1、负载均衡Load Balance(LB)
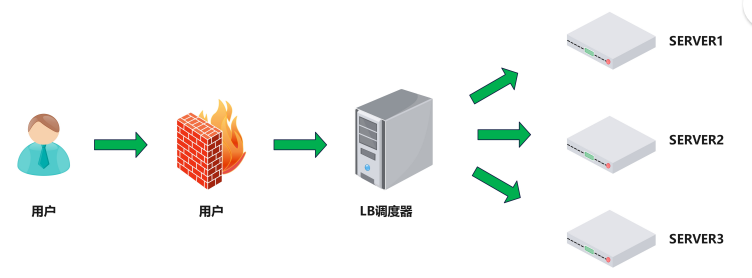
概念
负载均衡:是一种服务或基于硬件设备等实现的高可用反向代理技术,负载均衡将特定的业务(web服务、网络流量等)分担给指定的一个或多个后端特定的服务器或设备,从而提高了 公司业务的并发处理能力、保证了业务的高可用性、方便了业务后期的水平动态扩展
阿里云SLB介绍:SLB技术原理浅析-阿里云开发者社区
优势
-
Web服务器的动态水平扩展-->对用户无感知
-
增加业务并发访问及处理能力-->解决单服务器瓶颈问题
-
节约公网IP地址-->降低IT支出成本
-
隐藏内部服务器IP-->提高内部服务器安全性
-
配置简单-->固定格式的配置文件
-
功能丰富-->支持四层和七层,支持动态下线主机
-
性能较强-->并发数万甚至数十万
类型:F5、Netscaler(思杰)、Array(华耀)、AD-100(深信服)
四层负载均衡(基于TCP/IP协议栈的传输层)

1.通过ip+port决定负载均衡的去向。
2.对流量请求进行NAT处理,转发至后台服务器。
3.记录tcp、udp流量分别是由哪台服务器处理,后续该请求连接的流量都通过该服务器处理。
4.支持四层的软件:
lvs:重量级四层负载均衡器。
Nginx:轻量级四层负载均衡器,可缓存。(nginx四层是通过upstream模块)
Haproxy:模拟四层转发。
七层负载均衡(应用层)
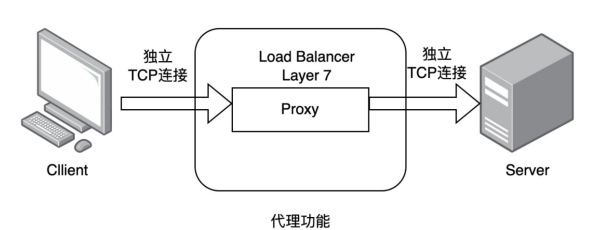
1.通过虚拟ur|或主机ip进行流量识别,根据应用层信息进行解析,决定是否需要进行负载均衡。
2.代理后台服务器与客户端建立连接,如nginx可代理前后端,与前端客户端tcp连接,与后端服务器建立
tcp连接,
3.支持7层代理的软件:
Nginx:基于http协议(nginx七层是通过proxy_pass)
Haproxy:七层代理,会话保持、标记、路径转移等。
所谓的四到七层负载均衡,就是在对后台的服务器进行负载均衡时,依据四层的信息或七层的信息来决定怎么样转发流量
四层的负载均衡,就是通过发布三层的IP地址(VIP),然后加四层的端口号,来决定哪些流量需要做负载均衡,对需要处理的流量进行NAT处理,转发至后台服务器,并记录下这个TCP或者UDP的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理
七层的负载均衡,就是在四层的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个Web服务器的负载均衡,除了根据VIP加80端口辨别是否需要处理的流量,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。
区别:
1.分层位置:四层负载均衡在传输层及以下,七层负载均衡在应用层及以下
2.性能 :四层负载均衡架构无需解析报文消息内容,在网络吞吐量与处理能力上较高:七层可支持解析应用
层报文消息内容,识别URL、Cookie、HTTP header等信息。、
3.原理 :四层负载均衡是基于ip+port;七层是基于虚拟的URL或主机IP等。
4.功能类比:四层负载均衡类似于路由器;七层类似于代理服务器。
5.安全性:四层负载均衡无法识别DDoS攻击;七层可防御SYN Cookie/Flood攻击
2、haproxy
haproxy的安装和服务信息
实验环境
| 功能 | IP |
| 客户端 | ens160:172.25.254.104 |
| haproxy | ens160:172.25.254.100 |
| RS1 | ens160:172.25.254.101 |
| RS2 | ens160:172.25.254.102 |
RS1和RS2的配置(都配成nat模式,如果是仅主机就要都是仅主机,要实现调度,需要都在一个网段中)
下载nginx
dnf install nginx -y
关闭防火墙!!
# 停止防火墙服务
systemctl stop firewalld# 禁止防火墙开机自启
systemctl disable firewalld# 验证状态(确保显示 inactive)
systemctl status firewalld将你所想呈现的命令导入nginx的默认发布目录(为了在验证时直观的看见,若成功就会显示自己导入的命令)
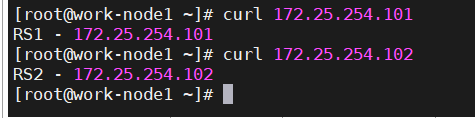
#在RS1上
echo RS1 - 172.25.254.101 > /usr/share/nginx/html/index.html#在RS2上
echo RS2 - 172.25.254.102 > /usr/share/nginx/html/index.html开启nginx
systemctl enable --now nginx在haproxy上进行检测(haproxy也要记得一个事情——关火墙!)
haproxy上的配置
关火墙
安装haproxy并启动
#安装
dnf install haproxy -y#启动
systemctl start haproxy#查看版本
[root@work-node1 ~]# haproxy -v
HAProxy version 2.4.22-f8e3218 2023/02/14 - https://haproxy.org/
Status: long-term supported branch - will stop receiving fixes around Q2 2026.
Known bugs: http://www.haproxy.org/bugs/bugs-2.4.22.html
Running on: Linux 5.14.0-427.13.1.el9_4.x86_64 #1 SMP PREEMPT_DYNAMIC Wed Apr 10 10:29:16 EDT 2024 x86_64haproxy软件基本信息
主配置目录:/etc/haproxy/
主配置文件:/etc/haproxy/haproxy.cfg
子配置目录:/etc/haproxy/conf.d/
启动文件:/lib/systemd/system/haproxy.service(初始化脚本)
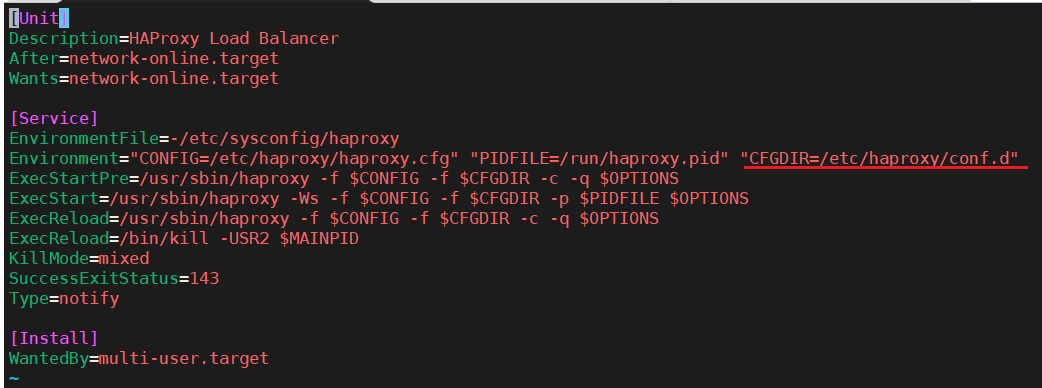
在启动文件里面发现将配置写在子配置目录是生效的且名字不限
基本配置信息
global:全局配置段
进程及安全配置相关的参数
性能调整相关参数
Debug参数
proxies:代理配置段
defaults:为frontend, backend, listen提供默认配置
frontend:前端,相当于nginx中的server {}
backend:后端,相当于nginx中的upstream {}
listen:同时拥有前端和后端配置,配置简单,生产推荐使用
注:最终代理中的参数会把默认中的参数覆盖,默认中的参数会把全局中的参数覆盖
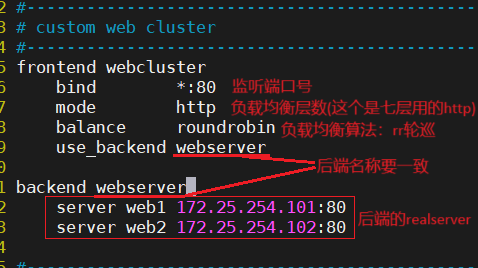
简单负载均衡示例
vim /etc/haproxy/haproxy.cfg注释掉原来的示例 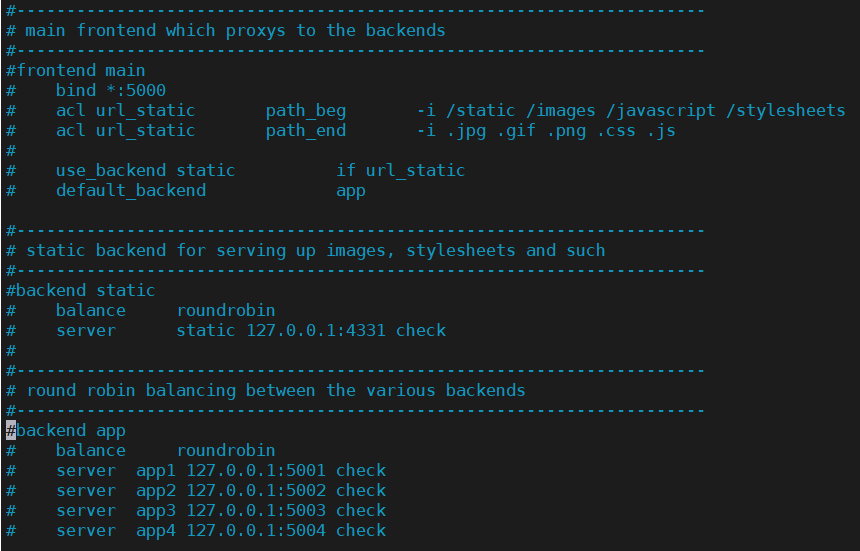
1、frontend(前端)配合backend(后端)
#重启
[root@work-node1 ~]# systemctl restart haproxy.service#检查haproxy是否开启80端口
[root@work-node1 ~]# netstat -antlupe | grep haproxy
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 0 138625 70945/haproxy测试

