0. 前言
前两天字节发布了GR-3,粗略的看了一下,在某些方面超过了SOTA pi0,虽然不开源,但是也可以来看一看。
官方项目页

1. GR-3模型
1.1 背景
在机器人研究领域,一直以来的目标就是打造能够帮助人类完成日常任务的智能通用机器人。一个核心挑战在于现实世界的多样性极高,因此机器人策略需要具备很强的泛化能力,才能应对各种新场景。而且,许多日常任务本质上是长周期的,需要复杂的灵巧操作,这就要求机器人策略必须非常稳健可靠。
最近在视觉-语言-动作(VLA)模型方面的进展,为开发智能通用机器人策略开辟了有希望的道路。这些模型以预训练的视觉-语言模型(VLMs)为基础,并融合了动作预测功能,使机器人能够根据自然语言指令执行各类任务。尽管取得了这些进展,机器人执行指令依然是个重大挑战,尤其是对于“分布外”指令(即含有机器人轨迹数据中未见过的新物体类别和/或需要复杂推理的概念)更是难上加难。
此外,VLA 模型通常需要大量示范数据来训练策略,这给高效适应新环境带来了巨大挑战。最后,在复杂的长周期任务中确保稳健性仍然具有挑战性,因为误差会累积,尤其是在处理可变形物体等需要灵巧技能的任务中。
1.2 相关技术
通用操作策略
构建能按照指令与真实世界高效交互的通用操作策略,一直是机器人学研究中的老大难问题,先前工作 [33,53,61,74] 建议先从大规模数据中学习通用表征,再用于后续策略学习,以在复杂任务中获得更鲁棒的机器人行为。
最近在视觉-语言-动作(VLA)模型上取得的进展,通过多种手段加强策略的泛化能力与操作能力。一大波研究 [9,18,29,37,41,49,55,58,60,68,70] 使用“跨载体数据”训练策略——即收集自不同机器人平台的轨迹数据。
除了真实轨迹数据,还有研究 [9,11,29] 借助预训练的视觉-语言模型来构建机器人策略,展现了对未见场景的强大泛化能力。另一种提升泛化的方法是:在海量网络视频上进行未来帧预测 [8,13,20,28,40,73],或从无动作标签的视频中学习潜在动作(latent actions)[7,12,77]。
本工作提出了 GR-3——一个在机器人轨迹和视觉-语言数据上联合训练的 VLA 模型,并可通过少量人类演示实现高效微调。
通过大量实验,作者证明 GR-3 能:1)严格跟随指令,并对新物体、新环境和新指令实现泛化;2)借助少样本人类轨迹高效适应新场景;3)以高鲁棒性执行长序列与灵巧任务。
机器人操作的多模态联合训练
真实机器人轨迹采集成本高、耗时久。因此,要扩展策略训练规模,多元化数据源就尤为关键。
一个常用思路是:先用预训练视觉编码器 [33,50,53,61,74] 或视觉-语言模型 [7,9,11,29] 初始化策略网络。在这一框架基础上,自然会在训练中引入除机器人轨迹外的多模态数据 [11,29,58,63,76]。
例如 GATO [63] 构建了一个通用智能体,能执行图像描述、用真实机器人堆积积木等多种任务。它将不同模态的数据转为统一的 token 序列,并用大型 Transformer 进行下一个 token 预测。
RT-2 [11] 表明:同时用机器人轨迹和视觉-语言数据微调大型视觉-语言模型,可显著增强泛化能力。通过对异构数据联合训练,π0.5 在多环境、多物体上展现出卓越的泛化性能,可有效部署于真实未见场景。
我有一个疑问,机器人轨迹可以转成lerobot格式去微调模型,视觉语言数据怎么使用呢?
本工作中,GR-3 也采用了类似共训练策略——从多源构建了精心设计的网络级视觉-语言数据集,并在诸多视觉-语言任务上进行了大规模联合训练。通过大规模联合训练,GR-3 在零样本泛化方面表现强劲——无论是新物体,还是需要抽象概念推理的复杂指令。
利用人类数据进行策略训练
为提升数据效率,将人类数据引入策略训练已成为机器人研究的热门思路。一系列研究 [1,5,51,72] 从人类视频中提取多种表征,用于丰富策略学习。Wu 等 [73] 与 Cheang 等 [13] 建议利用大规模人类视频 [16,23,24] 进行生成式视频预训练。
近期,随着手部跟踪和 VR 设备的发展,Qiu 等 [59] 与 Kareer 等 [34] 发现在少量机器人数据配合下,用含手部轨迹的人类视频联合训练,可提升策略在机器人平台上的表现。
在本报告中,我们沿袭这一研究思路,证明了 GR-3 可通过少样本人类轨迹学习,有效适应新场景。
同样的疑问,这种人类视频怎么使用呢?
