目 录
1、实验目的
2、实验环境
3、实验内容
3.1 DNS查询UDP数据分析
3.2 QQ通信UDP数据分析
4、实验结果与分析
4.1 DNS查询UDP数据分析
4.2 QQ通信UDP数据分析
4.3 根据捕获的数据包,分析UDP的报文结构,将UDP协议中个字段名,字段值,字段信息填入下表
4.4 通过分析实验结果,UDP报文结构由哪几部分组成,其功能是什么
5、实验小结
5.1 问题与解决办法:
5.2 心得体会:
1、实验目的
1、了解和掌握运输层UDP协议内容
2、理解UDP协议的工作原理
3、了解应用层和运输层协议的关系
2、实验环境
1、硬件要求:阿里云云主机ECS 一台、笔记本电脑一台
2、软件要求:Linux/ Windows 操作系统
3、实验内容
UDP(User Datagram Protocol)用户数据报协议是一种无连接的运输层协议,提供面向事物的简单不可靠信息传送服务,服务于很多应用层协议包括网络文件系统(NFS),简单的网络管理协议(SNMP),域名系统(DNS)以及简单的文件传输系统(TFTP)。与TCP不同UDP并不提供对IP协议的可靠机制,控制以及错误恢复等。由于UDP比较简单,UDP头包含很少的字节,比TCP负载消耗少。
3.1 DNS查询UDP数据分析
使用tcpdump抓取DNS查询网络通信数据包,利用wireshark分析UDP数据。
例如:
dig www.xju.edu.cn
3.2 QQ通信UDP数据分析
1. 利用wireshark抓取QQ网络通信数据包,分析UDP数据。
2. QQ客户端之间消息传送采用了UDP。国内网络环境非常复杂而且很多用户采用的方式是通过代理服务器共享一条线路上网