目录
Ⅰ.sorted排序
Ⅱ.排序具体的方法
(1)sort的神方法(注意是sort)
(2)sorted的神方法(注意这里是sorted)
常见场景
1. 单关键字排序
2. 多关键字排序
3.按倒序字符串排序:
4.按字典某字段排序:
5.单条件
6.多条件组合:
7.处理 None:
Ⅲ.list和str创建以及tuple元组
Ⅳ.字符串的拼接和for的倒序遍历
Ⅴ.列表的拼接---join的使用:列表list转为字符串
Ⅵ.split()的使用和join通常配合使用
Ⅶ.list的负数访问
Ⅷ.ord和chr函数(非常有用)
1. ord() 函数
2. chr() 函数
Ⅸ.一键实现 十进制转2、8、 16 进制(必须要会)
Ⅹ.一键实现2、 8、 16进制转10进制(同理这个也必须要会)
Ⅰ.sorted排序
》列表排序---segs=[[1, 4], [3, 6], [5, 7]]
(1)普通的简单方法:
s = sorted(segs)---(默认情况升序,值为False)
降序---s = sorted(segs, reverse=True)
默认排序规则:当不指定 key 参数时,sorted() 会使用默认的排序规则。对于列表中的子列表,Python 会按字典序进行比较:
-
先比较每个子列表的第一个元素,
-
如果第一个元素相等,再比较第二个元素,以此类推。
(2)带有lambda表达式的key方法:
s=sortef(segs,key=lambda x:x[0])
特别注意:字符也能进行排序

