PBR×BRDF原理&Unity实现深入浅出_哔哩哔哩_bilibili
进行改进
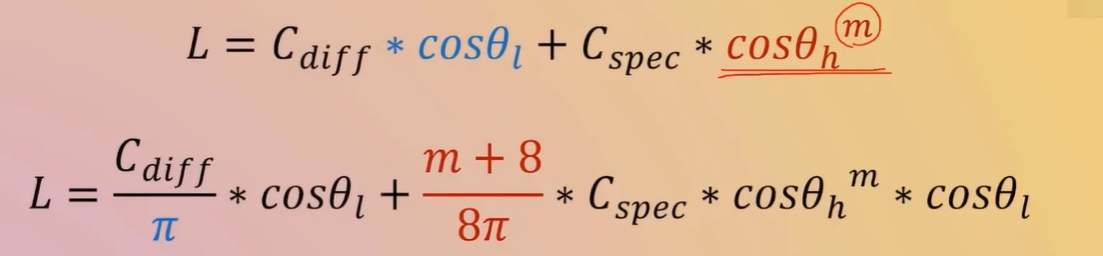
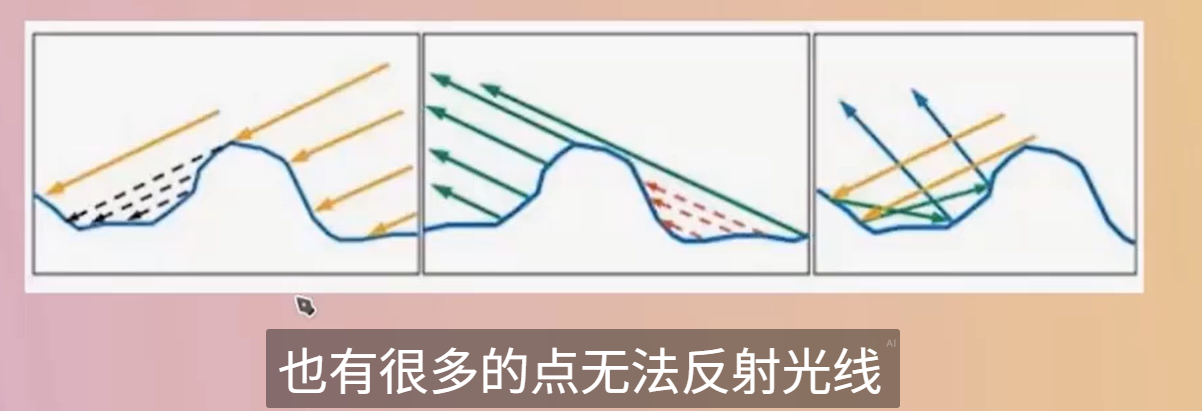
一个像素点对应一个范围内的 一个微表面--一个由无数个起起伏伏的结构组成的物理结构
屏幕上的每一个像素点,在渲染时通常会被视为一个“微表面”的代表
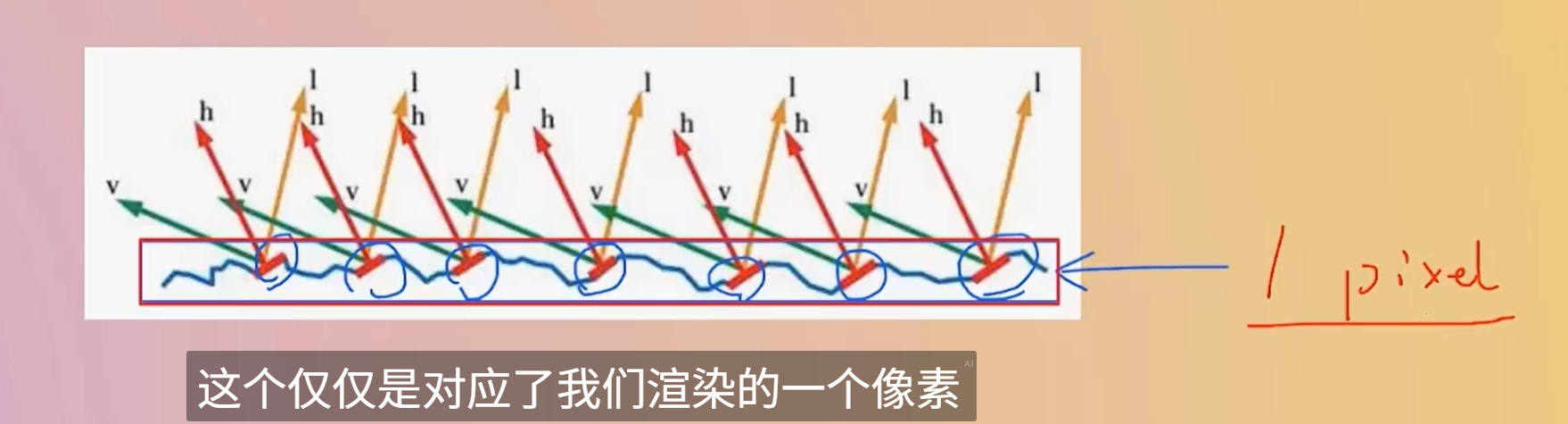
比如在这个图中,只关心红色的区域
float3 R = reflect(-L, N); // R 是 L 关于法线 N 的反射方向
float spec = pow(saturate(dot(R, V)), shininess);
xxx
半角更柔和,无需第四reflect vector,所以更适合做扩展--Cook-Torrance 等微表面模型
现代 PBR / BRDF,Half Vector 是必需的(Cook-Torrance 中 H 是中心变量)float3 H = normalize(L + V); // H 是光线方向 L 和视线方向 V 的中间向量
float spec = pow(saturate(dot(N, H)), shininess);
GGX 比 Blinn 更真实
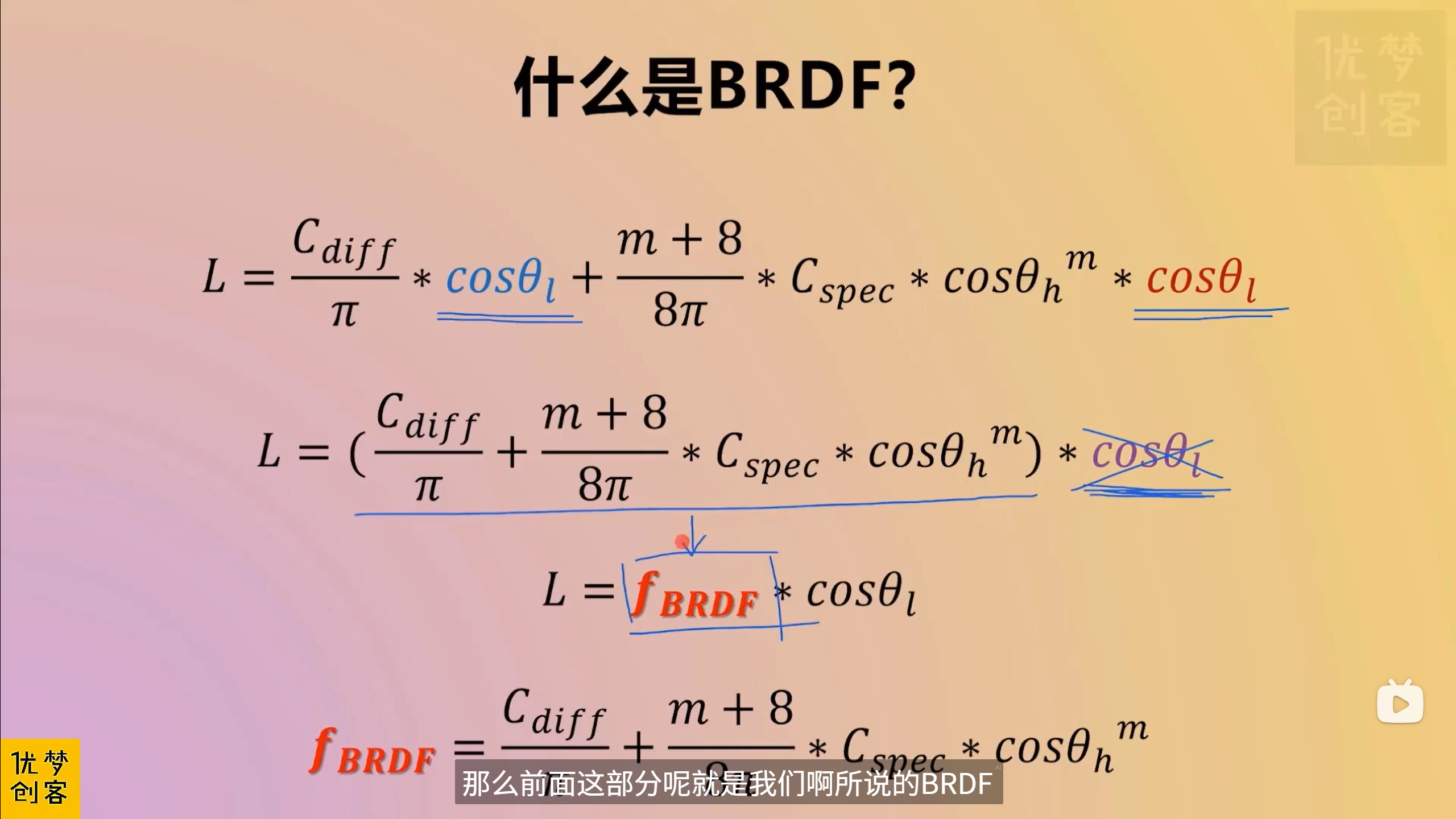
对于高光颜色的额外处理,整体起个名字--就是NDF normal distribution function
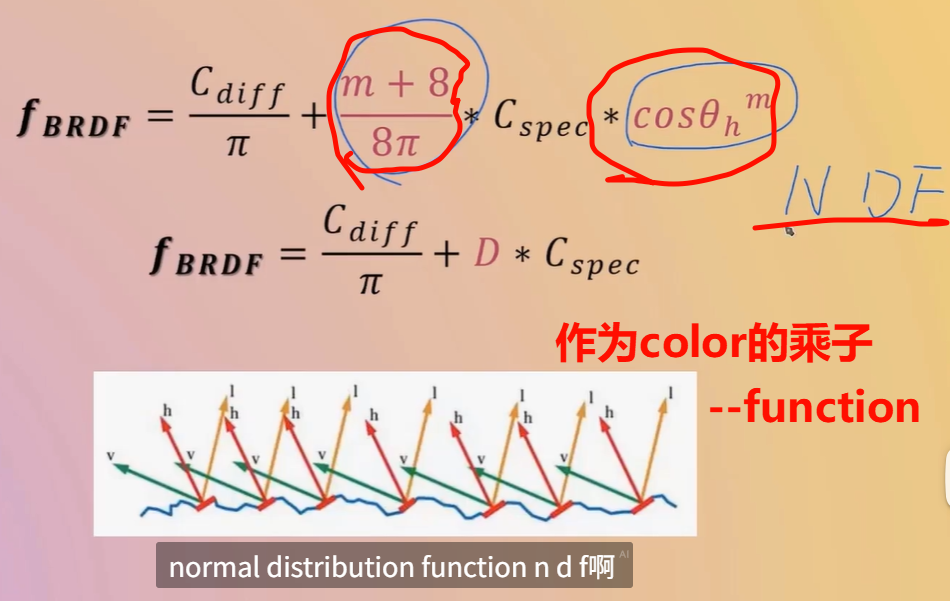
“某方向上的微镜面法线出现的概率密度”,即在单位立体角内,有多少微镜面法线与该方向对齐。这是描述表面粗糙程度的统计工具
Fresnel 项 F、几何遮蔽项 G 一起构成 Cook‑Torrance 等物理基础的镜面反射模型中的 D(分布项)
目前对于微表面,并没有加入表面本身的几何遮挡关系
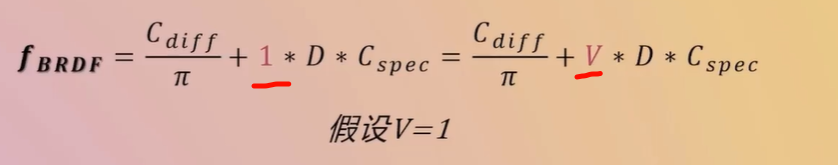
-
入射角越倾斜(越斜着看),反射光比例越大 → 更亮、更specular
-
入射角越垂直(正对看),反射光比例越小 → 更暗、更diff
-
是 角度相关的颜色变化核心因素
F 描述反射颜色比例,D 描述高光形状,G 描述遮挡和遮蔽

你问的是哪种“光追”?
“用一个 Shader 模拟出光追的感觉”
比如:
-
屏幕空间反射(SSR)
-
屏幕空间全局光照(SSGI)
-
Ray Marching 软阴影 / 反射 / 折射
