目录
1. 什么是 Alluxio?
2. Alluxio 的诞生背景:为什么需要数据编排层?
痛点 1:计算与存储强耦合,适配成本高
痛点 2:跨集群 / 跨云数据移动效率低
痛点 3:数据访问延迟高,缓存机制碎片化
3. Alluxio 的架构设计:分层解耦,弹性扩展
3.1 核心组件详解
(1)主节点(Master):元数据管理中心
(2)从节点(Worker):数据存储与服务节点
(3)客户端(Client):计算框架的对接入口
(4)底层存储(Under Storage):数据持久化层
3.2 架构分层图
3.3 核心数据流程:以 “读取 S3 数据” 为例
4. Alluxio 解决的核心问题:直击大数据架构痛点
问题 1:打破数据孤岛,实现统一数据访问
问题 2:降低数据访问延迟,提升计算效率
问题 3:减少跨存储 / 跨云数据移动,节省带宽成本
问题 4:解耦计算与存储,提升架构弹性
5. Alluxio 的关键特性:为什么它能成为数据编排首选?
特性 1:内存优先的多级存储(Tiered Storage)
特性 2:兼容 HDFS API,零成本迁移
特性 3:强一致性与高可用
特性 4:云原生友好,支持弹性扩缩容
特性 5:跨云 / 跨集群数据管理
特性 6:细粒度的缓存与权限控制
特性 7:丰富的监控与诊断工具
6. Alluxio 与同类产品对比:它的差异化优势在哪里?
7. Alluxio 的使用方法:从部署到集成 Spark 实操
7.1 环境准备
7.2 集群部署(3 节点:1 Master + 2 Worker)
7.3 集成 Spark 读取 Alluxio 数据
7.4 常用命令行工具
8.总结与最佳实践
参考资料:
Alluxio是当今大数据和人工智能领域最具创新性的数据编排平台之一,它通过独特的架构设计解决了计算与存储分离带来的性能瓶颈,成为云原生和存算分离架构的关键组件。作为位于计算框架与底层存储之间的中间层,Alluxio提供统一的API接口和全局命名空间,将数据从存储层移动到更接近计算应用的位置,显著加速数据访问 。在AI训练场景中,Alluxio可将模型训练速度提高20倍,模型服务速度提高10倍,同时将GPU利用率提升至90%以上,成为企业构建高效AI基础设施的首选技术。
1. 什么是 Alluxio?
Alluxio 的官方定义是:面向云原生和大数据场景的开源分布式数据编排系统(Data Orchestration Platform),它在计算框架(如 Spark、Flink)和底层存储系统(如 HDFS、S3、OSS、HBase)之间搭建了一层 “数据中间层”,核心作用是统一数据访问入口、加速数据流转、打破数据孤岛。
