文章目录
- 1. CS336介绍
- 2. 概览
- 2.1 为什么会有这门课程
- 2.1.1 LLM的参数和训练成本
- 2.2.2 小语言模型和LLM的区别
- 2.2 你可以学到什么?
- 2.2.1 Intuitions
- 2.2.2 The bitter lesson
- 3. 全景图(current landscape)/发展历史
- 4. 可执行的课件说明
- 5. 课程设计
- 6. 课程内容
- 6. 1 basic部分
- 6.1.1 分词器tokenization
- 6.1.2 架构Architecture
- 6.1.3 training
- 6.1.4 作业一
- 6.2 systems部分
- 6.2.1 kernel(GPU内核)
- 6.2.2 Parallelism(并行)
- 6.2.3 Inference
- 6.2.4 作业二
- 6.3 scaling_laws部分
- 6.3.1 说明
- 6.3.2 作业三
- 6.4 data部分
- 6.4.1 说明
- 6.4.2 作业四
- 6.5 alignment部分
- 6.5.1 说明
- 6.5.2 作业五
- 6.6 回顾总结
1. CS336介绍
B站视频:
- ❌【斯坦福大学 • CS336】从零开始构建语言模型 | 2025 年春季
- 这个清晰度不行,字幕有点问题
- ✅斯坦福CS336:大模型从0到1|第一讲:概述和tokenization【中英双语】
- 这个好点~
- 斯坦福大学《从零开始的语言模型|CS336 Language Modeling from Scratch Spring 2025》中
- 这个可能更好,但是要开月卡似乎
课程主页: CS336: Language Modeling from Scratch_Stanford / Spring 2025
Github主页:https://github.com/stanford-cs336/spring2025-lectures
额外说明:
- 课上老师讲解用的是py脚本,使用的是一个叫
trace-viewer的基于React等前端构建的一个浏览工具 trace-viewer就在课程的github里
2. 概览
以下内容来自: spring2025-lectures/lecture_01.py
trace-viewer浏览页面(最好用谷歌浏览器,不然页面布局显示会很混乱): Trace-lecture-01
(PS: 如果直接点击课程主页里的Course Materials的py文件,看的时候会位置错乱,就还不如直接看原始的脚本文件~)
2.1 为什么会有这门课程
2.1.1 LLM的参数和训练成本
GPT-4据传有1.8T(万亿)参数, article_link
GPT-4 据传花了 $100M(百万)/$1亿训练,article_link
xAI使用了一个20w个H100构成的集群来训练Grok. article_link
Stargate (OpenAI, NVIDIA, Oracle)四年内投资超过$500B(十亿)/$5千亿,article_link
2.2.2 小语言模型和LLM的区别
本课程不是为了训练一个GPT-4,而是为了训练一个小语言模型(small language models (<1B parameters in this class))
GPT-4 Technical Report中写道:
- 考虑到像GPT-4这样的大型模型的竞争格局和安全影响,本报告没有包含关于架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法或类似内容的进一步细节。
Exmaple 1: fraction of FLOPs spent in attention versus MLP changes with scale,图自链接
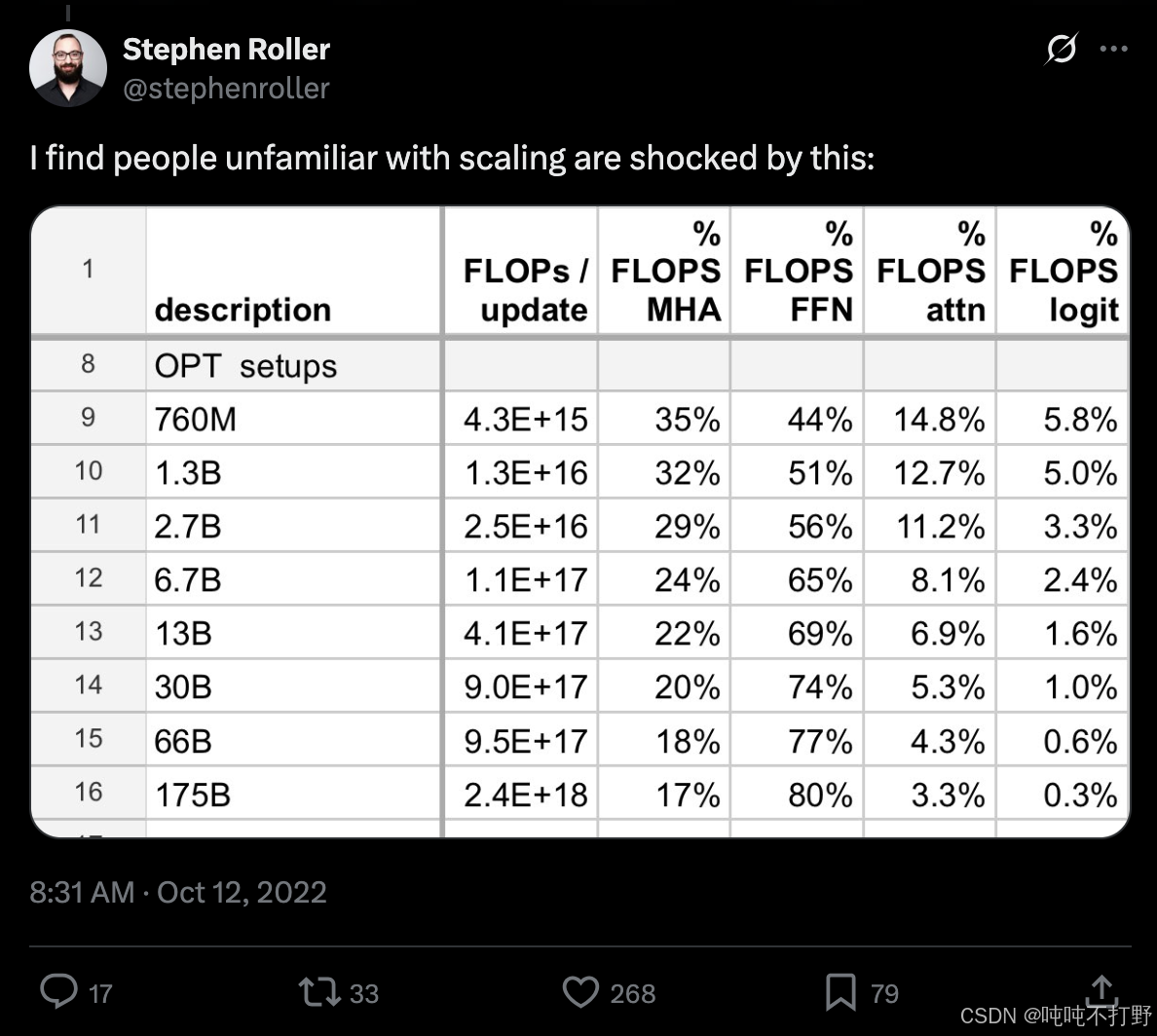
仔细观察语言模型随着规模的增大,MLP层和MHA(multi head attention)层消耗的flops计算的比例,可以发现:
