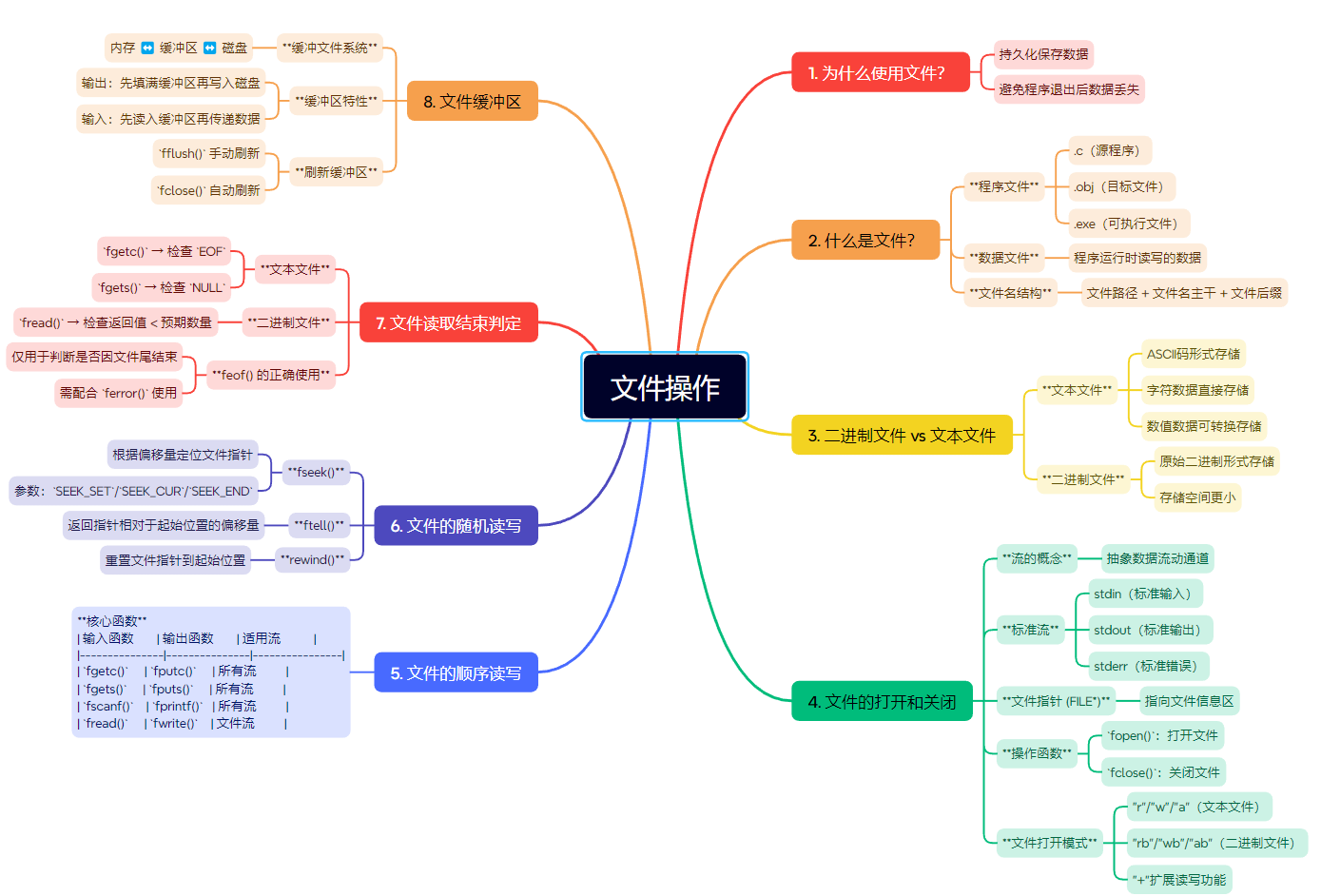
1. 为什么使用文件?
2. 什么是文件?
