目录
- 1.分组查询
- (1)聚合函数
- (2)group by子句
- (3)having
- 2.连接查询
- (1)内连接(笛卡尔积)
- (2)外连接
- (3)内外连接的区别
- (4)自连接
- a.给表取别名
- b.自连接的使用
- 3.合并查询
- (1)union
- (2)union all
- 4.子查询(嵌套查询)
- (1)单行
- (2)多行
- a.in
- b.all
- c.any
- (3)多列单行
- (4)多列多行
- (5)from中使用临时表
- (6)with的使用
- 5.select各个关键字的执行顺序
查询分为简单和复合查询,是利用select和各种相关用法通过逻辑连接实现特定的功能,筛选并正确展示数据。 上篇文章讲了select的基本用法,所以该部分是对上篇文章的延伸。
1.分组查询
(1)聚合函数
聚合函数是内置函数的子集,聚合函数多用于对多行数据进行统计等运算
select count(*) from tb; # 统计tb的行数,也可统计指定列不为空的数据个数
select sum(English) from tb; # 统计tb中English列成绩总和,自动忽略空值
select avg(Chinese) from tb18; # 统计tb18中Chinese列成绩平均值,自动忽略空值
select max(distinct English) from tb18; # 统计tb18中English列成绩最大值,自动忽略空值和重复值
select min(distinct Chinese) from tb18; # 统计tb18中Chinese列成绩最小值,自动忽略空值和重复值
(2)group by子句
