⼀ 、Redis性能压测脚本介绍
Redis的所有数据是保存在内存当中的, 得益于内存⾼效的读写性能, Redis的性能是⾮常强悍的 。但 是,内存的缺点是断电即丢失,所以 ,在实际项⽬中, Redis—旦需要保存—些重要的数据, 就不可能完全使⽤内存保存数据 。因此, 在真实项⽬中要使⽤Redis, —定需要针对应⽤场景, 对Redis的性 能进⾏估算, 从⽽在数据安全性与读写性能之间找到—个平衡点。
Redis提供了压测脚本redis-benchmark, 可以对Redis进⾏快速的基准测试。
# 20个线程,100W个请求,测试redis的set指令(写数据)
redis-benchmark -a 123qweasd -t set -n 1000000 -c 20redis-benchmark更多参数, 使⽤ redis-benchmark --help指令查看
关键结果解析:
●吞吐量(throughput):平均每秒处理约11.6万次写操作(116536.53 requests per second)。
●延迟(latency):
- avg(平均延迟):0.111毫秒。
- p50(中位数延迟):0.111毫秒。
- p95(95%请求延迟):0.167毫秒。
- max(最大延迟):3.199毫秒。
操作建议:
- 更多参数可通过redis-benchmark --help查看。
- 调整Redis部署架构后,建议多次进行对比测试以评估性能变化。
⼆ 、Redis数据持久化机制详解
1 、整体介绍Redis的数据持久化机制
官⽹介绍地址: Redis persistence | Docs
Redis提供了很多跟数据持久化相关的配置, ⼤体上, 可以组成以下⼏种策略:
.● ⽆持久化: 完全关闭数据持久化, 不保证数据安全 。相当于将Redis完全当做缓存来⽤ . RDB(RedisDatabase) :按照—定的时间间隔缓存Redis所有数据快照。
● AOF(Append Only File) :记录Redis收到的每—次写操作 。这样可以通过操作重演的⽅式恢复 Redis的数据
●RDB+AOF: 同时保存Redis的数据和操作。
两种⽅式的优缺点:
(1)RDB
● 优点:
1 )RDB⽂件⾮常紧凑, ⾮常适合定期备份数据。
2 )RDB快照⾮常适合灾难恢复。
3 )RDB备份时性能⾮常快, 对主线程的性能⼏乎没有影响 。RDB备份时, 主线程只需要启 动—个负责数据备份的⼦线程即可 。所有的备份⼯作都由⼦线程完成, 这对主线程的IO性能 ⼏乎没有影响。
4 )与AOF相⽐, RDB在进⾏⼤数据量重启时会快很多。
● 缺点:
1 )RDB不能对数据进⾏实时备份, 所以, 总会有数据丢失的可能。
2 )RDB需要fork化⼦线程的数据写⼊情况, 在fork的过程中, 需要将内存中的数据克隆— 份 。如果数据量太⼤, 或者CPU性能不是很好, RDB⽅式就容易造成Redis短暂的服务停⽤ 。相⽐之下, AOF也需要进⾏持久化, 但频率较低 。并且你可以调整⽇志重写的频率
(2) AOF
●优点:
1 )AOF持久化更安全 。例如Redis默认每秒进⾏—次AOF写⼊, 这样, 即使服务崩溃, 最多损失—秒的操作。
2)AOF的记录⽅式是在之前基础上每次追加新的操作 。因此AOF不会出现记录不完整的情 况 。即使因为—些特殊原因, 造成—个操作没有记录完整, 也可以使⽤ redis-check-aof⼯ 具轻松恢复。
3 )当AOF⽂件太⼤时, Redis会⾃动切换新的⽇志⽂件 。这样就可以防⽌单个⽂件太⼤的 问题。
4 )AOF记录操作的⽅式⾮常简单易懂, 你可以很轻松的⾃⾏调整⽇志 。⽐如, 如果你错误 的执⾏了—次 FLUSHALL 操作, 将数据误删除了 。使⽤AOF, 你可以简单的将⽇志中最后 —条FLUSHALL指令删掉, 然后重启数据库, 就可以恢复所有数据。
● 缺点:
1 )针对同样的数据集, AOF⽂件通常⽐RDB⽂件更⼤ 。
2)在写操作频繁的情况下, AOF备份的性能通常⽐RDB更慢。
整体使⽤建议:
1 )如果你只是把Redis 当做—个缓存来⽤, 可以直接关闭持久化
2 )如果你更关注数据安全性, 并且可以接受服务异常宕机时的⼩部分数据损失, 那么可以简单的使 ⽤RDB策略 。这样性能是⽐较⾼的。
3 )不建议单独使⽤AOF 。RDB配合AOF, 可以让数据恢复的过程更快。
2 、RDB详解
(1) RDB能⼲什么
RDB可以在指定的时间间隔, 备份当前时间点的内存中的全部数据集, 并保存到餐盘⽂件当中 。通常 是dump.rdb⽂件 。在恢复时, 再将磁盘中的快照⽂件直接都会到内存⾥ 。
由于RDB存的是全量数据, 你甚⾄可以直接⽤RDB来传递数据 。例如如果需要从—个Redis服务中将 数据同步到另—个Redis服务(最好是同版本), 就可以直接复制最近的RDB⽂件。
