掌握 Webpack Loader 的核心机制,解锁前端工程化进阶技能
前言:为什么需要理解 Loader?
在现代前端工程化体系中,Webpack 已成为构建工具的事实标准。然而面对非标准 JavaScript 文件或自定义语法时,你是否遇到过 Module parse failed: Unexpected token 这类令人头疼的错误?这正是 Webpack Loader 大显身手的场景。
作为 Webpack 的核心扩展机制,Loader 承担着源码转换的重任。本文将带你深入 Loader 的工作原理,掌握配置技巧,并通过实战案例解析常见问题,助你彻底征服 Webpack 构建过程中的各种“疑难杂症”。
一、Loader 核心概念剖析
webpack 做的事情,仅仅是分析出各种模块的依赖关系,然后形成资源列表,最终打包生成到指定的文件中。更多的功能需要借助 webpack loaders 和 webpack pluguns 完成。
webpack loader:loader 本质上是一个函数,它的作用是将某个源码字符串转换成另一个源码字符串返回。 loader 函数将在模块解析的过程中被调用,以得到最终的源码。
1. 源码字符串转换的本质
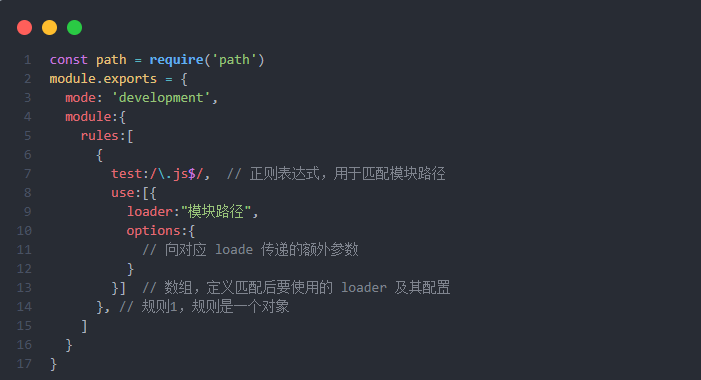
Loader 的本质是一个纯函数,其核心作用是将原始源码字符串转换为有效的 JavaScript 代码:
典型应用场景:
- 自定义语法转换(如中文关键字
变量a=1→var a=1) - 非标准文件处理(如 CSV 转 JSON)
- 代码预处理(自动注入 polyfill)
- 编译型语言转换(TypeScript, CoffeeScript 等)
2. 模块解析中的关键错误解析
当 Webpack 遇到无法解析的语法时,会抛出经典错误:
Module parse failed: Unexpected token
错误发生的根本原因:Webpack 在生成 AST(抽象语法树)阶段遇到非法语法
解析流程回顾:
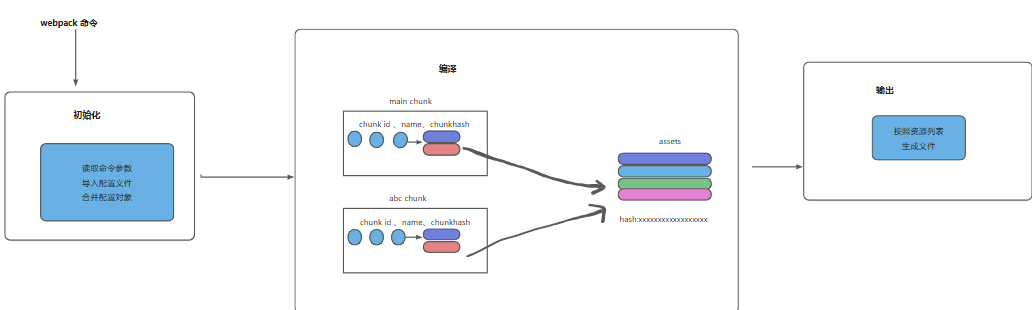
- 初始化:读取 webpack 配置
- 编译:根据入口文件递归分析依赖
- 生成 AST:对每个模块进行语法分析
- 构建依赖图:记录模块间依赖关系
- 输出:生成最终打包文件
关键结论:Loader 介入时机在文件读取之后,AST 生成之前,是解决语法解析错误的唯一途径
二、Loader 工作机制深度解析
1. 完整处理流程
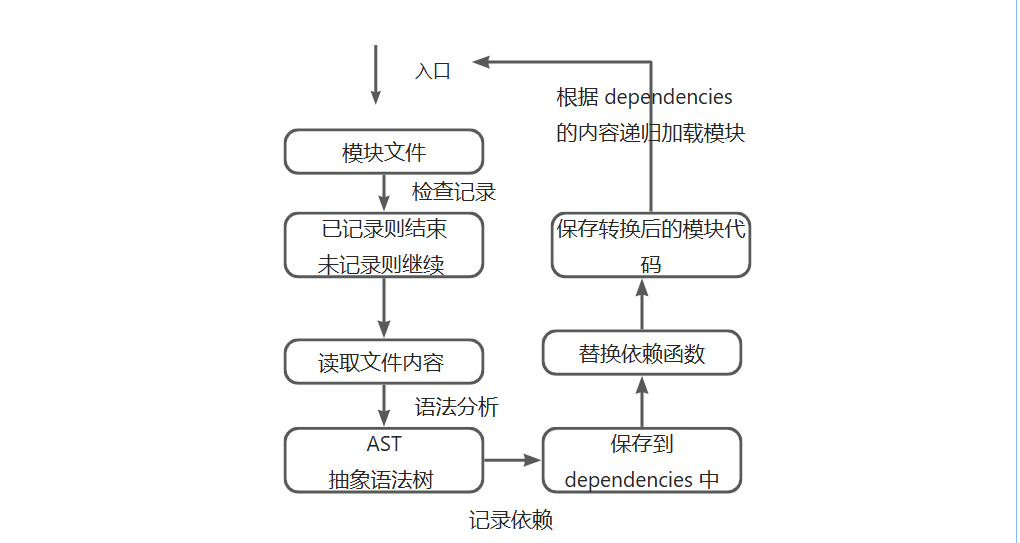
递归加载机制:根据dependencies的模块文件内容递归加载模块
模块解析关键步骤:
- 检查模块缓存(避免重复处理)
- 读取文件原始内容
- Loader 处理阶段(核心扩展点)
- 语法分析生成 AST
- 识别并记录依赖关系
- 生成最终模块代码
2. Loader 执行时机详解
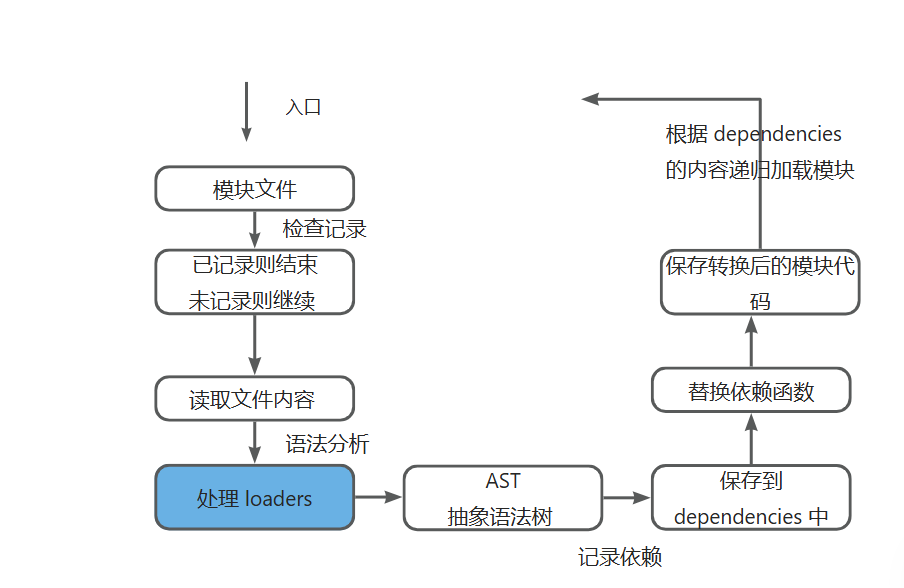
设计要点:
- 位置:文件内容读取后,AST 分析前
- 输入:原始文件内容(字符串)
- 输出:必须返回有效的 JavaScript 代码
- 必须返回有效JavaScript代码供后续AST分析
- 链式处理:支持多个 Loader 串联执行
- 设计特点:作为webpack的可扩展点,允许对源代码进行各种转换处理
3. 匹配机制与执行顺序
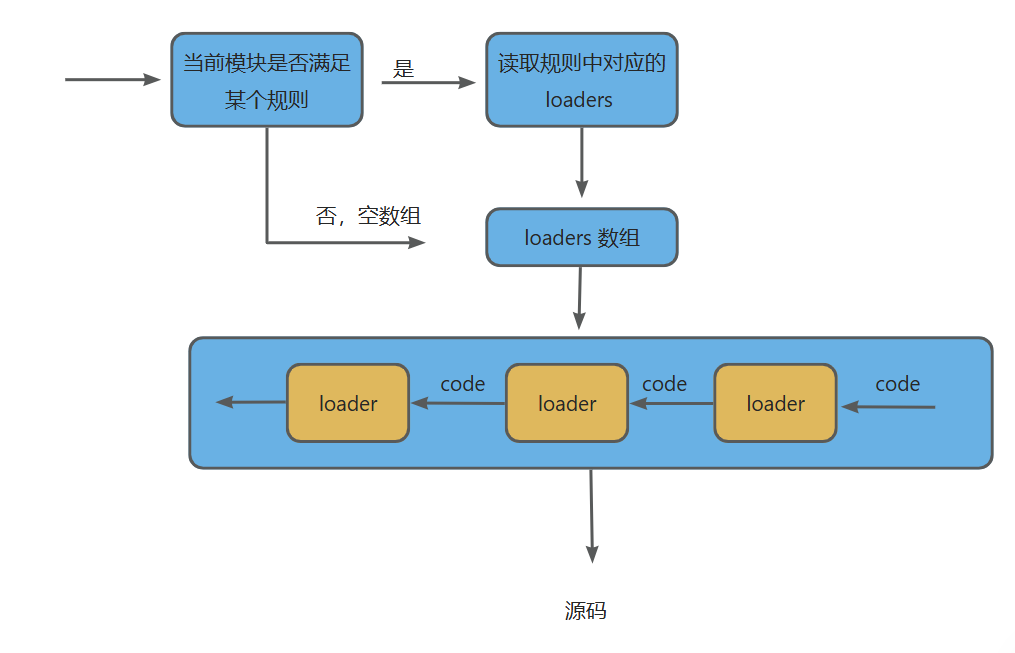
规则匹配:
-
- 判断当前模块是否满足配置中的loader规则
- 如不匹配任何规则,返回空数组
- 如匹配规则,返回对应的loaders数组
配置特性:
-
- 不是所有模块都需要loader处理
- 需要显式配置哪些模块需要哪些loader处理
- 示例:index.js作为入口模块默认不经过loader处理
反直觉的执行顺序:
// webpack.config.js
module: {rules: [{test: /.js$/,use: ['loader1', 'loader2'] // 实际执行顺序:loader2 → loader1},{test: /.js$/,use: ['loader3', 'loader4'] // 实际执行顺序:loader4 → loader3}]
}
执行流程:4 → 3 → 2 → 1
关键原理:
- 按 rules 顺序(从下到上)收集 Loader
- 倒序执行 Loader 链
- 前一个 Loader 的输出作为后一个的输入
三、loader 配置项详解
1. 更换关键字
- 参数传递原理:通过webpack.config.js中的options对象传递参数给loader,实现动态替换关键字
- 正则表达式替换:loader核心功能是通过正则表达式匹配并替换源代码中的特定字符串,如将"变量"替换为"var"
- 配置灵活性:可通过options.changeVar参数动态指定要替换的关键字,如将"未知数"替换为"var"
// loader 函数基本结构
module.exports = function(sourceCode) {// 转换逻辑const transformedCode = sourceCode.replace('变量', 'var');// 必须返回字符串return transformedCode;
}
2. this 上下文对象使用
