环境依赖
jdk、neo4j图数据库
操作一条数据完整demo
import os,json,sys,io
from py2neo import Graph,Nodetry:sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
except Exception:passclass MedicalGraph:def __init__(self):self.data_path = r'D:\skstudy\medical2.json'if not os.path.exists(self.data_path):raise FileNotFoundError(f"数据文件未找到: {self.data_path}")self.g = Graph('bolt://110.110.110.110:7110', auth=('110', 'neo4j110'))def read_nodes(self):diseases = [] # 疾病名drugs = [] # 药品名departments = [] # 科室名disease_infos = [] # 疾病详细信息rels_disease_drug = [] # 疾病-药品rels_disease_department = [] # 疾病-科室rels_department_department = [] # 科室-科室count = 0with open(self.data_path, 'r', encoding='utf-8') as f:data_json= json.load(f)# for line in f:# line = line.strip()# if not line:# continue# try:# data_json = json.loads(line)# except json.JSONDecodeError as e:# print(f"JSON解析错误: {e}, 行内容: {line}")# print(f"错误详情:{e}")# continuedisease_name = data_json['name']diseases.append(disease_name)disease_dict = {'name': disease_name,'recommand_drug': [],'cure_department': []}# 处理科室if 'cure_department' in data_json:cure_department = data_json['cure_department']if isinstance(cure_department, list):disease_dict['cure_department'] = cure_departmentdepartments.extend(cure_department)if len(cure_department) == 1:rels_disease_department.append([disease_name, cure_department[0]])elif len(cure_department) >= 2:rels_disease_department.append([disease_name, cure_department[1]])rels_department_department.append([cure_department[1], cure_department[0]])# 处理推荐药物if 'recommand_drug' in data_json:recommand_drug = data_json['recommand_drug']if isinstance(recommand_drug, list):disease_dict['recommand_drug'] = recommand_drugdrugs.extend(recommand_drug)for drug in recommand_drug:rels_disease_drug.append([disease_name, drug])disease_infos.append(disease_dict)# 去重return set(diseases), set(drugs), set(departments), disease_infos, \rels_disease_drug, rels_disease_department, rels_department_departmentdef create_node(self, label, nodes):count = 0for node_name in nodes:if not node_name: # 过滤空字符串continuenode = Node(label, name=node_name)self.g.merge(node, label, 'name') # 使用 merge 避免重复创建count += 1if count % 100 == 0:print(f"{label} 节点创建: {count}/{len(nodes)}")print(f"✅ {label} 节点创建完成,共 {count} 个")def create_diseases_nodes(self, disease_infos):count = 0for disease_dict in disease_infos:node = Node('Disease',name=disease_dict['name'],recommand_drug=disease_dict['recommand_drug'],cure_department=disease_dict['cure_department'])self.g.merge(node, 'Disease', 'name')count += 1if count % 100 == 0:print(f"疾病节点创建: {count}")print(f"✅ 疾病节点创建完成,共 {count} 个")def create_graphnodes(self):diseases, drugs, departments, disease_infos, _, _, _ = self.read_nodes()self.create_diseases_nodes(disease_infos)self.create_node('Drug', drugs)self.create_node('Department', departments)def create_relationship(self, start_label, end_label, edges, rel_type, rel_name):count = 0# 去重unique_edges = list(set(["###".join(edge) for edge in edges]))total = len(unique_edges)for edge_str in unique_edges:p_name, q_name = edge_str.split('###')if not p_name or not q_name:continue# 使用参数化查询,避免注入和引号问题query = ("MATCH (p:%s {name: $p_name}), (q:%s {name: $q_name}) ""MERGE (p)-[rel:%s {name: $rel_name}]->(q)") % (start_label, end_label, rel_type)try:self.g.run(query, p_name=p_name, q_name=q_name, rel_name=rel_name)count += 1if count % 100 == 0:print(f"{rel_name} 关系创建: {count}/{total}")except Exception as e:print(f"创建关系失败: {e}, 边: {p_name} -> {q_name}")print(f"✅ {rel_name} 关系创建完成,共 {count} 个")def create_graphrels(self):_, _, _, _, rels_disease_drug, rels_disease_department, rels_department_department = self.read_nodes()self.create_relationship('Disease', 'Drug', rels_disease_drug, 'RECOMMAND_EAT', '宜吃')self.create_relationship('Disease', 'Department', rels_disease_department, 'BELONGS_TO', '所属科室')self.create_relationship('Department', 'Department', rels_department_department, 'BELONGS_TO', '属于')def export_data(self):diseases, drugs, departments, _, _, _, _ = self.read_nodes()for filename, data in [('disease.txt', diseases), ('drug.txt', drugs), ('department.txt', departments)]:with open(filename, 'w', encoding='utf-8') as f:f.write('\n'.join(sorted(data)))print(f"✅ 已导出 {filename}")if __name__ == '__main__':medical_graph = MedicalGraph()medical_graph.create_graphnodes()medical_graph.create_graphrels()medical_graph.export_data()运行看下情况
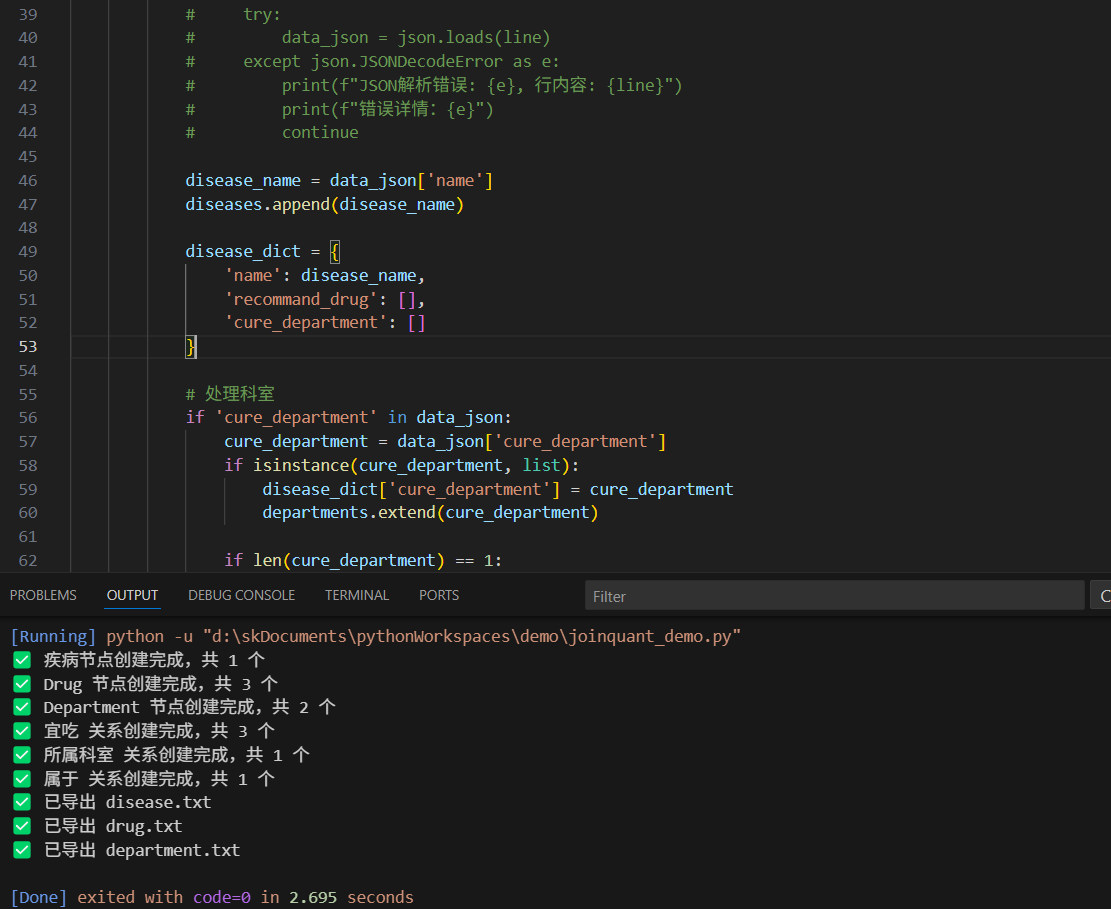 使用的json模板
使用的json模板