1.3 GR-3概述
在本报告中,字节汇报了在构建通用机器人策略方面的最新进展,即开发了 GR-3。
GR-3 是一个大规模的视觉 - 语言 - 动作(VLA)模型,如图1所示。
- 它对新物体、新环境以及含抽象概念的新指令展现出较好的泛化能力。
- 此外,GR-3 支持少量人类轨迹数据的高效微调,可快速且经济地适应新任务。
- GR-3 在处理长周期和灵巧性任务(包括需要双手操作和底盘移动的任务)上也展现出稳健且可靠的性能。
这些能力源自—种多样的训练方法,具体包括:利用大规模的视觉 - 语言数据联合训练、征集了用户授权的基于 VR 设备的人类轨迹数据进行高效微调,以及基于机器人轨迹数据进行有效地模仿学习。此外,他们还推出了一款双臂移动机器人 ByteMini。ByteMini 兼具灵巧性和可靠性,集成了 GR-3 后,能完成各式各样的复杂任务。
GR-3 的输入包括自然语言指令、环境观测和机器人状态;它输出一段动作序列,用于端到端地控制双臂移动机器人。具体来说,GR-3 构建在一个预训练视觉-语言模型基础上,并通过流匹配(flow-matching)方法预测动作。
作者对模型架构进行了细致研究,并引入了一系列精心挑选的设计方案,这些对执行指令能力和长周期任务性能至关重要。为了提升泛化能力,在机器人轨迹数据和涵盖多种视觉-语言任务的大规模数据上对 GR-3 进行联合训练。
这种训练方法使 GR-3 不但能处理新类别的物体,还能理解与大小、空间关系和常识相关的抽象概念(见图 2),而这些在机器人轨迹数据中并未出现过。

此外,作者展示了 GR-3 能通过 VR 设备收集的少量人类示教数据进行高效微调,从而快速且低成本地适应新环境。
通过在三个具有挑战性的真实场景任务中进行了大量实验:
- 通用的抓取与放置
- 长周期的桌面收拾(table bussing)
- 灵巧的布料操作。
他们证明 GR-3 在众多具有挑战性的任务上都超越了最先进的基准方法 π0。它展现出将新类别物体泛化及理解复杂语义的强大能力。此外,它仅需每个新物体 10 条人类示教轨迹就能高效适应。
最后,GR-3 在长周期和灵巧任务中表现出显著稳健,在桌面收拾和布料操作等挑战性任务中取得了高平均任务进度。
1.4 GR-3模型
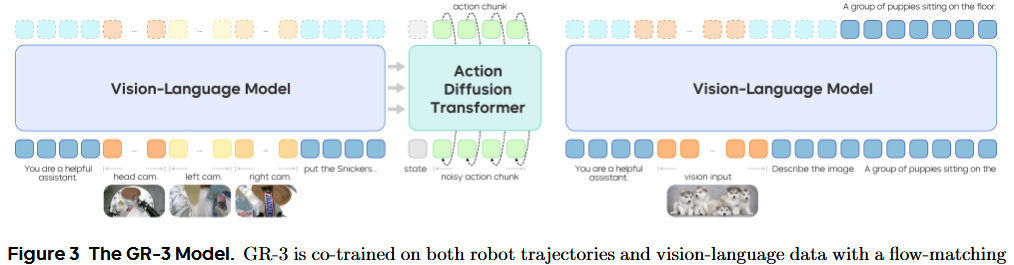
GR-3 是一个端到端的视觉-语言-动作(VLA)模型 πθπ_θπθ,它通过生成一段长度为 k 的动作序列 aₜ:ₜ₊ₖ 来控制带轮子的双手机器人,该生成过程依赖于输入的语言指令 l、时刻 t 的环境观测 oₜ 和机器人状态 sₜ;即 aₜ = πₜₕₑₜₐ(l, oₜ, sₜ)。
GR-3 采用了“混合变换器”(mixture-of-transformers)架构。它先用预训练视觉-语言模型(VLM)Qwen2.5‑VL‑3B‑Instruct处理来自多路相机的观测图像和语言指令,然后用**动作扩散变换器(DiT)**来预测动作序列。具体来说,GR-3 在动作预测时采用了流匹配(flow matching)方法。
流匹配的预测依赖于当前的机器人状态 sₜ 以及视觉-语言主干网络(backbone)输出的键值缓存(KV cache)。长度为 k 的动作序列 aₜ 会被分成 k 个 token,再与机器人状态的 token 拼接,形成动作 DiT 的输入序列。作者在动作 DiT 中使用因果注意力掩码(causal attention mask),以建模动作序列内部的时间依赖关系。
因果注意力掩码:确保模型预测第 i 步动作时,只能“看到”前面 i‑1 步,而不会窃取未来信息,就像写小说只能先写前面再写后面。
