达梦分布式集群DPC_节点故障分析
- 1 DPC核心概念回顾
- 2 场景1-主库故障
- 3 场景2-少数备库故障
- 4 场景3-多数节点故障
- 4.1 多数节点故障(包括主库)
- 4.2 多数备库节点故障(不包括主库)
1 DPC核心概念回顾
达梦分布式集群DPC,基于Raft协议实现高可用性,确保在节点故障时仍能维持数据强一致性与服务连续性。
raft协议
1.RAFT组角色划分:
1.领导者 (Leader):处理客户端请求,日志发送与提交
2.跟随者 (Follower): 接收领导者日志
3.候选者 (Candidate):临时角色,发起投票请求
2.日志复制流程
1.客户端提交请求,主库(领导者)修改数据后生成日志包;
2.记录并广播日志, 本地写redo日志前,发送给所有副本(跟随者);
3.副本确认: 副本收到日志后,确定日志包正确,然后修改数据,完成后回复主库已完成,协助主库刷盘。
3.raft核心参数
RAFT_HB_INTERVAL --主库广播心跳消息的间隔时间
RAFT_VOTE_INTERVAL --选举超时时间
2 场景1-主库故障
假设主库为A,其他副本为B、C
A的归档参数:
RAFT_HB_INTERVAL= 150 --主库广播心跳消息的间隔时间
RAFT_VOTE_INTERVAL= 3000 --选举超时时间
B的归档参数:
RAFT_HB_INTERVAL= 150
RAFT_VOTE_INTERVAL= 5000
C的归档参数:
RAFT_HB_INTERVAL= 150
RAFT_VOTE_INTERVAL= 7000
直接kill主库A复现,查看副本(B、C)之间的详细流程
①主库故障 09:49:59-09:50:00
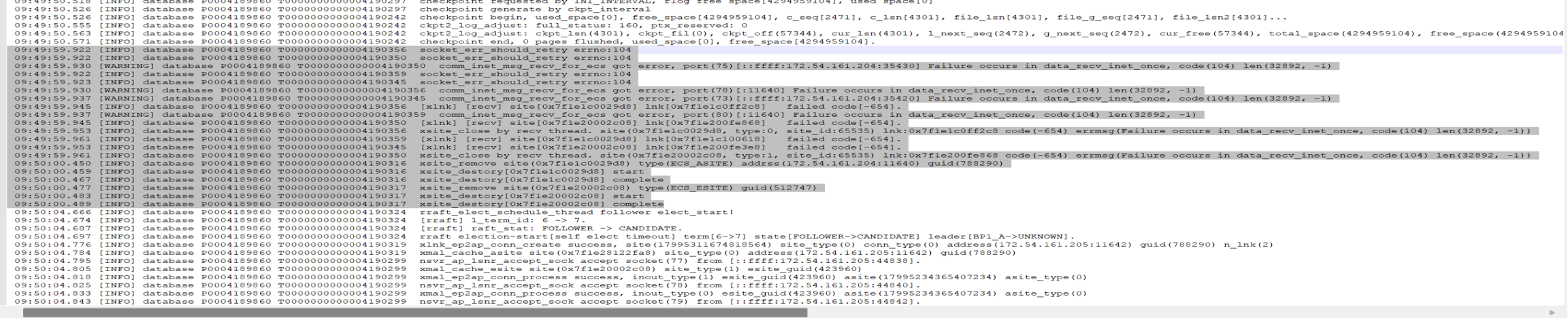
socket_err_should_retry errno:104 --两副本同时检测到主库连接断开
xsite_remove site(0x7f17b00029d8) type(ECS_ASITE) addrss(****:11640) guid(423960)--完成主库连接移除
②B副本5秒内没有收到主库的心跳广播,触发选举流程 09:50:04
rraft_elect_schedule_thread follower elect_start! --选举开始
[rraft] l_term_id: 6 -> 7 l_term_id+1 --广播投票请求
[rraft] raft_stat: FOLLOWER -> CANDIDATE. --转变成候选者
rraft election-start[self elect timeout] term[6->7] state[FOLLOWER->CANDIDATE] leader[BP1_A->UNKNOWN] --选举开始
③C副本7秒内没有收到主库的心跳广播,触发独立选举流程 09:50:06

