背景意义
研究背景与意义
在计算机视觉领域,实例分割技术作为一种重要的图像处理方法,近年来得到了广泛的关注和应用。实例分割不仅能够识别图像中的物体类别,还能精确地分割出每个物体的轮廓,提供更为细致的视觉信息。这一技术在自动驾驶、医疗影像分析、工业检测等多个领域展现出了巨大的潜力。随着深度学习技术的快速发展,基于卷积神经网络(CNN)的实例分割算法不断涌现,其中YOLO(You Only Look Once)系列模型因其高效性和实时性而备受青睐。
本研究旨在基于改进的YOLOv11模型,构建一个专门针对火柴的实例分割系统。火柴作为一种日常生活中常见的物品,其在图像识别中的应用相对较少,但其简单的形状和颜色特征使其成为实例分割研究的理想对象。通过构建一个包含2800张火柴图像的数据集,研究将能够深入探讨YOLOv11在处理特定类别物体时的性能表现。该数据集的设计不仅考虑了样本数量的丰富性,还通过多种数据增强技术提升了模型的泛化能力。
此外,火柴实例分割系统的研究具有重要的实际意义。随着智能家居和自动化设备的普及,能够精准识别和处理日常物品的计算机视觉系统将极大提升人机交互的智能化水平。通过对火柴的精确分割与识别,未来可以为相关领域的应用提供基础,例如在智能厨房中识别火柴的使用情况,或在安全监控中检测潜在的火灾隐患。
综上所述,基于改进YOLOv11的火柴实例分割系统不仅能够推动实例分割技术的发展,还能为实际应用提供有力支持,具有重要的研究价值和应用前景。
图片效果
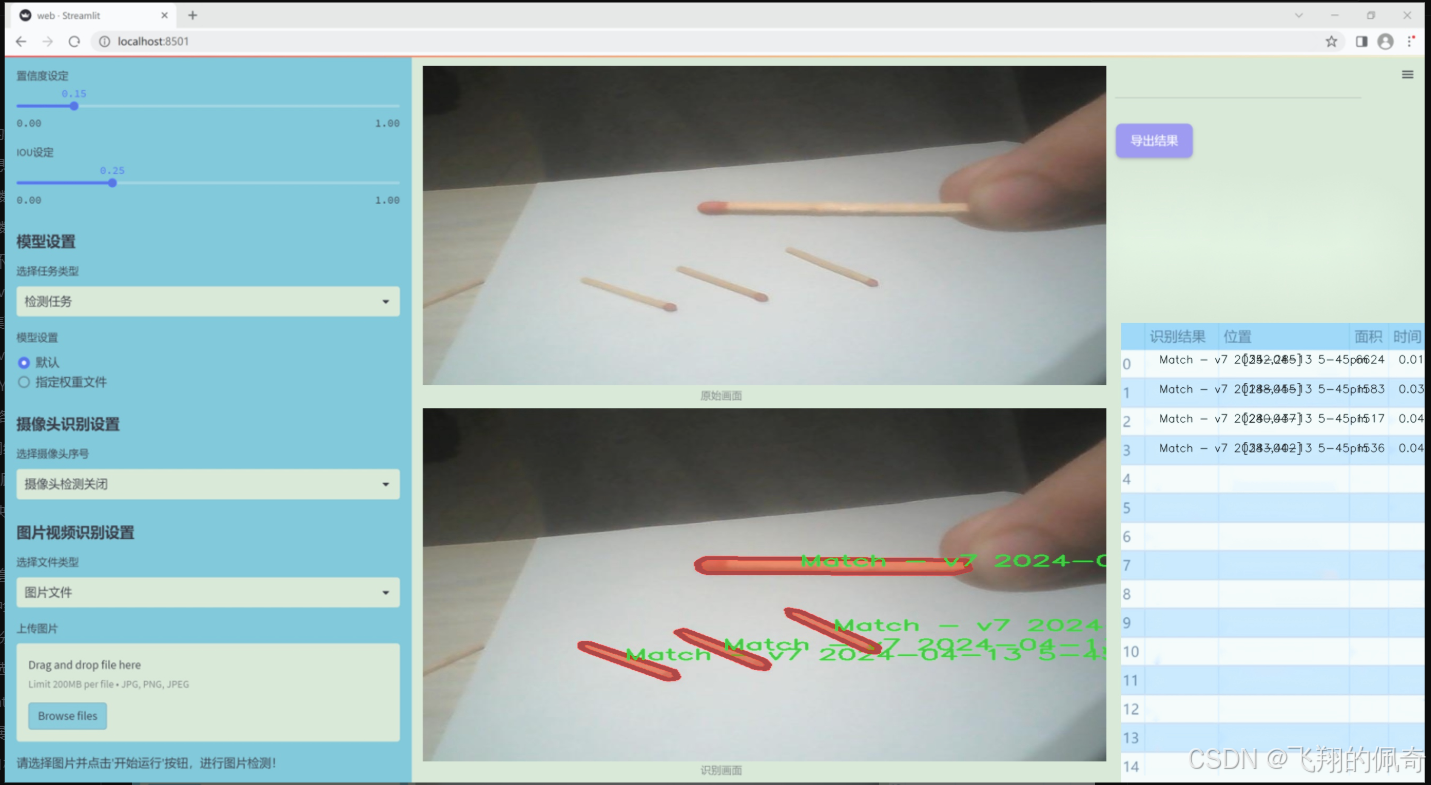
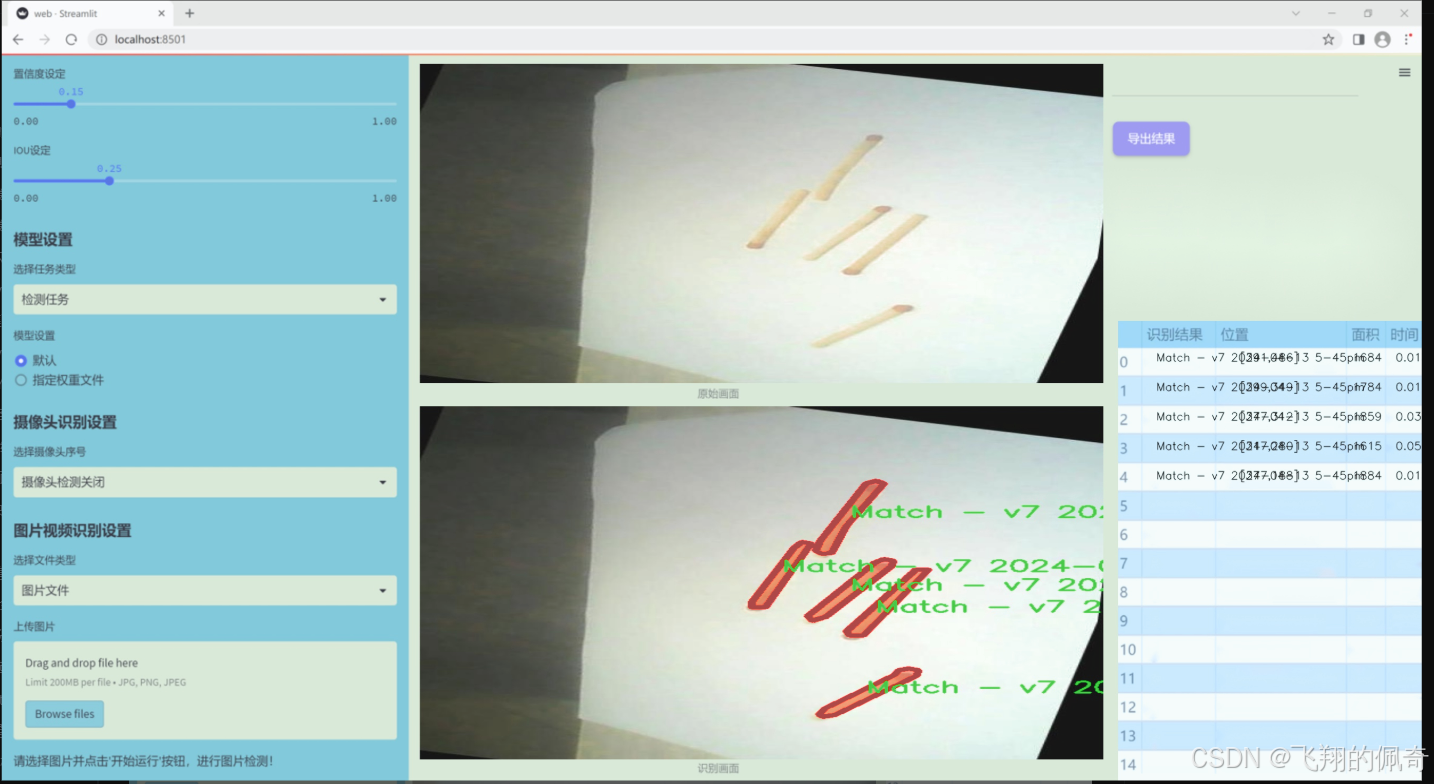
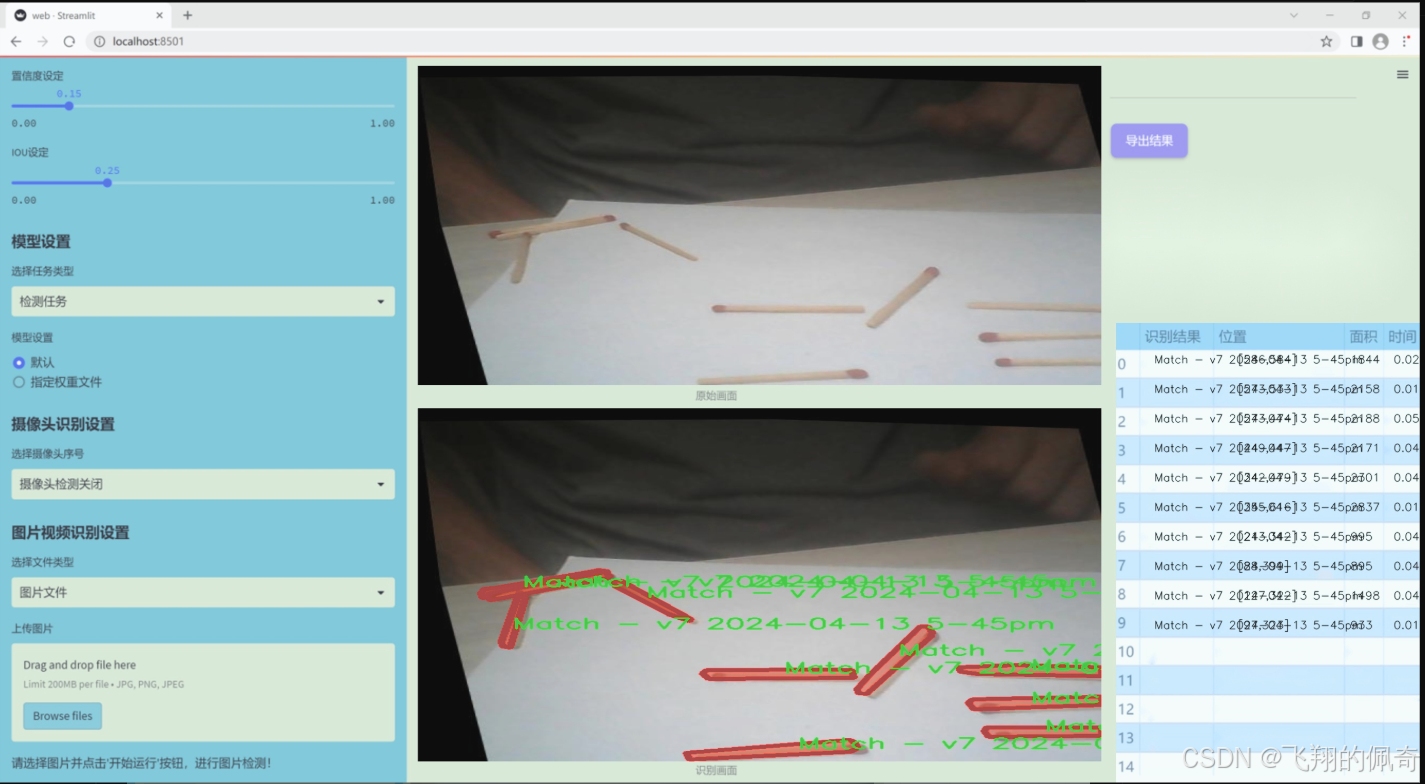
数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于“MatchSegmentation”主题,旨在为改进YOLOv11的火柴实例分割系统提供高质量的训练数据。该数据集的设计旨在支持火柴图像的精确分割,确保模型能够有效识别和处理不同场景中的火柴实例。数据集中包含一个类别,具体为“Match - v7 2024-04-13 5-45pm”,这一类别的命名不仅反映了数据集的创建时间,也体现了其针对火柴实例的专门化特征。
数据集的构建过程经过精心设计,涵盖了多种不同背景和光照条件下的火柴图像,以确保模型在多样化环境中的鲁棒性。每个图像都经过精确标注,确保火柴的轮廓和细节得以清晰呈现,这对于实例分割任务至关重要。通过这种方式,数据集不仅提供了丰富的视觉信息,还为模型的训练提供了坚实的基础,使其能够在实际应用中实现更高的准确性和效率。
此外,数据集的多样性和丰富性使其成为研究火柴实例分割的理想选择。随着YOLOv11的改进,研究人员能够利用这一数据集进行深入的实验和分析,从而推动火柴图像处理技术的发展。通过对该数据集的深入挖掘和应用,项目团队期望能够在火柴实例分割领域取得突破性进展,为相关应用提供更为精准和高效的解决方案。总之,本项目的数据集不仅为模型训练提供了必要的支持,也为未来的研究和应用奠定了坚实的基础。





