1. 什么是knn算法
knn算法全名叫做k-近邻算法(K-Nearest Neighbors,简称KNN),看到名字是不是能想到是算距离的,第一个k是指超参数的意思,就是可以认为设置的意思,这里是指最近的k个样本。
2. 为什么有这个算法
如果我们要给一些数据分类,是不是通过它的一些相似的特征或者都有的特征,我们就将它分为一类,那我们怎么判别数据相不相似是不是可以通过算距离的方法,数据特征都是可以量化为数字的。knn算法就是可以干这个的算距离的。
算距离的方式
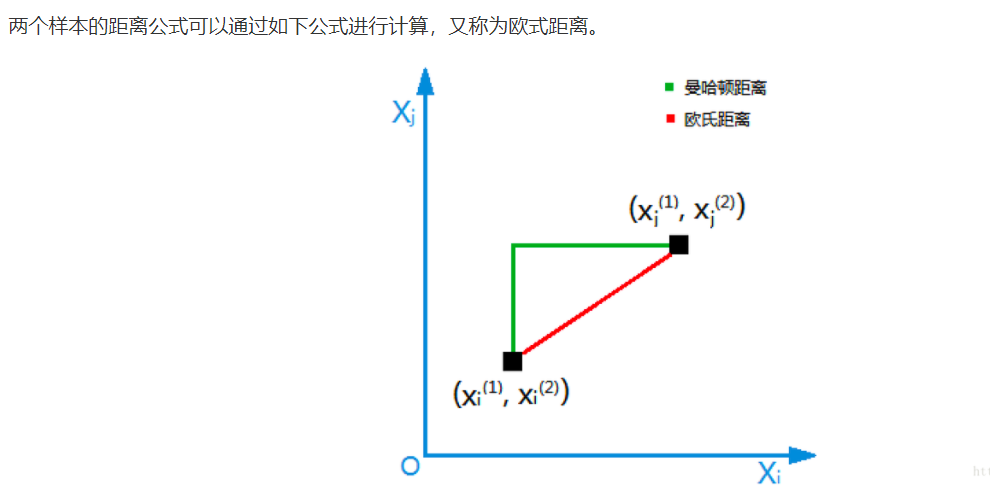
3. knn的原理
knn处理的数据是带有标签的,在使用训练集训练模型的时候,前面说了knn是通过算样本之间的距离的,所有训练模型的时候其实什么也没有干就只是保存了数据集,当测试数据的时候才会执行通过算每个样本和测试数据的特征距离,算好以后再排个序(由小到大),然后这里就需要自己传入的k值了,排序完后,就选择前k个数据,k个里面占比最高的类别是什么测试数据就属于什么。
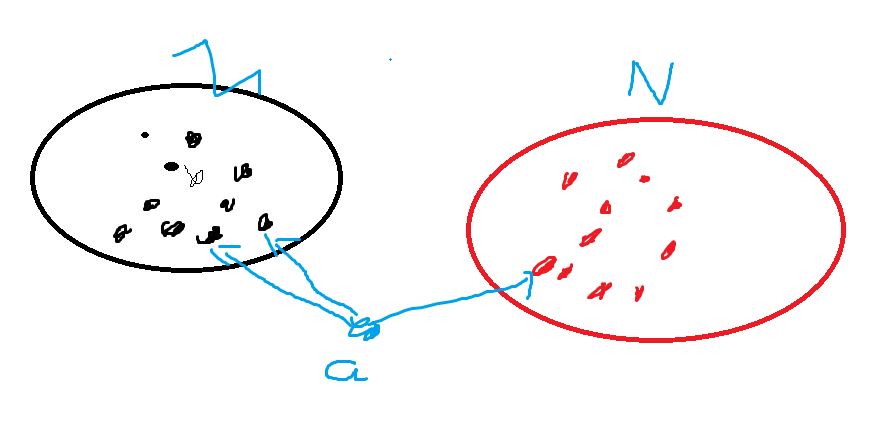
假如黑色的点归为M,红色的点为N,现在有一个a,k为3,那么就找最近的三个点,这里黑色的点有两个虽有将a划分为M。
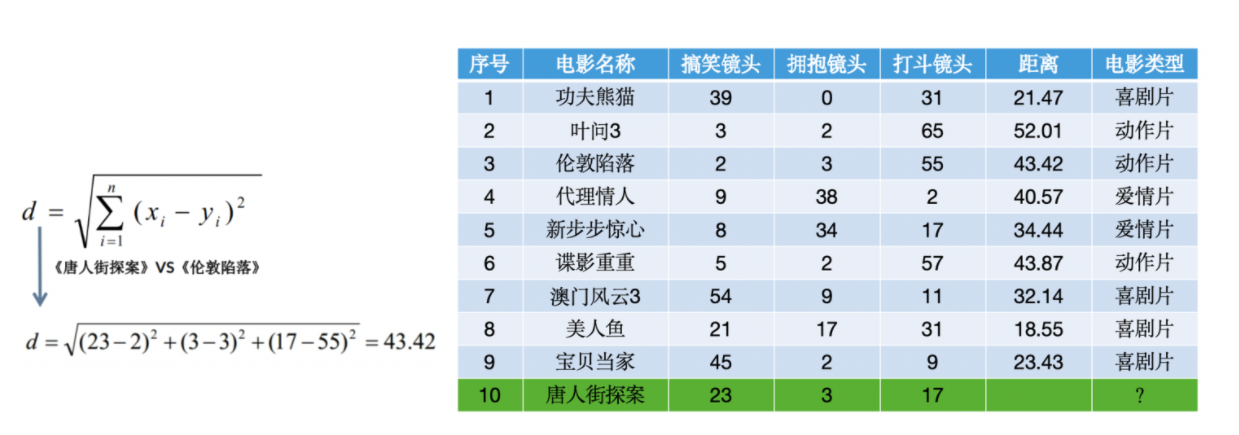
举个例子:我们这里测试集有1-9条,然后我们需要判断出10条什么电影类型的,假如k为3,那么前三条最近的就是8,1,9,全是喜剧片所以我们就推断10也是喜剧片,原理就这么简单。
4. api实现
KNeighborsClassifier(n_neighbors=5, algorithm='auto')
参数:
(1)n_neighbors:
int, default=5, 默认情况下用于kneighbors查询的近邻数,就是K
方法:
(1) fit(x, y)
使用X作为训练数据和y作为目标数据
(2) predict(X) 预测提供的数据,得到预测数据
# 用KNN算法对鸢尾花进行分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier# 1)获取数据
x,y = load_iris(return_X_y=True)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=42)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)KNN算法预估器, k=7表示找7个邻近来判断自身类型.