- FFN使用的就是MLP,MHA表示多头注意力机制层
- 随着scale的增大,MLP层消耗的计算占比越来越大,占据了主导位置,而MHA占比则越来越小(准确的说,是除了MLP之外的层,占比都是越来越少的)。
- 因此,如果你只看小语言模型,把大量的时间花在MHA多头注意力机制的优化上,那么你的优化方向就是错误的。。。因为在大语言模型上,MHA的作用很有限
Example 2: emergence of behavior with scale,图自论文-Emergent Abilities of Large Language Models-链接
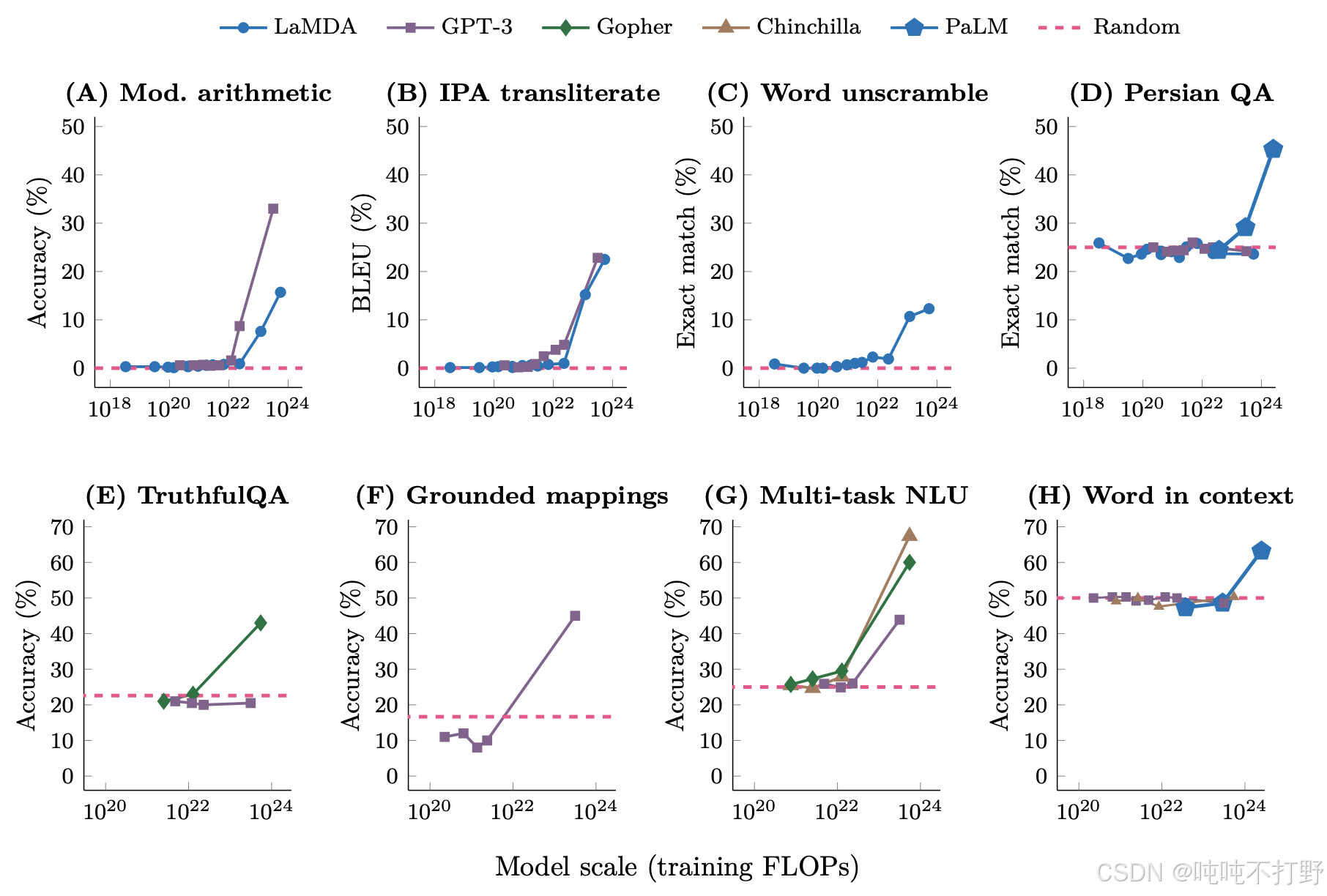
如上图所示:
- 横轴表示训练时的flops(越大表示模型越大)
- 在一定范围内时,例如:101810^{18}1018~102210^{22}1022之间,模型在各个任务上的准确率增长都不明显,几乎是平的
- 但是在模型规模(scale)到达一定规模后,随着scale的增长,各个任务上的准确率都呈现线性增长的趋势,这就是所谓的大模型的涌现能力,上下文,思维链等~
2.2 你可以学到什么?
🥳课程主要学习的内容:
- Mechanics/运行机制:
- how things work (what a Transformer is, how model parallelism leverages GPUs)
- Transformer模型是什么?如果通过GPUs高效的进行模型并行操作
- Mindset/思维方式:
- squeezing the most out of the hardware, taking scale seriously (scaling laws)
- 尽可能充分利用硬件性能,认真对待
scaling laws这个东西
- Intuitions:
- which data and modeling decisions yield good accuracy
- 哪些数据和建模决策/训练方案,可以产生好的结果
2.2.1 Intuitions
目前LLM中的大多数研究/采取的决策,都没有确切的科学根据,都是进行实验,以实验为导向的
例如: GLU Variants Improve Transformer

翻译: 我们没有解释为什么这些架构似乎有效;我们把他们的成功,和其他一切一样,归功于神的仁慈。
所以我们理解的程度,就是实验结果好,就可以用了。。。
2.2.2 The bitter lesson
Wrong interpretation: scale is all that matters, algorithms don’t matter.
- 错误的解释: scale就是最重要的,是一切,算法不重要
Right interpretation: algorithms that scale is what matters.
- 正确的解释:算法的规模才是最重要的。
accuracy=efficiency×resourcesaccuracy = efficiency \times resourcesaccuracy=efficiency×resources
准确率其实是 效率 和你投入的资源 的乘积。很明显,如果是大规模模型,efficiency效率是更重要的(因为负担不起浪费。。。)
效率其实是硬件(hardware)和算法(Algorithm)的结合
- 关于算法的效率:
- 论文-Measuring the Algorithmic Efficiency of Neural Networks
- 这个论文中提到: 从2012年到2019年,7年的时间里,训练一个在ImageNet上达到AlexNet水平的算法的效率提升了44倍。 比摩尔定律还快,摩尔定律在此期间涨了11倍

- 因此,最关键的问题是:
- 在给定计算资源和数据的情况下,最好的模型是什么?
- 考虑的其实是 每个单位资源的准确率(accuracy per resources)
- 如果能拿到更多的计算资源,那模型肯定会更好
- 但是作为研究人员,我们的目标是:maximize efficiency!
