🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【数据可视化-85】海底捞门店数据分析与可视化:Python + pyecharts打造炫酷暗黑主题大屏
- 一、引言
- 二、数据概览
- 2.1 数据清洗
- 三、数据可视化
- 3.1各省门店数量柱状图
- 3.2 全国门店分布地图
- 3.3 门店数量玫瑰图(极坐标)
- 3.4 营业时间分布折线图(带面积)
- 3.5 营业时长词云图
- 3.6 营业时长分布饼图
- 3.7 可视化大屏
- 四、可视化结果分析
- 4.1 各省海底捞门店数量分布柱状图
- 4.2 全国门店分布地图
- 4.3 门店数量玫瑰图(极坐标)
- 4.4 营业时间分布折线图(带面积)
- 4.5 营业时长词云图
- 4.6 营业时长分布饼图
- 五、结论
一、引言
在大数据时代,数据分析和可视化成为了企业洞察市场、优化运营的重要手段。本文将利用Python的pyecharts库对海底捞门店数据进行深入分析和可视化展示。通过这些图表,我们可以直观地了解海底捞的业务分布、营业时间分布以及门店的运营时长等关键指标。
二、数据概览
我们的数据集包含了海底捞门店的详细信息,字段包括序号、省份、地址、店名、营业时间、开始营业、结束营业、营业时长、纬度和经度。
2.1 数据清洗
import pandas as pd
from pyecharts.charts import *# 读取数据
df = pd.read_csv('clean_data.csv',encoding='gbk')# 1. 各省门店数量分析
province_count = df['省份'].value_counts().reset_index()
province_count.columns = ['省份', '门店数量']
# 创建黑色主题的可视化图表
theme = ThemeType.DARK
三、数据可视化
为了更好地理解数据,我们将绘制以下几种图表:
- 各省海底捞门店数量分布柱状图
- 全国门店分布地图
- 门店数量玫瑰图(极坐标)
- 营业时间分布折线图(带面积)
- 营业时长词云图
- 营业时长分布饼图
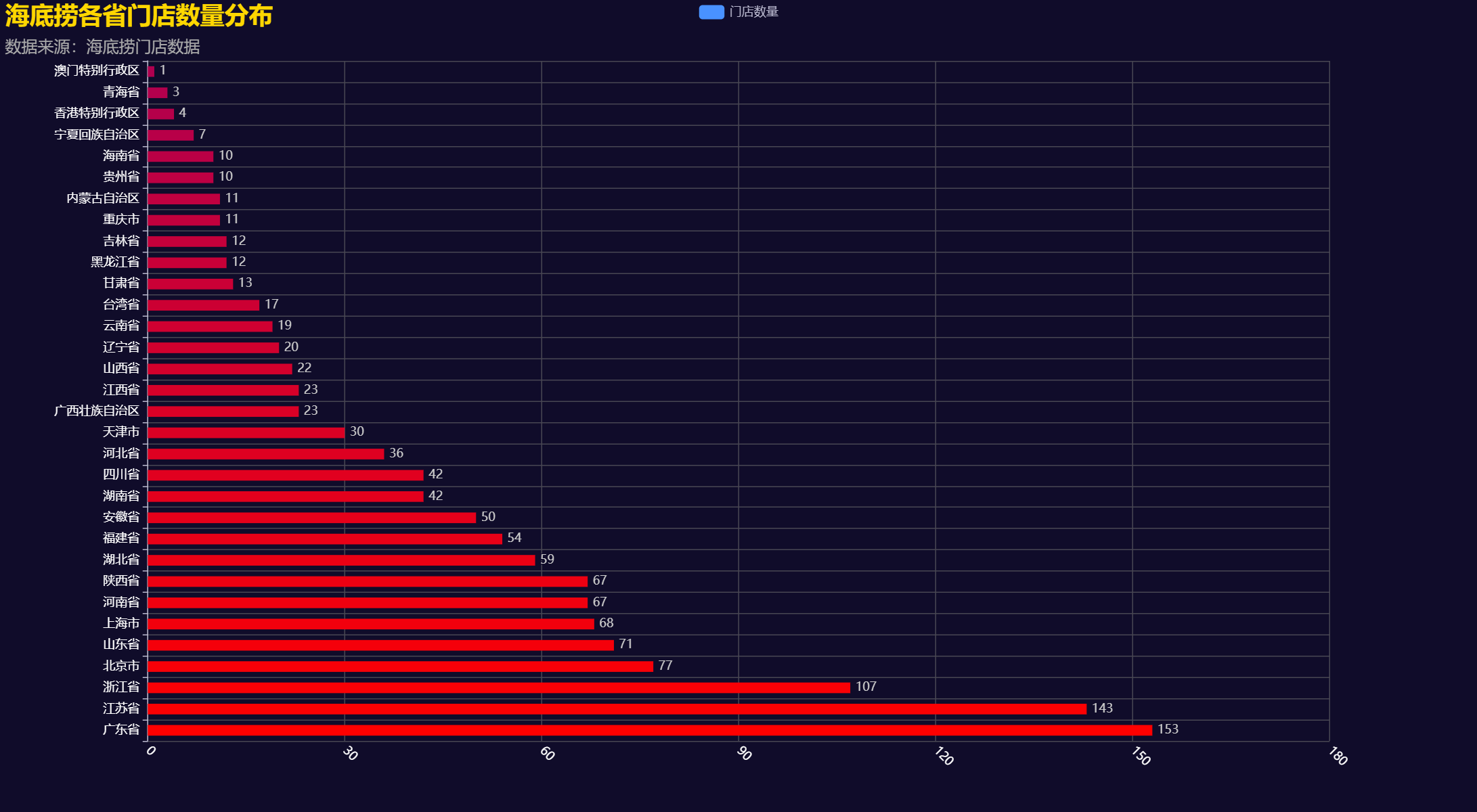
3.1各省门店数量柱状图
