【自然语言处理】用 Word2Vec 将词语映射到向量空间详解
一、背景介绍
在自然语言处理(NLP)领域,我们常常需要将文本信息转化为机器能够理解和处理的形式。传统的方法,如 one-hot编码,虽然简单,但存在严重的稀疏性和高维度问题,且无法体现词语之间的语义关系。
为了解决这一问题,研究人员提出了Word Embedding(词嵌入)的方法。其中最著名、应用最广泛的模型之一便是 Word2Vec。
二、什么是 Word2Vec?
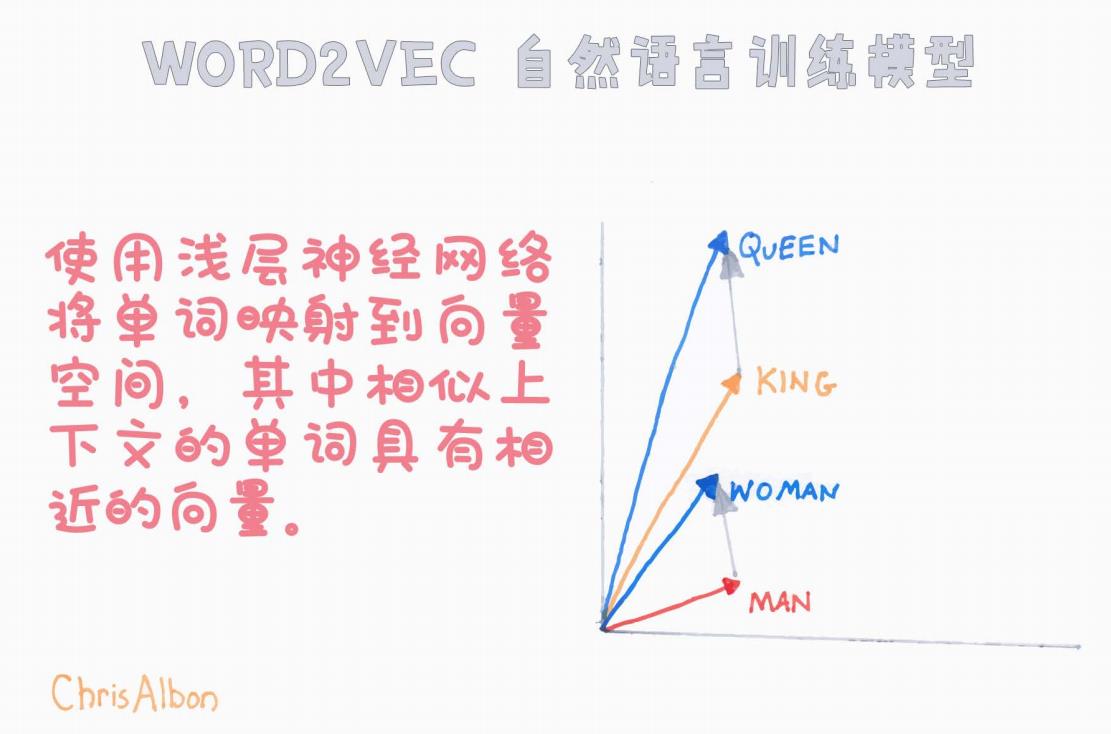
Word2Vec 是由 Google 团队在 2013 年提出的一种将单词映射为连续向量的浅层神经网络模型。
其核心思想是:
将词语投影到一个低维度的向量空间中,使得语义上相近或语法上相关的词在向量空间中也接近。
简单来说,Word2Vec 可以把“王(king)”和“女王(queen)”之间的关系,与“男人(man)”和“女人(woman)”之间的关系用向量差异表示出来,且这些关系在向量空间中保持一致。
从图中可以看到,
-
King - Man + Woman ≈ Queen
也就是:“男人之于国王,就像女人之于女王”。
这种特性使得 Word2Vec 在 NLP 各种任务中都发挥了巨大的作用,如文本分类、情感分析、机器翻译、推荐系统等。
三、Word2Vec的两种训练方法
Word2Vec 提供了两种主要的训练策略:
-
CBOW(Continuous Bag of Words,连续词袋模型)
-
通过上下文词(周围的词)来预测当前的中心词。
-
适合小型数据集,训练速度快。
-
示例:给定句子 "The cat sits on the mat",如果中心词是 "sits",那么输入是 "The", "cat", "on", "the", "mat",目标是预测 "sits"。
-
-
Skip-gram
-
通过当前词预测周围的上下文词。
-
更适合大规模数据集,且能够更好地捕捉稀有词的信息。
-
示例:给定中心词 "sits",目标是预测 "The", "cat", "on", "the", "mat"。
-
这两种方式本质上都是在通过局部上下文来学习词的分布式表示(distributional representations)。
四、向量空间的语义特性
如图所示,经过训练后,单词被映射到一个高维向量空间,具备如下特性:
-
语义相似性:词义相近的词在空间中位置也接近。
-
例子:king 与 queen,man 与 woman。
-
-
语法相似性:词性相同的词之间的向量方向相近。
-
例子:复数形式(cars vs. car),时态变化(running vs. run)。
-
-
向量运算:可以用简单的向量加减表示词与词之间的关系。
-
例子:
vector(king) - vector(man) + vector(woman) ≈ vector(queen)。
-
这一点,极大地提升了自然语言处理中理解、推理和生成文本的能力。
五、技术细节:训练过程
Word2Vec 的训练过程其实非常高效,主要分为以下几个步骤:
-
初始化词向量:为每个词随机初始化一个向量。
-
正样本采样:根据训练策略(CBOW或Skip-gram),抽取正样本。
-
负样本采样(Negative Sampling):为了减少计算量,仅更新少量负样本而不是全部词汇表。
-
误差反向传播:通过浅层神经网络(通常只有一层),更新词向量。
-
迭代优化:通过多次遍历数据集(epoch),使向量逐渐收敛。
最终,得到的词向量可以直接用于后续各种NLP任务。
六、应用场景
-
文本相似度计算:基于词向量的余弦相似度评估两段文本的相似性。
-
推荐系统:基于用户历史偏好推荐相关内容(例如基于文章标题、商品描述的Embedding相似性)。
-
情感分析:通过分析词向量组合,预测评论、帖子中的情感倾向。
-
问答系统:辅助搜索最相关的答案。
-
知识图谱构建:在向量空间中发现实体之间的潜在关联。
七、总结
Word2Vec 作为自然语言处理中里程碑式的技术,为后来的各种深度学习模型(如BERT、GPT)奠定了基础。
即使到今天,理解词嵌入和向量空间的基本原理,仍然是掌握高级自然语言处理技术的重要前提。
本文通过图示,简单直观地展示了 Word2Vec 如何将单词映射到向量空间,并体现出词语之间微妙而丰富的语义关系。
希望能帮助你更好地理解这一经典模型,为后续深入学习打下基础!
八、参考资料
-
Tomas Mikolov et al. (2013), “Efficient Estimation of Word Representations in Vector Space”
-
Chris Albon, Machine Learning Flashcards
-
《Deep Learning》 — Ian Goodfellow 等
🔔 如果你觉得本文有帮助,欢迎点赞、收藏或留言交流!






)


 和 annotate() 方法详解)


)


---无效区域的处理)