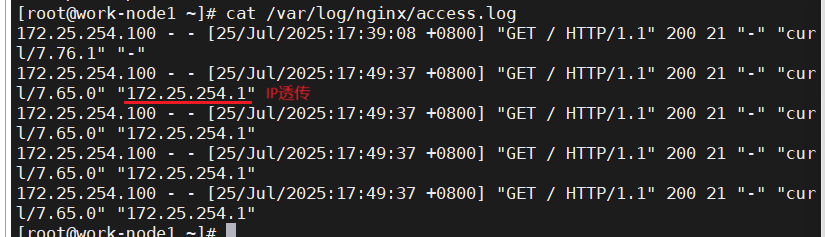
在RealServer中可发现访问的ip是haproxy的ip地址,通过ip透传知道是172.25.254.1要求172.25.254.100访问RealServer
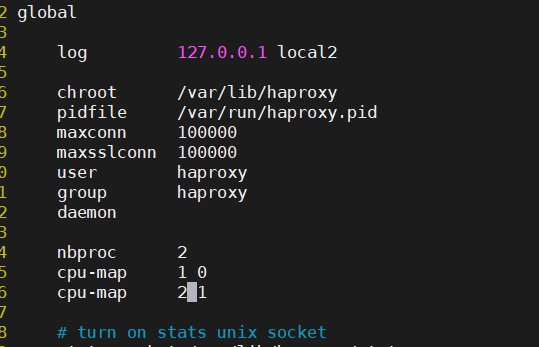
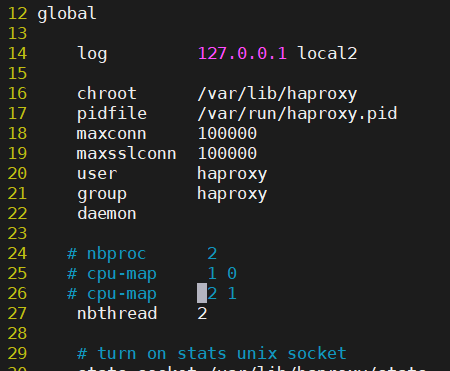
global 配置参数说明
global
log 127.0.0.1 local2 #定义全局的syslog服务器;日志服务器需要开启UDP协
议,最多可以定义两个
chroot /var/lib/haproxy #锁定运行目录
pidfile /var/run/haproxy.pid #指定pid文件
maxconn 100000 #指定最大连接数
user haproxy #指定haproxy的运行用户
group haproxy #指定haproxy的运行组
daemon #指定haproxy以守护进程方式运行
# turn on stats unix socket
stats socket /var/lib/haproxy/stats #指定haproxy的套接字文件
nbproc 2 #指定haproxy的work进程数量,默认是1个
cpu-map 1 0 #指定第一个work绑定第一个cpu核心
cpu-map 2 1 #指定第二个work绑定第二个cpu核心
nbthread 2 #指定haproxy的线程数量,默认每个进程一个线程,此参数与nbproc互斥
maxsslconn 100000 #每个haproxy进程ssl最大连接数,用于haproxy配置了证书的场景下
maxconnrate 100 #指定每个客户端每秒建立连接的最大数量
注:nbproc 2后接了几个数字就会开几个work,把主进程分成了多个子进程,和核有关,不是越多越好
多进程和多线程
多进程:

可以看出是一个父程序(haproxy)后接了两个子程序,子进程通常负责流量转发、负载均衡。
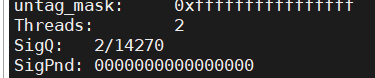
多线程(不能和多进程同时使用):

[root@work-node1 ~]# cat /proc/19012/status
proxies配置参数说明
| 参数 | 类型(都是proxies) | 作用 |
| defaults [<name>] | - | 默认配置项,针对以下的frontend、backend和listen生效,可以多个 name也可以没有name |
| frontend <name> | - | 前端servername,类似于Nginx的一个虚拟主机 server和LVS服务集 群。 |
| backend <name> | - | 后端服务器组,等于nginx的upstream和LVS中的RS服务器 |
| listen <name> | - | 将frontend和backend合并在一起配置,相对于frontend和backend 配置更简洁,生产常用 |
注:name字段只能使用大小写字母,数字,‘-’(dash),'_‘(underscore),'.' (dot)和 ':'(colon),并且严格区分大小写
Proxies配置-defaults:
defaultsmode http #HAProxy实例使用的连接协议 log global #指定日志地址和记录日志条目的
syslog/rsyslog日志设备#此处的 global表示使用 global配置段中设定的log值。option httplog #日志记录选项,httplog表示记录与 HTTP会话相关的各种属性值#包括 HTTP请求、会话状态、连接数、源地址以及连接时间等option dontlognull #dontlognull表示不记录空会话连接日志option http-server-close #等待客户端完整HTTP请求的时间,此处为等待10s。option forwardfor except 127.0.0.0/8 #透传客户端真实IP至后端web服务器#在apache配置文件中加入:<br>%{XForwarded-For}i#后在webserver中看日志即可看到地址透传信息option redispatch #当server Id对应的服务器挂掉后,强制定向到其他健康的服务器,重新派发option http-keep-alive #开启与客户端的会话保持retries 3 #连接后端服务器失败次数
timeout http-request 10s #等待客户端请求完全被接收和处理的最长时间timeout queue 1m #设置删除连接和客户端收到503或服务不可用等提示信息前的等待时间timeout connect 120s #设置等待服务器连接成功的时间timeout client 600s #设置允许客户端处于非活动状态,即既不发
送数据也不接收数据的时间timeout server 600s #设置服务器超时时间,即允许服务器处于既不接收也不发送数据的非活动时间timeout http-keep-alive 60s #session 会话保持超时时间,此时间段内会转发到相同的后端服务器timeout check 10s #指定后端服务器健康检查的超时时间maxconn 3000 default-server inter 1000 weight 3 Proxies配置-frontend
bind:指定HAProxy的监听地址,可以是IPV4或IPV6,可以同时监听多个IP或端口,可同时用于listen字段中
#格式:
bind [<address>]:<port_range> [, ...] [param*]
#注意:如果需要绑定在非本机的IP,需要开启内核参数:net.ipv4.ip_nonlocal_bind=1
backlog <backlog> #针对所有server配置,当前端服务器的连接数达到上限后的后援队列长度,注意:不支持backend
Proxies配置-backend
定义一组后端服务器,backend服务器将被frontend进行调用。
注意: 1、backend 的名称必须唯一,并且必须在listen或frontend中事先定义才可以使用,否则服务无法启动;
2、option后面加 httpchk,smtpchk,mysql-check,pgsql-check,ssl-hello-chk方法,可用于实现更多应用层检测功能。
mode http|tcp #指定负载协议类型,和对应的frontend必须一致
option #配置选项
server #定义后端real server,必须指定IP和端口
server配置
#针对一个server配置
check #对指定real进行健康状态检查,如果不加此设置,默认不开启检查,只有check后面没有其它配置也可以启用检查功能#默认对相应的后端服务器IP和端口,利用TCP连接进行周期性健康性检查,注意必须指定端口才能实现健康性检查addr <IP> #可指定的健康状态监测IP,可以是专门的数据网段,减少业务网络的流量
port <num> #指定的健康状态监测端口
inter <num> #健康状态检查间隔时间,默认2000 ms
fall <num> #后端服务器从线上转为线下的检查的连续失效次数,默认为3
rise <num> #后端服务器从下线恢复上线的检查的连续有效次数,默认为2
weight <weight> #默认为1,最大值为256,0(状态为蓝色)表示不参与负载均衡,但仍接受持久连接
backup #将后端服务器标记为备份状态,只在所有非备份主机down机时提供服务,类似Sorry
Serverdisabled #将后端服务器标记为不可用状态,即维护状态,除了持久模式#将不再接受连接,状态为深黄色,优雅下线,不再接受新用户的请求redirect prefix http://www.baidu.com/ #将请求临时(302)重定向至其它URL,只适用于http模式maxconn <maxconn> #当前后端server的最大并发连接数
对于server的配置练习
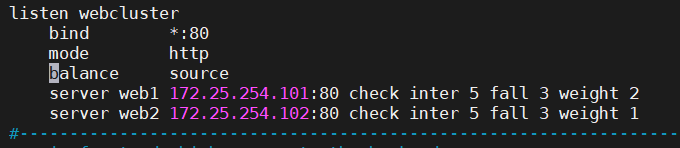
check,inter <num>,fall <num>,rise <num>:

权重weight <weight>:

web1:172.25.254.101次数增多,web2:172.25.254.102;条件是主机权重高且没有负载限额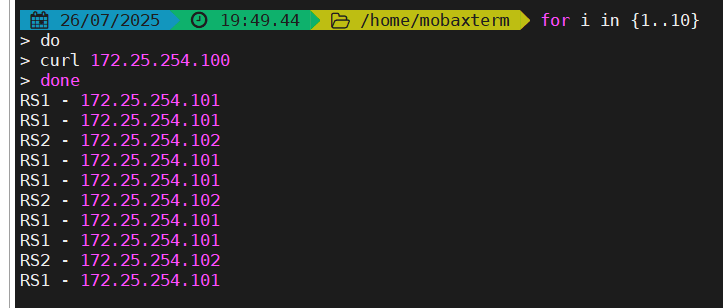
sorry server(当后端服务器都宕机出现问题时的返回页面)
用httpd充当sorryserver,端口改为8080
vim /etc/httpd/conf/httpd.conf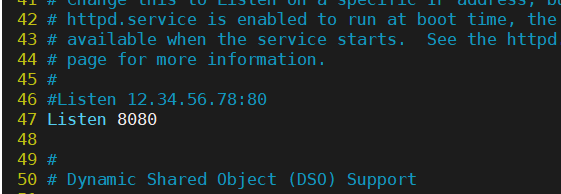
设定好显示sorryserver页面

在haproxy.cfg中配置好sorryserver
backup:指定它的sorryserver
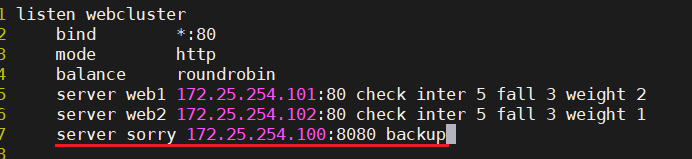
测试:
socat工具
对服务器动态权重和其它状态可以利用 socat工具进行调整,Socat 是 Linux 下的一个多功能的网络工具,名字来由是Socket CAT,相当于netCAT的增强版.Socat 的主要特点就是在两个数据流之间建立双向通道,且支持众多协议和链接方式。如 IP、TCP、 UDP、IPv6、Socket文件等
#修改配置文件
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
stats socket /var/lib/haproxy/stats mode 600 level admin#查看帮助
haproxy ~]# socat -h
haproxy ~]# echo "help" | socat stdio /var/lib/haproxy/stats
The following commands are valid at this level:
help : this message
prompt : toggle interactive mode with prompt
quit : disconnectenable server : enable a disabled server (use 'set server' instead) #启用服务器
set maxconn server : change a server's maxconn setting
set server : change a server's state, weight or address #设置服务器
get weight : report a server's current weight #查看权重
set weight : change a server's weight (deprecated) #设置权重
show startup-logs : report logs emitted during HAProxy startup
how peers [peers section]: dump some information about all the peers or this
peers section
set maxconn global : change the per-process maxconn setting
set rate-limit : change a rate limiting value
set severity-output [none|number|string] : set presence of severity level in
feedback information
set timeout : change a timeout setting
show env [var] : dump environment variables known to the process
show cli sockets : dump list of cli sockets
show cli level : display the level of the current CLI session
show fd [num] : dump list of file descriptors in use后面的实验里面出现的问题就是权限的问题,用socat工具改后解决问题
3、haproxy的算法----8种(面试笔试核心)
HAProxy通过固定参数 balance 指明对后端服务器的调度算法
balance参数可以配置在listen或backend选项中。
HAProxy的调度算法分为静态和动态调度算法。
有些算法可以根据参数在静态和动态算法中相互转换。
静态算法(2种)
静态算法:按照事先定义好的规则轮询公平调度,不关心后端服务器的当前负载、连接数和响应速度等,且无法实时修改权重(只能为0和1,不支持其它值),只能靠重启HAProxy生效。
static-rr:基于权重的轮询调度
不支持运行时利用socat进行权重的动态调整(只支持0和1,不支持其它值)
不支持端服务器慢启动
其后端主机数量没有限制,相当于LVS中的 wrr
译:慢启动是指在服务器刚刚启动上不会把他所应该承担的访问压力全部给它,而是先给一部分,当没问题后在给一部分
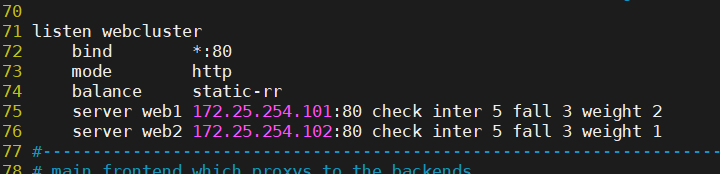
检测可看出严格按照权重值进行轮询
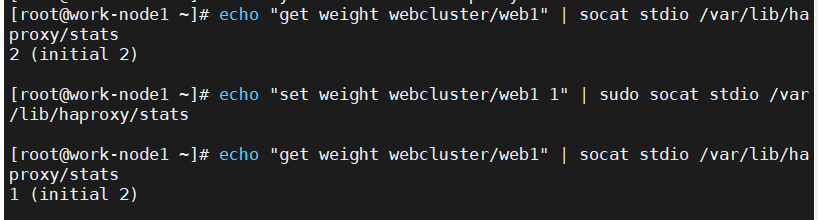
不支持热更新

因为权限问题所以在执行 echo "set weight webcluster/web1 1" | sudo socat stdio /var/lib/haproxy/stat会返回Permission denied
修改/etc/haproxy/haproxy.cfg中的命令
# 配置统计套接字,允许管理命令
stats socket /var/lib/haproxy/stats mode 660 user haproxy group haproxy level admin expose-fd listeners
成功!

first
根据服务器在列表中的位置,自上而下进行调度;
其只会当第一台服务器的连接数达到上限,新请求才会分配给下一台服务;
其会忽略服务器的权重设置;
不支持用socat进行动态修改权重,可以设置0和1,可以设置其它值但无效。
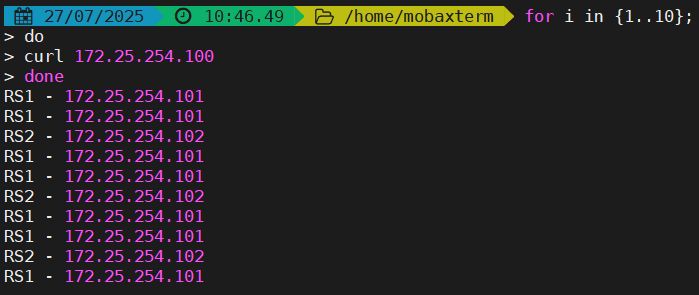
动态算法(2种)
基于后端服务器状态进行调度适当调整;新请求将优先调度至当前负载较低的服务器。权重可以在haproxy运行时动态调整无需重启。
roundrobin
1. 基于权重的轮询动态调度算法,
2. 支持权重的运行时调整,不同于lvs中的rr轮训模式,
3. HAProxy中的roundrobin支持慢启动(新加的服务器会逐渐增加转发数),
4. 其每个后端backend中最多支持4095个real server,
5. 支持对real server权重动态调整,
6. roundrobin为默认调度算法,此算法使用广泛