- 上下文对象特性:loader运行时webpack会绑定this上下文,包含大量打包过程信息
- 参数获取方式:options配置无法直接获取,必须通过this上下文对象访问
- 调试方法:可通过console.log(this)查看完整的上下文对象结构
3、 第三方库解析options
- 工具库安装:使用npm i -D loader-utils安装专门处理loader参数的第三方库
- 参数解析方法:通过loaderUtils.getOptions(this)可规范获取配置参数
- 参数读取示例:options.changeVar可读取配置中指定的替换关键字
let loaderUtils = require('loader-utils');
module.exports = function(sourceCode){let options = loaderUtils.getOptions(this);console.log(options);return sourceCode;
}
四、Loader 配置实战指南
1. 基础配置结构
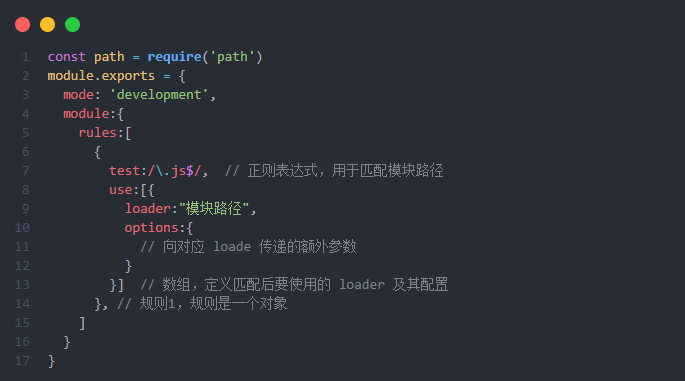
module.exports = {module: {rules: [{test: /.js$/, // 匹配规则(正则表达式)use: [{loader: './path/to/loader', // Loader 路径options: { // 传递参数changeVar: 'var'}}]}]}
}
-
配置位置: 在webpack配置文件的module.exports对象中,通过module属性进行配置
-
核心功能: 用于定义模块的解析规则,决定不同类型文件应该使用哪些loader进行处理
2. 参数传递的两种方式
方式 1:options 对象(推荐)
use: [{loader: './loaders/replace-loader',options: {from: '变量',to: 'let'}
}]
方式 2:query 字符串(简化版)
use: ['./loaders/replace-loader?from=变量&to=let']
3. 在 Loader 中获取参数
安装工具库:
npm install loader-utils -D
Loader 实现:
const { getOptions } = require('loader-utils');module.exports = function(source) {// 获取配置参数const options = getOptions(this);// 执行转换return source.replace(new RegExp(options.from, 'g'), options.to);