更通俗地说:如果把大数据架构比作 “物流网络”,计算框架是 “快递公司”(负责处理数据),底层存储是 “仓库”(负责存放数据),那么 Alluxio 就是 “物流调度中心 + 高速中转站”—— 它统一管理所有 “仓库” 的地址(统一命名空间),让 “快递公司” 不用逐个对接 “仓库”;同时通过缓存高频数据(如内存、SSD),让 “快递运输”(数据读取)速度提升 10 倍甚至 100 倍。
关键标签:
- 开源协议:Apache License 2.0
- 核心定位:数据编排层(Data Orchestration Layer)
- 关键能力:统一数据访问、多级缓存加速、跨存储 / 跨云兼容
2. Alluxio 的诞生背景:为什么需要数据编排层?
Alluxio 诞生于 2013 年,由加州大学伯克利分校 AMP 实验室(Apache Spark、Apache Mesos 的发源地)发起,创始人是李浩源(Haoyuan Li)。它的出现,本质是为了解决大数据发展中 “计算 - 存储分离” 带来的三大核心痛点:
痛点 1:计算与存储强耦合,适配成本高
早期大数据架构(如 Hadoop 1.x)是 “计算 + 存储一体化”(MapReduce+HDFS),但随着场景升级,计算框架逐渐多样化(Spark、Flink、Presto),存储系统也走向异构(HDFS、S3、OSS、Azure Blob)。此时,每个计算框架都需要单独适配不同的存储接口(如 Spark 对接 S3 要写 s3a 协议,对接 HDFS 要写 hdfs 协议),开发和维护成本急剧上升。
痛点 2:跨集群 / 跨云数据移动效率低
企业数据往往分散在多个存储系统中(如本地 HDFS 存离线数据,S3 存云端热数据),当计算框架需要跨存储读取数据时,只能通过 “全量拷贝”(如用distcp从 HDFS 拷贝到 S3),不仅耗时(TB 级数据可能需要数小时),还会占用大量网络带宽,导致 “数据不动,计算空等”。
痛点 3:数据访问延迟高,缓存机制碎片化
大数据计算中,高频访问的数据(如机器学习训练的样本数据、实时分析的热点表)如果每次都从远端存储(如 S3)读取,会产生很高的网络延迟(毫秒级甚至秒级)。而不同计算框架的缓存机制(如 Spark 的 RDD 缓存、Flink 的 State Backend)是孤立的,无法共享缓存数据,导致资源浪费和重复读取。