-
Path Tracing 预览器(离线渲染风格)
✅ 那么答案是:可以,可以只用 Shader(或者 Shader + Compute)实现近似“光追”表现
“真的发出一条物理射线,穿过场景,检测与三角形的精确交点”(即 DXR)
那就要:
-
✅ 支持 GPU 硬件加速的光线追踪(DXR)
-
✅ Unity 的 HDRP 渲染管线
-
✅ 使用 RayTracingShader 资源文件,不是传统
.shader文件
👉 这就不是“一个普通 Shader 就能搞定”的事情了,而是 Unity 2021+ 在 HDRP 下才支持的高级功能。
xxx
SV_DispatchThreadID
SV_DispatchThreadID - Win32 apps | Microsoft Learn
SV_DispatchThreadID is the sum of SV_GroupID * numthreads and GroupThreadID.
-
Dispatch(2,2,2):意味着你在 CPU 端对每个维度都分配了 2 个线程组(groups)。 -
[numthreads(3,3,3)]:意味着每个线程组内部,在每个维度上又有 3 个线程。
所以:
-
GPU 会在三个维度上创建
(2 groups) × (3 threads per group) = 6个全局线程索引单位。 -
因为索引从 0 开始,所以范围是
0, 1, 2, 3, 4, 5,即 “0..5”。
换句话说:
-
id.x的取值范围是 0 到 5 -
id.y也是 0 到 5 -
id.z也是 0 到 5
这反映了每个维度上:共计 2 × 3 = 6 的线程覆盖范围。
全局线程 ID(即 SV_DispatchThreadID)的最大值为 (groupCount * threadsPerGroup) – 1,所以总数各自为 a*x, b*y, c*z,
但这三个维度一起形成了 线程的唯一 3D 全局坐标。并不是说存在三个 Buffer,它们是组合起来确定线程的“定位”。
| 概念 | 含义 |
|---|---|
Dispatch(A,B,C) | CPU 发起的线程组数量 |
[numthreads(X,Y,Z)] | 每个线程组内部的线程数量 |
id.x | 全局 X 轴线程索引,范围 0..(A×X - 1) |
id.y | 全局 Y 轴线程索引,范围 0..(B×Y - 1) |
id.z | 全局 Z 轴线程索引,范围 0..(C×Z - 1) |
| 三者合并 | 构成一个线程在三维空间中的唯一位置(uint3) |