为了保证推理速度,动作 DiT 的层数只有视觉-语言主干网络的一半,且只使用后半部分 VLM 层输出的 KV cache。整体来说,GR-3 拥有大约 40 亿(4 B)个参数。
在早期尝试中,发现训练过程常出现不稳定现象。受到 QK norm 方法【26】的启发,在 DiT 模块中的注意力层和前馈网络(FFN)内部的线性层后,额外使用了 RMSNorm 归一化【78】。
RMSNorm:一种比传统 LayerNorm 更简单高效的归一化技巧,有助于平稳梯度,提升训练稳定度。
这一设计显著提升了整个训练过程的稳定性。此外,作者发现在下游任务实验中,这一改进也大幅增强了模型对语言指令的执行能力(详见第 4 节)。
2. 训练流程
作者在多种数据源上训练 GR-3 模型,包括用于模仿学习的机器人轨迹数据、用于联合训练的海量视觉-语言数据,以及用于少样本泛化的人类轨迹数据。
这种训练方案使 GR-3 能
- 泛化到新物体、新环境和新指令
- 以低成本高效地适应未见场景
- 稳健地执行长周期和灵巧任务
2.1 用机器人轨迹数据进行模仿学习
通过最大化策略在专家示范集 D 上的对数似然来训练 GR-3 的模仿学习目标:

具体地,我们在训练中用流匹配损失来监督动作预测:

其中 τ∼U(0,1)表示流匹配的时间步,atτ是加噪动作,其中 ϵ∼N(0,I)是随机噪声,u=at−ϵ是流预测的真实标签。
为了加快训练,在一次 VLM 主干网络前向过程中,对多个随机抽样的流匹配时间步计算损失。推理时,动作序列以随机噪声初始化,然后用欧拉方法从 τ=0积分到 τ=1。实验中 Δτ=0.2。
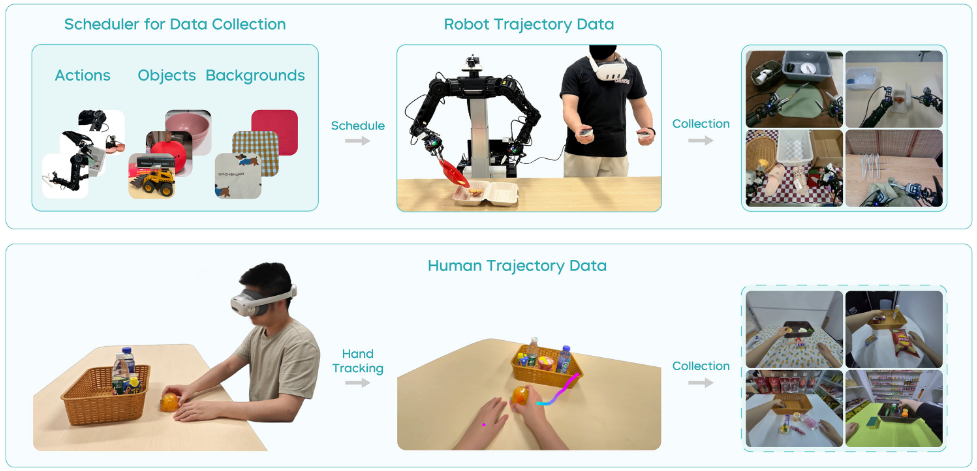
通过远程操控采集真实机器人轨迹。为了让采集更可控并最大化数据多样性,他们开发了一个数据采集调度程序(见图 4),向操作者提示 1)要执行的动作,2)物体组合,3)背景设置。
在每次轨迹采集开始时,系统会生成新的环境配置,操作者据此布置场景。该调度程序的实现能有效管理数据分布并彻底随机化采集数据,大大提升了数据集的丰富性和多样性。此外,采集后还需进行质量检查,过滤掉无效或低质量的数据,以优化数据集。
以往研究指出,策略可能利用来自多视角的“虚假关联”进行动作预测,而非真正关注语言指令。为了解决这一问题,引入“任务状态”作为额外动作维度,用于辅助监督。任务状态有三种:Ongoing(进行中,0),Terminated(已完成,1),Invalid(无效,−1)。
训练时,会随机用无效指令替换真实指令,并只让模型预测 Invalid 状态,而不监督其他动作维度。这一设计迫使动作 DiT 必须关注语言指令并判断任务状态,大幅提升了模型执行语言指令的能力(详见第 5.2 节)。
2.2 视觉-语言数据上进行联合训练
为了赋予 GR-3 对分布外(OOD)指令的泛化能力,在机器人轨迹数据和视觉-语言数据上对其进行联合训练(见图 3)。机器人轨迹数据用流匹配目标训练 VLM 主干网络和动作 DiT。
视觉-语言数据仅用下一个 token 预测目标训练 VLM 主干网络。为了简单起见,在每个小批次中以等比例动态混合视觉-语言数据和机器人轨迹。因此,联合训练的目标就是下一个 token 预测损失与流匹配损失之和。
通过与视觉-语言数据的联合训练,GR-3 能够以零样本方式有效泛化到未见物体,并理解复杂概念的新语义。
作者从多种来源整理出一个大型视觉-语言数据集。该数据集涵盖了多种任务(见图 4),包括图像描述、视觉问答、图像定位和交叉定位描述。
他们还开发了过滤和重新标注流程,以提高数据集质量,确保联合训练效果。联合训练不仅帮助 GR-3 保留预训练 VLM 的强大视觉-语言能力,还使动作 DiT 在动作预测中利用这些能力,从而有效提升下游操作任务的泛化能力。
2.3 用人类轨迹数据进行少样本泛化