方式,UDP包能够穿透大部分的代理服务器,因此QQ选择了UDP作为客户之间的通信协议。因此我们打开QQ聊天窗口开启捕获,与好友进行对话,停止捕获就得到了UDP数据包。
4、实验结果与分析
4.1 DNS查询UDP数据分析
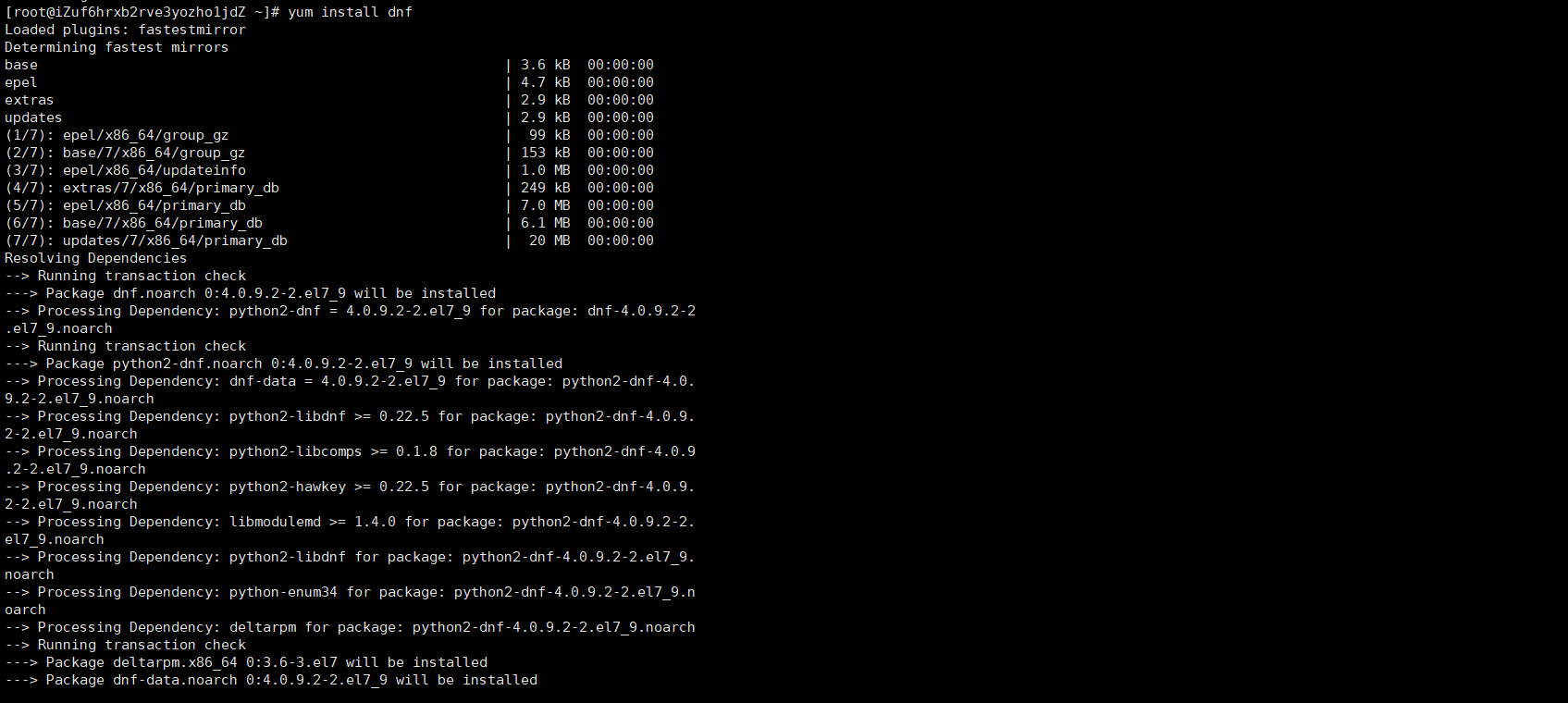
1. 由于系统中没有dig命令,因此需要使用如下语句进行下载。
yum install dnf
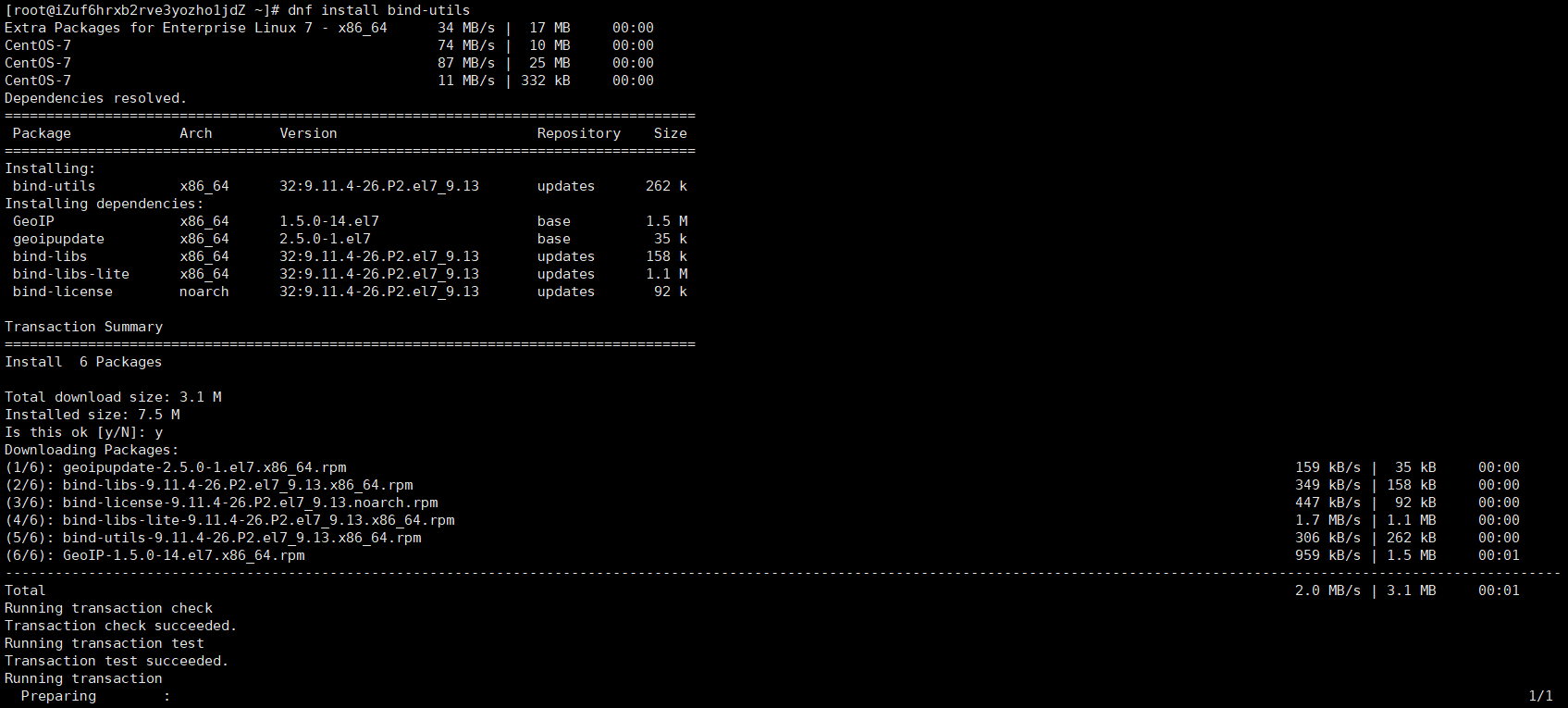