estimator = KNeighborsClassifier(n_neighbors=7)
estimator.fit(x_train, y_train)#该步骤就是estimator根据训练特征和训练目标在自己学习,让它自己变聪敏
# 5)模型评估 测试一下聪敏的estimator能力# 方法1:直接比对真实值和预测值,
y_predict = estimator.predict(x_test) #y_predict预测的目标结果
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法2:计算准确率,
score = estimator.score(x_test, y_test)# 里面会自己预测y值,然后和y_test作比较,相等的个数/总数
print("准确率为:\n", score) #1.0准确率100了,过度拟合了,这样反而是不好的,后面会讲到的。
5. knn的缺点
对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
我们这里没什么感觉是应为数据集只有100多条,但是实际开发中的数据都是几百万上千万的数据,那这个都算一遍就哼恐怖了。
对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”
就是那种算出来的距离为99999999912,99999999914,这样的他们的特征也不一样,但是这么数据太大了比较就有没有意义了。
需要选择合适的k值和距离度量,这可能需要一些实验和调整。
k值过大过小是不是都会影响准确率,k值太大假如接近全部样本的数量了,是不是根本就不用测我们直接统计谁的种类多就好了。
但是knn在实际应用开发中应用的好少,是应为他是训练的时候才去预测的,我们训练时时间花长一点都是没事的,但预测的时候太长,那客户使用的时候且不是要等好久才能有一个结果。


易视TV is-E4-G-全志A20芯片-安卓4-烧写卡刷工具及教程)
顺序表实现-增删查改)















