Transformer 模型非常强大,但往往太大太慢,不适合实时应用。为了解决这个问题,我们来看看三种关键的优化技术:知识蒸馏、量化和ONNX 图优化。这些技术可以显著减少推理时间和内存使用。
为了说明每种技术的利弊,我们以意图检测为例,因为它是基于文本的助手的重要组成部分,实时对话中低延迟至关重要。
为生产环境基准测试 Transformer 模型
就像任何机器学习模型一样,将 Transformer 部署到生产环境中,不仅仅是关于准确性——而是要在相互竞争的系统级需求之间做出明智的权衡。三个关键约束条件始终浮出水面:
- 模型性能:模型对真实世界数据的泛化能力如何?在错误代价高昂的领域——无论是由于监管风险、用户影响还是规模——即使是精度或召回率的微小改进,也可能产生巨大的下游效应。在高风险场景中,引入“人在回路”可以帮助最小化关键错误。
- 延迟:模型返回预测的速度有多快?在实时应用中,尤其是在大规模运行的应用中,低延迟推理至关重要。例如,Stack Overflow 需要一个响应式的分类器,以即时标记有问题的评论,而不干扰用户流程。
- 内存效率:我们如何部署像 GPT-2 或 T5 这样拥有数十亿参数且需要大量计算资源的模型?在移动设备或边缘环境中部署时,内存成为一个关键约束,因为这些环境可能无法访问高性能的云基础设施,或者根本不存在。
为什么基准测试很重要:关键要点
在 Transformer 部署中未能平衡性能、延迟和内存约束可能导致:
- 用户体验下降:缓慢、无响应的模型会让用户感到沮丧,降低产品价值。
- 不必要的基础设施成本:在流量很少的情况下在云服务器上运行大型模型,会导致过高的计算账单和资源利用不足。
解决方案:构建目标基准
为了解决这些挑战,我们将设计一个轻量级基准测试框架,它将:
- 评估核心约束(性能、延迟、内存)
- 在定义好的管道和测试集上运行
- 为应用模型优化技术(如量化、剪枝和蒸馏)奠定基础
这从一个简单且可扩展的基准测试类开始——这是系统性能分析和压缩实验的基础。
class PerformanceBenchmark:def __init__(self, pipeline, dataset, optim_type="BERT 基线"):self.pipeline = pipelineself.dataset = datasetself.optim_type = optim_typedef compute_accuracy(self):passdef compute_size(self):passdef time_pipeline(self):pass
def run_benchmark(self):metrics = {}metrics[self.optim_type] = self.compute_size()metrics[self.optim_type].update(self.time_pipeline())metrics[self.optim_type].update(self.compute_accuracy())return metrics
用真实数据测量模型准确性
有了我们的基准测试框架后,是时候让它“活”起来,通过计算模型在代表性测试集上的准确性。
为此,我们将使用CLINC150 数据集——这是一个广泛用于意图分类任务的基准数据集。这个数据集也被用来微调我们的基线 Transformer 模型,使其成为评估的理想起点。
from datasets import load_dataset
clinc = load_dataset("clinc_oos", "plus")
clinc
DatasetDict({train: Dataset({features: ['text', 'intent'],num_rows: 15250})validation: Dataset({features: ['text', 'intent'],num_rows: 3100})test: Dataset({features: ['text', 'intent'],num_rows: 5500})
})
了解 CLINC150 数据集结构
CLINC150 数据集中的每个条目包含:
- 一个用户查询(存储在
text字段中) - 其对应的意图标签(存储在
intent字段中)
为了基准测试,我们将关注测试集,因为它最能模拟真实世界的使用。为了了解数据格式,我们来检查测试集中的一个样本:
了解 CLINC150 数据集结构
CLINC150 数据集中的每个条目包含:一个用户查询(存储在 text 字段中)其对应的意图标签(存储在 intent 字段中)为了基准测试,我们将关注测试集,因为它最能模拟真实世界的使用。为了了解数据格式,我们来检查测试集中的一个样本:
意图是以 ID 形式提供的,但我们可以轻松地通过访问 Dataset.features 属性来获取字符串与 ID 之间的映射(反之亦然):
intents = clinc["test"].features["intent"]
intents.int2str(clinc["test"][42]["intent"])
'transfer'
现在我们已经对 CLINC150 数据集的内容有了基本的了解,让我们来实现 compute_accuracy 函数。
from datasets import load_metric
accuracy_score = load_metric('accuracy')
accuracy_score
Metric(name: "accuracy", features: {'predictions': Value(dtype='int32',> id=None), 'references': Value(dtype='int32', id=None)}, usage: """
Args:predictions: Predicted labels, as returned by a model.references: Ground truth labels.normalize: If False, return the number of correctly classified samples.Otherwise, return the fraction of correctly classified samples.sample_weight: Sample weights.
Returns:accuracy: Accuracy score.