(2)相关重要配置
1)save策略: 核⼼配置
# 保存策略:<秒数> <写操作次数>,满足条件触发快照
save 3600 1 # 1小时内至少1次写操作
save 300 100 # 5分钟内至少100次写操作
save 60 10000 # 1分钟内至少10000次写操作dir /data/redis # 快照存储目录
dbfilename dump.rdb # 快照文件名
rdbcompression yes # 是否压缩(默认开启,可节省磁盘空间但消耗CPU)
stop-writes-on-bgsave-error yes # 快照失败时是否停止写入(默认开启,保证数据一致性)2) dir ⽂件⽬录
3) dbfilename ⽂件名 默认dump.rdb
4) rdbcompression 是否启⽤RDB压缩, 默认yes 。 如果不想消耗CPU进⾏压缩, 可以设置为no
5) stop-writes-oin-bgsave-error 默认yes 。如果配置成no, 表示你不在乎数据不—致或者有其他 的⼿段发现和控制这种不—致 。在快照写⼊失败时, 也能确保redis继续接受新的写⼊请求。
6)rdbchecksum 默认yes 。在存储快照后, 还可以让redis使⽤CRC64算法来进⾏数据校验, 但是这 样做会增加⼤约10%的性能消耗 。如果希望获得最⼤的性能提升, 可以关闭此功能。
(3)何时会触发RDB备份
1) 到达配置⽂件中默认的快照配置时, 会⾃动触发RDB快照
2)⼿动执⾏save或者bgsave指令时, 会触发RDB快照 。 其中save⽅法会在备份期间阻塞主线程 。 bgsve则不会阻塞主线程 。但是他会fork—个⼦线程进⾏持久化, 这个过程中会要将数据复制—份, 因此会占⽤更多内存和CPU。
3) 主从复制时会触发RDB备份。
LASTSAVE指令查看最后—次成功执⾏快照的时间 。时间是—个代表毫秒的LONG数字, 在linux中可 以使⽤date -d @{timestamp} 快速格式化。
3 、AOF详解
(1)AOF能⼲什么
以⽇志的形式记录每个写操作(读操作不记录) 。只允许追加⽂件⽽不允许改写⽂件。
(2)相关重要配置
1 )appendonly 是否开启aof 。 默认是不开启的。
2)appendfilename ⽂件名称。
appendfilename "appendonly.aof"Redis7中, 对⽂件名称做了调整 。原本只是—个⽂件, 现在换成了三个⽂件 。base.rdb⽂件即⼆进 制的数据⽂件 。incr.aof是增量的操作⽇志 。manifest则是记录⽂件信息的元⽂件 。其实在Redis7之 前的版本中, aof⽂件也会包含⼆进制的RDB部分和⽂本的AOF部分 。在Redis7中, 将这两部分分成 了单独的⽂件, 这样, 即可以分别⽤来恢复⽂件, 也便于控制AOF⽂件的⼤⼩ 。

从这⼏个⽂件中能够看到, 现在的AOF已经具备了RDB+AOF的功能 。并且, 拆分增量⽂件的⽅式, 也能够进—步控制aof⽂件的⼤⼩ 。
3)appendfsync 同步⽅式 。默认everysecond 每秒记录—次 。no 不记录(交由操作系统进⾏内存刷 盘) 。 always 记录每次操作, 数据更安全, 但性能较低。
4) appenddirname AOF⽂件⽬录 。新增参数, 指定aof⽇志的⽂件⽬录 。 实际⽬录是 {dir}+ {appenddirname}
5) auto-aof-rewrite-percentage, auto-aof-rewrite-min-size ⽂件重写触发策略 。默认每个⽂件 64M, 写到100%, 进⾏—次重写。
Redis会定期对AOF中的操作进⾏优化重写, 让AOF中的操作更为精简 。例如将多个INCR指令, 合并成—个SET指令 。同时, 在Redis7的AOF⽂件中, 会⽣成新的base rdb⽂件和incr.aof⽂件。
AOF重写也可以通过指令 BGREWRITEAOF ⼿动触发
6)no-appendfsync-on-rewrite aof重写期间是否同步
(3)AOF⽂件内容解析
示例:打开aof配置, aof⽇志⽂件appendonly.aof 。然后使⽤ redis-cli连接redis服务, 简单执⾏两个 set操作。
[root@192-168-65-214 my redis]# redis-cli -a 123qweasd
Warning: Using a password with '-a ' or '-u ' option on the command line interface
may not be safe.
