导读:在构建大规模向量数据库应用时,数据组织架构的设计往往决定了系统的性能上限。Milvus作为主流向量数据库,其独特的三层架构设计——分区、分片、段,为海量向量数据的高效存储和检索提供了坚实基础。
本文通过图书馆管理系统的生动类比,系统阐述了这三个核心概念的工作机制与协作关系。分区如同按主题划分的楼层区域,实现业务维度的数据隔离;分片类似每个区域内的并行书架,提供水平扩展和负载均衡能力;段则如同书架上的可拆卸书盒,专注于存储空间优化和查询性能提升。
通过电商平台10万条商品数据的完整处理流程,文章详细展示了三层架构在实际工作中的协作过程。更重要的是,本文提供了基于硬件资源的分片数量计算公式、分区设计的最佳实践原则,以及段配置的优化策略。这些实用的配置建议能够帮助开发者避免常见的性能陷阱,在存储效率与查询性能之间找到最佳平衡点,确保Milvus系统在生产环境中的稳定高效运行。
概述
Milvus作为专业的向量数据库,采用了分区(Partition)、分片(Shard)、段(Segment)三层架构来实现高效的数据组织和查询优化。本文将通过具体的比喻和实践案例,深入解析这三种数据组织方式的工作原理和最佳实践。
关于向量数据库的选型可移步上一篇文章了解:向量数据库选型实战指南:Milvus架构深度解析与技术对比
核心概念解析
图书馆管理系统类比
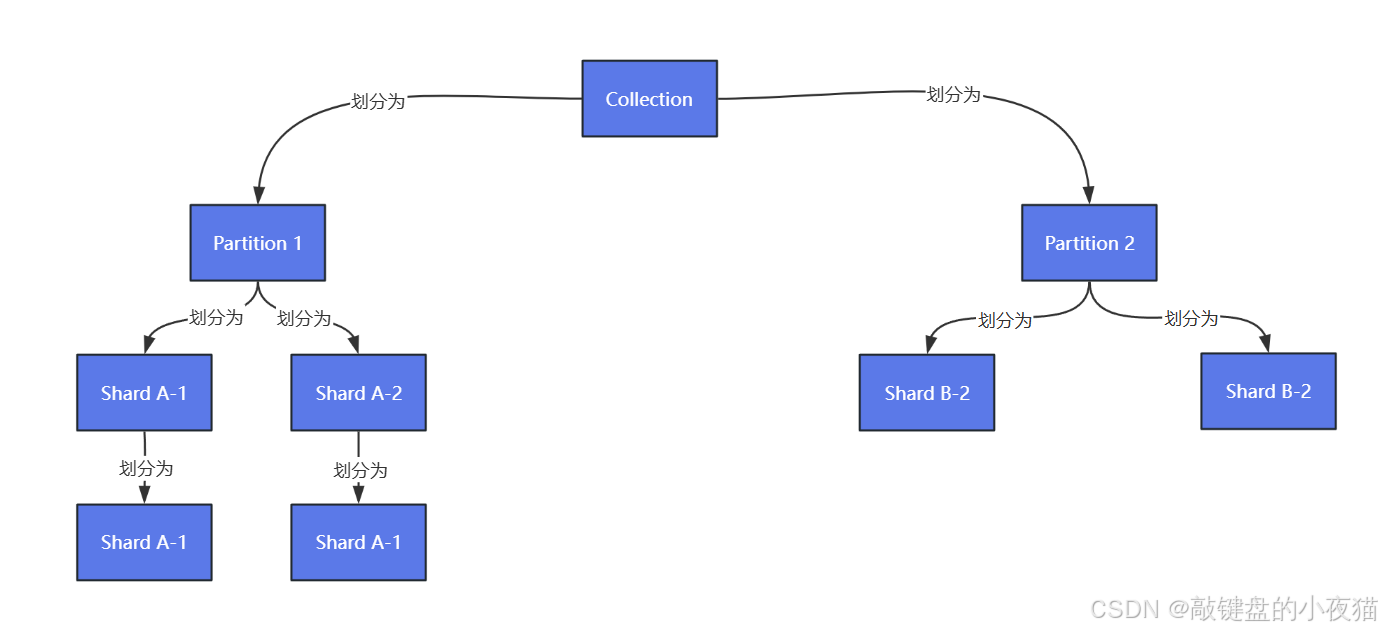
为了更好地理解分区、分片、段三者之间的关系,我们可以将其类比为管理一个超大型图书馆(对应Milvus中的Collection集合),该图书馆存放着上亿本书籍。
分区(Partition):主题区域划分
分区相当于按书籍主题划分的不同楼层区域。例如:1楼科技区、2楼文学区、3楼艺术区。
分区的核心作用是实现业务层面的数据隔离,使系统能够快速定位特定类别的数据,避免全库扫描。这类似于电商平台按商品类别(电器、服装、食品)进行分区存储的策略。
分片(Shard):并行处理单元
分片相当于每个主题区内设置的多个平行书架。以科技区为例,可以分成10个结构相同的书架,每个书架存储100万本书。
分片的主要目的是实现负载均衡和水平扩展。当多个用户同时查找时,不同书架可以并行工作,显著提高系统的并发处理能力。
