随机梯度下降算法简介
之前的章节中介绍了利用最速下降算法可以实现维纳滤波器的最优解(LMMSE),其最优解的形式为:
w0=R−1Pw_{0} = R^{- 1}Pw0=R−1P
它基于两个假设:
-
环境的联合平稳,即输入u(n)u(n)u(n)以及期望输出d(n)d(n)d(n)是联合平稳的。
-
环境的有关信息,即u(n)u(n)u(n)构成的自相关矩阵R\mathbf{R}R,以及由u(n)u(n)u(n)和d(n)d(n)d(n)构成的互相关矩阵P\mathbf{P}P需要已知。
遗憾的是R\mathbf{R}R和P\mathbf{P}P所包含的环境信息不可获得或不可用,因此我们应该寻找一类具有适应未知环境统计变化能力的新算法,导出这些算法由以下两种不同的方法:
-
一种是基于随机梯度下降的方法,将在此章节进行讨论。
-
另一种是基于最小二乘的方法。
随机梯度下降算法表示从某一次自适应循环到下一次自适应循环的自适应滤波算法中梯度的"随机选择"。随机梯度下降算法和最速下降算法都是局部滤波方法。
严格意义上不把随机梯度看成一种优化算法,理由如下:
因为梯度上由随机噪声的存在,它永远也无法达到凸优化问题所期望的最优解。相反,一旦它到达最优解的附近,它将用一种随机游走的方式持续在该解周围徘徊,从而无法停留在一个平衡点上。
故随机梯度下降算法是次优的。
LMS算法结构推导
最小均方LMS算法作为随机梯度算法的第一个应用,其独特特征可以概括如下:
-
LMS算法简易,复杂度和FIR滤波器的维数呈线性相关。
-
不用要知道P和R
-
在位置环境干扰下,具有一定的鲁棒性。
-
不需要相关矩阵求逆,所以它比RLS更加简单。
基于以上特征,LMS是目前最流行的自适应滤波算法之一,下面是LMS算法结构图:
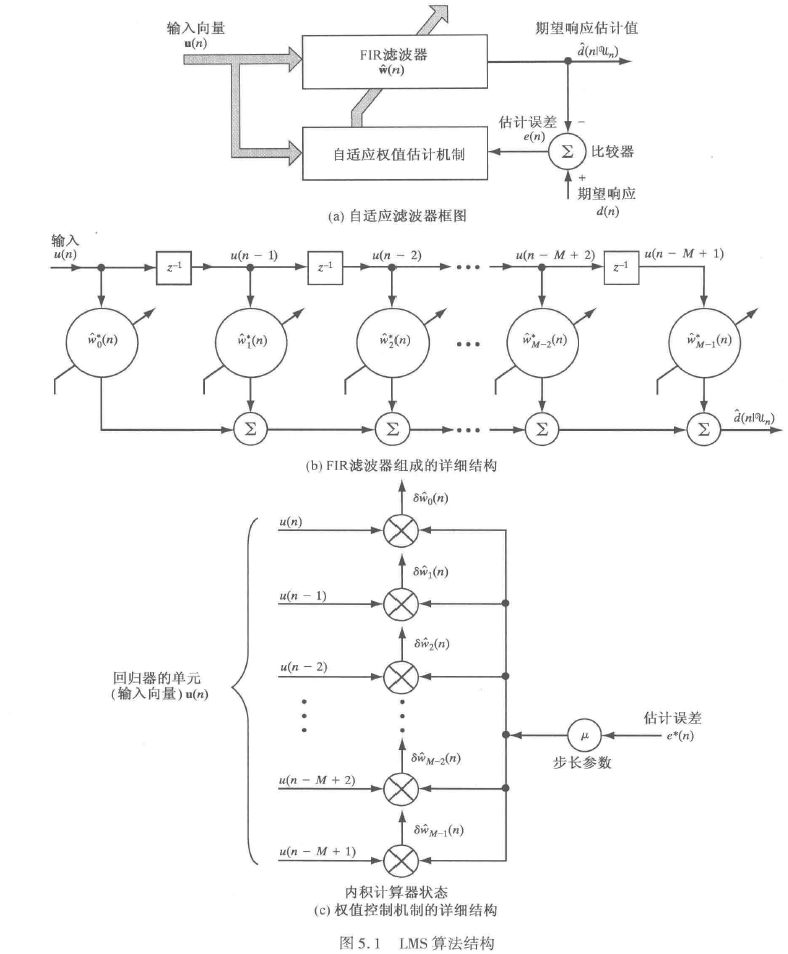
它包含了3个部分:
- FIR滤波器,实现估计输出的计算:
d^(n)=∑k=0M−1u(n−k)∗wk∗(n)\widehat{d}(n) = \sum_{k = 0}^{M - 1}{u(n - k)*{w_{k}}^{*}(n)}d(n)=k=0∑M−1u(n−k)∗wk∗(n) - 比较器,实现估计误差的计算
e(n)=d(n)−d^(n)e(n) = d(n) - \widehat{d}(n)e(n)=d(n)−d(n)
- 自适应权值控制机制,实现滤波器系数的更新
wk(n+1)=wk(n)+μ∗u(n−k)∗e∗(n),k=0,1,...,M−1w_{k}(n + 1) = w_{k}(n) + \mu*u(n - k)*e^{*}(n),k = 0,1,...,M - 1wk(n+1)=wk(n)+μ∗u(n−k)∗e∗(n),k=0,1,...,M−1
下面给出详细的推导过程。
回顾之前定义的代价函数(均方误差),期望算子对n时刻大量-统计-独立实现的瞬时平方估计,误差∣e(n)∣2|e(n)|^{2}∣e(n)∣2进行集平均。
J(n)=E(∣e(n)∣2)J(n) = E\left( |e(n)|^{2} \right)J(n)=E(∣e(n)∣2)
遗憾的是,在自适应滤波器的实际应用中,上述方式使用集平均是不可行的。
我们如此说是因为使用自适应滤波的动机是基于估计误差e(n)e(n)e(n)(随时间n而变)的单一实现,以在线方式来自适应未知环境的统计变化。这些做恰好和随机梯度下降算法是一回事,所以我们移除上面的期望算子,得到了新的代价函数:
Js(n)=∣e(n)∣2=e(n)∗e(n)∗J_{s}(n) = |e(n)|^{2} = e(n)*e(n)^{*}Js(n)=∣e(n)∣2=e(n)∗e(n)∗
Js(n)J_{s}(n)Js(n)的下标s用来表示有别于集平均表达式中的J(n)J(n)J(n)。估计误差e(n)e(n)e(n)是随机过程的样本函数,其代价函数Js(n)J_{s}(n)Js(n)本身就是一个随机过程的样值。因此Js(n)J_{s}(n)Js(n)相对于FIR滤波器第k个抽头权值wk(n)w_{k}(n)wk(n)的导数也是随机的,下面会给出证明。代价函数Js(n)J_{s}(n)Js(n)对wk∗(n){w_{k}}^{*}(n)wk∗(n)求偏导可表示为:
∇Js,k(n)=∂Js(n)∂wk∗(n)=∂(e(n)∗e(n)∗)∂wk∗(n)=∂((d(n)−d^(n))∗(d(n)−d^(n))∗)∂wk∗(n)\nabla J_{s,k}(n) = \frac{\partial J_{s}(n)}{\partial{w_{k}}^{*}(n)} = \frac{\partial(e(n)*e(n)^{*})}{\partial{w_{k}}^{*}(n)} = \frac{\partial((d(n) - \widehat{d}(n))*(d(n) - \widehat{d}(n))^{*})}{\partial{w_{k}}^{*}(n)}∇Js,k(n)=∂wk∗(n)∂Js(n)=∂wk∗(n)∂(e(n)∗e(n)∗)=∂wk∗(n)∂((d(n)−d(n))∗(d(n)−d(n))∗)