GR-3 是一款多功能的 VLA 模型,可以轻松微调以适应新场景,然而采集真实机器人轨迹既耗时又昂贵。VR 设备与手部追踪技术的最新进展带来了直接从人类轨迹数据学习动作的良好机会。本报告中,将 GR-3 高效微调能力扩展到从极少人类轨迹中进行少样本学习的挑战场景。
具体来说,在新场景下使用 PICO 4 Ultra Enterprise 收集少量人类轨迹数据。借助 VR 设备,人类轨迹可达每小时约 450 条,远超远程操控机器人每小时 250 条的速度。这种高效率促成了对新环境的快速且低成本适应。
具体来说,采集到的人类轨迹数据包括第一人称视角视频和手部轨迹。沿用机器人轨迹的标注流程,为人类轨迹数据添加语言标签。在完成第一阶段的视觉-语言数据和机器人轨迹训练后,加入人类轨迹数据,对三种数据同时进行联合训练。
与机器人轨迹不同,人类轨迹仅包含第一人称视角和手部轨迹,不含手臂关节状态或夹爪状态。因此,需要为缺失的腕部视角填充空白图像,并仅用手部轨迹来训练模型处理人类轨迹数据。
3. 硬件与系统
3.1 ByteMini Robot
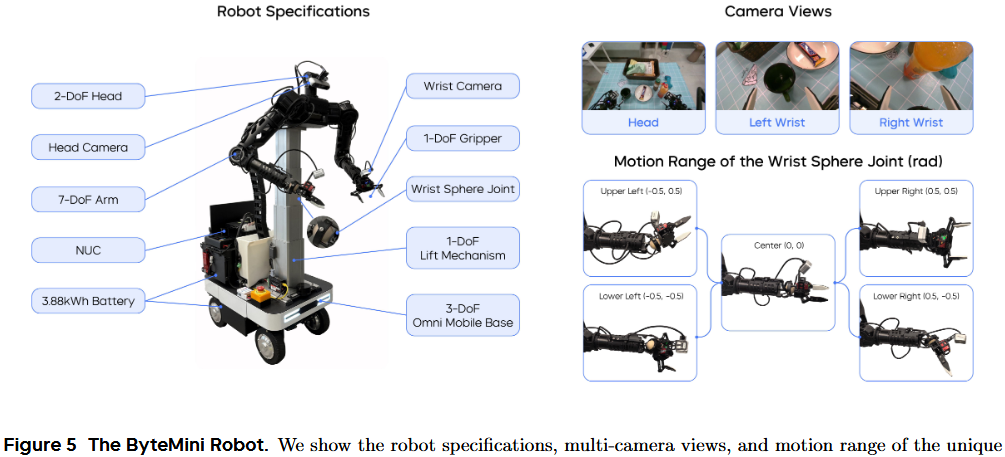
ByteMini 机器人(见图 5)被用于数据采集和策略执行。这款拥有 22 个自由度的双手机动机器人,围绕三个核心目标设计:灵活操作、高可靠性和易用性。这只拥有 7 个自由度的无偏置机械臂,采用了独特的球形腕关节设计,实现了类似人手的灵巧度。
紧凑的球形腕设计(见图 5)克服了传统 SRS 结构机械臂腕部体积过大、在狭小空间难以灵活操作的问题。机械臂肘部特别设计,可向内大幅度收拢至 2.53 弧度,使两臂能在机器人胸前区域完成精细操作。在数据采集和策略执行时,繁重任务要求 ByteMini 必须具备极高的稳定性和一致性。
采用带升降机构的全向移动平台,实现了平面移动和垂直高度调整的稳定控制。为进一步提升可靠性并确保运动一致性,臂部执行器采用了准直接驱动(QDD)原理设计,该原理以稳定和高响应性著称。
为提高易用性,在机器人上集成了便携式屏幕和一台 NUC(小型电脑),并配备双锂电池,可在多种场景下持续工作超过 10 小时。此外,ByteMini 配备了无线紧急停止装置(E-stop),可在紧急情况下迅速断电停机。在机器人头部和两只手腕上安装了 RGBD 相机。腕部相机可进行近距离观测,以辅助精细操作。
3.2 系统与控制
Whole-body compliance control
基于全身顺应性控制框架,将所有自由度作为一个整体结构,将任意远程操控的人体动作映射到机器人可行的运动上。在实时最优控制问题中,同时考虑可操纵性优化、奇异位置避免和关节物理极限,以最大化机器人灵巧度。
这样可以在大工作空间中生成流畅连续的动作,用于各种长周期操作任务,并产出高质量的专家级轨迹供策略训练。顺应性力控制器使机器人能进行高动态动作并与环境发生物理交互,提升安全性和数据采集效率。
全身远程操控
采集时通过 Meta VR Quest 实现全身动作映射,直观易用地将人类动作直接传递给机器人末端执行器。操作者可同时控制机械臂、升降机构、夹爪和底盘移动,使在真实环境下对复杂长周期任务的数据采集更加无缝顺畅。
策略执行的轨迹优化
用预测得到的动作序列来控制机器人的 19 个自由度(不含升降机构和头部的 3 个自由度)进行策略执行。引入纯追踪算法和轨迹优化方法,以提升 GR-3 在策略执行时生成轨迹的稳定性和平滑度。实时参数化优化可最小化加速度突变(jerk),并确保在路径点之间及各条轨迹间的平滑衔接。
4. 实验
在真实环境中进行了大量实验,以全面评估 GR-3 的性能。在这些实验中,希望回答以下四个问题:
- GR-3 是否能严格执行指令,包括训练时没见过的新指令?
