在后续的系列文章中,我们将逐步深入探讨 VGG16 相关的核心内容,具体涵盖以下几个方面:
-
卷积原理篇:详细剖析 VGG 的 “堆叠小卷积核” 设计理念,深入解读为何 3×3×2 卷积操作等效于 5×5 卷积,以及 3×3×3 卷积操作等效于 7×7 卷积。
-
架构设计篇:运用 PyTorch 精确定义 VGG16 类,深入解析 “Conv - BN - ReLU - Pooling” 这一标准模块的构建原理与实现方式。
3. 训练实战篇:在小规模医学影像数据集上对 VGG16 模型进行严格验证,并精心调优如 batch_size、学习率等关键超参数,以实现模型性能的最优化。
若您希望免费获取本系列文章的完整代码,可通过添加 V 信:18983376561 来获取。
一、VGG16 架构
VGG16 作为卷积神经网络中的经典架构,其结构清晰且具有强大的特征提取能力。下面是 VGG16 的架构图:
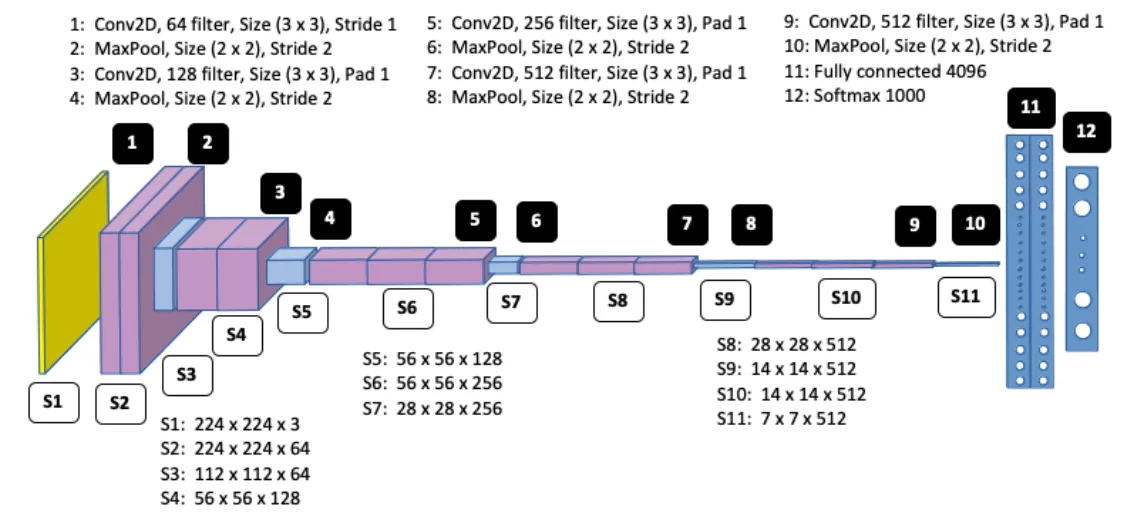
二、训练流程与代码解析
1. 数据预处理:让图像适应模型输入
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。
然而,VGG16 模型原设计是针对 224x224 的图像输入。为了使 CIFAR10 数据集能够适配 VGG16 模型,我们需要对图像进行预处理。具体而言,通过transforms.Resize((224, 224))将图像缩放至 224x224 的尺寸,再利用Normalize进行标准化处理,将均值和标准差均设为 0.5,从而使像素值归一化到 [-1, 1] 区间。以下是关键代码片段:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchinfo import summaryfrom VGG16 import VGG16
device = torch.device('cuda')transform_train = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
2. 数据加载:高效读取与批量处理
为了实现数据的高效读取与批量处理,我们使用DataLoader来加载数据。设置batch_size = 128,以平衡内存使用和训练效率;同时,设置num_workers = 12,利用多线程技术加速数据读取过程。对于训练集,我们将shuffle参数设置为True,打乱数据顺序,避免模型记忆数据顺序而导致过拟合;对于测试集,将shuffle参数设置为False,保持数据顺序,便于结果的复现和评估。以下是具体代码:
train = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(train, batch_size=128, shuffle=True, num_workers=12)test = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(test, batch_size=128, shuffle=False, num_workers=12)
3. 模型构建:调用自定义 VGG16 网络
在代码中,我们假设VGG16类已经被正确定义,该类应包含 16 层卷积层和全连接层结构。通过model.to(device)将模型部署到 GPU 上进行训练,以加速训练过程。由于 CIFAR10 是一个 10 分类任务,因此模型的最终全连接层输出维度应为 10。如果没有可用的 GPU,需要将device设置为cpu,但训练速度会显著降低。
4. 训练配置:损失函数与优化策略
在训练过程中,我们需要选择合适的损失函数和优化策略来指导模型的学习。具体配置如下:
- 损失函数:选用
CrossEntropyLoss来处理多分类问题,该损失函数会自动整合 Softmax 计算,简化了代码实现。 - 优化器:选择随机梯度下降(SGD)作为优化器,设置学习率
lr = 0.1,动量momentum = 0.9以加速收敛过程,同时设置权重衰减weight_decay = 0.0001,采用 L2 正则化防止模型过拟合。 - 学习率调度器:使用
ReduceLROnPlateau根据验证损失自动调整学习率。当验证损失连续 5 个 epoch 未下降时,学习率将乘以 0.1(factor = 0.1),这样可以避免模型陷入局部最优解。以下是相关代码:
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
model = VGG16().to(device)criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=0.0001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor = 0.1, patience=5)EPOCHS = 200
for epoch in range(EPOCHS):losses = []running_loss = 0for i, inp in enumerate(trainloader):inputs, labels = inpinputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)losses.append(loss.item())loss.backward()optimizer.step()running_loss += loss.item()if i % 100 == 0 and i > 0:print(f'Loss [{epoch + 1}, {i}](epoch, minibatch): ', running_loss / 100)running_loss = 0.0avg_loss = sum(losses) / len(losses)scheduler.step(avg_loss)
5. 训练循环:迭代优化与监控
在 200 个 epoch 的训练过程中,我们每 100 个批次打印一次平均损失,以便实时监控模型的训练进度。从输出日志可以看出,模型初始损失较高(第 1 个 epoch 约为 2.3),随着训练的不断进行,损失逐渐下降,最终损失趋近于 0.001 左右,这表明模型对训练数据的拟合效果良好。
print('Training Done')
# Loss [1, 100](epoch, minibatch): 3.8564858746528627
# Loss [1, 200](epoch, minibatch): 2.307221896648407
# Loss [1, 300](epoch, minibatch): 2.304955897331238
# Loss [2, 100](epoch, minibatch): 2.3278213500976563
# Loss [2, 200](epoch, minibatch): 2.3041475653648376
# Loss [2, 300](epoch, minibatch): 2.3039899492263793
# ...
# Loss [199, 100](epoch, minibatch): 0.001291145777431666
# Loss [199, 200](epoch, minibatch): 0.0017596399529429619
# Loss [199, 300](epoch, minibatch): 0.0013808918403083225
# Loss [200, 100](epoch, minibatch): 0.0013940928343799896
# Loss [200, 200](epoch, minibatch): 0.0011531753832969116
# Loss [200, 300](epoch, minibatch): 0.001689423452335177
三、训练结果与问题分析
在训练完成后,我们可以对模型进行保存和加载操作,以便后续的使用和评估。以下是保存和加载模型的代码示例:
# 保存整个模型
torch.save(model, 'VGG16.pth')# 或者只保存模型的参数
torch.save(model.state_dict(), 'VGG16_params.pth')# 加载整个模型
loaded_model = torch.load('VGG16.pth')# 或者加载模型的参数
loaded_params = torch.load('VGG16_params.pth')# 如果只加载了模型的参数,需要先将参数加载到模型对象中
# 假设我们有一个新的模型实例
new_model = VGG16(num_classes=10)
new_model.load_state_dict(loaded_params)correct = 0
