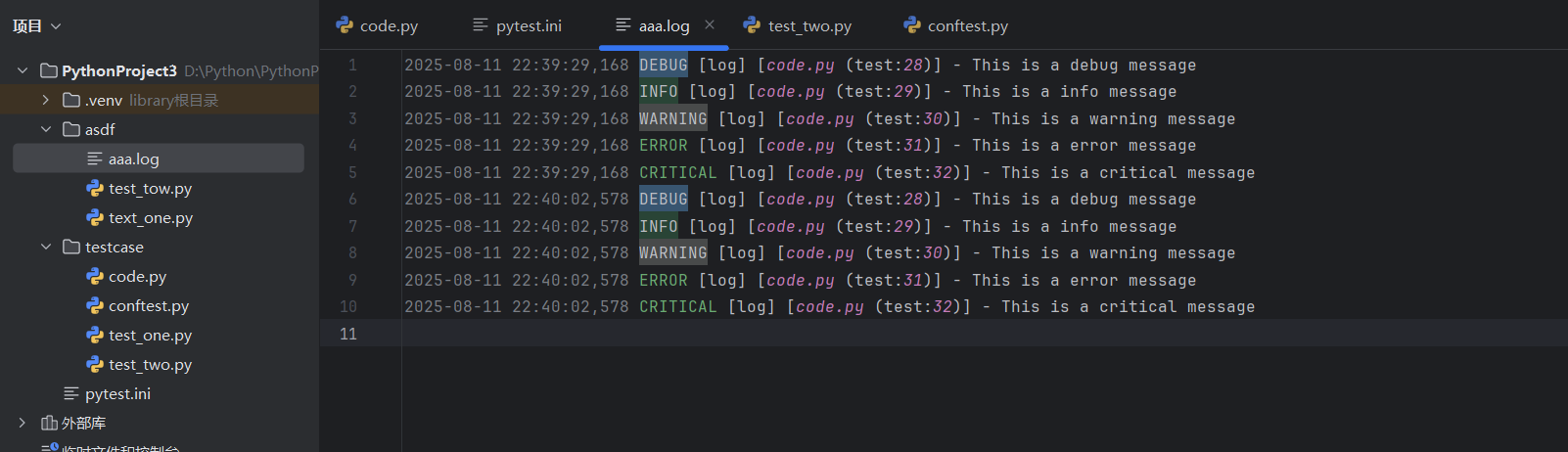
logger.addHandler(handler)def test():logger.debug("This is a debug message")logger.info("This is a info message")logger.warning("This is a warning message")logger.error("This is a error message")logger.critical("This is a critical message")
-
获取⽇志记录器: logging.getLogger(__name__) 获取⼀个⽇志记录器对象, name 是当前模块的名称。使⽤模块名称作为⽇志记录器的名称有助于在⼤型项⽬中区分不同模块的⽇志.
-
设置⽇志级别: logger.setLevel(logging.DEBUG) 将⽇志记录器的级别设置为 DEBUG ,这意味着所有 DEBUG 及以上级别的⽇志都会被记录.
-
创建⽂件处理器: logging.FileHandler(filename="aaa.log") 创建⼀个⽂件处理 器,将⽇志信息写⼊到名为 test.log 的⽂件中.