""", stored examples: 0)
为了评估我们模型的性能,我们将使用准确率指标——但它需要预测标签和真实标签都以整数 ID的形式表示。
以下是步骤:
- 生成预测:使用预训练的管道对
text字段进行预测。 - 将预测标签转换为整数 ID:使用
ClassLabel.str2int(),它将字符串类名映射到它们对应的数值索引。 - 将所有预测和真实标签分别收集到单独的列表中。
- 计算准确率:将两个列表传递给指标函数。
让我们将这个逻辑集成到我们的 PerformanceBenchmark 类中,以自动化这个过程:
ef compute_accuracy(self):preds, labels = [], []for example in self.dataset:pred = self.pipeline(example["text"])[0]["label"]label = example["intent"]preds.append(intents.str2int(pred))labels.append(label)accuracy = accuracy_score.compute(predictions=preds, references=labels)print(f"测试集上的准确率 - {accuracy['accuracy']:.3f}")return accuracy
PerformanceBenchmark.compute_accuracy = compute_accuracy
为了了解我们模型的内存占用,我们将把它序列化到磁盘并测量其大小。PyTorch 提供了一个方便的方法来实现这一点,使用 torch.save,它依赖于 Python 内置的 pickle 模块。它可以用来持久化从模型和张量到普通 Python 对象的一切。
在 PyTorch 中保存模型时,推荐的方法是保存其 state_dict——这是一个包含模型每一层的所有可学习参数(如权重和偏置)的字典。
让我们看看我们基线 Transformer 模型的 state_dict 里有什么:
list(pipe.model.state_dict().items())[42]
('bert.encoder.layer.2.attention.self.value.weight',tensor([[-1.0526e-02, -3.2215e-02, 2.2097e-02, ..., -6.0953e-03,4.6521e-03, 2.9844e-02],[-1.4964e-02, -1.0915e-02, 5.2396e-04, ..., 3.2047e-05,-2.6890e-02, -2.1943e-02],[-2.9640e-02, -3.7842e-03, -1.2582e-02, ..., -1.0917e-02,3.1152e-02, -9.7786e-03],...,[-1.5116e-02, -3.3226e-02, 4.2063e-02, ..., -5.2652e-03,1.1093e-02, 2.9703e-03],[-3.6809e-02, 5.6848e-02, -2.6544e-02, ..., -4.0114e-02,6.7487e-03, 1.0511e-03],[-2.4961e-02, 1.4747e-03, -5.4
所以如果我们用
torch.save(model.state_dict(), PATH)
保存我们的模型,我们可以用 Python 的 pathlib 模块来测量它的大小。具体来说,Path(PATH).stat().st_size 返回文件大小,单位是字节。
让我们将其集成到 PerformanceBenchmark 类中的一个 compute_size() 方法中,以自动化这个过程:
import torch
from pathlib import Path
def compute_size(self):state_dict = self.pipeline.model.state_dict()tmp_path = Path("model.pt")torch.save(state_dict, tmp_path)# 计算大小,单位为兆字节size_mb = Path(tmp_path).stat().st_size / (1024 * 1024)# 删除临时文件tmp_path.unlink()print(f"模型大小 (MB) - {size_mb:.2f}")return {"size_mb": size_mb}
PerformanceBenchmark.compute_size = compute_size
为了完成我们的基准测试,我们将测量推理延迟——模型处理单个输入并返回预测意图所需的时间。这为我们提供了一个关于真实世界响应性的估计,尤其是在需要实时预测的生产系统中尤为重要。
在这种情况下,延迟包括管道中的所有处理步骤,包括分词和模型推理。虽然分词速度极快(通常比推理快约 1000 倍),但它仍然是端到端过程的一部分,所以我们为了完整性而将其包含在内。
为了准确测量执行时间,我们将使用 Python 的 time.perf_counter(),它提供高分辨率计时,比 time.time() 更适合性能基准测试。
我们可以通过传递测试查询并计算开始和结束之间的时间差(以毫秒为单位)来用 perf_counter 对管道进行计时:
from time import perf_counter
for _ in range(3):start_time = perf_counter()_ = pipe(query)latency = perf_counter() - start_timeprint(f"延迟 (ms) - {1000 * latency:.3f}")
延迟 (ms) - 64.923
延迟 (ms) - 47.636
延迟 (ms) - 47.344
延迟在不同运行之间可能会有很大差异,特别是对于小输入或在系统负载不一致的情况下。对管道进行单次传递的计时通常会因为背景进程、CPU 节流或即时编译(JIT)效应而产生噪声测量结果。
为了缓解这种情况并获得更可靠的延迟估计,我们采取以下方法:
- 预热 CPU:运行几次初始推理以稳定运行时环境。
- 重复测量:对许多样本进行推理,以收集延迟的分布。
- 报告均值和标准差:这些统计值提供了典型延迟及其可变性的更稳健视图。
以下是如何在 PerformanceBenchmark 类中实现此逻辑:
import numpy as np