}
4) 配置对象结构和匹配规则
主要属性:rules:定义模块匹配规则的数组
规则特点:每个规则都是一个独立的对象,可以配置多个规则
匹配流程:webpack会从rules数组中依次检查每个规则,判断当前模块是否符合规则条件
执行顺序:实际匹配时是从数组末尾向前检查(即先检查最后一个规则)
五、loader 匹配流程
1. 匹配机制
- 将模块路径与每个规则的test正则表达式进行匹配
- 匹配成功则使用该规则中定义的loader处理模块
- 匹配失败则继续检查下一个规则
2. 处理结果
所有匹配成功的规则对应的 loader 都会被应用
六、实战应用与避坑指南
案例 1:动态关键字替换
需求:将源代码中的自定义关键字转换为 JavaScript 合法关键字
webpack.config.js:
rules: [{test: /.js$/,use: [{loader: './loaders/keyword-loader',options: {customKeyword: '未知数', // 自定义关键字jsKeyword: 'const' // 目标关键字}}]
}]
keyword-loader.js:
module.exports = function(source) {const { customKeyword, jsKeyword } = this.query;return source.replace(new RegExp(customKeyword, 'g'),jsKeyword);
}
案例 2:多 Loader 执行顺序分析
场景:
- 入口文件 index.js 引入 a.js
- index.js 匹配规则1和规则2
- a.js 只匹配规则2
webpack.config.js:
rules: [{ // 规则1test: /index.js$/,use: ['loader1', 'loader2']},{ // 规则2test: /.js$/,use: ['loader3', 'loader4']}
]
执行流程:
-
处理 index.js:
- 匹配规则1 → 加入 [loader1, loader2]
- 匹配规则2 → 加入 [loader3, loader4]
- 执行顺序:loader4 → loader3 → loader2 → loader1
-
处理 a.js:
- 匹配规则2 → 加入 [loader3, loader4]
- 执行顺序:loader4 → loader3
控制台输出:4 → 3 → 2 → 1 → 4 → 3
避坑指南
-
路径解析问题:
// 错误配置(缺少 ./) use: ['my-loader'] // 正确配置 use: ['./my-loader'] -
环境限制:
- Loader 在 Node 环境中运行
- 禁止使用浏览器 API(如 window, document)
- 使用 CommonJS 规范(非 ES Modules)
-
开发建议:
- ✅ 优先使用社区成熟 Loader(babel-loader, css-loader 等) - ✅ 仅特殊场景开发自定义 Loader(非标准文件处理) - ✅ 通过 `console.log` 调试执行顺序 - ❌ 避免在 Loader 中处理大文件(影响构建性能)
七、总结
| 知识点 | 核心内容 | 关键实现 | 易混淆点 |
|---|---|---|---|
| Loader概念 | 本质是转换源码字符串的函数,在webpack打包流程中处理模块转换 | 导出函数接收sourceCode参数并返回新字符串 | 与Plugin机制的区别(Loader处理单个文件,Plugin处理整体流程) |
| 工作流程 | 在模块解析阶段介入,位于文件读取和AST分析之间 | rules.test正则匹配模块路径,use指定处理loader链 | 执行顺序(从后向前)与规则匹配顺序(从下向上) |
| 配置结构 | module.rules数组定义匹配规则,每个规则包含test和use属性 | 支持对象形式(含options)和简写字符串形式 | test正则的编写(需匹配完整模块路径) |
| 参数传递 | 通过options配置参数,在loader内通过loader-utils解析 | this.query获取参数,复杂配置需用getOptions(this) | 参数传递格式(对象形式 vs query字符串) |
| 执行机制 | 多个loader形成处理链,前一个loader输出作为下一个输入 | 支持同步/异步处理,可通过callback返回结果 | loader环境限制(必须使用CommonJS模块规范) |
| 调试技巧 | 通过console.log输出处理过程,观察this上下文对象 | 使用loader-runner独立测试loader | 源码映射(sourceMap)的生成与处理 |
| 典型应用 | 语法转换(如ES6→ES5)、资源处理(图片转base64) | 示例实现变量声明关键字替换 | loader与babel等工具链的协作关系 |



)
--图论)


在Linux里面怎么查看进程)
---基于堆栈得到缓冲区溢出](http://pic.xiahunao.cn/[TryHackMe](知识学习)---基于堆栈得到缓冲区溢出)






)
 - 解析静态网页)


 ——225 用队列实现栈(C语言))