- GR-3 能否泛化到分布外场景,比如新物体、新环境、新指令?
- GR-3 是否能通过少量人类轨迹学习并迁移到机器人身体?
- GR-3 是否能学到稳健策略,胜任长周期且灵巧的任务?
作者设计了三项任务:可泛化的抓取放置、长周期餐桌整理,以及灵巧的布料挂放。欢迎访问项目主页观看演示视频。作者将方法与最先进基线 π₀ 进行了对比。他们按照官方 GitHub 中的说明,对 π₀ 基于其在大规模机器人数据上预训练的基础模型,分别在三项任务上进行微调。
4.1 可泛化的 Pick-and-Place
为了评估 GR-3 在分布外场景下的泛化能力,我们在一个以泛化为目标的抓取放置任务上进行测试。作者共采集了 3.5 万条机器人轨迹,涵盖 101 种物体,总时长约 69 小时。为轨迹标注了“将 A 放入 B”指令,其中 A 是物体类别,B 是容器。
对于基线 π₀,仅用机器人轨迹数据微调;而 GR-3 则用机器人轨迹和视觉-语言数据一起联合训练。训练时,对轨迹图像进行光度增强,以提升对环境变化的鲁棒性。还对比了不做联合训练的 GR-3 w/o Co-Training,仅用机器人轨迹训练。该消融研究可评估视觉-语言联合训练的效果及其对性能的具体贡献。
实验设置
在四种设置下评估:1) 基础场景、2) 未见环境、3) 未见指令、4) 未见物体
- 在基础场景,他们在训练中见过的环境里测试,用 54 种训练时见过的物体(见图 6(a))来检验基本执行指令能力。

- 在未见环境,用相同的 54 种物体,在四个训练时未见过的现实环境中测试:收银台、会议室、办公桌和休息室(见图 6©)。物体布局保持与基础场景一致。

- 在未见指令中,给模型下达需复杂概念推理的指令,如“把左边的可乐放入纸箱”“把有触手的动物放入纸箱”。
- 在未见物体设置下,用 45 种在轨迹数据中没见过的物体测试(见图 6(b))。

作者用“执行指令率(IF rate)”和“成功率”来评估模型,分别衡量模型按指令行动的能力和完成任务的整体表现。
对于 IF 率,只要机器人正确靠近指令指定的物体,该次试验即判成功。对于成功率,只有当机器人将目标物体放入容器后,才算成功。对于这两项指标,得分越高表示能力越强。
基本指令跟随
在基础和未见环境设置中,将 54 种已见物体分为九个小批次,每个批次六个物体。在每一次试验中,根据给定指令,要求模型从 6 个对象中挑选出一个。为了保证不同模型结果的可比性,采用预先拍摄的掩码来固定物体位置,确保每个小批次的布局在评测中尽可能一致。
如图 7(a) 所示,GR-3 在“基础环境”和“未见环境”中,无论是 IF(Instruction Following)率还是成功率,都超越了 π0。
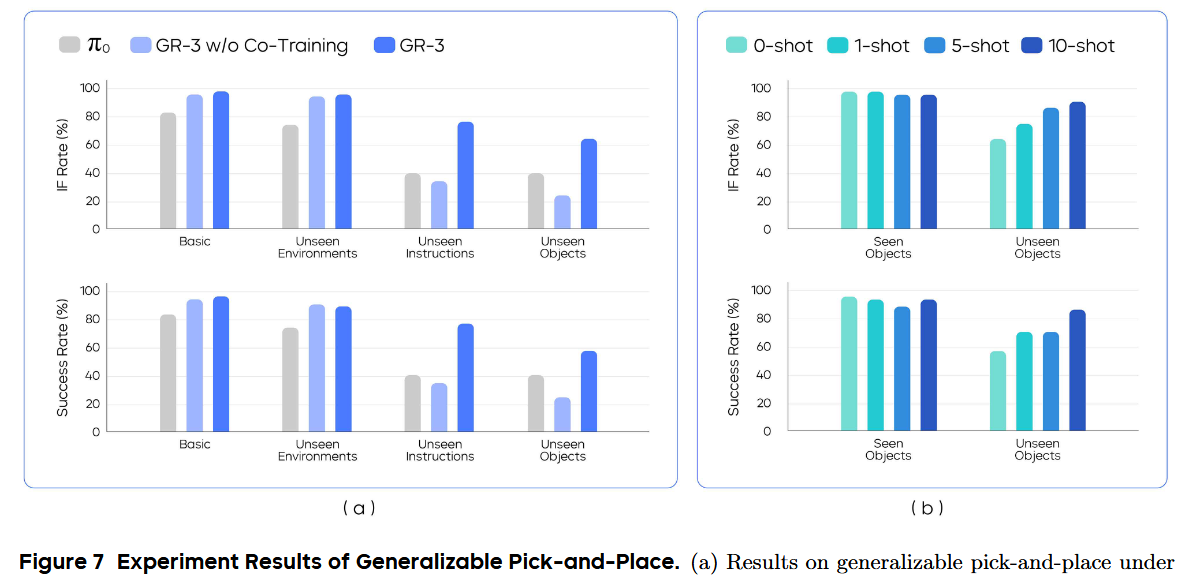
在“基础环境”和“未见环境”之间仅有小幅性能下降,凸显了 GR-3 对环境变化的鲁棒性。此外,发现有无“联合训练”(Co-Training)时,GR-3 在这两种设置下表现差异不大,说明对于已见对象,联合训练并不会影响其性能。
泛化指令跟随
