本文章记录观看B站python教程学习笔记和实践感悟,视频链接:【花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)】 https://www.bilibili.com/video/BV1wD4y1o7AS/?p=6&share_source=copy_web&vd_source=404581381724503685cb98601d6706fb
上节课学习本章总结,章节选择题,实战一:计算圆的面积和周长,实战二:定义学生类录入5个学生,实战三:使用面对对象思想实现乐队演奏,实战四:使用面向对象思想编写出租车和家用轿车类,本节课学习模块的简介及自定义模块,模块的导入,Python中的包,主程序运行,Python中常用的内置模块及random模块中常用函数的使用。
下面进入第十章(第一章是python的安装没有在博文中体现,这里标注的九是从第二章开始的),关于程序的模块,我认为是比较重要的一部分,因为后续写论文编写代码都是依靠这个框架搭建。

1.模块的简介及自定义模块


如何定义模块:
#模型的定义,命名这个文件名为my_info,因为模块名称必须为小写字母和下划线
#定义模块的变量
#定定义模块的函数
name='L'
def info():print(f'大家好我叫{name}')2.模块的导入

两个调用方式如上。具体使用案例如下:
首先我们定义两个模块(两个python文件)
模块一my_info.py:
name='L'
def info():print(f'大家好我叫{name}')模块二introduce.py:
name='K'
age=18
def info():print(f'姓名:{name},年龄:{age}')使用上面两个模块,导入:
#(1)调用模块的方法:import以后使用“模块名.函数名()”
import my_info
print(my_info.name)
my_info.info()#还可以“模块别名.函数名()”
import my_info as a
print(a.name)
a.info()#(2)from..import..
from my_info import name #导入的一个具体的变量的名称
from my_info import info #导入的一个具体的函数的名称
print(name) #此时不需要“模块名.”,直接使用变量名和函数名
info()#通配符,意思就是调用这个模块里面的所有内容
from my_info import *
print(name)
info()#同时导入多个模块,用逗号分割
import math,time,random如果有两个模块的变量和函数名字一样,那么如何处理这种情况:
from my_info import *
from introduce import *
#导入模块中具有同名的变量和函数,后导入的会将之前导入的覆盖
info()#如果我既想使用info中的函数也想使用introduce的函数,也就是不想覆盖其中一个方案
#解决方案:使用import
import my_info
import introduce
#使用模块中的函数或变量时,模块名打点调用
my_info.info()
introduce.info()运行结果如下:
姓名:K,年龄:18
大家好我叫L
姓名:K,年龄:18进程已结束,退出代码为 03.Python中的包
你也许经常从师兄师姐那里听到做科研就是“调包”,那么什么是调包?包又是个什么东西?

包的作用是避免模块名称相冲突的问题,一个包类似于电脑中一个文件夹,它只比文件夹多了一个叫做initpy的文件,将功能相似的模块放入一个包内从而方便模块的组织和管理。注意建立包的时候的名字必须是英文不允许出现汉字。
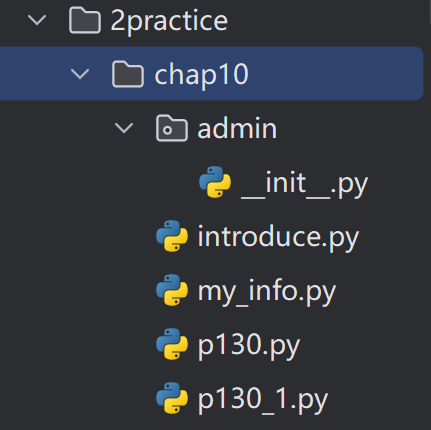 可以看到chap10文件夹和名为admin的包的区别就是,包一旦创建就会有_init_.py这个文件。在编写包的时候可以编写这个_init_.py也可以不编写,比方说我们可以在_init_.py这个文件里编写下面这些内容:
可以看到chap10文件夹和名为admin的包的区别就是,包一旦创建就会有_init_.py这个文件。在编写包的时候可以编写这个_init_.py也可以不编写,比方说我们可以在_init_.py这个文件里编写下面这些内容:
print('Hello World!')
print('How are you?')
选中admin这个包,单击右键选择新建python文件,比如我们命名为my_admin.py具体内容如下:
def info():print('大家好,我叫ysj,今年18岁')
name='ysj'
在chap10这个文件中新建一个python文件,想办法能从包中调用模块,语法为“包名.模块名”或者“from 包名 import 模块名 as 别名”,还有“from 包名.模块名 import 函数/变量等”内容可以编写如下:
import admin.my_admin as a #包名.模块名 其中admin为包名,my_admin为模块名(模块就是那个对应的python文件)
a.info() #此时一定会先执行_init_的内容,而且是自动执行的print('-'*40)
from admin import my_admin as b #from 包名 import 模块名 as 别名
b.info()print('-'*40)
from admin.my_admin import info #from 包名.模块名 import 函数/变量等
info() #此时在使用info这个函数的时候直接调用名字即可,不需要说明哪一个模块from admin.my_admin import * #from 包名.模块名 import *
print(name)运行结果如下:
Hello World!
How are you?
大家好,我叫ysj,今年18岁
----------------------------------------
大家好,我叫ysj,今年18岁
----------------------------------------
大家好,我叫ysj,今年18岁
ysj进程已结束,退出代码为 04.主程序运行