2.1 程序文件
2.2 数据文件
2.3 文件名
2.4 常见文件后缀
计算机中的文件后缀非常多,不同后缀对应不同的文件类型和用途。
一、程序文件(可执行或包含代码)
• .exe:Windows系统的可执行程序(如软件、游戏启动文件)。
• .msi:Windows的安装包程序(用于安装软件)。
• .bat / .cmd:Windows的批处理脚本(可自动执行一系列命令)。
• .sh:Linux/macOS的脚本文件(类似批处理,可执行命令)。
• .c / .cpp / .java / .py / .js:各种编程语言的源文件(包含代码,需编译/解释后执行)。
• .class:Java编译后的字节码文件(可被Java虚拟机执行)。
• .app:macOS的应用程序(本质是包含可执行文件的文件夹)。
• .apk:安卓系统的安装包(包含手机应用的可执行代码)。
二、数据文件(存储内容,需对应程序打开)
1. 文档类
• .txt:纯文本文件(记事本可打开)。
• .docx / .doc:Word文档(文字、格式)。
• .xlsx / .xls:Excel表格(数据、公式)。
• .pptx / .ppt:PowerPoint演示文稿(幻灯片)。
• .pdf:便携文档格式(跨平台的只读文档)。
2. 媒体类
• .jpg / .jpeg / .png / .gif:图片文件(分别对应不同压缩格式)。
• .mp3 / .wav / .flac:音频文件(音乐、声音)。
• .mp4 / .avi / .mov / .mkv:视频文件(电影、视频片段)。
3. 压缩/备份类
• .zip / .rar / .7z:压缩包(用于打包多个文件,节省空间)。
• .iso:光盘镜像文件(可模拟光盘内容,用于安装系统、游戏)。
4. 其他常用数据
• .html / .htm:网页文件(浏览器可打开)。
• .csv:逗号分隔的表格数据(Excel、记事本均可打开)。
• .json:存储结构化数据的文件(常用于程序间数据交换)。
核心区分小技巧:
• 如果你双击一个文件,它能“自己启动并让电脑做事”(比如打开软件、运行游戏),大概率是程序文件(如.exe、.app)。
• 如果你双击一个文件,必须先打开某个软件才能显示内容(比如用Word打开.docx,用播放器打开.mp4),那就是数据文件。
3. ⼆进制⽂件和⽂本⽂件
#include <stdio.h>
int main()
{int a = 10000;FILE* pf = fopen("test.txt", "wb");fwrite(&a, 4, 1, pf);//⼆进制的形式写到⽂件中fclose(pf);pf = NULL;return 0;}ps:二进制文件本身的内容就不是文字,用文本工具打开自然会是乱码
ps:就是说二进制的程序文件可以在源文件下用二进制编辑器的打开方式去实现。
3.1 这边用二进制编译器输出时为啥没有ox?
ox 并不是二进制或十六进制数据本身的一部分,它只是人类为了区分进制而加上的 '标记'。
4. 文件的打开和关闭
4.1 流和标准流
4.1.1 流
4.1.2 标准流
- stdin - 标准输⼊流,在⼤多数的环境中从键盘输⼊,scanf函数就是从标准输⼊流中读取数据。
- stdout - 标准输出流,⼤多数的环境中输出⾄显⽰器界⾯,printf函数就是将信息输出到标准输出流中。
- stderr - 标准错误流,⼤多数环境中输出到显⽰器界⾯。
4.1.3 为什么和 FILE*(文件指针)有关?
