为什么卷积核爱用 3×3?CNN 设计 “约定俗成” 的底层逻辑
做深度学习的同学,对 CNN 里 3×3 卷积核、最大池化、BN 层这些设计肯定不陌生,但你有没有想过:为啥卷积核总选 3×3?池化层为啥默认最大池化?BN 层又是咋让训练飞起的? 今天咱们抛开公式,用 “人话 + 小实验” 扒一扒这些设计背后的门道。
一、卷积核:3×3 凭啥 C 位出道?
先看个灵魂问题:卷积核尺寸怎么选?11×11 不行吗?
直接说结论:小卷积核(比如 3×3)堆起来,效果不输大核,还能省参数!
举个栗子:假设处理 5×5 的特征图,用 1 个 5×5 卷积核,参数是 5×5=25;但用 3 个 3×3 卷积核堆叠(感受野等效 5×5),参数是 3×(3×3)=27 。哎?参数还多了?别慌,层数更深时差距会爆炸!比如等效 7×7 感受野:
-
1 个 7×7 卷积核:参数 7×7=49
-
3 层 3×3 卷积核:3×(3×3)=27(参数直接砍半!)
而且小卷积核还有隐藏福利:堆叠的非线性激活(比如 ReLU)更多,模型表达能力更强 。就像 “用多个小滤镜层层加工,比一个大滤镜更容易调出复杂效果”。这也是 ResNet、VGG 里 3×3 卷积扎堆的原因 ——小核堆叠≈高效大核 + 更多非线性 。
二、池化层:为啥偏爱 “最大”?
池化层的使命是精简信息、保留关键特征 。那为啥 “最大池化” 比 “平均池化” 更常用?
做个小实验:用 3×3 最大池化 vs 平均池化处理边缘检测结果(下图左是原始边缘,右是池化后)。明显能看到:最大池化会 “强化突出特征”(比如边缘更清晰),平均池化则 “模糊了关键信息” 。
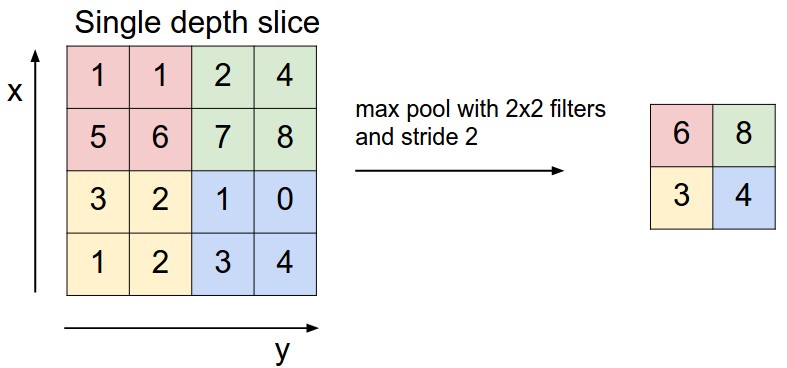
直观理解:池化就像 “在局部区域选代表”,最大池化选的是 “最亮眼的那个”(比如最强边缘、最明显纹理),这对后续特征提取超有用。而平均池化是 “雨露均沾”,反而会让关键特征被弱化。所以 CNN 里默认选最大池化,抓重点才是硬道理 !
三、BN 层:让训练 “起飞” 的秘密
训练 CNN 时,最头疼的就是梯度消失 / 爆炸 (比如网络深了,前面层的参数更新几乎没变化)。BN 层(Batch Normalization)就是来 “救场” 的!
通俗说,BN 层干了件事:让每一层的输入 “分布更稳定” 。想象一下:网络前层参数变了,后层的输入就会 “忽大忽小”(像坐过山车),训练很难稳定。BN 层通过 “归一化”,把输入强行拉回 “均值 0、方差 1” 的正态分布,相当于给后层吃了 “定心丸”—— 不管前层咋变,我这输入都稳稳的!
看组对比实验:有无 BN 层的训练损失曲线 (蓝线是加了 BN 的,红线没加)。明显看到:加 BN 后,损失下降更快、更稳定 ,甚至能缓解过拟合(因为每层输入更可控,模型不会 “死记硬背”)。这也是现在 CNN 里 BN 层几乎标配的原因 ——让训练效率直接起飞 !
四、总结:CNN 设计的 3 个底层逻辑
-
小核堆叠 > 大核:用更少参数实现等效感受野,还能多塞非线性激活,模型更能打。
-
抓关键 > 求平均:最大池化聚焦 “最突出特征”,比平均池化更适配特征提取需求。
-
稳定输入 = 高效训练:BN 层通过归一化稳住输入分布,让深网络训练不再 “抽风”。
这些 “约定俗成” 的设计,本质是在 “效果” 和 “效率” 间找平衡 —— 毕竟深度学习,既要能解决问题,又得跑得动才行~
(最后补个小思考:现在有些模型开始用动态卷积、可变形卷积,是不是又在打破这些 “约定”?评论区聊聊你的看法呀!)
技术延伸:想亲手验证这些结论?推荐用 PyTorch 写个极简 CNN,替换 3×3 为 5×5 卷积核,对比参数数量;或者去掉 BN 层,看看训练曲线变化。代码超简单,比如:
# 3层3×3卷积 vs 1层7×7卷积
model_3x3 = nn.Sequential(nn.Conv2d(3, 64, 3, 1, 1),nn.Conv2d(64, 64, 3, 1, 1),nn.Conv2d(64, 64, 3, 1, 1)
)
model_7x7 = nn.Conv2d(3, 64, 7, 1, 3)
# 打印参数数量
print(sum(p.numel() for p in model_3x3.parameters() if p.requires_grad)) # 3×(3×3×64 + 64) = 5568
print(sum(p.numel() for p in model_7x7.parameters() if p.requires_grad)) # 7×7×3×64 + 64 = 9472


)














)

