背景
最近在这家公司做了一些事情,做的事情和以往的工作不太一样,不一样的点呢就是 之前我主要的工作是关注计算这方面,因为数据量大,研究的是怎么加速查询,怎么研究规则去优化,怎么去解规则的bug等等。因为现在业务的不同,每次获取的数据量比较小,更加关注的索引效率,计算方面可能只是一些简单的SUM AVG等。
接下来谈谈我对这个计算存储引擎的理解与认知:
什么是SQL计算存储引擎
SQL计算存储引擎是利用SQL的能力进行计算,而用户无需担心后台计算的细节,而且计算需要用到的数据都是在这个计算存储引擎里。
它包括两个部分,一个是计算部分:包括SQL解析,SQL优化,SQL执行; 一个是存储部分,包括数据格式的存储,数据的获取。
SQL计算以及优化
如果单纯从计算的角度来说话的,这类的引擎典型的有 Spark离线引擎,Flink实时引擎,presto adhoc引擎, 这种不关心数据的存储,也就是说这类没有存储能力。这种往往在运行的时候,是从远端拉取数据,拉数据数据来以后再进行计算。
从大的方面来说,SQL计算引擎 一般会包括任务调度和SQL计算。
任务调度
任务调度的模式一般包括 Spark 的 StageByStage 调度模式 和Flink 的 AllAtOnce 调度模式。
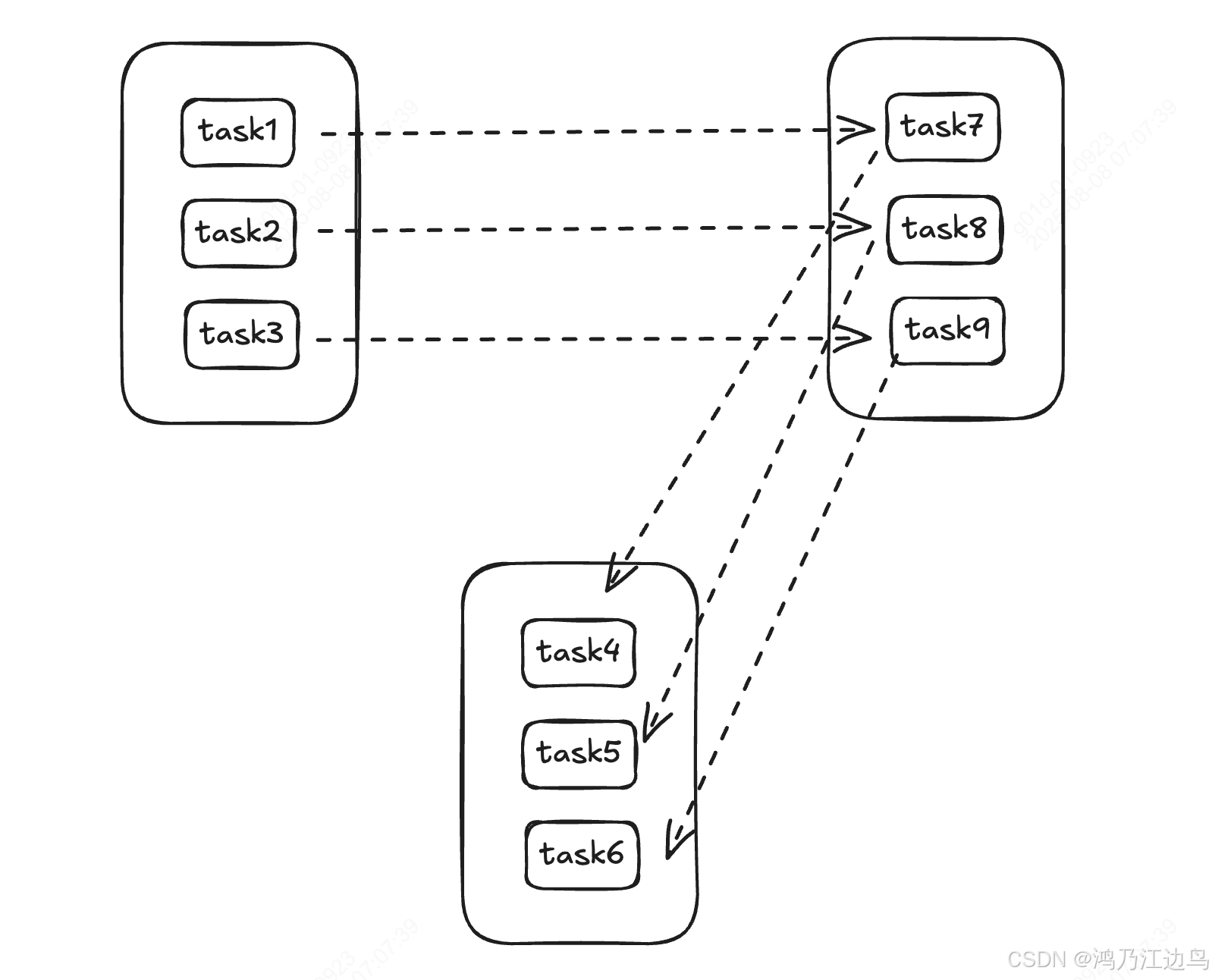
第一种模式:stageByStage, 这种是典型的离线调度模型,这种调度模型的运行方式为 一组任务按照Stage的方式进行组织,只有上一个Stage的所有Task运行完了以后下一个Stage才能继续执行,这种方式的好处是任务的失败的容错性高,因为stage与stage之间的数据交互会进行暂存,一个任务或者stage的失败,可以继续从容错点恢复重试执行。而且这种方式可以充分利用数据的亲和性,也就是说,下游stage的任务可以依赖上游任务的分布情况来进行调度,比如说把下游Task调度到上游Task运行的节点上,这样一来,就无须再进行远程数据的拉取,直接从本地读取数据,可以减少数据的拉取时间.