正是这些痛点,催生了 Alluxio—— 它通过 “统一抽象 + 全局缓存”,让计算框架与存储系统解耦,同时实现数据的 “一次加载,多次复用”。
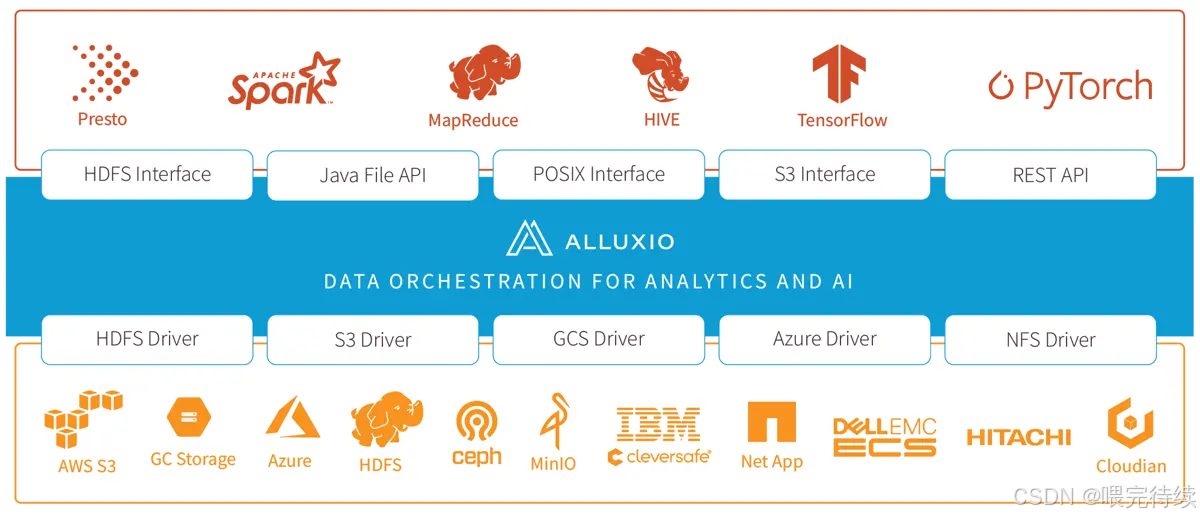
3. Alluxio 的架构设计:分层解耦,弹性扩展
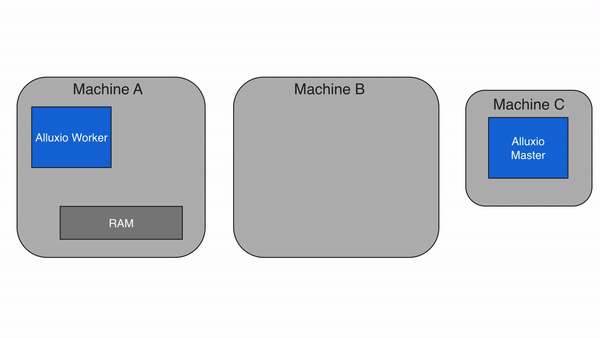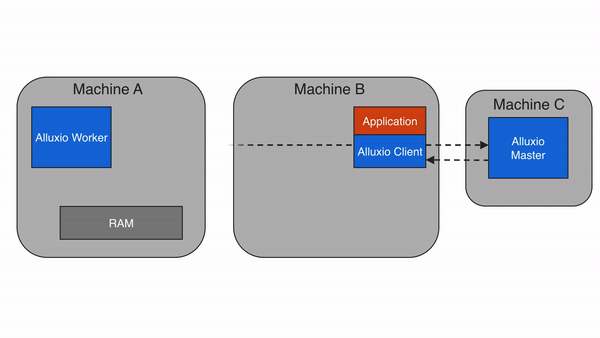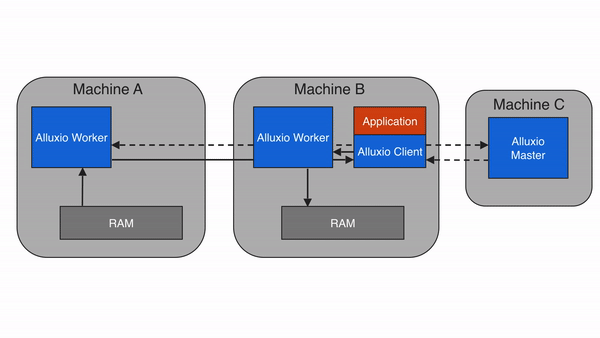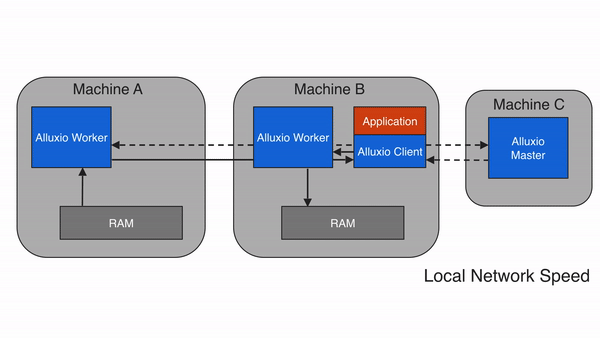
Alluxio 采用主从架构(Master-Worker),配合客户端(Client)和底层存储(Under Storage),形成四层结构(客户端层、主节点层、从节点层、存储层)。这种设计的核心是 “元数据与数据分离”——Master 只管理元数据(如文件路径、权限、块位置),Worker 负责存储数据块和提供读写服务,确保架构轻量、高效、可扩展。
3.1 核心组件详解
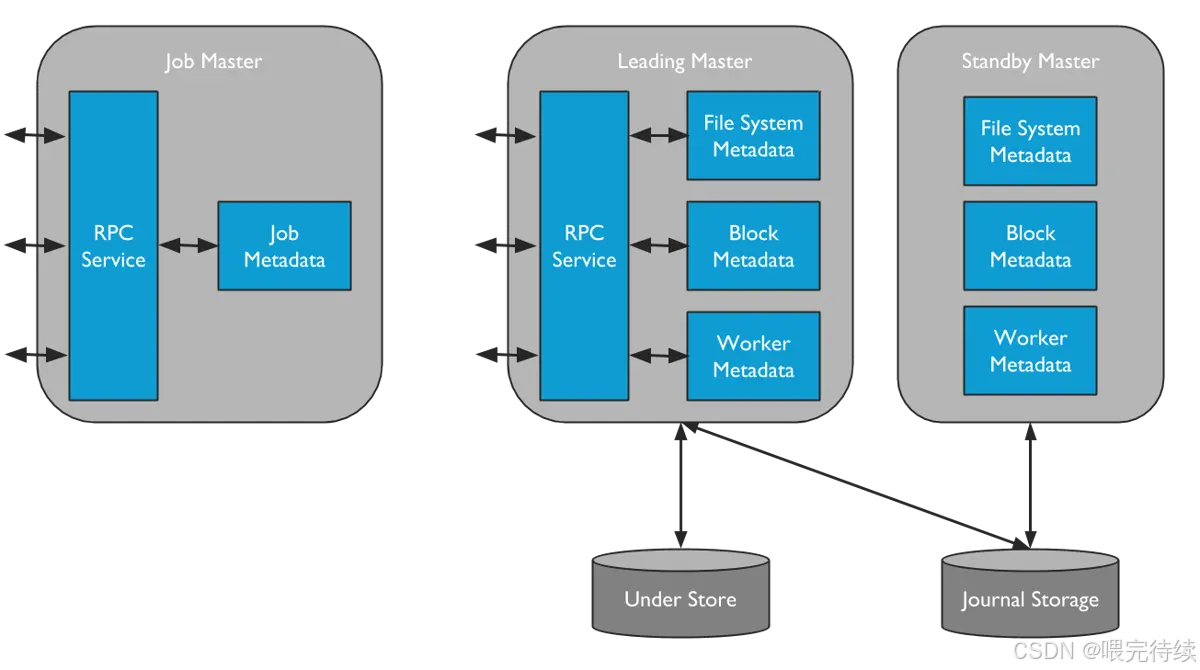
(1)主节点(Master):元数据管理中心
Master 是 Alluxio 的 “大脑”,主要负责元数据管理和集群协调,不存储实际数据块。核心功能包括:
- 元数据管理:维护文件系统的命名空间(如目录、文件、块的层级关系)、文件权限、块与 Worker 的映射关系;
- 块管理:负责数据块的分配(如将块分配给哪个 Worker)、复制(保证数据可靠性)、回收(淘汰冷数据);
- 集群管理:监控 Worker 的健康状态(如心跳检测)、处理 Worker 的加入 / 退出;
- 高可用(HA):支持多 Master 部署(1 个 Active Master + 多个 Standby Master),通过 Journal 日志(记录元数据变更)实现故障切换,避免单点故障。
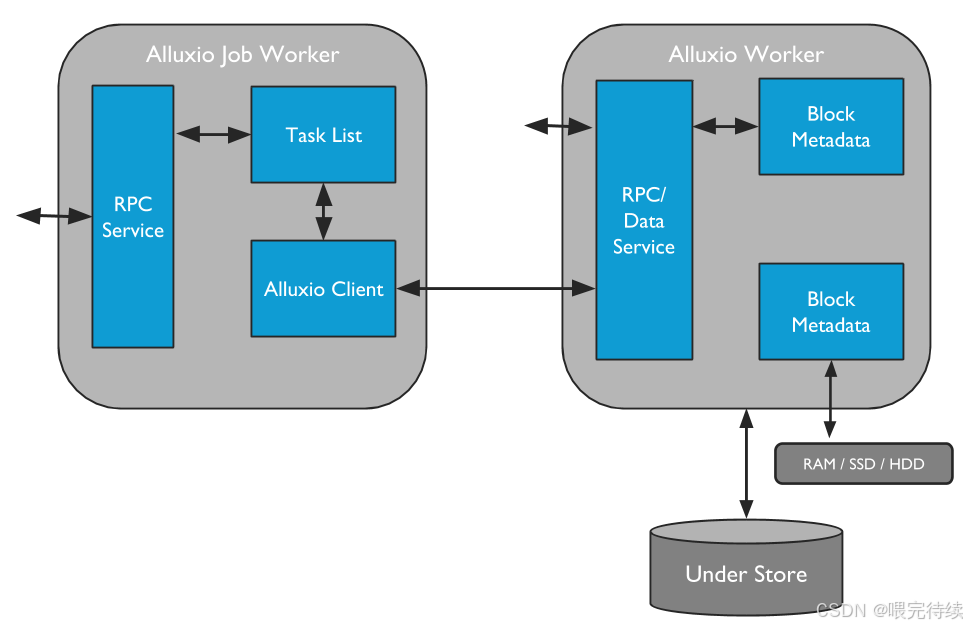
(2)从节点(Worker):数据存储与服务节点
Worker 是 Alluxio 的 “手脚”,部署在计算节点或存储节点上,负责实际数据块的存储、读取和写入。核心功能包括:
- 块存储:通过 “多级存储(Tiered Storage)” 存储数据块,支持内存(DRAM)、SSD、HDD、NVMe 等介质,优先将高频数据存放在高速介质(如内存)中;
- 数据服务:响应客户端的读写请求(如读取块、写入块),并与底层存储交互(如下载数据到本地缓存、将数据持久化到底层存储);