核心代码
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn.functional as F
def selective_scan_easy(us, dts, As, Bs, Cs, Ds, delta_bias=None, delta_softplus=False, return_last_state=False, chunksize=64):
“”"
选择性扫描函数,执行基于输入的状态和增量的递归计算。
参数:
us: 输入状态,形状为 (B, G * D, L)
dts: 增量,形状为 (B, G * D, L)
As: 权重矩阵,形状为 (G * D, N)
Bs: 权重矩阵,形状为 (B, G, N, L)
Cs: 权重矩阵,形状为 (B, G, N, L)
Ds: 偏置项,形状为 (G * D)
delta_bias: 可选的偏置调整,形状为 (G * D)
delta_softplus: 是否对增量应用softplus函数
return_last_state: 是否返回最后的状态
chunksize: 每次处理的序列长度返回:
输出状态,形状为 (B, G * D, L) 或 (B, G * D, L) 和最后状态
"""def selective_scan_chunk(us, dts, As, Bs, Cs, hprefix):"""处理一个块的选择性扫描,执行状态更新和输出计算。参数:us: 输入状态块,形状为 (L, B, G, D)dts: 增量块,形状为 (L, B, G, D)As: 权重矩阵,形状为 (G, D, N)Bs: 权重矩阵,形状为 (L, B, G, N)Cs: 权重矩阵,形状为 (L, B, G, N)hprefix: 前一个状态,形状为 (B, G, D, N)返回:输出状态和更新后的状态"""ts = dts.cumsum(dim=0) # 计算增量的累积和Ats = torch.einsum("gdn,lbgd->lbgdn", As, ts).exp() # 计算权重的指数rAts = Ats # 归一化权重duts = dts * us # 计算增量与输入状态的乘积dtBus = torch.einsum("lbgd,lbgn->lbgdn", duts, Bs) # 计算加权增量hs_tmp = rAts * (dtBus / rAts).cumsum(dim=0) # 更新状态hs = hs_tmp + Ats * hprefix.unsqueeze(0) # 加上前一个状态ys = torch.einsum("lbgn,lbgdn->lbgd", Cs, hs) # 计算输出return ys, hs# 数据类型设置
dtype = torch.float32
dts = dts.to(dtype) # 将增量转换为指定数据类型
if delta_bias is not None:dts += delta_bias.view(1, -1, 1).to(dtype) # 应用偏置调整
