过采样:
机器学习——过采样(OverSampling),解决类别不平衡问题,案例:逻辑回归 信用卡欺诈检测-CSDN博客
(完整代码在底部)
使用下采样解决类别不平衡问题 —— 以信用卡欺诈识别为例
在实际机器学习任务中,**类别不平衡问题(Imbalanced Classification Problem)**极为常见,特别是在金融风控、医疗诊断等领域。例如,信用卡欺诈交易仅占总交易数的一小部分,而模型往往容易“偏向”多数类,导致模型虽有高精度但检测效果极差。
本文将演示一种常用的应对策略:下采样(undersampling)
一、什么是下采样?
下采样是指从样本数量较多的类别中随机抽取一部分样本,使其与少数类的数量一致,从而达到类别平衡的目的。它的优点是简洁快速,缺点是可能舍弃有价值的信息,但在数据量非常大的情况下,通常是一种高效方案。
二、完整代码解析与步骤讲解
🔹 1. 导入依赖并读取数据
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 读取信用卡欺诈数据集
data = pd.read_csv('creditcard.csv') 信用卡欺诈检测数据集 creditcard.csv
-
数据来源:信用卡欺诈检测实战数据集_数据集-阿里云天池
 https://tianchi.aliyun.com/dataset/101562?accounttraceid=c1258603818f44d6a57fe125248cc969rkgu
https://tianchi.aliyun.com/dataset/101562?accounttraceid=c1258603818f44d6a57fe125248cc969rkgu -
样本总数:284,807 条
-
特征数:30(28个匿名特征 + 金额
Amount+ 时间Time) -
目标变量:
Class(0=正常交易,1=欺诈交易)

🔹 2. 数据预处理
# 标准化 Amount 字段(转换为均值为0、标准差为1的分布)
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']]) # 用标准化结果替换原始 'Amount'# 删除无关的 Time 字段
data = data.drop("Time", axis=1)标准化 Amount 字段有助于模型更快收敛;而 Time 特征在本任务中并无实际贡献,故直接删除。
三、原始数据训练模型
🔹 拆分训练集和测试集
# 将特征和标签分开
X = data.drop("Class", axis=1) # 特征变量
y = data.Class # 标签变量# 拆分原始数据为训练集和测试集(70%训练,30%测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=100)
🔹 构建并训练模型
# 在原始数据上训练逻辑回归模型
model = LogisticRegression(C=10, penalty='l2', max_iter=1000)
model.fit(X_train, y_train)🔍 在原始测试集上评估
# 原数据的‘0’‘1’组成
labels_count = pd.value_counts(data['Class'])
print("原数据组成:\n",labels_count)# 原始数据训练的模型,对原始测试集进行预测
print("‘原数据训练得到的模型’ 对 ‘原数据的测试集’ 的测试:")
predictions_test = model.predict(X_test)
print(metrics.classification_report(y_test, predictions_test)) # 输出分类评估指标
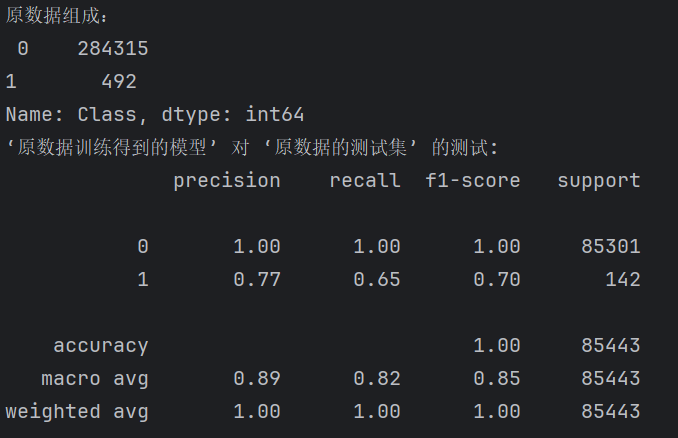
数据组成:可见欺诈交易极少,若不处理,模型训练会极度偏向“正常交易”,导致高精度但低召回。
recall(0)=1 , recall(1)=L:0.65
全部的0都被检查出来了,,但只有%65的1被检测出来。
这一步展示了原始数据训练出来的模型在测试集上的效果,由于训练数据严重不平衡,模型倾向于预测“正常交易”,虽然整体准确率高,但对“欺诈交易”的识别能力可能很差。