- 缓存管理:基于 LRU(最近最少使用)等策略淘汰冷数据,释放存储空间;
- 心跳汇报:定期向 Master 汇报自身状态(如可用存储空间、当前存储的块列表)。
(3)客户端(Client):计算框架的对接入口
Client 是计算框架(Spark、Flink 等)与 Alluxio 交互的 “桥梁”,提供文件系统 API(兼容 HDFS API)和 SDK(Java、Python、Go 等)。核心功能包括:
- 元数据操作:向 Master 发起目录创建、文件删除、元数据查询等请求;
- 数据读写:向 Worker 发起数据块的读写请求,本地缓存元数据(减少与 Master 的交互);
- 协议适配:自动适配底层存储的协议(如 S3、HDFS、OSS),计算框架无需感知底层存储差异。
(4)底层存储(Under Storage):数据持久化层
Alluxio 本身不负责数据的长期持久化(Worker 的缓存是临时的),底层存储是数据的 “最终归宿”,支持几乎所有主流存储系统:
- 分布式文件系统:HDFS、MapR FS;
- 对象存储:AWS S3、阿里云 OSS、腾讯云 COS、Azure Blob;
- 数据库:HBase、Cassandra;
- 本地文件系统:Linux Local FS。
Alluxio 通过 “挂载(Mount)” 机制将底层存储接入统一命名空间(如将 S3 的bucket1挂载到 Alluxio 的/s3data目录),实现对多存储系统的统一管理。
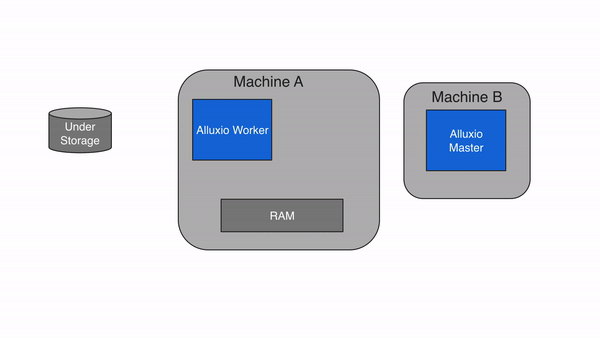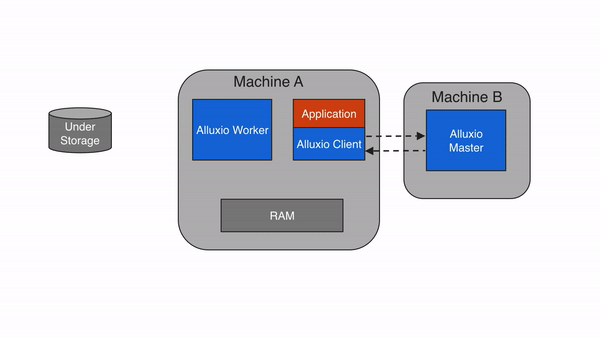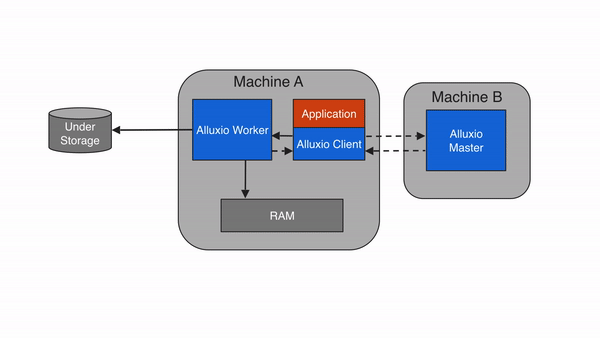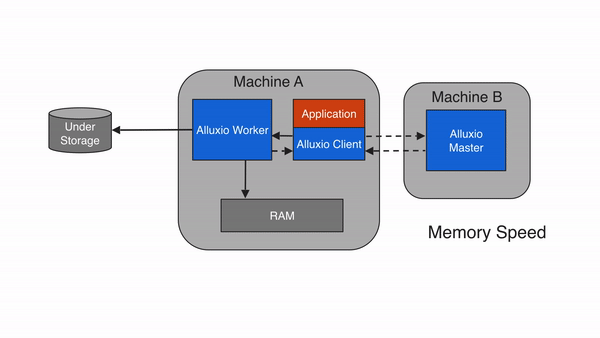
3.2 架构分层图
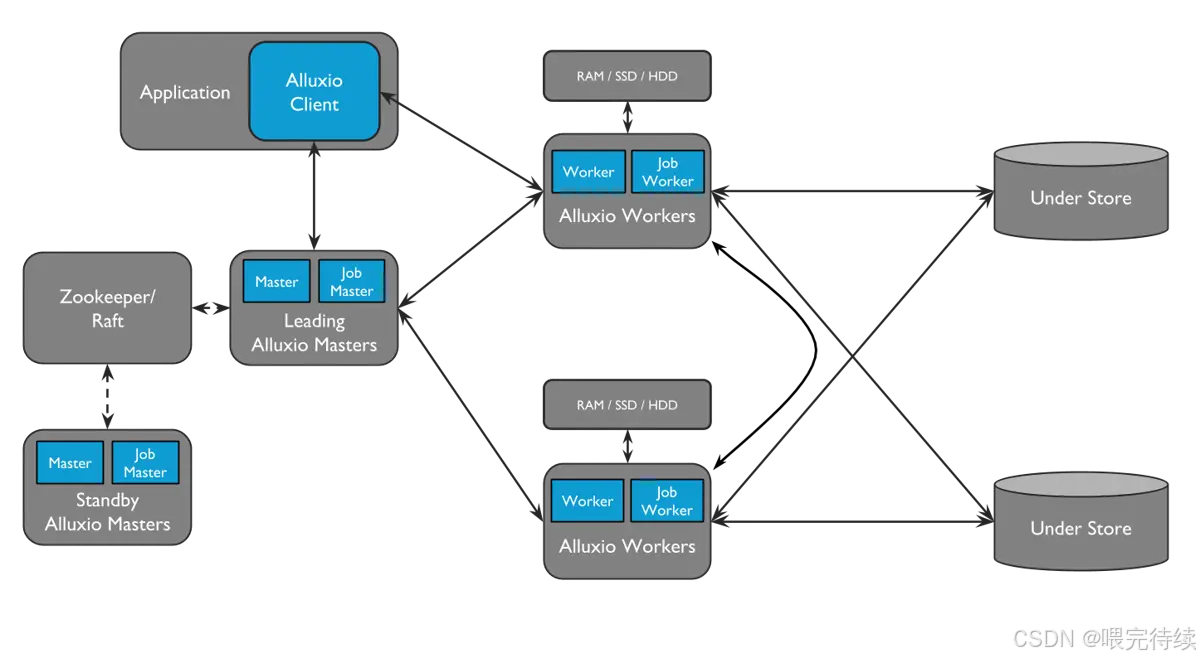
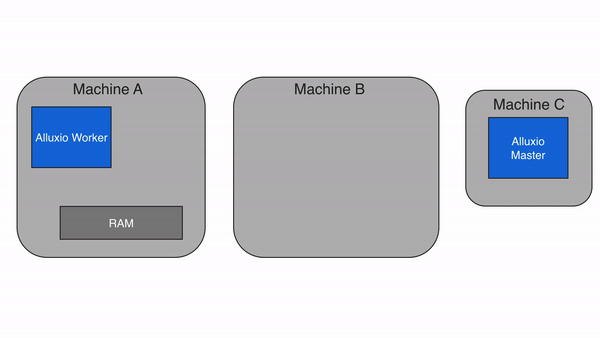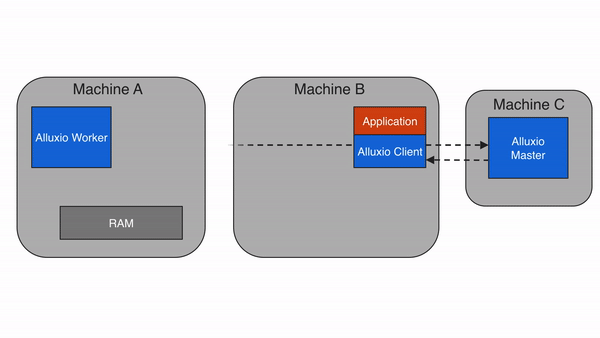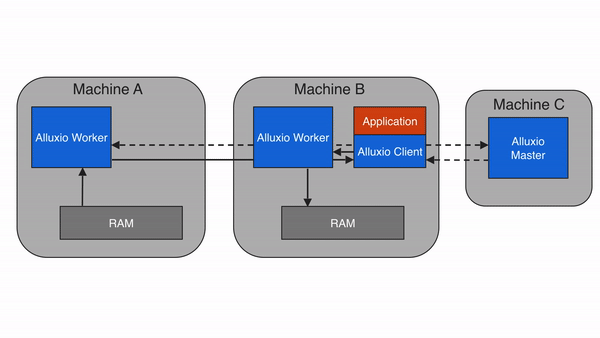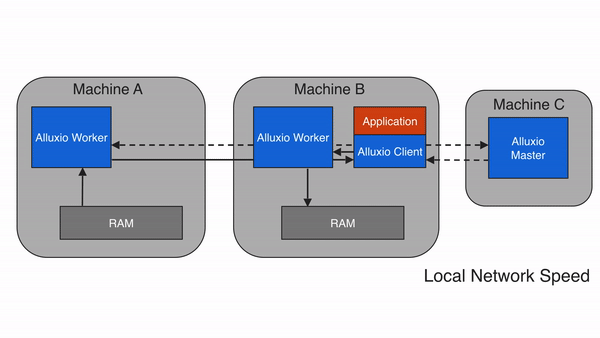
3.3 核心数据流程:以 “读取 S3 数据” 为例