在C语言里,所有“流”(包括标准流、你自己打开的文件)都用 FILE* 类型的指针来表示,这个指针就像“管道的阀门”——通过它操作流里的数据。
• 标准流对应的 FILE* 指针是系统预先定义好的:stdin(标准输入)、stdout(标准输出)、stderr(标准错误)。
• 你自己用 fopen 打开的文件(比如 fopen("a.txt", "r")),得到的也是 FILE* 指针,本质上和标准流的指针是同一类东西,只是指向的“管道”不同(一个是默认的屏幕/键盘,一个是你指定的文件)。
4.2 文件指针
struct _iobuf
{
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};typedef struct _iobuf FILE;
FILE* pf;//⽂件指针变量4.2.1 文件信息区
1. FILE结构体(你说的“文件信息区”)是程序和实际文件之间的“中间人”,程序通过它来操作文件内容。
打个比方:
你想往一个笔记本(实际文件)里写东西,不会直接拿笔戳笔记本——得先翻开笔记本(打开文件),这时FILE结构体就像笔记本的“封面+书签”:
• 封面记录着笔记本的位置(存在硬盘哪里)、能不能涂改(读写权限);
• 书签标记着当前写到哪一行(文件当前位置)。
2. FILE结构体和“程序打开的某个文件”是一一绑定的,但不是和“程序本身”绑定。
举个例子:
你写了一个程序,同时打开了a.txt和b.txt两个文件。这时程序里会有两个FILE结构体指针:
• 一个指向 a.txt 的FILE结构体(记录a.txt的读写位置、权限等);
• 另一个指向 b.txt 的FILE结构体(记录b.txt的信息)。
这两个结构体分别和 a.txt、b.txt绑定,程序通过它们分别操作两个文件。
- 当你关闭a.txt后,对应的FILE结构体就会被释放,不再和任何文件绑定;
- 而b.txt的结构体还在,直到你关闭它。
4.2.2 为啥说我们不需要特别关注到文件信息区的细节,而是通过它的指针形式找到它?
因为FILE结构体的内部细节对我们写程序来说,属于“没必要知道的底层实现”,就像你用手机拍照时,不用知道摄像头传感器的具体工作原理,按快门就行。
1. FILE结构体的内部太复杂,且不统一
它里面可能包含几十种信息(比如不同操作系统的FILE结构不一样),但我们编程时只需要“打开/读写/关闭”这几个动作。
就像你用遥控器开空调,不需要知道遥控器内部的电路板怎么设计——你只需要按“开”键,空调就工作了。
FILE指针就是那个“遥控器”,通过它调用fopen、fprintf等函数,就能完成操作,不用关心里面具体存了啥。
2. 用指针更安全、更方便
如果直接操作FILE结构体的内部数据(比如手动改它的“当前位置”),很容易改错(比如改到负数位置),导致程序崩溃。
而C语言提供的函数(如fread、fseek)已经帮我们封装好了这些操作,通过指针调用它们,相当于让“专业工具”来处理,不容易出错。
4.3 文件的打开和关闭
//打开⽂件FILE * fopen ( const char * filename, const char * mode );//关闭⽂件int fclose ( FILE * stream );- 权限问题
- 路径要对
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
| “r”(只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| “w”(只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| “a”(追加) | 向文本文件尾添加数据 | 建立一个新的文件 |
| “rb”(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| “wb”(只写) | 为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
| “ab”(追加) | 向一个二进制文件尾添加数据 | 建立一个新的文件 |
| “r+”(读写) | 为了读和写,打开一个文本文件 | 出错 |
| “w+”(读写) | 为了读和写,建议一个新的文件 | 建立一个新的文件 |
| “a+”(读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
| “rb+”(读写) | 为了读和写打开一个二进制文件 | 出错 |
| “wb+”(读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
| “ab+”(读写) | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
/* fopen fclose example */
#include <stdio.h>
int main ()
{FILE * pFile;//打开⽂件pFile = fopen ("myfile.txt","w");//⽂件操作if (pFile!=NULL){fputs ("fopen example",pFile);//关闭⽂件fclose (pFile);}return 0;
}4.3.1 文件路径中起始点的解析
假设程序当前运行的目录是 C:\A\B\C(即当前路径在 C 文件夹里),来看两个例子的区别:
例子1:.\\..\\..\\test.txt(1个 . + 2个 ..)
• 解析步骤:
1. . → 从当前目录 C:\A\B\C 开始
2. 第一个 .. → 跳至上一级 C:\A\B
3. 第二个 .. → 再跳至上一级 C:\A
4. 最终找 test.txt → 实际路径是 C:\A\test.txt
例子2:..\\..\\..\\test.txt(3个 ..)
• 解析步骤:
1. 从当前目录 C:\A\B\C 开始(默认起点,无需 .)