在“未见指令”(Unseen Instructions)中,测试模型理解抽象概念的能力——比如大小、空间关系和常识。示例指令包括“把可乐放到雪碧旁边再放进箱子”、“把最大的物体放进箱子”,以及“把第 9 个海洋动物放进箱子”。这些指令在机器人轨迹数据中未曾出现,要求模型推理其中复杂的语义。
在“未见对象”(Unseen Objects)中,将 45 种新对象分成九个小批次,每批次 5 个,对应每次试验要从 5 个对象中选一个。这个设置尤为具有挑战性,因为在这 45 个对象中,有超过 70% 属于机器人轨迹数据里未曾出现的类别。如图 7(a) 所示,GR-3 在两种设置中都大幅超越 π0,凸显了其出色的泛化能力。
它将“未见指令”的成功率从 40% 提升到 77.1%,并将“未见对象”的成功率从 40% 提升到 57.8%。在这两种设置下,GR-3 也明显优于未做联合训练的版本,说明引入视觉-语言(VL)数据的联合训练,有助于增强泛化能力。
这种 VLA 模型能够将大规模视觉-语言数据中的丰富知识有效迁移到策略学习中,并在新的场景下实现强大的零样本(zero-shot)能力。
还发现,仅用机器人轨迹训练的 GR-3,表现不如 π0 基线。π0 之所以更强,是因为它进行了大规模的跨载体(cross-embodiment)预训练。
基于人类轨迹的少样本泛化
使用 VR 设备收集的人类轨迹,评估模型的少样本泛化能力。这很有挑战性,原因有两点:1)模型要从跨载体数据中学习;2)数据非常稀缺。具体而言,在“未见对象”设置中,为45个未见物体最多收集了 10 条人类轨迹(见图 6(b))。这 450 条人类轨迹总时长约 30 分钟。
在已有用机器人轨迹和 VL 数据训练出的检查点基础上,进行增量训练。再联合训练 20,000 步,将人类轨迹与原有机器人轨迹和 VL 数据一起融合训练。
在已见和未见对象上,分别测试了 1、5、10 条示例(1-shot、5-shot、10-shot)下的表现(见图 7(b))。相比基础模型的零样本表现,通过增加人类轨迹数据,持续提升 IF 率和成功率;仅用每个对象 10 条人类轨迹,就能将成功率从 57.8% 提升到 86.7%。
另外,可以发现已见对象的表现并未明显下降,说明该少样本微调策略既高效又经济,能将预训练的 VLA 模型快速适配到下游新场景。
4.2 长时序桌面清理
在“清理餐桌”任务上进行实验,以评估 GR-3 在处理长时序 manipulation 时的鲁棒性(见图 8)。在该任务中,机器人需要收拾桌面上凌乱的餐具、食物、外带餐盒和塑料清餐箱。

为完成此任务,机器人需:1)将食物装入外带餐盒;2)将所有餐具放入清餐箱;3)将所有垃圾投入垃圾桶。由于工作区较大,机器人要从外带餐盒处移动底盘到清餐箱处,才能完成整个任务(见图 8(a))。
在 Flat 设置(图a)和“指令执行”(IF,图b)设置下对模型进行评估。
Flat 设置
在 Flat 设置中,给机器人一个总任务指令“清理餐桌”,让它在一次流程中自主完成全部子任务(见图 8(a))。这种设置帮助我们评估模型处理长序列任务的鲁棒性。
以“平均任务进度”作为评估指标,即已完成子任务数与总子任务数的比值。值为 1.0 表示完全成功,其他小于 1 的值表示部分成功。在五组不同的物体组合上进行了评测。