支持热更新
leastconn
leastconn加权的最少连接的动态
支持权重的运行时调整和慢启动,即:根据当前连接最少的后端服务器而非权重进行优先调度(新客户端连接)
比较适合长连接的场景使用,比如:MySQL等场景。
其他算法(4种)
其它算法即可作为静态算法,又可以通过选项成为动态算法
source
源地址hash,基于用户源地址hash并将请求转发到后端服务器,后续同一个源地址请求将被转发至同一个后端web服务器。
此方式当后端服务器数据量发生变化时,会导致很多用户的请求转发至新的后端服务器,默认为静态方式,但是可以通过hash-type支持的选项更改这个算法;一般是在不插入Cookie的TCP模式下使用,也可给拒绝会话cookie的客户提供最好的会话粘性,适用于session会话保持但不支持cookie和缓存的场景源地址。
有两种转发客户端请求到后端服务器的服务器选取计算方式,分别是取模法和一致性hash
同一个源地址请求将被转发至同一个后端web服务器
注:如果访问客户端时一个家庭,那么所有的家庭的访问流量都会被定向到一台服务器,这时source算法的缺陷
map-base取模法
map-based:取模法,对source地址进行hash计算,再基于服务器总权重的取模,最终结果决定将此请求转发至对应的后端服务器。
此方法是静态的,即不支持在线调整权重,不支持慢启动,可实现对后端服务器均衡调度
缺点是当服务器的总权重发生变化时,即有服务器上线或下线,都会因总权重发生变化而导致调度结果整体改变
hash-type 指定的默值为此算法
注:所谓取模运算,就是计算两个数相除之后的余数,10%7=3, 7%4=3
map-based算法:基于权重取模,hash(source_ip)%所有后端服务器相加的总权重
比如当源hash值时1111,1112,1113,三台服务器a b c的权重均为1,
即abc的调度标签分别会被设定为 0 1 2(1111%3=1,1112%3=2,1113%3=0)
1111 ----- > nodeb
1112 ------> nodec
1113 ------> nodea
如果a下线后,权重数量发生变化
1111%2=1,1112%2=0,1113%2=1
1112和1113被调度到的主机都发生变化,这样会导致会话丢失,一致性哈希可以解决这个问题
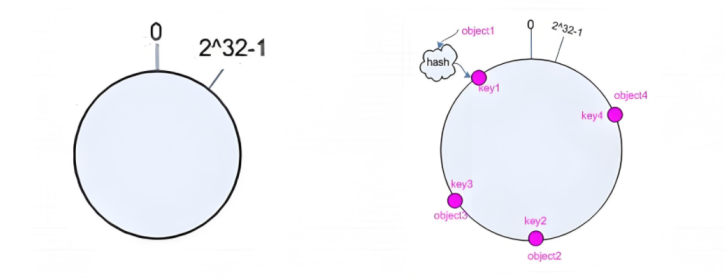
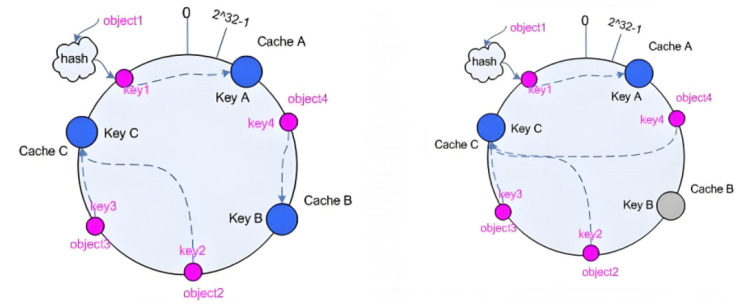
一致性hash
一致性哈希,当服务器的总权重发生变化时,对调度结果影响是局部的,不会引起大的hash(o) mod n
该hash算法是动态的,支持使用 socat等工具进行在线权重调整,支持慢启动
算法(就近访问原则):
1、后端服务器哈希环点keyA=hash(后端服务器虚拟ip)%(2^32)
2、客户机哈希环点key1=hash(client_ip)%(2^32) ,得到的值在[0---4294967295]之间,
3、将keyA和key1都放在hash环上,将用户请求调度到离key1最近的keyA对应的后端服务器
hash对象
Hash对象到后端服务器的映射关系:
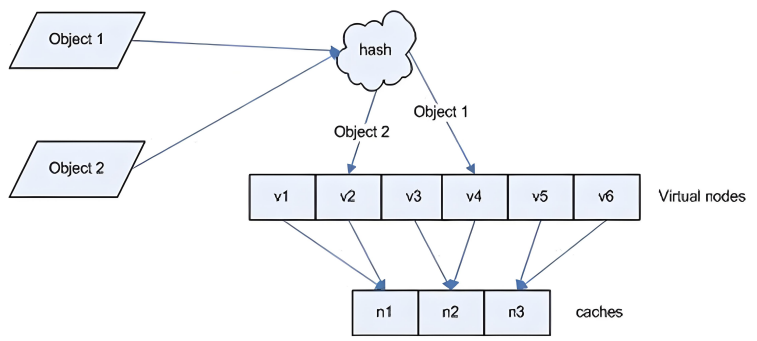
一致性哈希示意图
后端服务器在线与离线调度方式
uri(只能在七层做)
基于对http请求的URI的左半部分或整个uri做hash,再将hash结果对总权重进行取模后
根据最终结果将请求转发到后端指定服务器
适用于后端是缓存服务器场景
默认是静态算法,也可以通过hash-type指定map-based和consistent,来定义使用取模法还是一致性hash
注:此算法基于应用层,所以只支持 mode http ,不支持 mode tcp
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
整个uri:/<path>;<params>?<query>#<frag>
左半部分:/<path>;<params>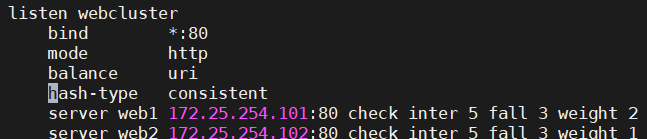
可以在指定的path中访问

