目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
1、准备工作
准备工作在性能测试中,是最为耗时以及麻烦的,不仅需要各个团队协同配合,还需要不断验证,以确保相关的准备事项不会对性能测试结果造成较大影响。
以我司的性能测试流程来说,准备阶段的各事项以及对应责任人,如下图:
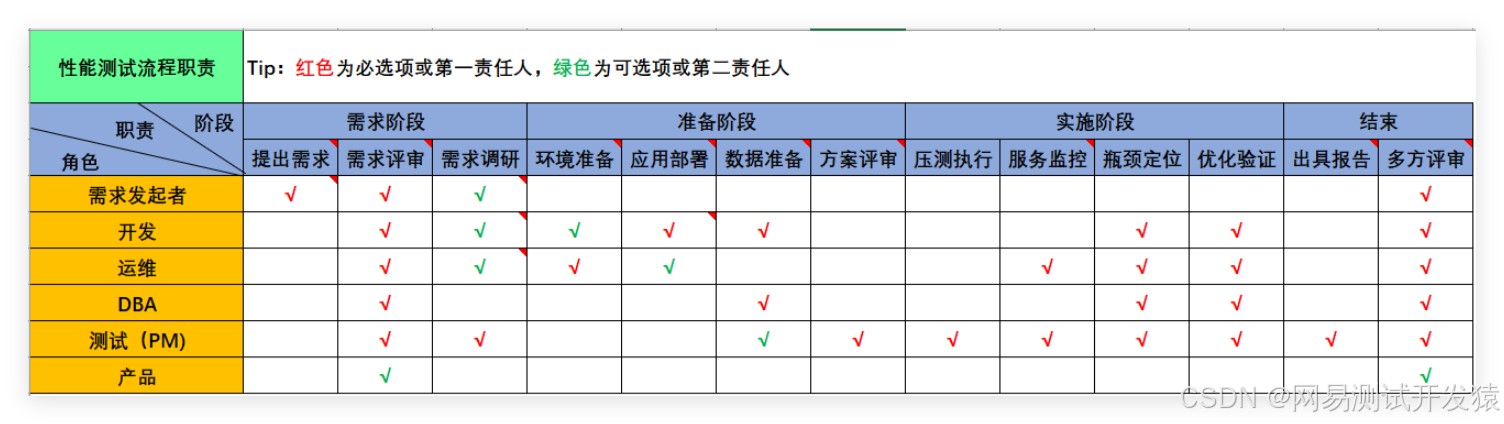
在准备阶段,性能测试童鞋,要尽可能承担起PM这一角色的职责,跨部门沟通,协调资源以及推动准备工作的快速落地,这样才能在有限时间内完成准备事项,为压测预留足够的时间。
2、压测监控
完成了前面的几项工作,就可以进入压测阶段了,这一阶段,可以分为两部分,压测+监控。
1)压测
压测工作主要有如下几种情景,按照预先制定的测试策略执行即可(不排除临时特殊情况,这里需灵活调整)。
①单机单接口测试:该策略主要是为了验证单接口的性能基准,避免整个调用链路过程中某个服务/接口成为瓶颈;
②单机多接口测试:相较于微服务架构的服务解耦,有时候某些服务间互相调用依赖的强关系可能会造成资源竞争等情况,需要通过这种方式来排查验证;
③单机混合场景测试:这种测试方式的主要作用是得到一个单机混合场景下的最优性能表现,为服务扩容和线上容量规划提供参考数据;