if delta_softplus:dts = F.softplus(dts) # 应用softplus函数# 数据维度调整
B, G, N, L = Bs.shape
us = us.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
dts = dts.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
As = As.view(G, -1, N).to(dtype)
Bs = Bs.permute(3, 0, 1, 2).to(dtype)
Cs = Cs.permute(3, 0, 1, 2).to(dtype)
Ds = Ds.view(G, -1).to(dtype) if Ds is not None else Noneoys = [] # 存储输出
hprefix = us.new_zeros((B, G, D, N), dtype=dtype) # 初始化前一个状态
for i in range(0, L, chunksize):ys, hs = selective_scan_chunk(us[i:i + chunksize], dts[i:i + chunksize], As, Bs[i:i + chunksize], Cs[i:i + chunksize], hprefix)oys.append(ys) # 添加输出hprefix = hs[-1] # 更新前一个状态oys = torch.cat(oys, dim=0) # 合并所有输出
if Ds is not None:oys += Ds * us # 加上偏置项
return oys.permute(1, 2, 3, 0).view(B, -1, L) if not return_last_state else (oys, hprefix.view(B, G * D, N).float())
选择性扫描函数的调用示例
result = selective_scan_easy(us, dts, As, Bs, Cs, Ds)
代码说明:
函数定义:selective_scan_easy是主函数,执行选择性扫描的逻辑。
参数说明:函数的参数包括输入状态、增量、权重矩阵等,具体的形状要求在注释中说明。
内部函数:selective_scan_chunk用于处理输入的一个块,计算输出和更新状态。
数据处理:对输入数据进行类型转换和维度调整,以适应后续计算。
循环处理:通过循环处理每个块,更新输出和状态,最后合并结果。
以上是对核心代码的简化和详细注释,便于理解其功能和实现逻辑。
这个程序文件 test_selective_scan_easy.py 是一个用于实现和测试选择性扫描(Selective Scan)算法的 PyTorch 代码。选择性扫描是一种用于处理序列数据的计算方法,通常用于递归神经网络(RNN)和其他序列模型中。