四、应用下采样处理数据不平衡
🔹 构造平衡数据集
# ============ 下采样处理开始 ============
# 获取正常交易样本(Class=0)和欺诈交易样本(Class=1)
class_0 = data[data['Class'] == 0]
class_1 = data[data['Class'] == 1]# 从正常交易中随机采样,数量与欺诈交易相同,实现类别平衡
class_0 = class_0.sample(len(class_1))# 合并下采样后的正常交易与全部欺诈交易
data_under = pd.concat([class_0, class_1])此处,原始正常交易有数十万条,而欺诈交易不足千条。下采样使得两个类别数量一致。
🔹 拆分下采样后的训练与测试集
# 构建下采样数据的特征和标签
X_under = data_under.drop("Class", axis=1)
y_under = data_under.Class# 拆分下采样数据为训练集和测试集
X_train_under, X_test_under, y_train_under, y_test_under = train_test_split(X_under, y_under, test_size=0.3, random_state=100)五、用下采样数据训练新模型
# 使用下采样数据训练逻辑回归模型
model_under = LogisticRegression(C=10, penalty='l2', max_iter=1000)
model_under.fit(X_train_under, y_train_under)这一步训练的是“下采样数据训练出来的模型”,它更公平地学习了两类样本特征,更有可能识别欺诈交易。
六、评估新模型在原始测试集的效果
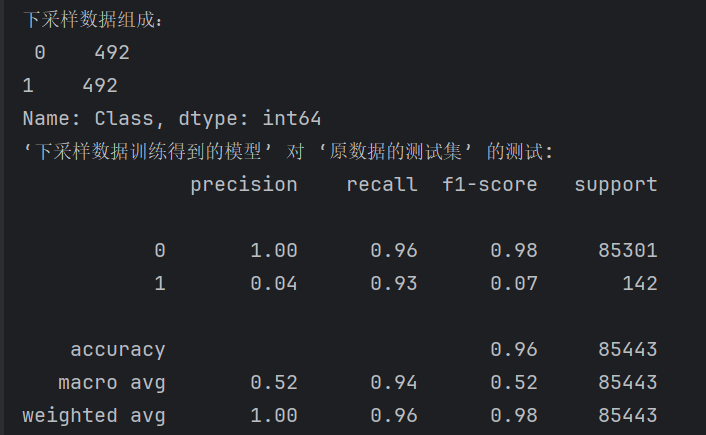
# 下采样数据的‘0’‘1’组成
labels_count_under = pd.value_counts(data_under['Class'])
print("下采样数据组成:\n",labels_count_under)# 用下采样模型对原始测试集进行预测
print("‘下采样数据训练得到的模型’ 对 ‘原数据的测试集’ 的测试:")
predictions_test = model_under.predict(X_test)
print(metrics.classification_report(y_test, predictions_test)) # 输出评估报告
-
从正常交易中随机抽取492条样本;
-
再与所有欺诈交易(492条)组合,得到总共 984 条样本的下采样数据集;
-
这使得逻辑回归模型在训练过程中对两个类别给予相同权重学习,提升模型识别少数类的能力。
此处,我们用下采样模型对原始数据测试集做预测,看看在现实中(多数为正常交易)的表现是否更好地平衡了 recall 与 precision。
七、实验对比分析:原始模型 vs 下采样模型
原始模型的特点
-
正常交易识别非常完美(precision=1.00, recall=1.00)
-
对欺诈交易识别较弱:虽然 precision 有 0.77,但 recall 仅为 0.65,意味着 仍有 35% 欺诈交易未被识别
-
整体准确率为 1.00,但这种“高准确率”是由数据极度不平衡带来的幻象
下采样模型的特点
-
正常交易略有误识别(recall 从 1.00 降至 0.95),但仍保持高 precision
-
对欺诈交易的 recall 高达 0.93,意味着识别出了 93% 欺诈交易,虽然 precision 非常低(0.04)
-
整体准确率下降为 0.96,但在安全场景中,召回率往往更重要
八、效果分析与建议
✅ 模型优点:
-
训练集平衡 → 提升对少数类(如欺诈交易)的学习能力
-
训练速度快 → 数据量减少
⚠️ 模型局限:
-
丢弃部分多数类样本 → 信息损失
-
在样本稀缺的场景不推荐使用(建议用过采样)
总结
| 方案 | 原始模型 | 下采样模型 |
|---|---|---|
| 优势 | 保留全部数据 | 解决类别不平衡 |
| 缺点 | 偏向多数类 | 可能舍弃有价值的信息 |
| 精度 | 高(总体) | 偏向 recall |