Ⅱ.排序具体的方法

(1)sort的神方法(注意是sort)
def var(x): print(f"处理: {x}") return x
N = [3, 1, 2]
N.sort(key=var) # 输出: # 处理: 3 # 处理: 1 # 处理: 2
print(N) # [1, 2, 3]为啥 var 不用带参数:
-
key=var 的写法:
-
sort() 会自动把列表中的每个元素传给 var 函数。
-
你写 key=var(不加括号),是把函数本身传给 sort(),而不是调用它。
-
sort() 内部会循环调用 var(x),x 是 N 中的每个元素。
-
-
不需要显式参数:
-
sort() 知道要对 N 的每个元素应用 var,所以你只定义 var(x) 的逻辑,sort() 负责传参。
-
-
错误写法:N.sort(key=var())
-
这会立刻调用 var(),但 var 需要一个参数,报错 TypeError: var() missing 1 required positional argument: 'x'。
-
-
正确写法:N.sort(key=var)
-
传函数名,sort() 自动处理。
-
(2)sorted的神方法(注意这里是sorted)
def var(x):print(f"处理: {x}")return xN = [3, 1, 2]
M = sorted(N, key=var)
# 输出:
# 处理: 3
# 处理: 1
# 处理: 2
print(M) # [1, 2, 3]
