目录
项目简介
要求
需要考虑的问题
硬件需求和环境配置
n卡驱动配置
以cuda11.8 版本为例
下载对应的cudnn(version11+)
安装GPU版本的torch
安装gpu版本的TensorFlow
检查cuda安装情况
项目简介
训练一个模型,实现歌词仿写生成
任务类型:文本生成;
数据集是一份歌词语料,训练一个模型仿写歌词。
要求
1.清洗数据。歌词语料中包含韩文等非中英文符号,可对语料做预处理,仅保留中英文与标点符号;
2.训练模型、生成歌词;
3.用Gradio网页展示生成的歌词;
需要考虑的问题
1.使用语料数据集csv:lyric.csv,不用到数据库;
2.硬件使用的gpu是5g的n卡,比较有限,项目本身数据量和模型参数规模都不是特别大;
3.使用tensorflow2.9.1gpu版本的框架进行构建;
4.使用的网络架构,以及每个部分的组件网络、骨干网络等,优先在各个环节选用目前的sota模型;
5.在模型训练过程中要使用tensorboard可视化训练过程;6.对于数据的处理,先对csv进行必要的可视化,然后进行多语言歌词清洗(可参考的步骤:多语言过滤、特殊格式处理、分词策略、序列对齐、同义词替换、句式重组等);7.项目构建严格规范文件架构,做到一个脚本做一个环节(数据预处理脚本、模型构建脚本、训练、测试、推理等等);
硬件需求和环境配置
n卡驱动配置
以cuda11.8 版本为例
CUDA Toolkit 11.8 Downloads | NVIDIA Developer







该提示是说未找到支持版本的 Visual Studio ,部分 CUDA 工具包组件可能无法正常工作,建议先安装 Visual Studio 。若你:
不打算在 Visual Studio 中使用 CUDA 开发:勾选 “I understand, and wish to continue the installation regardless.”,然后点击 “NEXT” 继续安装 CUDA,不影响 CUDA 在其他场景或非集成开发环境下的基本使用。
后续有在 Visual Studio 中进行 CUDA 开发的计划:可先停止 CUDA 安装,安装合适版本的 Visual Studio(CUDA 不同版本对应支持特定的 Visual Studio 版本,需提前确认适配关系 ),之后再重新安装 CUDA。



建议就默认安装路径,方便后续管理
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
添加环境变量
CUDA_PATH和CUDA_PATH_V11.8

添加后查看 cmd里输入
nvcc -V

cuda toolkit就安装完成
下载对应的cudnn(version11+)
跑深度学习任务还需要对应版本的cudnn,才能在执行模型训练等脚本时调用到gpu
cuDNN Archive | NVIDIA Developer


因为限制,国内无法注册nvidia账号,所以不能直接从官网下载,需要另找资源
需要这两个包

获取之后解压
cudnn

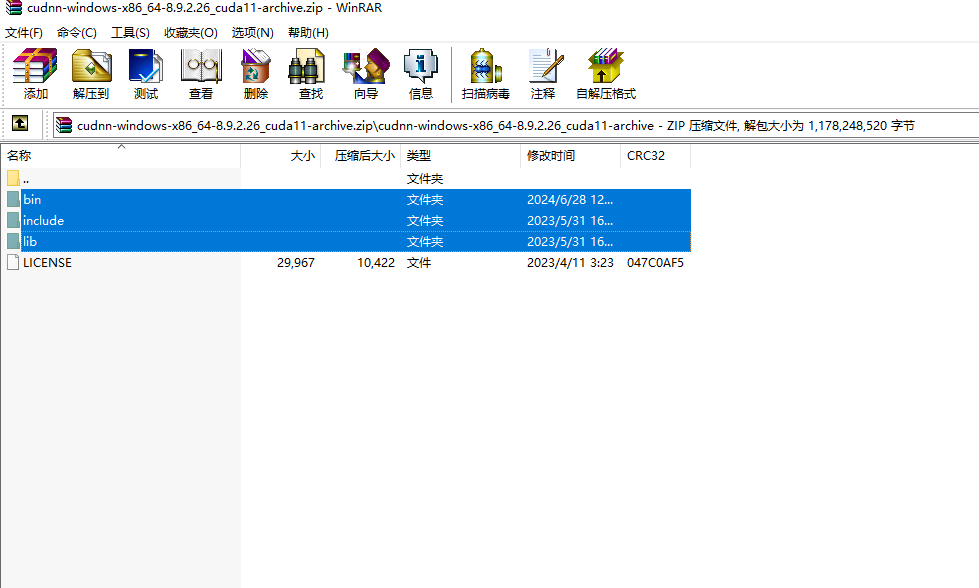
将这三个(bin include lib)复制,合并到上面下载cuda的目录下(要到对应版本的目录)