- 客户端(如 Spark)向 Alluxio Master 发起请求:“读取/s3data/user.csv文件”;
- Master 查询元数据,发现该文件对应的块分散在 Worker 1 和 Worker 2 的缓存中(若未缓存,则返回底层存储 S3 的地址);
- Master 将块的位置信息返回给客户端;
- 客户端直接向 Worker 1 和 Worker 2 读取数据块(无需经过 Master,减少转发开销);
- 若 Worker 中无缓存块,Worker 会先从 S3 下载数据块到本地缓存,再返回给客户端(下次读取直接用缓存)。
4. Alluxio 解决的核心问题:直击大数据架构痛点
基于上述架构,Alluxio 精准解决了大数据场景中的四大核心问题:
问题 1:打破数据孤岛,实现统一数据访问
通过 “统一命名空间”,Alluxio 将多个底层存储系统(如 HDFS、S3、OSS)挂载到同一个目录树下,计算框架只需通过 Alluxio 的路径(如alluxio://master:19998/s3data/user.csv)即可访问任意存储的数据,无需关注数据实际存放在哪里。
价值:开发人员无需为不同存储编写不同的访问代码,运维人员无需管理多套存储的访问权限,降低了跨存储数据管理的复杂度。
问题 2:降低数据访问延迟,提升计算效率
通过 “多级缓存”(内存→SSD→HDD),Alluxio 将高频访问的数据缓存到靠近计算节点的高速介质中,避免每次都从远端存储(如 S3)读取。根据官方测试,缓存命中时,数据读取延迟可从 “秒级” 降至 “毫秒级”,Spark 作业执行速度提升 3-10 倍。
价值:实时计算(如 Flink 流处理)、机器学习训练(如 TensorFlow)等对延迟敏感的场景,可大幅提升吞吐和响应速度。
问题 3:减少跨存储 / 跨云数据移动,节省带宽成本
当计算需要跨存储读取数据时(如 Spark 读取 S3 数据后写入 HDFS),Alluxio 会先将数据缓存到本地 Worker,后续计算直接复用缓存,无需重复从 S3 下载。此外,Alluxio 支持 “数据预加载”(提前将冷数据缓存到 Worker),避免计算时等待数据下载。
价值:减少跨云 / 跨集群的网络传输量(最高可减少 90%),降低带宽成本,同时避免 “计算空等数据” 的情况。
问题 4:解耦计算与存储,提升架构弹性
Alluxio 作为中间层,隔离了计算框架和底层存储的依赖关系:计算框架只需适配 Alluxio API,无需适配不同存储的协议;底层存储可以独立升级或替换(如从 HDFS 迁移到 S3),无需修改计算代码。