print(N) # [3, 1, 2](原列表不变)》明白了其实key里面就是对数组里的x进行统一的变化,比如x%10,x//10,甚至有a=sorted(a,key=lambda x:(var(x),x))
-
sorted(iterable, key=None, reverse=False):
-
iterable:要排序的对象(列表、元组等)。
-
key:一个函数,定义排序依据。
-
reverse:是否降序。
-
返回:新的排序后的列表。
-
-
lambda:
-
匿名函数,写法是 lambda 参数: 表达式。
-
在 sorted() 中,lambda 定义怎么比较每个元素。
-
常见场景
-
用 lambda 按绝对值排序:
a = [-3, 2, -1] b = sorted(a, key=lambda x: abs(x)) print(b) # [-1, 2, -3] -
降序:
a = [3, 1, 2] b = sorted(a, key=lambda x: x, reverse=True) print(b) # [3, 2, 1]
1. 单关键字排序
-
按最后一位数字排序:
a = [13, 25, 31] b = sorted(a, key=lambda x: x % 10) print(b) # [31, 13, 25](1, 3, 5) -
按字符串长度:
a = ['cat', 'elephant', 'dog'] b = sorted(a, key=lambda x: len(x)) print(b) # ['cat', 'dog', 'elephant']
2. 多关键字排序
-
用元组:lambda 返回元组,按元素顺序比较。
-
例子:按 (主关键字, 次关键字) 排序:
pairs = [(1, 3), (2, 1), (1, 2)] b = sorted(pairs, key=lambda x: (x[0], x[1])) print(b) # [(1, 2), (1, 3), (2, 1)]
3.按倒序字符串排序:
a = ['cat', 'dog', 'bat'] b = sorted(a, key=lambda x: x[::-1]) print(b) # ['dog', 'bat', 'cat'] #反转后的字符串是:'tac'、'god'、'tab'然后进行排序
4.按字典某字段排序:
data = [{'name': 'cat', 'age': 3}, {'name': 'dog', 'age': 2}] b = sorted(data, key=lambda x: x['age']) print(b) # [{'name': 'dog', 'age': 2}, {'name': 'cat', 'age': 3}]
5.单条件
a = [ -2,1,3, -4] b = sorted(a, key=lambda x: x if x > 0 else -x) print(b) # [1,-2, 3, -4] #把所有数字映射成“正数形式”,但保留正负信息,最终排序按照正数排但显示最初的值