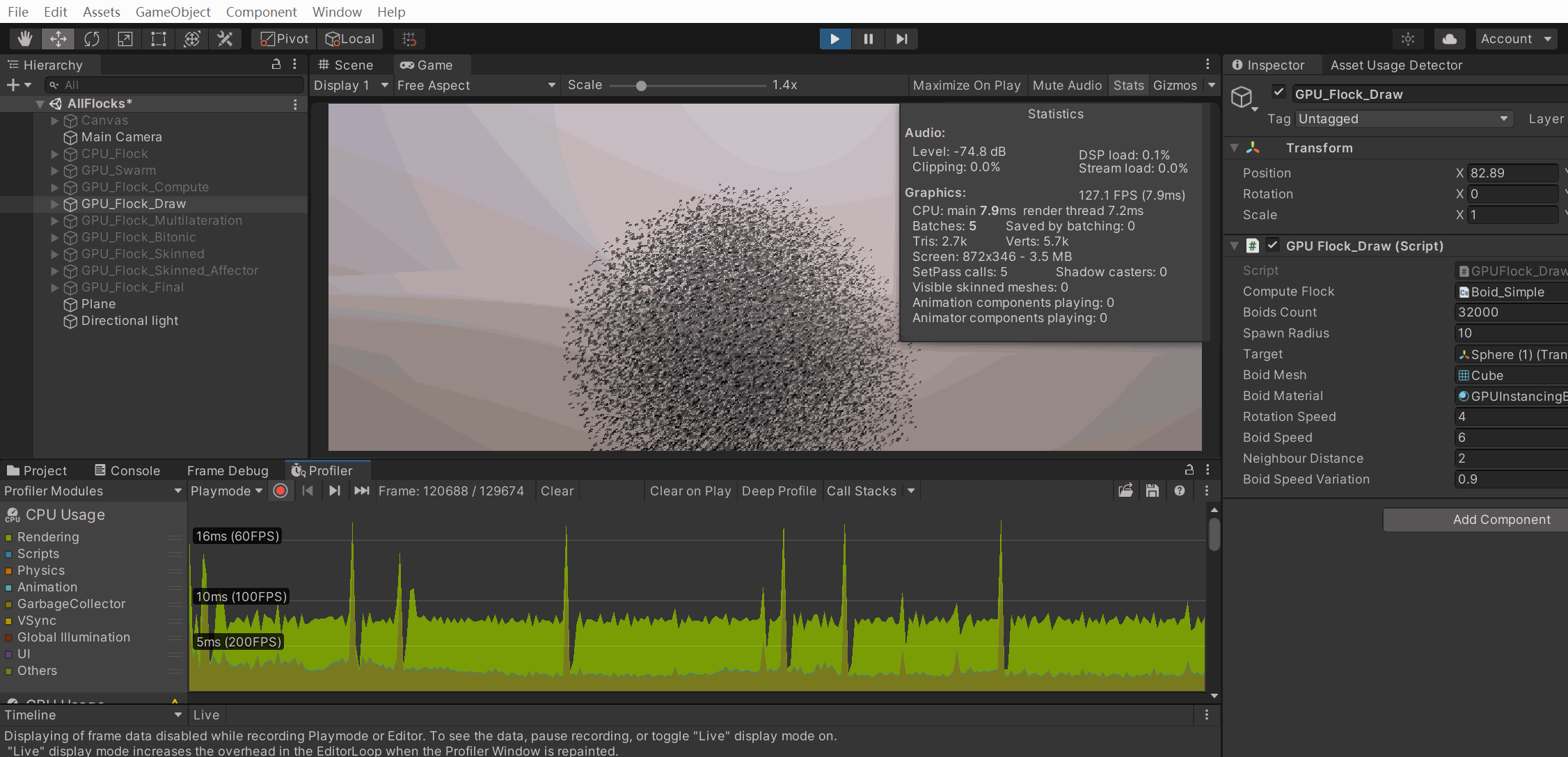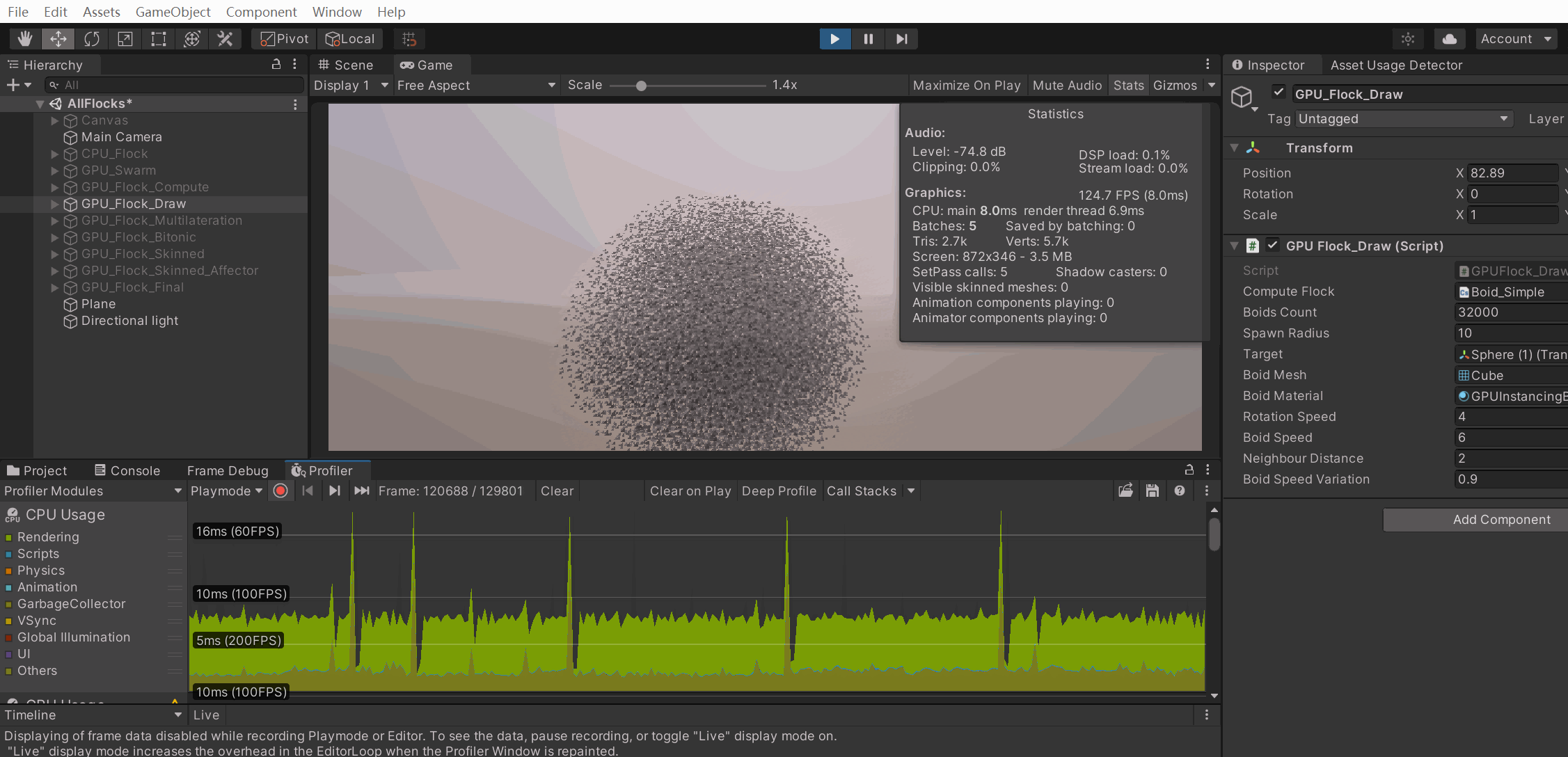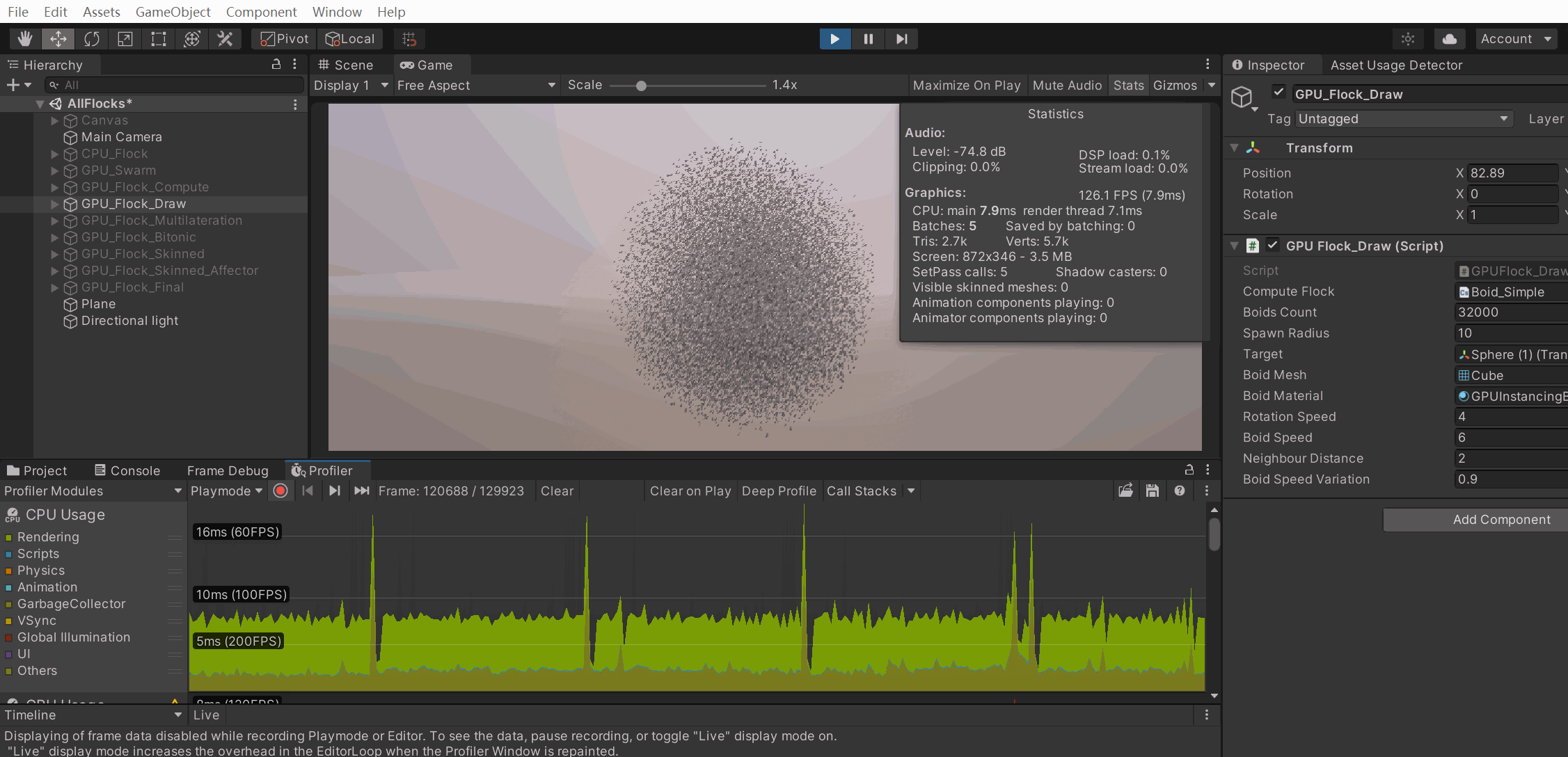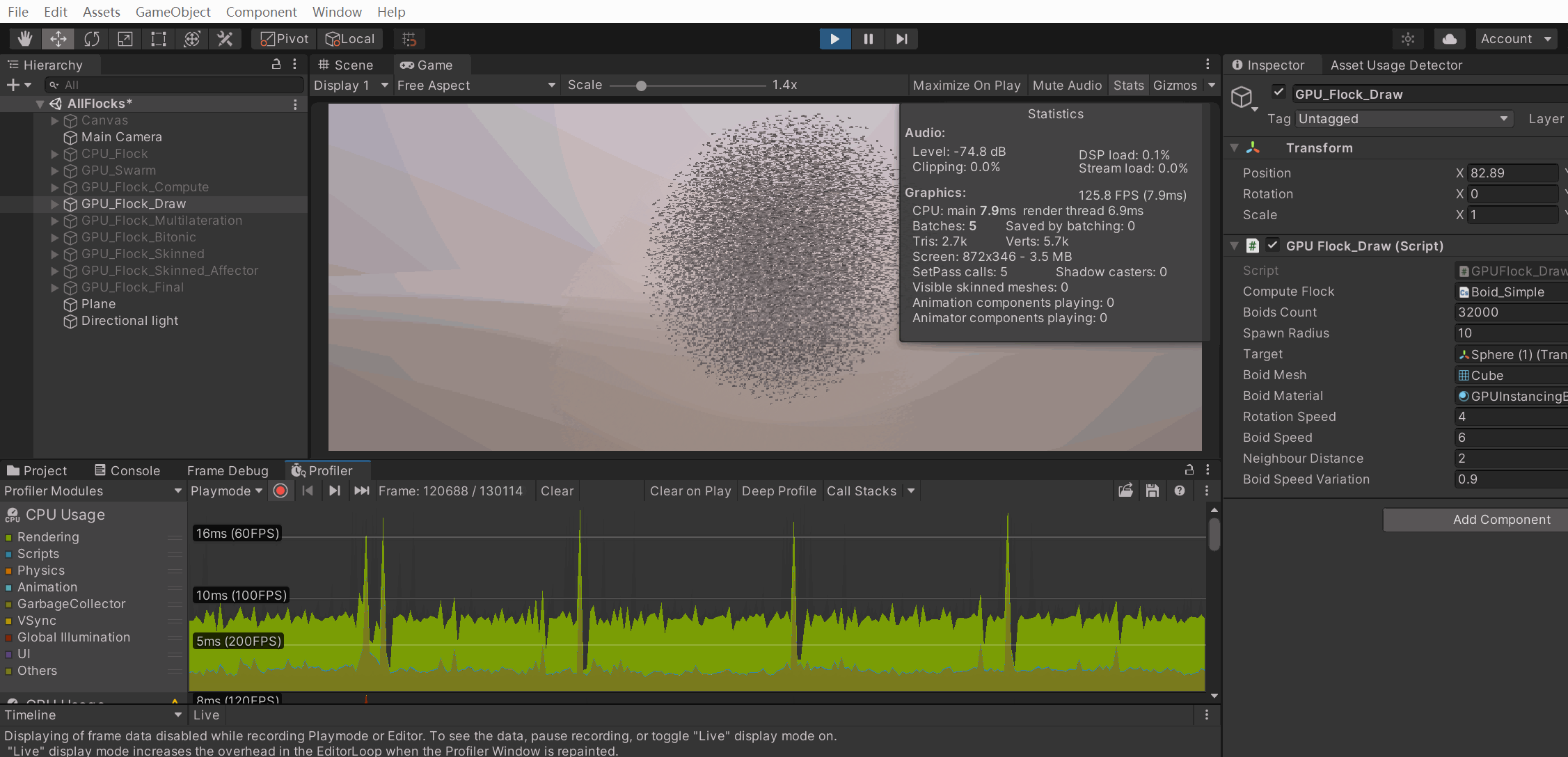
我去,三万多条三角形,,居然只10,ms不到,,牛哭了
Compute Shaders
For 40,000 points that's 2.56 million bytes—roughly 2.44MiB—that has to be copied to the GPU every time the points are drawn. URP has to do this twice per frame, once for shadows and once for the regular geometry. BRP has to do it at least three times, because of its extra depth-only pass, plus once more for every light besides the main directional one.
it would be ideal if that data only exists on the GPU side.
the CPU can no longer calcuate the positions, the GPU has to do it instead. Fortunately it is quite suited for the task.
https://docs.unity3d.com/ScriptReference/SerializeField.html
When Unity serializes your scripts, it only serializes public fields. If you also want Unity to serialize your private fields you can add the SerializeField attribute to those fields.
To store the positions on the GPU we need to allocate space for them. We do this by creating a ComputeBuffer object
https://docs.unity3d.com/ScriptReference/ComputeBuffer.html
Compute buffers are always supported in compute shaders. Compute shader support can be queried runtime using SystemInfo.supportsComputeShaders. See the Compute Shaders Manual page for more information about platforms supporting compute shaders. In regular graphics shaders the compute buffer support requires minimum shader model 4.5.
A compute buffer contains arbitrary untyped data. We have to specify the exact size of each element in bytes, via a second argument.
positionsBuffer = new ComputeBuffer(resolution * resolution, 3 * 4);store 3D position vectors, which consist of three float numbers, so the element size is three times four bytes.
Thus 40,000 positions would require 0.48MB or roughly 0.46MiB of GPU memory.
This gets us a compute buffer, but these objects do not survive hot reloads, which means that if we change code while in play mode it will disappear.
deal with this by replacing the Awake method with an OnEnable method, which gets invoked each time the component is enabled.
This happens right after it awakens—unless it's disabled—and also after a hot reload is completed.
