LightGBM、XGBoost和CatBoost自定义损失函数和评估指标
- 函数(缩放误差)
- 数学原理
- 损失函数定义
- 梯度计算
- 评估指标
- LightGBM实现
- 自定义损失函数
- 自定义评估指标
- 使用方式
- XGBoost实现
- 自定义损失函数
- 自定义评估指标
- 使用方式
- CatBoost实现
- 自定义损失函数
- 自定义评估指标
- 使用方式
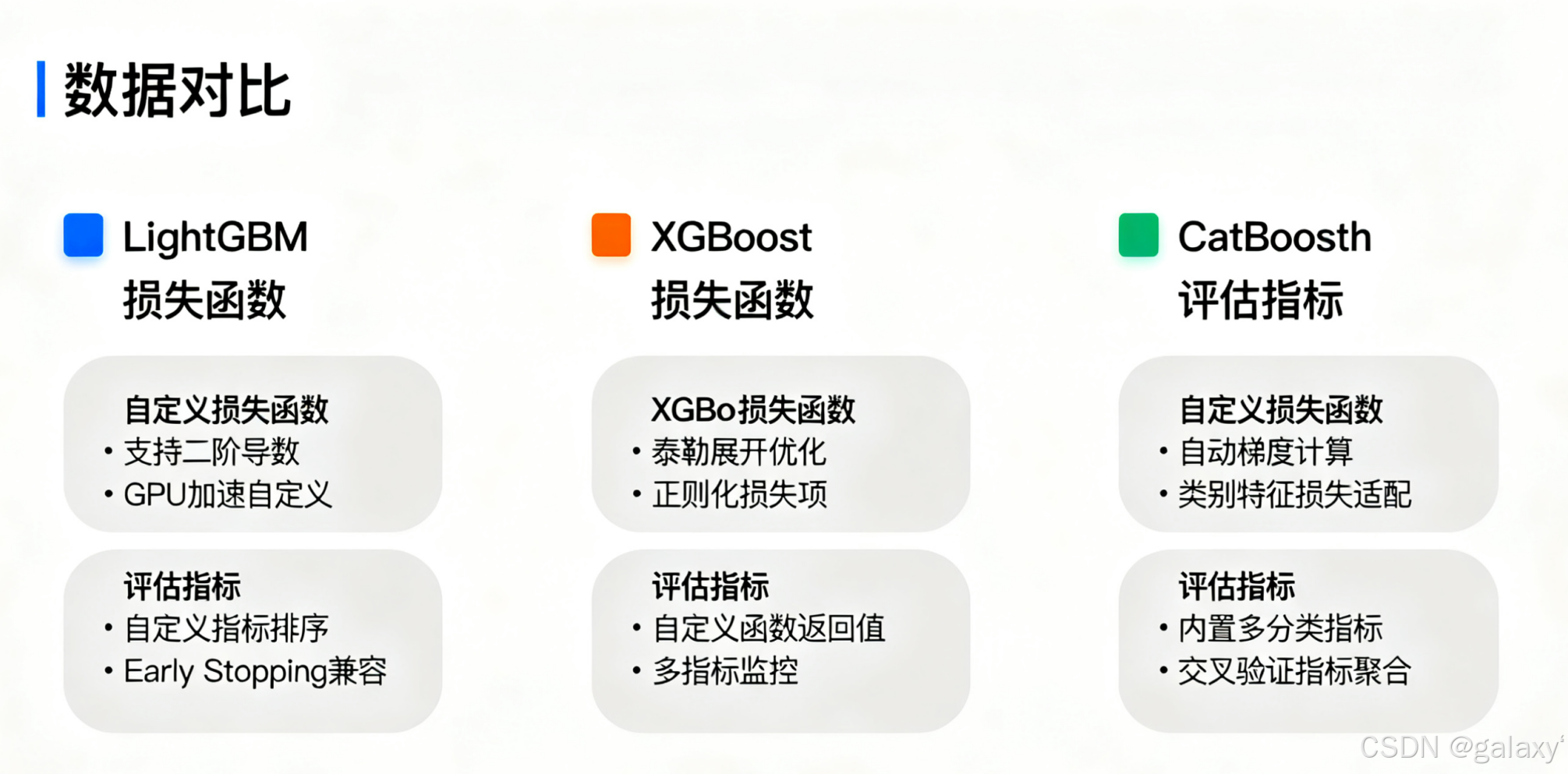
- 框架对比
- 实际应用
- 适用场景
- 常见问题
- 1. 为什么要设置最小阈值?
- 2. 梯度和Hessian计算错误怎么办?
