自然语言处理NLP中的连续词袋(Continuous bag of words,CBOW)方法、优势、作用和程序举例
目录
- 自然语言处理NLP中的连续词袋(Continuous bag of words,CBOW)方法、优势、作用和程序举例
- 一、连续词袋( Continuous Bag of Words, CBOW)介绍
- 1.1 什么是词嵌入( Word embeddings)
- 1.2 什么是连续词袋(CBOW)
- 1.3 连续词袋优势
- (1)高效性
- (2)灵活性
- (3)鲁棒性
- 1.4 CBOW模型体系结构(CBOW Architecture)
- 1.5 词袋( Bag-of-Words, BoW)模型和连续词袋(Continuous Bag-of-Words , CBOW)模型区别
- 二 、连续词袋的作用
- 2.1. 词嵌入生成
- (1)核心功能
- (2)工作原理
- 2.2. 提升语义理解能力
- (1)捕捉语义关系
- (2)减少维度灾难
- 三、连续词袋应用场景
- 3.1 文本分类
- 3.2 机器翻译
- 3.3 情感分析
- 3.4 信息检索
- 四、CBOW代码实现举例
- 4.1 对词语料库进行向量化
- 4.2 构建一个CBOW模型
- 4.3 使用模型可视化词嵌入
- 五、总结
为了使得计算机理解一个文本,可以将文本中的词表示为数字向量。连续词袋(Continuous Bag of Words, CBOW)是一种用于自然语言处理中的词嵌入模型,它是Word2Vec算法的一种变体。
Word2vec是一种基于神经网络的生成单词嵌入的方法,它是词的密集向量表示( dense vector representations of words),能够描述词的语义和关系。实现 Word2vec主要有两种方法:(1) 连续词袋(Continuous bag-of-words, CBOW) ; (2) 跳字模型(Skip-gram)。
本节重点介绍连续词袋(Continuous bag-of-words, CBOW) 内容。
一、连续词袋( Continuous Bag of Words, CBOW)介绍
1.1 什么是词嵌入( Word embeddings)
词嵌入(Word embeddings)是多数NLP任务中重要的描述了词的语义以及语言中词之间的句法关系的方法,是一种表示词为数字向量的方法。
1.2 什么是连续词袋(CBOW)
CBOW是一种根据目标词周围上下文预测目标词的基于神经网络的算法,是一种用于生成词嵌入的流行的自然语言处理技术。它是一种可以从未标记的数据中学习的无监督学习方法,如图1所示。
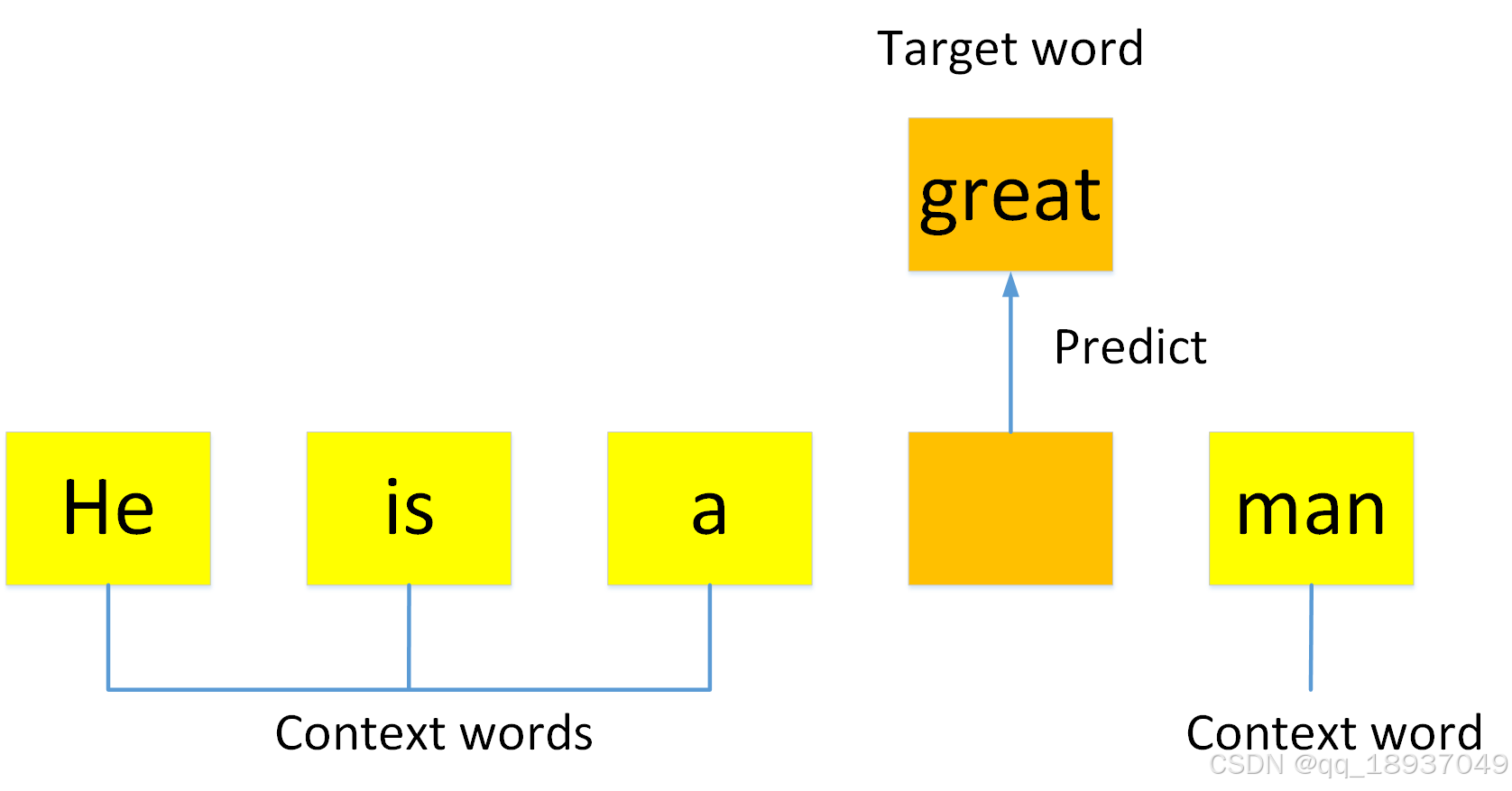
图1 CBOW模型举例
1.3 连续词袋优势
(1)高效性
相比其他方法,CBOW能够在较短的时间内完成大规模数据集上的训练。
(2)灵活性
可以很容易地集成到更复杂的NLP系统中去。
(3)鲁棒性