def time_pipeline(self, query="我的账户的 PIN 码是多少?"):latencies = []# 预热for _ in range(10):_ = self.pipeline(query)# 定时运行for _ in range(100):start_time = perf_counter()_ = self.pipeline(query)latency = perf_counter() - start_timelatencies.append(latency)# 计算运行统计信息time_avg_ms = 1000 * np.mean(latencies)time_std_ms = 1000 * np.std(latencies)print(f"平均延迟 (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}")return {"time_avg_ms": time_avg_ms, "time_std_ms": time_std_ms}
PerformanceBenchmark.time_pipeline = time_pipeline
对基线模型进行基准测试
我们将把结果收集到 perf_metrics 字典中,以便跟踪每个模型的性能:
pb = PerformanceBenchmark(pipe, clinc["test"])
perf_metrics = pb.run_benchmark()
模型大小 (MB) - 418.17
平均延迟 (ms) - 46.05 +\- 10.13
测试集上的准确率 - 0.867
扩展智能:知识蒸馏用于高效模型部署
知识蒸馏是一种通用方法,用于训练一个较小的学生模型来模仿一个较慢、较大但性能更好的教师模型的行为。
知识蒸馏用于高效微调
知识蒸馏是一种强大的技术,用于监督学习的微调阶段,其中较大的、经过良好训练的“教师”模型将其学到的行为传递给较小的“学生”模型。目标不仅仅是复制性能——而是传递通常在真实标签中看不见的细微、学到的见解。
🔢 蒸馏背后的数学机制
- 生成 logits:输入序列 x 被传递给教师,生成原始预测分数:z(x)=[z1(x),z2(x),…,zN(x)]
- 带温度缩放的 softmax:传统 softmax:
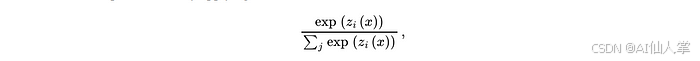
然而,这通常会导致尖峰分布,几乎没有信息增益。
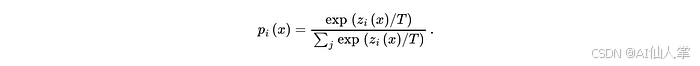
改进的 softmax 带温度 T:
✅ 更高的 T⇒ 更柔和的分布 ✅ 更有信息量,关于类别关系和决策边界
⚖️ 损失函数:平衡准确性与见解
-
学生的软预测:qi(x)
-
KL 散度损失(知识蒸馏损失):
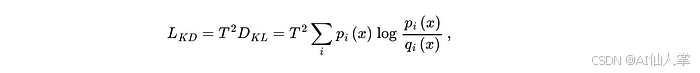
-
因子 T² 对梯度幅度进行归一化。
-
总学生损失:
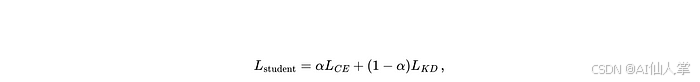
🧠 推理阶段
在推理时,温度 T 重置为 1,以恢复标准的预测置信度。
在预训练期间进行知识蒸馏:构建更智能、更小的模型
尽管知识蒸馏通常用于微调,但它在预训练期间同样有效——允许创建更紧凑、通用的模型,这些模型更快且更高效。
预训练中的工作原理
- 一个大型预训练教师(例如 BERT)将其对掩码语言建模(MLM)的理解传递给一个较小的学生。
- 学生不仅从原始的 MLM 目标中学习,还从教师的行为模式和表示中学习。
DistilBERT 损失函数
在DistilBERT架构中,总损失结合了三个组成部分:
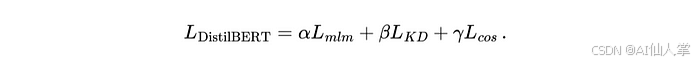
实际应用
由于我们已经有一个微调过的 BERT-base 模型,我们现在可以:
- 将其用作教师来指导一个较小的学生模型。
- 实现一个自定义的Trainer,它整合了交叉熵和蒸馏损失。
这种方法不仅加快了推理时间,还减少了资源使用——而没有过多地牺牲性能。
在 PyTorch 中构建知识蒸馏 Trainer
为了在微调设置中实现知识蒸馏,我们扩展了 Hugging Face Trainer 类,添加了允许学生模型从预训练的教师模型学习的额外组件。
要添加的关键组件
- 超参数:
alpha (α):平衡交叉熵和蒸馏损失(默认 = 0.5)。temperature (T):软化 logits 以获得更平滑的概率分布(默认 = 2.0)。
2.教师模型:
- 一个微调过的 BERT-base模型作为教师,学生将从中学习。
3.自定义损失函数:
- 结合交叉熵损失(针对真实标签)与KL 散度(模仿教师输出)。
逐步代码实现
1. 自定义训练参数
from transformers import TrainingArguments
class DistillationTrainingArguments(TrainingArguments):def __init__(self, *args, alpha=0.5, temperature=2.0, **kwargs):super().__init__(*args, **kwargs)self.alpha = alphaself.temperature = temperature
2. 带有蒸馏逻辑的自定义 Trainer
import torch.nn as nn
import torch.nn.functional as F
from transformers import Trainerclass DistillationTrainer(Trainer):def __init__(self, *args, teacher_model=None, **kwargs):super().__init__(*args, **kwargs)self.teacher_model = teacher_modeldef compute_loss(self, model, inputs):outputs_stu = model(**inputs)loss_ce = outputs_stu.losslogits_stu = outputs_stu.logits# 教师前向传播(不计算梯度)with torch.no_grad():outputs_tea = self.teacher_model(**inputs)logits_tea = outputs_tea.logits# 计算基于 KL 散度的蒸馏损失loss_fct = nn.KLDivLoss(reduction="batchmean")loss_kd = self.args.temperature ** 2 * loss_fct(F.log_softmax(logits_stu / self.args.temperature, dim=-1),F.softmax(logits_tea / self.args.temperature, dim=-1))# 损失加权求和return self.args.alpha * loss_ce + (1. - self.args.alpha) * loss_kd