bar = (Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK,width="100%",height="800px")).add_xaxis(province_count['省份'].tolist()).add_yaxis("门店数量", province_count['门店数量'].tolist(),category_gap="50%",label_opts=opts.LabelOpts(is_show=True, position="top", color="white")).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="海底捞各省门店数量分布", subtitle="数据来源:海底捞门店数据",title_textstyle_opts=opts.TextStyleOpts(font_size=24, color="#FFD700"),subtitle_textstyle_opts=opts.TextStyleOpts(font_size=16, color="#aaa")),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45,color="#FFF")),yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(color="#FFF")),visualmap_opts=opts.VisualMapOpts(is_show=False,pos_top='60%',pos_left='40%',range_color=["red","purple","green" ]))
)
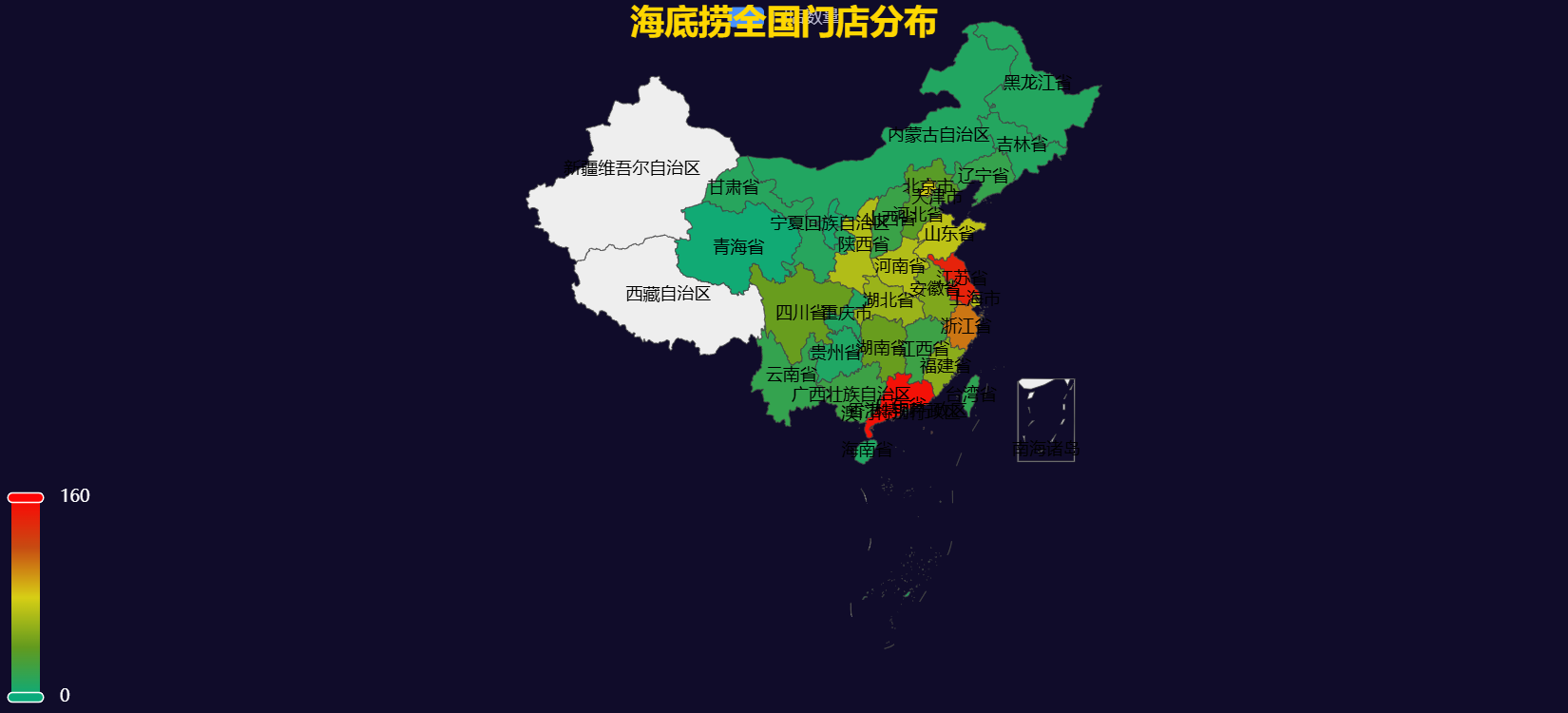
3.2 全国门店分布地图
map = (Map().add("门店数量",[list(z) for z in zip(province_count['省份'].tolist(),province_count['门店数量'].tolist())],maptype="china",is_map_symbol_show=False)
)
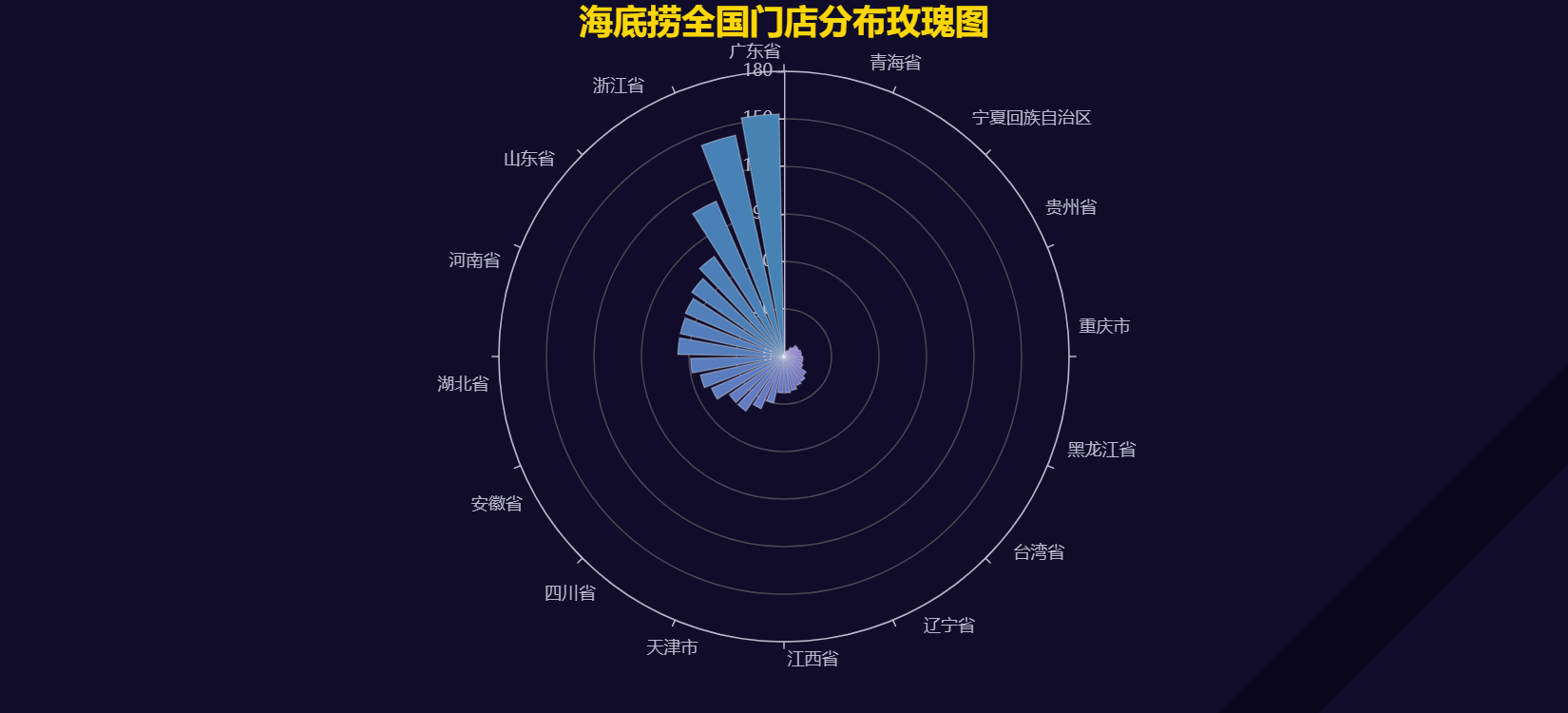
3.3 门店数量玫瑰图(极坐标)
# 创建玫瑰图
polar = (Polar(init_opts=opts.InitOpts(theme=ThemeType.DARK,width="1100px",height="500px")).add_schema(angleaxis_opts=opts