目录
题型
总结
编译五大组成部分
编译与解释方式区别?
前端,后端,Why?
概念
推导、归约
短语、简单短语、句柄
文法
分类
正则文法(3型)
NFA、DFA、最小化
自上而下语法分析(推导)
判断是否是LL(1)文法
消除左递归
求FISRST集、FOLLOW集
FIRST
FOLLOW
预测分析法
构造预测分析表
自下而上语法分析
*自上而下分析法,也称为“移进-归约”法,其一般过程为:
算符优先分析法
算符文法:
FIRSTVT、LASTVT
算符优先文法
过程
素短语、最左素短语
LR分析法
基本思想:
语法制导翻译
中间代码的表示形式
三地址代码
四元式
三元式
三元式和四元式的比较:
间接三元式
语句的翻译while、if、数组
数组
if
while
符号表组织方式
运行时存储
嵌套过程语言的栈式实现
1.带有静态链的活动记录
2.带有Display的活动记录(小本)
优化
基本块
编辑
循环
题型
判断5*2
选择10*2
简答3*5
综合5*11
总结
编译五大组成部分
更详细见【编译原理】一二章-CSDN博客

编译与解释方式区别?
编译是将源程序翻译成可执行的目标代码;不产生目标程序,边解释边执行
C语言和C++都是典型的编译型语言,它们的源代码需要被编译器完全编译成机器码才能执行。编译后生成的可执行文件直接在操作系统上运行,不需要虚拟机或解释器。
Java比较特别,它需要编译成字节码,然后由JVM解释执行或者通过JIT编译执行。所以严格来说,Java是编译和解释混合型的。
Python通常被认为是解释型语言,代码由解释器逐行执行。不过现在也有像PyPy这样的实现使用JIT编译,或者将Python代码编译成字节码(比如.pyc文件)
编译程序:源语言为高级语言,目标语言为汇编语言或机器语言的翻译程序
解释程序:源语言程序作为输入,但不产生目标程序,而是边解释边执行源程序本身。
编译方式 C C++
解释方式 数据库语言
python
解释
隐式编译为字节码.pyc
java
先编译成字节码,再通过JVM(java虚拟机)解释成目标程序

前端,后端,Why?
前端--与目标机无关的部分,与源语言有关
包括分析部分(词法、语法、语义分析)、中间代码生成与优化以及这部分的符号表管理错误处理
后端--与目标机有关的部分,不依赖源语言仅仅依赖于中间语言
包括代码生成、与目标机有关的优化以及这部分的符号表管理和错误处理工作
不同前端和不同后端相互配合可以得到不同的编译器
不同语言的前端可共享同一后端(如LLVM支持C、Rust、Swift)
跨平台
编译原理详解:前端后端划分、编译器可变目标机、高级语言执行方式-CSDN博客
前端主要由与源程序有关但与目标机无关的那些部分组成。这些部分通常包括词法分析、语法分析、语义分析与中间代码的产生,有些代码优化工作也可包括在前端。后端包括编译程序中与目标机有关的那些部分,如与目标机有关的代码优化和目标机的生成等。
将编译过程划分成前端和后端,主要目的是在多种源语言和多种目标语言的开发过程中,可以灵活搭配组合,消除重复开发的工作量,提高编译系统的开发效率。前端和后端的分离是为了提高系统的可维护性和可扩展性,同时也更好地分工合作
概念
【编译原理】一二章-CSDN博客
推导、归约
短语、简单短语、句柄
简单/直接短语:只有父子两代的子树
句柄:最左直接短语
文法
文法相关习题-CSDN博客
分类
0型(递归可枚举、图灵机)
1型(上下文有关)
2型(上下文无关文法)
3型(正规文法、线性文法)


语法分析
从源程序的第一个字符开始,从左到右扫描源程序, 一次读一个字符,根据词法规则将有关字符组合成单词, 并识别各类单词,当确定单词类别后,将单词输出。
正则文法(3型)