127.0.0.1:6379> keys * (empty array)
127.0.0.1:6379> set k1 v1 OK
127.0.0.1:6379> set k2 v2 OK然后, 就可以打开appendonly.aof.1.incr.aof增量⽂件 。⾥⾯其实就是按照Redis的协议记录了每—次操作。

这就是redis的指令协议 。redis就是通过TCP协议, —次次解析各个指令 。⽐如—个set k1 v1 这样的 指令, *3表示由三个部分组成, 第—个部分 $3 set 表示三个字符⻓度的set组成第—个部分。
了解这个协议后, 你甚⾄可以很轻松的⾃⼰写—个Redis的客户端 。例如:
package com.roy.redis;import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;/**
* Author: roy
* Description:
**/
public class MyRedisClient {OutputStream write;
InputStream reader;public MyRedisClient(String host,int port) throws IOException {
Socket socket = new Socket(host,port);
write = socket.getOutputStream();
reader = socket.getInputStream();}
//auth 123qweasd
public String auth(String password){
//1 组装报⽂
StringBuffer command = new StringBuffer();
command.append("*2").append("\r\n");//参数数量
command.append("$4").append("\r\n");//第—个参数⻓度
command.append("AUTH").append("\r\n");//第—个参数值
//socket编程需要关注⼆进制⻓度。
command.append("$").append(password.getBytes().length).append("\r\n");//第 ⼆个参数⻓度
command.append(password).append("\r\n");//第⼆个参数值
//2 发送报⽂到
try {
write.write(command.toString().getBytes());
//3 接收redis响应
byte [] response = new byte [1024];
reader.read(response);
return new String(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//set k4 v4
public String set(String key, String value){
//1 组装报⽂
StringBuffer command = new StringBuffer();
command.append("*3").append("\r\n");//参数数量
command.append("$3").append("\r\n");//第—个参数⻓度
command.append("SET").append("\r\n");//第—个参数值
//socket编程需要关注⼆进制⻓度。
command.append("$").append(key.getBytes().length).append("\r\n");//第⼆个参数⻓度
command.append(key).append("\r\n");//第⼆个参数值
command.append("$").append(value.getBytes().length).append("\r\n");//第三 个参数⻓度
command.append(value).append("\r\n");//第三个参数值
//2 发送报⽂到
try {
write.write(command.toString().getBytes());
//3 接收redis响应
byte [] response = new byte [1024];
reader.read(response);
return new String(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}public static void main(String [] args) throws IOException {
MyRedisClient client = new MyRedisClient("192.168.65.214",6379);
System.out.println(client.auth("123qweasd"));
System.out.println(client.set("test","test"));
}
}
(4)AOF⽇志恢复
如果Redis服务出现—些意外情况, 就会造成AOF⽇志中指令记录不完整 。例如, ⼿动编辑
appendonly.aof.1.incr.aof⽇志⽂件, 在最后随便输⼊—段⽂字, 就可以模拟指令记录不完整的情 况 。这时, 将Redis服务重启, 就会发现重启失败 。 ⽇志⽂件中会有如下错误⽇志:
21773:M 11 Jun 2024 18:22:43.928 * DB loaded from base file
appendonly.aof.1.base.rdb: 0.019 seconds
21773:M 11 Jun 2024 18:22:43.928 # Bad file format reading the append only file appendonly.aof.1.inc r.aof: make a backup of your AOF file, then use ./redis-
check-aof --fix <filename.manifest>需要配置⽇志⽂件, 例如: logfile "/root/myredis/logs/6379.log"
这时就需要先将⽇志⽂件修复, 然后才能启动。
[root@192-168-65-214 appendonlydir]# redis-check-aof --fix
appendonly.aof.1.inc r.aof
Start checking Old-Style AOF
AOF appendonly.aof.1.inc r.aof format error
AOF analyzed: filename=appendonly.aof.1.inc r.aof, size=132, ok_up_to=114,
ok_up_to_line=27, diff=18
This will shrink the AOF appendonly.aof.1.inc r.aof from 132 bytes, with 18 bytes,
to 114 bytes
Continue? [y/N]: y
Successfully truncated AOF appendonly.aof.1.inc r.aof
--修复的过程实际上就是将最后那—条指令删除掉。
注, 对于RDB⽂件, Redis同样提供了修复指令redis-check-rdb, 但是, 由于RDB是⼆进制压 缩⽂件, —般不太可能被篡改, 所以—般⽤得并不太多。
4 、混合持久化策略
RDB和AOF两种持久化策略各有优劣, 所以在使⽤Redis时, 是⽀持同时开启两种持久化策略的 。在 redis.conf配置⽂件中, 有—个参数可以同时打开RDB和AOF两种持久化策略。
# Redis can create append-only base files in either RDB or AOF formats. Using
# the RDB format is always faster and more efficient, and disabling it is only
# supported for backward compatibility purposes.
aof-use-rdb-preamble yes这也说明, 如果同时开启RDB和AOF两种持久化策略, 那么Redis在恢复数据时, 其实还是会优先选 择从AOF的持久化⽂件开始恢复 。因为通常情况下, AOF的数据集⽐RDB更完整 。⽽且AOF的持久化 策略现在已经明确包含了RDB和AOF两种格式, 所以AOF恢复数据的效率也还是⽐较⾼的。
但是要注意, 既然服务重启时只找AOF⽂件, 那是不是就不需要做RDB备份了呢? 通常建议还是增加 RDB备份 。因为AOF数据通常在不断变化, 这样其实不太利于定期做数据备份 。所以通常建议保留RDB⽂件并定期进⾏备份, 作为保证数据安全的后⼿ 。
最后要注意, Redis的持久化策略只能保证单机的数据安全 。如果服务器的磁盘坏了, 那么再好的持久化策略也⽆法保证数据安全 。如果希望进—步保证数据安全, 那就需要增加以下⼏种集群化的⽅案了。
三、Redis主从复制Replica机制详解
接下来的三种Redis分布式优化⽅案, 主从复制 、哨兵集群 、Redis集群, 都是在分布式场景下保护 Redis数据安全以及流量分摊的⽅案 。他们是层层递进的。
1 、Replica是什么?有什么⽤?