.AngleAxisOpts(data=province_count['省份'].tolist(), type_="category")).add("门店数量",province_count['门店数量'].tolist(),type_="bar",label_opts=opts.LabelOpts(is_show=False,position="middle",formatter="{b}: {c}")
)
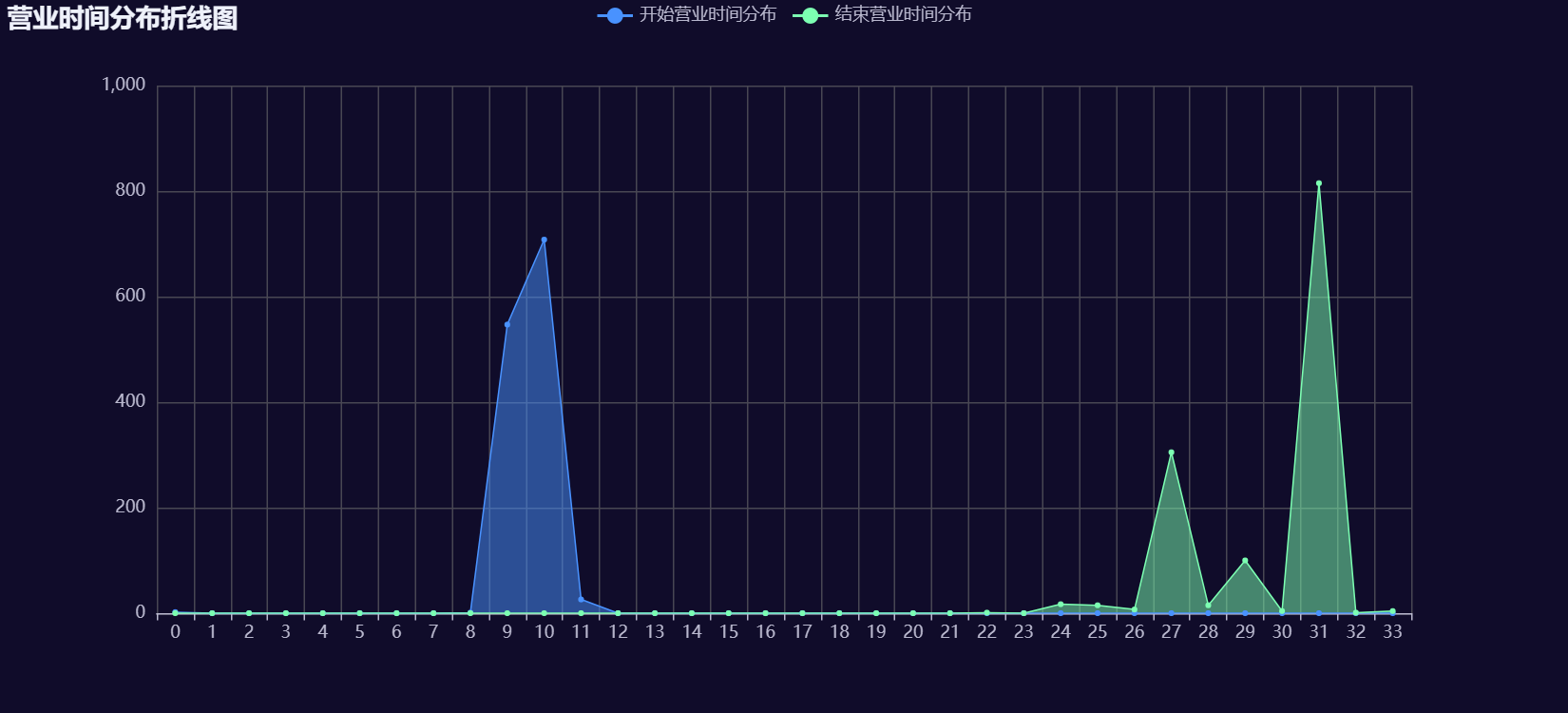
3.4 营业时间分布折线图(带面积)
# 创建带面积的折线图
line = (Line().add_xaxis([str(i) for i in range(34)]).add_yaxis("开始营业时间分布", start_hour_count.values.tolist()).add_yaxis("结束营业时间分布", end_hour_count.values.tolist())
)
3.5 营业时长词云图
# 生成词云
wordcloud = (WordCloud().add("",word_cloud_data,word_size_range=[12, 90])
)