-
添加处理器: logger.addHandler(handler) 将⽂件处理器添加到⽇志记录器中,这样⽇志 记录器就会使⽤这个处理器来处理⽇志信息
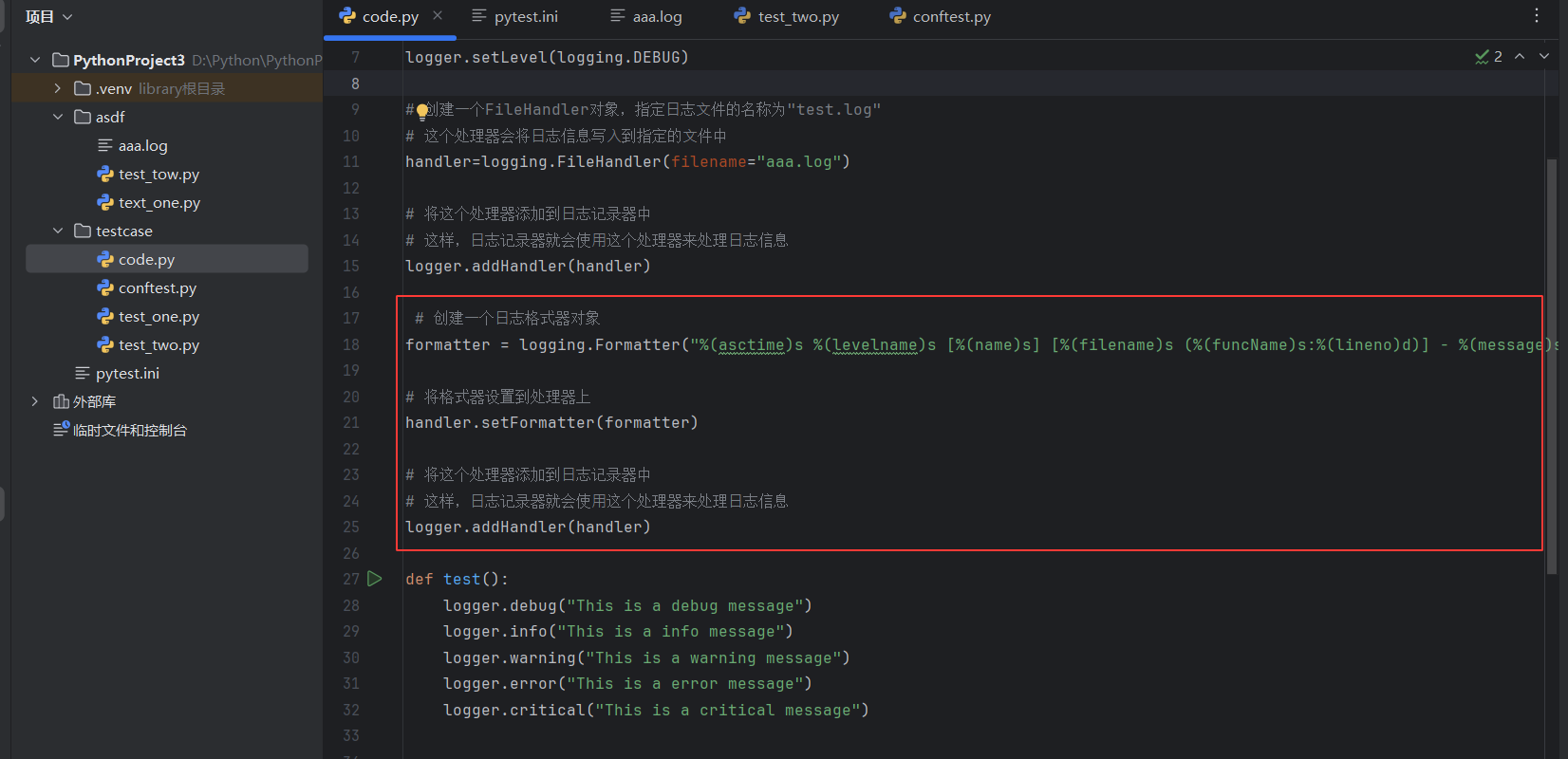
设置日志格式
-
logging.Formatter 是用于定义日志输出格式的类。在构造函数中,传递了⼀个格式字符串,用于指定日志信息的格式。格式字符串中使⽤了⼀些特殊的占位符(以 % 开头),这些占位符会被替换 为相应的日志信息内容
-
handler.setFormatter(formatter) 将创建的格式器对象设置到处理器上。这意味着处理器 在处理⽇志信息时,会使用这个格式器来格式化⽇志信息.
| 格式占位符 | 说明 |
| %(asctime)s | ⽇志记录的时间戳,通常显⽰为⽇期和时间。 |
| %(levelname)s | ⽇志级别(如DEBUG、INFO、WARNING、ERROR、CRITICAL)。 |
| %(name)s | ⽇志记录器的名称,通常为模块名称。 |
| %(filename)s | ⽇志记录发⽣的⽂件名。 |
| %(funcName)s | ⽇志记录发⽣的函数名。 |
| %(lineno)d | ⽇志记录发⽣的⾏号。 |
| %(message)s | ⽇志消息本⾝。 |
十一、测试报告allur
11.1、介绍
Allure Report 由⼀个框架适配器和 allure 命令⾏⼯具组成,是⼀个流⾏的开源⼯具,⽤于可视化 测试运⾏的结果。它可以以很少甚⾄零配置的⽅式添加到您的测试⼯作流中。它⽣成的报告可以在任何地⽅打开,并且任何⼈都可以阅读,⽆需深厚的技术知识.