Besides that we should also add a companion OnDisable method, which gets invoked when the component is disabled, which also happens if the graph is destroyed and right before a hot reload.
Have it release the buffer, by invoking its Release method. This indicates that the GPU memory claimed by the buffer can be freed immediately.
“热重载”(Hot Reload)是 Unity 编辑器中非常实用的一项功能,它允许你在**游戏仍在运行(Play Mode)**或编辑器处于打开状态时,修改并保存脚本后无需重启,Unity 会自动应用这些更改。
为什么推荐用 OnEnable() 而不是 Awake()?
-
Awake()通常只在脚本加载时执行一次,但在热重载后 Unity 的对象生命周期会被重置,你很可能不会得到一个新的 Awake 调用。 -
相对而言,
OnEnable()会在组件每次被启用或在热重载完成后调用,这使它成为重新初始化临时对象(例如 Compute Buffer)更可靠的地方。
由于在此之后我们将不再使用此特定对象实例,因此将字段显式设置为引用null是个好主意。这使得在运行模式下,如果我们的图被禁用或销毁,对象在下一次运行时可以被Unity的内存垃圾回收过程回收。
void OnDisable () {positionsBuffer.Release();positionsBuffer = null;}
如果没有任何引用指向该对象,垃圾回收器最终会回收它。但这种情况发生的时间是任意的。最好尽快显式释放它,以避免内存堵塞。
为了在GPU上计算位置,我们必须为其编写一个脚本,具体来说是一个计算着色器。Create one via Assets / Create / Shader / Compute Shader。它将成为我们FunctionLibrary类的GPU等效物,因此也命名为FunctionLibrary。虽然它被称为着色器并使用HLSL语法,但它作为一个通用程序运行,not a as regular shader used for rendering things.
GPU hardware contains compute units that always run a specific fixed amount of threads in lockstep.这些被称为warp或wavefront
If the amount of threads of a group is less than the warp size some threads will run idle, wasting time. If the amount of threads instead exceeds the size then the GPU will use more warps per group. In general 64 threads is a good default, as that matches the warp size of AMD GPUs while it's 32 for NVidia GPUs, so the latter will use two warps per group. 实际上,硬件更复杂,可以对线程组做更多的事情,但这对我们简单的图形不相关。
numthreads的三个参数可以用来在一维、二维或三维中组织线程。例如,(64, 1, 1)给我们提供了一个维度的64个线程,而(8, 8, 1)给我们相同数量的线程,但以2D 8×8正方形网格的形式呈现。由于我们根据2D UV坐标定义点,因此让我们使用后者选项。
[numthreads(8, 8, 1)]
Each thread is identified by a vector of three unsigned integers, which we can access by adding a uint3 parameter to our function.
我们可以将线程标识符转换为UV坐标,如果我们知道图形的步长。为它添加一个名为_Step的计算机着色器属性,就像我们为表面着色器添加_Smoothness属性一样。
https://www.youtube.com/watch?v=jbuGYhRWAkY
MaterialPropertyBlock - Unity 脚本 API
MaterialPropertyBlock is used by Graphics.RenderMesh and Renderer.SetPropertyBlock. Use it in situations where you want to draw multiple objects with the same material, but slightly different properties. For example, if you want to slightly change the color of each mesh drawn. Changing the render state is not supported.
Unity 的地形引擎使用 MaterialPropertyBlock 绘制树;它们全都使用 相同材质,但是每棵树具有不同的颜色、缩放和风力系数。
Note that this is not compatible with SRP Batcher. Using this in the Universal Render Pipeline (URP), High Definition Render Pipeline (HDRP) or a custom render pipeline based on the Scriptable Render Pipeline (SRP) will likely result in a drop in performance.
var props = new MaterialPropertyBlock();
renderer.GetPropertyBlock(props);
props.SetColor("_Color", Color.red);
renderer.SetPropertyBlock(props);
这段代码演示了如何为某个 Render 对象设置专属颜色,而无需创建新材质。Unity 的 GPU 间接实例化渲染(Instanced Indirect Rendering)
// 设置材质缓冲区并进行间接实例化绘制BoidMaterial.SetBuffer("boidBuffer", BoidBuffer);Graphics.DrawMeshInstancedIndirect(BoidMesh, 0, BoidMaterial,new Bounds(Vector3.zero, Vector3.one * 1000),_drawArgsBuffer, 0, _props);// 将 GPU 中的 BoidBuffer 绑定到材质,以便 Shader 内访问
BoidMaterial.SetBuffer("boidBuffer", BoidBuffer);// 用 GPU 进行间接实例化绘制
Graphics.DrawMeshInstancedIndirect(
BoidMesh, // 要实例化的 Mesh
0, // 子网格索引(一般为 0)
BoidMaterial, // 使用的材质
new Bounds(Vector3.zero, Vector3.one * 1000), // 包围盒,用于剔除优化
_drawArgsBuffer, // 包含绘制参数的 GPU 缓冲(Indirect Args)
0, // 参数缓冲偏移
_props // 可选的 MaterialPropertyBlock,用于覆盖材质属性
);
GPU 加速批量绘制(Instanced Indirect)
传统方式中,每帧 CPU 都会上传实例数据给 GPU,耗性能。
DrawMeshInstancedIndirect 方法则让渲染指令和实例数量来源于 GPU 缓冲 _drawArgsBuffer
GPU 自行决定绘制多少实例
参数缓冲(argsBuffer)
该缓冲需要包含 5 个组成的整数数组,按照顺序分别代表:
-
每个实例的索引数量(index count)
-
实例总数
-
开始索引位置(start index)
-
基础顶点偏移(base vertex)
-
开始实例偏移(start instance)
public struct GPUBoid_Draw
{public Vector3 position; // 3 × 4 = 12 bytespublic Vector3 direction; // 12 bytespublic float noise_offset; // 4 bytespublic Vector3 padding; // 12 bytes
}
position + direction = 24 bytesnoise_offset = 4 bytes → 总共 28 bytesGPU 更倾向于 16 字节对齐,所以下面会进行对齐填充为了让结构体对齐到 32 bytes(即 2 个 16‑byte 块),你添加了 padding,这使得整个结构体容量为 24 + 4 + 12 = 40 bytes,在 GPU 端更容易对齐甚至安全访问。对齐问题的风险
如果忽视对齐规则,很可能导致:
-
读取异常或数据错位:例如
noise_offset实际读取的是direction的部分数据。 -
GPU 崩溃或异常渲染:尤其使用
StructuredBuffer<T>时,对齐偏差会引起 shader 崩溃或数据错乱。
举个简单的例子来说明
假设你定义了这样一个 struct:
struct Example {Vector3 a; // 占 12 字节float b; // 占 4 字节float c; // 占 4 字节
}
整体看起来占 20 字节,但 GPU 可能仍然会按 16 字节的块来读取:
-
第一块(16 字节)包含
a(12 字)和b(4 字); -
第二块(16 字节)只剩下
c(4 字),剩余 12 字节是空的(未定义)。 -
如果没有填充,GPU “无法知道”
c应该读在哪里,就会出错。
bounds 参数:它为什么必须要提供?