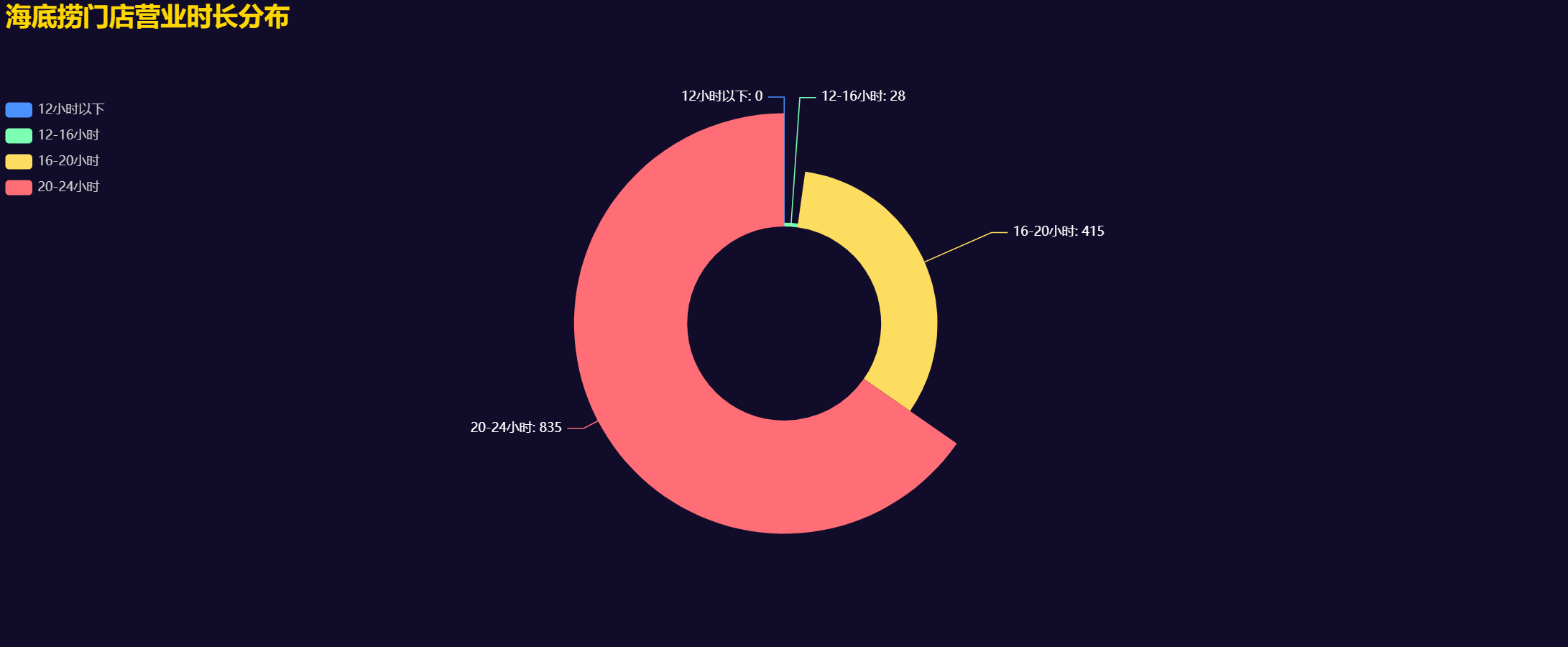
3.6 营业时长分布饼图
pie = (Pie().add("",[list(z) for z in zip(duration_count.index.tolist(), duration_count.values.tolist())],radius=["30%", "65%"],center=["50%", "50%"],rosetype="radius")
)
3.7 可视化大屏
from pyecharts.charts import Page# 创建Page对象
page = Page(page_title="海底捞门店数据分析大屏",layout=Page.DraggablePageLayout,
)# 添加所有图表
page.add(bar,map,polar,line,wordcloud,pie
)# 渲染大屏
page.render("海底捞门店数据分析大屏.html")
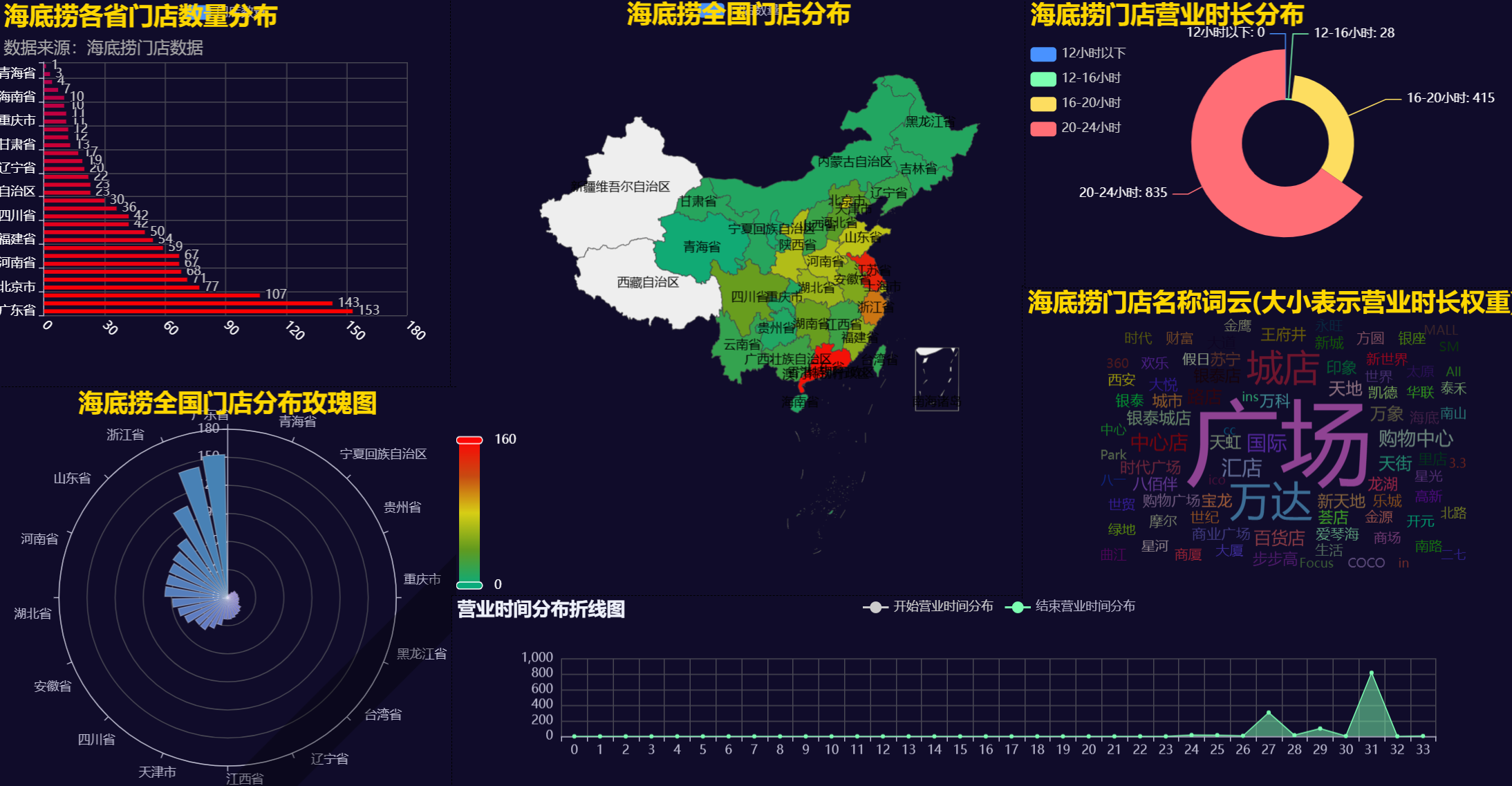
四、可视化结果分析
4.1 各省海底捞门店数量分布柱状图
通过柱状图,我们可以直观地看到江苏省和北京市的海底捞门店数量最多,这表明海底捞在这些地区的市场渗透率较高。