=∂[(d(n)−∑k=0M−1u(n−k)∗wk∗(n))∗(d(n)−∑k=0M−1u(n−k)∗wk∗(n))∗]∂wk∗(n)= \frac{\partial\left\lbrack \left( d(n) - \sum_{k = 0}^{M - 1}{u(n - k)*{w_{k}}^{*}(n)} \right)*\left( d(n) - \sum_{k = 0}^{M - 1}{u(n - k)*{w_{k}}^{*}(n)} \right)^{*} \right\rbrack}{\partial{w_{k}}^{*}(n)}=∂wk∗(n)∂[(d(n)−∑k=0M−1u(n−k)∗wk∗(n))∗(d(n)−∑k=0M−1u(n−k)∗wk∗(n))∗]
=∂[(d(n)−∑k=0M−1u(n−k)∗wk∗(n))∗(d∗(n)−∑k=0M−1u∗(n−k)∗wk(n))]∂wk∗(n)= \frac{\partial\left\lbrack \left( d(n) - \sum_{k = 0}^{M - 1}{u(n - k)*{w_{k}}^{*}(n)} \right)*\left( d^{*}(n) - \sum_{k = 0}^{M - 1}{u^{*}(n - k)*w_{k}(n)} \right) \right\rbrack}{\partial{w_{k}}^{*}(n)}=∂wk∗(n)∂[(d(n)−∑k=0M−1u(n−k)∗wk∗(n))∗(d∗(n)−∑k=0M−1u∗(n−k)∗wk(n))]
=∂(−d∗(n)∑k=0M−1u(n−k)∗wk∗(n)−d(n)∑k=0M−1u∗(n−k)∗wk(n)+∑k=0M−1u(n−k)∗wk∗(n)∗∑k=0M−1u∗(n−k)∗wk(n))∂wk∗(n)= \frac{\partial\begin{pmatrix}-d^{*}(n)\sum_{k = 0}^{M - 1}{u(n - k)*{w_{k}}^{*}(n) - d(n)\sum_{k = 0}^{M - 1}{u^{*}(n - k)*w_{k}(n)}} \\+\sum_{k = 0}^{M - 1}{u(n - k)*{w_{k}}^{*}(n)}*\sum_{k = 0}^{M - 1}{u^{*}(n - k)*w_{k}(n)}
\end{pmatrix}}{\partial{w_{k}}^{*}(n)}=∂wk∗(n)∂(−d∗(n)∑k=0M−1u(n−k)∗wk∗(n)−d(n)∑k=0M−1u∗(n−k)∗wk(n)+∑k=0M−1u(n−k)∗wk∗(n)∗∑k=0M−1u∗(n−k)∗wk(n))
=∂(−d∗(n)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))−d(n)∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+∑k=0M−1u(n−k)∗(ak(n)−jbk(n))∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n)))∂(ak(n)−jbk(n))= \frac{\partial\begin{pmatrix}-d^{*}(n)\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right) - d(n)\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)}} \\+\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right)}*\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)} \end{pmatrix}}{\partial\left( a_{k}(n) - jb_{k}(n) \right)}=∂(ak(n)−jbk(n))∂(−d∗(n)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))−d(n)∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+∑k=0M−1u(n−k)∗(ak(n)−jbk(n))∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n)))
=∂(−d∗(n)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))−d(n)∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+∑k=0M−1u(n−k)∗(ak(n)−jbk(n))∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n)))∂ak(n)+j∗∂(−d∗(n)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))−d(n)∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+∑k=0M−1u(n−k)∗(ak(n)−jbk(n))∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n)))∂bk(n)= \begin{matrix}
