关注gongzhonghao【CVPR顶会精选】
当今数字化时代,多模态技术正迅速改变我们与信息互动的方式。多模态被定义为在特定语境中多种符号资源的共存与协同。这种技术通过整合不同模态的数据,如文本、图像、音频等,为用户提供更丰富、更自然的交互体验。
近年来,多模态技术取得了显著进展,尤其是在深度学习和变换器架构的推动下,多模态模型能够更灵活地处理和融合多种输入模态的信息。这些进步不仅提升了模型的性能,也为实现更通用的人工智能奠定了基础。今天小图给大家精选3篇CVPR有关多模态方向的论文,请注意查收!
图灵学术论文辅导
论文一:Beyond Text: Frozen Large Language Models in Visual Signal Comprehension
方法:
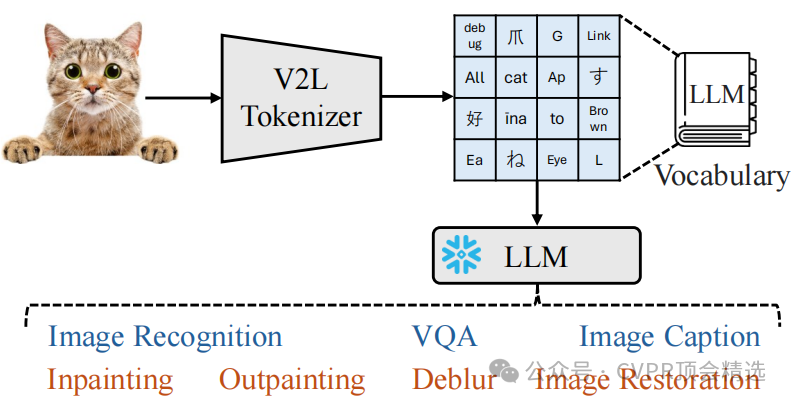
文章首先将图像视为一种“外语”,通过V2L Tokenizer将其翻译为LLM词汇表中的离散词。然后,利用扩展的LLM词汇表和CLIP模型生成全局和局部令牌,分别用于捕捉图像的语义信息和细节特征。最后,通过结合任务指令、上下文学习样本和这些令牌,使冻结的LLM能够执行多种视觉理解任务,如图像识别、图像描述和视觉问答。
创新点:
提出了Vision-to-Language Tokenizer,将图像转换为LLM词汇表中的离散词,使LLM能够直接处理视觉信息。
引入了词汇扩展技术,通过构建双词和三词组合来增强LLM词汇表的语义表示能力,从而提高对图像的语义理解。
设计了全局和局部令牌,分别用于图像理解任务和图像去噪任务,实现了对图像的多层次理解和生成。

论文链接:
https://arxiv.org/pdf/2403.07874
图灵学术论文辅导
论文二:InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
方法:
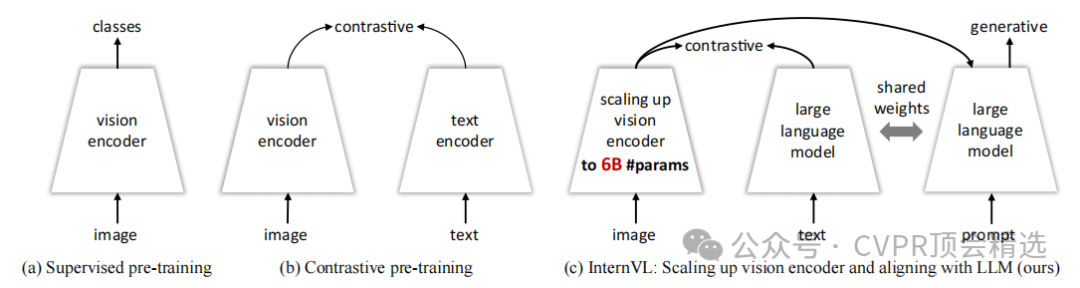
文章首先设计了一个60亿参数的视觉编码器 InternViT-6B,并通过多语言增强的LLaMA初始化语言中间件QLLaMA来对齐视觉特征和语言模型。接着,利用从网络收集的多源图像-文本数据,采用渐进式对齐训练策略,先进行对比学习,再进行生成学习,最后进行监督微调。这种设计使InternVL能够在多种视觉和视觉-语言任务上展现出强大的性能,如图像分类、视频分类、图像-文本检索、图像描述、视觉问答和多模态对话等。
创新点:
提出了InternVL,这是首个将视觉基础模型扩展到60亿参数并与LLM对齐的模型,有效填补了视觉基础模型与LLM之间的参数规模和特征表示能力的差距。
引入了渐进式图像-文本对齐策略,先在大规模噪声数据上进行对比学习,再在高质量数据上进行生成学习,确保了训练的稳定性并持续提升模型性能。
设计了参数平衡的视觉和语言组件,包括60亿参数的视觉编码器和80亿参数的语言中间件,能够灵活组合以应对对比学习和生成学习任务。

论文链接:
https://arxiv.org/pdf/2312.14238
图灵学术论文辅导
论文三:ViLa-MIL: Dual-scale Vision-Language Multiple Instance Learning for Whole Slide Image Classification
方法:
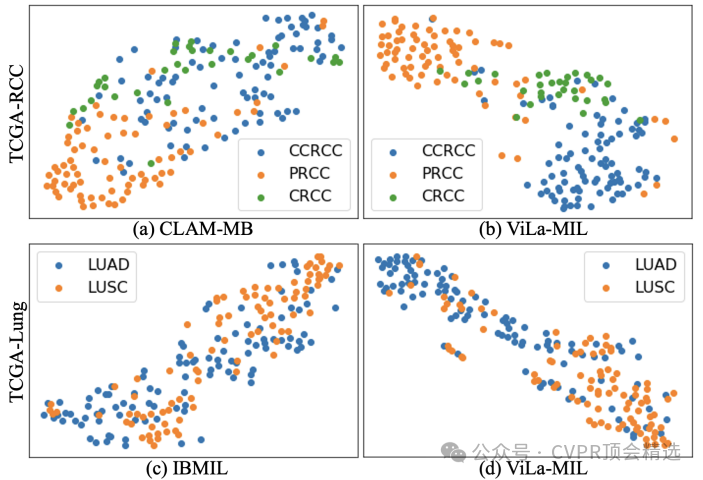
文章首先利用冻结的LLM生成与WSI不同分辨率对应的双尺度视觉描述性文本提示,以更好地利用病理诊断中的先验知识。接着,为高效处理WSI,提出了原型引导的图像分支解码器,通过分组相似图像块特征并逐步聚合,生成最终的幻灯片特征。同时,引入上下文引导的文本分支解码器,借助多粒度图像上下文信息优化文本特征。最后,通过计算图像特征和文本特征之间的相似性,结合交叉熵损失函数进行端到端训练,从而实现对WSI的分类。

创新点:
提出了双尺度视觉描述性文本提示,基于冻结的大语言模型生成,能够有效提升VLM的性能,使其更好地捕捉WSI中的诊断相关特征。
设计了原型引导的图像分支解码器,通过将相似的图像块特征分组到同一原型中,逐步聚合图像块特征,从而更有效地处理WSI。
引入了上下文引导的文本分支解码器,利用多粒度图像上下文来增强文本特征,进一步提升模型对WSI的分类能力。
论文链接:
https://arxiv.org/pdf/2502.08391
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!每天2个免费咨询名额,机会有限先到先得!
本文选自gongzhonghao【CVPR顶会精选】









的安装过程以及GD32的IAR工程模板搭建)

 钥匙串信息)
)

 配置IP封禁(防暴力破解))