现在有两个模块model_a和model_b,前者的内容如下:
print('welcome to Beijing')
name='ysj'
print(name)model_b的内容如下:
#导入的代码
import model_a此时执行model_b的代码输出的结果就是运行model_a的内容:
welcome to Beijing
ysj进程已结束,退出代码为 0那么如果我们不想要执行model_a的内容,像是
if __name__ == '__main__':
只需要先打上main,然后回车main就会自动变成上面这一行。将model_a修改为如下内容:
# print('welcome to Beijing')
# name='ysj'
# print(name)
if __name__ == '__main__':print('welcome to Beijing')name='ysj'print(name)此时再运行model_b就不会再输出上面的内容,它阻止了全局变量的数据被输出,也就是说在被调用模块的时候,需要将不希望输出的内容放进if main结构(主程序代码)里面。
5.Python中常用的内置模块及random模块中常用函数的使用
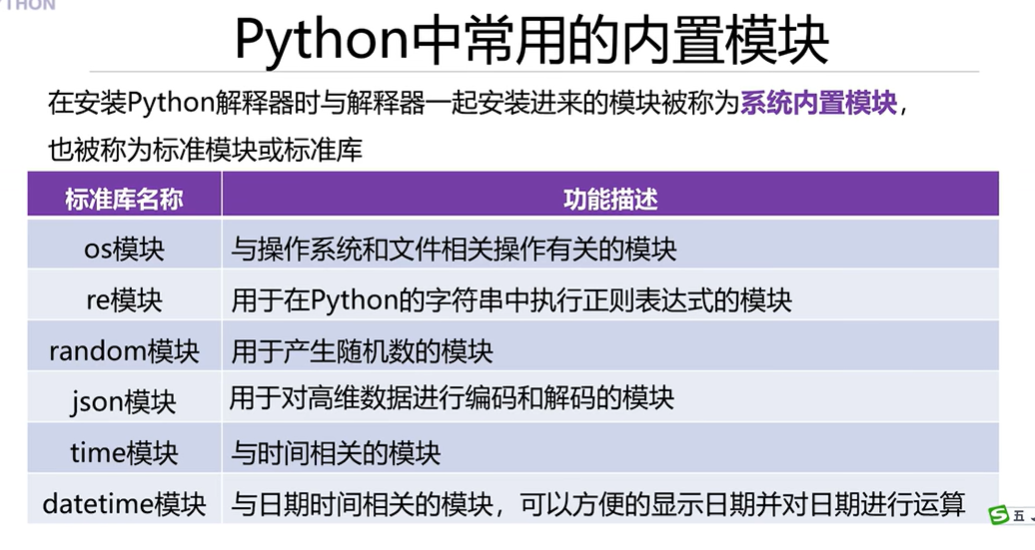
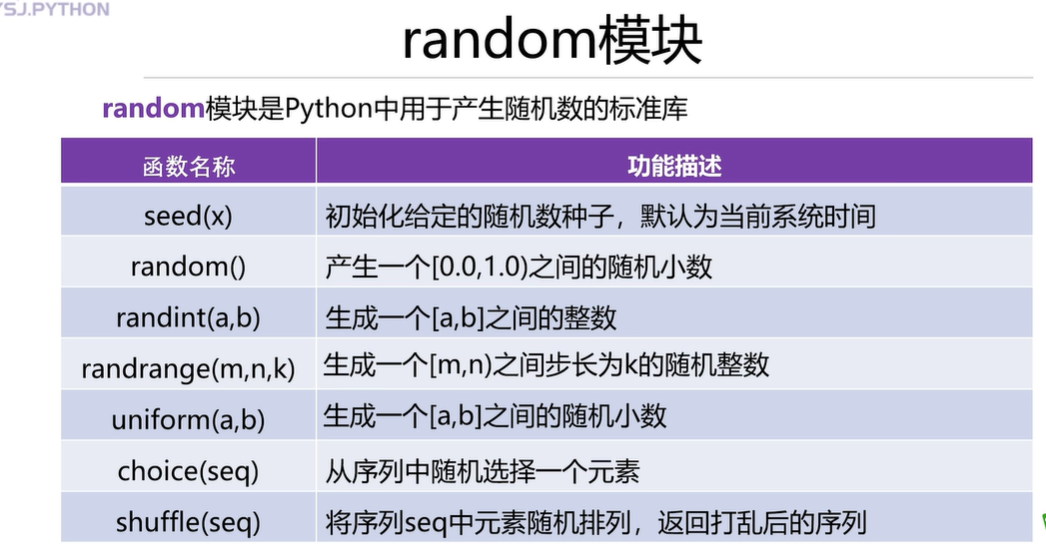
注意这里的随机种子根据这个数字产生特定的数字,规定好了随机种子不管在什么电脑上都能产生一样的数字。如果不规定随机种子就不能保证每一次产生的数字是一样的,如果想要不同的数字就要规定不同的随机种子数。
#导入
import random
#设置随机数种子
random.seed(10)
print(random.random()) #[0.0,1.0]
print(random.random()) #这两次结果是不一样
print('-'*40)
random.seed(10)
print(random.randint(1,100)) #[1,100]for i in range(10): #[m,n)步长为k,m-->start-->1,n-->stop-->10,k-->step-->print(random.randrange(1,10,3)) #12行代码执行了10次print(random.uniform(1,100)) #[a,b]随机小数lst=[i for i in range(1,11)]
print(random.choice(lst)) #lst是列表也是序列#随机的排序
random.shuffle(lst)
print(lst)
random.shuffle(lst) #必须写上这行要不然就会两行执行结果一样了
print(lst) #此时再执行一遍运行结果如下:
0.5714025946899135
0.4288890546751146
----------------------------------------
74
1
4
4
7
1
1
4
4
4
7
81.25126013057475
1
[5, 4, 10, 7, 3, 2, 1, 6, 8, 9]
[3, 4, 5, 6, 8, 10, 7, 1, 2, 9]进程已结束,退出代码为 0本节完






)





![[spring-cloud: 服务发现]-源码解析](http://pic.xiahunao.cn/[spring-cloud: 服务发现]-源码解析)