\frac{\partial\begin{pmatrix}-d^{*}(n)\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right) - d(n)\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)}} \\+\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right)}*\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)}
\end{pmatrix}}{\partial a_{k}(n)} + \\
j*\frac{\partial\begin{pmatrix}-d^{*}(n)\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right) - d(n)\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) +jb_{k}(n) \right)}} \\+\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right)}*\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)}
\end{pmatrix}}{\partial b_{k}(n)}
\end{matrix}=∂ak(n)∂(−d∗(n)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))−d(n)∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+∑k=0M−1u(n−k)∗(ak(n)−jbk(n))∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n)))+j∗∂bk(n)∂(−d∗(n)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))−d(n)∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+∑k=0M−1u(n−k)∗(ak(n)−jbk(n))∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n)))
=−d∗(n)u(n−k)−d(n)u∗(n−k)+u(n−k)∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+u∗(n−k)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))+j∗(j∗d∗(n)u(n−k)−j∗d(n)u∗(n−k)−j∗u(n−k)∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+j∗u∗(n−k)∗∑k=0M−1u(n−k)∗(ak(n)−jbk(n)))= \begin{matrix}
\begin{matrix}-d^{*}(n)u(n - k) - d(n)u^{*}(n - k) + u(n - k)*\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)} \\+u^{*}(n - k)\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right)}
\end{matrix} \\+j*\begin{pmatrix}
j*d^{*}(n)u(n - k) - j*d(n)u^{*}(n - k) - j*u(n - k)*\sum_{k = 0}^{M - 1}{u^{*}(n - k)*\left( a_{k}(n) + jb_{k}(n) \right)} \\+j*u^{*}(n - k)*\sum_{k = 0}^{M - 1}{u(n - k)*\left( a_{k}(n) - jb_{k}(n) \right)}
\end{pmatrix}
\end{matrix}=−d∗(n)u(n−k)−d(n)u∗(n−k)+u(n−k)∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+u∗(n−k)∑k=0M−1u(n−k)∗(ak(n)−jbk(n))+j∗(j∗d∗(n)u(n−k)−j∗d(n)u∗(n−k)−j∗u(n−k)∗∑k=0M−1u∗(n−k)∗(ak(n)+jbk(n))+j∗u∗(n−k)∗∑k=0M−1u(n−k)∗(ak(n)−jbk(n)))