IF 设置
在 IF 设置中,进一步评估模型执行指定指令的能力。连续给出多个子任务描述,例如“把纸杯放进垃圾桶”,来指导机器人清理餐桌。机器人从“home”开始执行每条子任务。以“平均子任务成功率”作为评估指标。
IF 设置共包含六种指令场景(见图 8(b))
- 基础:物体布局与训练时非常相似。
- 多物体:在场景中加入某些物体类别的多份实体,并下达“把所有该类别物体放入清餐箱或垃圾桶”的指令。
- 多目标:在场景中加入一个织物篮,并指令机器人将餐具放入织物篮或清餐箱。
- 多实例&多目标:把“多实例”和“多目标”结合,指令机器人将某类别的所有实例送往两者之一。
- 新目标:让机器人把物体放到训练时未曾一起出现过的目的地,例如“把叉子放进垃圾桶”。
- 无效任务:实际应用中,机器人需识别并拒绝不合理指令。例如桌上没蓝碗,却指令“把蓝碗放进塑料箱”就应视为无效。在此情况下,希望策略能拒绝执行不合理的任务。在此设置中,下达与观测不符的任务。只有当模型在 10 秒内不对任何物体动手时,才算该试验成功。
开始实验
为本任务,共收集了约 101 小时的机器人轨迹数据。在基线方法中,在这些轨迹数据上微调 π0。
我录的一条夹3个橘子的回合只有20-50s,合着需要10000条左右才能有人家的数据量。但是他这一条肯定没有我这么短
对于 GR-3,同时使用机器人轨迹和视觉-语言(VL)数据进行联合训练。还做了两种消融实验:GR-3 w/o Norm(去掉 RMSNorm)和 GR-3 w/o Task Status(去掉任务状态输入,简称 TS)。
GR-3 w/o Norm 去掉了 DiT 模块中 attention 和 FFN 里的 RMSNorm。
GR-3 w/o TS 在训练时不使用任务状态输入。
对所有方法,分别为 Flat 和 IF 设置训练两个独立模型。在 Flat 设置下的训练中,随机采样“总任务”或“子任务”作语言指令。在 IF 版训练中,仅使用子任务作为指令。
结果
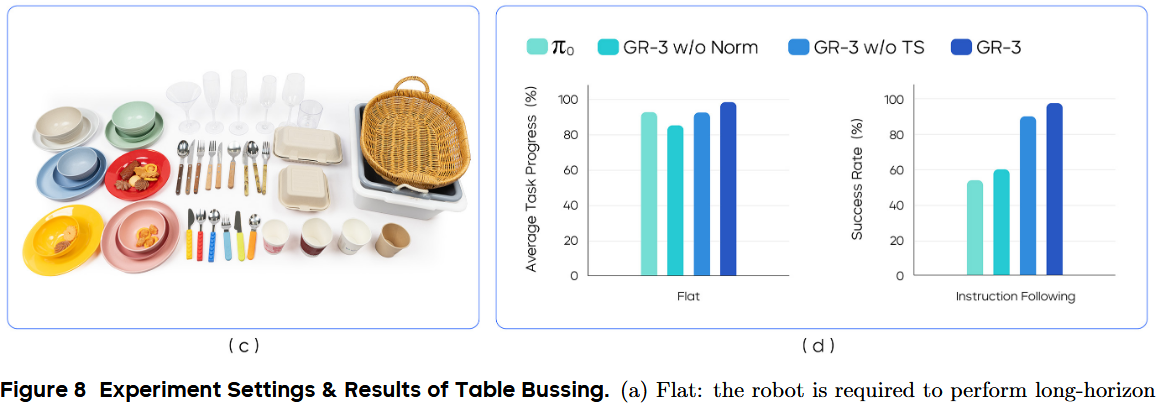
如图 8(d) 所示,GR-3 在两种设置中都优于 π0,尤以 IF 设置最明显(成功率 53.8% vs 97.5%)。虽然 π0 能完成长序列清餐任务,但在指令执行上,特别是分布外场景中,表现较差。
它分不清叉子和勺子。在新目标场景中,它会把物体放到与该物体在训练时出现过的容器里,而不是按指令行事。而 GR-3 在六种测试中都严格执行指令,对多实例和多目标场景泛化良好,并能在无效任务中拒绝操作。
去掉 RMSNorm 会降低两种设置下的性能,尤以 IF 场景影响最大。GR-3 w/o Norm 无法很好地执行指令,特别是对新目标无法泛化。缺少任务状态输入时,IF 能力也会下降,凸显了任务状态对 VLA 模型执行指令的辅助作用。
4.3 灵巧操作-叠衣服
在此实验中,评估 GR-3 在对可变形物体进行灵巧操作(dexterous manipulation)方面的表现。具体地,让模型使用衣架将衣物挂到晾衣架上(见图 2)。在此任务中,机器人需:1)抓起衣架;2)将衣物挂到衣架上;3)将挂好衣服的衣架挂到晾衣架上。