-
视锥剔除(Frustum Culling)
bounds参数定义了一个包围盒(AABB,Axis-Aligned Bounding Box),它用于告诉渲染系统所有要绘制实例的空间范围。引擎会基于此计算是否需要在当前帧渲染这些实例
→ 如果这个包围盒完全或部分在相机视锥内,这才可能执行绘制操作;如果包围盒完全在视野之外,那么整个实例绘制就会被剔除以节省性能。 -
批处理与 GPU 调度
在 GPU 调用中传入bounds明确告诉引擎在哪个区域中要进行实例化绘制,有助于引擎更好地组织和优化 GPU 工作,尤其是在使用大规模实例渲染(instanced indirect)技术时。
-
BoidMesh:要渲染的网格模型。 -
BoidMaterial:使用的材质及其着色器定义,管理视觉表现。 -
bounds:表示所有实例在世界空间里可能占据的范围。 -
_drawArgsBuffer:一个 GPU 计算缓冲区(ComputeBuffer),包含了DrawMeshInstancedIndirect所需的数据,如实例数量、顶点索引起始等(通常通过 Compute Shader 填充)。 -
_props:一个材质属性块(MaterialPropertyBlock),允许传递实例级别或批次级别的 Shader 数据,比如变换矩阵、颜色等。
这些参数共同构成了 GPU 渲染指令的完整信息流:
(mesh, material, instance count/arguments, world-space region, shader properties)
假设你用它来渲染成百上千只“Boid”鸟群,每只有不同的位置和形态:
-
ComputeShader 计算每帧的 boid 位置、旋转等数据,并写入
_drawArgsBuffer与_props。 -
然后调用
Graphics.DrawMeshInstancedIndirect,传入这些数据。 -
Unity 使用你设定的
bounds(例如(0,0,0), size (1000,1000,1000))告诉 GPU 这些 boid 可能都散布在这个范围里。 -
若这个包围盒根本不在镜头里,那么一切实例渲染就会被省略,提高渲染效率。
-
bounds参数关键在于 向渲染系统声明实例的空间分布范围,以便进行正确的剔除与调度优化。 -
它与其他参数(mesh、material、draw buffer、properties)一同构成了 GPU 批量实例绘制的完整逻辑链条。
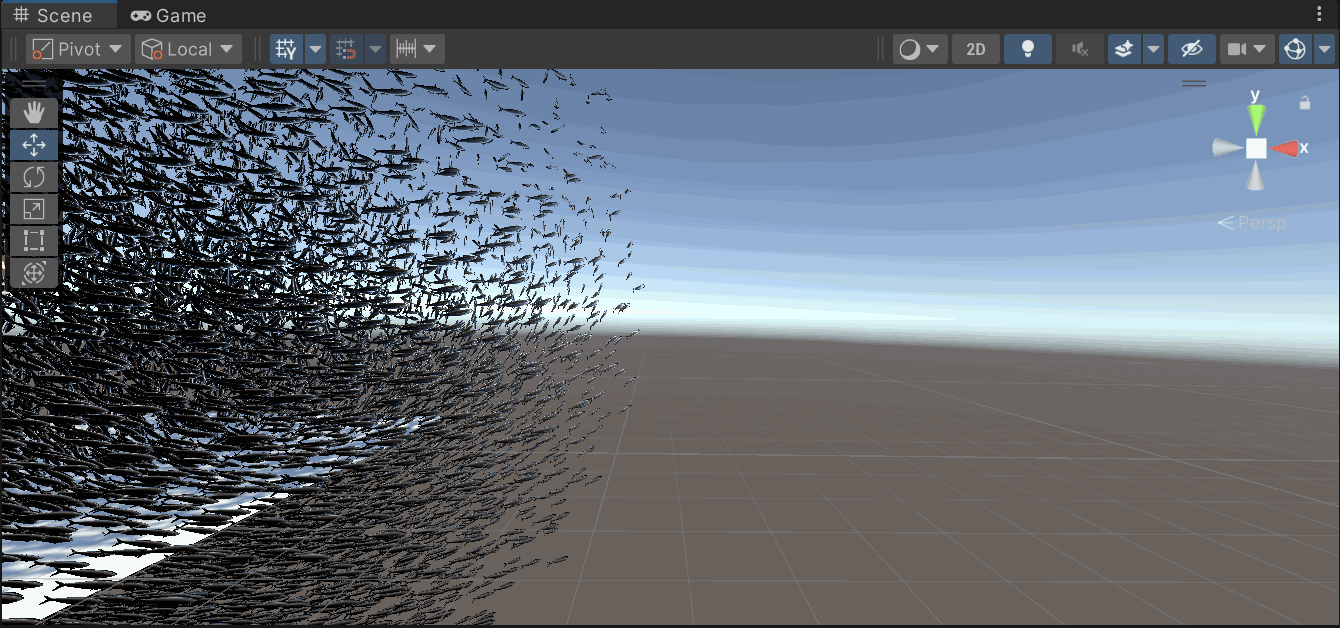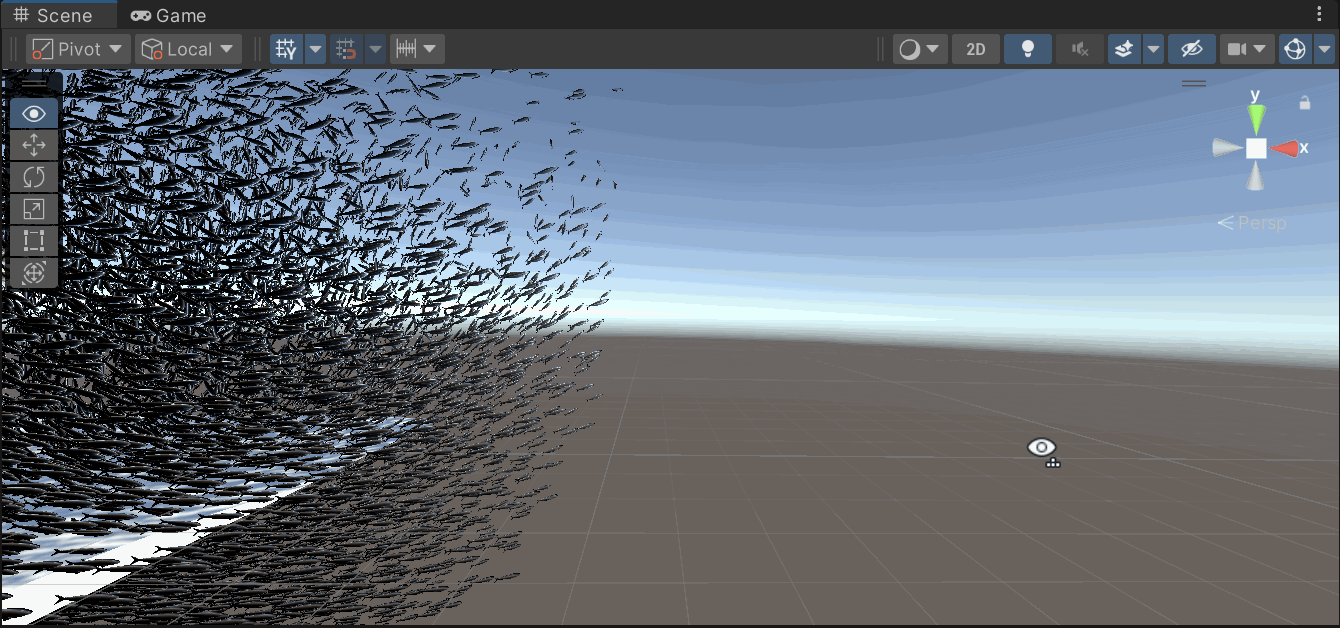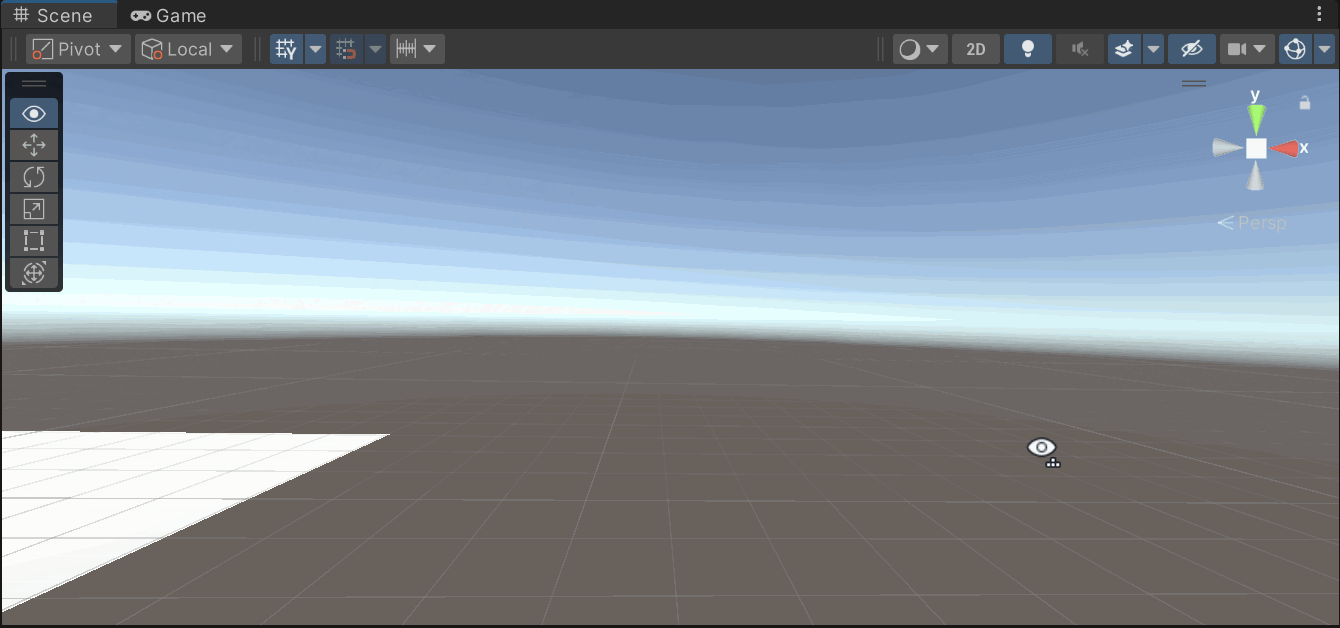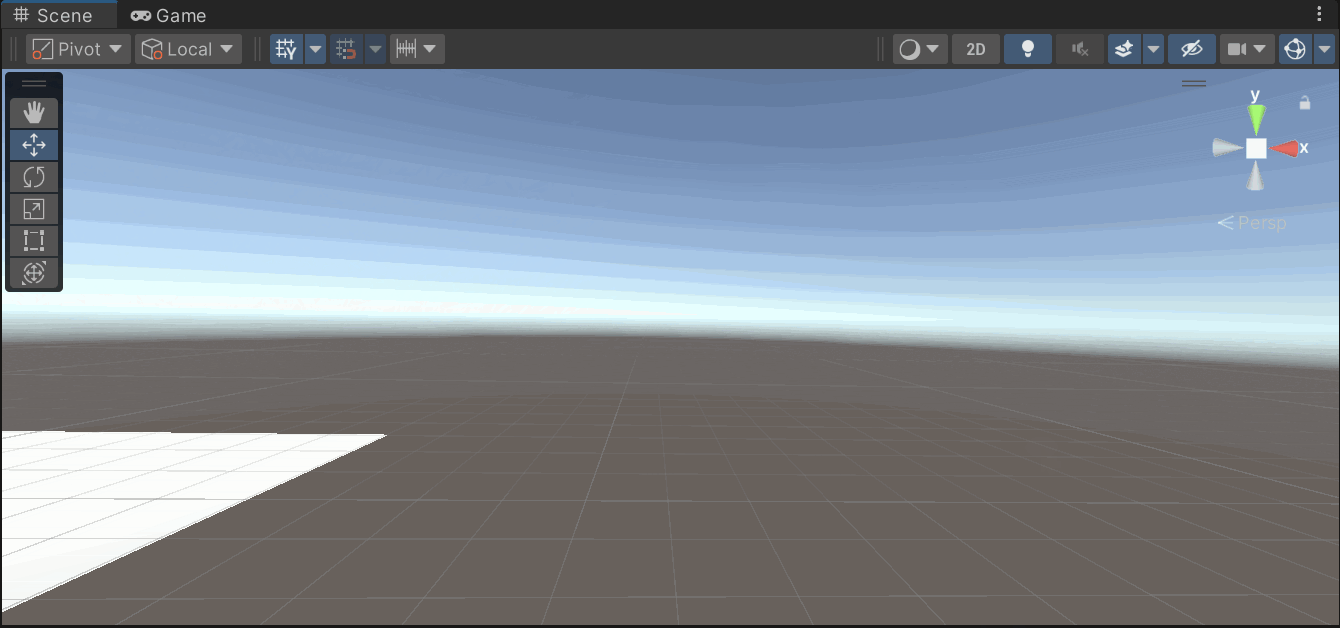
唯一发现的影响就是这样的,bound至少在这个问题上有解决的,也的确和剔除什么的有点关系