2. 第一个 .. → 跳至 C:\A\B
3. 第二个 .. → 跳至 C:\A
4. 第三个 .. → 再跳至 C:\(A 文件夹的上一级是根目录 C:\)
5. 最终找 test.txt → 实际路径是 C:\test.txt
核心区别:
• 例子1的路径最终定位到 C:\A\test.txt(向上跳2级)
• 例子2的路径最终定位到 C:\test.txt(向上跳3级)
跳转的层级不同,找到的文件位置自然不一样~
4.3.2 文件关闭和free有点相似
你混淆的点其实和「动态内存管理」「资源释放」的共性与差异有关,这几个概念确实容易串在一起,咱们分清楚核心逻辑就好了:
一、fclose() + 置空指针 与 free() + 置空指针的「异曲同工」之处
两者本质都是 “释放资源后避免误用”,逻辑完全一致:
• free(p):释放动态分配的内存(比如malloc申请的),但指针p仍保留原地址(变成野指针)。如果之后再用p读写,会访问无效内存,导致错误。
• fclose(fp):释放文件相关的系统资源(文件描述符、缓冲区等),但指针fp仍保留原地址(变成野指针)。如果之后再用fp操作文件,会访问已回收的资源,导致错误。
所以两者都需要在释放后 手动置空指针(p = NULL; 或 fp = NULL;),目的是把“隐藏的错误”变成“明确的空指针错误”,方便调试。
二、为什么有人会误认为“不置空会让程序一直运行”?
可能和 “内存泄漏”的概念混淆了。动态内存管理中:
• 如果用malloc申请了内存,却忘记free,会导致 内存泄漏(系统内存被持续占用,无法回收)。
• 对于长期运行的程序(比如服务器),内存泄漏累积到一定程度,可能导致系统内存不足,甚至程序崩溃(但不是“程序一直运行停不下来”,而是“运行中出问题”)。
但注意:
• 内存泄漏的核心是“资源没释放”,和指针是否置空无关(哪怕free后没置空,资源也已经释放了,不会泄漏)。
• 程序是否“停不下来”,只看代码逻辑(比如while(1)死循环),和内存/文件资源是否释放完全无关。
5. 文件的顺序读写
5.1 顺序读写函数介绍
| 函数名 | 功能 | 适用于 |
|---|---|---|
| fgetc | 字符输入函数 | 所有输入流 |
| fputc | 字符输出函数 | 所有输出流 |
| fgets | 文本行输入函数 | 所有输入流 |
| fputs | 文本行输出函数 | 所有输出流 |
| fscanf | 格式化输入函数 | 所有输入流 |
| fprintf | 格式化输出函数 | 所有输出流 |
| fread | 二进制输入 | 文件输入流 |
| fwrite | 二进制输出 | 文件输出流 |
5.2 对比⼀组函数:
scanf / fscanf / sscanfprintf / fprintf / sprintf
5.2.1 scanf/fscanf/sscanf 的区别
scanf
功能:从标准输入流(通常是键盘)读取格式化数据。
原型:int scanf(const char *format, ...);
示例:
#include <stdio.h>int main()
{int num;printf("请输入一个整数: ");scanf("%d", &num);printf("你输入的整数是: %d\n", num);return 0;
}说明:程序运行时,会等待用户通过键盘输入数据,scanf 按照指定的格式 %d 读取整数并存储到变量 num 中。
fscanf
功能:从指定的文件流中读取格式化数据。
原型:int fscanf(FILE *stream, const char *format, ...);
示例:
#include <stdio.h>int main()
{FILE *fp;int num;fp = fopen("test.txt", "r");if (fp != NULL) {fscanf(fp, "%d", &num);printf("从文件中读取的整数是: %d\n", num);fclose(fp);}return 0;
}说明:假设
test.txt文件中存储了一个整数,fscanf从打开的文件流fp中,按照%d的格式读取整数。它适用于从文件中读取特定格式的数据,而不是从标准输入读取。
sscanf
功能:从字符串中读取格式化数据。
原型:int sscanf(const char *str, const char *format, ...);
示例:
#include <stdio.h>int main()
{char str[] = "123";int num;sscanf(str, "%d", &num);printf("从字符串中读取的整数是: %d\n", num);return 0;
}- 说明:
sscanf从给定的字符串str中,按照%d的格式解析出整数,并存储到变量num中。它常用于从已有的字符串中提取特定格式的数据。
5.2.2 printf/fprintf/sprintf 的区别
printf
功能:将格式化的数据输出到标准输出流(通常是屏幕)。
原型:int printf(const char *format, ...);
示例:
#include <stdio.h>int main()