6.多条件组合:
a = ['cat', 'dog', 'elephant'] b = sorted(a, key=lambda x: (len(x), x)) # 先长度,再字典序 print(b) # ['cat', 'dog', 'elephant']
7.处理 None:
a = [1, None, 3] b = sorted(a, key=lambda x: (x is None, x)) print(b) # [None, 1, 3]
Ⅲ.list和str创建以及tuple元组
》tuple元组化:
![]()
》list和str创建:
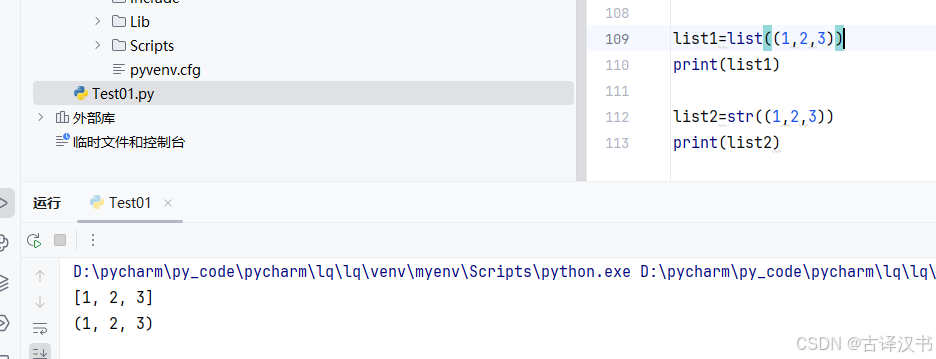
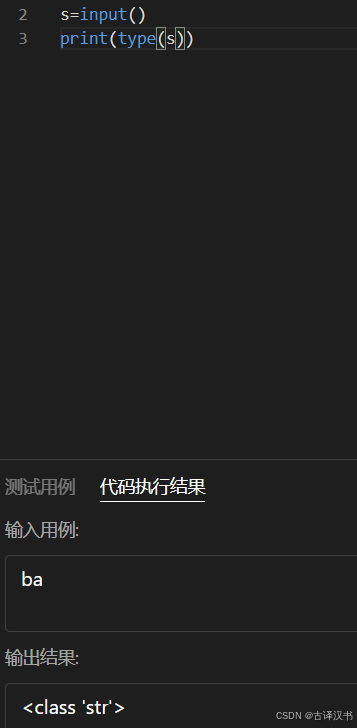
》默认情况下,输入的就是字符串类型
Ⅳ.字符串的拼接和for的倒序遍历
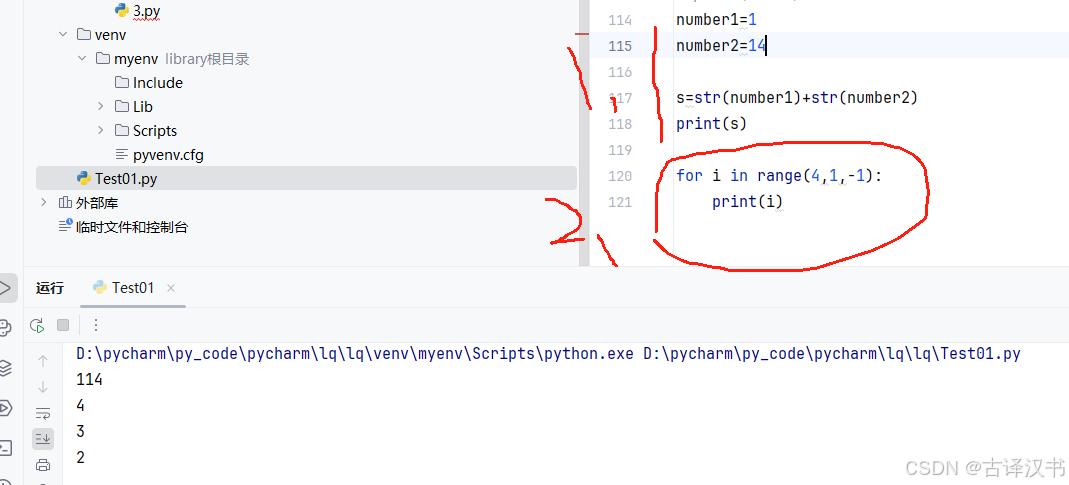
Ⅴ.列表的拼接---使得默认下标从1开始引入元素
join的使用:列表list转为字符串
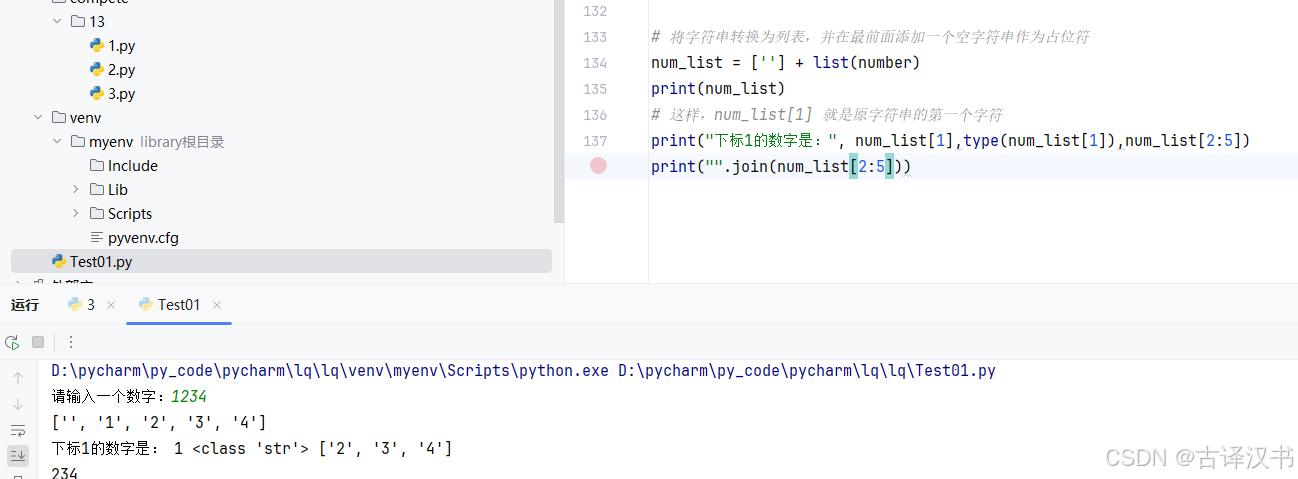
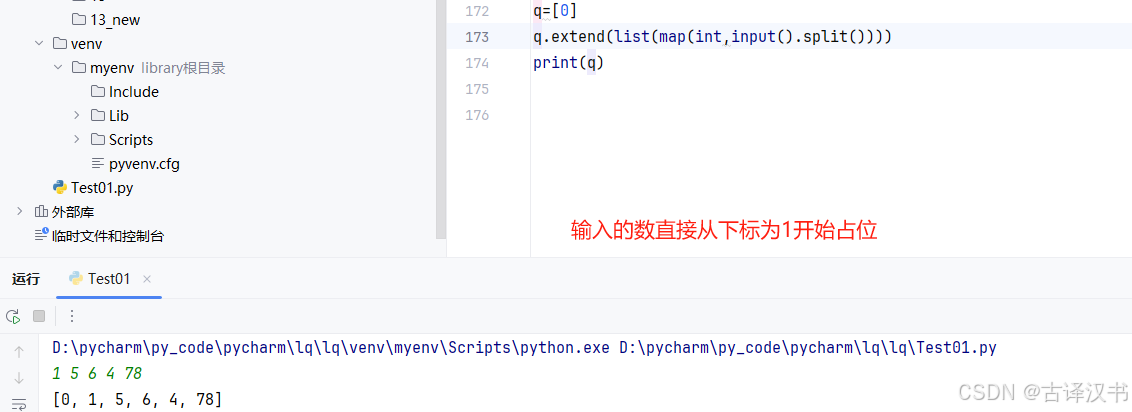
或者另一个方法

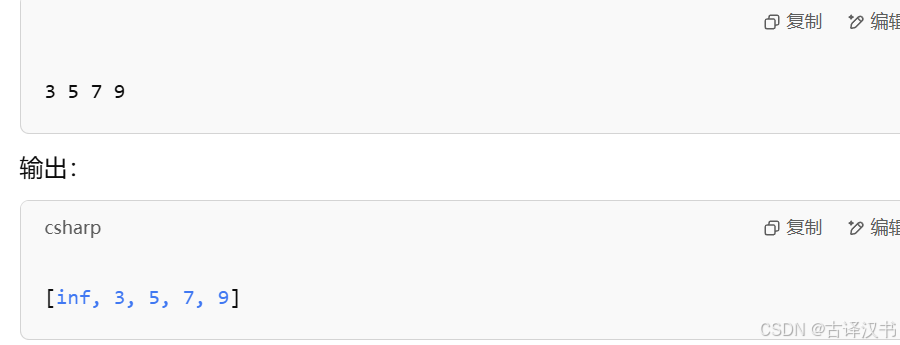
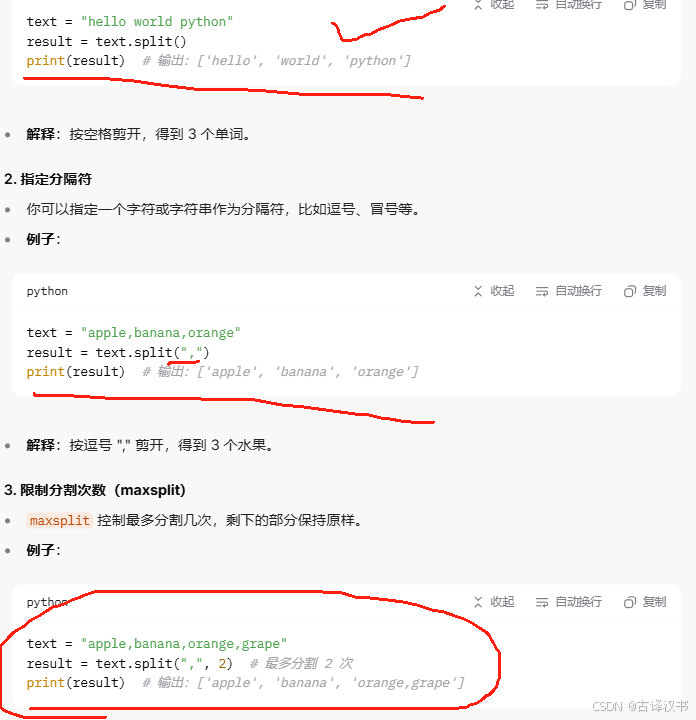
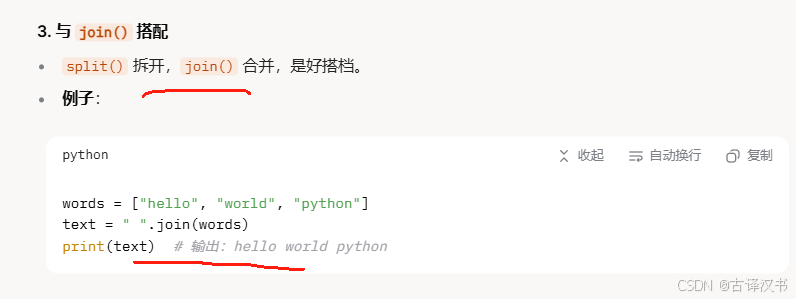