段(Segment):存储优化单元
段相当于每个书架上的可拆卸书盒。每个书架由多个书盒组成,新书先放入临时书盒,写满后密封成固定书盒。
段的设计目的是优化存储空间和查询性能。旧书盒可以进行压缩归档,类似于数据库将数据分块存储以便于后台合并优化。
三层架构对比分析
| 维度 | 分区(Partition) | 分片(Shard) | 段(Segment) |
|---|---|---|---|
| 层级定位 | 逻辑划分 | 物理分布 | 物理存储单元 |
| 可见性 | 用户主动创建管理 | 系统自动分配 | 完全由系统管理 |
| 主要目的 | 业务数据隔离 | 负载均衡与扩展 | 存储优化与查询加速 |
| 操作方式 | 手动指定查询分区 | 自动路由请求到不同节点 | 自动合并/压缩 |
实际工作流程示例
数据写入场景分析
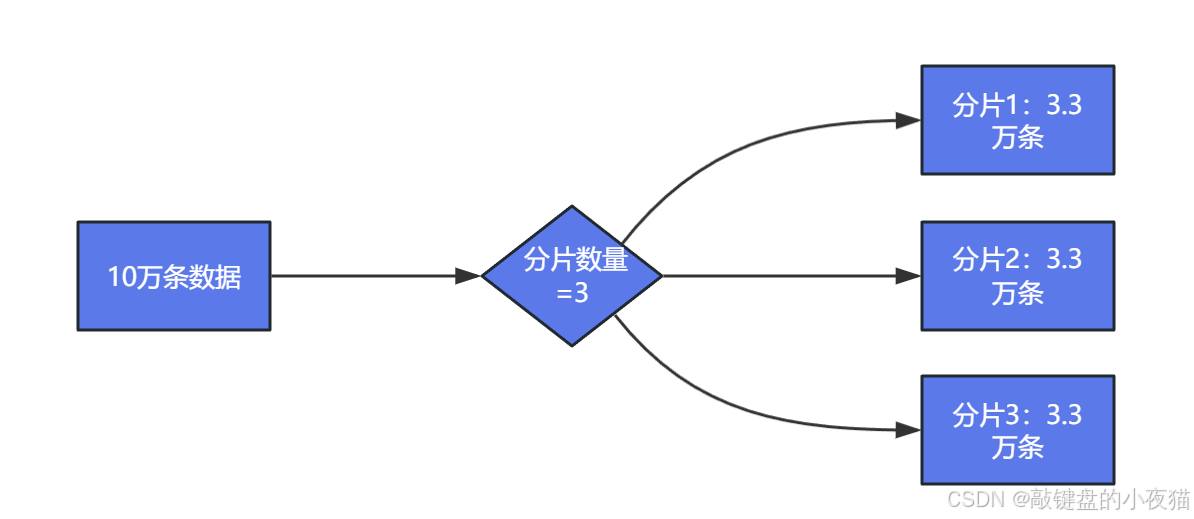
以电商平台上传10万条商品数据为例,展示三层架构的协作过程。
分区阶段:系统首先按业务维度进行数据划分,例如按商品类别创建不同分区。
# 按商品类别创建分区
collection.create_partition("electronics")
collection.create_partition("clothing")
分片阶段:系统自动将数据均匀分配到集群的各个节点。假设集群包含3个节点,数据将自动分配到3个分片中。
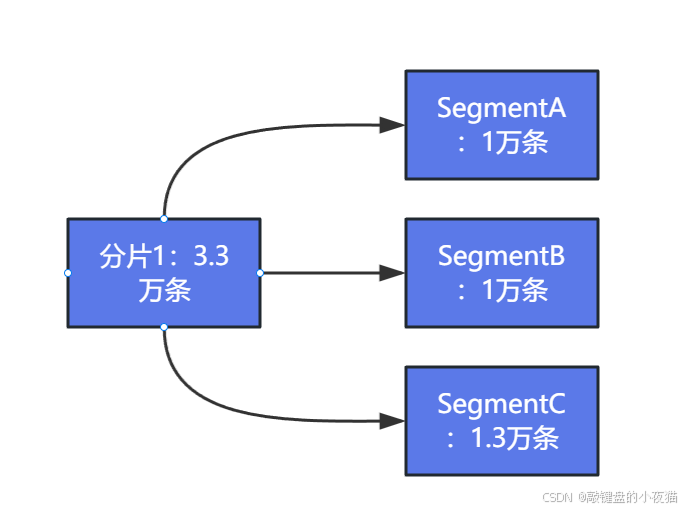
段阶段:分片内的数据按照预设大小(通常为512MB)自动切割成多个段进行存储。
数据查询流程
查询过程遵循以下步骤:用户发起查询请求 → 系统定位相关分区 → 并行查询所有相关分片 → 各分片扫描对应的段 → 合并结果并排序返回。
数据合并优化
系统会自动执行段合并操作,将多个小段合并成大段以提高查询效率。这个过程类似于HBase的Compaction机制:
[Segment1(100MB)] + [Segment2(100MB)] → [SegmentMerged(200MB)]
开发最佳实践
分区设计策略
推荐的分区方案包括按时间维度分区(如2023Q1、2023Q2)和按业务线分区(如user_profiles、product_info)。