3. 全景图(current landscape)/发展历史
大语言模型的简单发展历史(NLP+transformer)
- Pre-neural (before 2010s, 神经网络之前)
- 香农把语言模型作为衡量英语熵的一种方式,引用- Prediction and Entropy of Printed English-Shannon 1950
- 其实在2007年的时候,Google就训练过一个很大的
n-gram模型(Trained 5-gram model on 2T tokens), 在超过2万亿词源(比GPT3的tokens还要多)上建立了5-gram模型。引用-Language Models in Machine Translation-Brants 2007
- Neural ingredients (2010s,神经网络的组件)
- 第一个神经网络的语言模型是约书亚Bengio团队在2003年提出的, 引用-A Neural Probabilistic Language Model-Bengio 2003
- 以及2014年的用于机器翻译Seq2Seq(Sequence-to-sequence modeling)模型。引用-Sequence to Sequence Learning with Neural Networks-susketver2014
- Adam optimizer, 出现于距今为止10年的2014年,至今还有很多人在使用。引用-Adam: A Method for Stochastic Optimization-Kingma+ 2014
- Attention mechanism (注意力机制,最初是用在机器翻译领域的machine translation,促成了后来的transformer里的注意力机制架构) , 引用-Neural Machine Translation by Jointly Learning to Align and Translate-Bahdanau+ 2014
- Transformer architecture (for machine translation) ,引用-Attention Is All You Need-Vaswani+ 2017
- 研究如何扩展混合专家(scale Mixture of experts)模型。引用-Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer- Shazeer+2017
- 21世纪10年代末期(即2010年~2020年之间,尤其是2015年之后),大量研究工作开始关注模型并行(
Model parallelism),致力于研究如何训练千亿(hundreds of million)参数的模型,虽然没有训练很久,因为训练更像是一种系统层面的工作(system work)。引用:- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer- [Huang+ 2018],
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
-Rajbhandari+ 2019, - Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism-Shoeybi+ 2019
- 所以其实在2020年左右,所有大模型需要的训练要素(ingredients)都已经就位了
- Early foundation models (late 2010s,早期的基座模型)
- 21世纪10年代晚期,除了上面一些模型组件,还出现了另一种趋势,即:使用大量的文本训练得到一个基座模型,再通过进一步的微调训练来得到适应不同的下游任务的模型。
- ELMo: pretraining with LSTMs, fine-tuning helps tasks,引用-Deep contextualized word representations-[Peters+ 2018]
- BERT: pretraining with Transformer, fine-tuning helps tasks,引用-BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding-[Devlin+ 2018]
- Google’s T5 (11B): cast everything as text-to-text ,引用-Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer-[Raffel+ 2019]
- 当年BERT出现的时候,非常令人兴奋,只是相对于如今的LLM,可能人们已经忘记了当年的BERT等的超大模型~
- Embracing scaling, more closed(拥抱规模化,走向闭源)
- 促成大模型出现的最关键一步:OpenAI整合了上面的神经网络的组件,顺应了基座模型这个趋势,并且通过出色的工程能力真正应用了规模定律(
scaling laws) - OpenAI’s GPT-2 (1.5B): fluent text, first signs of zero-shot, staged release,Language Models are Unsupervised Multitask Learners-[Radford+ 2019]
- Scaling laws: provide hope / predictability for scaling , 规模定律——促进了GPT-2和GPT3的出现。Scaling Laws for Neural Language Models- [Kaplan+ 2020]
- OpenAI’s GPT-3 (175B): in-context learning, closed。Language Models are Few-Shot Learners-[Brown+ 2020]
- Google’s PaLM (540B): massive scale, undertrained。PaLM: Scaling Language Modeling with Pathways- [Chowdhery+ 2022]
- DeepMind’s Chinchilla (70B): compute-optimal scaling laws ,Training Compute-Optimal Large Language Models-[Hoffmann+ 2022]
- 促成大模型出现的最关键一步:OpenAI整合了上面的神经网络的组件,顺应了基座模型这个趋势,并且通过出色的工程能力真正应用了规模定律(
- Open models(开源模型)
- 闭源模型的进步,也在促使开源模型的出现
- EleutherAI’s open datasets (The Pile) and models (GPT-J),
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling-Gao+ 2020,
- 中文介绍见:The Pile: An 800GB Dataset of Diverse Text for Language Modeling——一个用于语言建模的800GB多样化文本数据集
- GPT-J-6B: 6B JAX-Based Transformer_Wang+ 2021, GPT3发布后的一个尝试。
- Meta’s OPT (175B): GPT-3 replication, lots of hardware issues,Meta的早期尝试,效果没有那么好。 OPT: Open Pre-trained Transformer Language Models- [Zhang+ 2022]
- Hugging Face / BigScience’s BLOOM: focused on data sourcing。BLOOM: A 176B-Parameter Open-Access Multilingual Language Model- [Workshop+ 2022]
- Meta’s Llama models
- LLaMA: Open and Efficient Foundation Language Models-[Touvron+ 2023]
- Llama 2: Open Foundation and Fine-Tuned Chat Models-[Touvron+ 2023]
- The Llama 3 Herd of Models- [Grattafiori+ 2024]
- Alibaba’s Qwen models,Qwen2.5 Technical Report-[Qwen+ 2024]
- DeepSeek’s models
- DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
-[DeepSeek-AI+ 2024] - DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model-[DeepSeek-AI+ 2024]
- DeepSeek-V3 Technical Report-[DeepSeek-AI+ 2024]
- DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- AI2’s OLMo 2, OLMo: Accelerating the Science of Language Models-[Groeneveld+ 2024],2 OLMo 2 Furious-[OLMo+ 2024]
- Levels of openness(开源的层次)
- 闭源模型(例如:GPT-4o),只允许通过API访问。GPT-4 Technical Report-[OpenAI+2023]
- 开放权重的模型
Open-weight models,例如: DeepSeek: 开放了权重,带有架构细节,一些训练细节,但没有数据细节的论文。DeepSeek-V3 Technical Report-[DeepSeek-AI+ 2024] - 开源模型
Open-source models,比如:OLMo: 权重,数据都是开源的,论文里有大多数的细节(但是没有基本原理necessarily the rationale以及失败的实验failed experiments)。 OLMo: Accelerating the Science of Language Models-[Groeneveld+ 2024]
- Today’s frontier models(前沿模型:主要是带有推理功能的模型)
- OpenAI’s o3, https://openai.com/index/openai-o3-mini/
- Anthropic’s Claude Sonnet 3.7,https://www.anthropic.com/news/claude-3-7-sonnet
- xAI’s Grok 3,https://x.ai/news/grok-3
- Google’s Gemini 2.5 ,https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025
- Meta’s Llama 3.3 ,https://ai.meta.com/blog/meta-llama-3/
- DeepSeek’s r1,DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning——[DeepSeek-AI+ 2025]
- Alibaba’s Qwen 2.5 Max,https://qwenlm.github.io/blog/qwen2.5-max
- Tencent’s Hunyuan-T1,https://tencent.github.io/llm.hunyuan.T1/README_EN.html
[!NOTE]
总结:本次课程会
- 重点查看上面所提到的一些关键技术组件(ingredients),研究其原理。
- 竭尽所能找到最接近前沿模型的最佳实践,所使用的信息基本都来自开源社区,同时去从闭源模型的一些只言片语的描述中去推理背后的某些内容~
4. 可执行的课件说明
原始的.py文件: https://github.com/stanford-cs336/spring2025-lectures/blob/main/lecture_01.py
在浏览器打开课件时: Trace-lecture-01 ,如果是首次加载(没有浏览器缓存),可以看到有以下提示:

进一步查看项目的github文件夹:
- https://github.com/stanford-cs336/spring2025-lectures/tree/main/trace-viewer
- 是一个用js类的语言写的一个前端类的项目,作为viewer来浏览/执行.py文件的
5. 课程设计
https://stanford-cs336.github.io/spring2025/
- 不建议上这门课:
- 如果你这学期有研究任务,和你的导师商量一下(因为作业量很大)
- 如果你对最新的技术感兴趣,比如:multimodality, RAG,那你应该去选择,因为这门课关注的是底层原理的实现,而不是最新/最热的技术。
- 如果你想对自己现有的模型/系统进行优化得到更好的效果(直接使用prompt提示词工程或者fine-tune微调现有的模型)
- 作业:
- 一共5个作业
- 不提供脚手架(scaffolding code),不给填空的代码模版,自己从空文件开始搞~
- 但是会提供单元测试(
unit tests)和适配器接口(adapter interfaces)来帮助检查是否正确运行 - 可以直接在本地的笔记本上跑test验证正确性,使用cluster跑benchmark(不要直接用大参数的模型来debug~)
- 有的作业会有leaderboard,通常是在给定资源的情况下,想办法降低困惑度(
perplexity)
- 关于AI tools (e.g., CoPilot, Cursor)
- 可能会让你的学习效果变差(你的学习效果需要自己负责~),想清楚用/不用/怎么用(老师的意思是:不建议使用)
其他:
- BPE算法
- 《从零构建大模型》系列(12):BPE算法——大语言模型的分词基石
- 详解BPE算法(Byte pair encoder )
- CS224N
- https://web.stanford.edu/class/cs224n/
6. 课程内容
课程的内容主要就是围绕效率(efficiency),即:
- 给定数据(data)和硬件(hardware)的情况下,如何在固定资源的情况下训练出最好的模型
- 比如:给你
Common Crawl数据集和可以用两周的32张H100卡,你会怎么做?