代码的开头部分定义了一些导入的库,包括数学运算、PyTorch、pytest 和 einops(用于张量重排的库)。接着,定义了一个主要的函数 selective_scan_easy,该函数的目的是执行选择性扫描操作。它的输入包括多个张量,代表不同的参数和状态,具体如下:
us: 输入序列的张量,形状为 (B, G * D, L),其中 B 是批量大小,G 是组数,D 是维度,L 是序列长度。
dts: 时间增量的张量,形状与 us 相同。
As, Bs, Cs, Ds: 这些张量分别代表不同的线性变换矩阵,形状和用途在函数注释中有详细说明。
delta_bias 和 delta_softplus: 可选的偏置和激活函数的标志。
return_last_state: 是否返回最后的状态。
chunksize: 分块大小,用于控制计算的并行度。
selective_scan_easy 函数内部定义了一个嵌套函数 selective_scan_chunk,用于处理每个块的选择性扫描逻辑。该函数实现了选择性扫描的核心算法,包括计算中间状态和输出的逻辑。
接下来,函数对输入数据进行了类型转换和形状调整,以确保它们适合后续的计算。然后,函数通过循环处理每个块,调用 selective_scan_chunk 函数,并将结果存储在列表中,最后将所有块的结果合并。
在类 SelectiveScanEasy 中,定义了前向和反向传播的方法,利用 PyTorch 的自动求导功能来计算梯度。这个类允许在训练过程中使用选择性扫描,并支持混合精度训练。
代码还包含了几个版本的选择性扫描实现(如 selective_scan_easyv2 和 selective_scan_easyv3),每个版本可能在实现细节上有所不同,以优化性能或内存使用。
最后,代码中定义了一个测试函数 test_selective_scan,使用 pytest 框架对选择性扫描的实现进行单元测试。测试涵盖了不同的输入配置,确保实现的正确性和稳定性。
整体来看,这个程序文件是一个复杂的深度学习模块,旨在高效地实现选择性扫描算法,并通过测试确保其功能的正确性。
10.4 val.py
以下是代码中最核心的部分,并附上详细的中文注释:
class DetectionValidator(BaseValidator):
“”"
扩展自 BaseValidator 类的检测模型验证器。
用于验证基于 YOLO 的目标检测模型的性能。
“”"
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):"""初始化检测模型所需的变量和设置。"""super().__init__(dataloader, save_dir, pbar, args, _callbacks)self.metrics = DetMetrics(save_dir=self.save_dir, on_plot=self.on_plot) # 初始化检测指标self.iouv = torch.linspace(0.5, 0.95, 10) # 生成用于计算 mAP 的 IoU 阈值self.niou = self.iouv.numel() # IoU 阈值的数量def preprocess(self, batch):"""对 YOLO 训练的图像批次进行预处理。"""