价值:大数据架构的灵活性大幅提升,支持 “计算弹性扩缩容” 和 “存储独立演进”,更适配云原生场景。
5. Alluxio 的关键特性:为什么它能成为数据编排首选?
Alluxio 的核心竞争力源于其七大关键特性,这些特性让它在数据编排领域脱颖而出:
特性 1:内存优先的多级存储(Tiered Storage)
- 能力:支持内存、SSD、HDD、NVMe 等多种存储介质,可配置不同介质的优先级(如内存优先),自动将高频数据迁移到高速介质,冷数据下沉到低速介质;
- 场景:实时分析、机器学习训练等需要低延迟数据访问的场景;
- 优势:平衡性能与成本,既利用内存的高速特性,又通过 HDD 存储大量冷数据。
特性 2:兼容 HDFS API,零成本迁移
- 能力:Alluxio 的文件系统 API 完全兼容 HDFS API(如FileSystem接口),现有基于 HDFS 开发的应用(如 Spark、Hive)无需修改代码,只需将hdfs://协议替换为alluxio://即可接入;
- 场景:从 Hadoop 架构向 “计算 - 存储分离” 架构迁移的场景;
- 优势:迁移成本极低,无需重构现有应用。
特性 3:强一致性与高可用
- 能力:
强一致性:元数据变更通过 Journal 日志同步,确保所有客户端看到一致的文件系统状态; 高可用:支持多 Master 部署(Active/Standby),Journal Node 集群存储元数据日志,故 障切换时间 < 30 秒;
- 场景:金融、电商等对数据一致性和系统可用性要求高的场景;
- 优势:避免数据不一致导致的业务错误,保障系统稳定运行。
特性 4:云原生友好,支持弹性扩缩容
- 能力:
支持 Kubernetes 部署(通过 Alluxio Operator),可动态创建 / 删除 Worker Pod;
支持自动扩缩容(根据存储使用率、CPU 负载触发扩缩容);
- 场景:云原生大数据平台(如 EKS、ACK 上的 Spark/Flink 集群);
- 优势:适配云环境的弹性特性,按需分配资源,降低运维成本。
特性 5:跨云 / 跨集群数据管理
- 能力:支持挂载不同云厂商的存储(如 AWS S3、阿里云 OSS、Azure Blob),实现跨云数据统一访问;同时支持跨 Alluxio 集群的数据复制(如将北京集群的缓存数据同步到上海集群);
- 场景:多云部署、异地灾备的企业;
- 优势:打破云厂商锁定,简化跨云数据管理。
特性 6:细粒度的缓存与权限控制
- 能力:
缓存策略:支持按文件、目录配置缓存规则(如/hotdata目录的文件全部缓存到内存),支 持 TTL(过期时间)淘汰;
权限控制:兼容 POSIX 权限模型,支持集成 LDAP、Kerberos 进行身份认证;
- 场景:多租户共享的大数据平台;
- 优势:精细化管理缓存资源和数据访问权限,保障数据安全。
特性 7:丰富的监控与诊断工具
- 能力:
内置 Web UI(默认端口 19999),展示集群状态、元数据信息、缓存命中率;
支持集成 Prometheus+Grafana 监控关键指标(如缓存命中率、读写延迟、Worker 使用 率);
提供日志分析工具(Alluxio Log Analyzer),快速定位问题;
- 场景:大规模集群的运维监控;