设计决策

- 比如分词器,架构;比如系统优化;比如数据处理等
- 课程整体被分为上述的五个部分,并且会轮流讲述其中的每一个部分~
作业一和作业二是最耗时的,作业三会好一些~
6. 1 basic部分
- 目标:让整个pipeline能跑起来的一个基础版本,没有任何优化或者高级处理~
- 组件:分词器tokenization, 模型架构model architecture,训练 training,
6.1.1 分词器tokenization
分词器:
课程里主要使用:
- Byte-Pair Encoding (BPE) —— Neural Machine Translation of Rare Words with Subword Units- [Sennrich+ 2015]
- 这种方法相对简单,同时目前仍然在使用
另外有一些不需要分词(Tokenizer-free approaches),直接对原始字节进行编码的很有前景的方法(虽然目前还没有被应用于前沿模型):
- ByT5: Towards a token-free future with pre-trained byte-to-byte models-[Xue+ 2021]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers-[Yu+ 2023]
- Byte Latent Transformer: Patches Scale Better Than Tokens-[Pagnoni+ 2024]
- T-FREE: Subword Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings-[Deiseroth+ 2024]
6.1.2 架构Architecture
完成分词后,即把一个序列/一段字符串/文字变成一个整数序列后;
接下来,我们就会在这个整数序列上定义一个模型架构(即:模型的输入是一串分词得到的整数序列)。
这里的架构主要的部分就是transformer, Attention Is All You Need-[Vaswani+ 2017]
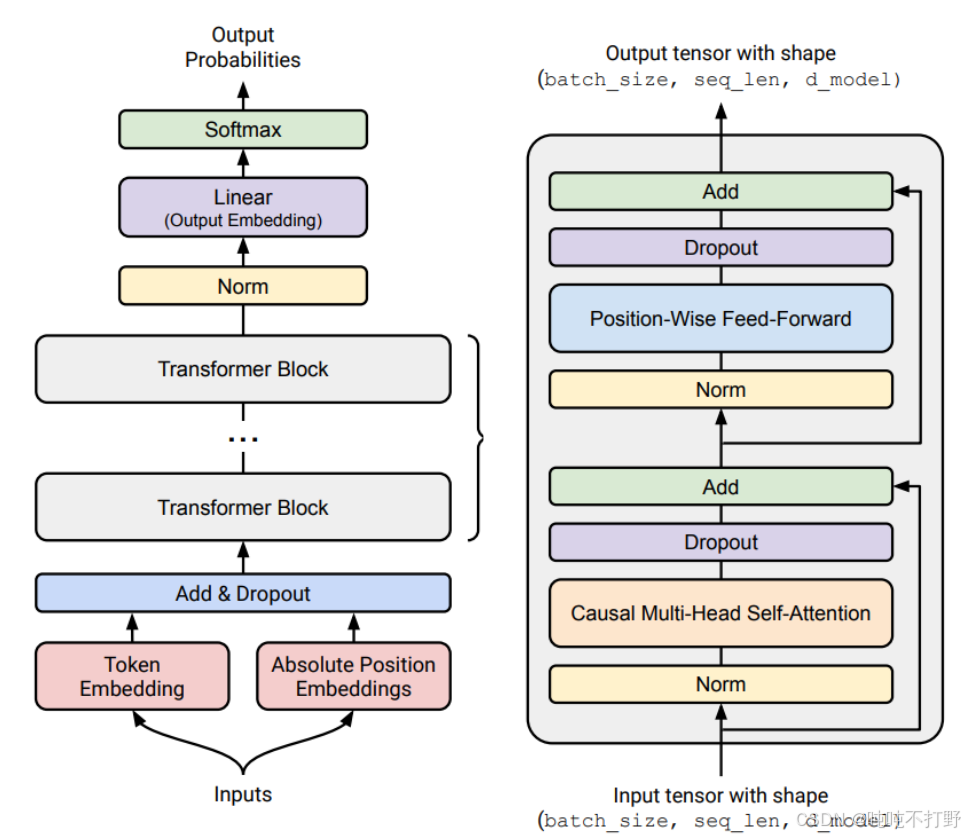
似乎有一种错觉,从2017年transformer出现以后,大家好像都只用transformer了,事实上这不是错觉,是真的。但是从2017年到现在,transformer的主体架构没有发生大的改变,但是也产生了很多变体(Variants),这些改变加在一起,就有很大的不同了
- Activation functions: ReLU, SwiGLU(新的激活函数)
- GLU Variants Improve Transformer- [Shazeer 2020]
- Positional encodings: sinusoidal, RoPE(新的位置编码)
- RoFormer: Enhanced Transformer with Rotary Position Embedding-[Su+ 2021]
- Normalization: LayerNorm, RMSNorm(不再使用层归一化,而是使用RMSNorm)
- Layer Normalization-[Ba+ 2016]
- Root Mean Square Layer Normalization-[Zhang+ 2019]
- Placement of normalization: pre-norm versus post-norm(norm层放置的位置和原始transformer不同)
- On Layer Normalization in the Transformer Architecture-[Xiong+ 2020]
- MLP: dense, mixture of experts(MLP是稠密的/dense,将MLP换为MOE稀疏)
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer -[Shazeer+ 2017]
- Attention: full, sliding window, linear(多种注意力机制:full-attention等,主要是为了防止quadratic blowup(二次爆炸))
- Mistral 7B- [Jiang+ 2023]
- Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention-[Katharopoulos+ 2020]
- 常用的FullAttention性能对比
- Mistral SWA(Sliding window attention)的一些理解
- Lower-dimensional attention: group-query attention (GQA), multi-head latent attention (MLA)(低维度的注意力机制:GQA,MLA)
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints-[Ainslie+ 2023]
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model-[DeepSeek-AI+ 2024]
- State-space models: Hyena(更激进的替代transformer的模型,不使用注意力机制,基于空间状态的模型)
- Hyena Hierarchy: Towards Larger Convolutional Language Models-[Poli+ 2023]
6.1.3 training
- Optimizer (e.g., AdamW, Muon, SOAP)
- Adam: A Method for Stochastic Optimization-Kingma+ 2014
- Adam的一个变体
- Decoupled Weight Decay Regularization-[Loshchilov+ 2017]
- Muon: An optimizer for hidden layers in neural networks-[Keller 2024]
- SOAP: Improving and Stabilizing Shampoo using Adam-[Vyas+ 2024]
- Adam: A Method for Stochastic Optimization-Kingma+ 2014
- Learning rate schedule (e.g., cosine, WSD)
- SGDR: Stochastic Gradient Descent with Warm Restarts-[Loshchilov+ 2016]
- MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies-[Hu+ 2024]
- Batch size (e…g, critical batch size)
- An Empirical Model of Large-Batch Training-[McCandlish+ 2018]
- Regularization (e.g., dropout, weight decay)
- Hyperparameters (number of heads, hidden dimension): grid search
训练当中有很多细节,一个精心调整过的网络和一个普通的transformer差距还是很大的~
6.1.4 作业一
- Github链接: https://github.com/stanford-cs336/assignment1-basics
- 完整的作业描述pdf文件:https://github.com/stanford-cs336/assignment1-basics/blob/main/cs336_spring2025_assignment1_basics.pdf
作业一大致描述:
- 实现一个BPE分词器(tokenizer)
- 实现Transformer, cross-entropy loss, AdamW optimizer, training loop
- 注意,可以使用pytorch,但是不可以直接用现成的函数~
- 提供了huggingface上的TinyStories数据集和OpenWebText的一个子集
- 有一个leaderboard:
- 你拥有的资源:H100显卡,90分钟时间
- 目标:最小化OpenWebText上的困惑度(perplexity)
- 去年的排行榜:stanford-cs336/spring2024-assignment1-basics-leaderboard
- 可以看到,基本都是用的
wandb这个可视化训练过程的框架
6.2 systems部分
- 目标:优化basic的内容——主要是如何充分利用硬件
- 组件:内核(kernels), 并行(parallelism), 推理(inference)
6.2.1 kernel(GPU内核)

如上图所示,右侧的GPU其实是由128个左侧这样的东西组成的
- 这是GPU
- 内存的部分其实是在右图的两侧(不是绿色格子)的灰色格子
- 计算一定是发生在显存中的,但是数据可以存储在任何地方,如何有效的组织计算来达到最高的计算效率??