正则文法与状态转换图等价,是指正则文法所确定 的语言L(G),与状态转换图所接受的语言L(TG)相同:
L(G)=L(TG)
NFA、DFA、最小化
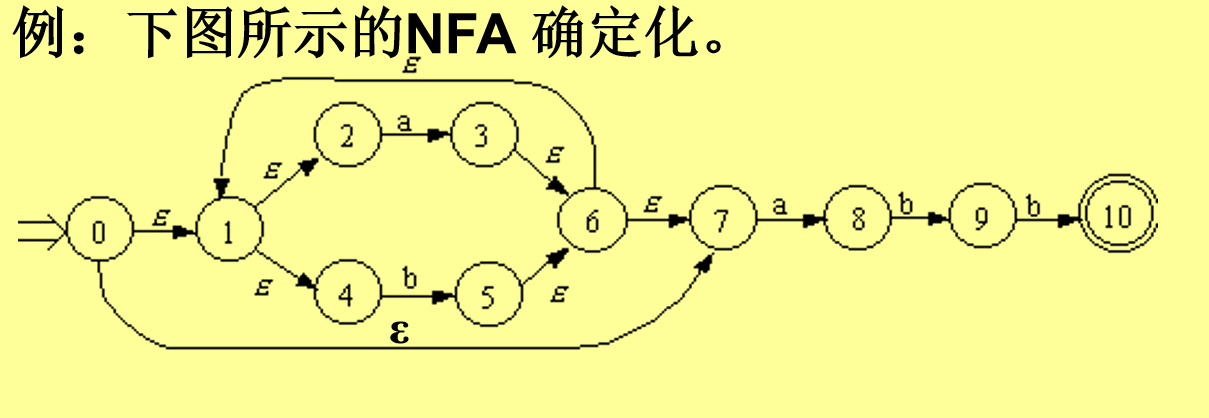
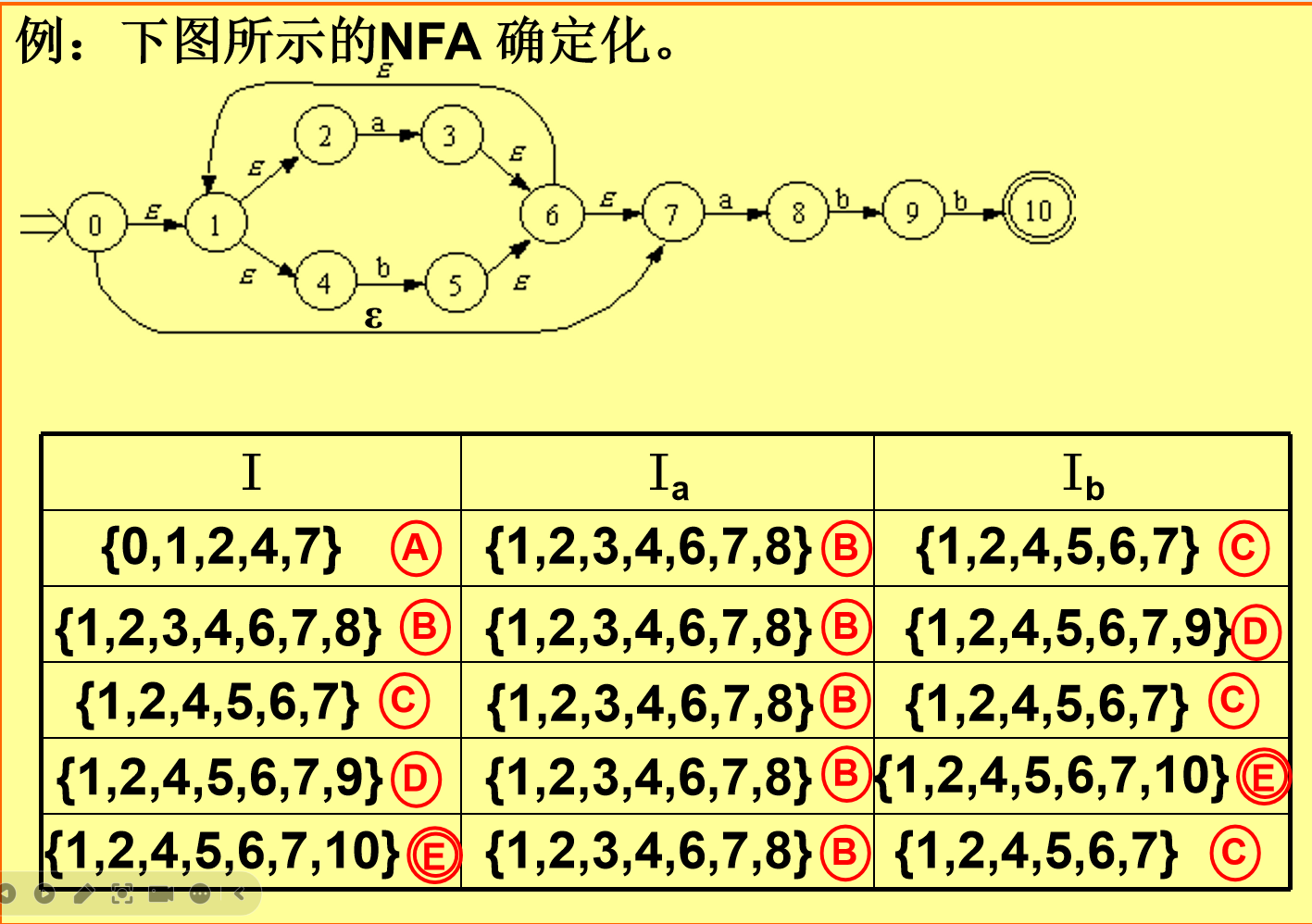