{int num = 10;printf("整数的值是: %d\n", num);return 0;
}说明:
printf按照指定的格式%d将变量num的值输出到屏幕上。fprintf
功能:将格式化的数据输出到指定的文件流中。
原型:int fprintf(FILE *stream, const char *format, ...);
示例:
#include <stdio.h>int main()
{FILE *fp;int num = 20;fp = fopen("output.txt", "w");if (fp != NULL) {fprintf(fp, "整数的值是: %d\n", num);fclose(fp);}return 0;
}说明:
fprintf将格式化的数据输出到打开的文件流fp指向的文件中,这里是将包含整数num值的字符串写入到output.txt文件。sprintf
功能:将格式化的数据输出到字符串中。
原型:int sprintf(char *str, const char *format, ...);
示例:
#include <stdio.h>int main()
{char result[50];int num = 30;sprintf(result, "整数的值是: %d\n", num);printf("生成的字符串是: %s", result);return 0;
}说明:sprintf 按照指定的格式将数据写入到字符数组 result 中,而不是直接输出到屏幕或文件,之后可以对这个字符串进行进一步的处理,比如传递给其他函数 。
5.3 我对内存和文件的总结
假设写了一个简单的程序:
#include <stdio.h>
int main()
{FILE *f = fopen("test.txt", "r"); // 用r模式打开文件int num_from_file;fscanf(f, "%d", &num_from_file); // 从文件读数据(比如读到123)fclose(f); // 关闭文件int num_from_keyboard;printf("请输入一个数字:");scanf("%d", &num_from_keyboard); // 从键盘读数据(比如输入456)int result = num_from_file + num_from_keyboard; // 计算123+456printf("结果是:%d", result); // 屏幕显示589return 0;
}这里的关键:
• test.txt是外部文件,里面的123是“长期存储”的(关了电脑也在)。
• 程序运行时,会把123从文件读到num_from_file这个变量里——这个变量存在内存里(临时存储,程序结束就消失了)。
• 你从键盘输入的456,会存在num_from_keyboard这个变量里——也在内存里,和文件没关系。
总结来了:
- r模式的核心:只允许“读取文件内容”,绝对不能改文件本身(文件里的123永远是123)。
- 程序的临时变量:键盘输入的数字、计算过程中的数据,都存在程序的内存里(像局部变量这种),是程序自己的“临时工作区”,和被打开的文件没关系。
- 文件和程序是分开的:用r模式打开文件,只是“借用”文件的内容来用,程序后续的代码(比如输入、计算、显示)都是服务于程序本身,不会碰文件一根毫毛。
简单说:r模式下,文件是“只读的素材”,程序是“处理素材的工具”,工具自己怎么折腾(临时变量、输入)都不影响素材本身。
6. 文件的随机读写
6.1 fseek
int fseek ( FILE * stream, long int offset, int origin );例子:
/* fseek example */
#include <stdio.h>
int main ()
{FILE * pFile;pFile = fopen ( "example.txt" , "wb" );fputs ( "This is an apple." , pFile );fseek ( pFile , 9 , SEEK_SET );fputs ( " sam" , pFile );fclose ( pFile );return 0;
}例子2:
int fseek(FILE *stream, long offset, int origin);参数说明:
stream:文件指针(如FILE *fp)offset:偏移量(字节数),可正可负(正数向后移,负数向前移)origin:起始点(从哪里开始计算偏移),有 3 种取值:SEEK_SET:从文件开头开始(值为 0)SEEK_CUR:从当前位置开始(值为 1)SEEK_END:从文件末尾开始(值为 2)
// 假设文件已打开(fp)
fseek(fp, 100, SEEK_SET); // 移动到文件第100个字节处(从开头数)
fseek(fp, 50, SEEK_CUR); // 从当前位置再向后移动50字节
fseek(fp, -30, SEEK_END); // 从文件末尾向前移动30字节(定位到倒数第30字节)6.2 ftell
long int ftell ( FILE * stream );
/* ftell example : getting size of a file */