更详细的图在NVIDIA的博客文章中: NVIDIA Ampere Architecture In-Depth
- 左图图像链接:https://developer-blogs.nvidia.com/wp-content/uploads/2021/guc/raD52-V3yZtQ3WzOE0Cvzvt8icgGHKXPpN2PS_5MMyZLJrVxgMtLN4r2S2kp5jYI9zrA2e0Y8vAfpZia669pbIog2U9ZKdJmQ8oSBjof6gc4IrhmorT2Rr-YopMlOf1aoU3tbn5Q.png
- 右图图像链接:https://developer.download.nvidia.com/devblogs/ga100-full-gpu-128-sms.png
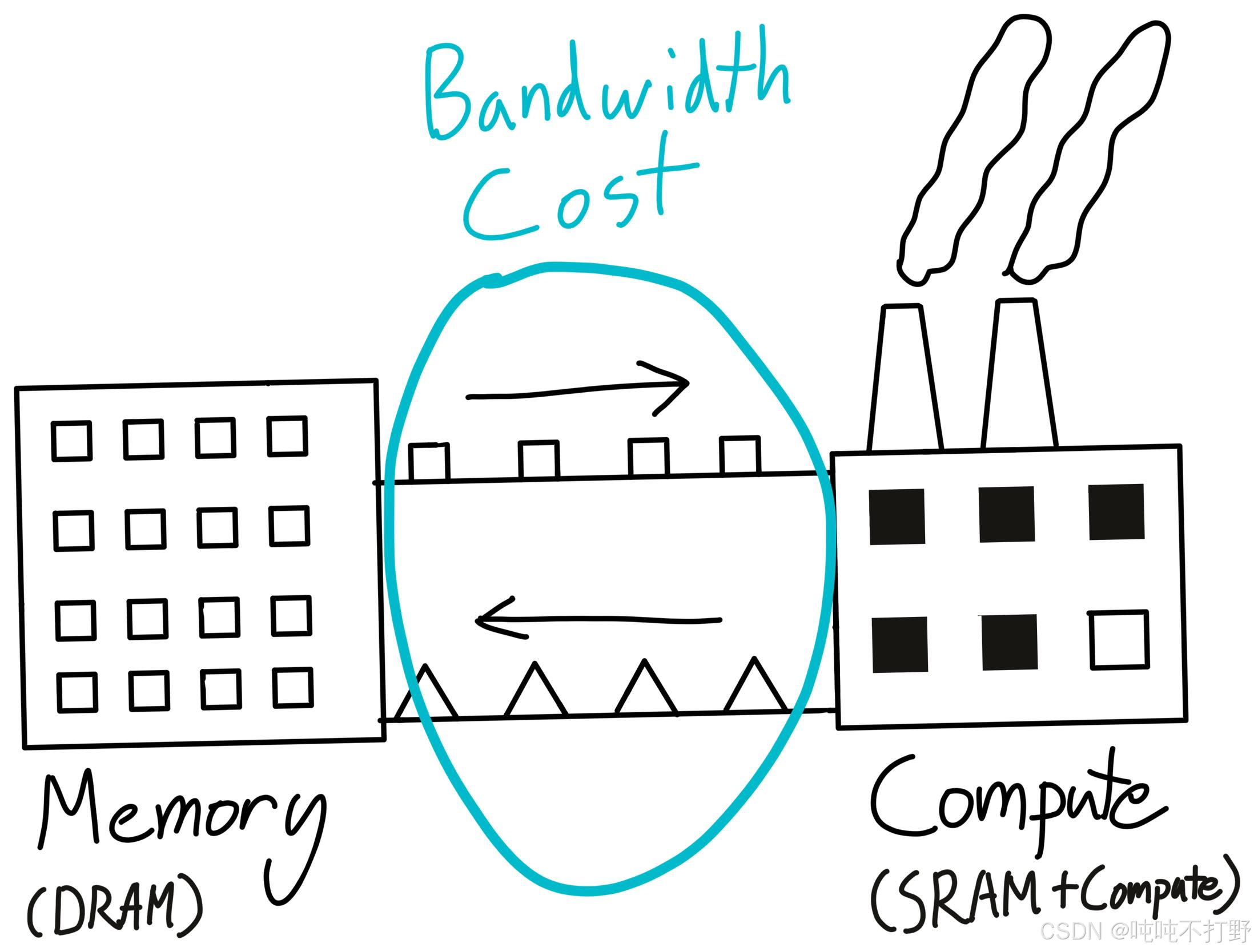
计算和数据的关系,可以类比为:
- warehouse : DRAM :: factory : SRAM
- DRAM就是仓库,是存储数据的地方
- SRAM就是工厂,是计算/处理数据的地方
窍门/tricks:通过最小化数据移动来组织计算,以最大限度地利用gpu
使用CUDA/Triton/CUTLASS/ thundercats来写内核
- 注意,这里使用的Triton是OpenAI开发的。
- Triton是一种并行编程语言和编译器。它旨在提供一个基于python的编程环境,用于高效地编写能够在现代GPU硬件上以最大吞吐量运行的自定义DNN计算内核。
- triton-lang/triton
- https://triton-lang.org/main/index.html
- Introducing Triton: Open-source GPU programming for neural networks: 2021年7月8号就有了
- 而不是之前NVIDIA开发的triton-inference-server/server
- Triton推理服务器是一个开源的推理服务软件,简化了人工智能推理。Triton使团队能够部署来自多个深度学习和机器学习框架的任何AI模型,包括TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL等。
6.2.2 Parallelism(并行)
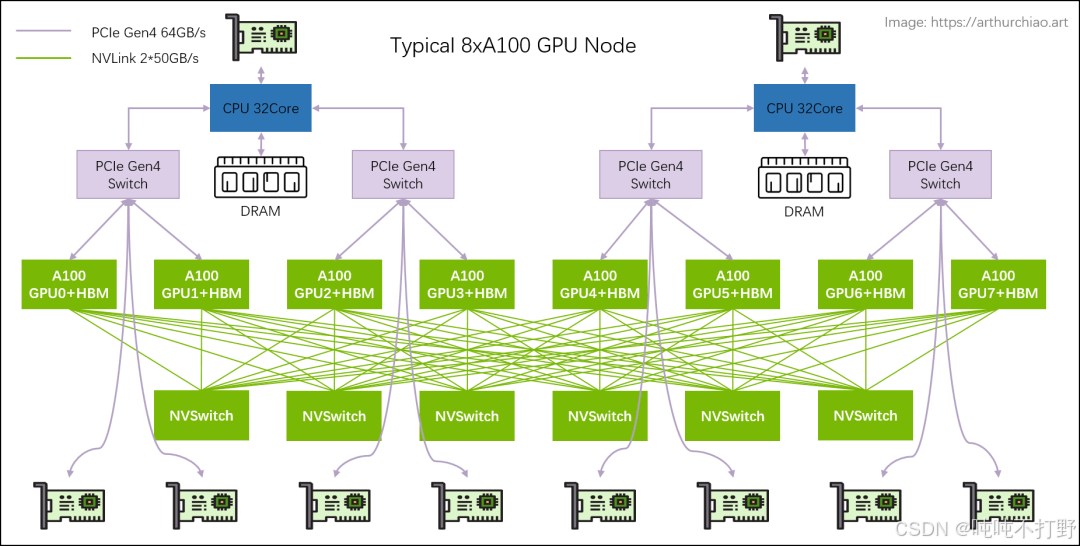
GPU之间的数据移动速度更慢,除非使用NVIDIA特定的一种架构(NVLink(或者被称为:NVSwitch) 高速 GPU 互连)
- NVIDIA NVLink 和 NVLink 交换机
- 软件/编程角度可以:
- 使用集合操作,例如:gather, reduce, all-reduce等
- 进行跨GPUs间的数据共享,例如:parameters, activations, gradients, optimizer states
- 如何划分计算,常见的并行方案有:
- data parallelism 数据并行
- tensor parallelism 张量并行
- {pipeline,sequence} 并行
图自: https://arthurchiao.art博客的文章
- Practical Storage Hierarchy and Performance: From HDDs to On-chip Caches(2024)
- 或者中文文章:GPU 进阶笔记(一):高性能 GPU 服务器硬件拓扑与集群组网(2023)
6.2.3 Inference
- 目标: 在实际使用模型时,主要就是对给定的prompt生成tokens
推理也用于强化学习(RL,reinforcement learning), 测试时计算(TTC,test-time compute),评估(evaluation)
- TTC: 从System-1到System-2:AI推理中的Test-Time Compute革命
整体上来看, 使用时的推理计算(inference compute (every use,每次使用)), 远远超过了训练时的计算( training compute (one-time cost, 一次性开销))
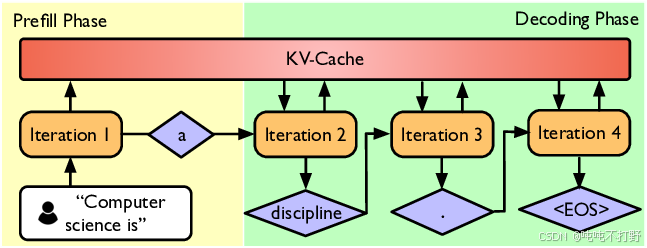
- Prefill阶段:
- 给定所有的输入的prompt的tokens, 然后通过模型的运行,得到一些激活值。