语法分析
按照文法从源程序单词串(符号串)中识别各类语法成分,判断所给出单词串是否是给定文法的正确句子,并为语义分析和代码生成做准备
自上而下语法分析(推导)
对于任一输入符号串,从文法的识别符号出 发,根据当前的输入符号,唯一确定一个产生式,用产 生式右部的符号串替代相应的非终结符往下推导,或构 造一棵语法树。若能推导出输入串或构造语法树成功则 输入串是句子,否则不是。
判断是否是LL(1)文法
该文法满足确定的自上而下的分析方法, 其中,第一个L表明自左(Left)向右扫描输入串,第二个L表明分析过程采用最左(Left)推导,括号中的1表明只需向右看一个符号便可决定选择哪个产生式进行推导。

消除左递归

P=E =+T
=T
P=T =*F
=F
求FISRST集、FOLLOW集
FIRST



FOLLOW




预测分析法
预测分析程序是一种自顶向下分析程序,预测分析
要求文法是LL(1)文法,它由分析栈、分析表和分析程序 三部分组成,其中分析表的构成与文法有关。




构造预测分析表


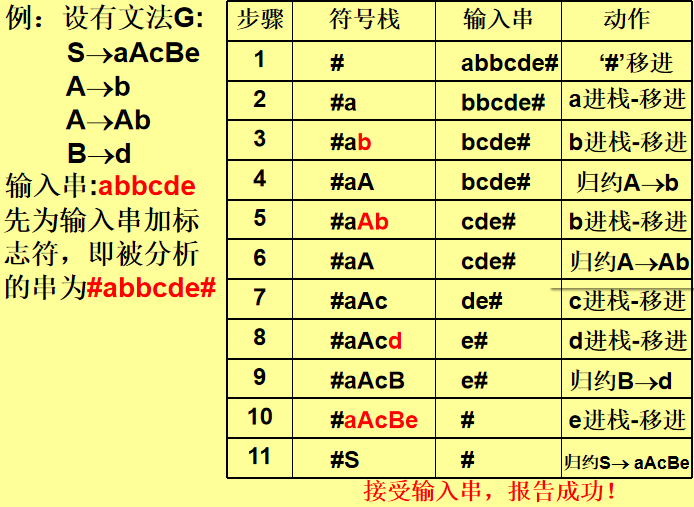
自下而上语法分析
从输入符号串开始,查找当前句柄,并用产生式将它归约成相应的非终结符,最后归约为开始符号
*自上而下分析法,也称为“移进-归约”法,其一般过程为:
(1)设置一个存放符号的栈称为符号栈,用于记录分析的过程和确定下一步的动作
(2)把输入符号串按扫描顺序逐个移进栈里(符号栈),当栈顶的符号组成的符号串形成一个句柄时(正好是某条产生式的右部),就进行归约。即把该符号串用与它对应的产生式左部的非终结符号代替,仍然置于栈顶
(3)接着检查新栈顶,若形成新的句柄,再进行归约,如没有形成新句柄,则从符号串种移进新的符号。如此重复,直到整个输入符号处理完毕为止
(4)若最终栈底为识别符号,则表明所分析的输入串合法,报告分析成功;否则是不合法的符号串,报告出错信息
注:
(1)对输入符号串的扫描,采用自左向右的顺序;
(2)分析过程是自下而上进行的(对语法树来说从末端 结点开始,最后归约到根结点);
(3)每次归约是对最左简单短语(句柄)进行的;
(4)算法的关键是确定最左简单短语。
算符优先分析法
算符优先分析法是自下而上分析方法中的一种, 虽然它不是规范(最左)归约,但它具有分析速度快,特别 适合表达式分析的特点,因而得到普遍应用。
A+B*C/D-E/F*G

算符文法:
任意产生式的右部不含有两个相继的非终结符
注:相继和相邻,相邻一定相继
FIRSTVT、LASTVT
假设有个产生式的一个候选形为
........aP........
对于任何b
FIRSTVT(P),有a
b
假设有个产生式的一个候选形为
.......Pb.....
对于任何a
b
aP
Pa
ab
aPb



算符优先文法
设有一个不含空产生式的算符文法(反应各终结符之间优先关系的优先关系矩阵),如果在任意两个终结符号之间,至多只有一种优先关系成立,则称这样的算符文法为算符优先文法 (Operator Precedence Grammar),即OPG文法。