_drawArgsBuffer(ComputeBuffer)
-
作用:
-
这是一个 GPU 缓存区,存储了绘制参数,比如实例数(instance count)、每实例的顶点偏移、索引偏移等控制绘制过程的底层数据。
-
通常,由 Compute Shader 每帧更新,提升 GPU-side 实例绘制的效率。
-
-
用途限制:
-
它只负责绘制的数量和方式,不包含材质或 Shader 参数等内容。
-
MaterialPropertyBlock
-
作用:
-
用于在渲染调用层面动态传递材质参数,比如每个实例的颜色、位置变换、贴图索引、特效参数等。
-
通过它可修改材质属性而不创建新的材质实例,节省性能开销。
-
-
与实例属性结合:
-
比如你想让每只 boid 颜色不同、朝向不同,或具备个性化的动画参数,就会用 MaterialPropertyBlock 将这些信息传入 Shader。
-
-
_drawArgsBuffer管理的是“几个实例要绘制、绘制方式”; -
MaterialPropertyBlock管理的是“这些实例呈现什么效果、使用哪些材质参数”。
-
即使你把所有数据写入 ComputeBuffer,也难以直接在传统 Shader 里访问和解析,而且 Shader 不直接读取 ComputeBuffer 中的数据作为材质属性。
-
而 MaterialPropertyBlock 是 Unity 渲染机制内建的方式,专门为每个渲染调用定制属性值。
MaterialPropertyBlock 将具体的 per-instance Shader 参数(如 Matrix、Color)封装传入 Draw 调用。
UNITY_PROCEDURAL_INSTANCING_ENABLED
这个宏 只在使用 Graphics.DrawMeshInstancedIndirect(或 Procedural Instancing)时启用。它与普通 GPU Instancing 的宏不同,而是专用于更底层、更灵活的实例化路径(即“procedural”方式)。
通常,你需要在 Shader 中写上:
#pragma multi_compile_instancing
#pragma instancing_options procedural:setup
procedural:setup 会把你的 setup() 函数(或指定函数)当作处理每个实例数据的入口,并激活宏 UNITY_PROCEDURAL_INSTANCING_ENABLED
------所以_drawArgsBuffer就是用来标记这个shader的
正确初始化 out 类型的 Input 结构体(通常被命名为 o 或 data)
void vert(inout appdata_full v, out Input data)
{
UNITY_INITIALIZE_OUTPUT(Input, data);
}
UNITY_INITIALIZE_OUTPUT 的作用是什么?
