一、什么是接口
接口涉及到四个实体:(我去饭店点餐)
我是客人 :客户端
厨师:服务器
服务员:接口
菜单:接口文档
接口定义了一套信息规则让两个系统之间互相不必知道对方的内部,只需通过接口就能进行交互
API应用编程接口:各个应用(程序之间进行高效的沟通与协作)
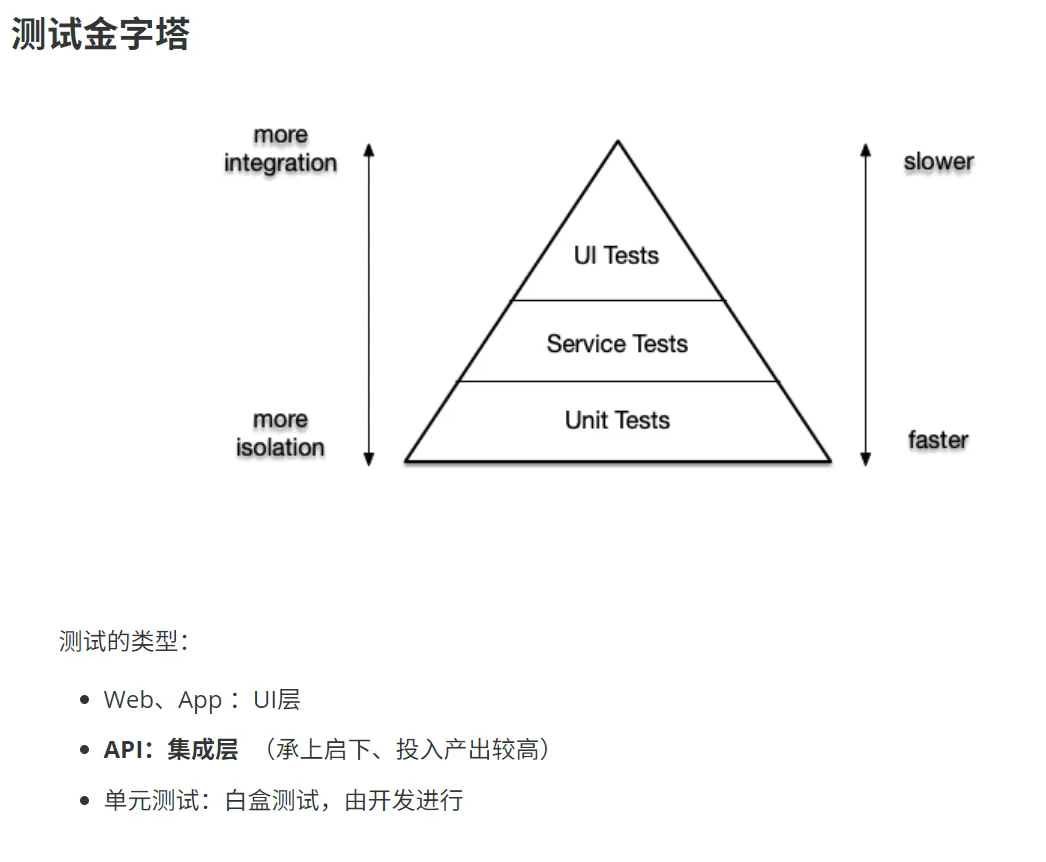
二、HTTP接口
基于HTTP协议的接口
基本特点
- 交互简单:请求 -> 响应模式,无状态
- 结构简单:请求、响应,都是:行、头、体
- 内容简单:除了体,其他均为 ASCII 内容
- 应用广泛:至于体,支持 JSON、HTML、XML、HTML、图片、视频、音乐
- 跨平台兼容性:电脑、电视、手机、智能家居
有冒号的是头 头完了两个换行是体
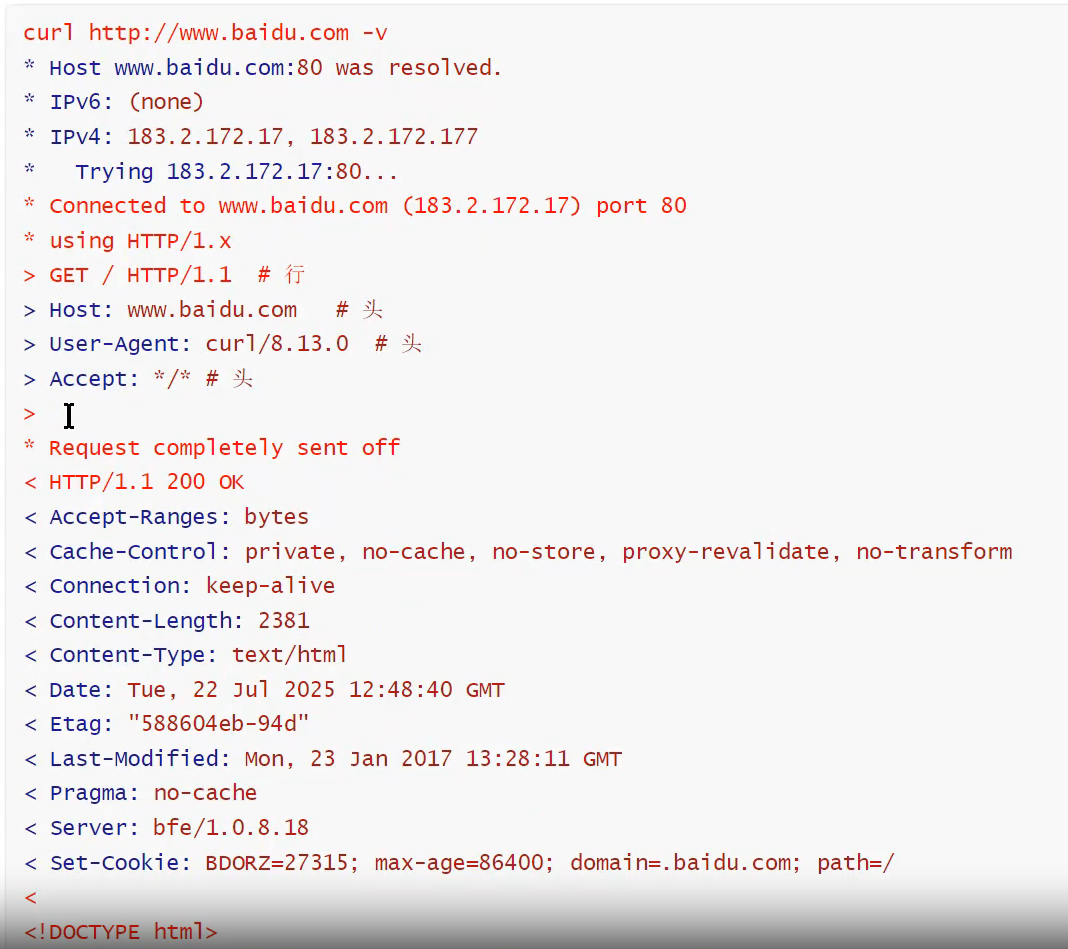
请求
行:方法(GET POST等)
头:描述(修饰)体
体:无限可能
响应
行:状态码
头:描述(修饰)体
缓存:CacheControl, Last-Modified
内容:Content-Type,Content-Length
体:无限可能
三、 接口测试工具实操
fiddler 的测试步骤:
1. 配置代理,使 Fiddler 录制请求
2. 点击 Replay and Edit,修改参数:构造的测试用例
3. 点击 Run、Start,发送修改后的请求,得到新的响应
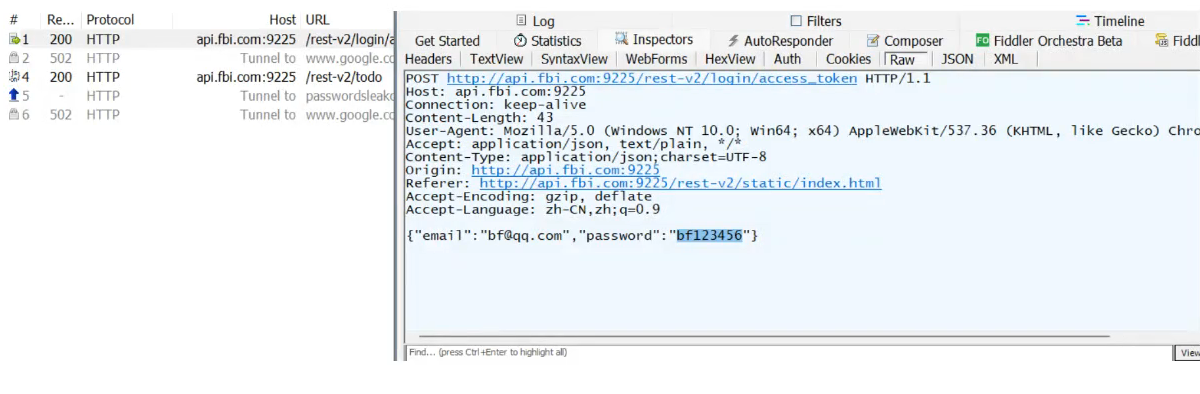
优势:
- 基于真实的请求,有连贯业务场景
- 进行底层的精细化的操作
- 配套的相关请求,由客户端完成,降低使用门槛
高颜值的 半自动化的接口测试工具:postman
完全自动化就是自己写python代码啦
四、自动化测试的流程
-
分析文档(理解需求)
- 核心功能
- 登录:
- 方法:post
- url: http://api.fbi.com:9225/rest-v2/login/access_token
- body:
- password
- 创建任务:
- 方法:post
- url: http://api.fbi.com:9225/rest-v2/todo
- body:
- title(选填)
- is_done(选填)
- 查询任务列表
- 方法:get
- url: http://api.fbi.com:9225/rest-v2/todo
- 参数:
- page(选填)
- size(选填)
- 删除任务:
- 方法:delete
- url: http://api.fbi.com:9225/rest-v2/todo/{todo_id}
- 参数:
- todo_id
- 登录:
- 次要功能
- 辅助功能
- 理解:
- 有些接口有安全性要求:需要先登录再使用
- 任务 id:需要动态获取(接口关联)
- 核心功能
2. 设计用例
- 用例标题:验证登录账号可删除任务
- 前置条件:
- 已登录(得到了身份信息)
- 有任务(已经创建待删除的任务)
- 测试步骤:
- 得到任务 ID
- 调用删除接口(结果 1)
- 调用查询接口(结果 2)
- 断言(验证结果):
- 结果 1 成功
- 结果 2 失败
3. 数据准备
数据驱动测试的数据⽂件
4. 编写脚本
- 1. 纯代码脚本
- 2. 框架的⽤例
5. 执⾏步骤
6. 断⾔结果
五、接口客户端 requests
HTTP 协议客户端事实上的标准:
- 不支持异步
- 不支持 HTTP2
pip install requests pytest jsonptah -i https://mirrors.aliyun.com/pypi/simple/