④多节点测试:现在大多数的互联网企业都采用的集群/分布式/微服务架构,在多节点部署时候,考虑到SLB的边际递减效应,需要进行多节点测试;
通过该种方式,来验证负载均衡递减比率,为生产扩容提供精确的参考依据;
⑤高可用测试:高可用主要验证2点:服务异常/宕机是否可以恢复以及恢复到正常水*所耗费的时间(越短越好)。
⑥稳定性测试:前面提到了核心业务流程必须保证稳定性,稳定性测试一般根据系统特点和业务类型,分为两类:5d*12h、7d*24h。
一般来说,稳定性测试的执行时间,12h即可(当然,24h或者更长也可以,根据具体情况灵活调整)。
2)监控
性能测试过程中,监控是很重要的一环,它可以帮助我们验证测试的结果是否满足预期指标,以及协助我们发现系统存在的问题。常见的监控指标如下:
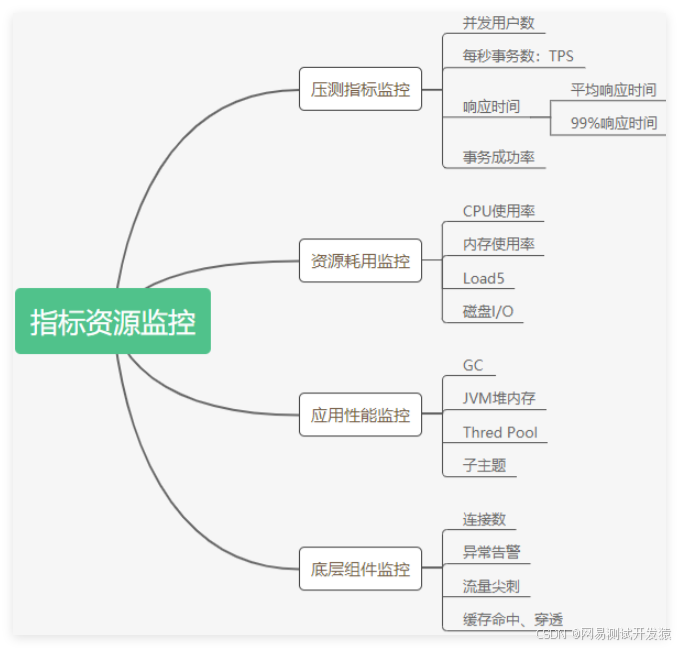
那么如何监控这些指标呢?
如果采用的云服务器(比如阿里云),现在国内的云厂商都提供了监控大盘以及各种监控服务(比如阿里云的APM、ARMS、AHAS)。
如果是自建服务机房,可以借助运维搭建的监控体系,比如全链路追踪(pinpoint、cat、zipkin、skywalking),专业的监控工具比如Nmon、Zabbix等。
测试指标的监控,可以搭建基于开源组件的Grafana+InfluxDB+Jmeter+Nmon2influxdb,或者ELK等监控体系。
3、分析调优
1)性能分析