这种模式下,任务的调度和执行是穿插在一起的。
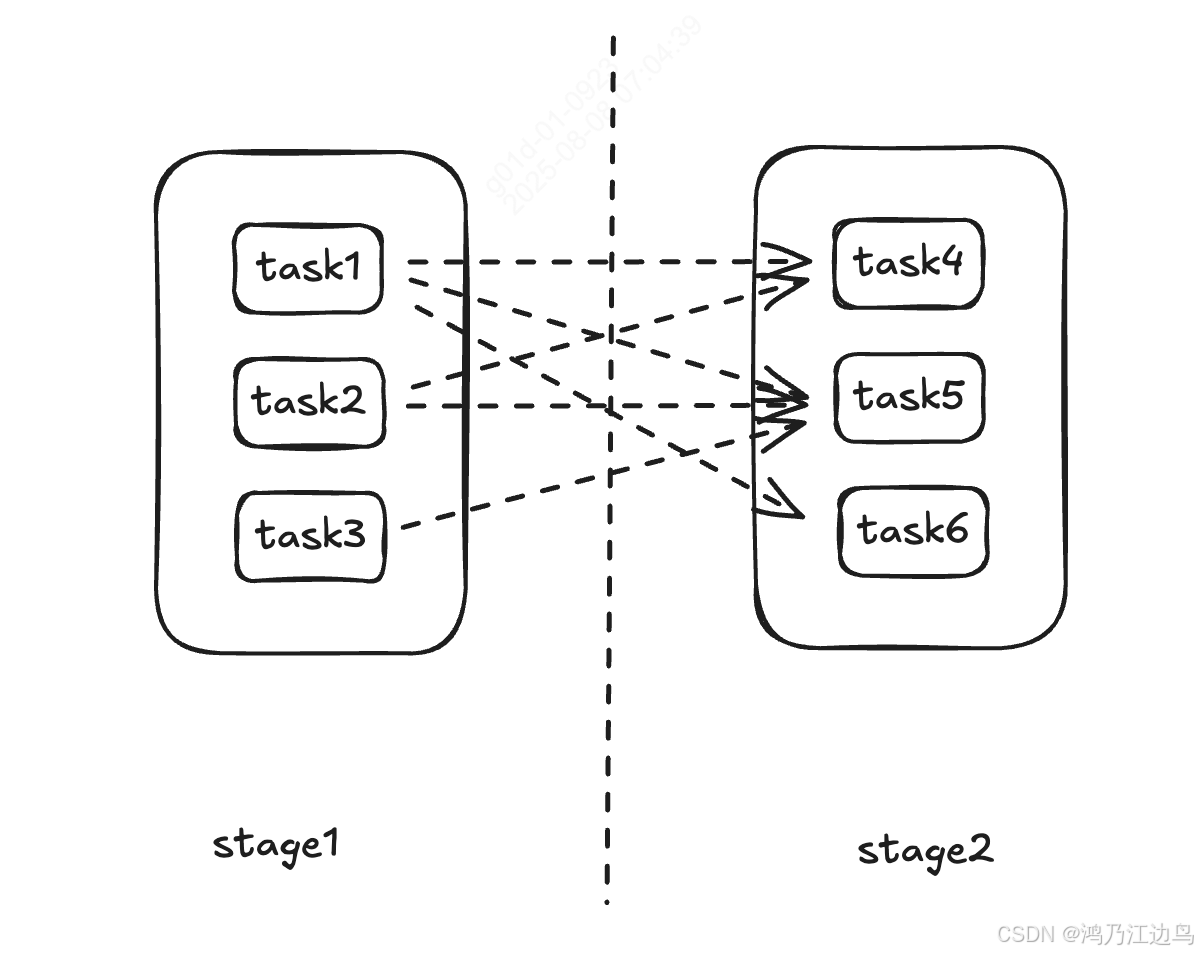
第二种模式:AllAtOnce,这种模式是典型的流式调度模型,也就是在任务执行之前,调度器会根据策略进行Task的调度了,这个时候每个任务在哪个节点执行都已经固定好了,之后所有的数据处理就像流水线一样,来一个处理一个,这个阶段Task的调度就是闲置状态。所以这种模式的时效性很好,数据的延迟低。但是如果Task失败或者task所在的容器重启了,这个时候调度器会重新调度Task。
SQL计算
SQL计算的话,一般会包括SQL部分,以及SQL转换成引擎底层API的部分,从整个引擎的发展来看,一般是先提供API接口,用户写底层的API进行调用,后着才慢慢的出现SQL引擎,这种SQL使用起来对用户是友好的,当然这后面逻辑的转换也会经过很多步骤:
- SQL解析为AST
- AST转为逻辑计划
- 逻辑计划优化为优化计划
- 优化计划换转为物理计划
- 物理计划转换为可执行的底层API
这种SQL的解析,目前从大部分开源框架的用的趋势来看,ANTLR4 是主流,只有一小部分,比如说Flink 用的是 Calcite,不得不说 ANTLR4还是挺好用的,这个阶段主要是判断语法的合规性,是不是符合定义的语法规则。
再者是 AST转换为逻辑计划,这个阶段主要是y结合元数据做一些校验,比如说 检查表存不存在,字段合不合理,函数存不存在等。
优化计划这一部分,这里面包括的内容就比较多了,但是一般来说,一种是基于规则的(RBO),一种是基于代价的(CBO)的。
这两种也不是非黑即白的,主要看侧重于那一方。
比如说,Spark主要是RBO,但是在join转换的部分,也是会基于CBO的(AQE),AQE也就是说基于运行时的指标信息来及时调整运行的计划以达到更好的加速效果。
又比如说 StarRocks 主要是基于CBO的,但是这种CBO的话,也是在RBO规则的下的,比如说这种常量折叠等这种都是RBO。而且这种CBO也有一部分是估算的,也没有精确的数值。
优化计划转换为物理计划这一块,这一块主要是转换为可执行的物理计划,也就是说这里的物理计划都是可以执行了,调用某个方法就会返回对应的API的调用,比如说
Spark中RowDataSourceScanExec这里的doExecute方法就是返回RDD,Flink也是如此。
当然这里还有一个很大的部分就是代码生成,这里主要就是为了减少虚函数的调用而采用的一种提速的方法,这种是因为JVM语言存在多态函数的二次寻址。
SQL优化
这一部分主要是从以下方面来优化
- 使获取的数据尽可能的少,减少计算的数据量
- 使中间任务传输的数据尽可能的少,减少传输带来的开销