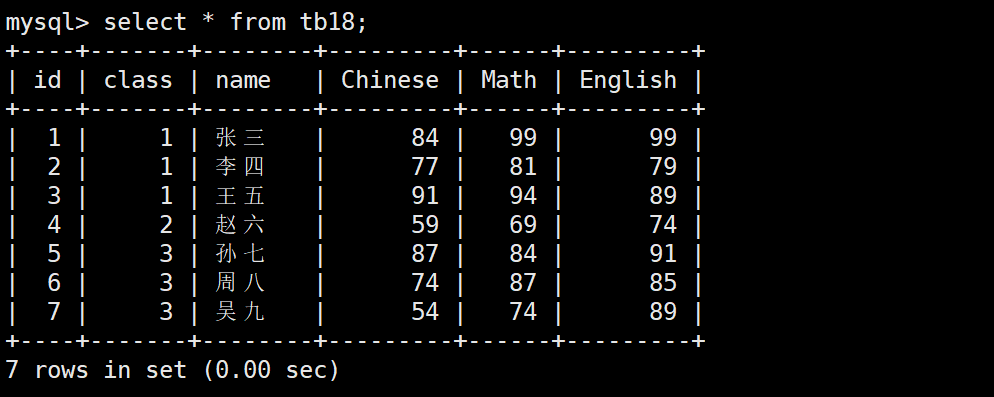
在这个表下面,如果我们想要得到每个班级的每科成绩的平均值,就需要对class分组。
select class, avg(Chinese), avg(Math), avg(English) from tb18 group by class; # 展示的列中只能由聚合函数结果、分组的列组成
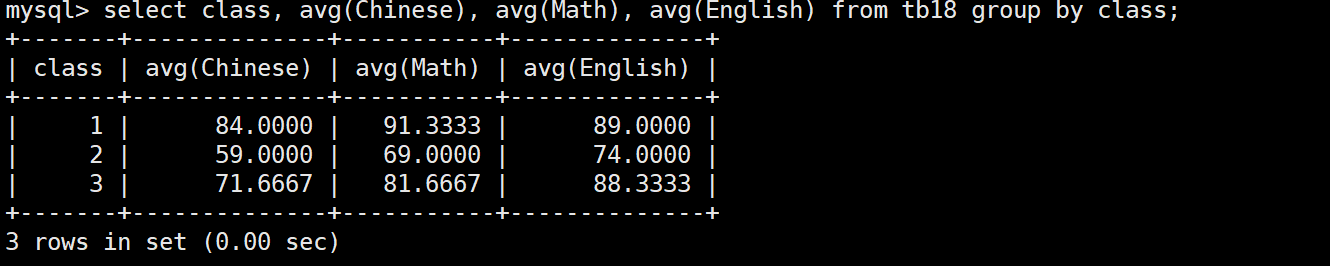
group by按照该列不同的值分组后,聚合函数的计算也会分组。最后select展示时只能由聚合函数、分组的列组成,其它的都没有意义,也会报错。
(3)having
having经常和group by子句联合使用,用于对即将展示的结果进行筛选。它和where的执行顺序不同,where在select之前执行,而having在select之后执行,因此你能看到having可以直接使用重命名。
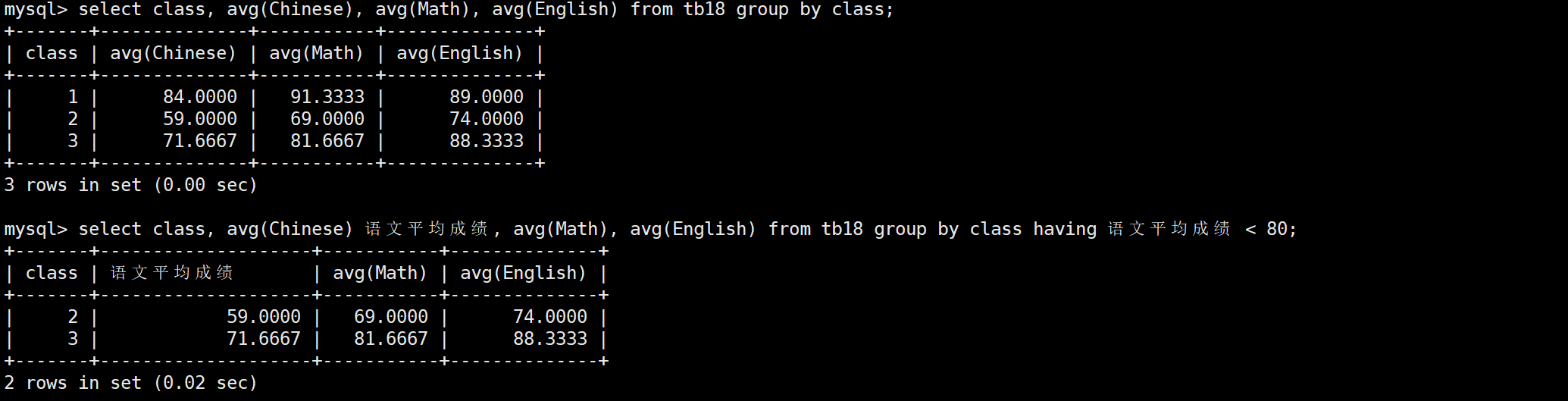
当然,having也可以单独使用
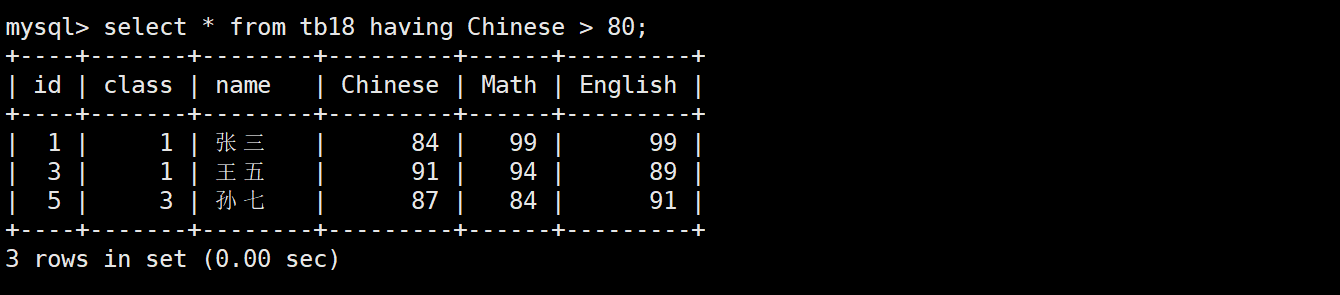
having和where在逻辑上一个是对执行结果做筛选,一个是筛选后执行,因此就只有having可以用在分组后,分组前两个都可以使用。
2.连接查询
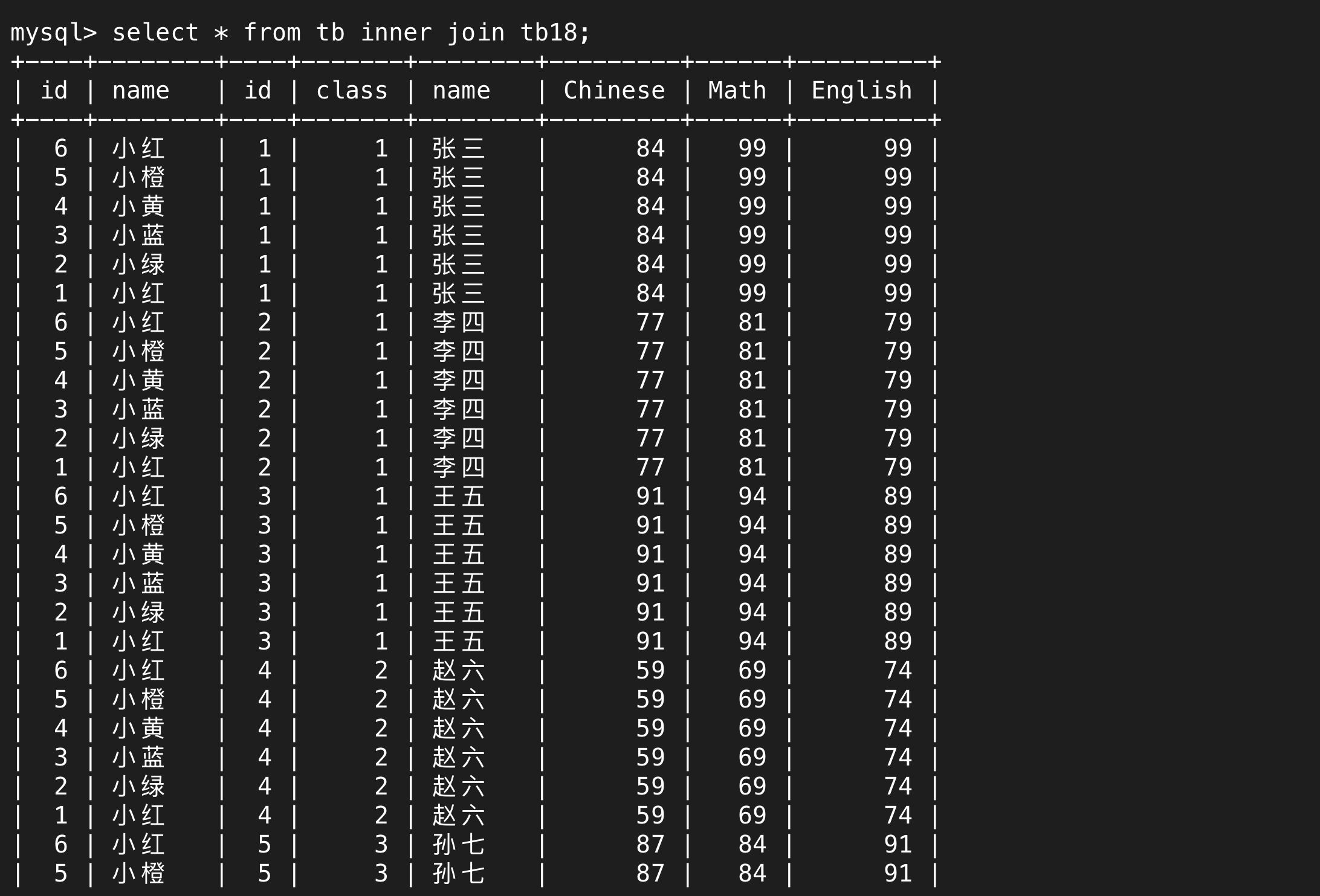
(1)内连接(笛卡尔积)
有的时候我们想要将两张表连在一起
如tb18是学生信息表,包括其成绩

tb是其老师的信息表
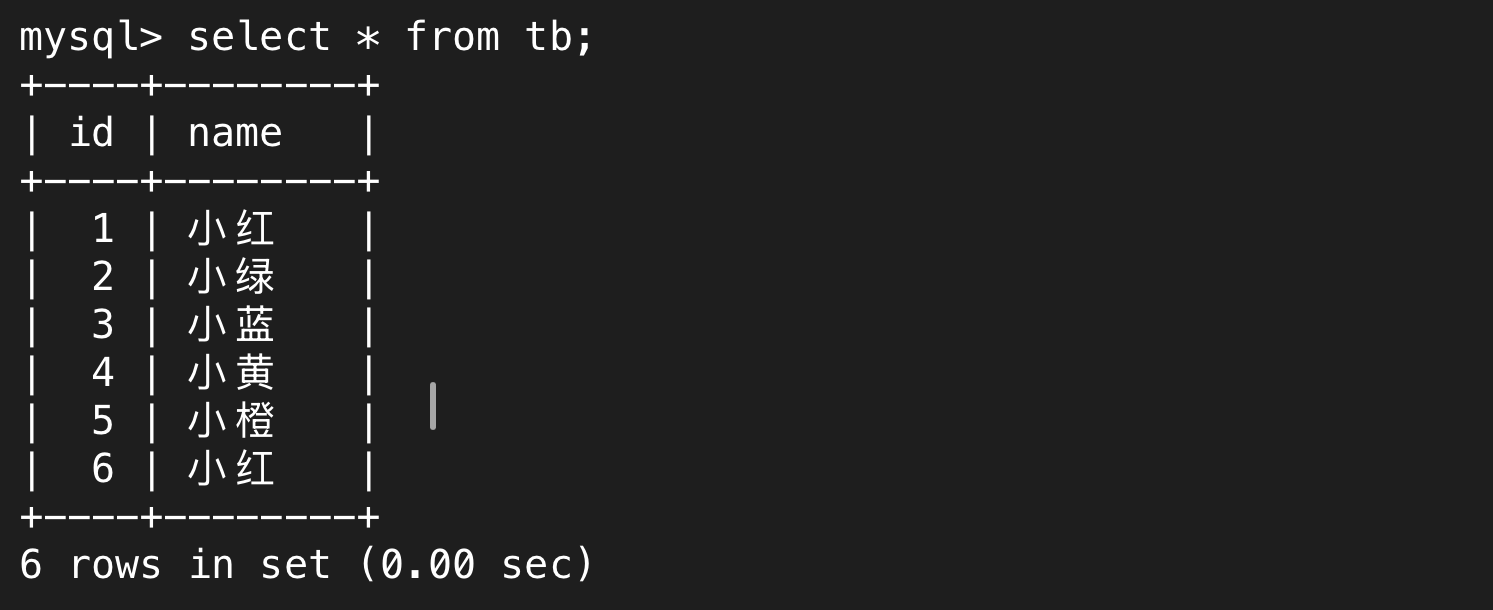
连接起来就是排列组合,以下就是所有学生和所有老师的组合情况