# 将图像移动到指定设备并进行归一化处理batch["img"] = batch["img"].to(self.device, non_blocking=True)batch["img"] = (batch["img"].half() if self.args.half else batch["img"].float()) / 255for k in ["batch_idx", "cls", "bboxes"]:batch[k] = batch[k].to(self.device)return batchdef postprocess(self, preds):"""对预测输出应用非极大值抑制(NMS)。"""return ops.non_max_suppression(preds,self.args.conf, # 置信度阈值self.args.iou, # IoU 阈值multi_label=True, # 允许多标签agnostic=self.args.single_cls, # 是否单类检测max_det=self.args.max_det, # 最大检测数量)def update_metrics(self, preds, batch):"""更新检测指标。"""for si, pred in enumerate(preds):self.seen += 1 # 记录已处理的图像数量pbatch = self._prepare_batch(si, batch) # 准备当前批次的真实标签cls, bbox = pbatch.pop("cls"), pbatch.pop("bbox") # 获取真实类别和边界框if len(pred) == 0: # 如果没有检测到目标continuepredn = self._prepare_pred(pred, pbatch) # 准备预测结果# 计算真阳性(TP)等指标stat = self._process_batch(predn, bbox, cls)# 更新统计信息for k in self.stats.keys():self.stats[k].append(stat[k])def get_stats(self):"""返回指标统计信息和结果字典。"""stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # 转换为 numpy 数组if len(stats) and stats["tp"].any():self.metrics.process(**stats) # 处理指标return self.metrics.results_dict # 返回结果字典def print_results(self):"""打印每个类别的训练/验证集指标。"""