import requestsresp = requests.get("http://www.baidu.com")print(resp.status_code)requests.request 参数
表单
import requests# 1. 登录
resp = requests.request(method='post',url="http://api.fbi.com:9225/rest-v2/login/access_token",data={"email": "bf@qq.com","password": "bf123456"}
)print(resp.status_code) # 人工判断
if resp.status_code == 200: # 自动判断print('成功')
else:print('失败')
json
import requests# 1. 登录
resp = requests.request(method='post',url="http://api.fbi.com:9225/rest-v2/login/access_token",json={"email": "bf@qq.com","password": "bf123456"}
)print(resp.status_code) # 人工判断if resp.status_code == 200: # 自动判断print('成功')
else:print('失败')
文件
import requests# 1. 登录
resp = requests.request(method='post',url="http://api.fbi.com:9225/rest-v2/login/access_token",files={"email": open("详细信息显示.mp4", "rb"),"password": open("惺惺惜惺惺.mp4", "rb"),}
)print(resp.status_code) # 人工判断
if resp.status_code == 200: # 自动判断print('成功')
else:print('失败')
requests.Response属性
状态码
响应头
resp = requests.request(method='get',url="http://www.baidu.com",
)print("行:", resp.status_code, resp.reason)
print("头:", resp.headers, )
print("头:", dict(resp.cookies), )
响应体
print(resp.content) # 二进制:传输
print(resp.text) # 文本:阅读
print(resp.json()) # 字典:使用 可能失败
print(resp.json()['token_type'])
requests.Session概念
cookies /session
(有多个请求构成的)同一个对话过程
共享参数
请求头(身份凭据)
共享网络
HTTP 协议基于 TCP,握手、挥手
最大端口 65535,其中 1024 保留
共享 cookies
🌰 示例场景:模拟用户登录知乎
假设我们使用requests.Session模拟用户登录知乎,并在登录后访问个人主页:
- 第一次请求:访问登录页面(获取初始 Cookies)
- 第二次请求:提交登录表单(服务器验证并设置身份 Cookies)
- 第三次请求:访问个人主页(自动携带登录态 Cookies)
🚀 代码演示与解析
import requests# 创建Session对象(核心:自动管理Cookies)