幕后工作原理
- 教师预测:不计算梯度;它是一个固定的模型。
- 软 logits:学生 logits 通过
log_softmax,教师 logits 通过softmax。 - KL 散度:衡量学生模仿教师软化预测的接近程度。
- 损失混合:最终损失 =
α * 交叉熵 + (1 - α) * 蒸馏损失。
选择一个好的学生初始化
首先,我们需要对查询进行分词和编码,所以让我们实例化 DistilBERT 的分词器并创建一个简单的函数来处理预处理:
student_ckpt = "distilbert-base-uncased"
student_tokenizer = AutoTokenizer.from_pretrained(student_ckpt)
def tokenize_text(batch, tokenizer):return tokenizer(batch["text"], truncation=True)
clinc_enc = clinc.map(tokenize_text, batched=True, remove_columns=["text"],fn_kwargs={"tokenizer": student_tokenizer})
clinc_enc.rename_column_("intent", "labels")
在这里,我们移除了 text 列,因为我们不再需要它,我们还使用 fn_kwargs 参数指定了 tokenize_text 函数中应该使用的分词器。我们还将 intent 列重命名为 labels,以便它可以被训练器自动检测。现在我们的文本已经处理好了,接下来要做的是实例化 DistilBERT 进行微调。由于我们将多次运行训练器,我们将使用一个函数来初始化每次运行的模型:
import torch
from transformers import AutoConfig
num_labels = intents.num_classes
id2label = bert_model.config.id2label
label2id = bert_model.config.label2id
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
student_config = (AutoConfig.from_pretrained(student_ckpt, num_labels=num_labels,id2label=id2label, label2id=label2id))
def student_init():return (AutoModelForSequenceClassification.from_pretrained(student_ckpt, config=student_config).to(device))
我们需要定义在训练期间跟踪的指标,
def compute_metrics(pred):predictions, labels = predpredictions = np.argmax(predictions, axis=1)return accuracy_score.compute(predictions=predictions, references=labels)
最后,我们只需要定义训练参数。为了热身,我们将 α 设置为 1,看看 DistilBERT 在没有任何教师信号的情况下表现如何:
batch_size = 48
student_training_args = DistillationTrainingArguments(output_dir="checkpoints", evaluation_strategy = "epoch", num_train_epochs=5,learning_rate=2e-5, per_device_train_batch_size=batch_size,per_device_eval_batch_size=batch_size, alpha=1, weight_decay=0.01)
接下来我们加载教师模型,实例化训练器并开始微调:
teacher_checkpoint = "lewtun/bert-base-uncased-finetuned-clinc"
teacher_model = (AutoModelForSequenceClassification.from_pretrained(teacher_checkpoint, num_labels=num_labels).to(device))
distil_trainer = DistillationTrainer(model_init=student_init,teacher_model=teacher_model, args=student_training_args,train_dataset=clinc_enc['train'], eval_dataset=clinc_enc['validation'],compute_metrics=compute_metrics, tokenizer=student_tokenizer)
distil_trainer.train();
将其包装在 TextClassificationPipeline 中并通过我们的性能基准进行测试:
pipe = TextClassificationPipeline(model=distil_trainer.model.to("cpu"), tokenizer=distil_trainer.tokenizer)
optim_type = "DistilBERT"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
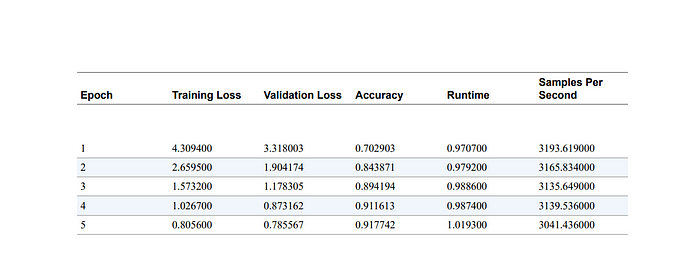
perf_metrics.update(pb.run_benchmark())模型大小 (MB) - 255.89
平均延迟 (ms) - 24.13 +\- 10.06
测试集上的准确率 - 0.856
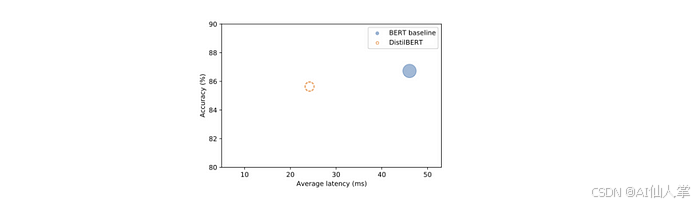