性能分析是一个复杂的话题,不同的系统架构设计、应用场景、业务逻辑、编程语言及采用的框架,都有一定的差异。抽象来说,有如下三种分析思路:
①自上而下:即通过生成负载来观察被测系统的性能表现,比如通过对TPS、RT等指标的监控,从请求发起端到OS端层层剖析,从而找到系统性能瓶颈。
②自下而上:通过监控各硬件及操作系统相关指标(CPU、Memory、磁盘I/O、网络)来分析性能瓶颈。
③从局部到整体:即通过性能表象结合工作经验做快速排除,确定可能存在瓶颈的局部所在,快速修改验证,避免大而全的全面分析带来的耗时,提高效率。
2)性能调优
性能调优主要关注三个方面:降低响应时间、提高系统吞吐量、提高服务的可用性。
性能优化的目的是:在保持和降低系统99%RT的前提下,不断提高系统吞吐量以及流量高峰时期的服务可用性。
性能调优建议遵循如下几点原则:
①Gustafson定律:系统优化某组件所获得的系统性能的改善程度,取决于该部件被使用的频率,或所占总执行时间的比例。
②Amdahl定律:S=1/(1-a+a/n)
其中,a为并行计算部分所占比例,n为并行处理结点个数。这样,当1-a=0时,(没有串行,只有并行)最大加速比s=n;
当a=0时(只有串行,没有并行),最小加速比s=1;当n→∞时,极限加速比s→ 1/(1-a),这也就是加速比的上限。
③最小可用原则:一般情况下,系统的代码量会随着功能的增加而变多,健壮性有时候也需要通过编写异常处理代码来实现,异常考虑越全面,异常处理的代码量就越大。