- 优势:实时掌握集群运行状态,快速排查故障,降低运维难度。
6. Alluxio 与同类产品对比:它的差异化优势在哪里?
在分布式缓存和数据中间层领域,Alluxio 常被与 Apache Ignite、Redis(分布式缓存场景)、HDFS(作为中间层时)对比。下面从核心定位、适用场景、关键能力三个维度进行对比,帮助大家选择:
| 特性 | Alluxio | Apache Ignite | Redis(分布式缓存) | HDFS(作为中间层) |
| 核心定位 | 数据编排平台(连接计算与多存储) | 内存计算平台(计算 + 存储一体化) | 分布式缓存 / 键值数据库 | 分布式文件系统(存储层) |
| 支持存储介质 | 内存、SSD、HDD、NVMe(多级) | 内存、SSD、HDD(多级) | 内存(主要)、SSD(持久化) | HDD、SSD(主要) |
| 统一数据访问 | 支持多存储(S3/OSS/HDFS 等)挂载 | 支持部分存储集成(HDFS/S3) | 不支持(需手动对接存储) | 仅支持自身,不支持其他存储 |
| 计算框架集成 | 无缝集成 Spark/Flink/Presto 等 | 支持集成 Spark/Flink,但需适配 | 需通过 API 集成,适配成本高 | 原生集成 Hadoop 生态,但扩展性差 |
| 高可用 | 支持多 Master+Journal Node | 支持分区副本,无专门 Master HA | 支持主从复制、哨兵模式 | 支持 NameNode HA |
| 适用场景 | 跨存储数据加速、统一数据访问 | 内存计算、实时分析 | 高频小数据缓存(如会话、热点 key) | 大规模数据持久化存储 |
| 差异化优势 | 解耦计算与多存储,跨云能力强 | 计算与存储结合,适合内存密集计算 | 低延迟、高吞吐,适合小数据缓存 | 成熟稳定,适合大规模持久化 |
结论:
- 若需统一管理多存储系统、跨云数据加速,Alluxio 是最佳选择;
- 若需内存密集型计算(如实时 OLAP),Apache Ignite 更合适;
- 若需高频小数据缓存(如业务系统的热点数据),Redis 更高效;
- 若仅需单一存储的持久化,HDFS 仍是经典方案。
7. Alluxio 的使用方法:从部署到集成 Spark 实操
下面以 “Alluxio 2.9.0 版本” 为例,带大家完成从环境准备、集群部署到集成 Spark 的实操步骤(基于 Linux 环境)。
7.1 环境准备
前置依赖
- JDK 1.8+(推荐 JDK 11);
- 集群节点间 SSH 免密登录;
- 底层存储(本文以 HDFS 为例,需提前部署 HDFS 集群);
- (可选)Kubernetes 环境(若需容器化部署)。
下载 Alluxio 安装包
从官网下载二进制包:
# 下载2.9.0版本(Hadoop 3.3兼容版)
wget https://downloads.alluxio.io/downloads/files/2.9.0/alluxio-2.9.0-bin-hadoop-3.3.tar.gz
# 解压
tar -zxvf alluxio-2.9.0-bin-hadoop-3.3.tar.gz
cd alluxio-2.9.07.2 集群部署(3 节点:1 Master + 2 Worker)
步骤 1:配置环境变量
编辑conf/alluxio-env.sh,设置 JDK 路径和 HDFS 配置:
# 复制模板
cp conf/alluxio-env.sh.template conf/alluxio-env.sh
# 编辑配置
vi conf/alluxio-env.sh添加以下内容:
export JAVA_HOME=/usr/local/jdk11 # 你的JDK路径
export ALLUXIO_MASTER_HOSTNAME=master # Master节点主机名
export ALLUXIO_UNDERFS_ADDRESS=hdfs://hdfs-master:9000/alluxio # 底层HDFS路径(需提前创建)
export ALLUXIO_WORKER_MEMORY_SIZE=4GB # Worker内存缓存大小
export ALLUXIO_WORKER_TIERED_STORAGE_LEVELS=1 # 1级存储(仅内存,如需SSD可配置多级)步骤 2:配置 Worker 节点列表
编辑conf/workers,添加 Worker 节点主机名:
worker1
worker2步骤 3:分发安装包到所有节点
# 假设Master节点已免密登录Worker节点
./bin/alluxio-copy-ssh-id.sh worker1
./bin/alluxio-copy-ssh-id.sh worker2
# 分发安装包
for node in worker1 worker2; doscp -r alluxio-2.9.0 $node:/opt/
done步骤 4:格式化与启动集群
# 在Master节点执行格式化(仅首次启动需执行)
./bin/alluxio format