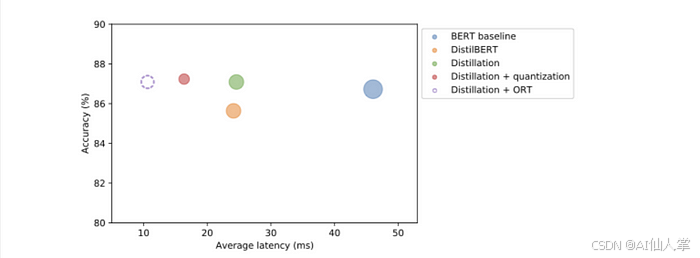
创建一个散点图,将准确率与延迟进行对比,每个点的半径对应模型的大小。
import pandas as pd
def plot_metrics(perf_metrics, current_optim_type):df = pd.DataFrame.from_dict(perf_metrics, orient='index')for idx in df.index:df_opt = df.loc[idx]if idx == current_optim_type:plt.scatter(df_opt["time_avg_ms"], df_opt["accuracy"] * 100,alpha=0.5, s=df_opt["size_mb"], label=idx,marker='$\u25CC')else:plt.scatter(df_opt["time_avg_ms"], df_opt["accuracy"] * 100,s=df_opt["size_mb"], label=idx, alpha=0.5)legend = plt.legend(bbox_to_anchor=(1,1))for handle in legend.legendHandles:handle.set_sizes([20])plt.ylim(80,90)plt.xlim(5, 53)plt.ylabel("准确率 (%)")plt.xlabel("平均延迟 (ms)")plt.show()
plot_metrics(perf_metrics, optim_type)
使用 Optuna 调整蒸馏超参数
Optuna 将超参数调整视为一个优化问题。它定义了一个目标函数,然后运行多次试验以最小化或最大化它。
Rosenbrock 的香蕉函数:
优化中的一个经典基准:
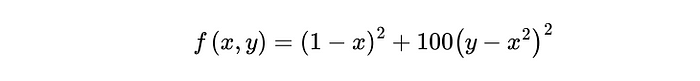
- 全局最小值在:(x,y)=(1,1)
- 因其弯曲的香蕉形状轮廓而得名
- 理论上简单,但收敛到真实最小值具有挑战性
现在,让我们用类似的方法来优化 Hugging Face Trainer 中的知识蒸馏参数。
定义超参数空间
def hp_space(trial):return {"num_train_epochs": trial.suggest_int("num_train_epochs", 5, 10),"alpha": trial.suggest_float("alpha", 0, 1),"temperature": trial.suggest_int("temperature", 2, 20)}
运行超参数搜索
best_run = distil_trainer.hyperparameter_search(n_trials=20,direction="maximize",hp_space=hp_space
)
direction="maximize"告诉 Optuna 寻找更高的准确率。best_run包含最佳试验的配置和性能。
样本输出
print(best_run)
# BestRun(run_id='4', objective=3080.87,
# hyperparameters={'num_train_epochs': 8, 'alpha': 0.31, 'temperature': 16})
💡 洞见:所选的 α = 0.31 表明大部分学习信号来自知识蒸馏,而不是真实标签。
应用最佳超参数并重新训练
for k, v in best_run.hyperparameters.items():setattr(distil_trainer.args, k, v)distil_trainer.train()保存模型以供日后使用:
distil_trainer.save_model("models/distilbert-base-uncased-distilled-clinc")
对蒸馏后的模型进行基准测试
创建一个管道并重新进行基准测试,看看我们在测试集上的表现如何:
pipe = TextClassificationPipeline(model=distil_trainer.model.to("cpu"), tokenizer=distil_trainer.tokenizer)
optim_type = "蒸馏"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())
模型大小 (MB) - 255.89
平均延迟 (ms) - 24.58 +\- 7.66
测试集上的准确率 - 0.871
用量化加速 Transformer
虽然知识蒸馏通过训练一个较小的学生模型来减小模型大小,但量化通过降低计算精度——通常从 32 位浮点数(FP32)降低到 8 位整数(INT8)来提高效率。这可以带来:
- 更小的模型大小
- 更快的推理速度
- 最小的准确率损失
可视化权重分布以进行量化
Transformer 权重通常位于一个狭窄的范围内,使其非常适合 INT8 量化。
import matplotlib.pyplot as plt
weights = bert_model.state_dict()["bert.encoder.layer.0.attention.output.dense.weight"]
plt.hist(weights.flatten().numpy(), bins=250, range=(-0.3, 0.3));
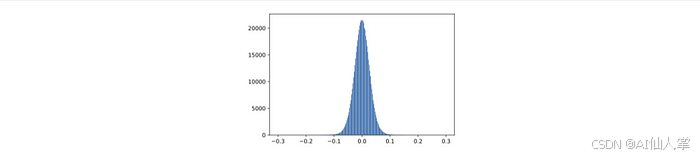
如果大多数值位于 [−0.1, 0.1] 范围内,我们可以安全地将它们量化为 INT8(−128 到 127),而几乎没有损失。
手动量化示例
步骤 1:计算比例因子和零点
zero_point = 0
scale = (weights.max() - weights.min()) / (127 - (-128))
步骤 2 :量化张量
(weights / scale + zero_point).clamp(-128, 127).round().char()
[[ 2, -1, 1, ..., -2, -6, 9],[ 7, 2, -4, ..., -3, 5, -3],[-15, -8, 5, ..., 3, 0, -2],...,[ 11, -1, 12, ..., -2, 0, -3],[ -2, -6, -13, ..., 11, -3, -10],[-12, 5, -3, ..., 7, -3, -1]], dtype=torch.int8)