=−d∗(n)u(n−k)−d(n)u∗(n−k)+u(n−k)d^∗(n)+u∗(n−k)d^(n)−d∗(n)u(n−k)+d(n)u∗(n−k)+u(n−k)d^∗(n)−u∗(n−k)d^(n)= \begin{matrix}-d^{*}(n)u(n - k) - d(n)u^{*}(n - k) + u(n - k){\widehat{d}}^{*}(n) + u^{*}(n - k)\widehat{d}(n) \\-d^{*}(n)u(n - k) + d(n)u^{*}(n - k) + u(n - k){\widehat{d}}^{*}(n) - u^{*}(n - k)\widehat{d}(n)
\end{matrix}=−d∗(n)u(n−k)−d(n)u∗(n−k)+u(n−k)d∗(n)+u∗(n−k)d(n)−d∗(n)u(n−k)+d(n)u∗(n−k)+u(n−k)d∗(n)−u∗(n−k)d(n)
=−2d∗(n)u(n−k)+2u(n−k)d^∗(n)= - 2d^{*}(n)u(n - k) + 2u(n - k){\widehat{d}}^{*}(n) =−2d∗(n)u(n−k)+2u(n−k)d∗(n)
=−2u(n−k)(d(n)−d^(n))∗= - 2u(n - k)\left( d(n) - \widehat{d}(n) \right)^{*}=−2u(n−k)(d(n)−d(n))∗
=−2u(n−k)∗e∗(n)= - 2u(n - k)*e^{*}(n)=−2u(n−k)∗e∗(n)
重写上面的结论,LMS算法的代价函数的梯度算子是:
∇Js,k(n)=−2u(n−k)∗e∗(n),k=0,1,2,...,M−1\nabla J_{s,k}(n) = - 2u(n - k)*e^{*}(n),k = 0,1,2,...,M - 1∇Js,k(n)=−2u(n−k)∗e∗(n),k=0,1,2,...,M−1
MSE(均方误差)算法的代价函数的梯度算子是:
∇kJ=−2∗E[u(n−k)∗e∗(n)],k=0,1,2,...,M−1\nabla_{k}J = - 2*E\left\lbrack u(n - k)*e^{*}(n) \right\rbrack,k = 0,1,2,...,M - 1∇kJ=−2∗E[u(n−k)∗e∗(n)],k=0,1,2,...,M−1
发现两者的区别仅在于是否有期望算子,那是因为新的代价函数Js(n)J_{s}(n)Js(n)取消了集平均,没有了期望算子,所以对系数的偏微分也就是没有期望算子。也正是没有了这个期望算子,再次重复上面的一个结论,Js(n)\mathbf{J}_{\mathbf{s}}\mathbf{(n)}Js(n)相对于FIR滤波器第k个抽头权值wk(n)\mathbf{w}_{\mathbf{k}}\mathbf{(n)}wk(n)的导数也是随机的(随机噪声没有被期望所平均)。
基于上面的随机梯度∇Js,k(n)\nabla J_{s,k}(n)∇Js,k(n),可得LMS算法的更新规则如下:
wk(n+1)=wk(n)−12μ∇Js,k(n),k=0,1,...,M−1w_{k}(n + 1) = w_{k}(n) - \frac{1}{2}\mu\nabla J_{s,k}(n),k = 0,1,...,M - 1wk(n+1)=wk(n)−21μ∇Js,k(n),k=0,1,...,M−1
将随机梯度代入可得:
wk(n+1)=wk(n)+μ∗u(n−k)∗e∗(n),k=0,1,...,M−1w_{k}(n + 1) = w_{k}(n) + \mu*u(n - k)*e^{*}(n),k = 0,1,...,M - 1wk(n+1)=wk(n)+μ∗u(n−k)∗e∗(n),k=0,1,...,M−1
简化成矩阵形式的
-
系数更新规则:
w(n+1)=w(n)+μu(n)e∗(n),k=0,1,...,M−1\mathbf{w}(n + 1) = \mathbf{w}(n) + \mu\mathbf{u}(n)e^{*}(n),k = 0,1,...,M - 1w(n+1)=w(n)+μu(n)e∗(n),k=0,1,...,M−1 -
估计误差:
e(n)=d(n)−d^(n)e(n) = d(n) - \widehat{d}(n)e(n)=d(n)−d(n) -
估计输出
d^(n)=wH(n)u(n)\widehat{d}(n) = \mathbf{w}^{H}(n)\mathbf{u}(n)d(n)=wH(n)u(n)
其中
w(n)=[w0(n)w1(n)...wM−1(n)],u(n)=[u(n)u(n−1)...u(n−M+1)]\mathbf{w}(n) = \begin{bmatrix}
w_{0}(n) \\
w_{1}(n) \\
... \\
w_{M - 1}(n)