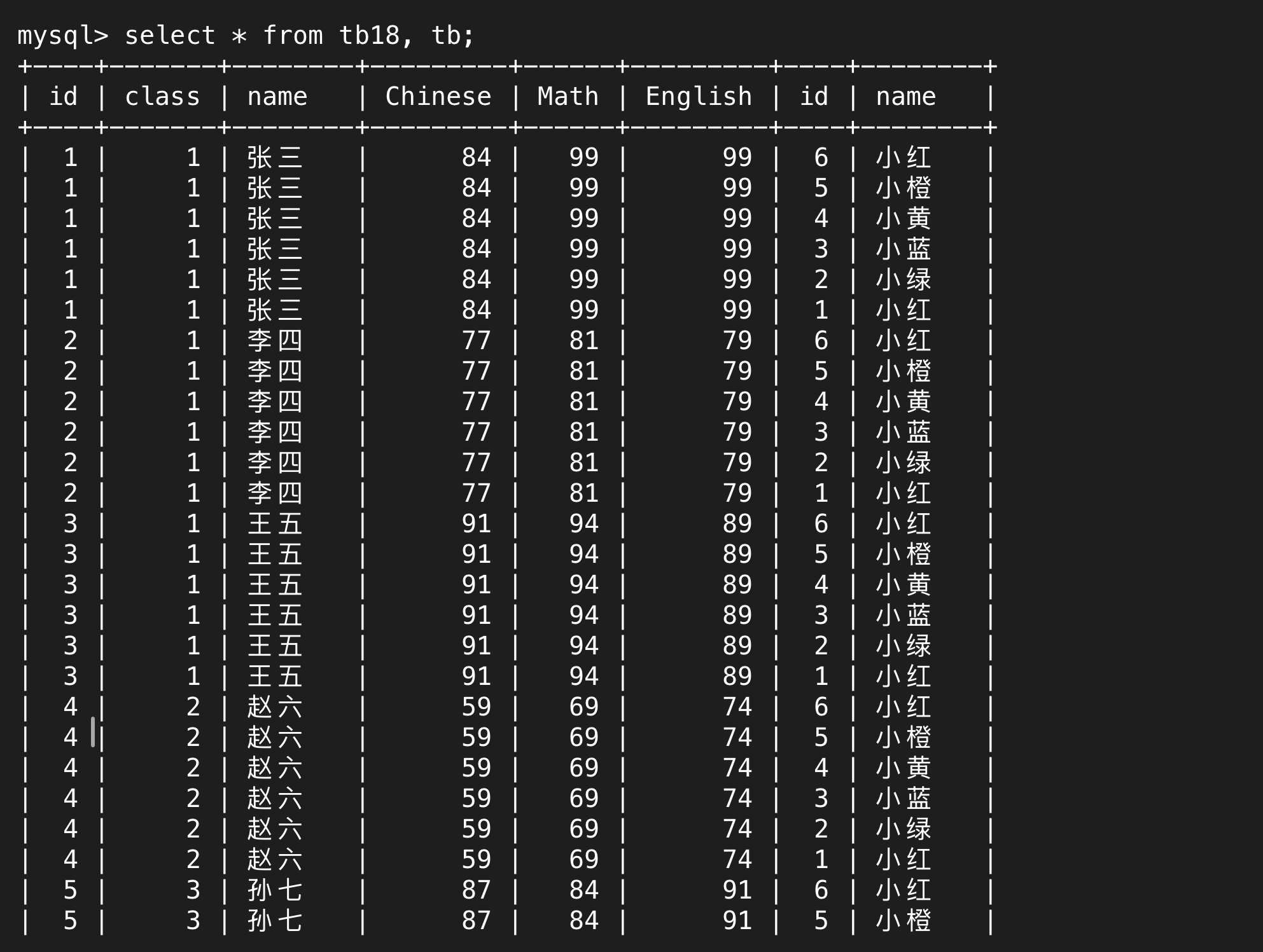
张三和小红、小橙……小绿都连在一起了,之后就是李四,又和这6个人连在一起了。笛卡尔积就是取前一张表的每一行,和后面一张表的每一行都连接一次,这就是排列组合,目的是穷举所有的可能性。
而显然,笛卡尔积的结果并不是最终我们想要的结果,它只是先为我们提供所有的可能性,我们需要再次筛选得到想要的行。
其中,无论是筛选还是select,只要有重复的列名,都需要用(表名).(列名)来唯一确定。
通过where子句,我们就可以筛选出我们需要的行
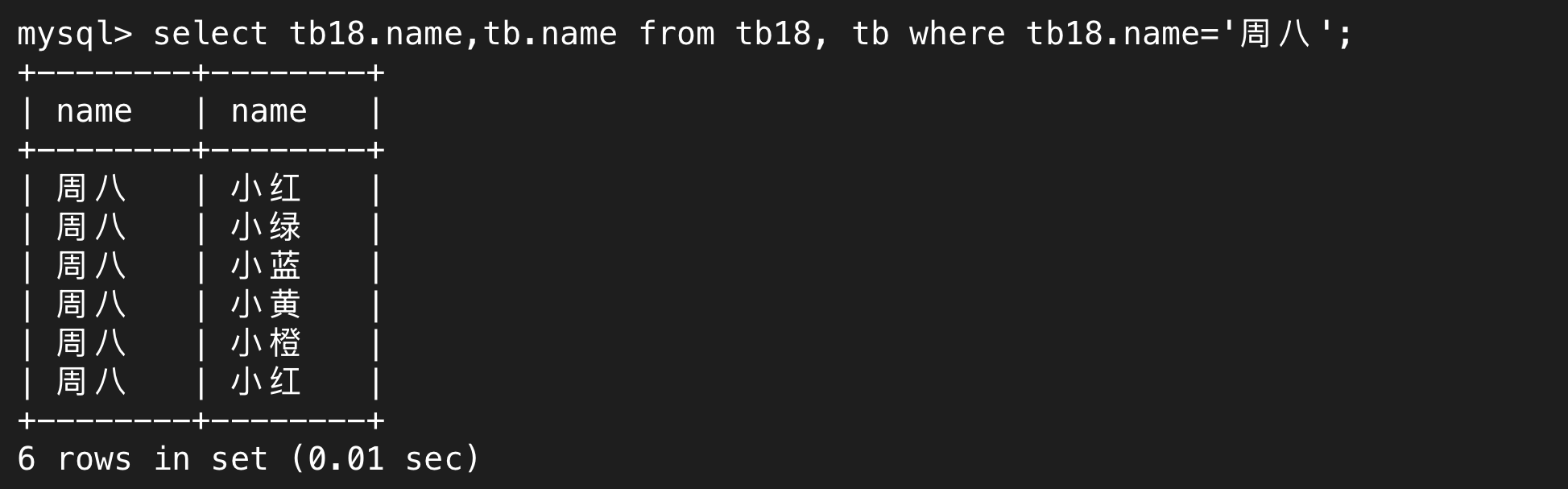
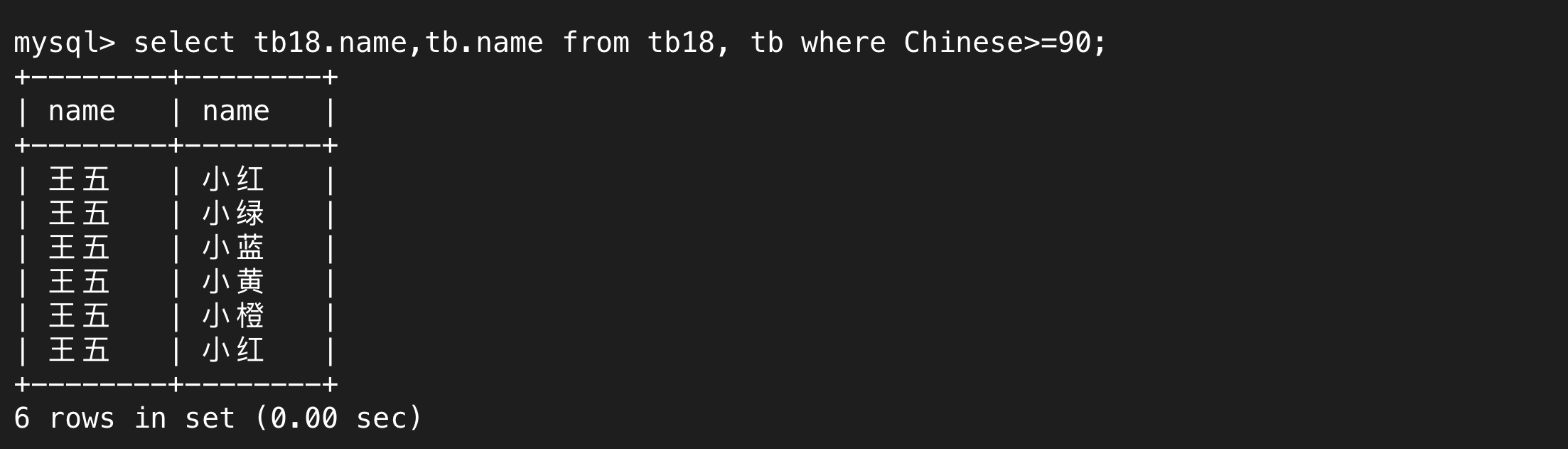
上述讲的就是内连接,只不过我们可以省略inner join这个关键字。我们还可以写成join,join默认指的就是内连接,外连接需要完整指定
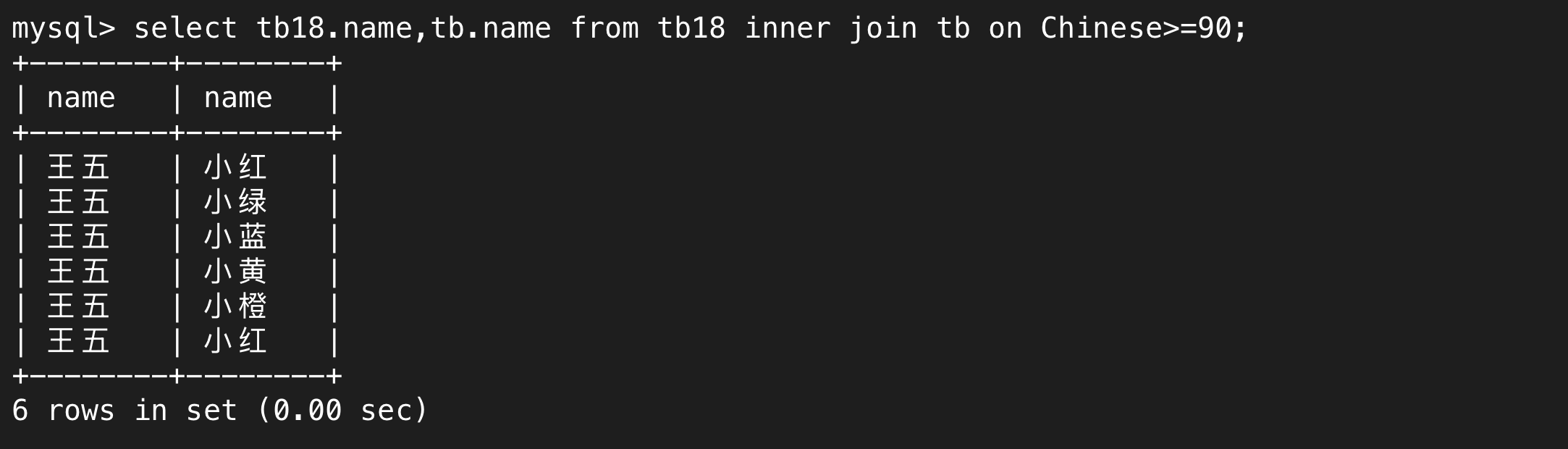
在内外连接且显式写了inner join(或left join / right join)的情况下可以用on代替where来进行筛选,on后面就代表关联条件。
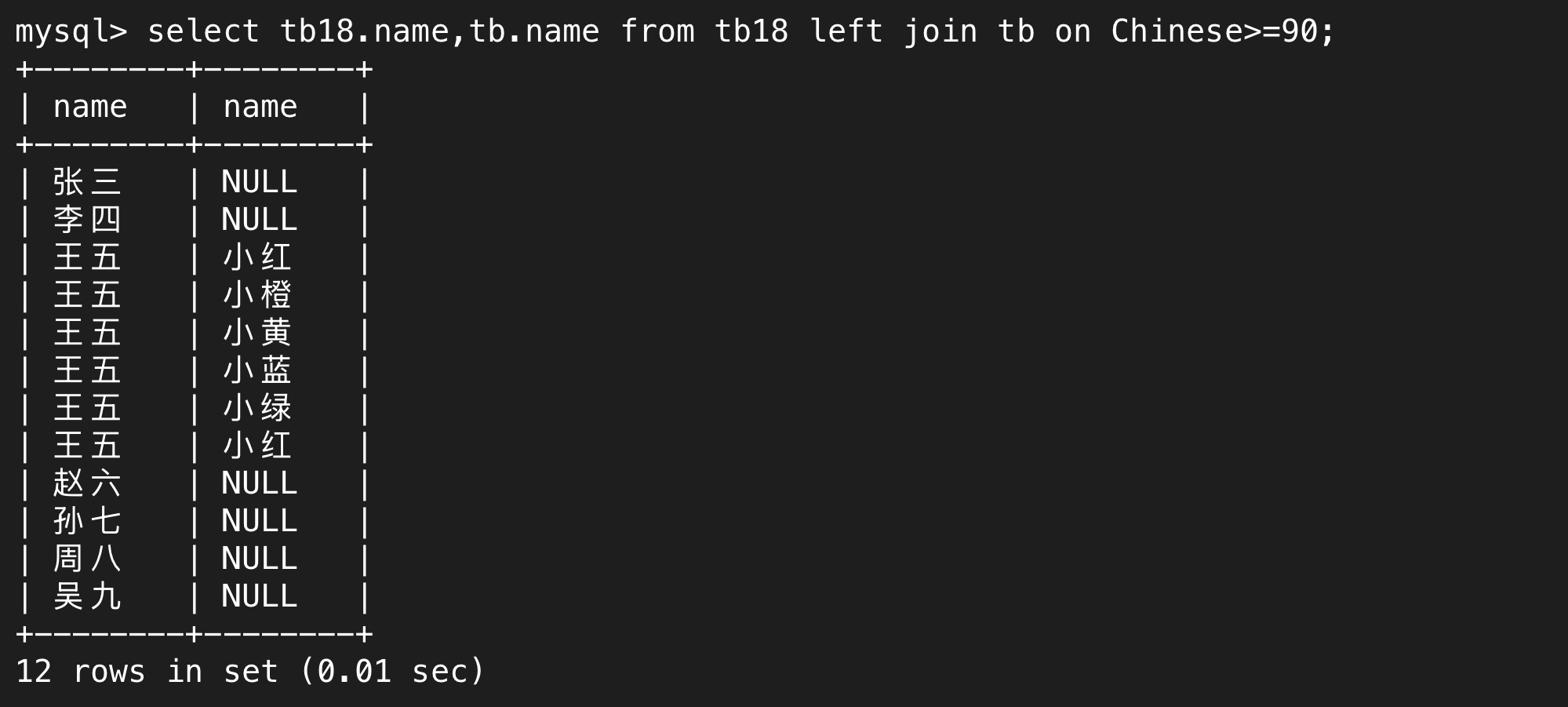
(2)外连接
下面是左外连接,在这张表中,左边这张表(tb18)相关的信息永远会完全展示,如张三、李四……吴九,如果满足筛选条件的会进一步展示,就是图中的王五,其它的人的右边表的相关信息都是NULL。
右外连接就是右边的表一定全部展示完,左边的不符合要求的会显示NULL。
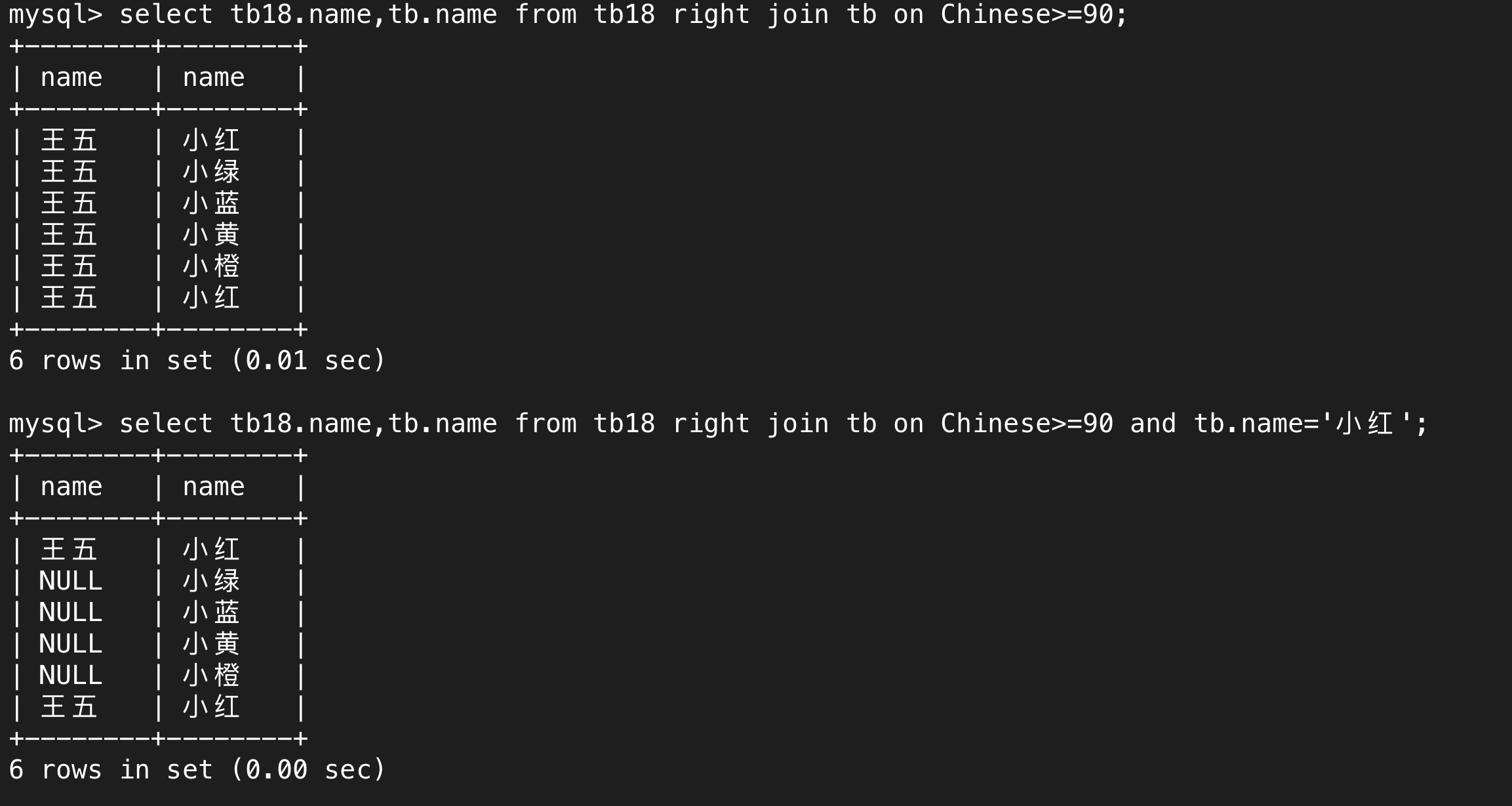