- 由于一次能看到所有输入,能够一次性处理完所有,就类似于训练/training。
- 这种情况很容易通过并行加速,因此
Prefill阶段的瓶颈在于计算——compute-bound(受限于计算)
- Decode阶段:
- 通过自回归的方式每次逐个生成token,无法并行,很难充分利用GPU
- 同时由于一直在移动数据,导致主要受限于内存(memory-bound)
- 针对
Decode阶段的一些加速方案:- 使用更便宜(/更小)的模型(比如通过:裁剪-pruning,量化-quantization,蒸馏-distillation)
- 推测/投机解码(Speculative decoding)技术: 使用一个更便宜的"draft"模型先产生多个tokens,然后使用"full"模型并行打分(精确解码),如果在某种规则下,这些tokens刚好是需要的/正确的,那就可以直接接受了~
- 其他系统优化,比如:KV caching, batching
相关参考:
- NVIDIA-blog: Mastering LLM Techniques: Inference Optimization
- huggingface-blog: Topic 23: What is LLM Inference, it’s challenges and solutions for it
- Speculative Decoding 推测解码方案详解
- Speculative Decoding: 总结、分析、展望
- 大模型推理加速之Speculative Decoding/投机解码(上)
6.2.4 作业二
- Github链接: https://github.com/stanford-cs336/assignment2-systems
- 完整的作业描述pdf文件:https://github.com/stanford-cs336/assignment2-systems/blob/main/cs336_spring2025_assignment2_systems.pdf
作业二大致描述:
- 使用
Triton实现一个fused RMSNorm kernel - 实现分布式的数据并行训练(distributed data parallel training)
- 实现优化器状态分片(
optimizer state sharding)- Optimizer state sharding (ZeRO)
- 一些模型并行(model parallelism),例如FSDP,从头实现会比较复杂,因此我们只需要实现一个简化版,但是鼓励大家去了解完整的版本,课上会讲解完整的版本
- 对上述实现进行基准测试和性能分析(
Benchmark and profile)
6.3 scaling_laws部分
6.3.1 说明
- 目标:在小规模上进行实验,搞清楚原理等内容;预测大规模实验上的超参/损失(hyperparameters/loss)
- 关键问题:
- 如果给了你一定的计算资源(FLOPs budget,flops预算),该选择什么样尺寸的模型呢?
- 如果选择了比较大的模型,那就只能用比较少的数据训练
- 如果选择了比较小的模型,就可以用比较多的数据训练
- 在给定的计算资源下,
模型size和数据规模的最佳平衡点是什么?
- 有广泛的研究回答了这个问题,Compute-optimal scaling laws(计算最优规模定律)
- OpenAI: Scaling Laws for Neural Language Models-[Kaplan+ 2020]
- DeepMind: Training Compute-Optimal Large Language Models-[Hoffmann+ 2022], chinchilla optimal
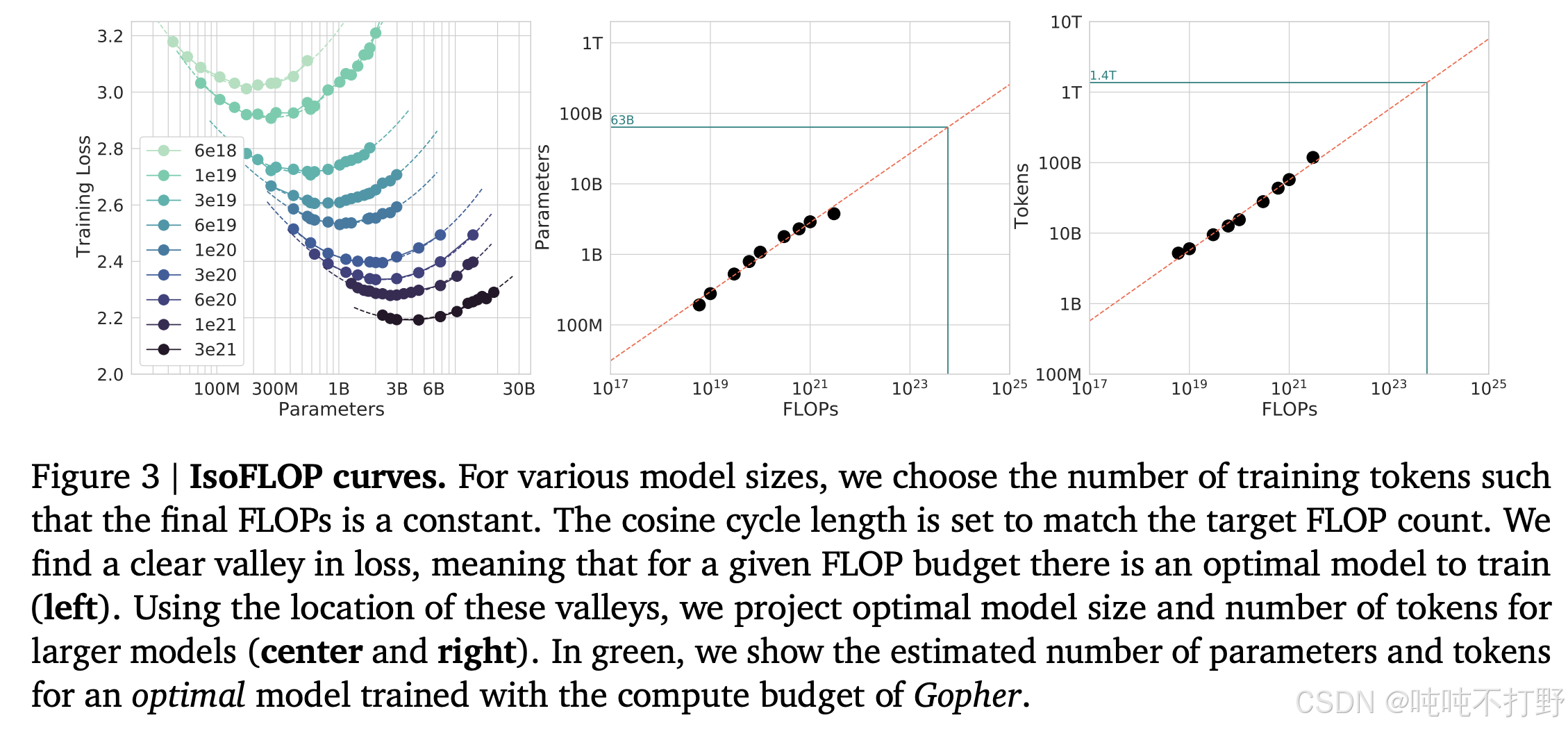 图自 Training Compute-Optimal Large Language Models-[Hoffmann+ 2022]
图自 Training Compute-Optimal Large Language Models-[Hoffmann+ 2022]
PS: 没有在论文里直接找到以下结论(可能是我看的太粗了)
𝐿(𝑁, 𝐷) as a function of the number of model parameters 𝑁, and the number of training tokens, 𝐷.