随着代码量的增大,引入BUG的概率也越大,系统也就越不健壮。从另一个方面来说,异常流程处理代码也要考虑健壮性的问题,这就形成了无限循环。
因此在系统设计和代码编写过程中,要求:一个功能模块如非必要,就不要;一段代码如非必写,则不写。
4、容量规划
性能测试的最终目的是保证线上服务的可用性,及时响应并满足业务需求。而容量规划,是对线上服务在峰值流量冲击下稳定运行的最佳保障。
1)单机混合容量
这里的容量指的是在单台服务器下,混合场景压测的最优性能表现(而不是最高)。比如一台4C8G的服务器,对核心业务场景进行按业务配比混合压测,示例如下图:
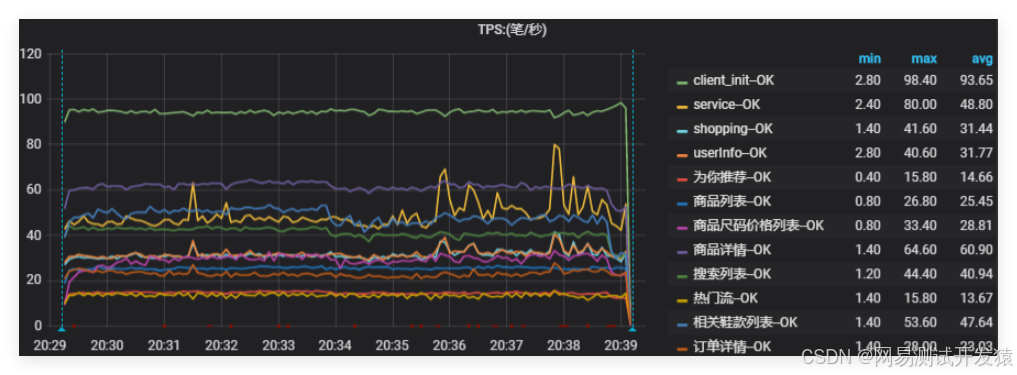
得到单机最优容量数值,然后可以通过增加被测系统的服务节点,来验证容量是否随着服务节点的增加而线性增长。
2)多节点SLB容量
以上面的示例图来说,单机最优TPS≈450,然后通过增加服务节点数量,再次压测,通过扩容后的压测数值除以服务节点数量,然后和单机混合容量对比,就可以得到多节点SLB的递减比率。
举例:扩容后的压测数值为R,服务节点数量为N,单机混合容量为D,那么多节点SLB的递减比率计算公式为:SLB%=(R/N)/D。
以前面的例子来说,单机混合容量为450,服务节点扩展到2台,得到测试结果为750,那么SLB%=(750/2)/450≈83.33%。