(3)内外连接的区别
下图的筛选条件一模一样,只是内外连接的方式不一样。
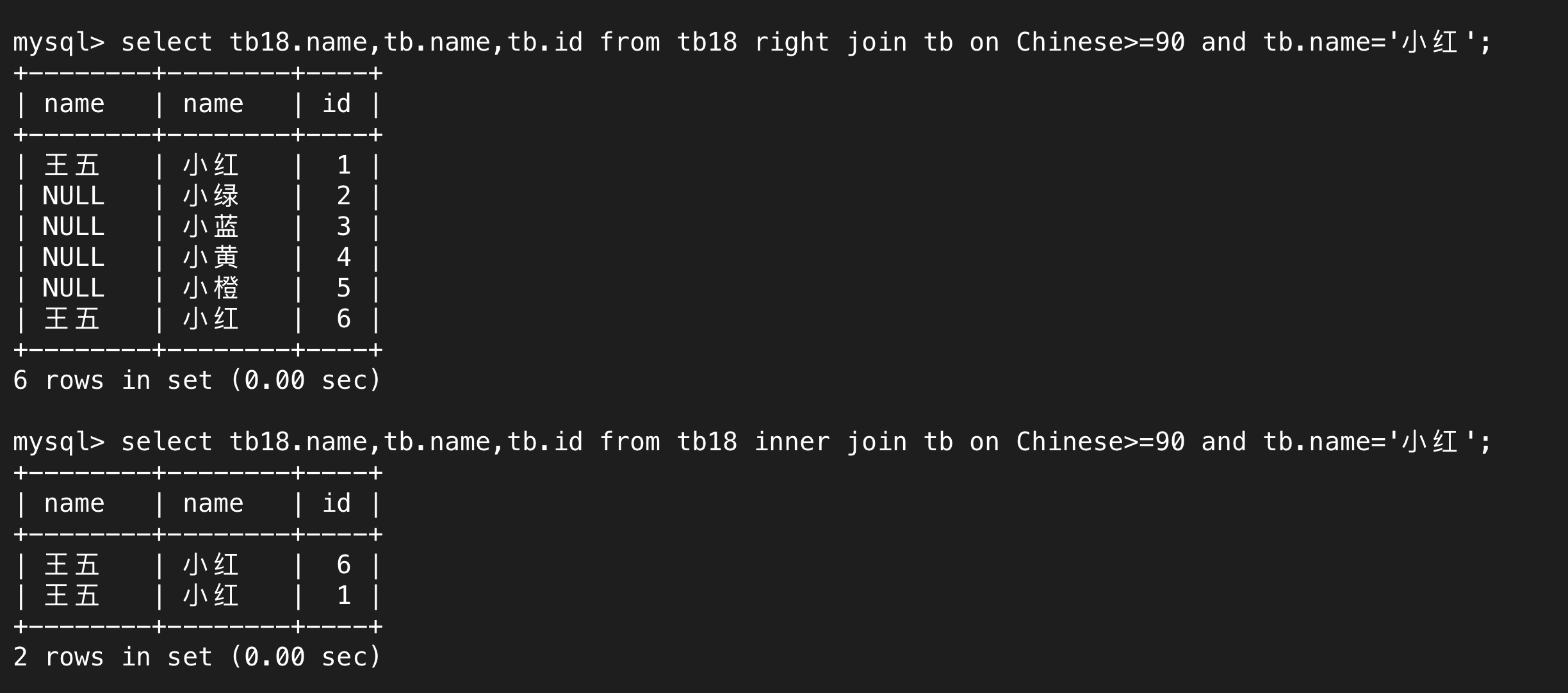
内连接就是先将两张表进行笛卡尔积,再根据筛选条件展示符合条件的行。外连接就是在内连接的基础上,根据左外连接和右外连接分别将左边或右边表的相关信息展示完全,符合筛选条件的就像内连接那样正常显示,不符合要求的行的相关属性会显示NULL。
一般情况下使用最多的是内连接,外连接一般在某个表的信息非常关键的情况下使用。
(4)自连接
a.给表取别名
下面是对表取别名的用法,根据执行顺序,我们可以在select和后面的where中使用新名字。
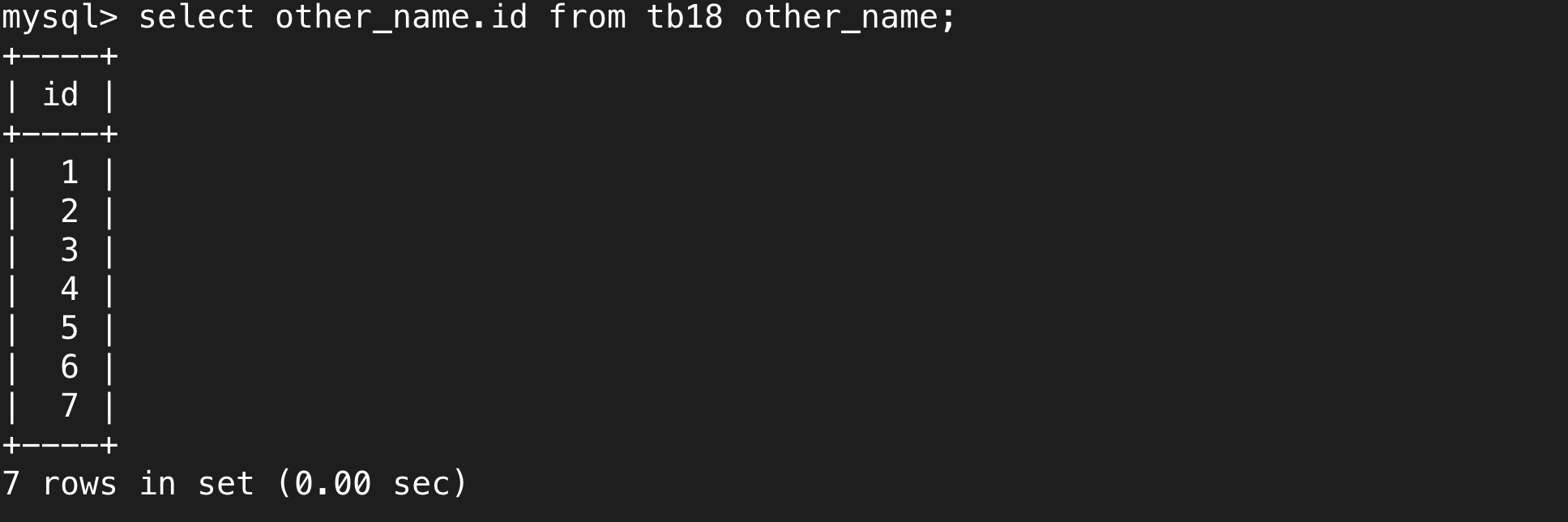
b.自连接的使用
我们可以内连接两张表,对每张表取不同的名字,在自连接中,这两张表是同一张表。
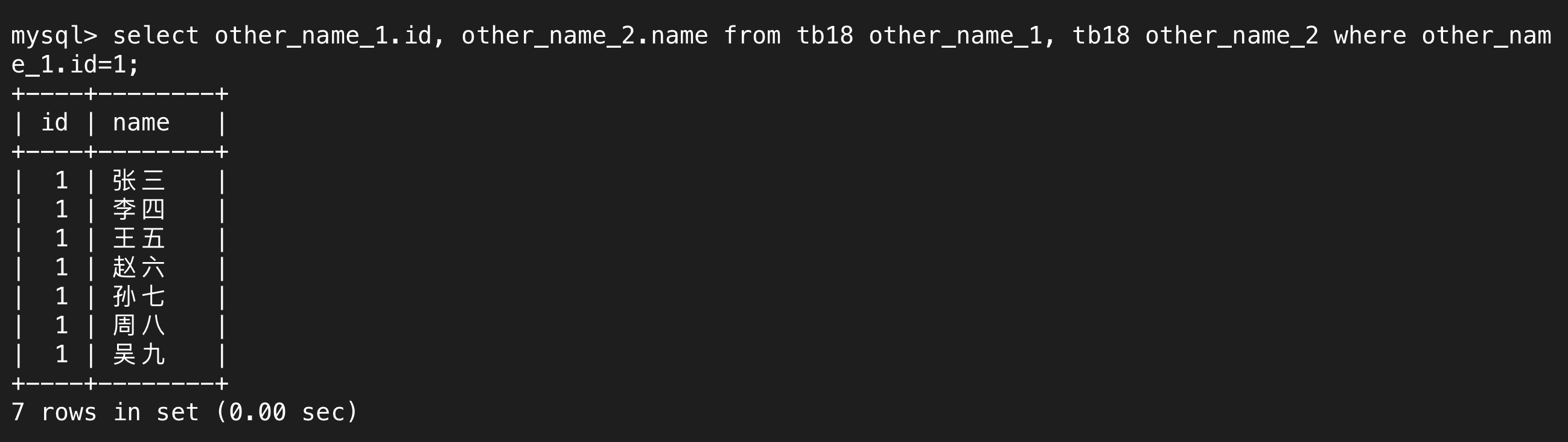
自连接本质上就是内外连接,只不过连接的两张表是同一张表,然后对每张表取别名用于区分而已。
3.合并查询
(1)union
union是合并查询的关键字,union前后是两个独立的select语句,并且两个语句的结果取并集,并且两个语句的结果会被去重,所以下面的语句意思是语文成绩>80或者数学成绩>70。
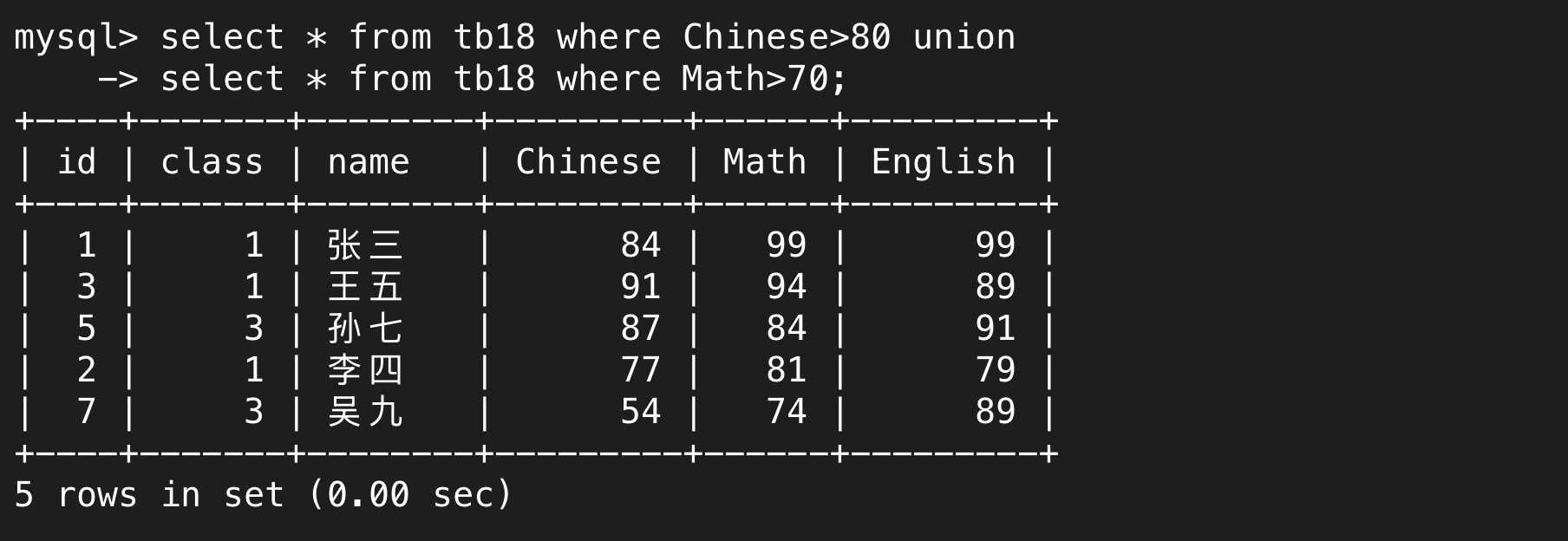
(2)union all
union的基础上不去重就是union all,也就是说同时满足union前后两个语句的结果会出现两次。
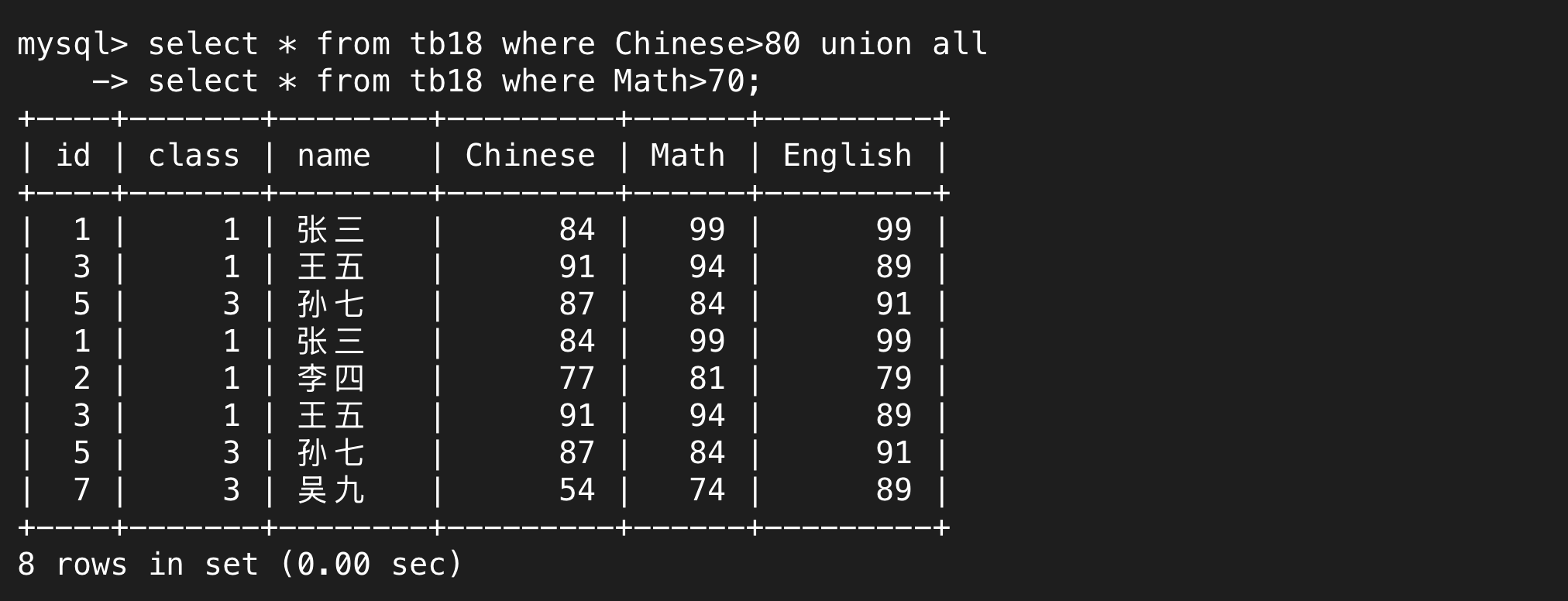
4.子查询(嵌套查询)