\end{bmatrix},\mathbf{u}(n) = \begin{bmatrix}
u(n) \\
u(n - 1) \\
... \\
u(n - M + 1)
\end{bmatrix}w(n)=w0(n)w1(n)...wM−1(n),u(n)=u(n)u(n−1)...u(n−M+1)
同样的,这里的μ\muμ的取值将会影响LMS算法中系数的稳定性和瞬态响应,从稳定性的角度出发,μ\muμ应当取一个较小的正值。
小结
不管LMS算法和维纳滤波之间可能存在何种联系,一旦从维纳滤波器导出LMS算法时删除了期望算子E,他们之间的联系就完全破坏了。
最优性考虑
考虑LMS算法的最优性有两种办法:
-
局部最优性
-
全局次优性
局部最优性
之前提及随机梯度下降法是一种局部方法,它表明搜索的一个梯度不仅是随机的,而且是以一种局部的方式进行的。前者说梯度是随机的,可有梯度的表达式看出来,重写如下:
∇Js,k(n)=−2u(n−k)∗e∗(n),k=0,1,2,...,M−1\nabla J_{s,k}(n) = - 2u(n - k)*e^{*}(n),k = 0,1,2,...,M - 1∇Js,k(n)=−2u(n−k)∗e∗(n),k=0,1,2,...,M−1
上式的估计误差就是随机量,所以梯度也是随机的。
只要从一次自适应循环到下一次自适应循环由数据引起的扰动充分小,那么且不管其随机性,LMS算法在欧氏意义下呈现局部最优性,为了解释,我们考虑以下两种场景
- 当前估计误差表达式如下e(n)=d(n)−wH(n)u(n)e(n) = d(n) - \mathbf{w}^{H}(n)\mathbf{u}(n)e(n)=d(n)−wH(n)u(n)
- 后验估计误差表达式如下r(n)=d(n)−wH(n+1)u(n)r(n) = d(n) - \mathbf{w}^{H}(n + 1)\mathbf{u}(n)r(n)=d(n)−wH(n+1)u(n)
注意后验估计误差有别于一步预测wH(n)u(n+1)\mathbf{w}^{H}(n)\mathbf{u}(n + 1)wH(n)u(n+1)
将后验估计误差减去当前估计误差可得(中间利用了w(n+1)=w(n)+μu(n)e∗(n)\mathbf{w}(n + 1) = \mathbf{w}(n) + \mu\mathbf{u}(n)e^{*}(n)w(n+1)=w(n)+μu(n)e∗(n) ):
r(n)−e(n)=(wH(n)−wH(n+1))u(n)=(w(n)−w(n+1))Hu(n)=(−μu(n)e∗(n))Hu(n)=−μe(n)uH(n)u(n)=−μe(n)∥u(n)∥2{r(n) - e(n) = \left( \mathbf{w}^{H}(n) - \mathbf{w}^{H}(n + 1) \right)\mathbf{u}(n) = \left( \mathbf{w}(n) - \mathbf{w}(n + 1) \right)^{H}\mathbf{u}(n) }{= \left( - \mu\mathbf{u}(n)e^{*}(n) \right)^{H}\mathbf{u}(n) = - \mu e(n)\mathbf{u}^{H}(n)\mathbf{u}(n) }{= - \mu e(n)\left\| \mathbf{u}(n) \right\|^{2}}r(n)−e(n)=(wH(n)−wH(n+1))u(n)=(w(n)−w(n+1))Hu(n)=(−μu(n)e∗(n))Hu(n)=−μe(n)uH(n)u(n)=−μe(n)∥u(n)∥2
移项重新整理可得:
r(n)=(1−μ∥u(n)∥2)e(n)r(n) = (1 - \mu\left\| \mathbf{u}(n) \right\|^{2})e(n)r(n)=(1−μ∥u(n)∥2)e(n)
为了让后验估计误差小于当前估计误差,那么就必须满足下列约束条件:
−1<1−μ∥u(n)∥2<1- 1 < 1 - \mu\left\| \mathbf{u}(n) \right\|^{2} < 1−1<1−μ∥u(n)∥2<1
或者是
0<12μ∥u(n)∥2<10 < \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} < 10<21μ∥u(n)∥2<1
在此约束条件下,进一步寻找w(n+1)\mathbf{w}(n + 1)w(n+1) 与过去值w(n)\mathbf{w}(n)w(n)
的平方欧氏范数达到最小的w(n+1)\mathbf{w}(n + 1)w(n+1)的最优值。因此局部最优化实际上就是一个约束最优化问题。
之前已经推得r(n)−e(n)+μe(n)∥u(n)∥2=0r(n) - e(n) + \mu e(n)\left\| \mathbf{u}(n) \right\|^{2} = 0r(n)−e(n)+μe(n)∥u(n)∥2=0,将后面的拆分成两个式子分别放在式子的左右,可得