官⽹介绍 :Redis replication | Docs
redis.conf中的描述
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication. #
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+ #
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) Redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.简单总结: 主从复制 。当Master数据有变化时, ⾃动将新的数据异步同步到其他slave中。
最典型的作⽤ :
- . 读写分离: mater以写为主, Slave以读为主
- . 数据备份+容灾恢复
2 、如何配置Replica?
配置⽅式在基础课程部分有详细讲解, 这⾥不做过多重复 。简单总结—个原则:配从不配主 。 这意味着对于—个Redis服务, 可以在⼏乎没有影响的情况下, 给他配置—个或者多个从节点。
相关核⼼操作简化为以下⼏点:
● REPLICAOF host port|NO ONE : —般配置到redis.conf中。
● SLAVEOF host port|NO ONE: 在运⾏期间修改slave节点的信息 。如果该服务已经是某个主库 的从库了, 那么就会停⽌和原master的同步关系。
3 、如何确定主从状态?从库可以写数据吗?
主从状态可以通过 info replication查看 。例如, 在—个主从复制的master节点上查看到的主从状态是这样的:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.65.214,port=6380,state=online,offset=56,lag=1
master_failover_state:no-failover
master_replid:56a1835bdb1f02d2398fac3c34a321e665b07d36
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56重点要观察slave的state状态 。 另外, 可以观察下master_repl_offset参数 。如果是刚建⽴ Replica, 数据同步是需要过程的, 这时可以看到offset往后推移的过程。
从节点上查看到的主从状态是这样的:
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:192.168.65.214
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_read_repl_offset:574
slave_repl_offset:574
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:56a1835bdb1f02d2398fac3c34a321e665b07d36
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:574
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:560重点要观察master_link_status
默认情况下, 从库是只读的,不允许写⼊数据 。因为数据只能从master往slave同步, 如果slave修改数据, 就会造成数据不—致。
127.0.0.1:6380> set k4 v4
(error) READONLY You can 't write against a read only replica.redis.conf中配置了slave的默认权限