# 启动集群
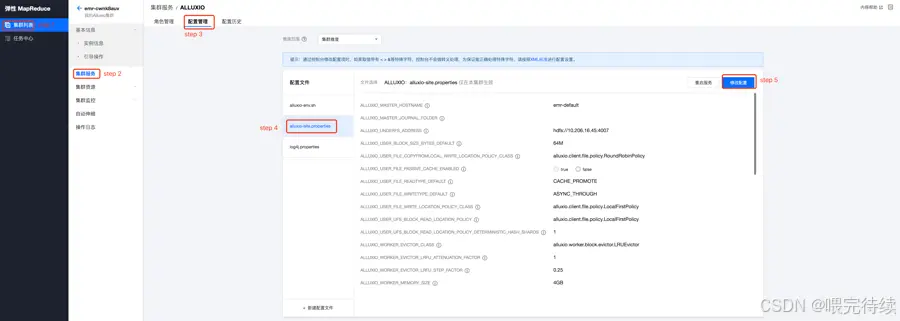
./bin/alluxio-start.sh all步骤 5:验证集群状态
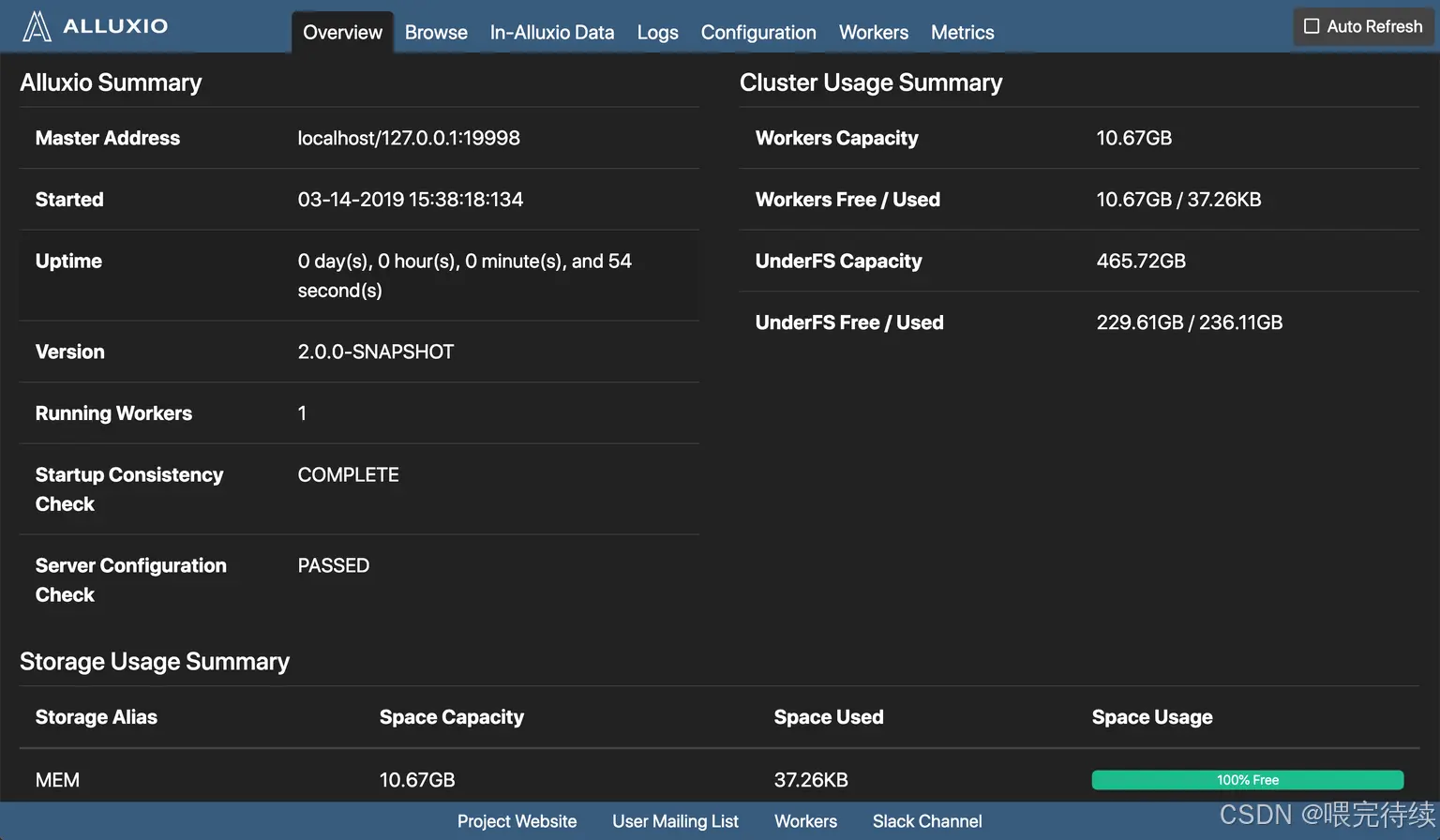
- 访问 Master Web UI:http://master:19999,查看集群状态(Worker 数量、缓存使用率等);
- 执行命令行测试:
# 创建目录
./bin/alluxio fs mkdir /test
# 上传本地文件到Alluxio(自动持久化到HDFS)
./bin/alluxio fs copyFromLocal ./LICENSE /test/
# 查看文件信息(确认块已缓存)
./bin/alluxio fs ls /test/LICENSE
7.3 集成 Spark 读取 Alluxio 数据
步骤 1:配置 Spark 依赖
将 Alluxio 客户端 JAR 包复制到 Spark 的jars目录(或通过--jars指定):
cp $ALLUXIO_HOME/client/alluxio-client-hadoop-3.3-2.9.0.jar $SPARK_HOME/jars/步骤 2:编写 Spark 作业(Scala 示例)
import org.apache.spark.sql.SparkSessionobject AlluxioSparkDemo {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("AlluxioSparkDemo").master("yarn") // 或local[*].getOrCreate()// 读取Alluxio中的文件(协议为alluxio://)val df = spark.read.text("alluxio://master:19998/test/LICENSE")// 统计文件行数val count = df.count()println(s"Alluxio file /test/LICENSE has $count lines")spark.stop()}
}步骤 3:提交 Spark 作业
spark-submit \--class AlluxioSparkDemo \--master yarn \--deploy-mode cluster \demo.jar步骤 4:验证缓存效果
- 首次运行:Spark 从 HDFS 下载数据到 Alluxio Worker 缓存,耗时较长;
- 第二次运行:Spark 直接读取 Alluxio 缓存,耗时显著减少(可在 Alluxio Web UI 查看 “缓存命中率” 提升)。
7.4 常用命令行工具
Alluxio 提供bin/alluxio fs命令行工具,常用命令如下:
| 命令 | 功能描述 |
| alluxio fs ls /path | 查看目录下文件 |
| alluxio fs mkdir /path | 创建目录 |
| alluxio fs copyFromLocal localPath alluxioPath | 本地文件上传到 Alluxio |
| alluxio fs copyToLocal alluxioPath localPath | Alluxio 文件下载到本地 |
| alluxio fs cache /path | 手动缓存文件到 Worker |
| alluxio fs free /path | 手动释放文件缓存 |
| alluxio fsadmin report | 查看集群状态报告 |
8.总结与最佳实践
Alluxio 作为数据编排层的核心技术,通过 “统一访问 + 多级缓存”,解决了大数据架构中 “计算 - 存储分离” 带来的效率低、管理难、成本高的问题。在实际使用中,建议遵循以下最佳实践:
- 缓存策略选择:高频访问的小文件(如 <1GB)优先缓存到内存,低频大文件(如> 10GB)缓存到 SSD;
- 内存配置:Worker 内存缓存大小建议为计算节点内存的 50%-70%(避免与计算框架争夺内存);
- 高可用部署:生产环境必须启用 Master HA 和 Journal Node 集群,避免单点故障;
- 监控重点:核心监控指标包括 “缓存命中率”(目标 > 90%)、“Worker 内存使用率”(避免超过 90%)、“元数据操作延迟”(避免 > 100ms);
- 云原生部署:在 Kubernetes 环境中,使用 Alluxio Operator 管理集群,配合 PVC 动态分配存储资源。
如果大家在使用 Alluxio 过程中遇到问题,或有更复杂的场景(如跨云数据同步、机器学习缓存优化),欢迎在评论区交流 —— 后续我会针对具体场景推出更深入的实操教程。
参考资料:
- Alluxio
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于博主:
🌟博主GitHub
🌞博主知识星球




)





)