在最后一步,机器人需将底盘从桌边转向晾衣架所在位置,以便挂衣服。为本任务,我们共收集了约 116 小时的机器人轨迹数据。用这些数据微调 π0;而对 GR-3,则同时用机器人轨迹和视觉-语言数据进行联合训练。在三种评测设置下进行测试:Basic(基础)、Position(位置变化)和 Unseen Instances(未见实例)。
实验设置
在 Basic 设置中,测试六件训练阶段见过的衣物,且其摆放方式与训练时相似。在 Position 设置中,我们如图 9(b) 所示对衣物进行旋转和揉皱处理。

Position 设置评估模型应对复杂衣物布局的鲁棒性。在 Unseen Instances 设置中,测试模型对训练中未见过衣物的泛化能力。具体地,我们在四件未曾见过的衣物上进行评测(见图 9(a))。训练数据中所有衣物都是长袖,但测试集里有两件短袖。
以“平均任务进度”作为评估指标,完整挂好衣服(最终里程碑)对应 1.0。整个过程分为四个关键节点:1)抓起衣架;2)将右肩挂到衣架上;3)将左肩挂到衣架上;4)将衣架挂到晾衣架上(见图 10(a))。每个里程碑都会对整体进度贡献一个分数片段。
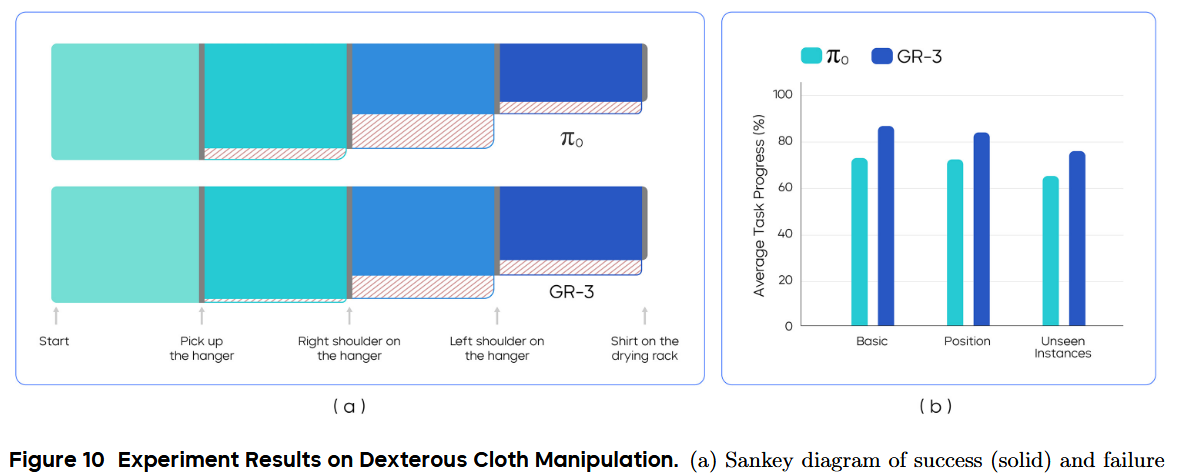
结果
结果见图 10。GR-3 在三种设置下均优于 π0。它在 Basic 和 Position 中的平均任务进度分别达到 86.7% 和 83.9%,展现了对复杂灵巧操作的熟练度以及对布局变化的鲁棒性。此外,GR-3 能泛化到拥有新图案和不同袖长的未见衣物,平均任务进度达 75.8%。
为深入分析执行过程,在图 10(a) 中绘制了 Basic 设置下四个里程碑成功与失败的图(Sankey diagram)。对两种模型来说,最具挑战的是在挂好右肩后再挂左肩这一步。这是因为机器人在手持衣架的同时,需要将左领部拉出——它常常折叠在衣架后面——才能抓取。
另一个失败模式是,在挂左肩过程中衣架从爪手中滑落,导致最后一步失败。
5. 结论与讨论
5.1 限制与未来工作
尽管在多项高难度任务中表现强劲,GR-3 仍存在局限。虽然展现了出色的泛化能力,但在执行涉及新概念和新物体的未见指令时会出错,并且在抓取未见形状的物体时表现不佳。
他们计划扩大模型规模和训练数据,以持续提升其处理新场景的能力。此外,与所有模仿学习方法类似,GR-3 在执行过程中可能陷入分布外状态,无法自我恢复导致失败。
未来,将拟引入强化学习(RL),以增强在复杂与灵巧任务上的鲁棒性,并突破模仿学习的固有局限。
5.2 结论
在本报告中,提出了 GR-3——一个能输出动作指令以控制双臂移动机器人的强力视觉-语言-动作(VLA)模型。seed深入研究模型架构,并制定了结合大规模视觉-语言数据联合训练、高效少样本人类轨迹学习以及有效机器人轨迹模仿学习的全方位训练方案。
在三项高难度真实任务上的大量实验表明,GR-3 能:理解带抽象概念的复杂指令;对新物体和新环境有效泛化;从极少人类演示中高效学习;以极高的鲁棒性和可靠性执行长序列与灵巧任务。期望 GR-3 能成为构建通用机器人、在现实世界中为人类完成多样任务的基石。


)










)


 详细解释,使用 PyTorch代码示例说明)