子查询指的是在where子句中使用select语句的结果作为值,即select * from tb where name=(select……)形式,看上去就是在一个select语句里面嵌套另一个select语句,以达到查询的目的。
(1)单行
单行子查询中“单行”指的是返回的结果是一行,单行结果中列名不占一行。
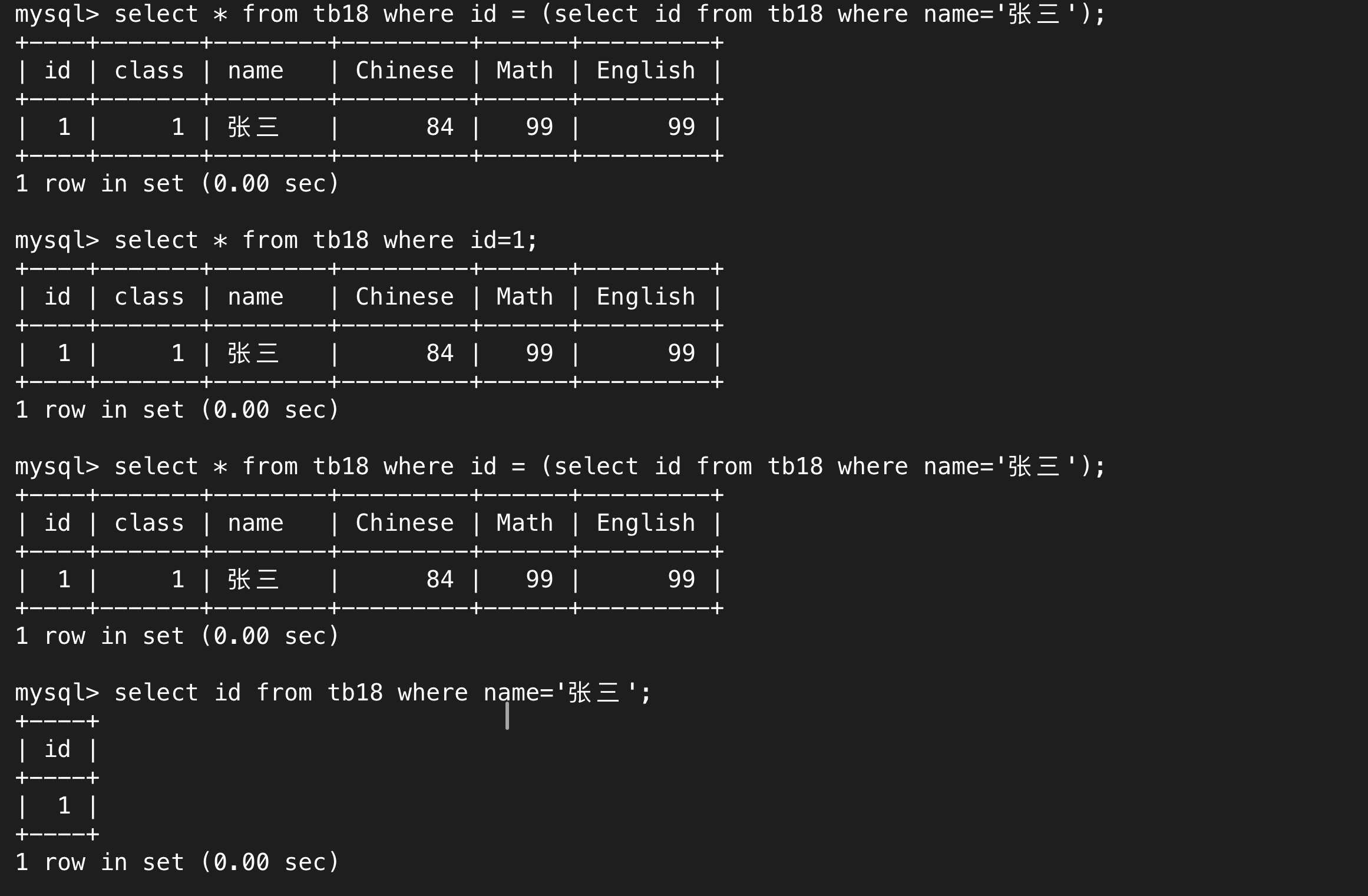
(2)多行
多行子查询指的是返回结果是多行的。
a.in
select 得到的多行的结果,直接用=接收显然是不够的,用in就可以接受多行数据,在下图中指的就是id在selcet语句的执行结果中就符合条件,这个子select的执行结果是多个数字,在这里指的就是大于3的数字。
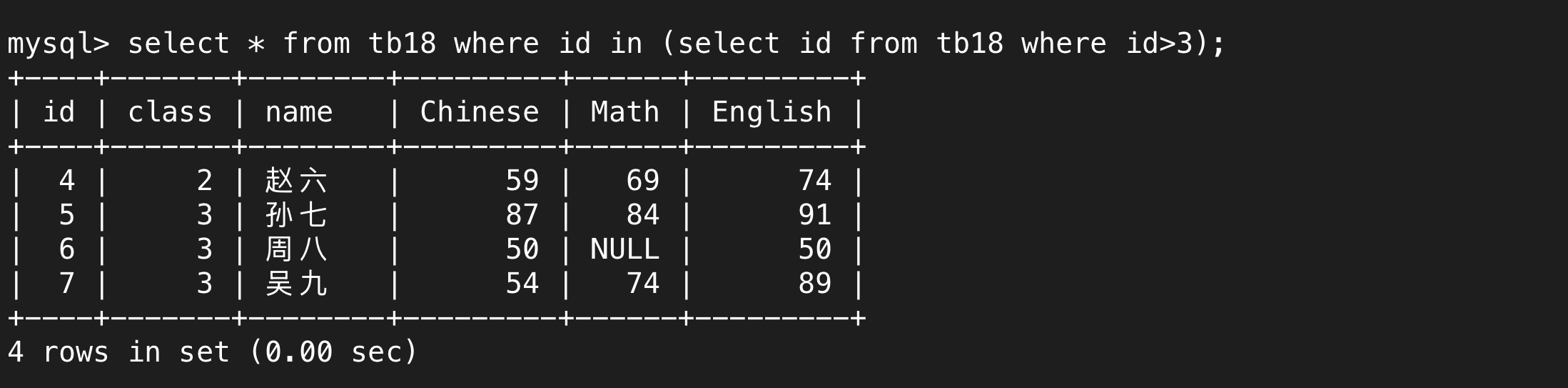
b.all
在这里id > all(select……)指的是select返回多行数据,再拿着多行数据中的每个数据对匹配id > 该数据,最后取交集就是结果

下面的语句中,是对select中的每个数据单独比较id <= 该数据,再取交集。上一张图中相当于和最大值进行比较,这里是对最小值进行比较。

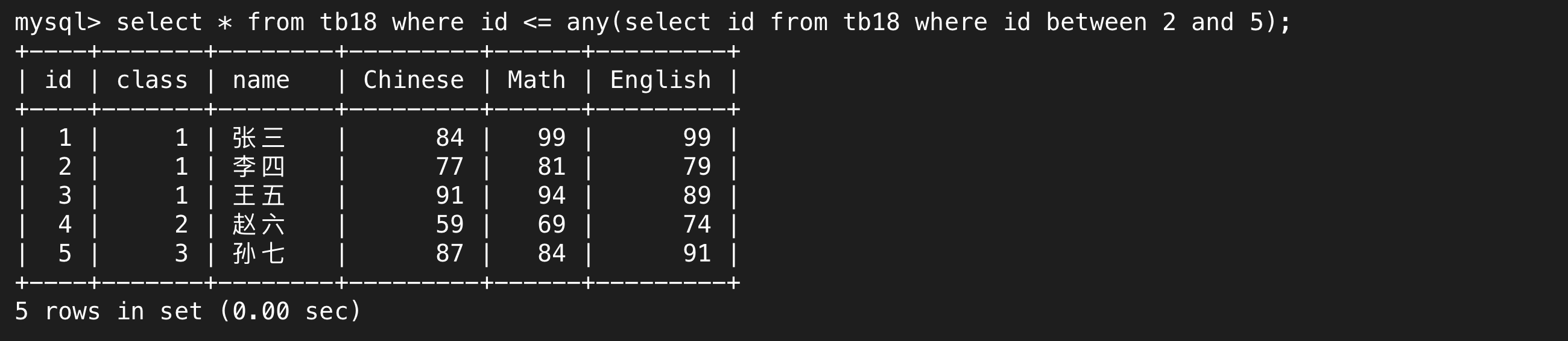
c.any
和all不同,all表示的是和所有数据单独比较,最后取一个交集;any也是和所有数据单独做比较,最后取并集。
体现在语句中,id > all表示比select结果中最大的还要大,id > any表示比select结果中最小的还要大;id < all中表示比select结果中最小的还要小,id < any表示比select结果中最大的还要小,分清这个逻辑是最重要的。
(3)多列单行