session = requests.Session()# 1. 第一次请求:访问登录页面(获取初始Cookies)
response1 = session.get('https://www.zhihu.com/signin')
print(f"第一次请求后Session中的Cookies: {session.cookies.get_dict()}")
# 输出示例: {'_zap': 'xxx', 'd_c0': 'yyy'}
第一次请求详细过程:
- 客户端发送请求:
GET https://www.zhihu.com/signin(无 Cookies) - 服务器响应:
- 返回登录页面 HTML
- 设置初始 Cookies(如
_zap=xxx; d_c0=yyy)
Session自动捕获并存储这些 Cookies- 此时
session.cookies包含:{'_zap': 'xxx', 'd_c0': 'yyy'}
- 此时
# 2. 第二次请求:提交登录表单(携带初始Cookies,获取身份Cookies)
response2 = session.post(url='https://www.zhihu.com/api/v3/oauth/sign_in',json={'username': 'test@example.com', 'password': '123456'}
)
print(f"第二次请求后Session中的Cookies: {session.cookies.get_dict()}")
# 输出示例: {'_zap': 'xxx', 'd_c0': 'yyy', 'z_c0': 'token123'}
第二次请求详细过程:
- 客户端发送请求:
- 请求头自动携带第一次获取的 Cookies:
Cookie: _zap=xxx; d_c0=yyy - 请求体:
{"username": "test@example.com", "password": "123456"}
- 请求头自动携带第一次获取的 Cookies:
- 服务器响应:
- 验证登录信息
- 设置身份 Cookies(如
z_c0=token123,表示用户已登录)
Session更新 Cookies:- 合并新 Cookies:
{'_zap': 'xxx', 'd_c0': 'yyy', 'z_c0': 'token123'}
- 合并新 Cookies:
# 3. 第三次请求:访问个人主页(自动携带所有Cookies)
response3 = session.get('https://www.zhihu.com/settings/profile')
print(f"第三次请求后Session中的Cookies: {session.cookies.get_dict()}")
# 输出示例: {'_zap': 'xxx', 'd_c0': 'yyy', 'z_c0': 'token123'}
第三次请求详细过程:
- 客户端发送请求:
- 请求头自动携带所有 Cookies:
Cookie: _zap=xxx; d_c0=yyy; z_c0=token123
- 请求头自动携带所有 Cookies:
- 服务器响应:
- 验证
z_c0身份令牌 - 返回个人主页内容(只有登录用户可见)
- 验证
📊 三次请求对比表
| 请求步骤 | 请求 URL | 请求携带的 Cookies | 服务器返回的 Cookies | 最终 Session 中 Cookies |
|---|---|---|---|---|
| 第一次 | /signin | 无 | _zap=xxx; d_c0=yyy | {'_zap': 'xxx', 'd_c0': 'yyy'} |