- 3. 不同框架的性能差异
- 4. 超参数调优建议
函数(缩放误差)
传统的均方误差(MSE)和平均绝对误差(MAE)对所有预测值给予相同的权重,但在某些场景下,更关心相对误差而非绝对误差。缩放误差通过将误差除以真实值来实现这一目标:
缩放误差 = (真实值 - 预测值) / max(真实值, 阈值)
这样设计的优势:
- 对于大数值和小数值的预测给予相对平等的权重
- 避免大数值主导损失函数
- 更适合预测范围变化很大的场景
数学原理
损失函数定义
设损失函数为:
L(y, ŷ) = ((y - ŷ) / max(y, threshold))²
其中:
y是真实值ŷ是预测值threshold是防止除零的最小阈值
梯度计算
对于梯度提升算法,我们需要计算损失函数对预测值的一阶导数(梯度)和二阶导数(Hessian):
设 d = max(y, threshold),e = (y - ŷ) / d
- 一阶导数(梯度):
∂L/∂ŷ = -2e/d - 二阶导数(Hessian):
∂²L/∂ŷ² = 2/d²
评估指标
配套的评估指标使用缩放平均绝对误差(Scaled MAE):
Scaled MAE = mean(|y - ŷ| / max(y, threshold))
LightGBM实现
自定义损失函数
def custom_loss_squared_lgb(y_pred, train_data):"""LightGBM自定义缩放均方误差损失函数参数:y_pred: 预测值数组train_data: LightGBM的Dataset对象返回:tuple: (梯度数组, Hessian数组)"""y_true = train_data.get_label() # 获取真实标签# 计算分母,防止除零denominator = np.maximum(y_true, threshold)# 计算缩放误差error = (y_true - y_pred) / denominator# 计算梯度和Hessiangrad = -2 * error / denominatorhess = 2 / (denominator ** 2)return grad, hess
自定义评估指标
def mae_metric_lgb(preds, train_data):"""LightGBM自定义缩放MAE评估指标参数:preds: 预测值数组train_data: LightGBM的Dataset对象返回:tuple: (指标名称, 指标值, 是否越大越好)"""y_true = train_data.get_label()denominator = np.maximum(y_true, threshold)error = np.abs(preds - y_true) / denominatorreturn 'scaled_mae', np.mean(error), False
使用方式
import lightgbm as lgb
import numpy as np# 参数配置
params = {'objective': custom_loss_squared_lgb, # 使用自定义损失函数'boosting_type': 'gbdt','num_leaves': 31,'learning_rate': 0.01,'verbosity': -1
}# 训练模型
model = lgb.train(params, train_set, valid_sets=[train_set, valid_set],feval=mae_metric_lgb, # 使用自定义评估指标num_boost_round=1000,callbacks=[lgb.early_stopping(100)]
)
XGBoost实现
自定义损失函数
def custom_loss_squared_xgb(y_pred, train_data):"""XGBoost自定义缩放均方误差损失函数参数:y_pred: 预测值数组train_data: XGBoost的DMatrix对象返回:tuple: (梯度数组, Hessian数组)"""y_true = train_data.get_label() # 获取真实标签# 计算分母,防止除零denominator = np.maximum(y_true, threshold)# 计算缩放误差error = (y_true - y_pred) / denominator# 计算梯度和Hessiangrad = -2 * error / denominatorhess = 2 / (denominator ** 2)return grad, hess
自定义评估指标
def mae_metric_xgb(y_pred, train_data):"""XGBoost自定义缩放MAE评估指标参数:y_pred: 预测值数组train_data: XGBoost的DMatrix对象返回:tuple: (指标名称, 指标值)"""y_true = train_data.get_label()denominator = np.maximum(y_true, threshold)error = np.abs(y_true - y_pred) / denominatorreturn 'custom_mae', np.mean(error)
使用方式
import xgboost as xgb
import numpy as np# 参数配置
params = {'booster': 'gbtree','learning_rate': 0.01,'max_depth': 6,'random_state': 42
}# 训练模型
model = xgb.train(params,train_matrix,num_boost_round=1000,evals=[(train_matrix, 'train'), (valid_matrix, 'valid')],obj=custom_loss_squared_xgb, # 自定义损失函数feval=mae_metric_xgb, # 自定义评估指标early_stopping_rounds=100,verbose_eval=50
)
CatBoost实现
CatBoost的自定义函数需要用类的形式实现。
自定义损失函数
class CustomCatBoostObjective(object):"""CatBoost自定义缩放均方误差损失函数"""def calc_ders_range(self, approxes, targets, weights):"""计算梯度和Hessian参数:approxes: 当前预测值列表targets: 真实标签列表weights: 样本权重列表(可选)返回:list: [(梯度, Hessian), ...] 的列表"""assert len(approxes) == len(targets)if weights is not None:assert len(weights) == len(approxes)result = []for index in range(len(targets)):y_true = targets[index]y_pred = approxes[index]# 计算分母,防止除零denominator = max(y_true, threshold)# 计算缩放误差error = (y_true - y_pred) / denominator# 计算梯度和Hessiangrad = -2 * error / denominatorhess = 2 / (denominator ** 2)# 应用样本权重if weights is not None:grad *= weights[index]hess *= weights[index]result.append((grad, hess))return result