pf = "%22s" + "%11i" * 2 + "%11.3g" * len(self.metrics.keys) # 打印格式LOGGER.info(pf % ("all", self.seen, self.nt_per_class.sum(), *self.metrics.mean_results())) # 打印总体结果# 打印每个类别的结果if self.args.verbose and self.nc > 1 and len(self.stats):for i, c in enumerate(self.metrics.ap_class_index):LOGGER.info(pf % (self.names[c], self.seen, self.nt_per_class[c], *self.metrics.class_result(i)))def _process_batch(self, detections, gt_bboxes, gt_cls):"""返回正确的预测矩阵。参数:detections (torch.Tensor): 形状为 [N, 6] 的检测结果张量。gt_bboxes (torch.Tensor): 形状为 [M, 5] 的真实标签张量。返回:(torch.Tensor): 形状为 [N, 10] 的正确预测矩阵,表示 10 个 IoU 阈值的结果。"""iou = box_iou(gt_bboxes, detections[:, :4]) # 计算 IoUreturn self.match_predictions(detections[:, 5], gt_cls, iou) # 匹配预测与真实标签def save_one_txt(self, predn, save_conf, shape, file):"""将 YOLO 检测结果保存到指定格式的 txt 文件中。"""gn = torch.tensor(shape)[[1, 0, 1, 0]] # 归一化增益for *xyxy, conf, cls in predn.tolist():xywh = (ops.xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 转换为归一化的 xywh 格式line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # 生成保存格式with open(file, "a") as f:f.write(("%g " * len(line)).rstrip() % line + "\n") # 写入文件
代码核心部分解释:
DetectionValidator 类:这是一个用于验证 YOLO 模型性能的类,继承自 BaseValidator。
初始化方法:设置必要的变量和指标,包括检测指标和 IoU 阈值。
预处理方法:对输入的图像批次进行归一化和设备转换。
后处理方法:应用非极大值抑制来过滤检测结果。
更新指标方法:更新每个批次的检测结果和真实标签的统计信息。
获取统计信息方法:计算并返回模型的性能指标。
打印结果方法:输出模型在训练/验证集上的性能指标。
处理批次方法:计算 IoU 并返回正确的预测矩阵。
保存检测结果方法:将检测结果保存为指定格式的文本文件。