| 第二次 | /api/v3/oauth/sign_in | _zap=xxx; d_c0=yyy | z_c0=token123 | {'_zap': 'xxx', 'd_c0': 'yyy', 'z_c0': 'token123'} |
| 第三次 | /settings/profile | _zap=xxx; d_c0=yyy; z_c0=token123 | 无(或更新已有 Cookies) | {'_zap': 'xxx', 'd_c0': 'yyy', 'z_c0': 'token123'} |
🔑 关键结论
- Cookies 自动传递:
Session会自动在后续请求中携带之前获取的所有 Cookies,无需手动干预。 - Cookies 自动合并:如果服务器返回新的 Cookies(如登录后的身份令牌),
Session会自动合并(覆盖同名 Cookies,保留不同名的)。 - 会话一致性:整个过程模拟了真实浏览器的行为,确保多个请求属于同一个用户会话。
🛠️ 调试技巧
如果你想查看每次请求的详细信息(包括请求头、响应头等),可以添加以下代码:
# 打印请求信息(包含Cookies)
print(f"请求URL: {response1.request.url}")
print(f"请求头: {response1.request.headers}")
print(f"响应状态码: {response1.status_code}")
print(f"响应头: {response1.headers}")六、关联请求
接口关联:使用另一个接口的响应内容,作为下一个接口的请求参数
- 大部分接口都需要:共享参数
- 个别接口才需要:全局变量
其他的提取方式:re、jsonpath
jsonpath 用法:
- 针对字典
- 使用 jsonpath 语法
- 返回列表
import jsonpathtoken = jsonpath.jsonpath(resp.json(), "$.access_token")[0]s.headers.update({"Authorization": f"bearer {token}"})
jsonpath 讲解 🧐
jsonpath 是用于从 JSON 数据(Python 中常表现为字典、列表嵌套结构 )里提取特定内容的工具,类似字符串处理里的正则表达式,但专为 JSON 结构设计,在接口关联(从接口响应提取数据给下一个接口用)场景超实用,核心要点如下:
1. 基础作用 🎯
从复杂 JSON 结构里,按路径规则精准提取值。比如接口返回如下 JSON 数据(登录接口返回带 access_token ):
{ "code": 200, "data": { "access_token": "abc123", "expires_in": 3600 }, "msg": "success"
}
想提取 access_token,就可以用 jsonpath 按路径 $.data.access_token 快速拿到。
2. 语法规则(常用) 📖
| 语法符号 | 含义 | 示例 & 效果 |
|---|---|---|
$ | 根节点(整个 JSON 数据的入口) | $.data → 提取 data 字典内容:{"access_token": "abc123", "expires_in": 3600} |
. | 取子节点、对象属性 | $.data.access_token → 提取 access_token 值:abc123 |
[] | 取列表元素、过滤对象(索引 / 条件) | - 列表取值:$.data.users[0](假设 users 是列表,取第 1 个元素)- 过滤: $.data.users[?(@.age>18)](取 users 里 age 大于 18 的对象) |