Since the computational budget 𝐶 is a deterministic function FLOPs(𝑁, 𝐷) of the number of seen
training tokens and …
根据论文里的以上内容:
- NNN表示 模型的参数量
- DDD表示 训练的tokens的数量
- CCC表示 给的计算的FLOPS
计算公式:
D∗=20N∗D^* = 20N^*D∗=20N∗
即:模型参数量为NNN的模型,应该用20×N20\times N20×N大小的语料tokens来训练(这里并没有考虑推理的情况),例如:1.4B参数量的模型应该在28B tokens的语料上训练)
6.3.2 作业三
- Github链接: https://github.com/stanford-cs336/spring2024-assignment3-scaling
- 或者2025年最新的:https://github.com/stanford-cs336/assignment3-scaling/tree/main
- 完整的作业描述pdf文件:https://github.com/stanford-cs336/spring2024-assignment3-scaling/blob/master/cs336_spring2024_assignment3_scaling.pdf
作业三大致描述:
- 我们基于先前的运行结果定义一个训练API(超参数 → 损失),输入一套训练的超参,输出损失
- 在FLOPs预算范围内提交“训练任务”,并收集数据点
- 根据数据点拟合一个缩放定律
- 提交针对放大后超参数的预测结果
- 排行榜:在给定FLOPs预算下最小化损失
6.4 data部分
6.4.1 说明
数据决定了模型的能力,比如:在多语言(multilanguage)的数据集上训练的llm就具有多语言能力;在code数据集上训练的llm就具有code的能力;数学数据集同理~
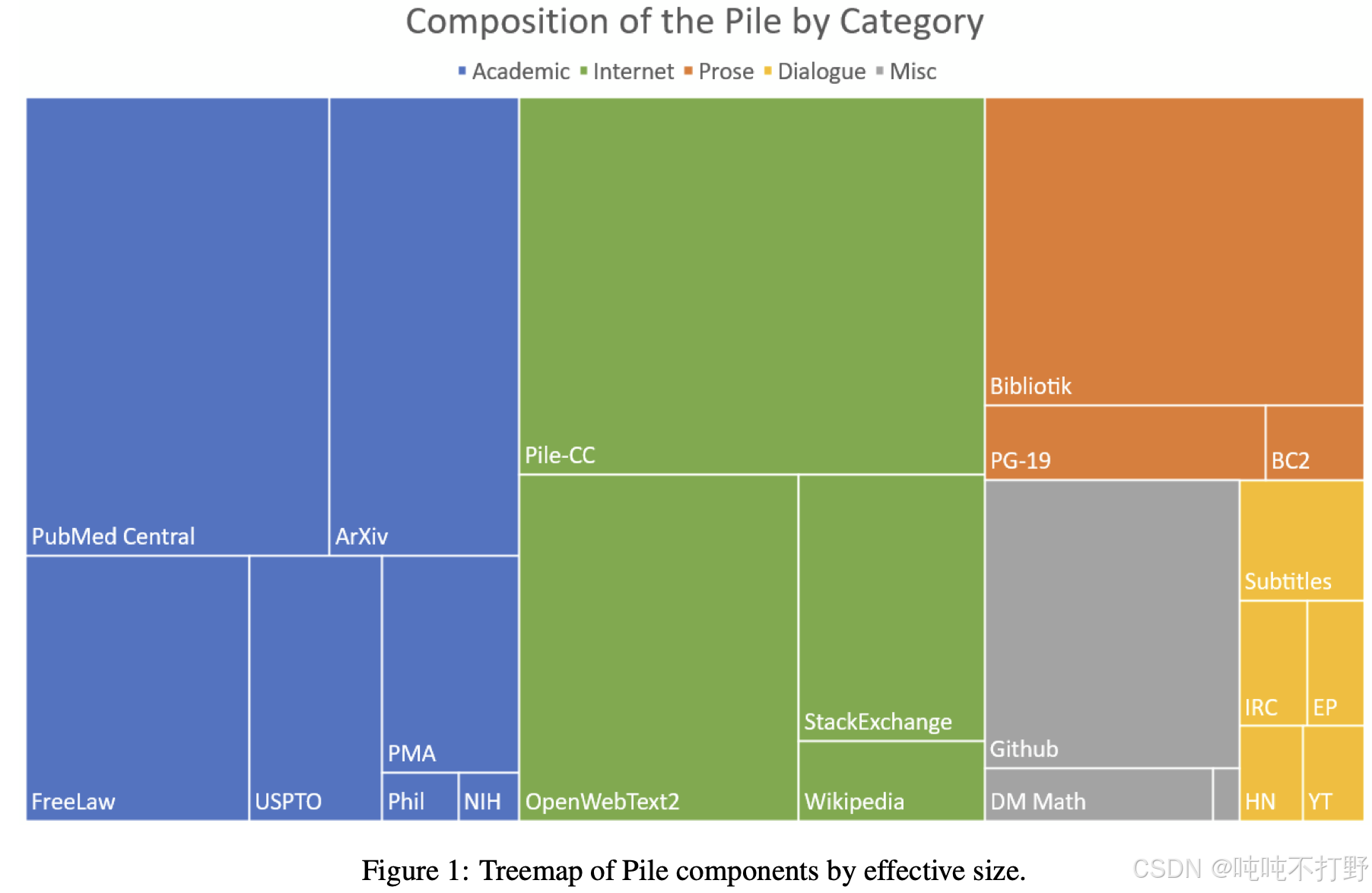
上图来论文-arxiv: The Pile: An 800GB Dataset of Diverse Text for Language Modeling
参考:
- Pile
- arxiv: The Pile: An 800GB Dataset of Diverse Text for Language Modeling
- arxiv: Datasheet for the Pile
评估(Evalution),如何评价一个模型的好坏,包括以下内容:
- Perplexity(
困惑度): textbook evaluation for language models - Standardized testing(
标准测试/基于基准数据集的测试) (e.g., MMLU, HellaSwag, GSM8K)- 如果是基座模型,就使用标准测试
- Instruction following(
指令跟随基准数据集测试) (e.g., AlpacaEval, IFEval, WildBench)- 如果是对话模型,就使用指令跟随测试
- Scaling test-time compute: chain-of-thought, ensembling
- 如果包含思维链,以及模型集成,该怎么测试
- LM-as-a-judge: evaluate generative tasks
- 以及使用LM作为裁判,来评估生成式的任务
- Full system: RAG, agents
- 如果是添加了RAG或者智能体的系统,该如何去进行评测
Data curation(数据监管)
- 数据并不是凭空产生的
- 常见的数据来源:webpage(scrawled from the Internet), books, arXiv papers, GitHub code, etc.