即使面对拼写错误或罕见词汇时,也能给出合理的表示。
1.4 CBOW模型体系结构(CBOW Architecture)
CBOW模型使用周围的上下文词来预测目标词。考虑上面的例子’’ He is a great man“。CBOW模型将该短语转换为上下文词和目标词对。在窗口大小为2的情况下,词对(word pairings)将呈现如下形式([He, a],is), ([is, great], a), ([a, man],great)。
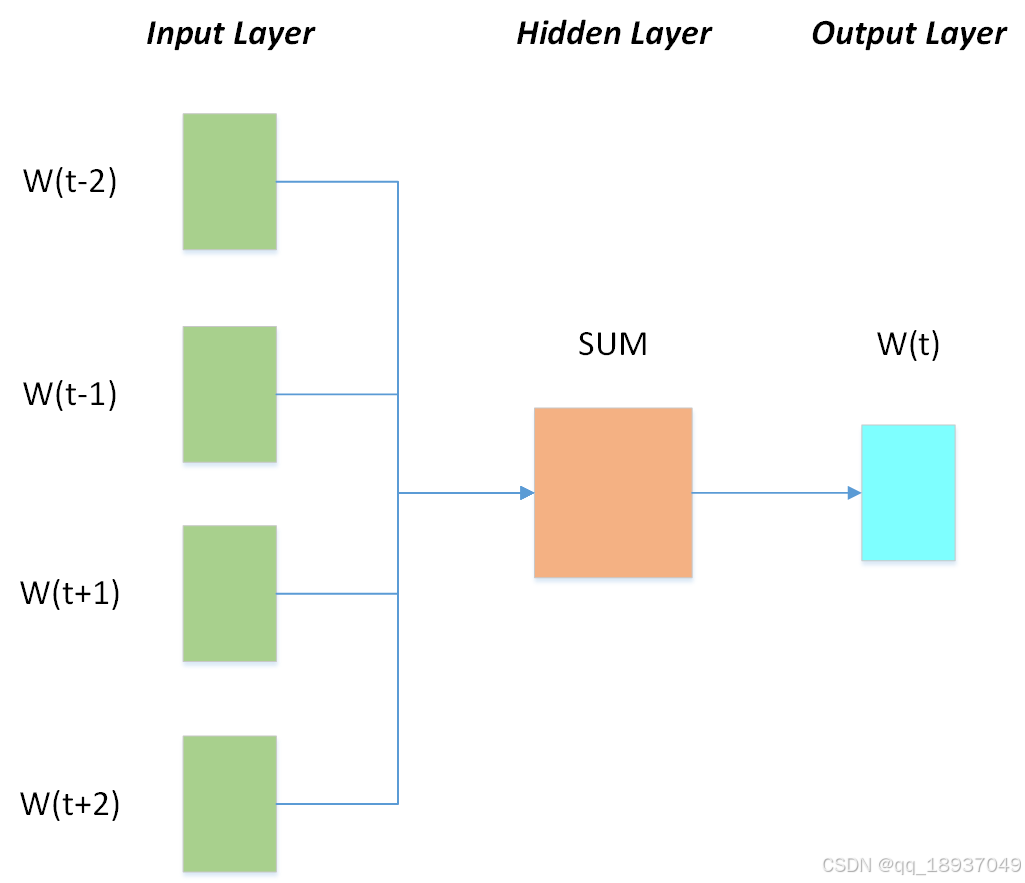
图2 CBOW模型体系结构
该模型考虑上下文单词,并尝试预测目标词。如果使用四个单词作为上下文单词来预测一个目标词,则四个1∗W输入向量将被传递给输入层(input layer)。隐藏层(hidden layer )将接收输入向量,然后将它们乘以 W∗N 矩阵。最后,来自隐藏层的1∗N输出进入求和层。在该层中,向量进行元素级求和再执行最终激活,然后从输出层获得输出。
1.5 词袋( Bag-of-Words, BoW)模型和连续词袋(Continuous Bag-of-Words , CBOW)模型区别
词袋模型BoW和连续词袋模型CBOW都是自然语言处理中使用的以计算机可读格式表示文本的技术,但它们在描述上下文的方式上有所不同。
(1) BoW模型将给定文档(given document)或语料库(corpus)中的文本表示为单词及其频率的集合。它不考虑单词出现的顺序或上下文,因此,它可能无法捕获文本的全部含义。BoW模型简单易实现,但在理解语言意义方面存在局限性。
(2)相比之下,CBOW模型是一种基于神经网络的方法,可以捕获单词的上下文。它根据上下文窗口前后出现的词来学习预测目标词。CBOW模型通过考虑周围的词,可以更好地捕捉给定上下文中的词义。
二 、连续词袋的作用
连续词袋的作用主要有以下四方面:
2.1. 词嵌入生成
(1)核心功能
CBOW通过上下文预测目标词的方式,将词语映射到一个固定维度的稠密向量空间中。
(2)工作原理
给定一个词的上下文(即若干个相邻的词),模型的目标是预测这个上下文所对应的中心词。例如,在句子“我喜欢吃西红柿”中,如果已知上下文是“喜欢”和“吃”,那么CBOW会尝试预测中心词“西红柿”。
2.2. 提升语义理解能力
(1)捕捉语义关系
通过训练,CBOW能够捕捉到词汇之间的语义关系。比如,“国王”与“王后”的关系类似于“男人”与“女人”的关系。
(2)减少维度灾难
相比于传统的稀疏表示方法,词嵌入可以有效减少数据维度,使得后续任务更加高效。
三、连续词袋应用场景
3.1 文本分类
利用预训练好的词向量作为特征输入到分类器中。
3.2 机器翻译
在神经网络翻译模型中使用词向量来提高翻译质量。
3.3 情感分析
通过对文本进行词嵌入后,可以更好地识别文本的情感倾向。
3.4 信息检索
基于词向量的距离度量来进行文档相似度计算或者查询扩展。
四、CBOW代码实现举例