3. 在代码里的使用步骤(结合接口关联场景) 💻
以登录后拿 token 给后续接口用为例:
import requests
import jsonpath # 1. 发送登录接口请求,拿到响应
login_url = "http://api.example.com/login"
login_data = {"username": "test", "password": "123"}
resp = requests.post(login_url, json=login_data) # 2. 用 jsonpath 提取 access_token(假设响应是 JSON 格式)
# resp.json() 把响应转成 Python 字典/列表,jsonpath 按规则提取
token_list = jsonpath.jsonpath(resp.json(), "$.data.access_token")
# jsonpath 返回列表,提取第 1 个元素(实际场景需判断列表非空)
token = token_list[0] if token_list else None # 3. 把 token 放到请求头,给后续接口用(比如带 Authorization)
s = requests.Session()
s.headers.update({"Authorization": f"bearer {token}"}) # 4. 后续接口请求自动带 token(实现接口关联)
user_info_url = "http://api.example.com/userinfo"
user_resp = s.get(user_info_url)
4. 常见场景 & 优势 🌟
- 接口关联必备:登录接口返回的
token、创建订单返回的order_id等,用jsonpath能轻松提取,传给下一个接口当参数。 - 处理复杂结构:如果 JSON 嵌套很深(比如多层字典、列表混合),用
.逐层找属性,比 Python 手动写循环 / 字典取值简洁太多。 - 兼容性:不管是
requests响应转的字典,还是普通 JSON 格式字符串转的字典,都能处理,只要结构符合 JSON 规范。
5. 注意事项 ⚠️
jsonpath.jsonpath()返回列表,如果没找到匹配内容,返回False而不是空列表!所以实际用的时候,建议判断一下:-
result = jsonpath.jsonpath(data, "$.xxx") if result: value = result[0] else: # 处理提取失败逻辑,比如抛异常、设默认值 raise ValueError("提取 xxx 失败") - 语法别和 Python 字典取值搞混,
jsonpath用$.data.access_token,Python 原生是data["access_token"],但jsonpath更适合复杂结构遍历。
简单说,jsonpath 就是为 JSON 提取而生的 “导航仪”,按路径找数据超方便,接口自动化里处理响应、做关联请求必学~ 结合代码多试几个嵌套结构,就能快速掌握啦 ✨
七、完整的自动化实战
import requests
import jsonpath# 0. 创建会话,共享参数和网络链接
s = requests.Session()
test_user = "bf@qq.com"
test_pass = "bf123456"# 1. 登录
resp = s.request(method='post',url="http://api.fbi.com:9225/rest-v2/login/access_token",json={"email": test_user,"password": test_pass}