过程
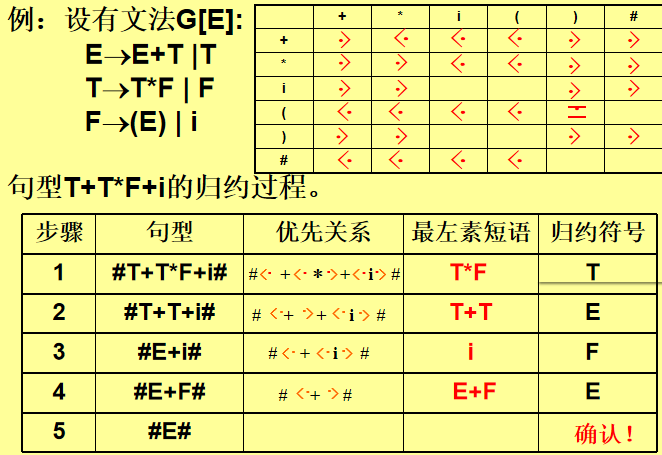
素短语、最左素短语

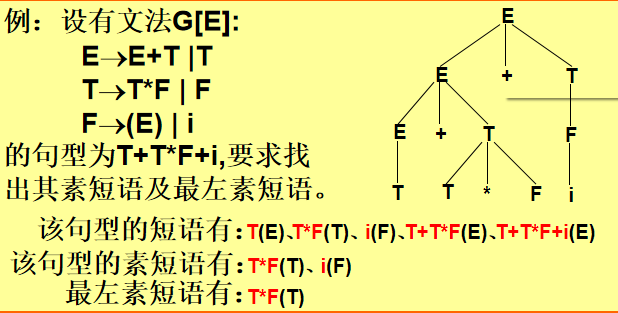
LR分析法
LR分析法是一种有效的自底向上的语法分析技术, 它能适用于大部分上下文无关文法的分析,一般叫 LR(k)分析方法,其中L是指自左(Left)向右扫描输入单 词串,R是指分析过程都是构造最右(Right)推导的逆过程(规范归约),括号中的k是指在决定当前分析动作时向 前看的符号个数。
基本思想:
在规范归约过程中,一方面记住以移进和归约出的整个符号串,即记住“历史”,另一方面根据所用的产生式推测未来可能碰到的输入符号,即对于未来进行“展望”
( 当一串貌似句柄的符号串呈现分析栈的顶端时,根据所记载的“历史”和“展望”以及“现实”的输入符号等三方面的材料,来确定栈顶的符号串是否构成相对某一产生式的句柄)

语法制导翻译
根据文法中每个产生式所蕴含的语义,为其配备一个(或多个)语法或子程序,对所要完成的功能进行描述,在语法分析过程中,当分析器使用该产生式进行语法分析时(无论是推导还是归约),除完成语法分析动作之外,还将调用为其配备的语义子程序,进行相应地语义处理,完成语义翻译工作
中间代码的表示形式
- 后缀式
- 图表示法(抽象语法树、DAG图)
- 三地址码(三元式、四元式、间接三元式)


抽象语法树



DAG图
DAG(Directed Acyclic Graph)无循环有向图, 与抽象语法树类似,但是在一个DAG中代表公共子表 达式的结点可有多个父结点。