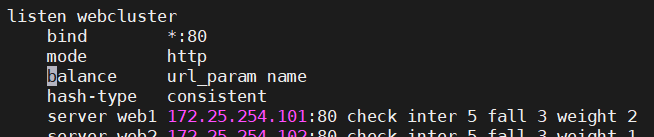
url_param
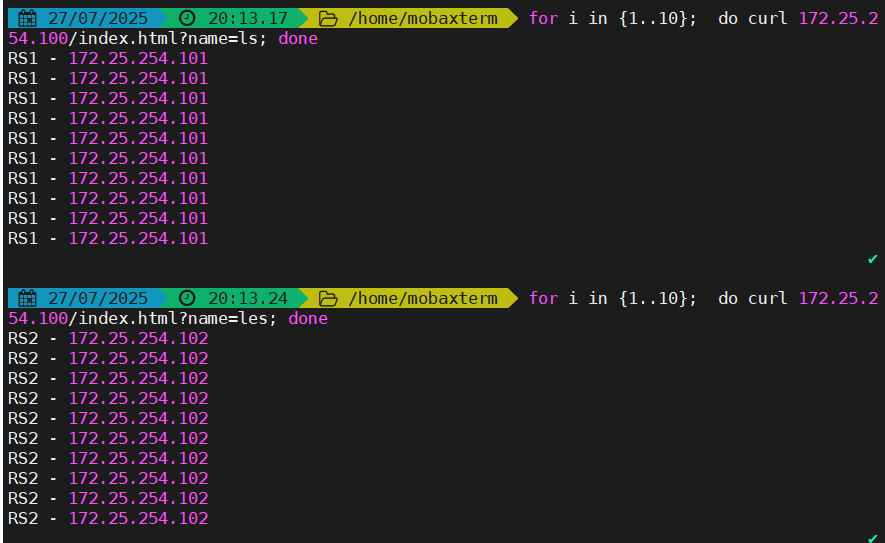
url_param对用户请求的url中的 params 部分中的一个参数key对应的value值作hash计算,并由服务器总权重相除以后派发至某挑出的服务器,后端搜索同一个数据会被调度到同一个服务器,多用于电商
通常用于追踪用户,以确保来自同一个用户的请求始终发往同一个real server
如果无没key,将按roundrobin算法
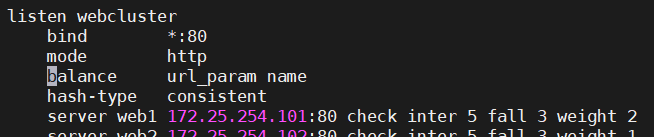
hdr
针对用户每个http头部(header)请求中的指定信息做hash,
此处由 name 指定的http首部将会被取出并做hash计算,
然后由服务器总权重取模以后派发至某挑出的服务器,如果无有效值,则会使用默认的轮询调度。
算法总结
#静态
static-rr--------->tcp/http
first------------->tcp/http
#动态
roundrobin-------->tcp/http
leastconn--------->tcp/http
random------------>tcp/http
#以下静态和动态取决于hash_type是否consistent
source------------>tcp/http
Uri--------------->http
url_param--------->http
hdr--------------->http
场景:
first #使用较少
static-rr #做了session共享的web集群
roundrobin
random
leastconn #数据库
source保持
#基于客户端公网IP的会话保持
Uri--------------->http #缓存服务器,CDN服务商,蓝汛、百度、阿里云、腾讯
url_param--------->http #可以实现session保持
hdr #基于客户端请求报文头部做下一步处理
4、高级功能及配置
基于cookie的会话保持
cookie value:为当前server指定cookie值,实现基于cookie的会话黏性,相对于基于 source 地址hash
调度算法对客户端的粒度更精准,但同时也加大了haproxy负载,目前此模式使用较少, 已经被session共享服务器代替
注:不支持 tcp mode,使用 http mode;意味着只走七层
cookie name [ rewrite | insert | prefix ][ indirect ] [ nocache ][ postonly ] [
preserve ][ httponly ] [ secure ][ domain ]* [ maxidle <idle> ][ maxlife ]name: #cookie 的 key名称,用于实现持久连接
insert: #插入新的cookie,默认不插入cookie
indirect: #如果客户端已经有cookie,则不会再发送cookie信息
nocache: #当client和hapoxy之间有缓存服务器(如:CDN)时,不允许中间缓存器缓存cookie,#因为这会导致很多经过同一个CDN的请求都发送到同一台后端服务器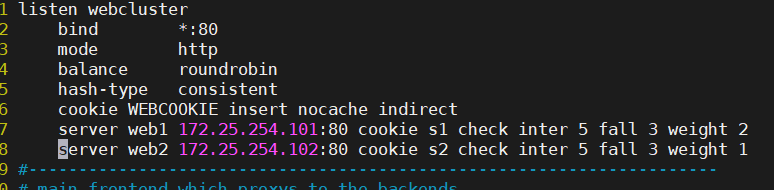
验证cookie信息
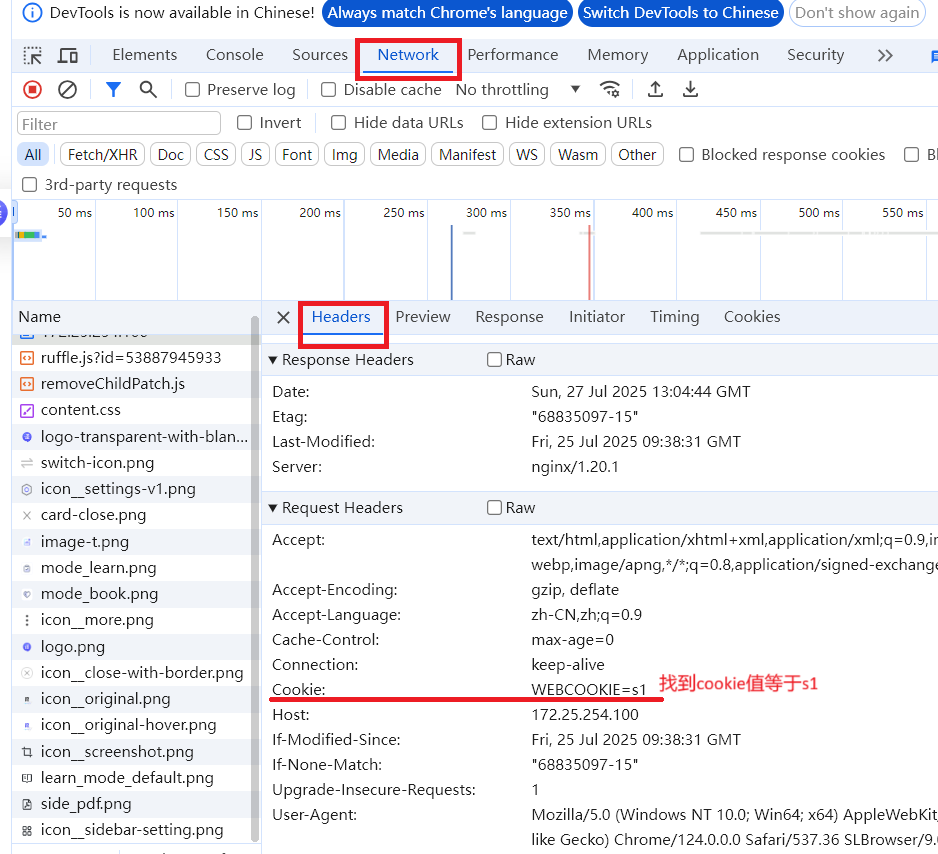
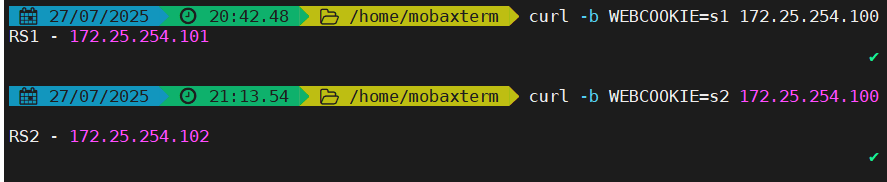
也可在本机上进行测试
HAProxy状态页
通过web界面,显示当前HAProxy的运行状态
stats enable #基于默认的参数启用stats page
stats hide-version #将状态页中haproxy版本隐藏
stats refresh <delay> #设定自动刷新时间间隔,默认不自动刷新
stats uri <prefix> #自定义stats page uri,默认值:/haproxy?stats
stats auth <user>:<passwd> #认证时的账号和密码,可定义多个用户,每行指定一个用户#默认:no authentication
stats admin { if | unless } <cond> #启用stats page中的管理功能启动状态页
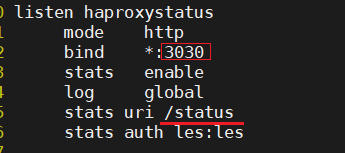