粘贴进去
然后来到这个路径下
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\extras\demo_suite
查看是否存在这两个文件
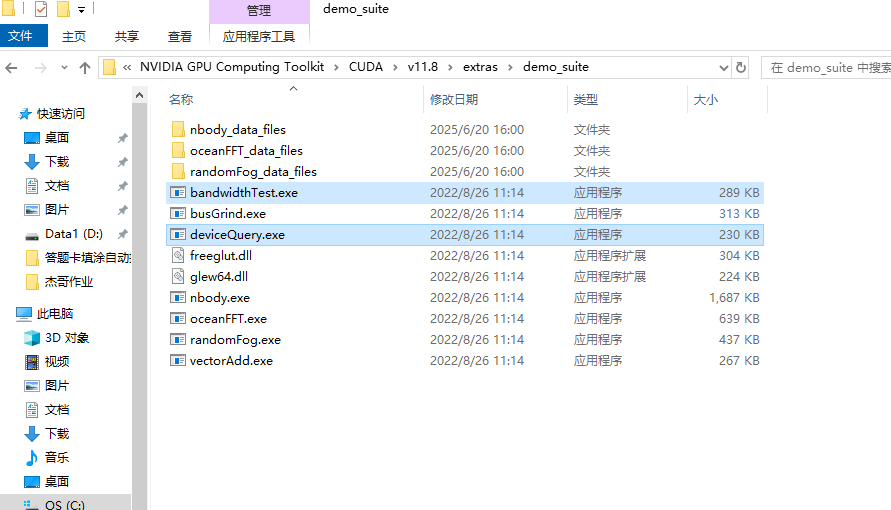
打开cmd
进入这个路径

依次执行
bandwidthTest.exe

看到末尾有‘PASS’说明成功

deviceQuery.exe


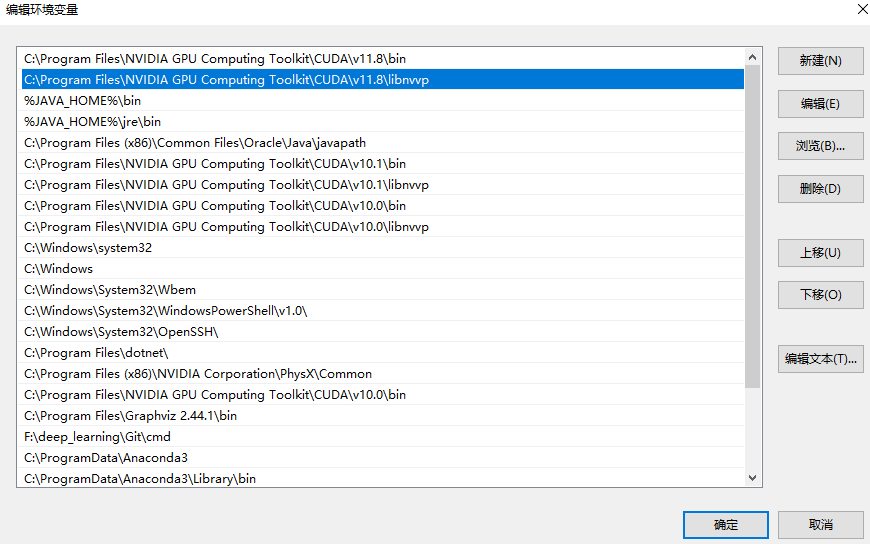
最后添加、检查系统环境变量
Path中

需要有这三个路径


安装GPU版本的torch
版本是2.3.0 这个版本和cuda11.8 cudnn11.8兼容性较好 目前也使用得比较多
下载torch torchvision torchaudio
pip install torch==2.3.0 --index-url https://download.pytorch.org/whl/cu118
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ torchvision==0.14.0
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ torchaudio==2.3.0
测试脚本
import torch
import platformdef test_pytorch_gpu():"""测试当前环境中PyTorch与GPU的兼容性"""print(f"Python版本: {platform.python_version()}")print(f"PyTorch版本: {torch.__version__}")# 检查CUDA是否可用if torch.cuda.is_available():print("\n=== CUDA 可用 ===")print(f"CUDA版本: {torch.version.cuda}")print(f"GPU数量: {torch.cuda.device_count()}")# 获取并打印第一个GPU的信息
gpu_name = torch.cuda.get_device_name(0)print(f"第一个GPU: {gpu_name}")# 创建张量并在GPU上执行简单运算try:# 创建在GPU上的张量
x = torch.tensor([1.0, 2.0], device='cuda')
y = torch.tensor([3.0, 4.0], device='cuda')# 执行加法运算
z = x + y# 将结果传回CPU并打印print(f"\n在GPU上执行运算: {x} + {y} = {z.cpu().numpy()}")# 测试CUDA流
stream = torch.cuda.Stream()with torch.cuda.stream(stream):
a = torch.ones(1000, 1000, device='cuda')
b = a * 2
c = b.mean()
torch.cuda.synchronize()print("CUDA流测试成功")print("\nPyTorch与GPU环境兼容正常!")return Trueexcept Exception as e:print(f"\nGPU运算测试失败: {str(e)}")print("PyTorch与GPU环境存在兼容性问题!")return Falseelse:print("\n=== CUDA 不可用 ===")print("PyTorch未检测到可用的CUDA设备")print("可能原因: 没有NVIDIA GPU、驱动未安装或PyTorch版本与CUDA不匹配")# 检查是否有MPS (Apple Silicon) 支持if hasattr(torch, 'has_mps') and torch.has_mps:print("\nMPS (Apple Silicon) 支持已检测到")print("提示: 当前测试针对CUDA GPU,建议在NVIDIA GPU环境下运行")return Falseif __name__ == "__main__":
test_pytorch_gpu()
看到这个表示框架和软硬件环境兼容了