这个程序文件 val.py 是一个用于YOLO(You Only Look Once)目标检测模型验证的实现。它继承自 BaseValidator 类,专注于通过检测模型进行验证。程序中导入了多个库和模块,包括 torch、numpy 和 ultralytics 的相关模块,这些都是进行数据处理、模型评估和结果可视化所必需的。
在 DetectionValidator 类的初始化方法中,设置了一些必要的变量和参数,包括数据加载器、保存目录、进度条、参数字典等。该类的主要功能是对YOLO模型的性能进行评估,计算各种指标,如mAP(mean Average Precision)等。初始化时还定义了一些与评估相关的变量,如 iouv(用于计算不同IoU阈值的向量)和 lb(用于自动标记)。
preprocess 方法负责对输入的图像批次进行预处理,包括将图像转换为适合模型输入的格式,并根据需要进行归一化处理。该方法还会根据配置决定是否保存混合标签。
init_metrics 方法用于初始化评估指标,检查数据集是否为COCO格式,并根据模型的类别名称设置相应的参数。get_desc 方法返回一个格式化的字符串,用于描述各类指标。
postprocess 方法应用非极大值抑制(NMS)来处理模型的预测输出,以减少重叠的边界框。_prepare_batch 和 _prepare_pred 方法则分别用于准备真实标签和模型预测的批次数据,以便后续的评估。
update_metrics 方法负责更新模型的评估指标,包括计算TP(True Positive)、FP(False Positive)等。该方法会根据模型的预测结果和真实标签进行比较,并更新混淆矩阵。
finalize_metrics 方法在所有批次处理完成后设置最终的评估指标。get_stats 方法将统计信息整理为字典并返回。
print_results 方法用于打印训练或验证集的每类指标,包括每类的TP、FP等信息,并在需要时绘制混淆矩阵。
_process_batch 方法用于计算正确预测的矩阵,返回不同IoU阈值下的预测结果。build_dataset 和 get_dataloader 方法则用于构建YOLO数据集和返回数据加载器。
plot_val_samples 和 plot_predictions 方法用于可视化验证样本和模型预测结果,并将结果保存为图像文件。
save_one_txt 方法将YOLO检测结果保存为文本文件,格式化为特定的规范。pred_to_json 方法将预测结果序列化为COCO格式的JSON文件,以便后续评估。
最后,eval_json 方法用于评估YOLO输出的JSON格式,并返回性能统计信息。它会检查所需的文件是否存在,并使用pycocotools库计算mAP指标。
整体来看,这个程序文件实现了YOLO模型验证的完整流程,包括数据预处理、模型评估、结果可视化和性能统计,适用于目标检测任务的评估和分析。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻



单例模式)












详解)


