工业场景漏洞检测新突破:CodeBERT跨领域泛化能力评估与AI-DO工具开发
论文信息
- 论文原标题:Cross-Domain Evaluation of Transformer-Based Vulnerability Detection: Open-Source vs. Industrial Data
- 引文格式(APA):[作者]. (年份). Cross-Domain Evaluation of Transformer-Based Vulnerability Detection: Open-Source vs. Industrial Data. [期刊/会议名称, 卷(期), 页码]. https://arxiv.org/pdf/2509.09313
一段话总结
该论文聚焦学术领域漏洞检测深度学习方案在工业场景应用的痛点,构建了覆盖开源与工业的PHP函数漏洞标注数据集,通过不同数据平衡策略微调CodeBERT模型,评估其在跨领域(开源与工业数据)的漏洞检测性能,开发了集成于CI/CD流程的漏洞检测推荐系统AI-DO,并结合企业IT专业人员调查评估工具实用性,最终明确了CodeBERT在工业漏洞检测中的可行性及跨领域泛化能力,为学术技术向工业落地提供参考。
研究背景
在当下的软件安全领域,漏洞检测就像给软件“体检”,目的是找出潜在的“健康隐患”(漏洞),避免后续被黑客利用造成损失。然而,目前学术研究中提出的很多基于深度学习的漏洞检测方案,却像“实验室里的精密仪器”,在实际工业场景中“水土不服”。
一方面,这些学术方案的开发者可访问性低,工业界的开发团队想用上并不容易;另一方面,它们在工业场景的适用性没被充分验证,就像一款新药没在广泛的患者群体中测试,无法确定在实际治疗中的效果。从学术到工业的技术迁移,还面临着不少“拦路虎”:比如方案的可信度,工业界担心学术方案在真实复杂的工业环境中不靠谱;还有遗留系统问题,很多企业还在使用旧系统,学术方案可能无法兼容;同时,工业界部分人员数字素养有限,专业知识也和学术界存在差距,导致难以有效使用学术方案;另外,深度学习模型的性能以及和现有工作流的集成度,也是工业界非常顾虑的问题,毕竟如果模型性能差,或者和现有工作流程不契合,会严重影响工作效率。
举个例子,某制造企业使用基于PHP开发的ERP系统来管理生产、库存等核心业务,这个系统已经运行了十几年,属于遗留系统。之前尝试引入一款学术界提出的漏洞检测工具,结果要么因为工具无法适配旧系统的代码结构,要么检测出的漏洞和实际工业场景中的漏洞类型偏差大,还经常出现漏检或误检的情况,最终不得不放弃使用,还是依靠人工代码审查来检测漏洞,不仅效率低,还容易因为人为疏忽漏掉关键漏洞。
正是这些问题的存在,使得工业界对高效、适配的漏洞检测方案需求迫切,这也正是该论文研究的出发点。
创新点
- 构建独特数据集:填补了同时覆盖开源与工业PHP函数漏洞标注数据集的空白,且严格遵循数据集质量框架,保证了数据的准确性、唯一性、一致性、完整性和时效性,为后续跨领域评估提供了可靠的数据基础。
- 多维度跨领域评估:不仅评估CodeBERT在单一数据集(开源或工业)上的漏洞检测性能,更重点分析了模型在开源数据上微调后测试工业数据(反之亦然)的跨领域泛化能力,还对比了不同数据平衡策略对跨领域性能的影响,视角更全面。