④一共10s后,B副本首次选举超时,触发第二轮选举 09:50:09

[rraft] l_term_id: 7 → 8 首次选举超时,触发第二轮选举
[recv] vote res from node[id:2] 获得副本C投票
raft_stat: CANDIDATE → LEADER 切换为领导者
Change BP1_A arch status from VALID to INVALID, arch_type[RAFT] 改故障节点的归档为 invalid
⑤C副本投票给B,转换成跟随者 09:50:09

[rraft] l_term_id: 7 → 8 # 准备二次竞选
[rraft] raft_stat: CANDIDATE -> FOLLOWER.
[vote] received g_seq is larger 承认副本B日志更新
rraft recv vote request from[BP1_B]
[rraft] [send] node[id: 1] vote res, term: 8, voted: 1. 投票给副本B
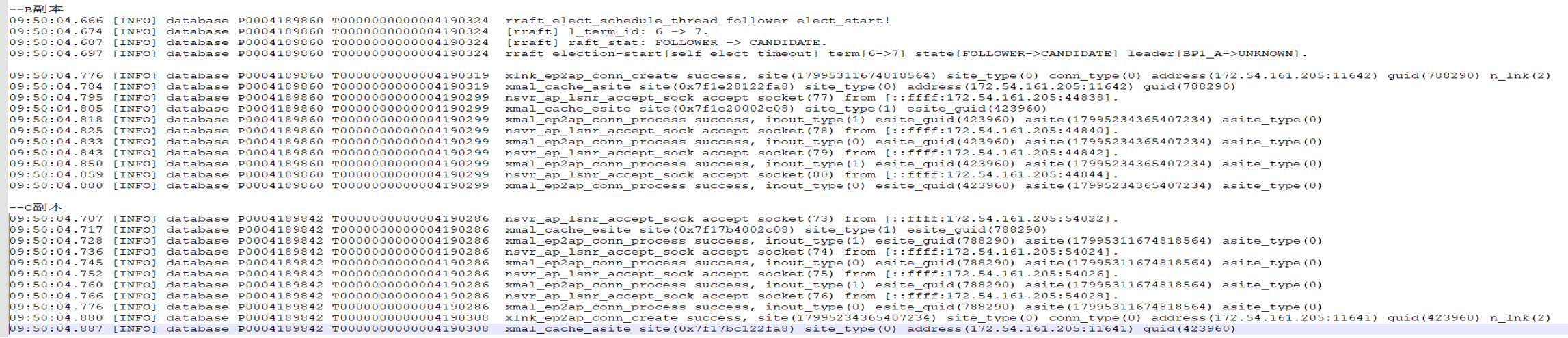
3 场景2-少数备库故障
断开少数备库后
改变备库归档为INVALID,并异步发送日志到备库,不影响主库正常读写
4 场景3-多数节点故障
4.1 多数节点故障(包括主库)
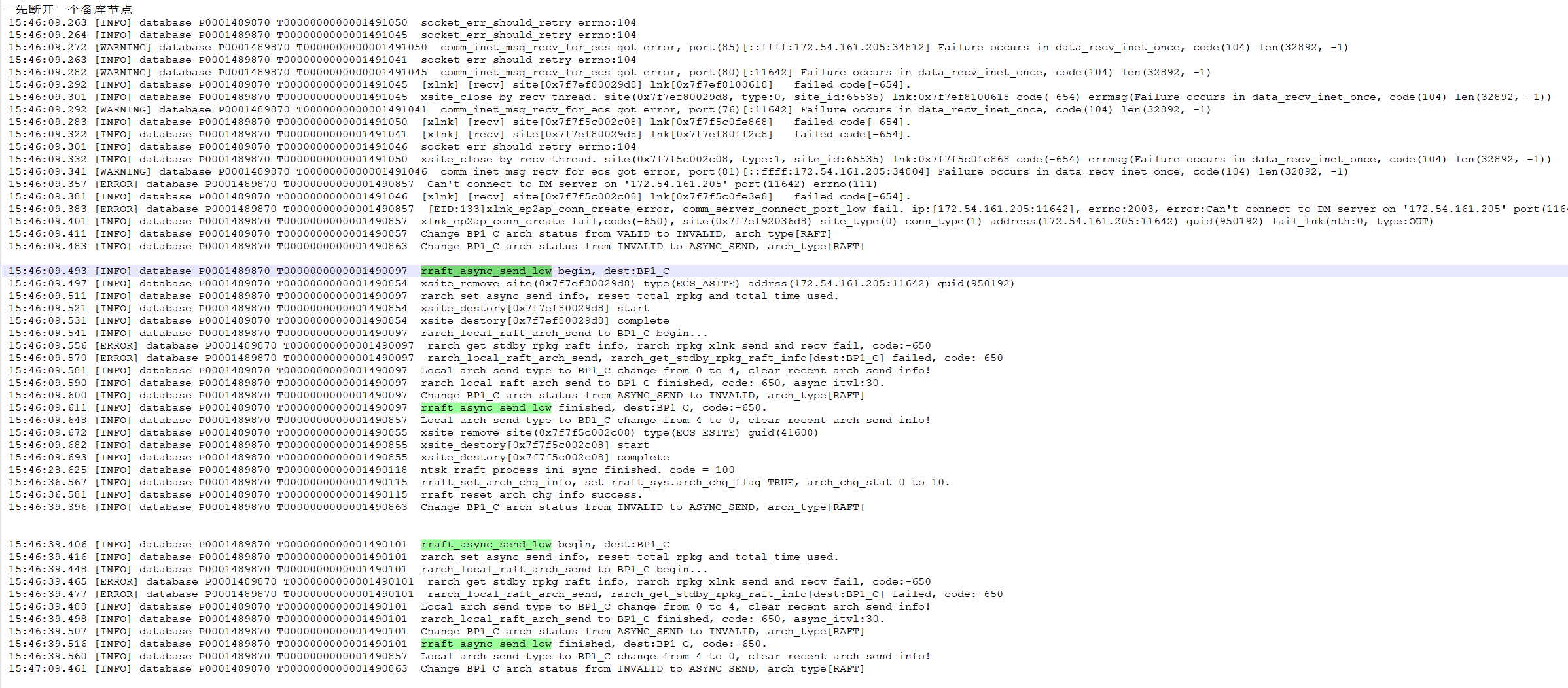
①当kill主备库后,只剩下一个备库
socket_err_should_retry errno:104 --检测到主库连接断开xsite_remove site(0x7f17b4002c08) type(ECS_ESITE) guid(788290)--完成主库连接移除
②备库一直触发选举,但是因为没有多数派投票,所以一直失败
13:11:28.310 [INFO] database P0004189842 T0000000000004190313 rraft_elect_schedule_thread follower elect_start!
13:11:28.319 [INFO] database P0004189842 T0000000000004190313 [rraft] l_term_id: 8 -> 9.