{"_id": {"$oid": "5bb578b6831b973a137e3ee7"},"name": "慢性阻塞性肺疾病","desc": "慢性阻塞性肺疾病(COPD)是一种常见的以持续性气流受限为特征的呼吸系统疾病,主要由长期吸烟、空气污染或职业粉尘暴露引起,表现为慢性咳嗽、咳痰和进行性呼吸困难。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、戒烟是预防COPD最重要的措施。\n2、避免接触工业粉尘、烟雾和空气污染物。\n3、定期接种流感疫苗和肺炎疫苗。","cause": "主要病因包括长期吸烟、吸入有害气体或颗粒(如煤烟、粉尘)、遗传因素(如α1-抗胰蛋白酶缺乏)、反复呼吸道感染等。吸烟是导致COPD最常见且可预防的原因。","symptom": ["咳嗽", "咳痰", "呼吸困难", "喘息", "胸闷"],"yibao_status": "是","get_prob": "约0.3%","get_way": "无传染性","acompany": ["肺心病", "自发性气胸", "呼吸衰竭"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["药物治疗", "氧疗", "肺康复训练"],"cure_lasttime": "长期管理,需终身控制","cured_prob": "不可完全治愈,但可控制病情","cost_money": "年均费用约5000-20000元,视病情严重程度而定","check": ["肺功能检查", "胸部X线", "血气分析", "高分辨率CT"],"recommand_drug": ["沙美特罗替卡松粉吸入剂", "噻托溴铵", "布地奈德福莫特罗"],"drug_detail": ["沙美特罗替卡松:每日两次,用于缓解支气管痉挛","噻托溴铵:长效抗胆碱药,改善肺功能","布地奈德福莫特罗:控制炎症与扩张支气管联合用药"]}查询下neo4j库中信息
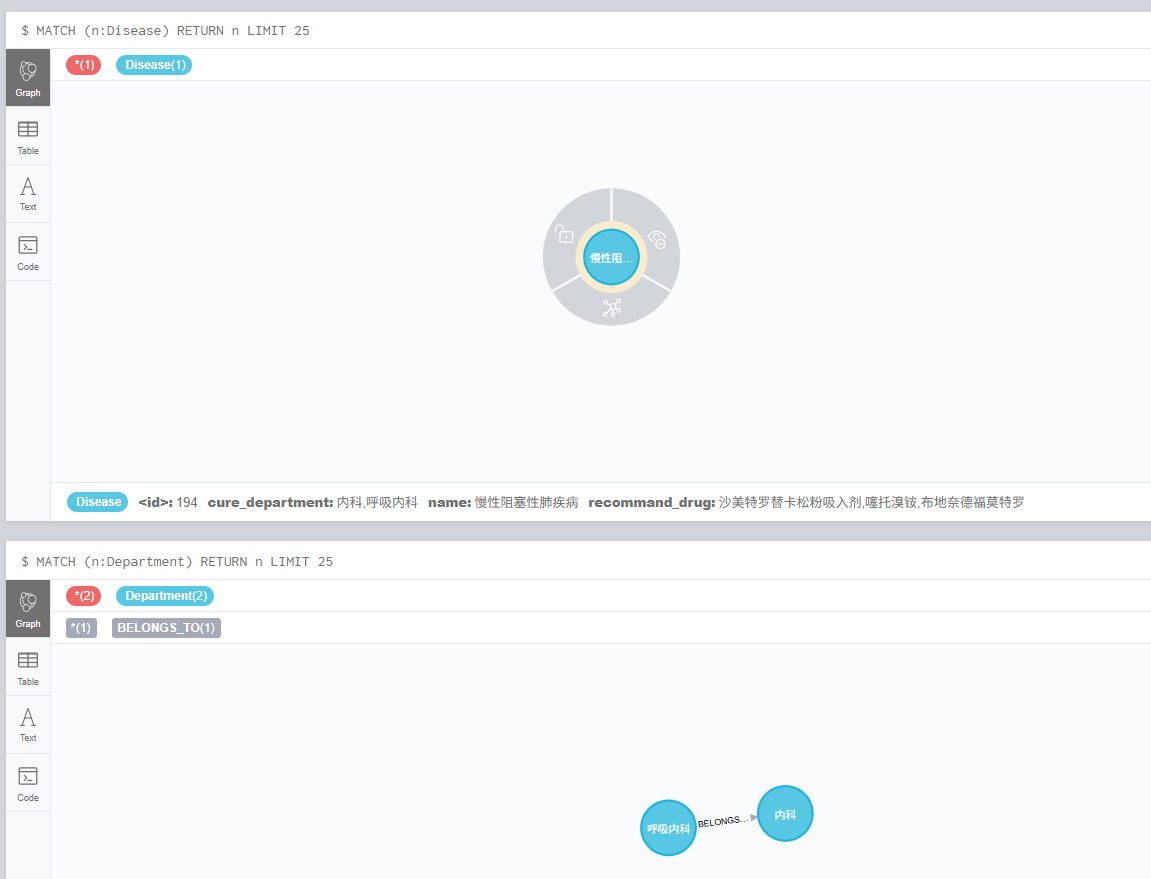
确实,只显示了一个节点的信息。还需要再修改,将json的内容再通过大模型扩写下。丰富下内容
通过大模型扩容后的json文件,后续如果是其他数据的json文件,都可以按照这个模板去创建节点,创建关系。
操作多条数据完美demo
json文件
[{"_id": {"$oid": "5bb578b6831b973a137e3ee7"},"name": "慢性阻塞性肺疾病","desc": "慢性阻塞性肺疾病(COPD)是一种常见的以持续性气流受限为特征的呼吸系统疾病,主要由长期吸烟、空气污染或职业粉尘暴露引起,表现为慢性咳嗽、咳痰和进行性呼吸困难。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、戒烟是预防COPD最重要的措施。\n2、避免接触工业粉尘、烟雾和空气污染物。\n3、定期接种流感疫苗和肺炎疫苗。","cause": "主要病因包括长期吸烟、吸入有害气体或颗粒(如煤烟、粉尘)、遗传因素(如α1-抗胰蛋白酶缺乏)、反复呼吸道感染等。吸烟是导致COPD最常见且可预防的原因。","symptom": ["咳嗽", "咳痰", "呼吸困难", "喘息", "胸闷"],"yibao_status": "是","get_prob": "约0.3%","get_way": "无传染性","acompany": ["肺心病", "自发性气胸", "呼吸衰竭"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["药物治疗", "氧疗", "肺康复训练"],"cure_lasttime": "长期管理,需终身控制","cured_prob": "不可完全治愈,但可控制病情","cost_money": "年均费用约5000-20000元,视病情严重程度而定","check": ["肺功能检查", "胸部X线", "血气分析", "高分辨率CT"],"recommand_drug": ["沙美特罗替卡松粉吸入剂", "噻托溴铵", "布地奈德福莫特罗"],"drug_detail": ["沙美特罗替卡松:每日两次,用于缓解支气管痉挛","噻托溴铵:长效抗胆碱药,改善肺功能","布地奈德福莫特罗:控制炎症与扩张支气管联合用药"]},{"_id": {"$oid": "5bb578b6831b973a137e3ee8"},"name": "支气管哮喘","desc": "支气管哮喘是一种慢性气道炎症性疾病,特征为可逆性气流受限、气道高反应性和反复发作的喘息、呼吸困难、胸闷和咳嗽,尤其在夜间或清晨加重。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、避免接触过敏原(如花粉、尘螨、宠物皮屑)。\n2、保持室内空气流通,控制湿度。\n3、避免剧烈运动和冷空气刺激。","cause": "与遗传易感性、环境因素(如过敏原、空气污染)、呼吸道病毒感染、职业性刺激物暴露等有关。免疫系统异常激活导致气道慢性炎症。","symptom": ["喘息", "呼吸困难", "胸闷", "咳嗽", "夜间憋醒"],"yibao_status": "是","get_prob": "约1%-3%","get_way": "无传染性","acompany": ["肺气肿", "呼吸衰竭", "焦虑障碍"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["吸入性药物治疗", "脱敏治疗", "生活方式干预"],"cure_lasttime": "长期控制,部分儿童可缓解","cured_prob": "约30%儿童可临床治愈,成人多为控制","cost_money": "年均2000-10000元,取决于用药方案","check": ["肺功能检查", "呼出气一氧化氮检测", "过敏原测试"],"recommand_drug": ["丙酸氟替卡松", "沙丁胺醇", "孟鲁司特钠"],"drug_detail": ["丙酸氟替卡松:每日吸入,控制气道炎症","沙丁胺醇:急救用支气管扩张剂","孟鲁司特钠:口服抗炎药,适用于过敏性哮喘"]},{"_id": {"$oid": "5bb578b6831b973a137e3ee9"},"name": "肺炎","desc": "肺炎是指终末气道、肺泡和肺间质的炎症,可由细菌、病毒、真菌或非典型病原体引起,常见症状包括发热、咳嗽、咳痰和呼吸困难。