需要避免的错误做法是创建过多分区,如超过1000个分区会严重影响元数据性能。
# 良好实践:按时间分区
client.create_partition(collection_name="logs",partition_name="2024-01"
)# 错误做法:为每个用户创建单独分区(容易超过系统限制)
分片数量配置
分片数量的配置需要基于硬件资源进行合理计算。推荐使用公式:分片数 = 节点数 × CPU核心数。
错误的配置如在8核机器上设置128个分片会导致线程频繁切换,严重影响性能。正确的做法是根据实际硬件配置进行设置:
collection = Collection(name="product_images",shards_num=64, # 8台机器 × 8核 = 64个分片partitions=["electronics","clothing", "home_appliances"]
)
段配置优化
段的配置可以通过调整系统参数来优化:
# 调整段的最大大小为1GB
client.set_property("dataCoord.segment.maxSize", "1024")
# 设置段密封比例为70%
client.set_property("dataCoord.segment.sealProportion", "0.7")
段优化策略包括定期监控段大小、手动触发合并操作以及根据数据特性设置合适的段容量阈值。
# 监控段信息
collection.get_segment_info()# 手动触发段合并
collection.compact()# 根据向量维度调整段大小
if 向量维度 > 1024:maxSize = 512 # 降低段大小以缓解内存压力
else:maxSize = 1024
性能优化建议
分片数量对性能的影响
| 分片配置 | 单分片数据量 | 写入吞吐量 | 潜在问题 |
|---|---|---|---|
| 分片数少 | 大 | 低 | 容易成为性能瓶颈 |
| 分片数多 | 小 | 高 | 资源消耗较大 |
存储配置优化
根据实际业务需求调整存储参数:
# 设置段容量阈值(单位:MB)
storage.segmentSize = 1024
通过合理配置这些参数,可以在存储效率和查询性能之间找到最佳平衡点,确保Milvus系统在大规模数据处理场景下的稳定运行。
总结
Milvus的分区-分片-段三层架构设计充分体现了现代分布式数据库的设计理念。分区实现业务层面的数据隔离,分片提供水平扩展能力,段则专注于存储优化。正确理解和配置这三个层次的参数,是构建高性能向量数据库应用的关键基础。
概述
Milvus作为专业的向量数据库,采用了分区(Partition)、分片(Shard)、段(Segment)三层架构来实现高效的数据组织和查询优化。本文将通过具体的比喻和实践案例,深入解析这三种数据组织方式的工作原理和最佳实践。
核心概念解析
图书馆管理系统类比
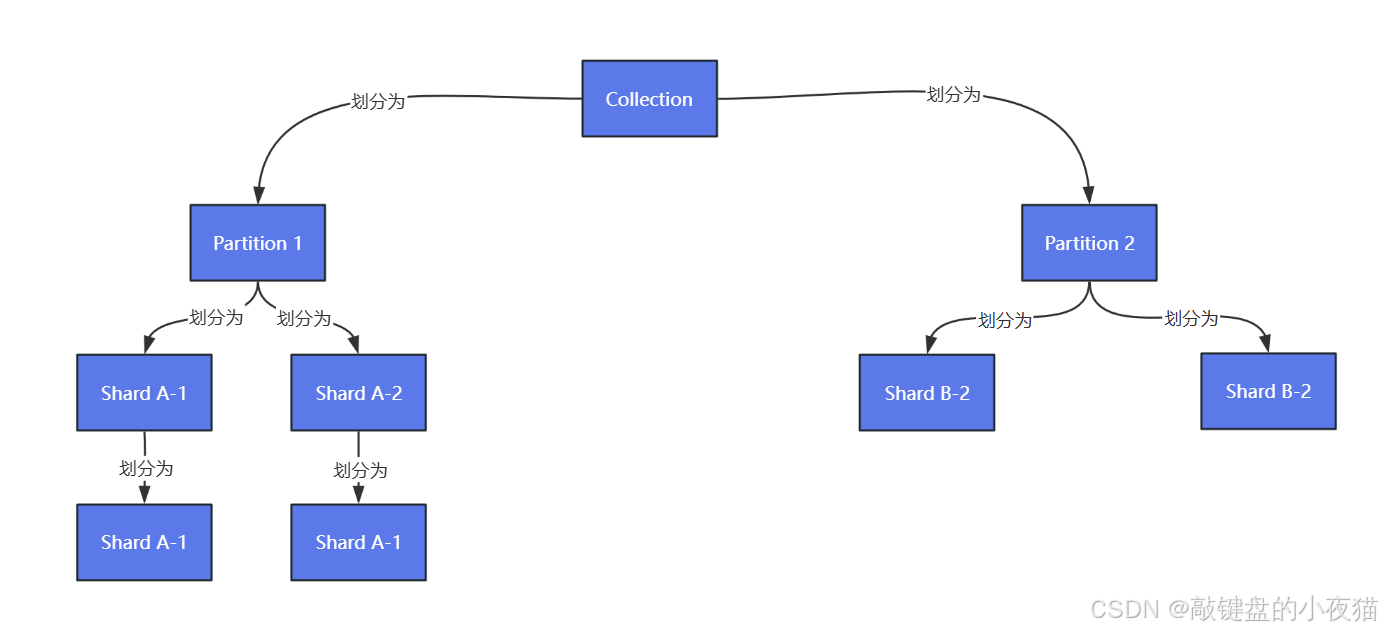
为了更好地理解分区、分片、段三者之间的关系,我们可以将其类比为管理一个超大型图书馆(对应Milvus中的Collection集合),该图书馆存放着上亿本书籍。
分区(Partition):主题区域划分
分区相当于按书籍主题划分的不同楼层区域。例如:1楼科技区、2楼文学区、3楼艺术区。
分区的核心作用是实现业务层面的数据隔离,使系统能够快速定位特定类别的数据,避免全库扫描。这类似于电商平台按商品类别(电器、服装、食品)进行分区存储的策略。
分片(Shard):并行处理单元
分片相当于每个主题区内设置的多个平行书架。以科技区为例,可以分成10个结构相同的书架,每个书架存储100万本书。
分片的主要目的是实现负载均衡和水平扩展。当多个用户同时查找时,不同书架可以并行工作,显著提高系统的并发处理能力。
段(Segment):存储优化单元
段相当于每个书架上的可拆卸书盒。每个书架由多个书盒组成,新书先放入临时书盒,写满后密封成固定书盒。
段的设计目的是优化存储空间和查询性能。旧书盒可以进行压缩归档,类似于数据库将数据分块存储以便于后台合并优化。
三层架构对比分析
| 维度 | 分区(Partition) | 分片(Shard) | 段(Segment) |
|---|---|---|---|
| 层级定位 | 逻辑划分 | 物理分布 | 物理存储单元 |