在上面的例子中,最大的特点就是子select中只显示一列数据,我们也可以设定成多列的。

在上面的这个例子中,是根据两列单行的值进行筛选的,筛选时要使用(列名1, 列名2)和等号来进行匹配。
(4)多列多行
mysql也支持多列多行的子查询,其含义和单列的一样

不过mysql不支持在多列多行中使用any和all,需要我们自己拆分成单列的情况才行。

(5)from中使用临时表
经过这么久的学习,我们需要意识到每一次操作返回的结果本质上都是一张表,无论是单列也好还是多列也好,单行还是多行,都是这样。每一个select语句执行的结果就是一张表,所以我们可以将select执行的结果放进from语句后面。
我们还可结合对表取别名的用法,简化书写。
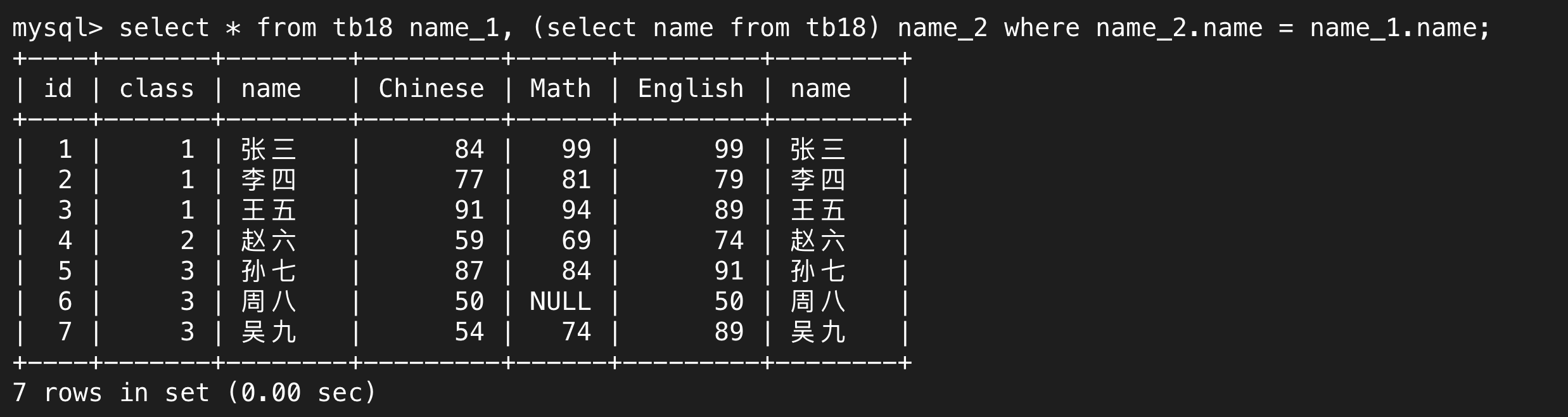
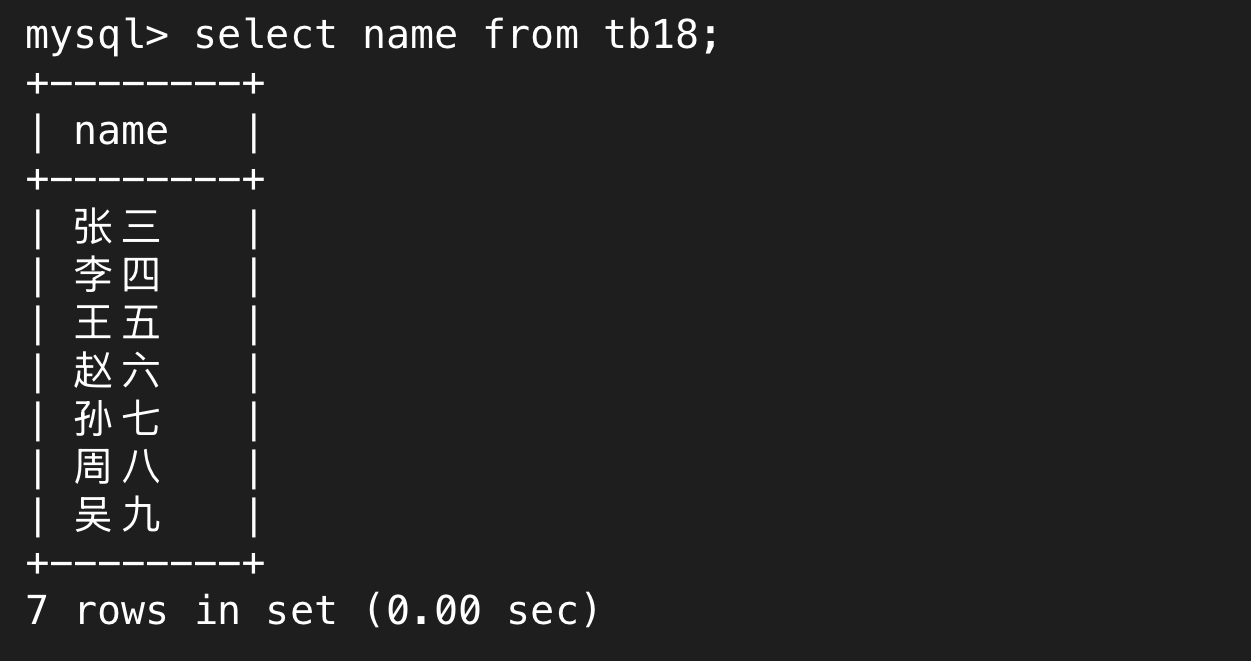
单独使用select name from tb18;得到的就是个完整的表,只不过这个表是临时的,我们要仔细体会MySQL中的每一步操作本质上都是生成一张表这个道理。
(6)with的使用
with的作用和from后面跟select语句的作用一样,都是构建一个临时表进行使用,只不过如果要更多的使用临时表,可以统一提到最前面用with来提高易读性。
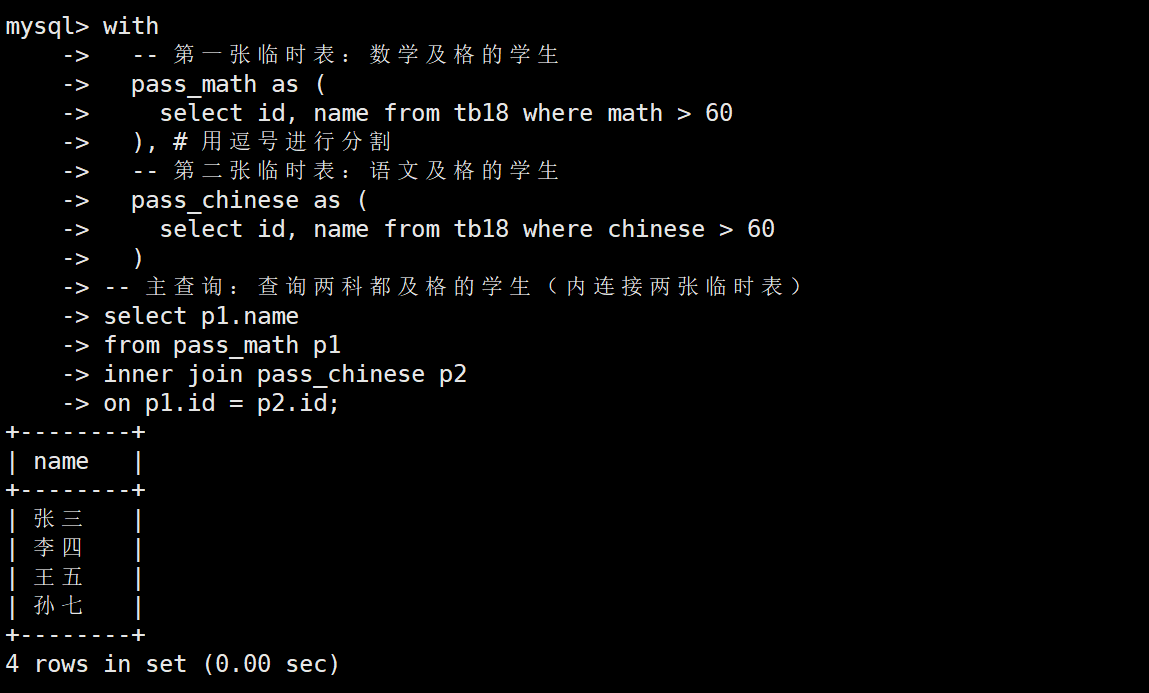
下面这个例子要实现的功能是找到数学、语文都及格的学生
with -- 第一张临时表:数学及格的学生pass_math as (select id, name from tb18 where math > 60), # 用逗号进行分割-- 第二张临时表:语文及格的学生pass_chinese as (select id, name from tb18 where chinese > 60)