- 互联网数据,比如:
Common Crawl爬的数据,远比你想象的更tra
- 互联网数据,比如:
- Appeal to fair use to train on copyright data? Henderson+ 2023
- 关于训练所使用的数据的版权问题
- Might have to license data (e.g., Google with Reddit data), article
- 虽然互联网上有很多社区,比如知乎,csdn等,但是实际上,想要使用这些社区的数据,是需要购买
license(许可)的
- 虽然互联网上有很多社区,比如知乎,csdn等,但是实际上,想要使用这些社区的数据,是需要购买
- Formats: HTML, PDF, directories (not text!)
- 爬取的数据,大多都是HTML,PDF等格式,并不是直接可用的文本
Data processing
- Transformation: convert HTML/PDF to text (preserve content, some structure, rewriting)
- 转换,把HTML/PDF等格式转为纯文本内容
- 这是一个有损过程(lossy process),
- 关键在于保留内容,以及一些结构(目录/标题,段落等的区分)
- Filtering: keep high quality data, remove harmful content (via classifiers)
- 过滤主要是为了得到更高质量的数据
- 一般会使用分类器来过滤有害内容,比如:敏感信息等~
- Deduplication: save compute, avoid memorization; use Bloom filters or MinHash
- 去重
6.4.2 作业四
- Github链接: https://github.com/stanford-cs336/spring2024-assignment4-data
- 完整的作业描述pdf文件:https://github.com/stanford-cs336/spring2024-assignment4-data/blob/master/cs336_spring2024_assignment4_data.pdf
大致描述:
- 会提供原始的
Common Crawl文件,亲自感受下互联网一手数据的处理难度~- 要求将
Common Crawl HTML转为text
- 要求将
- 训练分类器,用来过滤高质量数据,以及有害信息;
- 使用
MinHash来进行去重; - Leaderboard: 在给定的token下,最小化困惑度(minimize
perplexitygiven token budget);
6.5 alignment部分
6.5.1 说明
有了数据,和基本的一些网络组件之后,就可以开始训练模型了。
此时得到的模型是 base model(基座模型)
- 基座模型的作用,根据当前输入,预测下一个token。
- 基座模型具有巨大的潜力
为了让基座模型能够更好的为人所使用,需要进行对齐/(alignment),对齐主要有以下三个作用:
- 更好的遵循指令(
follow instructions) - 调整风格(指定格式,例如: json/md; 长度,长篇/短篇;语调:严谨/诙谐)
- 保证安全(拒绝回答有害问题)
对齐通常包含两个阶段:
- supervised fine tuning(即: SFT)
def supervised_finetuning():"""Supervised finetuning (SFT)Instruction data: (prompt, response) pairssft_data: list[ChatExample] = [ChatExample(turns=[Turn(role="system", content="You are a helpful assistant."),Turn(role="user", content="What is 1 + 1?"),Turn(role="assistant", content="The answer is 2."),],),]"""Data often involves human annotation.Intuition: base model already has the skills, just need few examples to surface them. [Zhou+ 2023]Supervised learning: fine-tune model to maximize p(response | prompt).- SFT使用的数据,一般都包含人类标注
- [Zhou+ 2023]——LIMA: Less Is More for Alignment:
base model已经包含大部分的内容,只需要一些例子来展示(fewshot的作用,举一反三~) - SFT的目的: 最大化概率
p(response | prompt)
- learning_from_feedback()
- 在SFT得到初步的指令遵循模型后,如果想要改进,可以:1)找更多的SFT数据或者人工标注更多;2)不使用昂贵的标注,考虑使用基于反馈的数据进行训练,这样标注更便宜~
- 偏好数据(Preference data):
Data: generate multiple responses using model (e.g., [A, B]) to a given prompt.User provides preferences (e.g., A < B or A > B).preference_data: list[PreferenceExample] = [PreferenceExample(history=[Turn(role="system", content="You are a helpful assistant."),Turn(role="user", content="What is the best way to train a language model?"),],response_a="You should use a large dataset and train for a long time.",response_b="You should use a small dataset and train for a short time.",chosen="a",)] - Verifiers:①
Formal verifiers(e.g., for code, math)
比如你要进行数学或者代码垂直领域的训练,则可以直接用计算器或者编译器等执行结果来进行验证。②Learned verifiers: train against an LM-as-a-judge(训练一个llm来作为评价器,即:习得验证器) - Algorithms:强化学习算法也可以在不标注数据的情况下,进一步优化模型的性能
- Proximal Policy Optimization (PPO) from reinforcement learning
[Schulman+ 2017][Ouyang+ 2022]: 最早开发并用于指令调优的强化学习算法是 PPO - Direct Policy Optimization (DPO): for preference data, simpler
[Rafailov+ 2023]:如果只有偏好数据,则使用更简单的DPO算法,也会有很好的效果。(如果是Verifiers data,则必须要用完全的强化学习,不能用DPO) - Group Relative Preference Optimization (GRPO): remove value function
[Shao+ 2024]: Deepseek开发的通过移除PPO的value function,简化并使的PPO变得更高效。
- Proximal Policy Optimization (PPO) from reinforcement learning
6.5.2 作业五
- Github链接: https://github.com/stanford-cs336/spring2024-assignment5-alignment
- 完整的作业描述pdf文件:https://github.com/stanford-cs336/spring2024-assignment5-alignment/blob/master/cs336_spring2024_assignment5_alignment.pdf
大致描述:
- Implement supervised fine-tuning,实现SFT
- Implement Direct Preference Optimization (DPO),实现DPO
- Implement Group Relative Preference Optimization (GRPO),实现GRPO
- 以及上述结果的评估evaluation
6.6 回顾总结
Efficiency drives design decisions
效率是第一设计原则~
Today, we are compute-constrained, so design decisions will reflect squeezing the most out of given hardware.
- Data processing: avoid wasting precious compute updating on bad / irrelevant data
- 数据预处理的时候,会进行比较激进的filter,防止宝贵的计算资源浪费在差的/不想关的数据上
- Tokenization: working with raw bytes is elegant, but compute-inefficient with today’s model architectures.
- 能够直接对字节数据进行训练肯定是更好的,但是对于现有的模型架构来说,这样计算效率不高
- 因而采用分词的方法,来提升训练效率(字节数据的粒度更细,需要的计算资源会更多,分词相当于减少了token总量)
- Model architecture: many changes motivated by reducing memory or FLOPs (e.g., sharing KV caches, sliding window attention)
- 模型结构在设计时,也更多是考虑到计算效率,比如:共享KV caches,以及滑动窗口注意力机制等
- transformers架构本身也是一个高效计算的结构
- Training: we can get away with a single epoch!
- 目的是看到更多的数据,而不是在某个数据点上花费大量的时间
- Scaling laws: use less compute on smaller models to do hyperparameter tuning
- 规模定律则就更是为了效率服务了,目的就是想用更少的计算来确定超参
- Alignment: if tune model more to desired use cases, require smaller base models
- 如果对齐是到更垂直的场景,那么需要的base model可以更小
Tomorrow, we will become data-constrained… (对于顶尖实验室来说,已经是数据受限,而不是计算资源受限了)
GPT-5发布解读:期待与现实的落差,AI发展的新转折点中,提到:
- GPT-5大量使用合成数据、建立数据分级分类体系,以及开发通用的数据质量评估模型,这些工程层面的优化在一定程度上缓解了高质量数据稀缺的问题
一文读懂GPT-5发布会|价格屠夫、编程惊艳,新功能乏善可陈
- 在o1模型推出时,大家一直猜想的由推理模型产生高质量数据,让预训练模型越来越强,再由此通过强化学习加强下一代推理模型的“左脚踩右脚”式训练方法,被OpenAI证实了。
- 不过从效果上看,这个方法明显Scaling的不那么有效。数据的困境,还没有被完全解决。



)




)
)







)