| 可见性 | 用户主动创建管理 | 系统自动分配 | 完全由系统管理 |
| 主要目的 | 业务数据隔离 | 负载均衡与扩展 | 存储优化与查询加速 |
| 操作方式 | 手动指定查询分区 | 自动路由请求到不同节点 | 自动合并/压缩 |
实际工作流程示例
数据写入场景分析
以电商平台上传10万条商品数据为例,展示三层架构的协作过程。
分区阶段:系统首先按业务维度进行数据划分,例如按商品类别创建不同分区。
# 按商品类别创建分区
collection.create_partition("electronics")
collection.create_partition("clothing")
分片阶段:系统自动将数据均匀分配到集群的各个节点。假设集群包含3个节点,数据将自动分配到3个分片中。
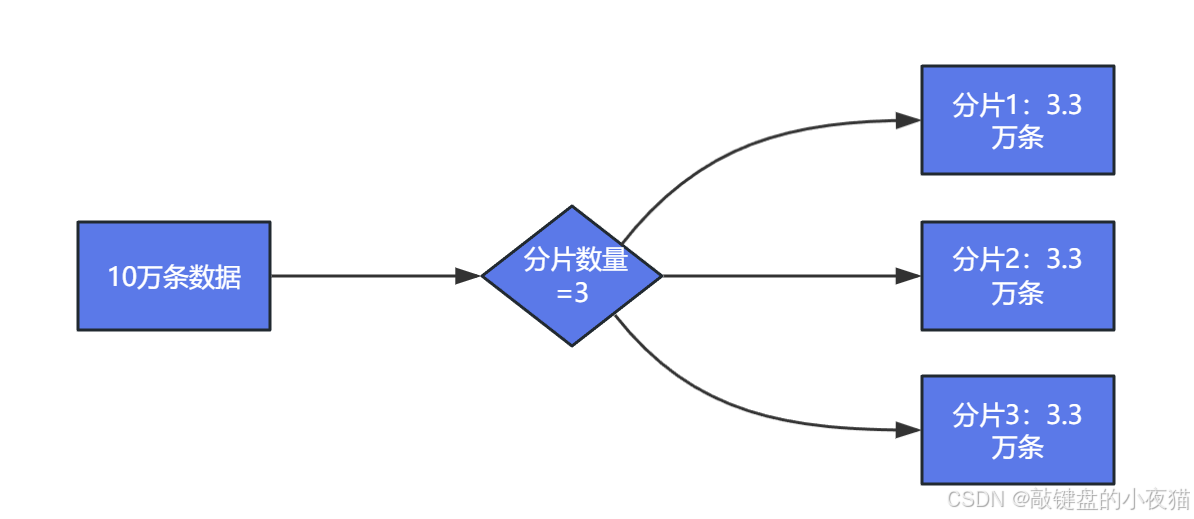
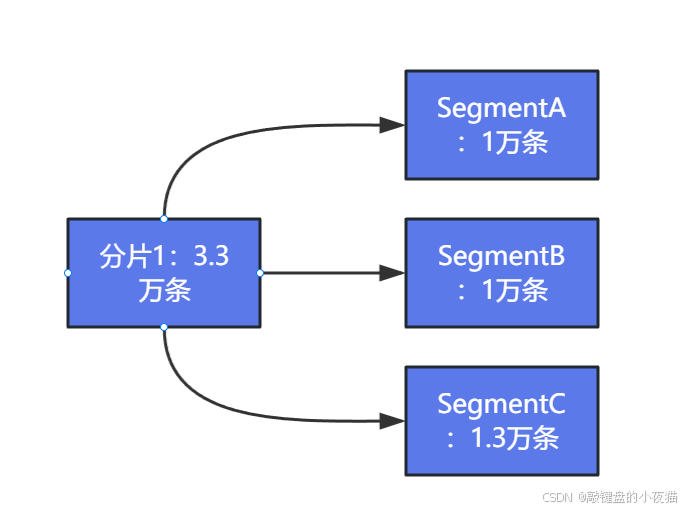
段阶段:分片内的数据按照预设大小(通常为512MB)自动切割成多个段进行存储。
数据查询流程
查询过程遵循以下步骤:用户发起查询请求 → 系统定位相关分区 → 并行查询所有相关分片 → 各分片扫描对应的段 → 合并结果并排序返回。
数据合并优化
系统会自动执行段合并操作,将多个小段合并成大段以提高查询效率。这个过程类似于HBase的Compaction机制:
[Segment1(100MB)] + [Segment2(100MB)] → [SegmentMerged(200MB)]
开发最佳实践
分区设计策略
推荐的分区方案包括按时间维度分区(如2023Q1、2023Q2)和按业务线分区(如user_profiles、product_info)。
需要避免的错误做法是创建过多分区,如超过1000个分区会严重影响元数据性能。
# 良好实践:按时间分区
client.create_partition(collection_name="logs",partition_name="2024-01"
)# 错误做法:为每个用户创建单独分区(容易超过系统限制)
分片数量配置
分片数量的配置需要基于硬件资源进行合理计算。推荐使用公式:分片数 = 节点数 × CPU核心数。