11.2、安装
下载allure-pytest包
pip install allure-pytest==2.13.5下载Windows版Allure报告
下载链接:https://github.com/allure-framework/allure2/releases/download/2.30.0/allure 2.30.0.zip
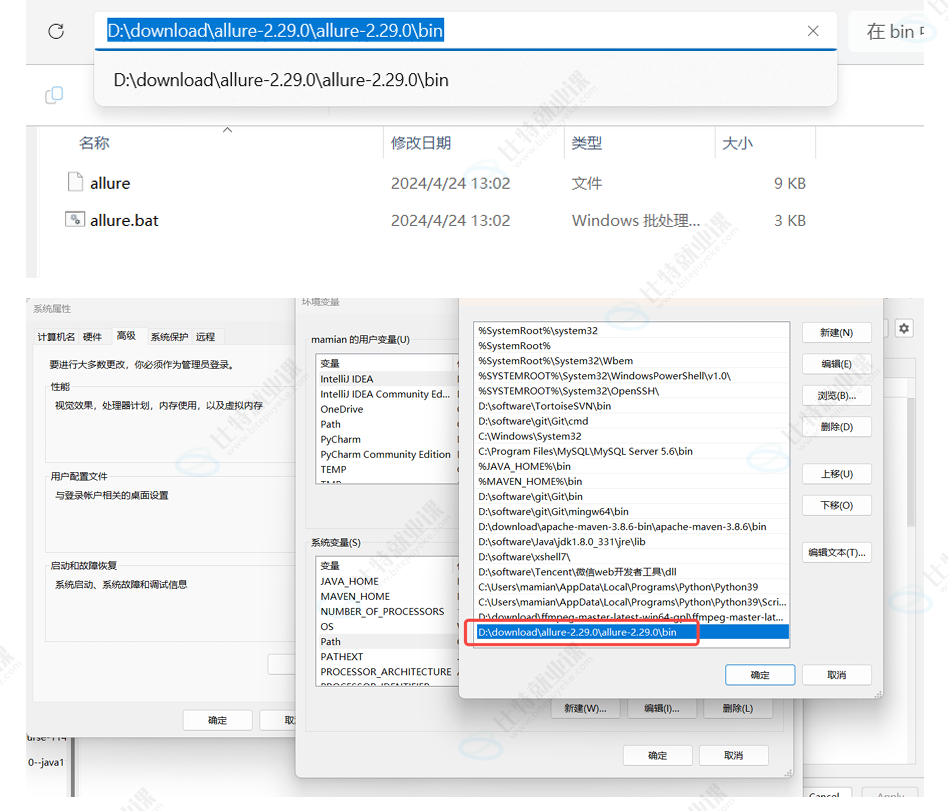
添加系统环境变量
将allure-2.29.0 对应bin⽬录添加到系统环境变量中
确认结果
打 开cmd,查看allure版本
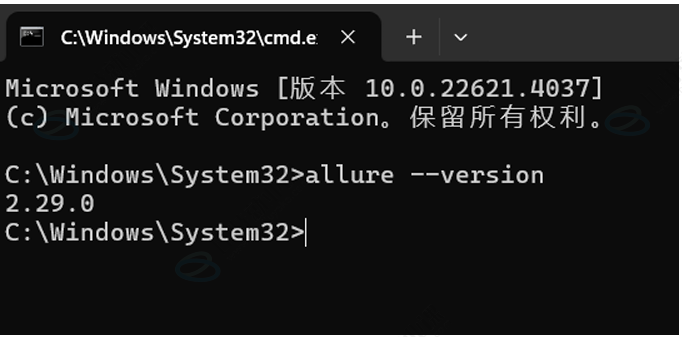
出现 a llure 版本则安装成功。
10.3、使用
step1:运行自动化,并指定测试报告放置路径
代码块pytest --alluredir=results_dir
(保存测试报告的路径)⽰例:
pytest --alluredir=allure-results生成测试报告可以在控制台通过命令将结果保存在 pytest.ini⽂件中配置测试报告放置路径 allre-results ⽂件夹中,也可以在 addopts = -vs --alluredir allure-results
step2:查看测试报告
⽅法⼀:启动⼀个本地服务器来在浏览器中展⽰测试报告
终端执⾏命令: allure serve [options] <allure-results>,⾃动在浏览器打开测试 报告(options:其他的配置项,<allure-results>:存放测试报告的路径)
-
--host :指定服务器监听的主机地址,默认为localhost。
-
-- port :指定服务器监听的端⼝号,默认为0(⾃动选择空闲端⼝)
-
--clean-alluredir :清除上⼀次⽣成的测试报告
不指定端⼝号和主机地址
allure serve .\allure-results\指定端⼝号
allure serve --port 8787 .\allure-results\ 清除上⼀次⽣成的测试报告
allure serve .\allure-results\ --clean-alluredir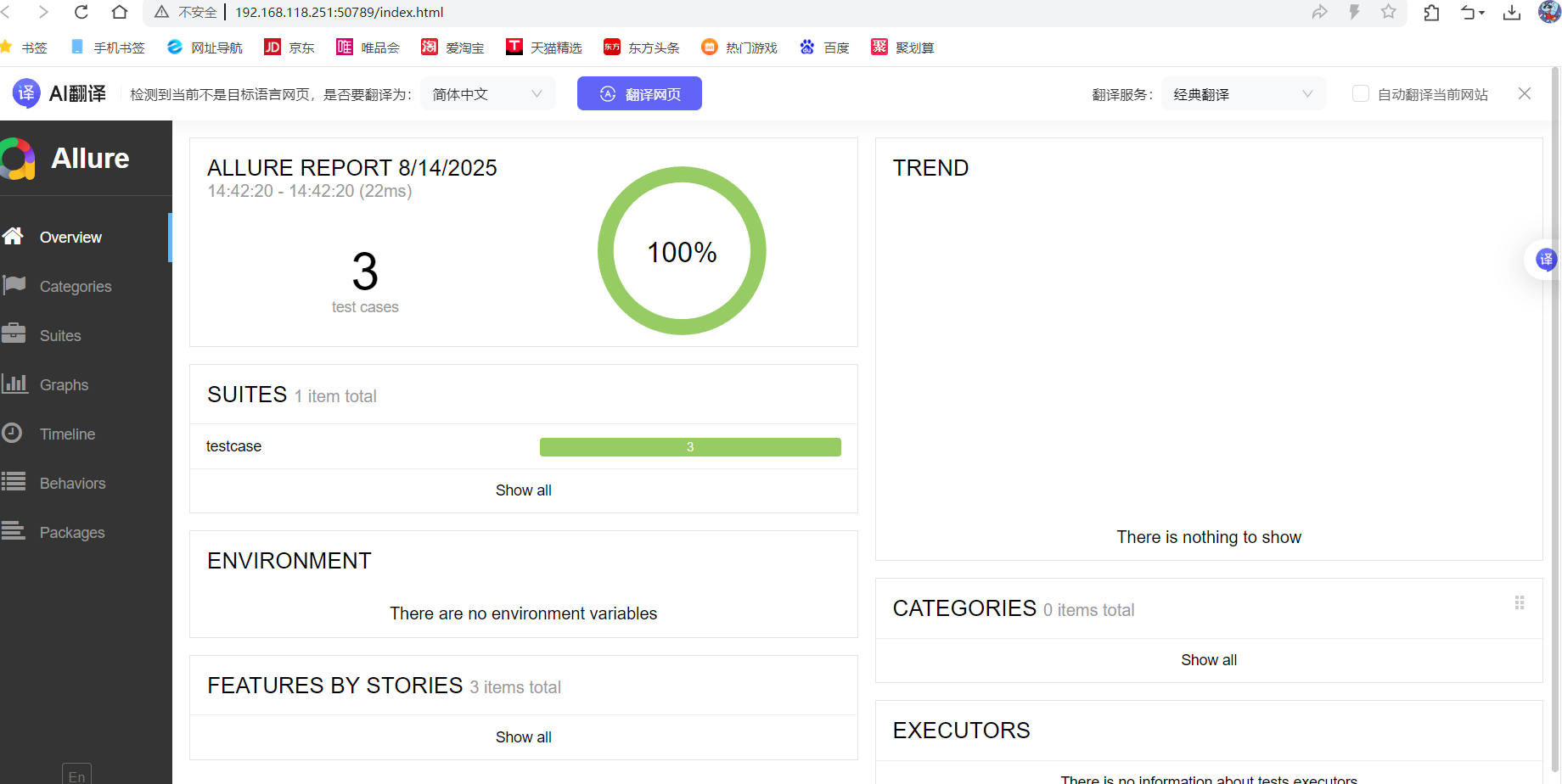
方法⼆:从测试结果生成测试报告
终端执⾏命令: allure generate [options] <allure-results> -o <reports>
-
<reports>:存放测试结果的位置
-
<allure-results>:存放测试报告的路径
allure generate .\results_dir\ -o .\allure_dir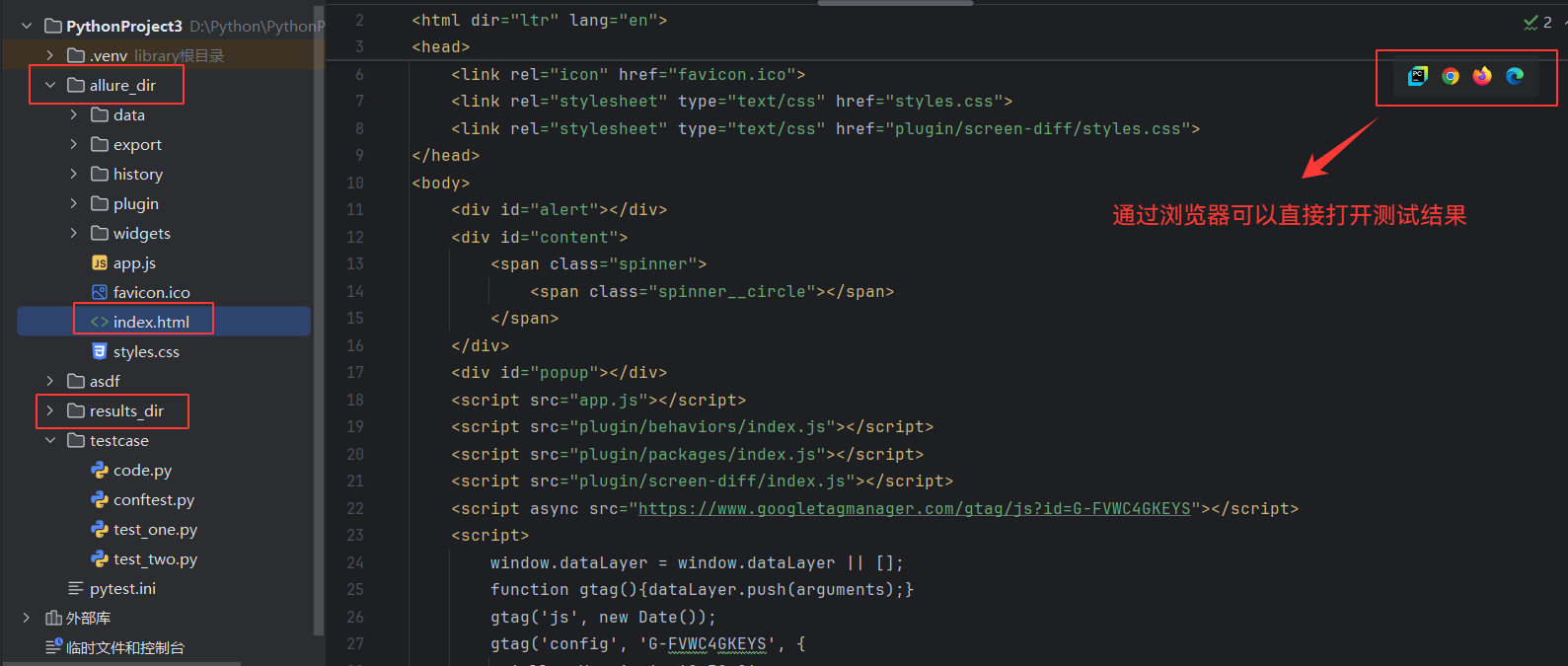


)
)
Homebrew 的安装和使用)
全解析2)




:AI 编程助手的服务器部署与实战指南)


-可自定义累加字段(如有重复KEY))
与节流(Throttle))