13:11:28.331 [INFO] database P0004189842 T0000000000004190313 [rraft] raft_stat: FOLLOWER -> CANDIDATE.
13:11:28.338 [INFO] database P0004189842 T0000000000004190313 rraft election-start[self elect timeout] term[8->9] state[FOLLOWER->CANDIDATE] leader[BP1_B->UNKNOWN].
13:11:35.310 [INFO] database P0004189842 T0000000000004190313 [rraft] l_term_id: 9 -> 10.
13:11:42.310 [INFO] database P0004189842 T0000000000004190313 [rraft] l_term_id: 10 -> 11.
13:11:49.311 [INFO] database P0004189842 T0000000000004190313 [rraft] l_term_id: 11 -> 12.
13:11:49.591 [INFO] database P0004189842 T0000000000004189895 rraft_set_arch_chg_info, set rraft_sys.arch_chg_flag TRUE, arch_chg_stat 0 to 9.
13:11:49.597 [INFO] database P0004189842 T0000000000004189895 ini_sync_process_for_raft, leader_id is ULINT_UNDEFINED!
13:11:49.603 [INFO] database P0004189842 T0000000000004189895 rraft_reset_arch_chg_info success.
每个7S进行一次选举,因为C副本的RAFT_VOTE_INTERVAL= 7000(选举超时时间)
4.2 多数备库节点故障(不包括主库)
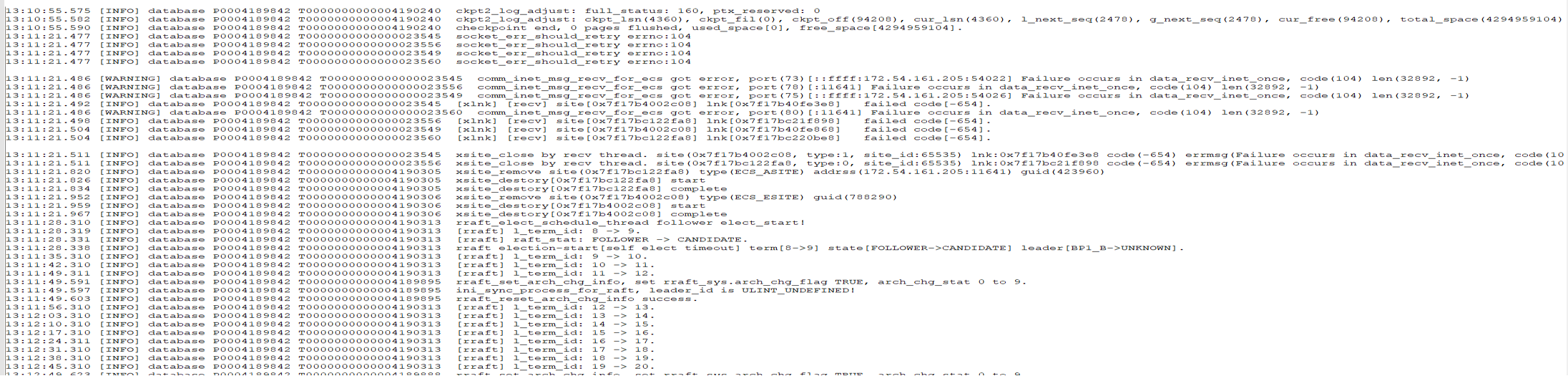
①当kill掉多数备库后