| 适用场景 | 多数类重要 | 少数类重要(如欺诈识别) |
在高度不平衡的分类任务中,下采样是一个简单且常见的解决方案。与模型调参、特征选择配合使用,能取得不错的效果。
所以本专栏还有过采样(OverSampling)文章
完整代码:
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 读取信用卡欺诈数据集
data = pd.read_csv('creditcard.csv')# 标准化 Amount 字段(转换为均值为0、标准差为1的分布)
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']]) # 用标准化结果替换原始 'Amount'# 删除无关的 Time 字段
data = data.drop("Time", axis=1)# 将特征和标签分开
X = data.drop("Class", axis=1) # 特征变量
y = data.Class # 标签变量# 拆分原始数据为训练集和测试集(70%训练,30%测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=100)# 在原始数据上训练逻辑回归模型
model = LogisticRegression(C=10, penalty='l2', max_iter=1000)
model.fit(X_train, y_train)# 原数据的‘0’‘1’组成
labels_count = pd.value_counts(data['Class'])
print("原数据组成:\n",labels_count)
# 原始数据训练的模型,对原始测试集进行预测
print("‘原数据训练得到的模型’ 对 ‘原数据的测试集’ 的测试:")
predictions_test = model.predict(X_test)
print(metrics.classification_report(y_test, predictions_test)) # 输出分类评估指标# ============ 下采样处理开始 ============# 获取正常交易样本(Class=0)和欺诈交易样本(Class=1)
class_0 = data[data['Class'] == 0]
class_1 = data[data['Class'] == 1]# 从正常交易中随机采样,数量与欺诈交易相同,实现类别平衡
class_0 = class_0.sample(len(class_1))# 合并下采样后的正常交易与全部欺诈交易
data_under = pd.concat([class_0, class_1])# 构建下采样数据的特征和标签
X_under = data_under.drop("Class", axis=1)
y_under = data_under.Class# 拆分下采样数据为训练集和测试集
X_train_under, X_test_under, y_train_under, y_test_under = train_test_split(X_under, y_under, test_size=0.3, random_state=100)# 使用下采样数据训练逻辑回归模型
model_under = LogisticRegression(C=10, penalty='l2', max_iter=1000)
model_under.fit(X_train_under, y_train_under)# 下采样数据的‘0’‘1’组成
labels_count_under = pd.value_counts(data_under['Class'])
print("下采样数据组成:\n",labels_count_under)
# 用下采样模型对原始测试集进行预测
print("‘下采样数据训练得到的模型’ 对 ‘原数据的测试集’ 的测试:")
predictions_test = model_under.predict(X_test)
print(metrics.classification_report(y_test, predictions_test)) # 输出评估报告














)

)