)if resp.status_code == 200: # 自动判断print('登录成功')
else:print('登录失败')# 共享参数(身份凭据)
token = jsonpath.jsonpath(resp.json(), "$.access_token")[0]
s.headers.update({"Authorization": f"bearer {token}"})# 2. 查询任务列表
resp = s.request("get","http://api.fbi.com:9225/rest-v2/todo",
)if resp.status_code == 200:print('查询任务列表成功')total = resp.json()['total']print(f"当前任务总数: {total}")# 3. 创建任务
resp = s.request("post","http://api.fbi.com:9225/rest-v2/todo",json={"title": "新的任务", "is_done": False}
)if resp.status_code == 200:print('创建任务成功')# 提取变量,以便关联new_id = jsonpath.jsonpath(resp.json(), "$.id")[0]print(f"新创建的任务ID: {new_id}")# 4. 再次查询任务列表
resp = s.request("get","http://api.fbi.com:9225/rest-v2/todo",
)if resp.status_code == 200:print('再次查询任务列表成功')new_total = resp.json()['total']print(f"当前任务总数: {new_total}")if new_total == total + 1:print('任务创建验证成功')# 5. 删除任务
resp = s.request("delete",f"http://api.fbi.com:9225/rest-v2/todo/{new_id}",
)if resp.status_code == 200:print('删除任务成功')# 6. 再次查询任务列表
resp = s.request("get","http://api.fbi.com:9225/rest-v2/todo",
)if resp.status_code == 200:print('最后一次查询任务列表成功')renew_total = resp.json()['total']print(f"当前任务总数: {renew_total}")if renew_total == new_total - 1:print('任务删除验证成功')if renew_total == total:print('任务总数恢复验证成功')
在 API 认证中,Bearer 是一种常见的身份验证方案,用于在 HTTP 请求中传递令牌(Token),表明请求者的身份。它是 OAuth 2.0 协议的一部分,也是现代 API 最常用的认证方式之一。
📜 Bearer Token 的基本概念
Bearer 本质是一个授权类型(Authorization Type),告诉服务器:“我持有这个令牌,请验证我的身份”。它的格式通常是:
Authorization: Bearer <token>
Bearer:固定关键字,表示使用令牌认证。<token>:服务器颁发的唯一身份令牌(如 JWT、Access Token)。
🔐 为什么需要 Bearer?