以此类推,如果预期线上性能指标要求TPS≥5000,那么通过计算,我们可以得到线上服务节点最少需要扩容到14台,才能满足需要。
PS:服务节点数量越多,那么递减效应越明显,建议通过测试多个服务节点的递减比率,来得到一个区间数。
3)告警阈值
这里的告警阈值,指的是运维同事对各个服务状态及相关资源指标进行监控时,设定的提醒和告警阈值。
前面所说的单机混合容量的最优值,建议结合运维设定的阈值来综合评估(比如运维告警设定的阈值是CPU使用率达到80%,那么就以单机CPU80%耗用下的容量数值作为计算基准)。
4)Buffer机
文章的开头已经说过,系统不仅要具有高可用和稳定性,还要具有容灾机制。比如某个或某部分服务不可用,服务器宕机,需要预留的机器来随时补上来。
本文所说的Buffer机,即作为预留容灾的机器。按照我个人的实践经验来说,以线上扩容机器数量的30%来作为预留Buffer机,已经能满足绝大部分情况(适合中小型团队)。
当然,有些特殊场景(比如2019年春节联欢晚会,百度承包的口令红包场景),就需要综合考虑更多的影响因素。
除了容量规划,我们还可以通过服务降级、网关限流甚至熔断等机制,来保证系统在峰值流量的冲击下保持服务可用。
完整版!企业级性能测试实战,速通Jmeter性能测试到分布式集群压测教程