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、接种肺炎球菌疫苗和流感疫苗。\n2、增强体质,避免受凉感冒。\n3、注意个人卫生,勤洗手,戴口罩。","cause": "常见病原体包括肺炎链球菌、流感嗜血杆菌、支原体、病毒(如流感病毒、新冠病毒)等。机体免疫力下降时易发生感染。","symptom": ["发热", "咳嗽", "咳痰", "胸痛", "呼吸困难"],"yibao_status": "是","get_prob": "每年约1%-2%","get_way": "可通过飞沫传播","acompany": ["胸腔积液", "败血症", "急性呼吸窘迫综合征"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["抗生素治疗", "抗病毒治疗", "支持治疗"],"cure_lasttime": "轻症约1-2周,重症可达4周以上","cured_prob": "约90%以上可治愈","cost_money": "普通住院约5000-15000元","check": ["胸部X光", "血常规", "痰培养", "C反应蛋白"],"recommand_drug": ["阿莫西林克拉维酸", "左氧氟沙星", "头孢曲松"],"drug_detail": ["阿莫西林克拉维酸:广谱抗生素,用于社区获得性肺炎","左氧氟沙星:针对革兰阴性菌有效","头孢曲松:静脉用药,重症常用"]},{"_id": {"$oid": "5bb578b6831b973a137e3eea"},"name": "肺结核","desc": "肺结核是由结核分枝杆菌引起的慢性传染病,主要侵犯肺部,表现为咳嗽、咳痰、咯血、低热、盗汗、乏力等症状,具有较强传染性。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、接种卡介苗(BCG)。\n2、避免与活动性肺结核患者密切接触。\n3、保持良好通风环境,增强免疫力。","cause": "由结核分枝杆菌感染引起,通过空气飞沫传播。当人体抵抗力降低时,潜伏菌可重新活跃致病。","symptom": ["咳嗽", "咳痰", "咯血", "低热", "盗汗", "体重下降"],"yibao_status": "是","get_prob": "中国年发病率约0.06%","get_way": "通过呼吸道飞沫传播","acompany": ["结核性胸膜炎", "肺空洞", "播散性结核"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["抗结核化疗", "隔离治疗", "营养支持"],"cure_lasttime": "至少6-9个月","cured_prob": "规范治疗下治愈率可达90%以上","cost_money": "国家免费提供一线药物,自费部分约1000-5000元","check": ["PPD试验", "T-SPOT检测", "胸部CT", "痰涂片找抗酸杆菌"],"recommand_drug": ["异烟肼", "利福平", "乙胺丁醇", "吡嗪酰胺"],"drug_detail": ["异烟肼:杀菌主力,需监测肝功能","利福平:强效杀菌,可能导致体液变红","乙胺丁醇:防止耐药,注意视力变化","吡嗪酰胺:早期杀菌作用强"]},{"_id": {"$oid": "5bb578b6831b973a137e3eeb"},"name": "间质性肺疾病","desc": "间质性肺疾病是一组以肺间质炎症和纤维化为主要表现的异质性疾病群,病因多样,进展缓慢,最终可导致肺功能严重受损。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、避免接触粉尘、石棉、鸟粪等职业或环境致病因素。\n2、戒烟。\n3、及时治疗自身免疫性疾病。","cause": "包括特发性肺纤维化、结缔组织病相关间质性肺病、药物或放射线损伤、尘肺等。确切机制涉及慢性炎症与异常修复过程。","symptom": ["干咳", "进行性呼吸困难", "乏力", "杵状指"],"yibao_status": "部分纳入","get_prob": "约0.02%","get_way": "无传染性","acompany": ["肺动脉高压", "肺癌", "右心衰竭"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["抗纤维化药物", "糖皮质激素", "氧疗"],"cure_lasttime": "长期治疗,难以逆转","cured_prob": "约10%-20%病情稳定,多数缓慢进展","cost_money": "年均1万-5万元以上,抗纤维化药昂贵","check": ["高分辨率CT", "肺功能检查", "肺活检", "自身抗体检测"],"recommand_drug": ["尼达尼布", "吡非尼酮", "泼尼松"],"drug_detail": ["尼达尼布:抑制纤维化进程","吡非尼酮:抗氧化、抗纤维化","泼尼松:用于炎症活跃期"]},{"_id": {"$oid": "5bb578b6831b973a137e3eec"},"name": "肺癌","desc": "肺癌是起源于支气管黏膜或肺泡上皮细胞的恶性肿瘤,是最常见的癌症死因之一,分为小细胞肺癌和非小细胞肺癌两大类。