- 尽量减少shuffle的数据量,或者消除shuffle
- 减少shuffle所需要的时间
比如说
hashjoin转换为 broadcastJoin 就是 消除shuffle
hashjoin转为换sortmergejoin 就是减少shuffle需要的时间
runtimefilter 就是减少传输的数据量
谓词下推 就是使获取的数据尽可能的少
数据的存储与索引
对于没有自身存储系统的计算引擎
这种引擎其实是没没有索引一说的,因为你无法快速的定位到某一行数据,这种如果想加速的话,只能依靠存储系统的本身一种快读过滤机制,就拿现在流行的数据湖来说,如paimon或者delta,他们的底层文件存储是列式存储,比如说parquet。
这种引擎如果想快速的过滤出出数据的话,得依靠parquet这个底层文件系统自带的统计信息,比如说最大最小值,又或者说布隆过滤器(Bloom Filter),这些是基于rowgroup级别的来的,也就是说这些过滤器能够做到快读的跳过文件。
或者从计算层级来加速,比如说字典编码,这种把String的比较转换为整数的比较。
当然也可可以通过文件的布局来进行加速,比如说Zorder等
对于带有自身存储的计算引擎
这种引擎的话,大部分是存算一体的,也就是说计算和存储耦合在一起,这种引擎在写入数据的时候,往往会进行索引的建立,比如说主键索引(能够快速定位到某一行数据),bitmap索引(能够快读定位过滤条件所在的行),聚簇索引(能够根据聚簇键进行快速查询)。
但是需要注意的是,这种索引是需要单独维护的,尤其在大量数据更新的场景下,索引的维护也需要一定的开销。不像前者,前者是把这些信息存储在文件的元数据信息里。
点查
这里需要单独说一下这个点查,大部分都是通过主键来查找来达到点查的效果的。
这里的如果要有点查的效果,必须是针对于带有自身粗处的计算引擎。
以上所过,我们写完SQL以后会进入到优化器以及调度环节,但是对于点查不一样,它只需要简单的优化,调度环节的的话直接越过。
为什么跳过呢?
因为我们是简单的查询,没有计算,只需要查询对应的数据,无需要进行Task的调度。就拿Starrocks来说,一个SQL的调度可能就需要花费20多毫秒
- -- Deploy[1] 23ms- -- DeployLockInternalTime[1] 23ms- -- DeploySerializeConcurrencyTime[1] 0- -- DeployStageByStageTime[3] 0- -- DeployWaitTime[3] 23ms- -- DeployAsyncSendTime[1] 0
)



:I2C总线的传输速率与上拉电阻有什么关系?)





用户的区别)




)