dnf install bind-utils
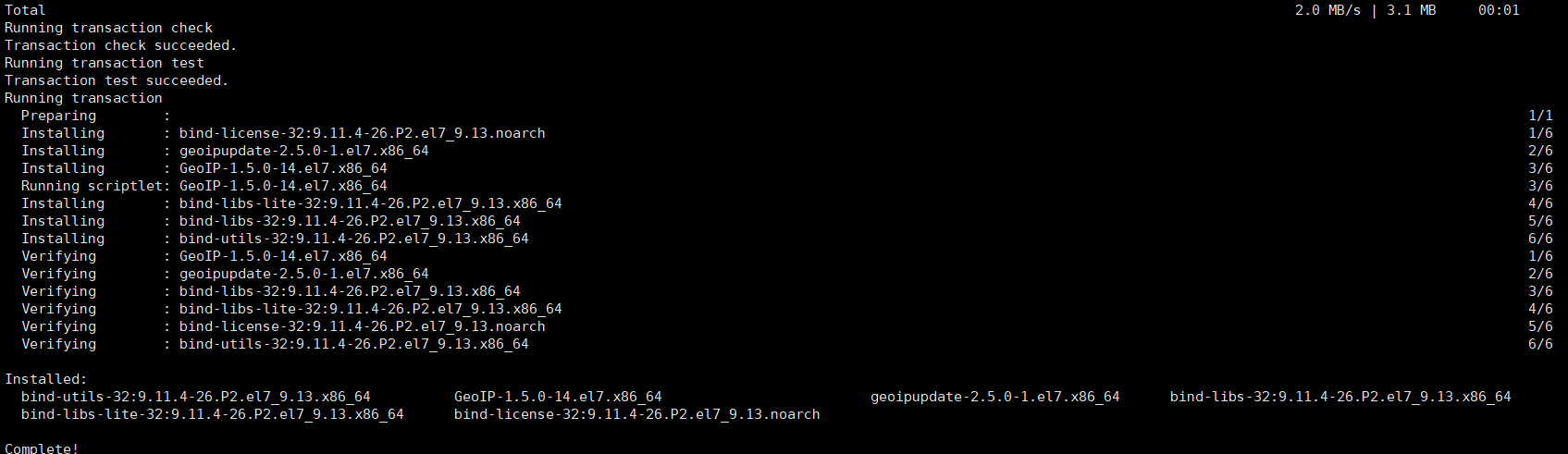
2. 如下图所示则为dig命令下载成功。
3. 利用dig解析新疆大学网站的DNS。
dig www.xju.edu.cn

4. 利用tcpdump抓取DNS查阅网络通信数据包,并以dns.cap文件保存下来。
tcpdump -i eth0 -w dns.cap

5. 使用Xftp7将dns.cap文件移动到桌面上。
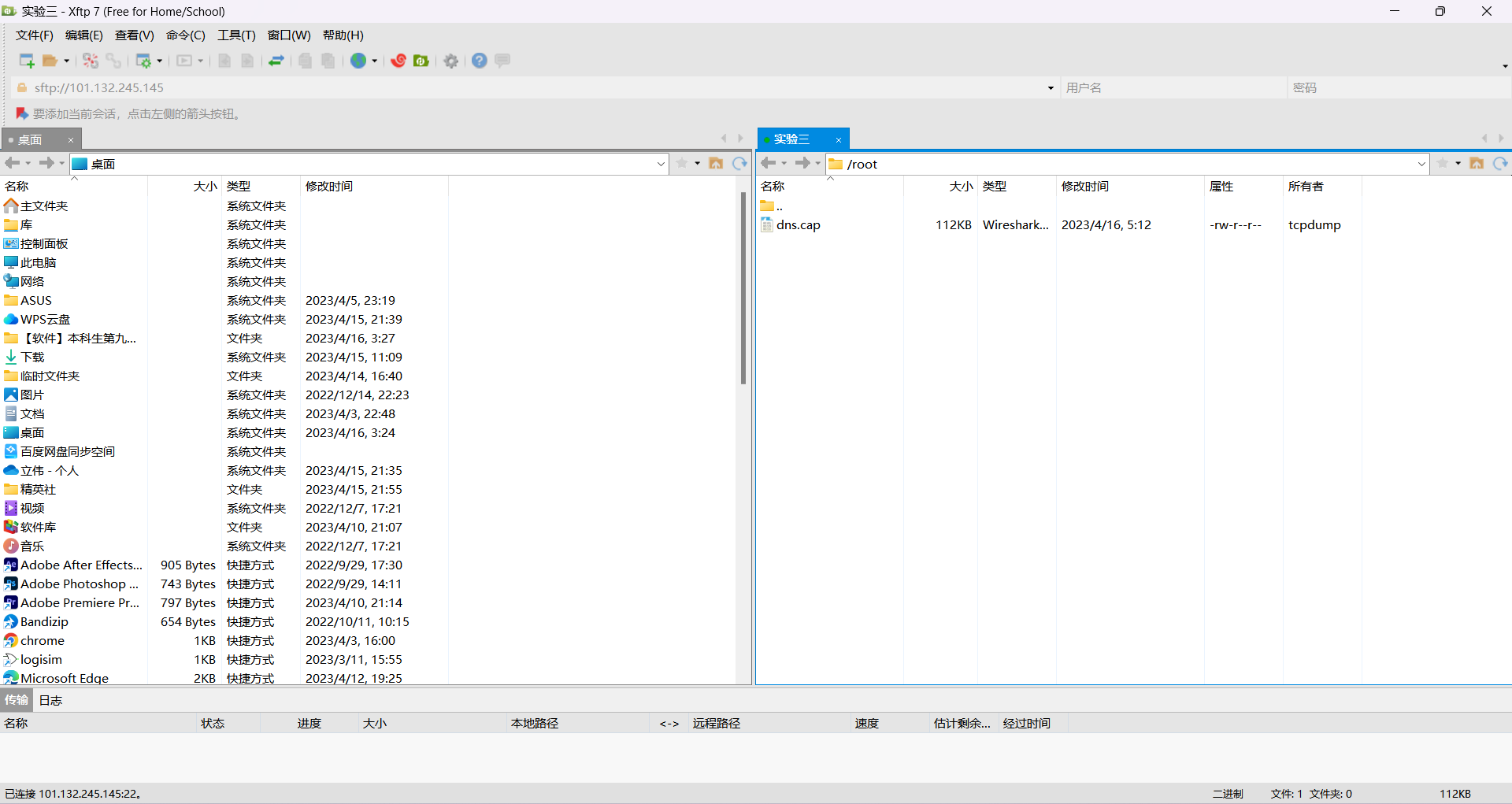