在此,通过CBOW模型实现词嵌入,以展示单词之间的相似性。在本文中,定义了自己的词语料库,你可以使用任何数据集。
4.1 对词语料库进行向量化
首先,将导入所有必要的库;其次,定义语料库。然后,将对每个单词进行分词( tokenize each word),并将其转换为整数向量。
# 1.导入需要的模块
from tensorflow.keras.preprocessing.text import Tokenizer# 2.定义语料库
corpus = ['The Fish swam in the water','The cat sat on the mat','The horse galloped on the grassland','The dog ran in the park','The bird sang in the tree'
]# 3.将语料库转换为整数向量
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
print("将语料库中的单词转换为整数向量后:",sequences)运行输出结果: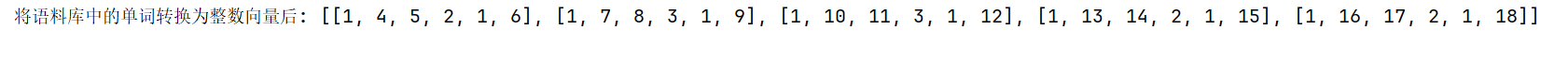
4.2 构建一个CBOW模型
接着,建立一个窗口大小=2的CBOW模型
# 1.导入需要的模块
from tensorflow.keras.preprocessing.text import Tokenizer
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Lambda, Dense
import tensorflow as tf
# 2.定义语料库
corpus = ['The Fish swam in the water','The cat sat on the mat','The horse galloped on the grassland','The dog ran in the park','The bird sang in the tree'
]# 3.将语料库转换为整数向量
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
print("将语料库中的单词转换为整数向量后:",sequences)# 4。定义参数
vocab_size = len(tokenizer.word_index) + 1
embedding_size = 10
window_size = 2# 5.产生上下文——目标对
contexts = []
targets = []
for sequence in sequences:for i in range(window_size, len(sequence) - window_size):context = sequence[i - window_size:i] + sequence[i + 1:i + window_size + 1]target = sequence[i]contexts.append(context)targets.append(target)# 6.转换上下文和目标为numpy向量X = np.array(contexts)