-- 主查询:查询两科都及格的学生(内连接两张临时表)
select p1.name
from pass_math p1
inner join pass_chinese p2
on p1.id = p2.id;
5.select各个关键字的执行顺序
with > from + join + on > where > select + distinct > group by + having > order by + limit
上述关键词都已经介绍过了,下面将举一个完整的例子来说明其执行顺序。
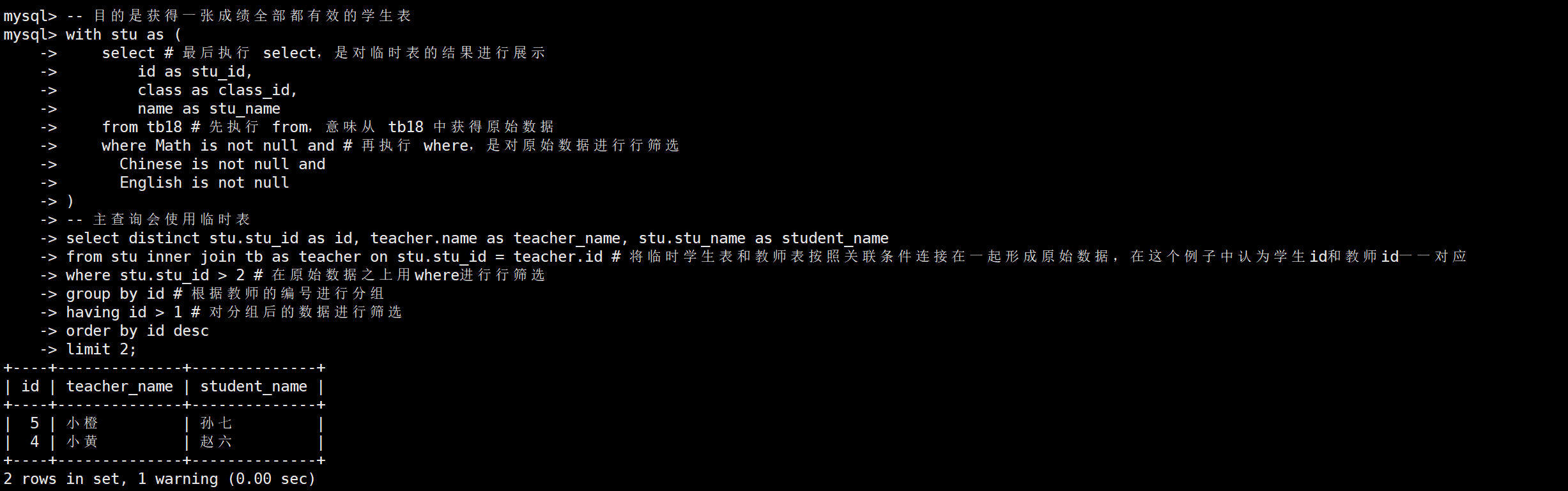
-- 目的是获得一张成绩全部都有效的学生表
with stu as (select # 最后执行 select,是对临时表的结果进行展示id as stu_id,class as class_id,name as stu_namefrom tb18 # 先执行 from,意味从 tb18 中获得原始数据where Math is not null and # 再执行 where,是对原始数据进行行筛选Chinese is not null andEnglish is not null
)
-- 主查询会使用临时表
select distinct stu.stu_id as id, teacher.name as teacher_name, stu.stu_name as student_name
from stu inner join tb as teacher on stu.stu_id = teacher.id # 将临时学生表和教师表按照关联条件连接在一起形成原始数据,在这个例子中认为学生id和教师id一一对应