步骤 3:使用 PyTorch 的 API
from torch import quantize_per_tensor
quantized_weights = quantize_per_tensor(weights, scale, zero_point, torch.qint8)
quantized_weights.int_repr()
([[ 2, -1, 1, ..., -2, -6, 9],[ 7, 2, -4, ..., -3, 5, -3],[-15, -8, 5, ..., 3, 0, -2],...,[ 11, -1, 12, ..., -2, 0, -3],[ -2, -6, -13, ..., 11, -3, -10],[-12, 5, -3, ..., 7, -3, -1]], dtype=torch.int8)
如果我们对这个张量进行反量化,我们可以可视化频率分布,看看四舍五入对原始值的影响:
from mpl_toolkits.axes_grid1.inset_locator import zoomed_inset_axes,mark_inset
# 创建直方图
fig, ax = plt.subplots()
ax.hist(quantized_weights.dequantize().flatten().numpy(),bins=250, range=(-0.3,0.3));
# 创建放大插入图
axins = zoomed_inset_axes(ax, 5, loc='upper right')
axins.hist(quantized_weights.dequantize().flatten().numpy(),bins=250, range=(-0.3,0.3));
x1, x2, y1, y2 = 0.05, 0.1, 500, 2500
axins.set_xlim(x1, x2)
axins.set_ylim(y1, y2)
axins.axes.xaxis.set_visible(False)
axins.axes.yaxis.set_visible(False)
mark_inset(ax, axins, loc1=2, loc2=4, fc="none", ec="0.5")
plt.show()
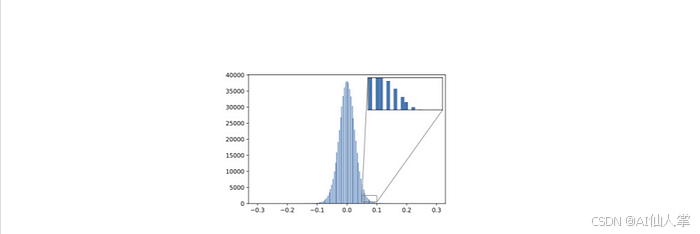
这非常清楚地显示了由于只精确映射一些权重值并对其余值进行四舍五入而引起的离散化。为了完善我们的小分析,让我们比较一下计算两个权重张量乘法所需的时间,一个使用 FP32 值,另一个使用 INT8 值。对于 FP32 张量,我们可以使用 PyTorch 的便捷 @ 运算符进行乘法:
%%timeit
weights @ weights
对于量化张量,我们需要 QFunctional 包装器类,以便我们可以使用特殊的 torch.qint8 数据类型进行操作:
from torch.nn.quantized import QFunctional
q_fn = QFunctional()
这个类支持各种基本操作,比如加法,在我们的情况下,我们可以这样对量化张量的乘法进行计时:
%%timeit
q_fn.mul(quantized_weights, quantized_weights)
107 µs ± 7.87 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
内存比较
import sys
sys.getsizeof(weights.storage()) / sys.getsizeof(quantized_weights.storage())
# 约小 4 倍
使用 PyTorch 量化 Transformer
from torch.quantization import quantize_dynamic
from transformers import AutoModelForSequenceClassification, AutoTokenizermodel_ckpt = "models/distilbert-base-uncased-distilled-clinc"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)model = AutoModelForSequenceClassification.from_pretrained(model_ckpt).to("cpu")model_quantized = quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
这行代码:
- 量化所有
nn.Linear层。 - 使用 INT8 算术进行更快的推理。
- 几乎保持了相同的准确率。
对量化模型的性能进行基准测试
我们的模型已经成功量化,现在是时候测试它的性能了。我们将运行一个基准测试来评估它的速度和内存效率——这对于在资源受限的环境中部署至关重要。
以下是设置和执行基准测试的方式:
pipe = TextClassificationPipeline(model=model_quantized, tokenizer=tokenizer)
optim_type = "蒸馏 + 量化"
pb = PerformanceBenchmark(pipe, clinc["test"], optim_type=optim_type)
perf_metrics.update(pb.run_benchmark())
plot_metrics(perf_metrics, optim_type)
使用 ONNX 和 ONNX 运行时优化推理
我们的蒸馏模型已经经过优化和量化,现在是时候使用 ONNX 框架进一步突破极限了——这是一个强大的平台,用于深度学习模型的互操作性和高性能推理。
ONNX(Open Neural Network Exchange)是一个开放标准,定义了:
- 跨框架的通用操作符集
- 统一的文件格式用于模型导出/导入
- 神经网络的计算图表示
得益于 ONNX,你可以轻松地导出 PyTorch 模型并将其导入到 TensorFlow 中——反之亦然——从而实现在不同生态系统中的灵活部署。
设置 OpenMP 环境变量以供 ONNX 使用:
from psutil import cpu_count
%env OMP_NUM_THREADS={cpu_count()}
%env OMP_WAIT_POLICY=ACTIVE
env: OMP_NUM_THREADS=8
env: OMP_WAIT_POLICY=ACTIVE