Ⅵ.split()的使用和join通常配合使用
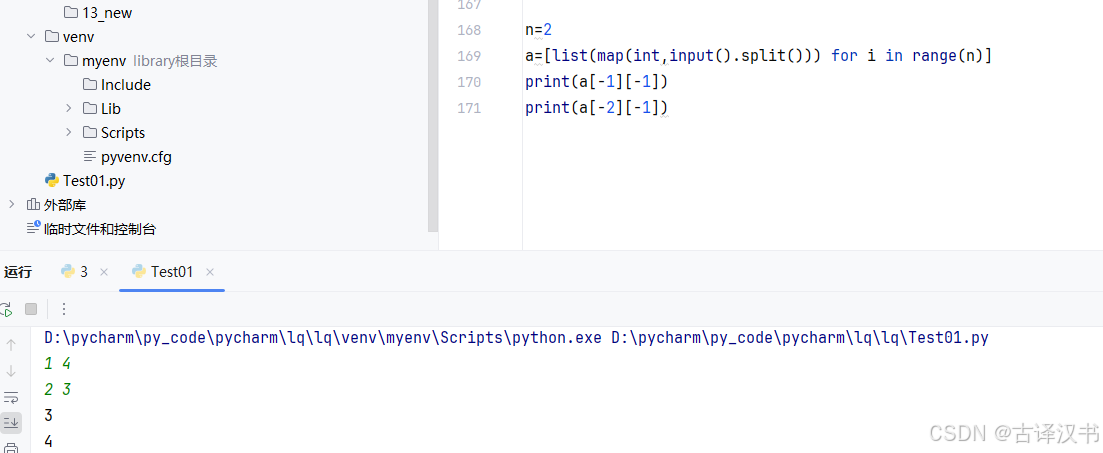
Ⅶ.list的负数访问
Ⅷ.ord和chr函数(非常有用)
1. ord() 函数
ord() 函数用于获取一个字符的 Unicode 码点(整数表示)。
语法
ord(c)
参数
c:一个长度为 1 的字符串(即单个字符)。
返回值
返回字符 c 的 Unicode 码点(整数)。
print(ord('A')) # 输出:65
print(ord('a')) # 输出:97
print(ord('中')) # 输出:20013
2. chr() 函数
chr() 函数用于将一个 Unicode 码点(整数)转换为对应的字符。
语法
chr(i)
参数
i:一个整数,表示 Unicode 码点(范围:0 到 1114111)。
返回值
返回 Unicode 码点 i 对应的字符。
print(chr(65)) # 输出:A
print(chr(97)) # 输出:a
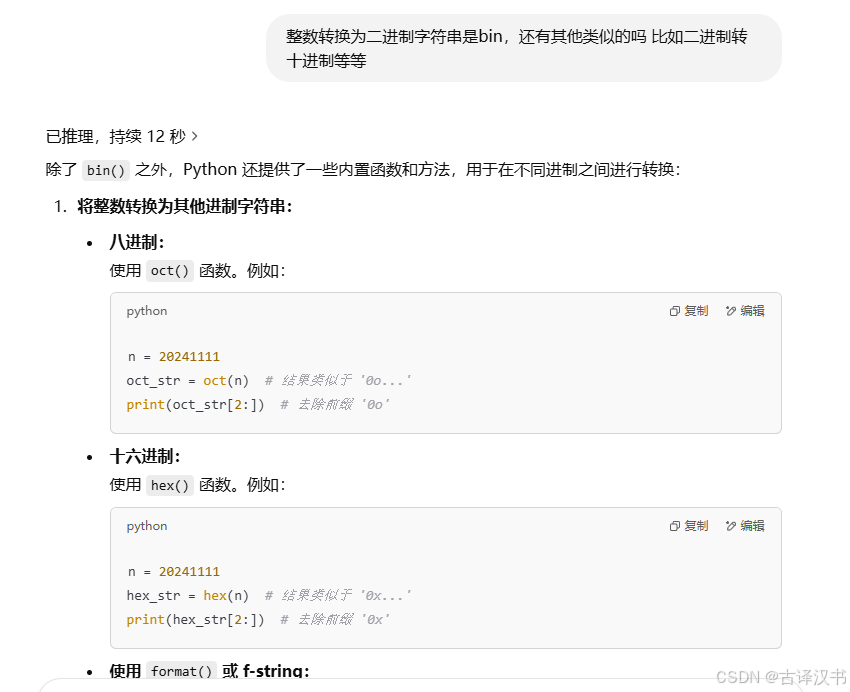
print(chr(20013)) # 输出:中Ⅸ.一键实现 十进制转2、8、 16 进制(必须要会)
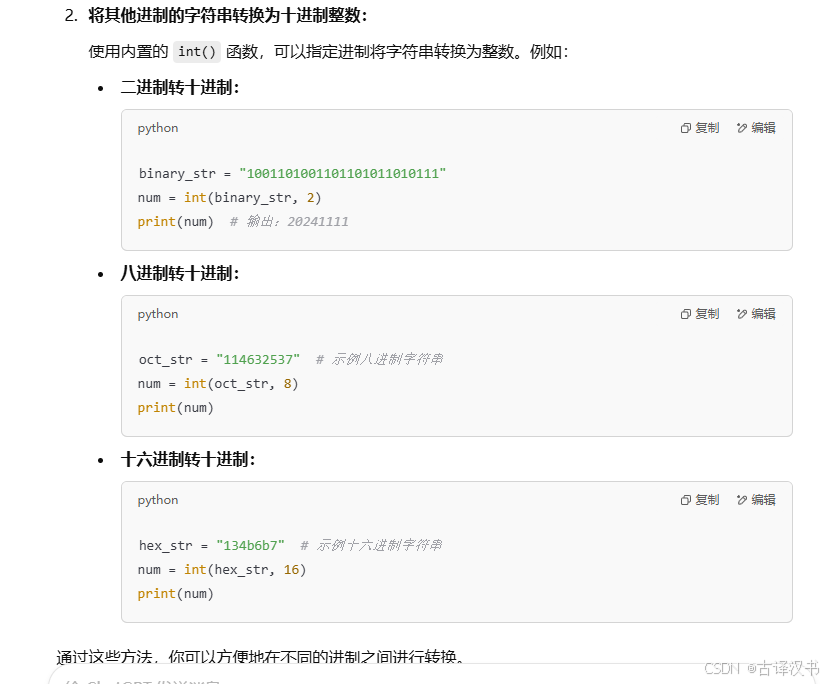
Ⅹ.一键实现2、 8、 16进制转10进制(同理这个也必须要会)














—— IOT 设备 OTA 升级方案)

)
)