y = to_categorical(targets, num_classes=vocab_size)# 7.定义CBOW模型model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embedding_size, input_length=2 * window_size))
model.add(Lambda(lambda x: tf.reduce_mean(x, axis=1)))
model.add(Dense(units=vocab_size, activation='softmax'))# 8.编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 9.训练此模型
model.fit(X, y, epochs=100, verbose=0)
print(model.summary())
运行结果为:

4.3 使用模型可视化词嵌入
最后,使用模型进行可视化。
# 1.导入需要的模块
from tensorflow.keras.preprocessing.text import Tokenizerimport numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Lambda, Dense
import tensorflow as tffrom sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 2.定义语料库
corpus = ['The Fish swam in the water','The cat sat on the mat','The horse galloped on the grassland','The dog ran in the park','The bird sang in the tree'
]# 3.将语料库转换为整数向量
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
print("将语料库中的单词转换为整数向量后:",sequences)# 4.定义参数
vocab_size = len(tokenizer.word_index) + 1
embedding_size = 10
window_size = 2# 5. 产生上下文——目标对
contexts = []
targets = []
for sequence in sequences:for i in range(window_size, len(sequence) - window_size):context = sequence[i - window_size:i] + sequence[i + 1:i + window_size + 1]target = sequence[i]contexts.append(context)targets.append(target)# 6. 转换上下文和目标为numpy向量X = np.array(contexts)
y = to_categorical(targets, num_classes=vocab_size)# 7. 定义CBOW模型model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embedding_size, input_length=2 * window_size))
model.add(Lambda(lambda x: tf.reduce_mean(x, axis=1)))
model.add(Dense(units=vocab_size, activation='softmax'))# 8.编译模型model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 9.训练此模型
model.fit(X, y, epochs=100, verbose=0)# 10.提取词嵌入
# Extract the embeddings
embedding_layer = model.layers[0]
embeddings = embedding_layer.get_weights()[0]# 11.执行PCA以降低词嵌入维度pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(embeddings)# 12.可视化词嵌入
plt.figure(figsize=(6, 6))
for word, idx in tokenizer.word_index.items():x, y = reduced_embeddings[idx]plt.scatter(x, y)plt.annotate(word, xy=(x, y), xytext=(5, 2),textcoords='offset points', ha='right', va='bottom')
plt.title("Word Embeddings Visualized")
plt.show()
运行结果:
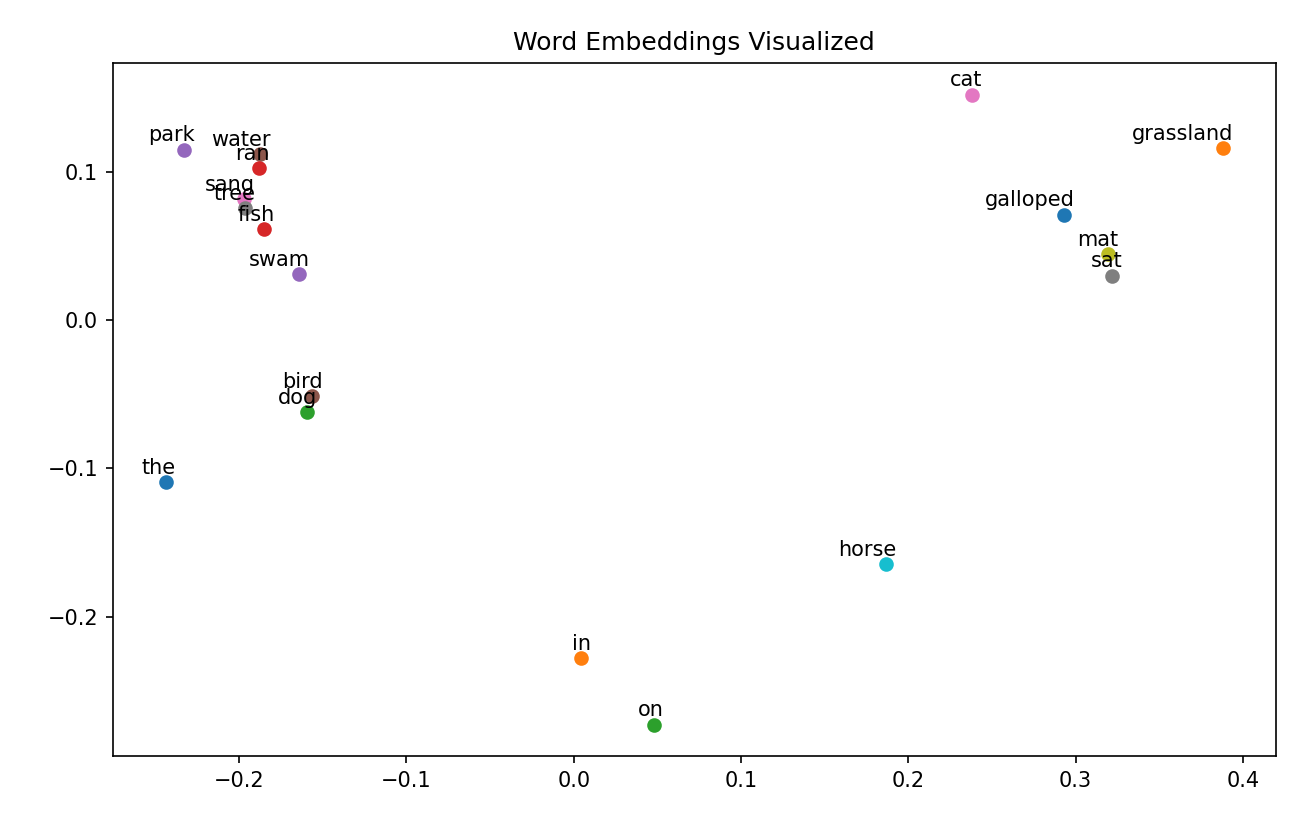
这种可视化使能够根据单词的嵌入来观察单词的相似性。词或上下文意思相似的,在图中应该彼此接近。
五、总结
连续词袋模型通过学习词语之间的共现概率分布,成功地将离散的词汇转换成了连续的空间表示形式,这对于许多需要深层次语义理解的应用来说是非常重要的工具之一。本文介绍了自然语言处理NLP中的连续词袋(Continuous bag of words,CBOW)的概念,优势,作用,应用场景,并通过程序举例说明其用法。


)




)




)