total = 0with torch.no_grad():for data in testloader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print('Accuracy on 10,000 test images: ', 100 * (correct / total), '%')
通过测试集计算模型的准确率,我们得到约 86.5% 的结果。然而,需要注意以下两个问题:
- CIFAR10 的挑战:CIFAR10 数据集中的图像分辨率较低(32x32),图像细节较少,并且部分类别之间存在一定的相似性(如狗与猫),这对模型的特征提取能力提出了较高的要求。
- 过拟合风险:训练损失极低,但测试准确率未能达到 90% 以上,这可能表明模型存在过拟合现象,即模型在训练集上的表现远好于在测试集上的表现。
四、优化方向:如何让模型更上一层楼
1. 数据增强:对抗过拟合的 “核武器”
原代码未使用数据增强技术,为了提高模型的泛化能力,我们可以添加以下数据增强操作:
- 随机裁剪与翻转:使用
transforms.RandomCrop(32, padding = 4)和transforms.RandomHorizontalFlip(),增加数据的多样性,使模型能够学习到更多不同视角和位置的特征。 - 颜色扰动:通过
transforms.ColorJitter(brightness = 0.1, contrast = 0.1, saturation = 0.1),增强模型对色彩变化的鲁棒性,使其能够适应不同光照和色彩条件下的图像。 - Cutout/MixUp:采用随机遮挡图像区域(Cutout)或混合样本(MixUp)的方法,进一步提升模型的泛化能力。
2. 模型调整:更适配小数据集的设计
- 使用预训练模型:可以将在 ImageNet 上预训练的 VGG16 模型权重迁移到 CIFAR10 任务中。但需要注意输入尺寸的差异(从 224 调整为 32),可以尝试冻结部分卷积层,只对后续层进行微调。
- 轻量化改进:VGG16 模型的参数量较大(约 1.38 亿),对于 CIFAR10 这样的小数据集可能会导致过拟合。可以考虑改用更小的网络,如 VGG11、ResNet18,或者减少通道数(如将起始通道从 64 减少到 32)。
- 添加 Dropout:在全连接层前插入
nn.Dropout(0.5),抑制神经元之间的共适应现象,降低模型过拟合的风险。
3. 优化策略升级
- 学习率策略:可以改用余弦退火(Cosine Annealing)或周期性学习率(CLR)策略,动态调整学习率,帮助模型逃离鞍点,提高收敛速度和性能。
- 优化器选择:尝试使用 AdamW(结合权重衰减的 Adam)或 RMSprop 等优化器,这些优化器在处理稀疏梯度场景时可能更有效。
- 混合精度训练:使用 PyTorch 的
torch.cuda.amp模块进行混合精度训练,减少显存占用并加速训练过程,尤其适用于长周期的训练任务。
4. 训练技巧与调参
- 早停(Early Stopping):监控验证集损失,若连续多个 epoch 验证集损失未提升,则提前终止训练,避免无效的训练过程。
- 标签平滑(Label Smoothing):在损失函数中引入标签平滑技术,防止模型对单一类别过度自信,提高模型的泛化能力。
- 调整批量大小:尝试使用更小的
batch_size(如 64)以增加梯度更新的频率,或者使用更大的批量(如 256)以充分利用 GPU 的并行计算能力。
5. 测试阶段优化
- 测试时增强(TTA):在测试阶段,对测试图像进行多尺度裁剪、翻转等操作,然后取预测结果的平均值,提升预测的鲁棒性。
- 集成学习:训练多个不同初始化的 VGG 模型,通过投票或平均法融合这些模型的预测结果,降低模型的随机性影响,提高整体性能。
五、总结与实践建议
本次实战通过在 CIFAR10 数据集上训练 VGG16 模型,全面展示了深度学习从数据预处理到模型部署的完整流程。86.5% 的准确率仅仅是一个起点,通过采用数据增强、模型轻量化、优化策略调整等一系列优化手段,完全有能力将模型的准确率提升至 90% 以上(CIFAR10 的当前最优模型准确率可达 95% 以上)。
深度学习的学习过程需要理论与实践紧密结合,希望大家能够动手实践,亲自体验模型优化的过程。如果您需要完整代码或希望进行进一步的讨论,欢迎在评论区留言。







详解)


)

)

)