r(n)−e(n)+12μe(n)∥u(n)∥2=−12μe(n)∥u(n)∥2r(n) - e(n) + \frac{1}{2}\mu e(n)\left\| \mathbf{u}(n) \right\|^{2} = - \frac{1}{2}\mu e(n)\left\| \mathbf{u}(n) \right\|^{2}r(n)−e(n)+21μe(n)∥u(n)∥2=−21μe(n)∥u(n)∥2
设g(n)g(n)g(n) 为
g(n)=r(n)−e(n)+12μe(n)∥u(n)∥2=−12μe(n)∥u(n)∥2g(n) = r(n) - e(n) + \frac{1}{2}\mu e(n)\left\| \mathbf{u}(n) \right\|^{2} = - \frac{1}{2}\mu e(n)\left\| \mathbf{u}(n) \right\|^{2}g(n)=r(n)−e(n)+21μe(n)∥u(n)∥2=−21μe(n)∥u(n)∥2
g(n)g(n)g(n) 进一步表达为:
g(n)=r(n)−(1−12μ∥u(n)∥2)e(n)=−12μe(n)∥u(n)∥2g(n) = r(n) - \left( 1 - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) = - \frac{1}{2}\mu e(n)\left\| \mathbf{u}(n) \right\|^{2}g(n)=r(n)−(1−21μ∥u(n)∥2)e(n)=−21μe(n)∥u(n)∥2
重写之前的约束条件0<12μ∥u(n)∥2<10 < \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} < 10<21μ∥u(n)∥2<1,因此可得
−1<g(n)=r(n)−(1−12μ∥u(n)∥2)e(n)=−12μe(n)∥u(n)∥2<0,或−1<g(n)<0- 1 < g(n) = r(n) - \left( 1 - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) = - \frac{1}{2}\mu e(n)\left\| \mathbf{u}(n) \right\|^{2} < 0,或 - 1 < g(n) < 0−1<g(n)=r(n)−(1−21μ∥u(n)∥2)e(n)=−21μe(n)∥u(n)∥2<0,或−1<g(n)<0
接下来应用著名的拉格朗日乘子法,首先引入拉格朗日函数,其标准的表达式为
L(n)=f(n)+λ(n)g(n)L(n) = f(n) + \lambda(n)g(n)L(n)=f(n)+λ(n)g(n)
其中f(n)f(n)f(n)是需要求极值(一般是极小值)的代价函数,
g(n)g(n)g(n)是约束条件,λ(n)\lambda(n)λ(n)是拉格朗日乘子。在LMS算法里,我们定义的拉格朗日函数为:
L(n)=12∥w(n+1)−w(n)∥2+λ(n)[r(n)−(1−12μ∥u(n)∥2)e(n)]L(n) = \frac{1}{2}\left\| \mathbf{w}(n + 1) - \mathbf{w}(n) \right\|^{2} + \lambda(n)\left\lbrack r(n) - \left( 1 - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) \right\rbrackL(n)=21∥w(n+1)−w(n)∥2+λ(n)[r(n)−(1−21μ∥u(n)∥2)e(n)]
其中λ(n)\lambda(n)λ(n) 是时变的拉格朗日乘子。
此时将L(n)L(n)L(n) 对wH(n+1)\mathbf{w}^{H}(n + 1)wH(n+1)求导数,得到:
∂L(n)∂wH(n+1)=∂{12∥w(n+1)−w(n)∥2+λ(n)[r(n)−(1−12μ∥u(n)∥2)e(n)]}∂wH(n+1)=∂[12(w(n+1)−w(n))H(w(n+1)−w(n))+λ(n)(d(n)−wH(n+1)u(n))]∂wH(n+1)=∂[12(w(n+1)H−w(n)H)(w(n+1)−w(n))+λ(n)(d(n)−wH(n+1)u(n))]∂wH(n+1)=∂[12(wH(n+1)−wH(n))(w(n+1)−w(n))]∂wH(n+1)+∂[λ(n)(d(n)−wH(n+1)u(n))]∂wH(n+1)=∂[12(wH(n+1)w(n+1)−wH(n+1)w(n)−wH(n)w(n+1)+wH(n)w(n))]∂wH(n+1)−∂[λ(n)wH(n+1)u(n)]∂wH(n+1)=12∂wH(n+1)∂wH(n+1)w(n+1)+12∂w(n+1)∂wH(n+1)wH(n+1)−12∂wH(n+1)∂wH(n+1)w(n)−12∂w(n+1)∂wH(n+1)wH(n)−λ(n)u(n){\frac{\partial L(n)}{\partial\mathbf{w}^{H}(n + 1)} = \frac{\partial\left\{ \frac{1}{2}\left\| \mathbf{w}(n + 1) - \mathbf{w}(n) \right\|^{2} + \lambda(n)\left\lbrack r(n) - \left( 1 - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) \right\rbrack \right\}}{\partial\mathbf{w}^{H}(n + 1)}