- 实用工具开发与反馈收集:并非只停留在理论研究和模型评估,而是开发了可集成于CI/CD流程的漏洞检测推荐系统AI-DO,能自动在代码审查阶段检测并标记漏洞函数,还通过企业IT专业人员调查,收集真实使用反馈,为工具优化和工业落地提供依据,实现了从理论到实践的落地。
- 优先考虑工业场景需求:在评估指标中,充分考虑到工业漏洞检测中漏检可能导致严重安全风险的特点,优先关注召回率,使研究更贴合工业实际需求,而不是单纯追求综合性能指标。
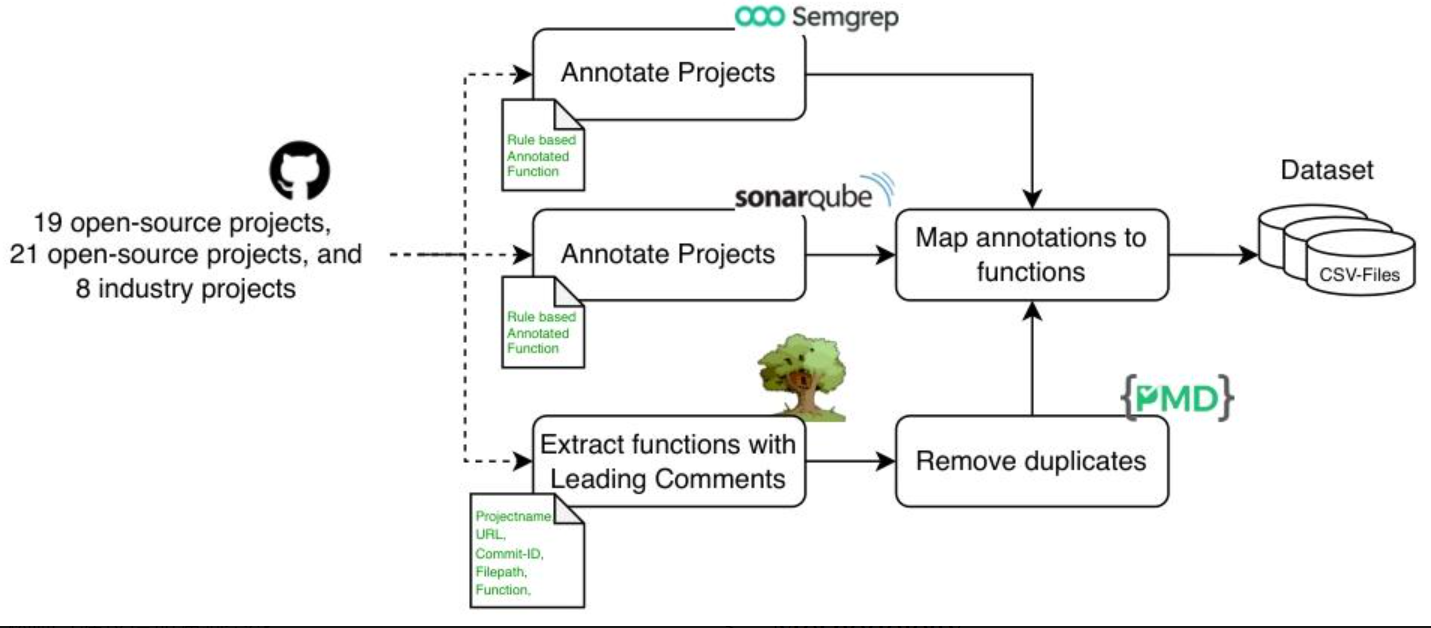
研究方法和思路、实验方法
(一)数据集构建与标注(分4步)
- 确定数据集类型与来源:明确构建三类数据集,分别是工业数据集(ID,来自合作企业8个ERP项目)、通用开源数据集(GOD,选取21个热门PHP开源项目)、技术相似开源数据集(TOD,来自GitHub上19个PHP开发的顶级ERP工具),确保数据覆盖不同场景。
- 函数提取与去重:使用TreeSitter工具提取PHP函数,再用PMD-CPD工具,通过滑动窗口(窗口大小30)和99%杰卡德指数阈值检测重复代码,去除重复函数,保证数据唯一性,避免重复数据对模型训练的干扰。
- 统一标注方式:结合SemGrep(0.73.0版本)和SonarQube(9.4版本)两款主流静态分析工具进行函数级标注,并且排除SemGrep的“Info/Minor”标签和SonarQube的“Warning”标签作为漏洞指标,一个函数即使有多个漏洞也仅计为一次标注,确保标注标准一致。
- 质量保障:遵循Croft等人提出的数据集质量框架,从准确性(依赖主流SAST工具标注)、唯一性(去重处理)、一致性(统一工具版本与配置)、完整性(包含函数定位信息)和时效性(所有数据集同时构建,时间对齐)五个方面保障数据集质量。
(二)CodeBERT微调(分3步)
- 确定模型基础与参数:选择由微软研究院开发的CodeBERT模型,该模型预训练涵盖Python、Java、PHP等6种编程语言,在代码相关任务上性能较优;设置块大小为512,批次大小16,学习率2e-5,训练10个epoch,若5个epoch内F1分数提升不超过0.001则手动早停,同时将数据集按80%/10%/10%随机划分为训练集、验证集和测试集,仅训练集采用平衡策略。
- 设计4种数据平衡策略:
- 无平衡(NB):直接保留数据集自然分布,不做任何处理。
- 全局欠采样(USC):以所有数据集中最小类别(ID的漏洞实例,共4,934个)为基准,对其他类别进行欠采样,平衡类别数量。
- 数据集内欠采样(URSC):在每个数据集内部,以较小类别(漏洞类)的规模来确定非漏洞类样本量,实现单个数据集内的类别平衡。
- 加权损失函数(WLF):保持数据集自然分布不变,通过调整损失函数的权重,让模型在训练时更多关注重要的样本(漏洞样本),区分两类样本的重要性。
- 模型训练与评估准备:按照上述参数和平衡策略对CodeBERT进行微调训练,为后续跨领域性能评估做好准备。
(三)跨领域评估与工具开发(分2步)
- 确定评估指标与评估逻辑:采用精确率(P)、召回率(R)和F1分数作为评估指标,因漏洞检测中漏检可能导致严重安全风险,评估时优先考虑召回率;分别评估模型在同域(同一数据集微调并测试)和跨域(一个数据集微调,另一个数据集测试)的性能,分析平衡策略和数据集类型对模型性能的影响。