登录状态页
如图两台web服务器都在正常运行
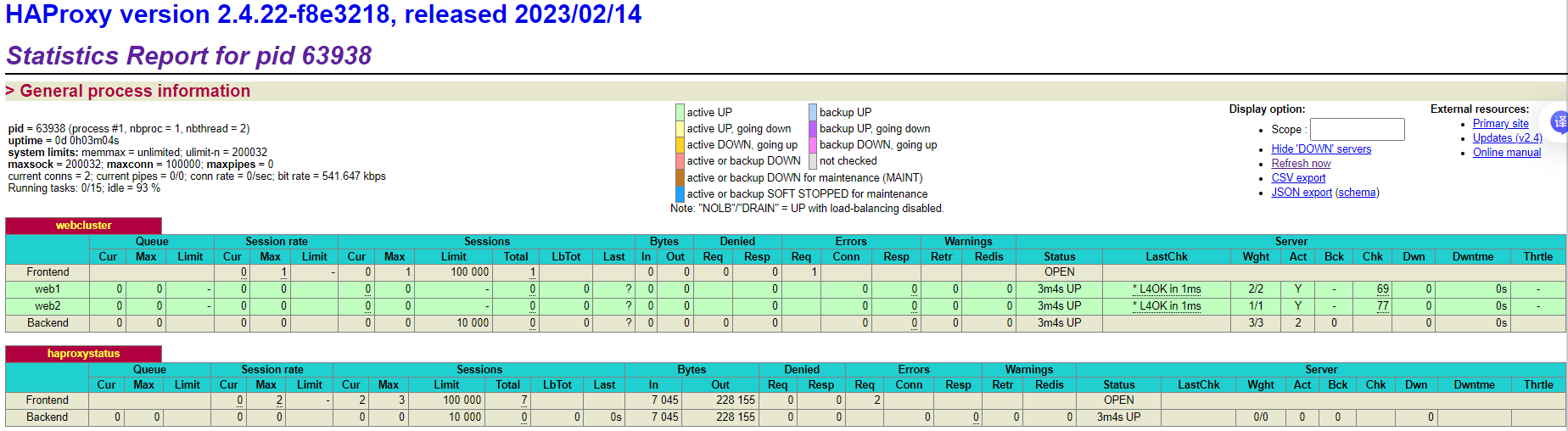
#pid为当前pid号,process为当前进程号,nbproc和nbthread为一共多少进程和每个进程多少个线程
pid = 27134 (process #1, nbproc = 1, nbthread = 1)
#启动了多长时间
uptime = 0d 0h00m04s
#系统资源限制:内存/最大打开文件数/
system limits: memmax = unlimited; ulimit-n = 200029
#最大socket连接数/单进程最大连接数/最大管道数maxpipes
maxsock = 200029; maxconn = 100000; maxpipes = 0
#当前连接数/当前管道数/当前连接速率
current conns = 2; current pipes = 0/0; conn rate = 2/sec; bit rate = 0.000 kbps#运行的任务/当前空闲率
Running tasks: 1/14; idle = 100 %
active UP: #在线服务器
backup UP: #标记为backup的服务器
active UP, going down: #监测未通过正在进入down过程
backup UP, going down: #备份服务器正在进入down过程
active DOWN, going up: #down的服务器正在进入up过程
backup DOWN, going up: #备份服务器正在进入up过程
active or backup DOWN: #在线的服务器或者是backup的服务器已经转换成了down状态
not checked: #标记为不监测的服务器
#active或者backup服务器人为下线的
active or backup DOWN for maintenance (MAINT)
#active或者backup被人为软下线(人为将weight改成0)
active or backup SOFT STOPPED for maintenance
IP透传
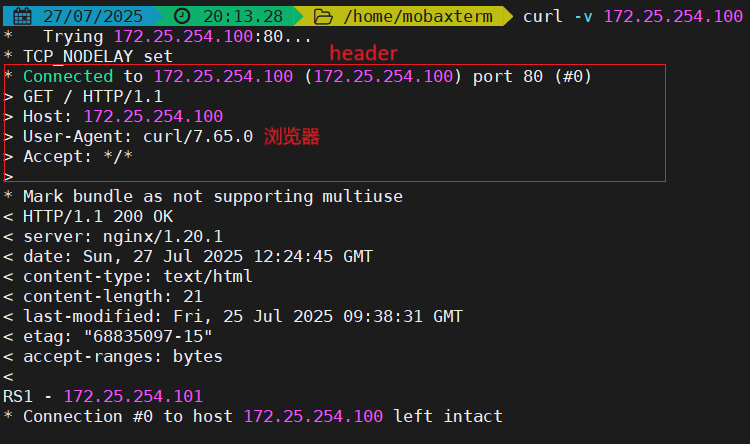
web服务器中需要记录客户端的真实IP地址,用于做访问统计、安全防护、行为分析、区域排行等场景。
四层IP透传
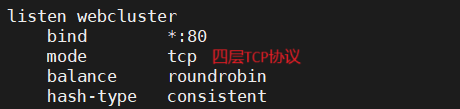
未开透传,后端realserver没有显示访问信息