三地址代码
最基本的形式: x=y op z
其中x、y、z为名字、常数或编译时产生的临时变量; op代表运算符号。每个语句的右边只能有一个运算符


四元式


三元式


三元式和四元式的比较:
相同点:
① 无论在一个三元式序列还是四元式序列中,各个三元式或四元式都是按相应表达式的实际运算顺序出现的;
② 对同一表达式,所需三元式或四元式个数一般都是相同的。
不同点:
① 由于三元式没有result字段,且不需要临时变量,故三元式比四元式占用的存储空间少;
②在进行代码优化处理时,在三元式中删去或移动运算的位置是很困难的,但四元式之间的相互联系是通过临时变量来实现的,所以影响就比较小。
间接三元式
建立两个与三元式有关的表格,一个称为三元式表, 用于存放各三元式本身;另一个称为执行表,它按照三 元式的执行顺序,依次列出相应各三元式在三元式表中 的位置,也就是说我们用一个三元式表连同执行表来表 示中间代码。通常我们称这种表示方法为间接三元式。


语句的翻译while、if、数组
【编译原理】语句的翻译_编译原理语句翻译-CSDN博客
数组



if




while




符号表组织方式
- 线性表
- 二叉树
- 哈希(杂凑技术)
运行时存储
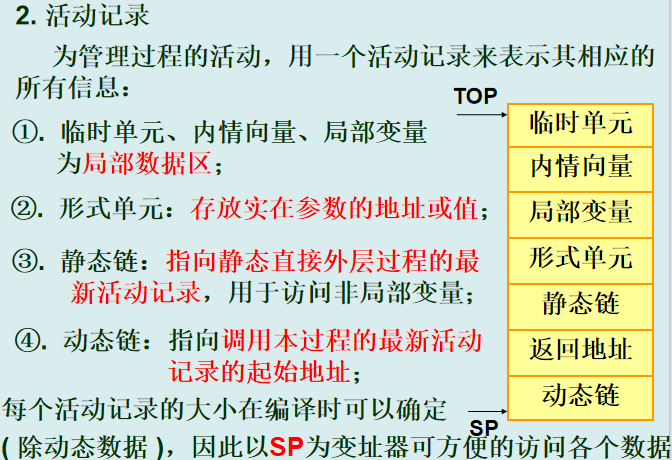
局部变量存放过程中的简单变量
内情向量存放数组变量
临时单元存放表达式计算的中间结果
形式单元存放实参的值或地址
--动态链 SP :函数调用关系,首地址
--静态链:外层、直接外层
嵌套过程语言的栈式实现