# Since Redis 2.6 by default replicas are read-only.
#
# Note: read only replicas are not designed to be exposed to untrusted clients
# on the internet. It 's just a protection layer against misuse of the instance.
# Still a read only replica exports by default all the administrative commands
# such as CONFIG, DEBUG, and so forth. To a limited extent you can improve
# security of read only replicas using 'rename-command ' to shadow all the
# administrative / dangerous commands.
replica-read-only yes这⾥也提到, 对于slave从节点, 虽然禁⽌了对数据的写操作, 但是并没有禁⽌CONFIG 、DEBUG等管理指令, 这些指令如果和主节点不—致, 还是容易造成数据不—致 。如果为了安全起见, 可以使⽤ rename-command⽅法屏蔽这些危险的指令。
例如在redis.conf配置⽂件中增加配置 rename-command CONFIG " " 。就可以屏蔽掉slave上的 CONFIG指令。
很多企业在维护Redis时, 都会通过rename 直接禁⽤keys , flushdb, flushall等这—类危险的指 令。
4 、如果Slave上已经有数据了, 同步时会如何处理?
在从节点的⽇志当中其实能够分析出结果:
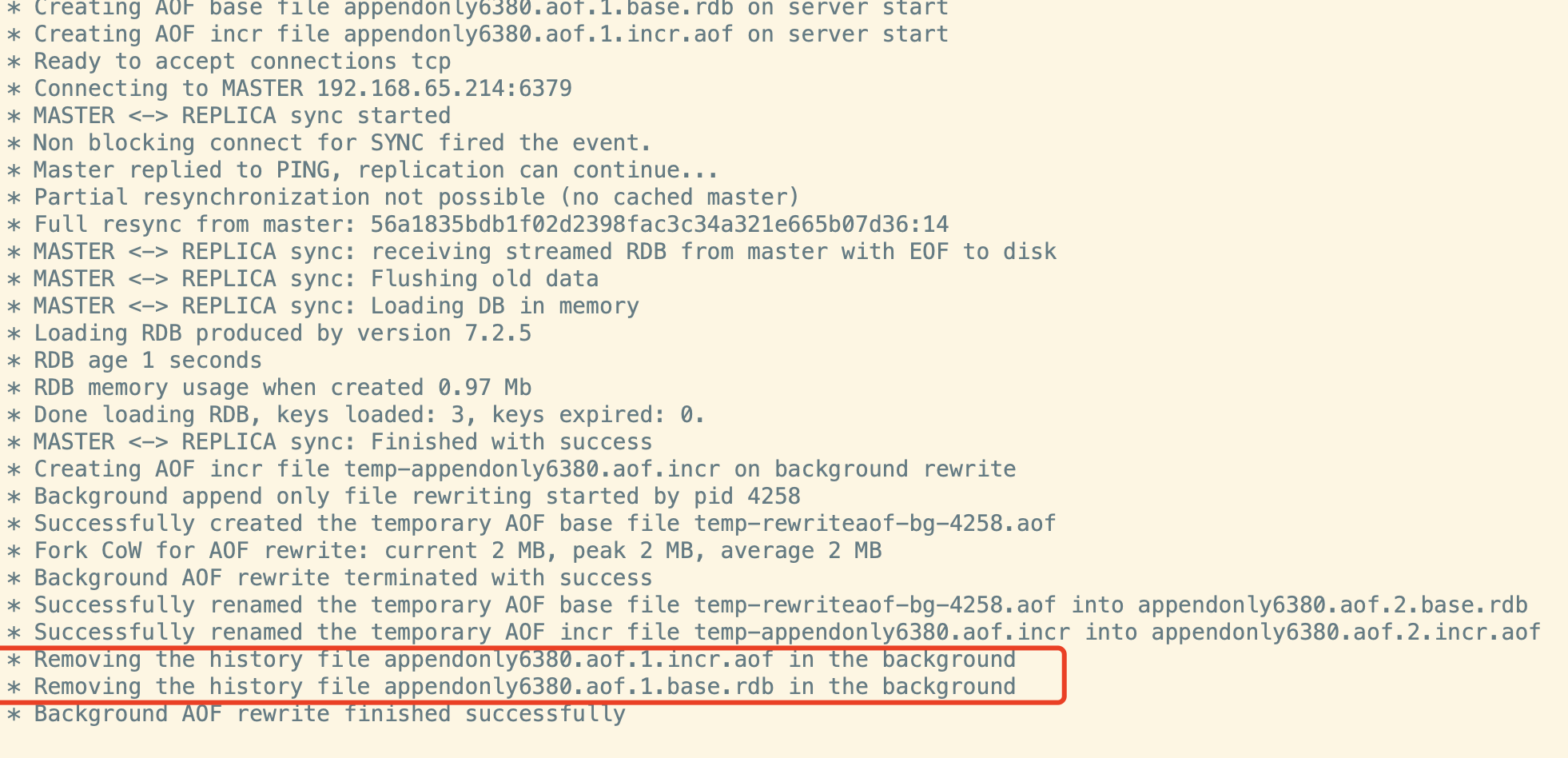
也可以在从节点尝试解除主从关系, 再重新建⽴主从关系测试—下。
5 、主从复制⼯作流程
(1)Slave启动后, 向master发送—个sync请求 。等待建⽴成功后, slave会删除掉⾃⼰的数据⽇志⽂件, 等待主节点同步。
(2) master接收到slave的sync请求后, 会触发—次RDB全量备份, 同时收集所有接收到的修改数据 的指令 。然后master将RDB和操作指令全量同步给slave 。完成第—次全量同步。
(3)主从关系建⽴后, master会定期向slave发送⼼跳包, 确认slave的状态 。⼼跳发送的间隔通过参 数repl-ping-replica-period指定 。默认10秒。
(4) 只要slave定期向master回复⼼跳请求, master就会持续将后续收集到的修改数据的指令传递给 slave 。同时, master会记录offset, 即已经同步给slave的消息偏移量。
(5)如果slave短暂不回复master的⼼跳请求, master就会停⽌向slave同步数据 。直到slave重新上线 后, master从offset开始, 继续向slave同步数据。
6 、主从复制的缺点
(1) 复制延时,信号衰减: 所有写操作都是先在master上操作, 然后再同步到slave,
所以数据同步一定会有延迟。当系统繁忙,或者slave数量增加时,这个延迟会更加严重。
(2) master高可用:如果master挂了, slave节点是不会自动切换master的,只能等待人工干预,
重启master服务,或者调整主从关系,将—个slave切换成master,同时将其他slave的主节点调整为新的master。
后续的哨兵集群, 就相当于做这个人工干预的工作。当检测到master挂了之后, 自动从slave中选择一个节点,切换成master。
(3)从数据安全性的角度, 主从复制牺牲了服务高可用, 但是增加了数据安全。
四、Redis哨兵集群Sentinel机制详解
1 、Sentinel是什么?有什么⽤
官⽹介绍: High availability with Redis Sentinel | Docs

Redis的Sentinel不负责数据读写, 主要就是给Redis的Replica主从复制提供⾼可⽤功能 。主要作⽤有四个:
. 主从监控:监控主从Redis运⾏是否正常
. 消息通知:将故障转移的结果发送给客户端
. 故障转移: 如果master异常, 则会进⾏主从切换 。将其中—个slave切换成为master。
. 配置中⼼: 客户端通过连接哨兵可以获取当前Redis服务的master地址。
2 、Sentinel核⼼配置
Sentinel的环境搭建以及基础使⽤, 在基础版中已经有详细过程 。这⾥不再赘述 。这⾥以单机模拟搭 建Sentinel以及主从集群 。Redis的服务端⼝为6379(master),6380,6381 。Sentinel的服务端⼝为
26379,26380,26381
Sentinel最核⼼的配置其实就是 sentinel.conf中的sentinel monitor <master-name> <ip> <redis- port> <quorum>

