根据论文网络结构图讲一下:
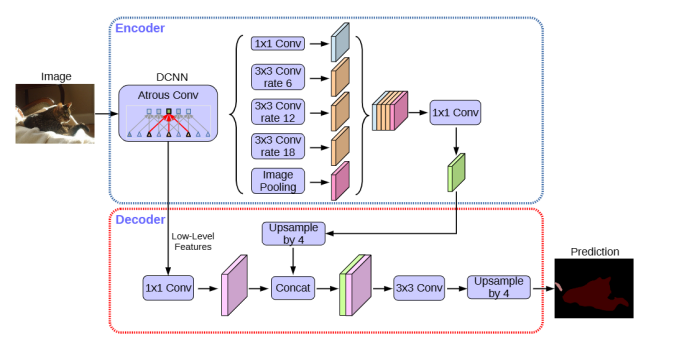
网络分为两部分:encoder和decoder部分。
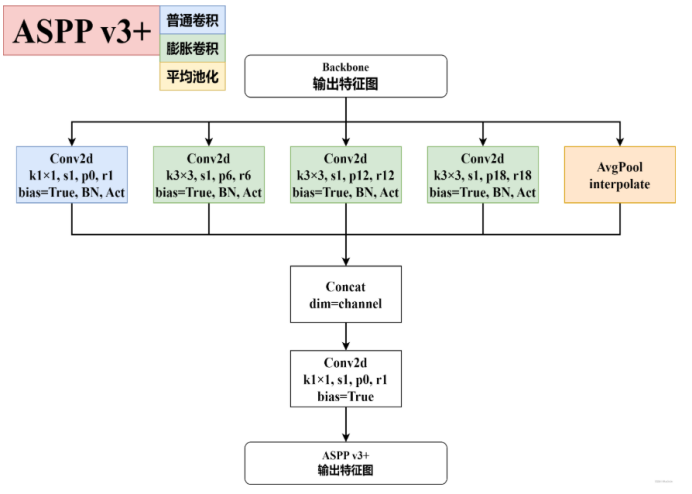
Encoder:DCNN就是主干网络,例如resnet,Xception,MobileNet这些(主干网络也要使用空洞卷积),对dcnn的结果利用ASPP(Atrous Spatial Pyramid Pooling)ASPP也就是利用不能rate的空洞卷积,并把ASPP的结果合并,经过11卷积得到高级特征。
Decoder:对DCNN的低层次结果进行11卷积,并对encoder的高级特征进行4倍上采样,将二者合并,再经过3*3卷积和4倍上采样对像素进行分类。
现在来看deeplabV3+的结构还是很简单的。参考下面的链接阅读源码:
VainF/DeepLabV3Plus-Pytorch: Pretrained DeepLabv3 and DeepLabv3+ for Pascal VOC & Cityscapes
bubbliiiing/deeplabv3-plus-pytorch: 这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。
参考:
deeplabv3+
https://arxiv.org/abs/1802.02611
https://blog.csdn.net/qq_37541097/article/details/121752679
https://zhuanlan.zhihu.com/p/68531147
https://blog.csdn.net/weixin_44878336/article/details/132061772
https://blog.csdn.net/m0_46677695/article/details/143885395














 和 endGeometry () 打造自定义 3D 模型)
NMPC非线性模型预测控制及机械臂ROS控制器实现)