| 下面是我整理的2025年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
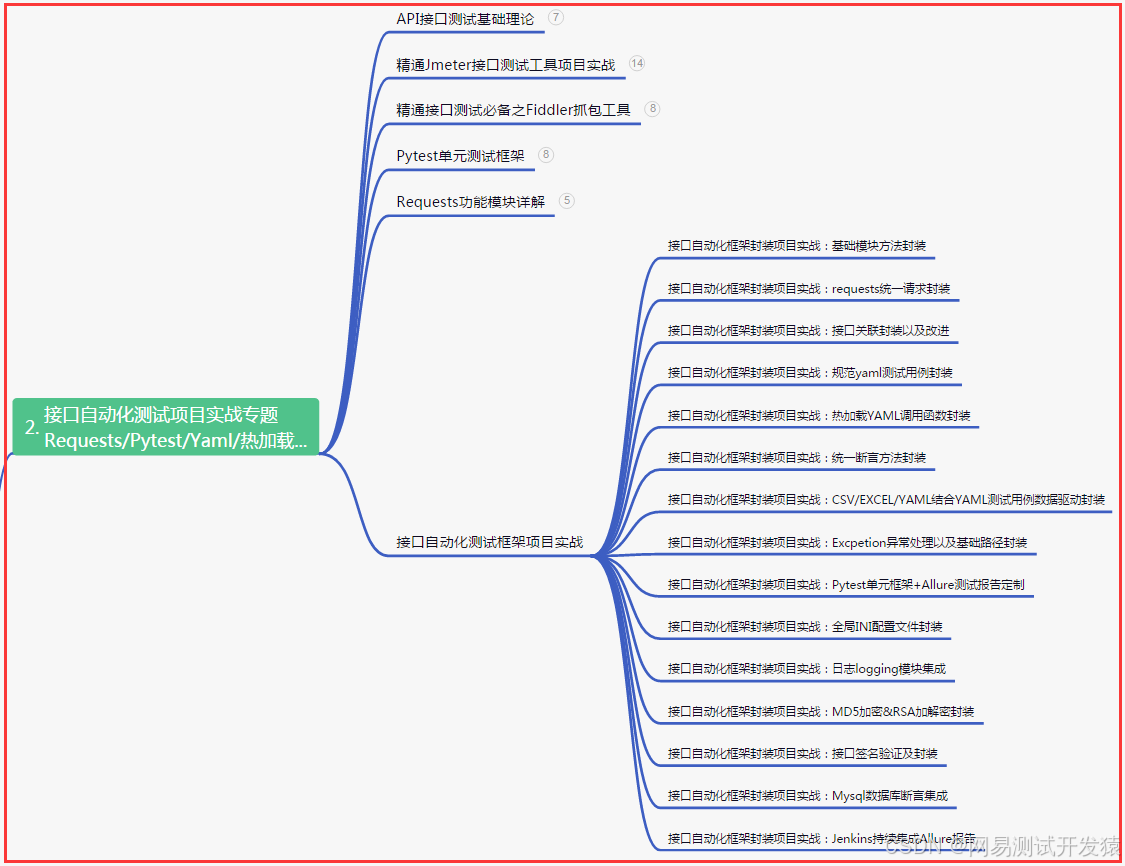
二、接口自动化项目实战
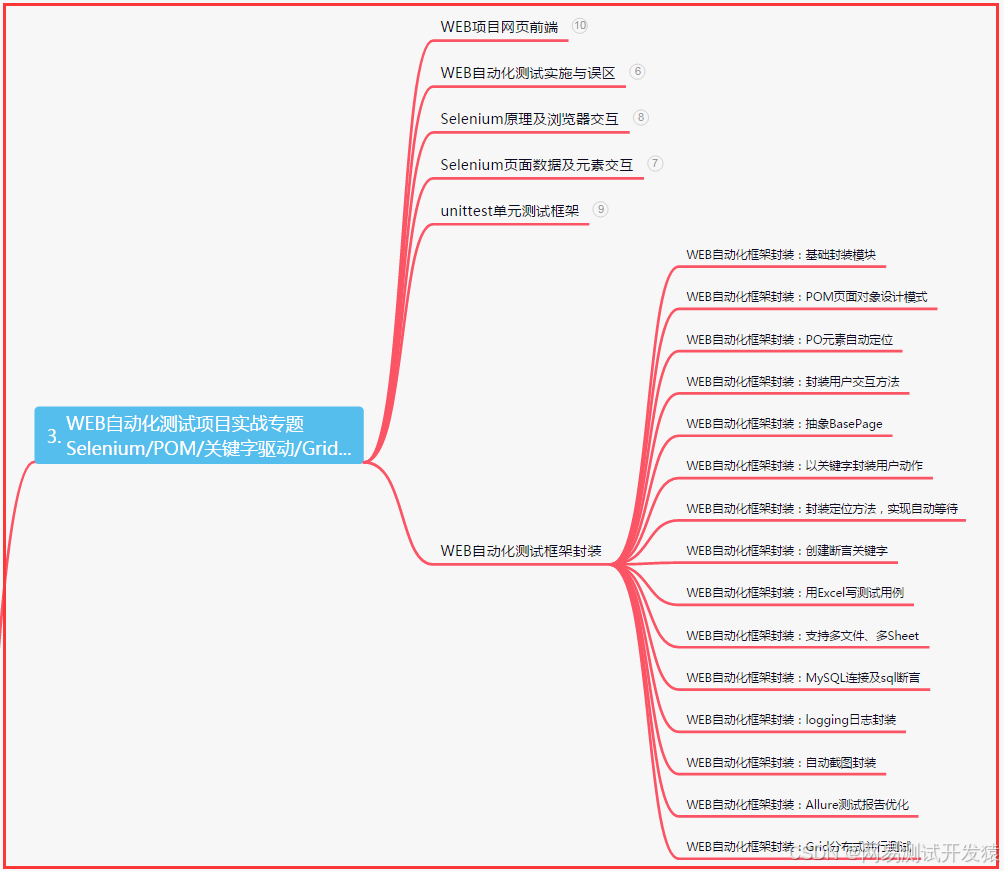
三、Web自动化项目实战
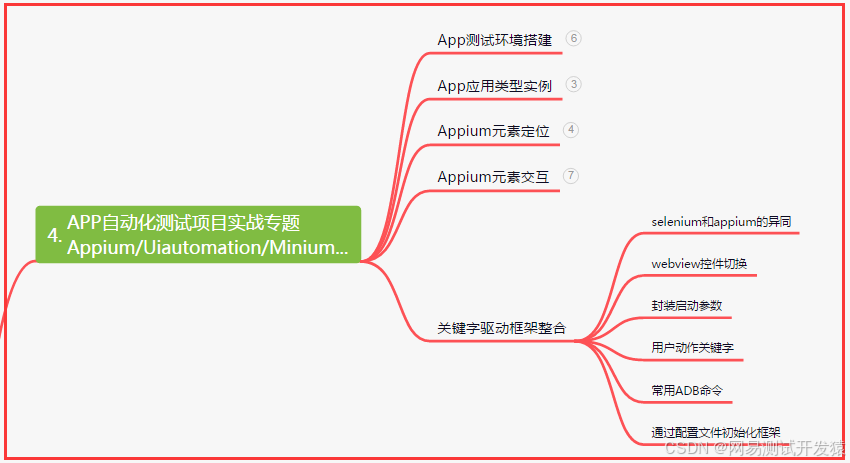
四、App自动化项目实战
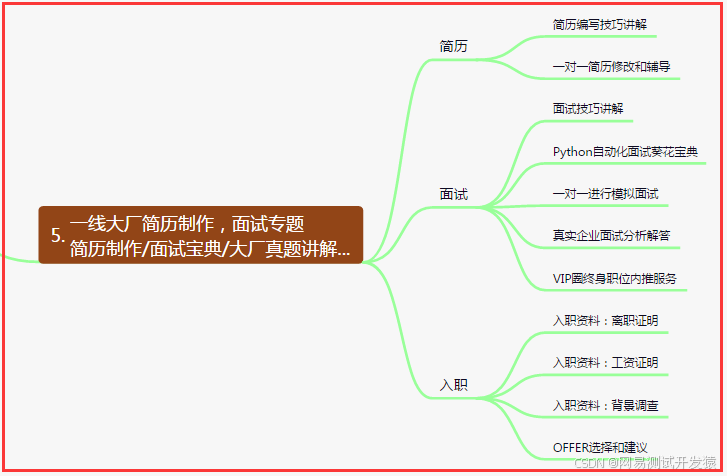
五、一线大厂简历
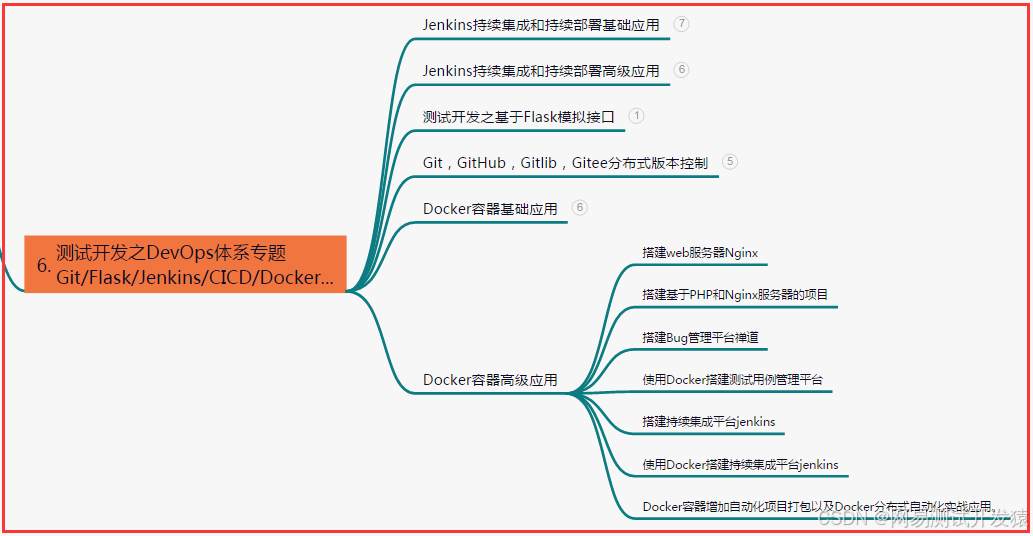
六、测试开发DevOps体系
七、常用自动化测试工具

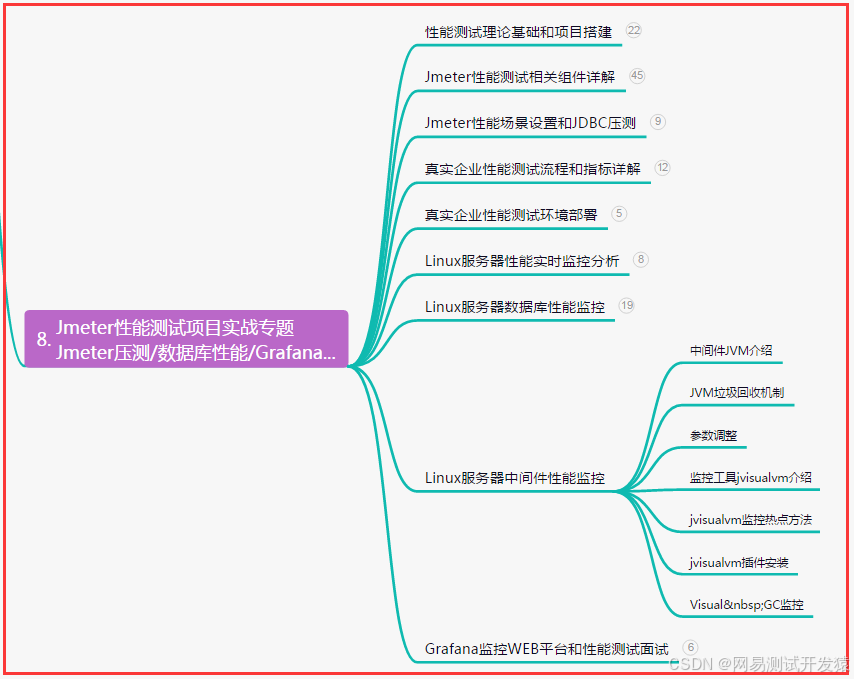
八、JMeter性能测试
九、总结(尾部小惊喜)
人生最动人的风景,往往藏在最险峻的山巅。当你觉得力竭时,请记住:每一次坚持都在重塑更强大的自己。别问路有多远,只管迈步向前;别怕山有多高,向上攀登就是答案!
你体内沉睡着改变世界的力量!每个清晨都是改写命运的新机会,每次挫折都是精心包装的礼物。当全世界都在说"不可能"时,正是你证明"可能"的最好时机!
 v1.0.2 绿色版)
)
:91-100语法+考え方13)


)

)





——非传统影像轻量级解决方案)




)
)