在传统的认证方式(如 Basic Auth)中,用户凭证(用户名 + 密码)会直接暴露在请求中,存在安全风险。而 Bearer Token 允许用户通过无状态、一次性的令牌访问受保护资源,避免了直接传递敏感信息。
常见场景:
- 用户登录后,服务器返回一个 Token(如 JWT)。
- 客户端在后续请求中携带这个 Token,无需再次登录。
- 服务器验证 Token 有效性,确认请求者身份。
🚀 代码中的 Bearer 实现
Bearer 用于传递登录后获取的 access_token:
# 登录后提取Token
token = jsonpath.jsonpath(resp.json(), "$.access_token")[0]# 将Token添加到请求头,格式为 "Bearer <token>"
s.headers.update({"Authorization": f"bearer {token}"})
- 注意大小写:标准写法是
Bearer(首字母大写),但有些服务器可能不区分大小写。
🔒 安全注意事项
-
Token 泄露风险:Bearer Token 相当于 “数字钥匙”,一旦泄露,攻击者可冒充用户访问系统。因此:
- 永远不要在 URL、日志或客户端代码中明文存储 Token。
- 优先使用 HTTPS 确保传输安全。
- 为 Token 设置合理的过期时间(如 2 小时)。
-
防止 CSRF 攻击:Bearer Token 通常用于 API 请求,需配合同源策略(Same-Origin Policy)或 CSRF 令牌保护。
🤔 Bearer vs. 其他认证方式
| 认证方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Bearer Token | 无状态、易于扩展、支持跨域 | Token 泄露风险高 | REST API、前后端分离 |
| Basic Auth | 简单、标准 | 明文传输密码,安全性低 | 内部系统、临时访问 |
| OAuth 2.0 | 第三方授权、细粒度权限控制 | 实现复杂 | 开放平台(如微信登录) |
🌟 总结
Bearer 是一种通过令牌进行身份验证的机制,在现代 API 中广泛使用。它的核心是将服务器颁发的 Token 放在请求头中,格式为 Authorization: Bearer <token>,从而实现安全、无状态的身份验证。
total = resp.json()['total'] 是从 API 响应中提取数据的关键步骤!我来拆解一下它的含义和作用~ 🧐
1. 代码拆解:分步解释
① resp.json()
resp是requests发送请求后得到的响应对象。resp.json()是将响应内容(通常是 JSON 格式的字符串)解析为 Python 字典或列表。
例如,如果响应是{"code": 200, "total": 10},则resp.json()返回{'code': 200, 'total': 10}。
② ['total']
- 从解析后的字典中,通过键(Key)
'total'提取对应的值。
例如,上面的例子中resp.json()['total']就是10。
2. 结合场景理解
这行代码出现在 查询任务列表 的步骤中:
# 查询任务列表
resp = s.request("get", "http://api.fbi.com:9225/rest-v2/todo")
if resp.status_code == 200:total = resp.json()['total'] # 提取任务总数
假设 API 返回的 JSON 是这样的:
{"code": 200,"message": "success","data": {"items": [{"id": 1, "title": "任务1"},{"id": 2, "title": "任务2"}],"total": 2 # 这是任务总数}
}
那么 resp.json()['total'] 就会提取出 2,表示当前有 2 个任务。
3. 为什么需要这个值?
在自动化测试中,这个值通常用于 验证业务逻辑:
- 比如创建新任务后,检查总数是否增加 1。
- 删除任务后,检查总数是否减少 1。
# 创建任务前的总数
total = resp.json()['total'] # 创建任务...# 创建后的总数
new_total = resp.json()['total'] # 验证总数是否增加1
if new_total == total + 1:print('任务创建验证成功')
4. 潜在风险与优化
① Key 不存在的情况
如果 API 返回的 JSON 中没有 total 键,直接访问会报错。
优化建议:使用 .get() 方法,不存在时返回默认值(如 None)。
total = resp.json().get('total') # 不存在时返回None
if total is not None:# 处理逻辑
else:print("响应中缺少'total'字段")
② 响应格式变化
如果 API 升级后返回格式变了(如 total 移到 data.total),代码会失效。
优化建议:使用 jsonpath 更灵活地提取数据(已经在用啦!)。
total = jsonpath.jsonpath(resp.json(), '$.total')[0] # 更健壮的写法
🌟 总结
这行代码的核心作用是:从 API 响应中提取 任务总数,用于后续的业务逻辑验证(如创建 / 删除任务后检查数量变化)。它是接口自动化测试中 数据断言 的关键步骤!





)






)

)