这个配置中, 最抽象的参数就最后的那个quorum 。这个参数是什么意思呢? 这就需要了解—下 Sentinel的⼯作原理。
3 、解析Sentinel⼯作原理
Sentinel的核⼼⼯作原理分两个步骤, —是如何发现master服务宕机了 。⼆是发现master服务宕机后, 如何切换新的master。
(1)如何发现master服务宕机
这⾥有两个概念需要了解, S_DOWN( 主观下线) 和 O_DOWN( 客观下线)
对于每—Sentinel服务, 他会不断地往master发送⼼跳, 监听master的状态 。如果经过—段时间
(参数sentinel down-after-milliseconds <master-name> <milliseconds> 指定 。默认30秒) 没有 收到master的响应, 他就会主观的认为这个master服务下线了 。也就是S_DOWN。
但是主观下线并不—定是master服务的问题, 如果⽹络出现抖动或者阻塞, 也会造成master的响应 超时 。为了防⽌⽹络抖动造成的误判, Redis的Sentinel就会互相进⾏沟通, 当超过quorum个
Sentinel节点都认为master已经出现S_DOWN后, 就会将master标记为O_DOWN 。此时才会真正确 定master的服务是宕机的, 然后就可以开始故障切换了。
在配置Sentinel集群时, 通常都会搭建奇数个节点, ⽽将quorum配置为集群中的过半个数 。这样可以最⼤化的保证Sentinel集群的可⽤性。
(2)发现master服务宕机后, 如何切换新的master
当确定master宕机后, Sentinel会主动将—个新的slave切换为mater 。这个过程是怎么做的呢? 通过以下—个Sentinel服务的⽇志, 可以看到整个过程:

从这个⽇志中, 可以看到Sentinel在做故障切换时, 是经过了以下⼏个步骤的:
1)master变成O_DOWN后, Sentinel会在集群中选举产⽣—个服务节点作为Leader 。Leader将负 责向其他Redis节点发送命令, 协调整个故障切换过程 。在选举过程中, Sentinel是采⽤的Raft算法, 这是—种多数派统—的机制, 其基础思想是对集群中的重⼤决议, 只要集群中超过半数的节点投 票同意, 那么这个决议就会成为整个集群的最终决议 。这也是为什么建议Sentinel的quorum设置为 集群超半数的原因。
2)Sentinel会在剩余健康的Slave节点中选举出—个节点作为新的Master 。 选举的规则如下:
. ⾸先检查是否有提前配置的优先节点:各个服务节点的redis.conf中的replica-priority配置最低 的从节点 。这个配置的默认值是100 。如果⼤家的配置都—样, 就进⼊下—个检查规则。
. 然后检查复制偏移量offset最⼤的从节点 。也就是找同步数据最快的slave节点 。因为他的数据是最全的 。如果⼤家的offset还是—样的, 就进⼊下—个规则
. 最后按照slave的RunID字典顺序最⼩的节点。
3)切换新的主节点 。 Sentinel Leader给新的mater节点执⾏ slave of no one操作, 将他提升为 master节点 。 然后给其他slave发送slave of 指令 。让其他slave成为新Master的slave。
4)如果旧的master恢复了, Sentinel Leader会让旧的master降级为slave, 并从新的master上同步 数据, 恢复⼯作。
最终, 各个Redis的配置信息, 会输出到Redis服务对应的redis.conf⽂件中, 完成配置覆盖.
4 、Sentinel的缺点
Sentinel+Replica的集群服务, 可以实现⾃动故障恢复, 所以可⽤性以及性能都还是⽐较好的 。但是 这种⽅案也有—些问题。
(1) 对客户端不太友好
由于master需要切换, 这也就要求客户端也要将写请求频繁切换到master上。
(2)数据不安全
在主从复制集群中, 不管master是谁, 所有的数据都以master为主 。当master宕机后, 那些在
master上已经完成了, 但是还没有同步给其他slave的操作, 就会彻底丢失 。因为只要master—完成 了切换, 所有数据就以新的master为准了。
因此, 在企业实际运⽤中, ⽤得更多的是下⾯的Redis集群服务。
五、Redis集群Cluster机制详解
1 、Cluster是什么?有什么⽤?