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、绝对戒烟并避免二手烟。\n2、减少厨房油烟、空气污染暴露。\n3、定期体检,高危人群做低剂量CT筛查。","cause": "主要危险因素包括吸烟(占80%以上)、职业致癌物(如石棉、砷)、电离辐射、遗传易感性和空气污染。","symptom": ["持续性咳嗽", "咯血", "胸痛", "消瘦", "声音嘶哑"],"yibao_status": "是","get_prob": "约0.05%","get_way": "无传染性","acompany": ["恶性胸水", "骨转移", "脑转移"],"cure_department": ["内科", "呼吸内科", "肿瘤科"],"cure_way": ["手术切除", "化疗", "靶向治疗", "免疫治疗"],"cure_lasttime": "根据分期,治疗周期数月至数年","cured_prob": "早期5年生存率可达60%-80%,晚期低于10%","cost_money": "治疗总费用约5万-50万元不等","check": ["胸部CT", "PET-CT", "支气管镜活检", "基因检测"],"recommand_drug": ["吉非替尼", "奥希替尼", "帕博利珠单抗"],"drug_detail": ["吉非替尼:EGFR突变阳性患者一线用药","奥希替尼:三代靶向药,用于T790M突变","帕博利珠单抗:PD-1抑制剂,用于免疫治疗"]},{"_id": {"$oid": "5bb578b6831b973a137e3eed"},"name": "肺栓塞","desc": "肺栓塞是由于内源性或外源性栓子堵塞肺动脉主干或分支,引起肺循环障碍的临床综合征,常见为下肢深静脉血栓脱落所致。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、术后早期下床活动,预防深静脉血栓。\n2、长途旅行时多活动下肢。\n3、高危人群可预防性抗凝。","cause": "最常见的栓子来自下肢深静脉血栓形成(DVT),其他原因包括脂肪栓塞、空气栓塞、羊水栓塞等。长期卧床、手术、肿瘤、妊娠为高危因素。","symptom": ["突发呼吸困难", "胸痛", "咯血", "心悸", "晕厥"],"yibao_status": "是","get_prob": "约0.01%","get_way": "无传染性","acompany": ["右心衰竭", "休克", "慢性血栓栓塞性肺动脉高压"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["抗凝治疗", "溶栓治疗", "介入取栓"],"cure_lasttime": "急性期1-2周,抗凝治疗持续3-6个月","cured_prob": "及时治疗下存活率超90%","cost_money": "住院治疗约2万-8万元","check": ["D-二聚体", "CT肺动脉造影", "下肢静脉超声"],"recommand_drug": ["低分子肝素", "华法林", "利伐沙班"],"drug_detail": ["低分子肝素:急性期首选抗凝药","华法林:需监测INR,长期使用","利伐沙班:新型口服抗凝药,使用方便"]},{"_id": {"$oid": "5bb578b6831b973a137e3eee"},"name": "睡眠呼吸暂停综合征","desc": "睡眠呼吸暂停综合征是一种在睡眠中反复出现呼吸暂停或低通气的疾病,最常见为阻塞性类型,常伴有打鼾、白天嗜睡等症状。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、控制体重,避免肥胖。\n2、避免饮酒和镇静药物。\n3、侧卧睡眠,保持鼻腔通畅。","cause": "上气道结构狭窄、肥胖、下颌后缩、长期吸烟饮酒、家族遗传等因素导致睡眠时气道塌陷。","symptom": ["打鼾", "呼吸暂停", "白天嗜睡", "晨起头痛", "注意力不集中"],"yibao_status": "是","get_prob": "成人约2%-4%","get_way": "无传染性","acompany": ["高血压", "冠心病", "脑卒中"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["持续气道正压通气(CPAP)", "减重", "手术"],"cure_lasttime": "需长期管理","cured_prob": "通过治疗可显著改善症状,根治较难","cost_money": "CPAP设备约5000-15000元,治疗费另计","check": ["多导睡眠监测(PSG)", "鼻咽喉镜检查", "血氧监测"],"recommand_drug": [],"drug_detail": []},{"_id": {"$oid": "5bb578b6831b973a137e3eef"},"name": "支气管扩张症","desc": "支气管扩张症是由于支气管壁结构破坏导致其异常扩张的慢性疾病,常表现为慢性咳嗽、大量脓痰和反复咯血。