4.2 全国门店分布地图
地图展示了海底捞门店在全国范围内的分布情况。颜色越深表示门店数量越多。可以看到,门店主要集中在东部沿海地区。
4.3 门店数量玫瑰图(极坐标)
玫瑰图展示了各省门店数量占全国总门店数量的比例。广东省占比最高,为11.96%,其次是江苏省和浙江省。
4.4 营业时间分布折线图(带面积)
折线图显示了不同时间段内开始营业和结束营业的门店数量。可以看到,大多数门店在上午9点和10点开始营业。
4.5 营业时长词云图
词云图展示了海底捞门店名称中出现频率较高的词汇,词汇的大小表示营业时长的权重。通过词云图,我们可 以直观地了解门店名称中常见的词汇及其与营业时长的相关性。
4.6 营业时长分布饼图
饼图展示了不同营业时长的门店数量占比。可以看到,营业时长为22小时和21.5小时的门店数量最多。
五、结论
通过上述分析,我们可以得出以下结论:
- 海底捞门店主要集中在东部沿海地区,尤其是江苏省和北京市。
- 大部分门店的营业时间较长,集中在22小时和21.5小时。
- 开始营业和结束营业时间相对集中,分别在上午9点和凌晨3点。






)










、生成(Generate)和构建(Build))