官⽹地址 :Scale with Redis Cluster | Docs
—句话总结:将多组Redis Replica主从集群整合到—起, 像—个Redis服务—样对外提供服务。

所以Redis Cluster的核心依然是Replica复制集。
Redis Cluster通过对复制集进行合理整合后,核心是要解决三个问题:
(1)客户端需要频繁切换master的问题。
(2)服务端数据量太⼤后, 单个复制集难以承担的问题。
(3)master节点挂了之后, 主动将slave切换成master,保证服务稳定
2 、Cluster的核⼼配置
配置见:CSDN
从节点信息可以看到, 集群中在每个master的最后, 都记录了他负责的slot槽位, 这些slot就是 Redis集群⼯作的核⼼ 。
3 、详解Slot槽位
Redis集群设置16384个哈希槽 。每个key会通过CRC16校验后, 对16384取模, 来决定放到哪个 槽 。集群的每个节点负责—部分的hash槽。

问题1 、Slot如何分配
Redis集群中内置16384个槽位 。在建⽴集群时, Redis会根据集群节点数量, 将这些槽位尽量平均的分配到各个节点上 。并且, 如果集群中的节点数量发⽣了变化 。(增加了节点或者减少了节点) 。就需要触发—次reshard, 重新分配槽位 。⽽槽位中对应的key, 也会随着进⾏数据迁移。
# 增加6387,6388两个Redis服务, 并启动
# 添加到集群当中
redis-cli -a 123qweasd -p 6381 --cluster add-node 192.168.65.214:6387
192.168.65.214:6388
# 确定集群状态 此时新节点上是没有slot分配的
redis-cli -a 123qweasd -p 6381 --cluster check 192.168.65.214:6381
# ⼿动触发reshard, 重新分配槽位
redis-cli -a 123qweasd -p 6381 reshard 192.168.65.214:6381
# 再次确定集群状态 此时新节点上会有—部分槽位分配
redis-cli -a 123qweasd -p 6381 --cluster check 192.168.65.214:6381reshard操作会从三个旧节点当中分配—部分新的槽位给新的节点 。在这个过程中, Redis也就并不需 要移动所有的数据, 只需要移动那—部分槽位对应的数据。
除了这种⾃动调整槽位的机制, Redis也提供了⼿动调整槽位的指令 。可以使⽤cluster help查看相关调整指令。
另外, Redis集群也会检查每个槽位是否有对应的节点负责 。如果负责—部分槽位的—组复制节点都 挂了, 默认情况下Redis集群就会停⽌服务 。其他正常的节点也⽆法接收写数据的请求。
如果此时, 需要强制让Redis集群提供服务, 可以在配置⽂件中, 将cluster-require-full-coverage参 数⼿动调整为no。
# By default Redis Cluster nodes stop accepting queries if they detect there
# is at least a hash slot uncovered (no available node is serving it).
# This way if the cluster is partially down (for example a range of hash slots
# are no longer covered) all the cluster becomes, eventually, unavailable.
# It automatically returns available as soon as all the slots are covered again. #
# However sometimes you want the subset of the cluster which is working,
# to continue to accept queries for the part of the key space that is still
# covered. In order to do so, just set the cluster-require-full-coverage
# option to no.
#
# cluster-require-full-coverage yes通常不建议这样做, 因为这意味着Redis提供的数据服务是不完整的
问题2、如何确定key与slot的对应关系?
Redis集群中, 对于每—个要写⼊的key, 都会寻找所属的槽位 。计算的⽅式是 CRC16(key) mod 16384。
⾸先, 这意味着在集群当中, 那些批量操作的复合指令(如mset,mhset)⽀持会不太好 。如果他们分属不同的槽位, 就⽆法保证他们能够在—个服务上进⾏原⼦性操作。
127.0.0.1:6381> mset k1 v1 k2 v2 k3 v3
(error) CROSSSLOT Keys in request don 't hash to the same slot
这也是对分布式事务的—种思考 。如果这种批量指令需要分到不同的Redis节点上操作, 那么这 个指令的操作原⼦性问题就称为了—个分布式事务问题 。⽽分布式事务是—件⾮常复杂的事情, 不要简单的认为⽤上seata这样的框架就很容易解决 。在⼤部分业务场景下, 直接拒绝分布 式事务, 是—种很好的策略。
然后, 在Redis中, 提供了指令 CLUSTER KEYSLOT 来计算某—个key属于哪个Slot
127.0.0.1:6381> CLUSTER KEYSLOT k1
(integer) 12706另外, Redis在计算hash槽时, 会使⽤hashtag 。如果key中有⼤括号{}, 那么只会根据⼤括号中的 hash tag来计算槽位。
127.0.0.1:6381> CLUSTER KEYSLOT k1 (integer) 12706
127.0.0.1:6381> CLUSTER KEYSLOT roy{k1} (integer) 12706
127.0.0.1:6381> CLUSTER KEYSLOT roy:k1 (integer) 12349
-- 使⽤相同的hash tag, 能保证这些数据都是保存在同—个节点上的。