15:46:09.411 [INFO] database P0001489870 T0000000000001490857 Change BP1_C arch status from VALID to INVALID, arch_type[RAFT]
15:46:09.483 [INFO] database P0001489870 T0000000000001490863 Change BP1_C arch status from INVALID to ASYNC_SEND, arch_type[RAFT]
改变备库归档为INVALID,并异步发送日志到备库
②如果发现多数备库故障
Too many rlog_pkgs cannot commit, set database readonly. --主库只读
③恢复多数备库节点
手动启动故障备库后
Rlog_pkgs committed, set database writable
Change BP1_B arch status from ASYNC_SEND to VALID, arch_type[RAFT]
Change BP1_C arch status from ASYNC_SEND to VALID, arch_type[RAFT]
待恢复完成后,主库会将其归档状态设置为有效状态,然后转入正常日志同步。
更多其他数据库相关专栏:
1.数据库优化
数据库优化基本思路、索引详解、执行计划、统计信息、CBO原理、单表优化、多表优化、分布式优化、子查询、优化案例等
数据库优化(sql优化)专栏连接
2.达梦分布式数据库:
部署详细步骤(DEM)、备份还原实战、核心特性理解、使用心得、表分区方式详细介绍、表分区最佳实践、DPC架构详解等
达梦分布式DPC专栏连接
3.应用开发类
jdbc、hibernate、ibatis、mybatis、MyBatis-Plus、Spring、中间件mycat、Sharding-JDBC等
达梦数据库应用开发专栏连接



![[ CSS 前端 ] 网页内容的修饰](http://pic.xiahunao.cn/[ CSS 前端 ] 网页内容的修饰)







)



:使用 Arduino IDE 对 ESP8266 进行编程并刷新其内存)