错误的配置如在8核机器上设置128个分片会导致线程频繁切换,严重影响性能。正确的做法是根据实际硬件配置进行设置:
collection = Collection(name="product_images",shards_num=64, # 8台机器 × 8核 = 64个分片partitions=["electronics","clothing", "home_appliances"]
)
段配置优化
段的配置可以通过调整系统参数来优化:
# 调整段的最大大小为1GB
client.set_property("dataCoord.segment.maxSize", "1024")
# 设置段密封比例为70%
client.set_property("dataCoord.segment.sealProportion", "0.7")
段优化策略包括定期监控段大小、手动触发合并操作以及根据数据特性设置合适的段容量阈值。
# 监控段信息
collection.get_segment_info()# 手动触发段合并
collection.compact()# 根据向量维度调整段大小
if 向量维度 > 1024:maxSize = 512 # 降低段大小以缓解内存压力
else:maxSize = 1024
性能优化建议
分片数量对性能的影响
| 分片配置 | 单分片数据量 | 写入吞吐量 | 潜在问题 |
|---|---|---|---|
| 分片数少 | 大 | 低 | 容易成为性能瓶颈 |
| 分片数多 | 小 | 高 | 资源消耗较大 |
存储配置优化
根据实际业务需求调整存储参数:
# 设置段容量阈值(单位:MB)
storage.segmentSize = 1024
通过合理配置这些参数,可以在存储效率和查询性能之间找到最佳平衡点,确保Milvus系统在大规模数据处理场景下的稳定运行。
总结
Milvus的分区-分片-段三层架构设计充分体现了现代分布式数据库的设计理念。分区实现业务层面的数据隔离,分片提供水平扩展能力,段则专注于存储优化。正确理解和配置这三个层次的参数,是构建高性能向量数据库应用的关键基础。








:配置“构建历史的显示名称,加上包名等信息“)

)