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、积极治疗儿童期呼吸道感染。\n2、接种疫苗预防麻疹、百日咳等。\n3、戒烟,避免刺激性气体。","cause": "常见于儿童期严重肺部感染(如肺炎、结核)、免疫缺陷、囊性纤维化、纤毛功能障碍等。反复感染导致支气管壁破坏。","symptom": ["慢性咳嗽", "大量脓痰", "咯血", "反复肺部感染", "杵状指"],"yibao_status": "是","get_prob": "约0.01%","get_way": "无传染性","acompany": ["肺脓肿", "慢性肺心病", "呼吸衰竭"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["抗感染治疗", "体位引流", "支气管镜吸痰"],"cure_lasttime": "长期慢性过程,需反复治疗","cured_prob": "无法根治,但可控制症状","cost_money": "年均3000-10000元","check": ["高分辨率CT", "痰培养", "肺功能检查"],"recommand_drug": ["阿莫西林克拉维酸", "左氧氟沙星", "氨溴索"],"drug_detail": ["阿莫西林克拉维酸:用于急性感染期","左氧氟沙星:覆盖革兰阴性菌","氨溴索:促进痰液排出"]},{"_id": {"$oid": "5bb578b6831b973a137e3ef0"},"name": "急性呼吸窘迫综合征","desc": "急性呼吸窘迫综合征(ARDS)是由于严重感染、创伤、休克等引起的急性弥漫性肺损伤,表现为严重低氧血症和呼吸衰竭。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、及时治疗原发病(如重症肺炎、脓毒症)。\n2、避免误吸。\n3、合理输血和补液。","cause": "直接肺损伤(如肺炎、吸入性肺炎)或间接损伤(如脓毒症、严重创伤、胰腺炎)引发全身炎症反应,导致肺泡-毛细血管屏障破坏。","symptom": ["严重呼吸困难", "呼吸急促", "紫绀", "烦躁不安", "低氧血症"],"yibao_status": "是","get_prob": "重症患者中约10%-15%","get_way": "无传染性","acompany": ["多器官功能衰竭", "气压伤", "深静脉血栓"],"cure_department": ["内科", "呼吸内科", "重症医学科"],"cure_way": ["机械通气", "肺保护性通气策略", "治疗原发病"],"cure_lasttime": "数天至数周,部分遗留肺功能损害","cured_prob": "总体死亡率约30%-40%","cost_money": "ICU治疗每日约1万-3万元,总费用高昂","check": ["动脉血气分析", "胸部X光或CT", "肺力学监测"],"recommand_drug": ["哌拉西林他唑巴坦", "甲泼尼龙", "镇静肌松药"],"drug_detail": ["哌拉西林他唑巴坦:广谱抗生素,用于抗感染","甲泼尼龙:在特定阶段减轻炎症反应","镇静肌松药:辅助机械通气"]}
]python脚本从读取一条json数据,要修改成读取所有的json数据,在json的数组中,再依次将数据解析出来,创建节点。
import os
import json
import sys,io
from py2neo import Graph,Nodetry:sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
except Exception:passclass MedicalGraph:def __init__(self):self.data_path = r'D:\skstudy\medical2.json'if not os.path.exists(self.data_path):raise FileNotFoundError(f"数据文件未找到: {self.data_path}")self.g = Graph('bolt://10.15.32.71:7687', auth=('neo4j', 'neo4j1234'))def read_nodes(self):diseases = [] # 疾病名drugs = [] # 药品名departments = [] # 科室名disease_infos = [] # 疾病详细信息rels_disease_drug = [] # 疾病-药品rels_disease_department = [] # 疾病-科室rels_department_department = [] # 科室-科室count = 0with open(self.data_path, 'r', encoding='utf-8') as f:data_jsons= json.load(f)for data_json in data_jsons:disease_name = data_json['name']diseases.append(disease_name)disease_dict = {'name': disease_name,'recommand_drug': [],'cure_department': []}# 处理科室if 'cure_department' in data_json:cure_department = data_json['cure_department']if isinstance(cure_department, list):disease_dict['cure_department'] = cure_departmentdepartments.extend(cure_department)if len(cure_department) == 1:rels_disease_department.append([disease_name, cure_department[0]])elif len(cure_department) >= 2:rels_disease_department.append([disease_name, cure_department[1]])rels_department_department.append([cure_department[1], cure_department[0]])# 处理推荐药物if 'recommand_drug' in data_json:recommand_drug = data_json['recommand_drug']if isinstance(recommand_drug, list):disease_dict['recommand_drug'] = recommand_drugdrugs.extend(recommand_drug)for drug in recommand_drug:rels_disease_drug.append([disease_name, drug])disease_infos.append(disease_dict)# 去重return set(diseases), set(drugs), set(departments), disease_infos, \rels_disease_drug, rels_disease_department, rels_department_departmentdef create_node(self, label, nodes):count = 0for node_name in nodes:if not node_name: # 过滤空字符串continuenode = Node(label, name=node_name)self.g.merge(node, label, 'name') # 使用 merge 避免重复创建count += 1if count % 100 == 0:print(f"{label} 节点创建: {count}/{len(nodes)}")print(f"✅ {label} 节点创建完成,共 {count} 个")def create_diseases_nodes(self, disease_infos):count = 0for disease_dict in disease_infos:node = Node('Disease',name=disease_dict['name'],recommand_drug=disease_dict['recommand_drug'],cure_department=disease_dict['cure_department'])self.g.merge(node, 'Disease', 'name')count += 1if count % 100 == 0:print(f"疾病节点创建: {count}")print(f"✅ 疾病节点创建完成,共 {count} 个")def create_graphnodes(self):diseases, drugs, departments, disease_infos, _, _, _ = self.read_nodes()self.create_diseases_nodes(disease_infos)self.create_node('Drug', drugs)self.create_node('Department', departments)def create_relationship(self, start_label, end_label, edges, rel_type, rel_name):count = 0# 去重unique_edges = list(set(["###".join(edge) for edge in edges]))total = len(unique_edges)for edge_str in unique_edges:p_name, q_name = edge_str.split('###')if not p_name or not q_name:continue# 使用参数化查询,避免注入和引号问题query = ("MATCH (p:%s {name: $p_name}), (q:%s {name: $q_name}) ""MERGE (p)-[rel:%s {name: $rel_name}]->(q)") % (start_label, end_label, rel_type)try:self.g.run(query, p_name=p_name, q_name=q_name, rel_name=rel_name)count += 1if count % 100 == 0:print(f"{rel_name} 关系创建: {count}/{total}")except Exception as e:print(f"创建关系失败: {e}, 边: {p_name} -> {q_name}")print(f"✅ {rel_name} 关系创建完成,共 {count} 个")def create_graphrels(self):_, _, _, _, rels_disease_drug, rels_disease_department, rels_department_department = self.read_nodes()self.create_relationship('Disease', 'Drug', rels_disease_drug, 'RECOMMAND_EAT', '宜吃')self.create_relationship('Disease', 'Department', rels_disease_department, 'BELONGS_TO', '所属科室')self.create_relationship('Department', 'Department', rels_department_department, 'BELONGS_TO', '属于')def export_data(self):diseases, drugs, departments, _, _, _, _ = self.read_nodes()for filename, data in [('disease.txt', diseases), ('drug.txt', drugs), ('department.txt', departments)]:with open(filename, 'w', encoding='utf-8') as f:f.write('\n'.join(sorted(data)))print(f"✅ 已导出 {filename}")if __name__ == '__main__':medical_graph = MedicalGraph()medical_graph.create_graphnodes()medical_graph.create_graphrels()medical_graph.export_data()运行结果
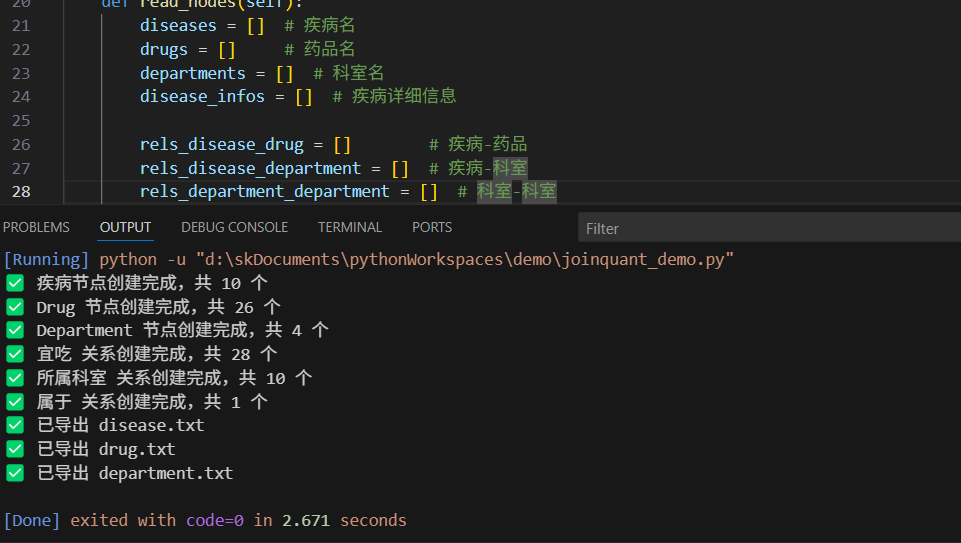
查看库中信息
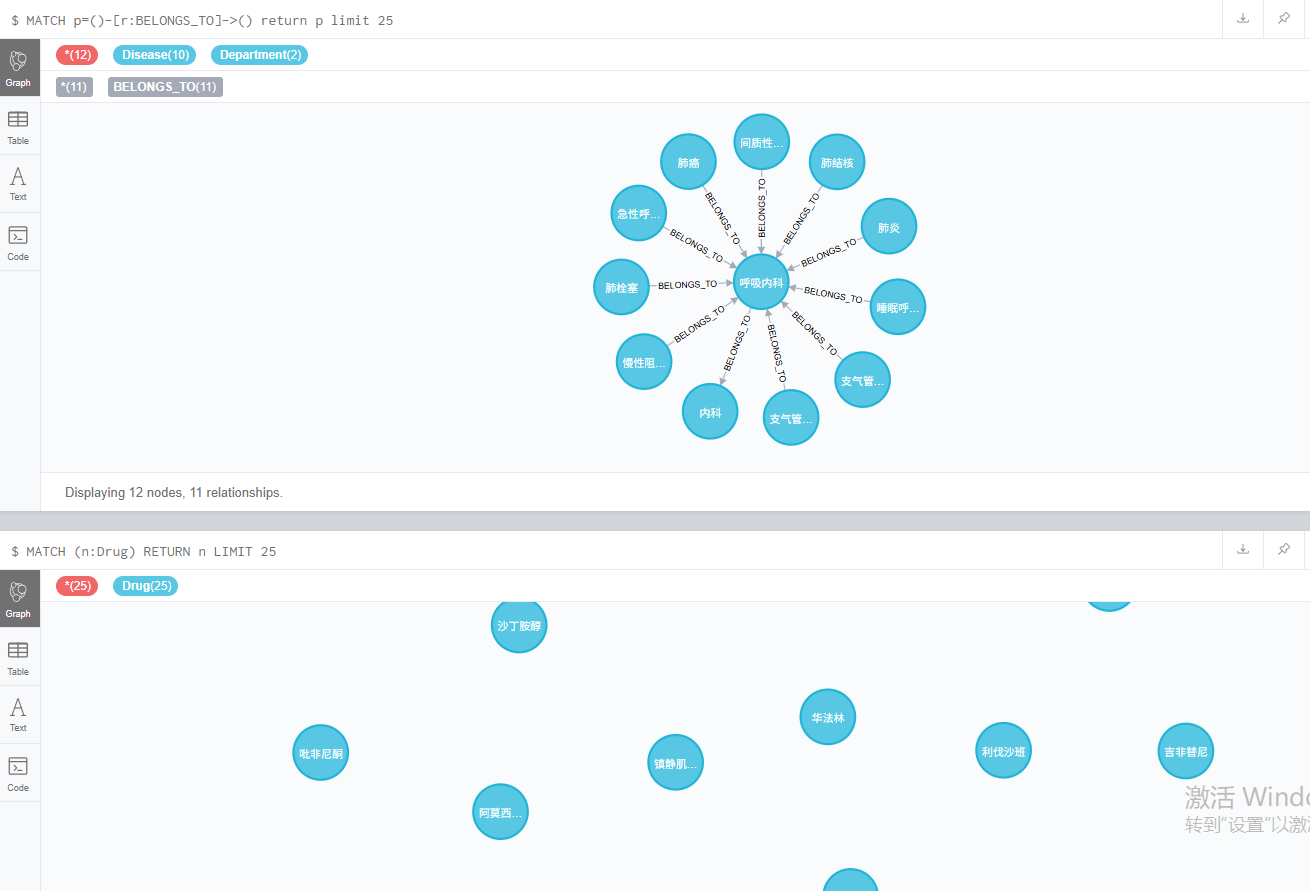
这下就可以了,数据已经存在库中了,各自的对应关系也已经有了,那么后面就是多查询出来的数据进行具体的操作了。
操作技巧
读取一个 JSON 文件
假设你有一个文件 data.json,内容如下:
{"name": "张三","age": 30,"city": "北京","hobbies": ["读书", "游泳", "编程"],"is_student": false
}✅ 读取代码:
import json# 打开并读取 JSON 文件
with open('data.json', 'r', encoding='utf-8') as file:data = json.load(file)# 现在 data 是一个 Python 字典
print(data)
print("姓名:", data['name'])
print("年龄:", data['age'])
print("爱好:", data['hobbies'])🔍 输出结果:
{'name': '张三', 'age': 30, 'city': '北京', 'hobbies': ['读书', '游泳', '编程'], 'is_student': False}
姓名: 张三
年龄: 30
爱好: ['读书', '游泳', '编程']✅ 处理不同类型的 JSON 文件
📌 情况 1:JSON 文件是一个数组(列表)
[{"name": "张三", "age": 30},{"name": "李四", "age": 25}
]import jsonwith open('users.json', 'r', encoding='utf-8') as file:users = json.load(file)for user in users:print(f"姓名: {user['name']}, 年龄: {user['age']}")📌 情况 2:JSON Lines 格式(每行一个 JSON)
每行是一个独立的 JSON 对象,常用于大数据:
{"name": "张三", "age": 30}
{"name": "李四", "age": 25}import jsondata_list = []with open('data.jsonl', 'r', encoding='utf-8') as file:for line in file:line = line.strip()if line:data = json.loads(line) # 注意是 json.loads()data_list.append(data)for item in data_list:print(item)遗留问题
后面有机会再试试milvus向量库。看看图片是怎么操作的。



:广播/连接/扫描流程详解)



 - 入门篇)




的原理与实现)