- 开发AI-DO工具并收集反馈:将微调后的CodeBERT模型集成于GitHub Action,开发AI-DO工具,该工具能利用git和TreeSitter自动提取拉取请求(PR)中新增/修改的函数,检测漏洞并自动标记,在PR页面反馈结果;同时设计调查,收集13名企业IT专业人员对工具的使用反馈,评估工具感知实用性。
主要成果和贡献
(一)核心成果(表格形式)
| 类别 | 具体内容 |
|---|---|
| RQ1答案 | CodeBERT能用于工业源代码漏洞检测。基于企业数据微调的CodeBERT在工业未见过数据上表现良好,F1分数较开源未见过数据(同模型微调测试)最多下降10%,加权损失函数可缩小差距;欠采样技术能有效减少漏检,但在工业DevOps环境推广需应对安全专家等高度专业人员的抵触情绪 |
| RQ2答案 | 基于开源漏洞数据微调的CodeBERT,对工业技术特定数据的泛化能力受开源数据类型和平衡策略影响。技术无关开源数据(GOD)结合URSC欠采样微调,能更好控制工业未见过数据的漏检(因开源数据漏洞类型和编码风格更多样),但会增加假阳性,可能降低开发团队对工具的信任 |
| 平衡策略效果 | 1. 最大化召回率(减少漏检):欠采样技术(USC/URSC)更优;优化F1分数(综合性能):无平衡(NB)或加权损失函数(WLF)更合适 2. 同域场景:NB或WLF带来更高F1分数和精确率,欠采样提升召回率 3. 跨域场景:欠采样提升F1分数和召回率,NB或WLF更利于精确率提升 |
| 数据集影响 | 1. 同域优势:模型在微调数据集上测试性能最佳 2. TOD微调模型:在ID上测试的召回率优于GOD 3. GOD微调模型:在ID上测试的召回率与GOD测试结果相近甚至更优 4. ID微调模型:在开源数据上测试召回率显著下降 5. GOD+URSC:对工业数据漏洞漏检控制效果优于ID任何平衡策略微调结果,但假阳性增加 |
| AI-DO工具反馈 | 1. 积极态度群体:频繁遭遇漏洞的DevOps专家(认为加速开发)、资深软件工程师、软件架构师(建议增加漏洞详情)、初级开发者(满意度中等) 2. 谨慎/负面态度群体:安全专家(担忧岗位价值)、极少遭遇漏洞的DevOps专家(建议扩展检测规则)、团队负责人(认为精度不足,漏洞常跨多行/类) 3. 规律:接受度与自身漏洞检测经验及工具满足需求度高度相关 |
(二)核心贡献
- 数据贡献:完成了工业与开源数据集的跨领域性能评估,并且公开了构建的三类PHP函数漏洞标注数据集,填补了该领域同时覆盖开源与工业数据的空白,为后续相关研究提供了可靠的数据支持。
- 工具贡献:开发了可集成于CI/CD流程的漏洞检测推荐系统AI-DO,该工具能在代码审查阶段自动检测并定位漏洞函数,不干扰现有开发流程,还支持模型离线微调与更新,为工业界提供了实用的漏洞检测工具,提升了漏洞检测效率。
- 实践参考贡献:通过企业IT专业人员调查,明确了漏洞检测工具在工业场景的接受度影响因素(如使用者自身漏洞检测经验、工具对需求的满足度等),为学术技术向工业落地提供了宝贵的实践参考,帮助后续研究更好地贴合工业实际需求。
(三)开源资源
- 数据集:论文中构建的工业数据集(ID)、通用开源数据集(GOD)、技术相似开源数据集(TOD)已公开(具体地址需参考论文补充信息)。
- 代码:AI-DO工具及CodeBERT微调相关代码(具体地址需参考论文补充信息)。
关键问题(问答形式)
- 问题:CodeBERT模型是否能够有效应用于工业源代码的漏洞检测工作?