将我们的蒸馏模型转换为 ONNX 格式:
from transformers.convert_graph_to_onnx import convert
onnx_model_path = Path("onnx/model.onnx")
convert(framework="pt", model=model_ckpt, tokenizer=tokenizer,output=onnx_model_path, opset=12, pipeline_name="sentiment-analysis")
ONNX opset version set to: 12
Loading pipeline (model: models/distilbert-base-uncased-distilled-clinc,> tokenizer: PreTrainedTokenizerFast(name_or_path='models/distilbert-base-> uncased-distilled-clinc', vocab_size=30522, model_max_len=512, is_fast=True,> padding_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token':> '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token':> '[MASK]'}))
Creating folder onnx
Using framework PyTorch: 1.5.0
Found input input_ids with shape: {0: 'batch', 1: 'sequence'}
Found input attention_mask with shape: {0: 'batch', 1: 'sequence'}
Found output output_0 with shape: {0: 'batch'}
Ensuring inputs are in correct order
head_mask is not present in the generated input list.
Generated inputs order: ['input_ids', 'attention_mask']
ONNX 使用操作符集将不可变的操作符规范分组在一起,因此 opset=12 对应于 ONNX 库的一个特定版本。现在我们已经保存了模型。
我们需要创建一个推理会话来将输入传递给模型:
om onnxruntime import (GraphOptimizationLevel, InferenceSession,SessionOptions)
def create_model_for_provider(model_path, provider="CPUExecutionProvider"):options = SessionOptions()options.intra_op_num_threads = 1options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALLsession = InferenceSession(str(model_path), options, providers=[provider])session.disable_fallback()return session
onnx_model = create_model_for_provider(onnx_model_path)
用测试集中的一个示例进行测试。由于转换函数的输出告诉我们 ONNX 只期望 input_ids 和 attention_mask 作为输入,因此我们需要从样本中删除标签列:
inputs = clinc_enc["test"][:1]
del inputs["labels"]
logits_onnx = onnx_model.run(None, inputs)[0]
logits_onnx.shape##(1, 151)
通过取 argmax 获取预测标签:
np.argmax(logits_onnx)## 添加真实标签clinc_enc["test"][0]["labels"]
我们将创建自己的类来模拟核心行为:
from scipy.special import softmax
class OnnxPipeline:def __init__(self, model, tokenizer):self.model = modelself.tokenizer = tokenizerdef __call__(self, query):model_inputs = self.tokenizer(query, return_tensors="pt")inputs_onnx = {k: v.cpu().detach().numpy()for k, v in model_inputs.items()}logits = self.model.run(None, inputs_onnx)[0][0, :]probs = softmax(logits)pred_idx = np.argmax(probs).item()return [{"label": intents.int2str(pred_idx), "score": probs[pred_idx]}]
然后我们可以在简单的查询上测试这个,看看我们是否能够恢复 car_rental 意图:
pipe = OnnxPipeline(onnx_model, tokenizer)
pipe(query)
[{'label': 'car_rental', 'score': 0.8440852}]
高效地对 ONNX 模型进行基准测试
现在我们的 ONNX 管道已经正常工作,下一步是对它的性能进行基准测试。为此,我们将扩展我们现有的 PerformanceBenchmark 类。由于 ONNX 模型是一个 InferenceSession 实例(而不是 PyTorch 的 nn.Module),它没有像 state_dict 这样的属性,因此无法使用 torch.save() 来计算大小。
🔧 为了解决这个问题,我们将只覆盖 compute_size() 方法,同时重用现有的 compute_accuracy() 和 time_pipeline() 的实现。
以下是一种简洁的方式来处理 ONNX 模型的大小计算:
lass OnnxPerformanceBenchmark(PerformanceBenchmark):def __init__(self, *args, model_path, **kwargs):super().__init__(*args, **kwargs)self.model_path = model_pathdef compute_size(self):size_mb = Path(self.model_path).stat().st_size / (1024 * 1024)print(f"模型大小 (MB) - {size_mb:.2f}")return {"size_mb": size_mb}
使用我们新的基准测试工具,让我们看看将蒸馏模型转换为 ONNX 格式后的表现如何:
optim_type = "蒸馏 + ORT"
pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type,model_path="onnx/model.onnx")
perf_metrics.update(pb.run_benchmark())# 模型大小 (MB) - 255.89
# 平均延迟 (ms) - 10.54 +\- 2.20
# 测试集上的准确率 - 0.871plot_metrics(perf_metrics, optim_type)
使用 ONNX 运行时优化 Transformer 推理
我们已经看到,当将蒸馏 Transformer 模型转换为 ONNX 格式时,ONNX 运行时(ORT)已经提供了相当不错的性能提升。但我们还可以更进一步,通过应用 ORT 的优化工具包中的Transformer 特定图优化。
Transformer 特定优化
对于像 DistilBERT 这样的 Transformer 架构,ONNX 运行时工具提供了针对类型为 bert 的模型的高级优化。首先,我们使用 BertOptimizationOptions 定义一组模型特定的优化选项:
from onnxruntime_tools.transformers.onnx_model_bert import BertOptimizationOptionsmodel_type = "bert"
opt_options = BertOptimizationOptions(model_type)
opt_options.enable_embed_layer_norm = False # 改善模型大小压缩
禁用嵌入层归一化融合在某些情况下可以实现更好的压缩效果。
接下来,我们运行优化过程:
from onnxruntime_tools import optimizeropt_model = optimizer.optimize_model("onnx/model.onnx",model_type=model_type,num_heads=12,hidden_size=768,optimization_options=opt_options
)opt_model.save_model_to_file("onnx/model.opt.onnx")
我们提供了 DistilBERT 模型的注意力头数和隐藏层大小。优化完成后,我们可以运行性能基准测试:
onnx_model_opt = create_model_for_provider("onnx/model.opt.onnx")
pipe = OnnxPipeline(onnx_model_opt, tokenizer)
optim_type = "蒸馏 + ORT (优化)"pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type, model_path="onnx/model.opt.onnx")
perf_metrics.update(pb.run_benchmark())# 输出# 模型大小 (MB) - 255.86# 平均延迟 (ms) - 11.22 ± 3.52# 测试集上的准确率 - 0.871plot_metrics(perf_metrics, optim_type)
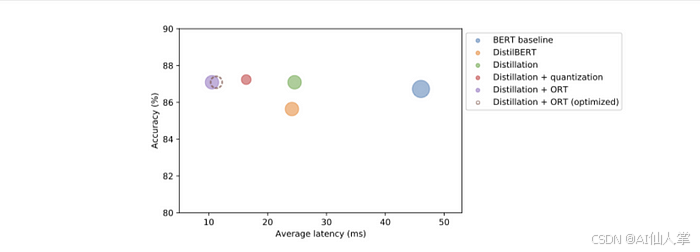
🔍 洞见:我们最初的 ONNX 优化已经接近最优——这个针对 BERT 的特定优化并没有在大小或速度上带来重大改进。
加入量化
为了进一步减小大小和延迟,我们使用 ONNX 运行时的量化工具应用动态量化。与 PyTorch 主要量化 nn.Linear 层不同,ORT 还可以量化嵌入层,从而获得更好的结果。
from onnxruntime.quantization import quantize_dynamic, QuantTypemodel_input = "onnx/model.onnx"
model_output = "onnx/model.quant.onnx"quantize_dynamic(model_input, model_output, weight_type=QuantType.QInt8)
现在,让我们对量化后的 ONNX 模型进行基准测试:
onnx_quantized_model = create_model_for_provider(model_output)
pipe = OnnxPipeline(onnx_quantized_model, tokenizer)
optim_type = "蒸馏 + ORT (量化)"pb = OnnxPerformanceBenchmark(pipe, clinc["test"], optim_type, model_path=model_output)
perf_metrics.update(pb.run_benchmark())# 输出# 模型大小 (MB) - 185.71# 平均延迟 (ms) - 6.95 ± 4.75# 测试集上的准确率 - 0.875plot_metrics(perf_metrics, optim_type)
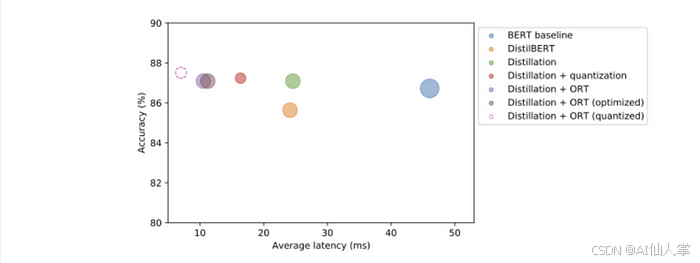
结果:ORT 量化将大小和延迟都几乎减少了 50%,与 PyTorch 量化相比。总体而言,这带来了令人印象深刻的 7 倍加速,与原始 BERT 基线相比,准确率几乎没有损失。



)
)


)
 deny(1) file-write-create)

![[特殊字符] 超强 Web React版 PDF 阅读器!支持分页、缩放、旋转、全屏、懒加载、缩略图!](http://pic.xiahunao.cn/[特殊字符] 超强 Web React版 PDF 阅读器!支持分页、缩放、旋转、全屏、懒加载、缩略图!)
)