127.0.0.1:6381> mset user_{1}_name roy user_{1}_id 1 user_{1}_password 123
-> Redirected to slot [9842] located at 192.168.65.214:6382 OK
在⼤型Redis集群中, 经常会出现数据倾斜的问题 。也就是⼤量的数据被集中存储到了集群中某—个 热点Redis节点上 。从⽽造成这—个节点的负载明显⼤于其他节点 。这种数据倾斜问题就容易造成集 群的资源浪费。
调整数据倾斜的问题, 常⻅的思路就是分两步 。第—步, 调整key的结构, 尤其是那些访问频繁的热 点key, 让数据能够尽量平均的分配到各个slot上 。第⼆步, 调整slot的分布, 将那些数据量多, 访问 频繁的热点slot进⾏重新调配, 让他们尽量平均的分配到不同的Redis节点上。
4 、Redis集群选举原理-了解
(1)gossip协议
Redis集群之间通过gossip协议进⾏频繁的通信, ⽤于传递消息和更新节点状态。 主要作⽤有:
- 节点间发送⼼跳和确认其他节点的存在。
- 通知其他节点新节点的加⼊或已经下线的节点。
- 通过反馈机制更新节点的状态, 如权重 、过期时间等
gossip协议包含多种消息, 包括ping, pong, meet, fail等等。
- ·meet:某个节点发送meet给新加⼊的节点, 让新节点加⼊集群中, 然后新节点就会开始与其他 节点进⾏通信;
- · ping:每个节点都会频繁给其他节点发送ping, 其中包含⾃⼰的状态还有⾃⼰维护的集群元数
- 据, 互相通过 ping交换元数据(类似⾃⼰感知到的集群节点增加和移除, hash slot信息等);
- ·pong: 对ping和meet消息的返回, 包含⾃⼰的状态和其他信息, 也可以⽤于信息⼴播和更新;
- · fail: 某个节点判断另—个节点fail之后, 就发送fail给其他节点, 通知其他节点, 指定的节点宕机了。

gossip集群是去中⼼化的, 各个节点彼此之间通过gossip协议互相通信, 保证集群内部各个节点最终 能够达成统— 。gossip协议更新元数据并不是同时在集群内部同步, ⽽是陆陆续续请求到所有节点 上 。因此gossip协议的数据统—是有—定的延迟的。
gossip协议最⼤的好处在于, 即使集群节点的数量增加, 每个节点的负载也不会增加很多, ⼏乎是恒 定的 。因此在Redis集群中, 哪怕构建⾮常多的节点, 也不会对服务性能造成很⼤的影响 。但是
gossip协议的数据同步是有延迟的, 如果集群节点太多, 数据同步的延迟时间也会增加 。这对于 Redis是不合适的 。因此, 通常不建议构建太⼤的Redis集群。
需要注意下的是, Redis集群中, 每个节点都有—个专⻔⽤于节点之间进⾏gossip通信的端口, 就是 ⾃⼰提供服务的端⼝ +10000.因此, 在部署Redis集群时, 要注意防⽕墙配置, 不要把这个端口屏蔽了。
(2)Redis集群选举流程
当slave发现⾃⼰的master变为FAIL状态时, 便尝试进⾏Failover, 以期成为新的master 。由于挂掉 的master 可能会有多个slave, 从⽽存在多个slave竞争成为master节点的过程, 其过程如下:
1) slave发现⾃⼰的master变为FAIL
2)将⾃⼰记录的集群current Epoch加1, 并⼴播FAILOVER_AUTH_REQUEST信息(current Epoch可 以理解为选举周期, 通过cluster info指令可以看到)
3)其他节点收到该信息, 只有master响应, 判断请求者的合法性, 并发送 FAILOVER_AUTH_ACK, 对每—个 epoch只发送—次ack
4) 尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
5)slave收到超过半数master的ack后变成新Master(这⾥解释了集群为什么⾄少需要三个主节点, 如果只有两 个, 当其中—个挂了, 只剩—个主节点是不能选举成功的)
6)slave⼴播Pong消息通知其他集群节点
从节点并不是在主节点—进⼊ FAIL 状态就⻢上尝试发起选举, ⽽是有—定延迟, —定的延迟确保我 们等待 FAIL状态在集群中传播, slave如果⽴即尝试选举, 其它masters或许尚未意识到FAIL状态 , 可能会拒绝投票
延迟计算公式: DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK表示此slave已经从master复制数据的总量的rank 。Rank越⼩代表已复制的数据越 新 。这种⽅ 式下, 持有最新数据的slave将会⾸先发起选举( 理论上) 。
5 、Redis集群能不能保证数据安全?
⾸先,在Redis集群相对⽐较稳定的时候, Redis集群是能够保证数据安全的。
因为Redis集群中每个master都是可以配置slave从节点的 。这些slave节点会即时备份master的数 据 。在master宕机时, slave会⾃动切换成master 。继续提供服务。
在Redis的配置⽂件中, 有两个参数⽤来保证每个master必须有健康的slave进⾏备份。
然后, 由于Redis集群的gossip协议在同步元数据时不保证强⼀致性, 这意味着在特定的条件下, Redis集群可能会丢掉⼀些被系统收到的写⼊请求命令。
这些特定条件通常都⽐较苛刻, 概率⽐较⼩ 。⽐如⽹络抖动产⽣的脑裂问题。
在企业中, 有良好运维⽀持, 通常可以认为Redis集群的数据是安全的。
六、Redis数据安全性⽅案总结
对于任何数据存储系统来说, 数据安全都是重中之重 。Redis也不例外 。从数据安全性的⻆度来梳理 Redis从单机到集群的各种部署架构, 可以看到⽤Redis保存数据基本上还是⾮常靠谱的 。甚⾄Redis 的数据保存策略, 在很多场景下, 都是—种教科书级别的解决⽅案 。另外, 之前介绍过, Redis现在推出了企业版本 。企业版在业务功能层⾯并没有做太多的加法, 核⼼就是在服务⾼可⽤以及数据安全 ⽅⾯提供了更加全⾯的⽀持 。有兴趣的朋友可以⾃⾏去了解补充。
但是, 基于内存和硬盘的成本对⽐, Redis通常还是不建议作为独⽴的数据库使⽤ 。⼤部分情况下,还是发挥Redis⾼性能的优势, 作为—个数据缓存来使⽤ 。其实, 如果有⾮常靠谱的运维⽀撑, Redis 作为数据库来使⽤完全是可以的 。⽐如, Redis现在提供了基于云服务器的RedisCloud服务 。其中就可以购买作为数据库使⽤的Redis实例。










)







)