nginx配置
vim /etc/nginx/nginx.conf 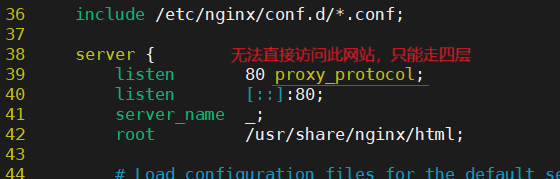
开启IP透传
在haproxy上:
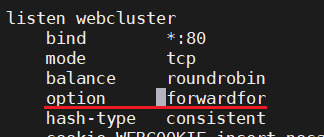
在后端服务器上:

测试

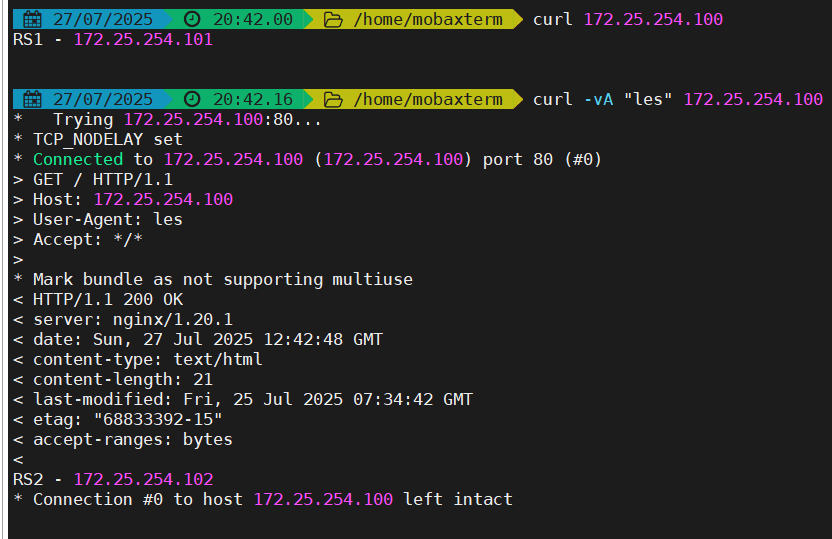
七层IP透传
当haproxy工作在七层的时候,也可以透传客户端真实IP至后端服务器(默认开启透传)
配制
在由haproxy发往后端主机的请求报文中添加“X-Forwarded-For"首部,其值为前端客户端的地址;用于向后端主发送真实的客户端IP
option forwardfor [ except <network> ] [ header <name> ] [ if-none ]
[ except <network> ]:请求报请来自此处指定的网络时不予添加此首部,如haproxy自身所在网络
[ header <name> ]: 使用自定义的首部名称,而非“X-Forwarded-For",示例:X-client
[ if-none ] 如果没有首部才添加首部,如果有使用默认值
ACL
访问控制列表ACL,Access Control Lists)
是一种基于包过滤的访问控制技术
它可以根据设定的条件对经过服务器传输的数据包进行过滤(条件匹配)即对接收到的报文进行匹配和过滤,基于请求报文头部中的源地址、源端口、目标地址、目标端口、请求方法、URL、文件后缀等信息内容进行匹配并执行进一步操作,比如允许其通过或丢弃。
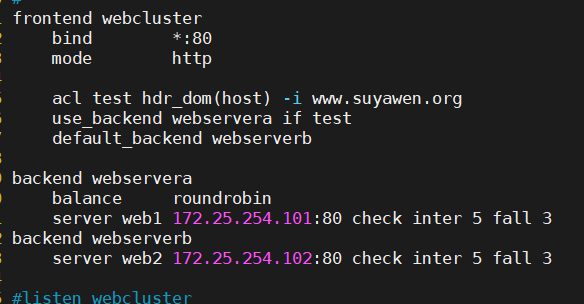
测试
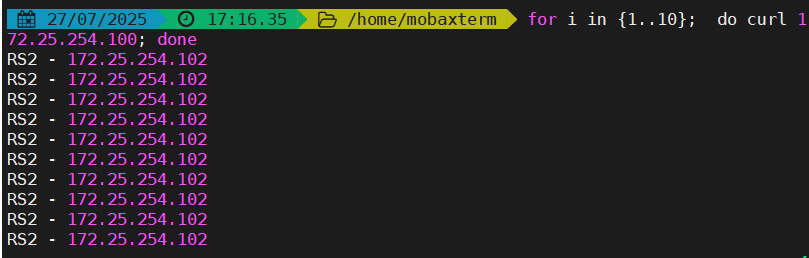
[root@work-node1 ~]# curl 172.25.254.100
RS2 - 172.25.254.102
[root@work-node1 ~]# curl www.suyawen.org
RS1 - 172.25.254.101自定义HAProxy 错误界面
[root@localhost ~]# mkdir -p /etc/haproxy/errorpage
[root@localhost ~]# vim /etc/haproxy/errorpage/503.http
HTTP/1.0 503 Service Unavailable
Cache-Control: no-cache
Connection: close
Content-Type: text/html;charset=UTF-8
<html><body><h1>什么动物生气最安静</h1>
大猩猩!!
</body></html>
[root@localhost ~]# vim /etc/haproxy/haproxy.cfgerrorfile 503 /etc/haproxy/errorpage/503.http
[root@localhost ~]# systemctl restart haproxy.service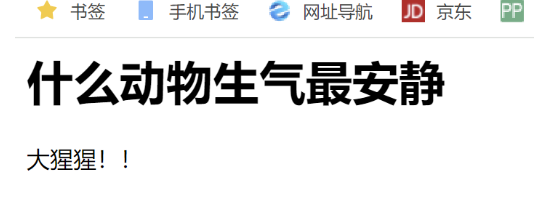
 视频教程 - 微博文章数据可视化分析-点赞区间实现)
-- 高级数据结构zset)

)

KNN,K近邻算法(K-Nearest Neighbors))








构造邻接表(运用队列实现搜索))