安装gpu版本的TensorFlow
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ tensorflow-gpu==2.9.1
# 深度学习框架
# tensorflow-gpu==2.9.1
# keras==2.9.0


测试安装
import tensorflow as tfdef test_tensorflow_gpu():"""测试TensorFlow-GPU与CUDA的兼容性"""try:# 检查TensorFlow版本
tf_version = tf.__version__print(f"TensorFlow版本: {tf_version}")# 检查GPU是否可用
gpus = tf.config.list_physical_devices('GPU')if not gpus:print("未发现GPU设备。请确保安装了正确的GPU驱动和CUDA工具包。")returnprint(f"发现{len(gpus)}个GPU设备:")for gpu in gpus:print(f" - {gpu}")# 测试GPU计算with tf.device('/GPU:0'):
a = tf.constant([1.0, 2.0, 3.0], shape=[1, 3])
b = tf.constant([1.0, 2.0, 3.0], shape=[3, 1])
c = tf.matmul(a, b)print("GPU计算测试成功!")print(f"计算结果: {c.numpy()}")# 检查CUDA版本兼容性try:# 获取TensorFlow编译时的CUDA版本
cuda_compile_version = tf.sysconfig.get_build_info()['cuda_version']print(f"TensorFlow编译时使用的CUDA版本: {cuda_compile_version}")# 获取运行时CUDA版本(通过TensorFlow)
runtime_cuda_version = tf.test.is_built_with_cuda()if runtime_cuda_version:print("TensorFlow已启用CUDA支持。")else:print("TensorFlow未启用CUDA支持,可能无法使用GPU。")# 尝试获取更详细的CUDA运行时版本try:from tensorflow.python.platform import build_info
cuda_version = build_info.cuda_version_number
cudnn_version = build_info.cudnn_version_numberprint(f"TensorFlow使用的CUDA版本: {cuda_version}")print(f"TensorFlow使用的cuDNN版本: {cudnn_version}")except Exception as e:print(f"无法获取详细的CUDA/cuDNN版本信息: {e}")# 检查GPU驱动版本try:from tensorflow.python.client import device_lib
local_device_protos = device_lib.list_local_devices()for x in local_device_protos:if x.device_type == 'GPU':print(f"GPU驱动信息: {x.physical_device_desc}")except Exception as e:print(f"无法获取GPU驱动信息: {e}")except Exception as e:print(f"CUDA版本检查失败: {e}")print("请手动检查您的CUDA版本是否与TensorFlow兼容。")print("TensorFlow CUDA兼容性矩阵: https://www.tensorflow.org/install/source#gpu")except Exception as e:print(f"测试过程中发生错误: {e}")if __name__ == "__main__":
test_tensorflow_gpu()
检查cuda安装情况
NVIDIA 显卡:使用 nvidia-smi 命令
若已安装 NVIDIA 驱动,输入:
nvidia-smi
可查看:
GPU 型号、驱动版本、CUDA 版本。
显存使用情况、GPU 温度、功耗等实时数据。

需要电脑有配置5G及以上显存的显卡,这里我使用n卡
再配置conda环境,创建一个项目环境
这是我的显卡信息,现在用conda创建一个支持tensorflow2.x版本(同时tf编写的源代码使用的是2版本以下的numpy,降级numpy到2以下才能正常使用tf)的conda环境,注意python版本:
conda create -n nlp_tf python=3.9

完成后输入conda activate nlp_tf启动环境
在环境里下载tensorflow-gpu版本2.x以上
用华为云安装:
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ tensorflow-gpu==2.9.1
# pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ tensorflow==2.5.0


tensorflow安装成功(目前很多镜像源都下不成功,用华为云的源还可以,如果也不行只能自行再找找镜像站或者资源)

在编译器里面激活环境并更改解释器

 案例详解)









)

)