-
它是 Unity 提供的一个宏,用于给输出结构体(如
Input data)中的所有字段赋初值(通常为零)。 -
在某些平台(尤其是 D3D、Mobile)上,如果输出结构体的字段没有被完全初始化,就会引发渲染警告甚至错误。使用该宏能有效避免这些问题。
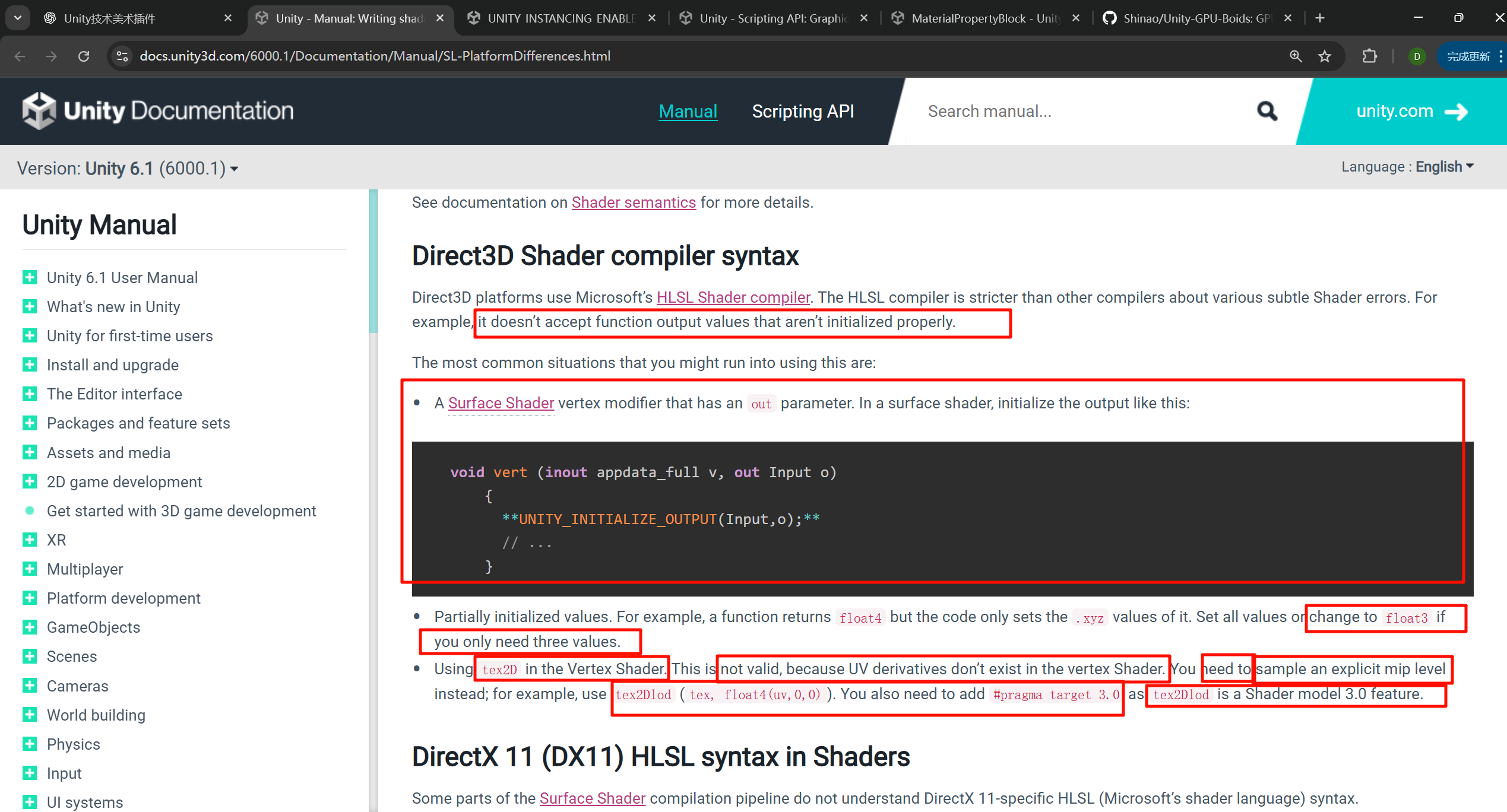
为了dx
Direct3D platforms use Microsoft’s HLSL Shader compiler. The HLSL compiler is stricter than other compilers about various subtle Shader errors. For example, it doesn’t accept function output values that aren’t initialized properly.
look_at_matrix
// 计算朝向矩阵float4x4 look_at_matrix(float3 at, float3 eye, float3 up){// 计算 z 轴方向(目标点到观察点的方向向量)float3 zaxis = normalize(at - eye);// 计算 x 轴方向(up 向量与 z 轴的叉积,表示水平向量)float3 xaxis = normalize(cross(up, zaxis));// 计算 y 轴方向(z 轴与 x 轴的叉积,表示垂直向量)float3 yaxis = cross(zaxis, xaxis);// 返回 4x4 矩阵,表示从 eye 看向 at 的变换矩阵return float4x4(xaxis.x, yaxis.x, zaxis.x, 0, // 第一列:x 轴方向xaxis.y, yaxis.y, zaxis.y, 0, // 第二列:y 轴方向xaxis.z, yaxis.z, zaxis.z, 0, // 第三列:z 轴方向0, 0, 0, 1 // 第四列:齐次坐标);}典型的 “Look‑At” 朝向矩阵 构造函数(常用于生成相机或物体朝向目标的旋转矩阵)
三个输入参数—目标位置 (at)、观察者位置 (eye) 和 上方向向量 (up)
转化为一个 4×4 的变换矩阵(旋转变换)
| x.x, y.x, z.x, 0 |
| x.y, y.y, z.y, 0 |
| x.z, y.z, z.z, 0 |
| 0, 0, 0, 1 |
按照 HLSL “行主序”解析是正确的。在 Unity 中,这样的矩阵设置表现为首三列是旋转轴,最后一列是齐次(平移为零,保持 1)。
-----首先搞清楚坐标系,是脚本的本地坐标系
HLSL 中,如果你用 float3 与 float4x4 相乘,系统默认将该 float3 当作 float4(x, y, z, 0) 来处理——也就是说,默认设置了 w = 0
这意味着该向量不会受到矩阵中的平移分量影响,因为 w = 0 的情况下,平移那一行的计算乘积为零,不会加上任何偏移值。
因此,整个变换只会应用旋转与缩放部分,产生的是一个旋转后的向量。
| 输入类型 | 输出效果 |
|---|---|
float3 × 4×4 矩阵(无平移,或平移有但 w = 0) | 纯旋转(+ 缩放)结果 |
float4(x, y, z, 1) × 4×4 矩阵 | 包含平移的完整变换 |
假设你有一个方向向量要在 Shader 中旋转但不想添加任何位移,此时你直接写:
HLSL 会自动当作 float4(oldDir, 0),所以自然只会产生旋转后的结果。
一个向量的第四位只有0和1,如果是1,此时参与矩阵变换,没有则无,如果矩阵中有不是0001的第四行和第四列,这个向量就一定会参与位移
w = 1 代表“点”,因此变换中会包括平移;w = 0 代表“向量”,不会受到平移部分的影响。
“If w = 0, then the translation part is ignored... if w = 1, the point is translated... if w = n, translation is scaled by n.”
— from GameDev.net discussion Unity Community+8GameDev+8GameDev+8
在数学上,使用 w = 1 搭配转换矩阵,可以实现“点加位移”,而 w = 0 时则只执行线性变换(如旋转),不包含平移。
这是齐次坐标系统的标准用法,非常适合于图形渲染管线。
https://docs.unity3d.com/410/Documentation/ScriptReference/Matrix4x4.MultiplyPoint.html
Returns a position v transformed by the current fully arbitrary matrix. If the matrix is a regular 3D transformation matrix, it is much faster to use MultiplyPoint3x4 instead. MultiplyPoint is slower, but can handle projective transformations as well.
xxxxx
BoidMaterial.SetBuffer("boidBuffer", BoidBuffer);
为什么是Material类去绑定而不是shader类呢,明明计算的逻辑是写在shader里的
背后,体现了 Unity 的面向材质(Material-oriented)渲染机制。
-
Shader 是不具状态的程序模板;
-
Material 是 Shader 的具体实例,包含该 Shader 使用的参数(如贴图、颜色、缓冲数据等)。
因此,缓冲区(ComputeBuffer)必须通过 Material 才能绑定给具体的渲染调用。
Material.SetBuffer:在 GPU 渲染调用中传参
Unity 的 Material.SetBuffer(string name, ComputeBuffer value) API 的职责是将 ComputeBuffer 绑定到材质的某个属性名(比如 "boidBuffer"),然后在实际的渲染调用中,Shader 便能读取这个缓冲区
你可能会问:为什么不是写在 Shader 里?原因如下:
-
Shader 是静态的模板,不管理具体缓冲;
-
Material 才是实例化 Shader 并携带参数的东西;
-
只有通过 Material 才能在渲染阶段将缓冲数据传递给 GPU。
与 ComputeShader 的 SetBuffer 区别
虽然代码中逻辑是在 ComputeShader 中执行,但渲染的 Shader(例如用于 Instancing 或普通渲染的 Surface Shader)并不会自动从 ComputeShader 拿缓冲。需要显式地绑定到 Material 上。
computeShader.SetBuffer(kernel, "boidBuffer", BoidBuffer);
...
BoidMaterial.SetBuffer("boidBuffer", BoidBuffer);
这是两步流程:先 GPU 计算出数据,再通过 Material 把数据传给渲染 Shader。



:用 ProgressBar+Timer 打造动态进度展示功能)
)








)





)