Index(写)调优
副本数置0
如果是集群首次灌入数据,可以将副本数设置为0,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过 程。
PUT /my_temp_index/_settings
{
"number_of_replicas": 0
}自动生成doc ID
通过Elasticsearch写入流程可以看出,如果写入doc时如果外部指定了id,则Elasticsearch会先尝试读取原来doc 的版本号,以判断是否需要更新。这会涉及一次读取磁盘的操作,通过自动生成doc ID可以避免这个环节。
合理设置mappings
- 将不需要建立索引的字段index属性设置为not_analyzed或no。对字段不分词,或者不索引,可以减少很多运 算操作,降低CPU占用。 尤其是binary类型,默认情况下占用CPU非常高,而这种类型进行分词通常没有什么意义。
- 减少字段内容长度,如果原始数据的大段内容无须全部建立 索引,则可以尽量减少不必要的内容。
-
使用不同的分析器(analyzer),不同的分词器在索引过程中 运算复杂度也有较大的差异。
调整_source字段
source 字段用于存储 doc 原始数据,对于部分不需要存储的字段,可以通过 includes excludes过滤,或者将 source禁用,一般用于索引和数据分离,这样可以降低 I/O 的压力,不过实际场景中大多不会禁用_source。
对analyzed的字段禁用norms
Norms用于在搜索时计算doc的评分,如果不需要评分,则可以将其禁用:
"title": {
"type": "string",
"norms": {
"enabled": false
}调整索引的刷新间隔
该参数缺省是1s,强制ES每秒创建一个新segment,从而保证新写入的数据近实时的可见、可被搜索到。比如该参 数被调整为30s,降低了刷新的次数,把刷新操作消耗的系统资源释放出来给index操作使用。
PUT /my_index/_settings
{
"index" : {
"refresh_interval": "30s"
}
}批处理
批处理把多个index操作请求合并到一个batch中去处理,和mysql的jdbc的bacth有类似之处。如图:
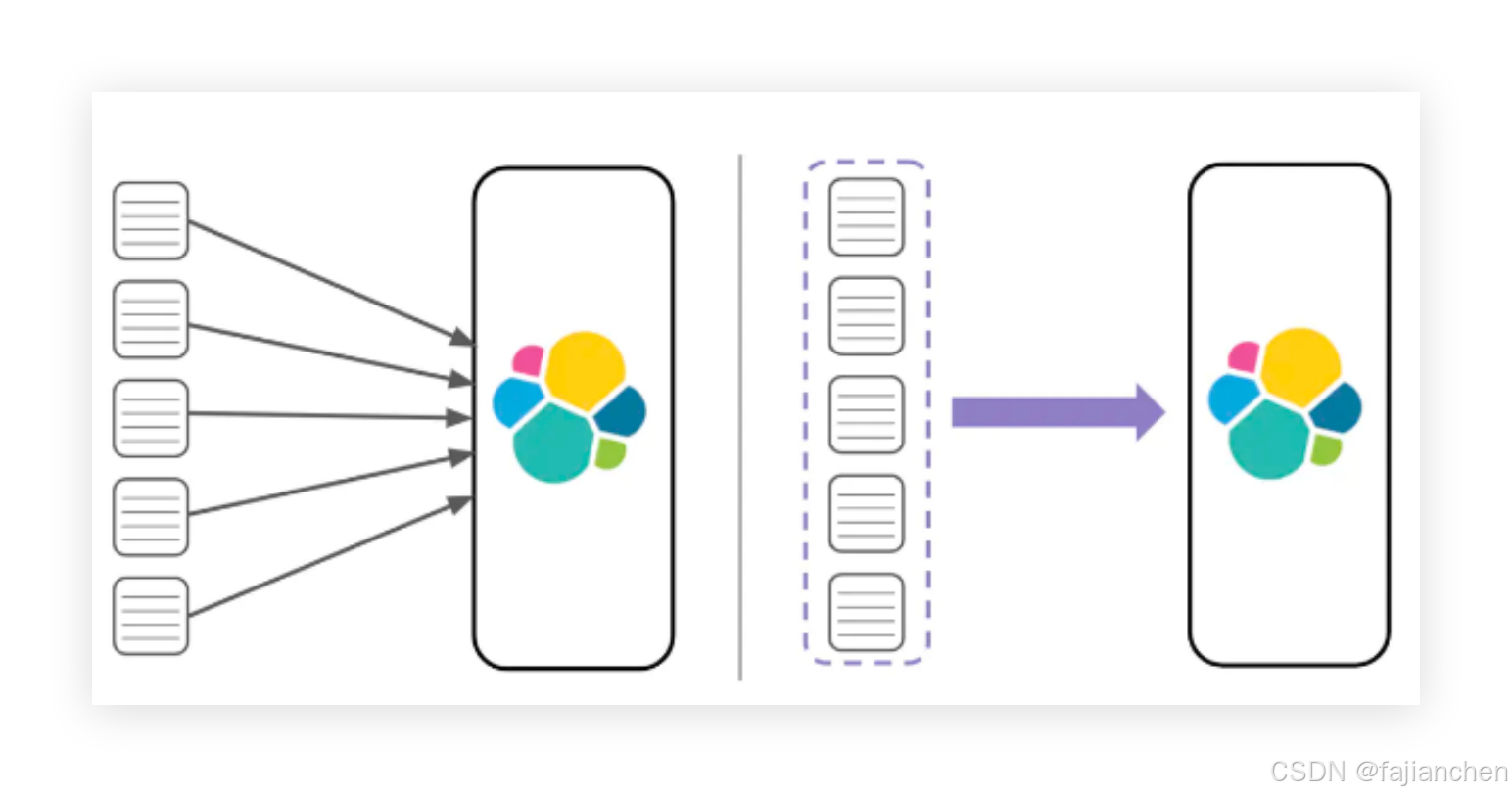
比如每批1000个documents是一个性能比较好的size。每批中多少document条数合适,受很多因素影响而不同
推荐阅读
什么是AI Agent
高性能:为什么说Elasticsearch的倒排表比mySql的B+树查询快呢?
技术总体方案设计思路









鼠标控制、可拓展陀螺仪与脚本控制)
)
)

)

)


)
——梯度处理、边缘检测、图像轮廓)