自定义评估指标
class CustomCatBoostEval(object):"""CatBoost自定义缩放MAE评估指标"""def is_max_optimal(self):"""指标是否越大越好"""return Falsedef evaluate(self, approxes, targets, weights):"""计算评估指标参数:approxes: 预测值列表的列表 [[pred1, pred2, ...]]targets: 真实标签列表weights: 样本权重列表(可选)返回:tuple: (误差总和, 权重总和)"""assert len(approxes) == 1assert len(targets) == len(approxes[0])error_sum = 0.0weight_sum = 0.0for i in range(len(targets)):y_true = targets[i]y_pred = approxes[0][i]# 计算缩放误差denominator = max(y_true, threshold)error = abs(y_true - y_pred) / denominator# 应用样本权重if weights is not None:error *= weights[i]weight_sum += weights[i]else:weight_sum += 1.0error_sum += errorreturn error_sum, weight_sumdef get_final_error(self, error, weight):"""计算最终的评估指标值"""return error / (weight + 1e-38)
使用方式
from catboost import CatBoostRegressor, Pool
import numpy as np# 创建数据池
train_pool = Pool(X_train, y_train)
valid_pool = Pool(X_valid, y_valid)# 参数配置
params = {'objective': CustomCatBoostObjective(),'eval_metric': CustomCatBoostEval(),'iterations': 1000,'learning_rate': 0.01,'depth': 6,'random_state': 42,'verbose': False
}# 训练模型
model = CatBoostRegressor(**params)
model.fit(train_pool,eval_set=valid_pool,early_stopping_rounds=100,verbose_eval=50,use_best_model=True
)
框架对比
| 特性 | LightGBM | XGBoost | CatBoost |
|---|---|---|---|
| 损失函数形式 | 函数 | 函数 | 类方法 |
| 参数名称 | objective | obj | objective |
| 数据获取 | train_data.get_label() | dtrain.get_label() | 直接传入 targets |
| 评估指标形式 | 函数 | 函数 | 类方法 |
| 评估返回格式 | (name, value, is_higher_better) | (name, value) | error_sum, weight_sum |
| 权重支持 | 自动处理 | 自动处理 | 需手动处理 |
| 实现复杂度 | 简单 | 简单 | 中等 |
实际应用
适用场景
- 新能源功率预测:风电、光伏功率预测范围从0到满功率
- 金融风险评估:不同规模公司的风险评估
- 销售预测:不同产品类别的销售额预测
- 网络流量预测:不同时段流量变化很大
常见问题
1. 为什么要设置最小阈值?
问题:直接用真实值作为分母会遇到什么问题?
答案:
- 当真实值为0或接近0时,会导致除零错误或梯度爆炸
- 设置最小阈值可以保证数值稳定性
- 阈值的选择应根据数据的实际分布来确定
2. 梯度和Hessian计算错误怎么办?
问题:如何验证梯度计算的正确性?
答案:可以用数值微分验证:
def verify_gradients(y_true, y_pred, eps=1e-6):"""验证梯度计算的正确性"""# 解析梯度denominator = np.maximum(y_true, threshold)error = (y_true - y_pred) / denominatorgrad_analytical = -2 * error / denominator# 数值梯度loss_plus = ((y_true - (y_pred + eps)) / denominator) ** 2loss_minus = ((y_true - (y_pred - eps)) / denominator) ** 2grad_numerical = (loss_plus - loss_minus) / (2 * eps)# 比较diff = np.abs(grad_analytical - grad_numerical)print(f"最大梯度差异: {np.max(diff)}")return np.allclose(grad_analytical, grad_numerical, atol=1e-5)
3. 不同框架的性能差异
问题:三个框架在使用自定义损失函数时的性能如何?
答案:
- LightGBM:通常最快,内存效率高
- XGBoost:稳定性好,文档完善
- CatBoost:对类别特征处理好,但自定义函数实现相对复杂
4. 超参数调优建议
# LightGBM调优示例
from optuna import create_studydef objective(trial):params = {'objective': custom_loss_squared_lgb,'boosting_type': 'gbdt','num_leaves': trial.suggest_int('num_leaves', 10, 100),'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.1),'feature_fraction': trial.suggest_float('feature_fraction', 0.4, 1.0),'bagging_fraction': trial.suggest_float('bagging_fraction', 0.4, 1.0),'verbosity': -1}model = lgb.train(params,train_data,valid_sets=[valid_data],feval=mae_metric_lgb,num_boost_round=1000,callbacks=[lgb.early_stopping(100)],verbose_eval=False)y_pred = model.predict(X_valid)scaled_mae = np.mean(np.abs(y_valid - y_pred) / np.maximum(y_valid, threshold))return scaled_maestudy = create_study(direction='minimize')
study.optimize(objective, n_trials=100)










:函数返回值:多返回值、None与函数嵌套调用)








)