where stu.stu_id > 2 # 在原始数据之上用where进行行筛选
group by id # 根据教师的编号进行分组
having id > 1 # 对分组后的数据进行筛选
order by id desc
limit 2;
以下是执行的结果
首先,with是最先执行的,用于提供临时表数据,以便后续和from进行连接。
其次,from、join、on是紧挨着执行的,on必须跟在join后面才行,作为关联条件。这三个关键词是将我们需要的表按照on关联规则连接起来形成一个原始数据表,后续的所有操作都是在这个原始数据表上进行的。我们对表取的别名可以用在后面语句上。
然后,就是where子句,是对原始数据进行行筛选,在这里可以用上表的别名了。
之后,在MySQL中执行select并对列明取别名,这个语句执行完就有初步的结果了,distinct会对这个结果根据需要展示的列进行去重,不展示的列不在去重考虑范围内。有的SQL中select是在分组后进行的,这导致那种情况下分组时无法使用列的别名。
之后,便是分组,根据分组参照对象值的不同分成不同组,使用它需要我们使用聚合函数或者能和分组参照对象的值形成一一对应的列来作为select的列,having就是在分组之后进行进一步筛选。
最后用order by和limit进行展示上的限制。



协议的全面解析:理论、机制与实践局限性)


![[SC]SystemC 常见的编译/语法错误与解法(三)](http://pic.xiahunao.cn/[SC]SystemC 常见的编译/语法错误与解法(三))



)



)