#include <stdio.h>
int main ()
{FILE * pFile;long size;pFile = fopen ("myfile.txt","rb");if (pFile==NULL)perror ("Error opening file");else{fseek (pFile, 0, SEEK_END); // non-portablesize=ftell (pFile);fclose (pFile);printf ("Size of myfile.txt: %ld bytes.\n",size);}
return 0;
}- 记录当前位置,方便后续回到该位置
- 计算文件大小(先定位到文件末尾,再用
ftell获取偏移量):
fseek(fp, 0, SEEK_END); // 移动到文件末尾
long file_size = ftell(fp); // 此时的偏移量就是文件总字节数6.3 rewind
(fp, 0, SEEK_SET)。
void rewind ( FILE * stream );
/* rewind example */
#include <stdio.h>
int main ()
{int n;FILE * pFile;char buffer [27];pFile = fopen ("myfile.txt","w+");for ( n='A' ; n<='Z' ; n++)fputc ( n, pFile);rewind (pFile);fread (buffer,1,26,pFile);fclose (pFile);buffer[26]='\0';printf(buffer);return 0;
}区别:rewind 没有返回值,而 fseek 会返回 0(成功)或非 0(失败),可以判断操作是否成功。
6.4 三者总结
fseek是 "主动移动" 指针到任意位置ftell是 "查询" 当前指针的位置rewind是 "快速复位" 指针到开头
7. 文件读取结束的判定
7.1 被错误使用的 feof
- fgetc 判断是否为 EOF .
- fgets 判断返回值是否为 NULL .
- fread判断返回值是否⼩于实际要读的个数。
#include <stdio.h>
#include <stdlib.h>int main(void)
{int c; // 注意:int,⾮char,要求处理EOFFILE* fp = fopen("test.txt", "r");if(!fp) {perror("File opening failed");return EXIT_FAILURE;}//fgetc 当读取失败的时候或者遇到⽂件结束的时候,都会返回EOFwhile ((c = fgetc(fp)) != EOF) // 标准C I/O读取⽂件循环{putchar(c);}//判断是什么原因结束的if (ferror(fp))puts("I/O error when reading");else if (feof(fp))puts("End of file reached successfully");fclose(fp);
}
#include <stdio.h>enum { SIZE = 5 };
int main(void)
{double a[SIZE] = {1.,2.,3.,4.,5.};FILE *fp = fopen("test.bin", "wb"); // 必须⽤⼆进制模式fwrite(a, sizeof *a, SIZE, fp); // 写 double 的数组fclose(fp);double b[SIZE];fp = fopen("test.bin","rb");size_t ret_code = fread(b, sizeof *b, SIZE, fp); // 读 double 的数组if(ret_code == SIZE) {puts("Array read successfully, contents: ");for(int n = 0; n < SIZE; ++n)printf("%f ", b[n]);putchar('\n');} else { // error handlingif (feof(fp))printf("Error reading test.bin: unexpected end of file\n");else if (ferror(fp)) {perror("Error reading test.bin");}}fclose(fp);
}8. 文件缓冲区
8.1 考点一:缓冲区概念
#include <stdio.h>
#include <stdlib.h>int main()
{FILE *fp;fp = fopen("test.txt", "w");if (fp == NULL) {perror("fopen");exit(EXIT_FAILURE);}// 向文件写入数据,此时数据先写入缓冲区fputs("Hello, File Buffer!", fp); // 程序结束前,缓冲区数据会自动写入磁盘fclose(fp); return 0;
}










笔记)



顾客管理、供应商管理、用户管理)


 流媒体解决方案)