}{= \frac{\partial\left\lbrack \frac{1}{2}\left( \mathbf{w}(n + 1) - \mathbf{w}(n) \right)^{H}\left( \mathbf{w}(n + 1) - \mathbf{w}(n) \right) + \lambda(n)\left( d(n) - \mathbf{w}^{H}(n + 1)\mathbf{u}(n) \right) \right\rbrack}{\partial\mathbf{w}^{H}(n + 1)}
}{= \frac{\partial\left\lbrack \frac{1}{2}\left( \mathbf{w}(n + 1)^{H} - \mathbf{w}(n)^{H} \right)\left( \mathbf{w}(n + 1) - \mathbf{w}(n) \right) + \lambda(n)\left( d(n) - \mathbf{w}^{H}(n + 1)\mathbf{u}(n) \right) \right\rbrack}{\partial\mathbf{w}^{H}(n + 1)}
}{= \frac{\partial\left\lbrack \frac{1}{2}\left( \mathbf{w}^{H}(n + 1) - \mathbf{w}^{H}(n) \right)\left( \mathbf{w}(n + 1) - \mathbf{w}(n) \right) \right\rbrack}{\partial\mathbf{w}^{H}(n + 1)} + \frac{\partial\left\lbrack \lambda(n)\left( d(n) - \mathbf{w}^{H}(n + 1)\mathbf{u}(n) \right) \right\rbrack}{\partial\mathbf{w}^{H}(n + 1)}
}{= \frac{\partial\left\lbrack \frac{1}{2}\left( \mathbf{w}^{H}(n + 1)\mathbf{w}(n + 1) - \mathbf{w}^{H}(n + 1)\mathbf{w}(n) - \mathbf{w}^{H}(n)\mathbf{w}(n + 1) + \mathbf{w}^{H}(n)\mathbf{w}(n) \right) \right\rbrack}{\partial\mathbf{w}^{H}(n + 1)} - \frac{\partial\left\lbrack \lambda(n)\mathbf{w}^{H}(n + 1)\mathbf{u}(n) \right\rbrack}{\partial\mathbf{w}^{H}(n + 1)}
}{= \frac{\frac{1}{2}\partial\mathbf{w}^{H}(n + 1)}{\partial\mathbf{w}^{H}(n + 1)}\mathbf{w}(n + 1) + \frac{\frac{1}{2}\partial\mathbf{w}(n + 1)}{\partial\mathbf{w}^{H}(n + 1)}\mathbf{w}^{H}(n + 1) - \frac{\frac{1}{2}\partial\mathbf{w}^{H}(n + 1)}{\partial\mathbf{w}^{H}(n + 1)}\mathbf{w}(n) - \frac{\frac{1}{2}\partial\mathbf{w}(n + 1)}{\partial\mathbf{w}^{H}(n + 1)}\mathbf{w}^{H}(n) - \lambda(n)\mathbf{u}(n)
}∂wH(n+1)∂L(n)=∂wH(n+1)∂{21∥w(n+1)−w(n)∥2+λ(n)[r(n)−(1−21μ∥u(n)∥2)e(n)]}=∂wH(n+1)∂[21(w(n+1)−w(n))H(w(n+1)−w(n))+λ(n)(d(n)−wH(n+1)u(n))]=∂wH(n+1)∂[21(w(n+1)H−w(n)H)(w(n+1)−w(n))+λ(n)(d(n)−wH(n+1)u(n))]=∂wH(n+1)∂[21(wH(n+1)−wH(n))(w(n+1)−w(n))]+∂wH(n+1)∂[λ(n)(d(n)−wH(n+1)u(n))]=∂wH(n+1)∂[21(wH(n+1)w(n+1)−wH(n+1)w(n)−wH(n)w(n+1)+wH(n)w(n))]−∂wH(n+1)∂[λ(n)wH(n+1)u(n)]=∂wH(n+1)21∂wH(n+1)w(n+1)+∂wH(n+1)21∂w(n+1)wH(n+1)−∂wH(n+1)21∂wH(n+1)w(n)−∂wH(n+1)21∂w(n+1)wH(n)−λ(n)u(n)