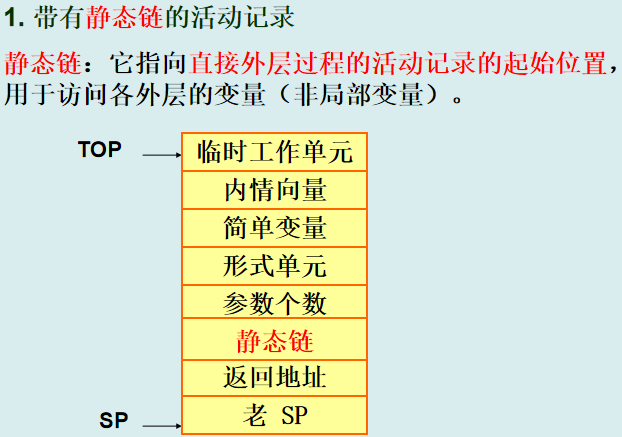
1.带有静态链的活动记录
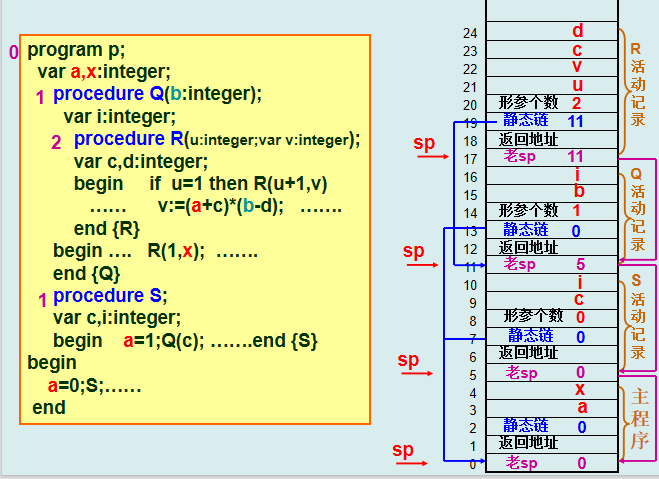
2.带有Display的活动记录(小本)

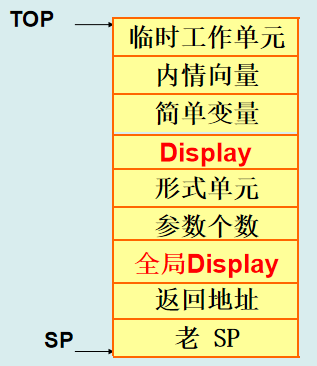
Display表是栈式结构,从栈顶到栈底,分别存放本层及各外层的最新活动记录首地址
访问外层变量,只要知道该变量的层号,就可以在Display表中取到某个过程活动记录的首地址,来访问它局部数据区的数据
如何生成Display表?
全局Display存放主调过程的display表首地址
利用全局Display,找到主调过程的display表
利用主调过程的display表,来生成被调过程的display表
如何利用主调过程的display表,生成被调过程的display表?
P1的display表包括了P1以及P1的各个外层过程的最新活动记录的首地址


从主调过程display表里面,取i项,i是被调过程的层号,然后再添加上被调过程p2自己的基地址SP,就可以得到p2的display表




7全局display=2?


优化
基本块
-
合并已知量
- 交换语句位置
- 代数变换

循环
- 删除公共子表达式(多余运算)
- 复写传播
- 删除无用代码
- 代码外提
- 强度削弱
- 删除归纳变量
- 合并已知量



)










)