答案:可以。基于企业数据微调后的CodeBERT模型,在工业未见过的数据上表现良好,其F1分数相较于在开源未见过数据(同模型微调测试)的结果最多下降10%,且采用加权损失函数还能进一步缩小这一差距;若重点关注减少漏检情况,欠采样技术会更有效。不过,在工业DevOps环境推广时,需要应对安全专家等高度专业人员的抵触情绪,因为他们可能认为该工具会降低自身岗位价值。 - 问题:基于开源漏洞数据微调的CodeBERT模型,对工业技术特定数据的跨领域泛化能力怎么样?
答案:其泛化能力受开源数据类型和数据平衡策略的影响。其中,技术无关开源数据(GOD)结合数据集内欠采样(URSC)策略进行微调后,能更好地控制工业未见过数据的漏检情况,这是因为开源数据中包含的漏洞类型和编码风格更加多样,有助于提升模型识别真实漏洞的能力;但这种方式会伴随假阳性的增加,可能导致开发团队进行不必要的调查工作,进而降低对工具的信任度。 - 问题:在漏洞检测中,不同的数据平衡策略分别能起到什么效果,该如何选择?
答案:不同平衡策略效果不同,选择需结合需求。若要最大化召回率(减少漏检),欠采样技术(USC/URSC)更优;若要优化F1分数(综合性能),无平衡(NB)或加权损失函数(WLF)更合适。在同一数据集上微调与测试(同域)时,NB或WLF能带来更高F1分数和精确率,欠采样可提升召回率;在跨数据集场景中,欠采样能提升F1分数和召回率,NB或WLF更利于精确率提升。 - 问题:开发的AI-DO工具在工业场景中的接受度如何,不同角色的IT专业人员对其态度有何差异?
答案:工具接受度与使用者自身漏洞检测经验及工具对其需求的满足度高度相关。积极态度群体包括频繁遭遇漏洞的DevOps专家(认为工具加速开发、提前发现问题)、资深软件工程师、软件架构师(建议增加漏洞类型详情与推理说明)、初级开发者(满意度中等);谨慎/负面态度群体包括安全专家(担忧工具威胁自身岗位价值,态度中等)、极少遭遇漏洞的DevOps专家(认为需扩展检测规则)、团队负责人(认为工具精度不足,因漏洞常跨多行/类)。 - 问题:该研究在有效性方面存在哪些威胁,未来有哪些改进方向?
答案:有效性威胁包括构念有效性(已通过统一流程确保贴合目标)、内部有效性(PMD-CPD无法识别所有共享代码)、外部有效性(结果受限于PHP语言和实验数据集,调查可能有偏向性)、结论有效性(采用标准指标确保可靠)。未来工作方向包括扩展到多编程语言、多Transformer模型和多标注类型,利用新数据集(Madewic)优化方案,提升AI-DO工具精度,解决漏洞跨多行/类检测问题,完善漏洞说明与推理逻辑。
总结
该论文针对学术领域漏洞检测深度学习方案在工业场景应用的痛点,开展了全面且深入的研究。首先,构建了三类覆盖开源与工业的PHP函数漏洞标注数据集,并严格保障数据质量;接着,通过四种不同的数据平衡策略对CodeBERT模型进行微调,系统评估了模型在同域和跨域场景下的漏洞检测性能,明确了不同策略和数据集类型对模型性能的影响;然后,开发了可集成于CI/CD流程的AI-DO漏洞检测工具,并结合企业IT专业人员反馈,分析了工具在工业场景的接受度及影响因素;最后,回答了研究提出的核心问题,指出了研究的有效性威胁并给出未来改进方向。
)
















)