应用了∂f∂wH=(∂f∂w)H\frac{\partial\mathbf{f}}{\partial\mathbf{w}^{H}} = \left( \frac{\partial\mathbf{f}}{\partial\mathbf{w}} \right)^{H}∂wH∂f=(∂w∂f)H后,可以进一步化简为下式
∂L(n)∂wH(n+1)=w(n+1)−w(n)−λ(n)u(n)\frac{\partial L(n)}{\partial\mathbf{w}^{H}(n + 1)} = \mathbf{w}(n + 1) - \mathbf{w}(n) - \lambda(n)\mathbf{u}(n)∂wH(n+1)∂L(n)=w(n+1)−w(n)−λ(n)u(n)
为使上式为0,可得
w(n+1)=w(n)+λ(n)u(n)\mathbf{w}(n + 1) = \mathbf{w}(n) + \lambda(n)\mathbf{u}(n)w(n+1)=w(n)+λ(n)u(n)
将此代入拉格朗日方程使其为0,求解λ(n)\lambda(n)λ(n) 的表达式。
L(n)=12∥w(n+1)−w(n)∥2+λ(n)[r(n)−(1−12μ∥u(n)∥2)e(n)]=12∥λ(n)u(n)∥2+λ(n)[(1−μ∥u(n)∥2)e(n)−(1−12μ∥u(n)∥2)e(n)]=12∥λ(n)u(n)∥2+λ(n)[−12μ∥u(n)∥2e(n)]=12λ2(n)∥u(n)∥2−12λ(n)μ∥u(n)∥2e(n)=0{L(n) = \frac{1}{2}\left\| \mathbf{w}(n + 1) - \mathbf{w}(n) \right\|^{2} + \lambda(n)\left\lbrack r(n) - \left( 1 - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) \right\rbrack
}{= \frac{1}{2}\left\| \lambda(n)\mathbf{u}(n) \right\|^{2} + \lambda(n)\left\lbrack \left( 1 - \mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) - \left( 1 - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2} \right)e(n) \right\rbrack
}{= \frac{1}{2}\left\| \lambda(n)\mathbf{u}(n) \right\|^{2} + \lambda(n)\left\lbrack - \frac{1}{2}\mu\left\| \mathbf{u}(n) \right\|^{2}e(n) \right\rbrack
}{= \frac{1}{2}\lambda^{2}(n)\left\| \mathbf{u}(n) \right\|^{2} - \frac{1}{2}\lambda(n)\mu\left\| \mathbf{u}(n) \right\|^{2}e(n) = 0}L(n)=21∥w(n+1)−w(n)∥2+λ(n)[r(n)−(1−21μ∥u(n)∥2)e(n)]=21∥λ(n)u(n)∥2+λ(n)[(1−μ∥u(n)∥2)e(n)−(1−21μ∥u(n)∥2)e(n)]=21∥λ(n)u(n)∥2+λ(n)[−21μ∥u(n)∥2e(n)]=21λ2(n)∥u(n)∥2−21λ(n)μ∥u(n)∥2e(n)=0
故可得:
λ(n)=u(n)e∗(n)\lambda(n) = \mathbf{u}(n)e^{*}(n)λ(n)=u(n)e∗(n)
所以我们再次得到了系数更新规则:
w(n+1)=w(n)+μu(n)e∗(n)\mathbf{w}(n + 1) = \mathbf{w}(n) + \mu\mathbf{u}(n)e^{*}(n)w(n+1)=w(n)+μu(n)e∗(n)
该式和上一节的结论是一致的。因此我们用拉格朗日乘子法得到了同样的最优系数更新规则,这也证明了LMS法在局部是最优的,或者说是约束最优化。
全局次优性
为维纳滤波器相比,LMS算法的相应学习曲线接近一个最终值J(∞)J(\infty)J(∞),J(∞)J(\infty)J(∞)和维纳解下的最小代价JminJ_{\min}Jmin存在一个额外的均方误差,因此和维纳解相比,LMS是次优的:
-
在最速下降法中,在计算学习曲线之前要进行集平均,所以最速下降法的学习曲线在性质上是确定性的。
-
LMS法没有上述的集平均,所以梯度会存在"噪声",因此LMS的学习曲线在性质上是统计的。
梯度自适应格型算法
其实现结构如下图所示:
因为目前应用中该算法结构没有被使用,这里不再展开讨论。
其实随机梯度下降算法还有很多其他的应用,这里不再展开。





)



)




)

)