6. 在Wireshark中打开桌面上的dns.cap文件进行分析。
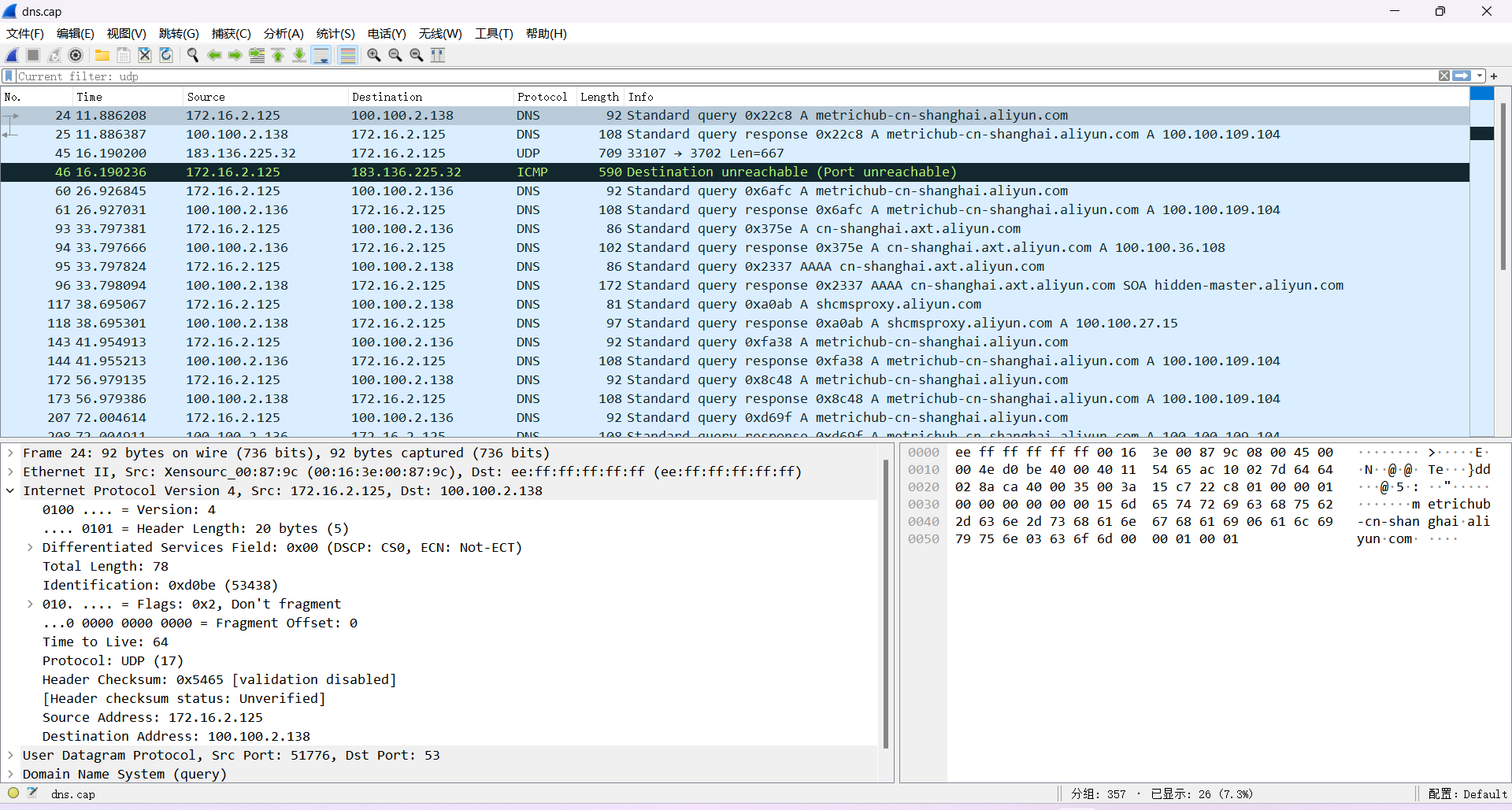
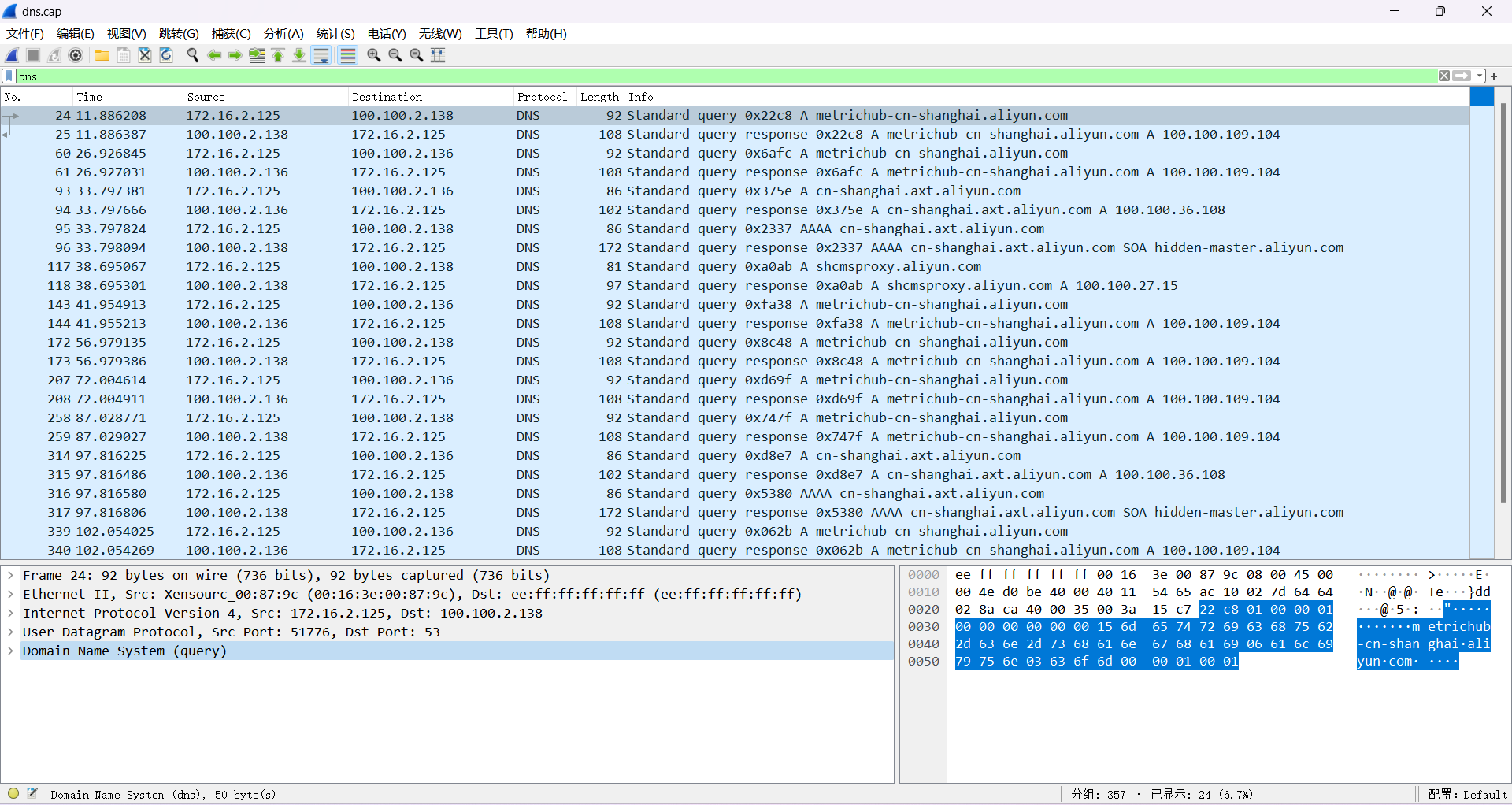
7. 在过滤器中输入以下语句过滤出DNS数据包。
dns
4.2 QQ通信UDP数据分析
1. 打开Wireshark,由于笔记本电脑连接的是WIFI,所以点击WLAN进行数据包捕获。
2. 正在进行数据包的抓取。
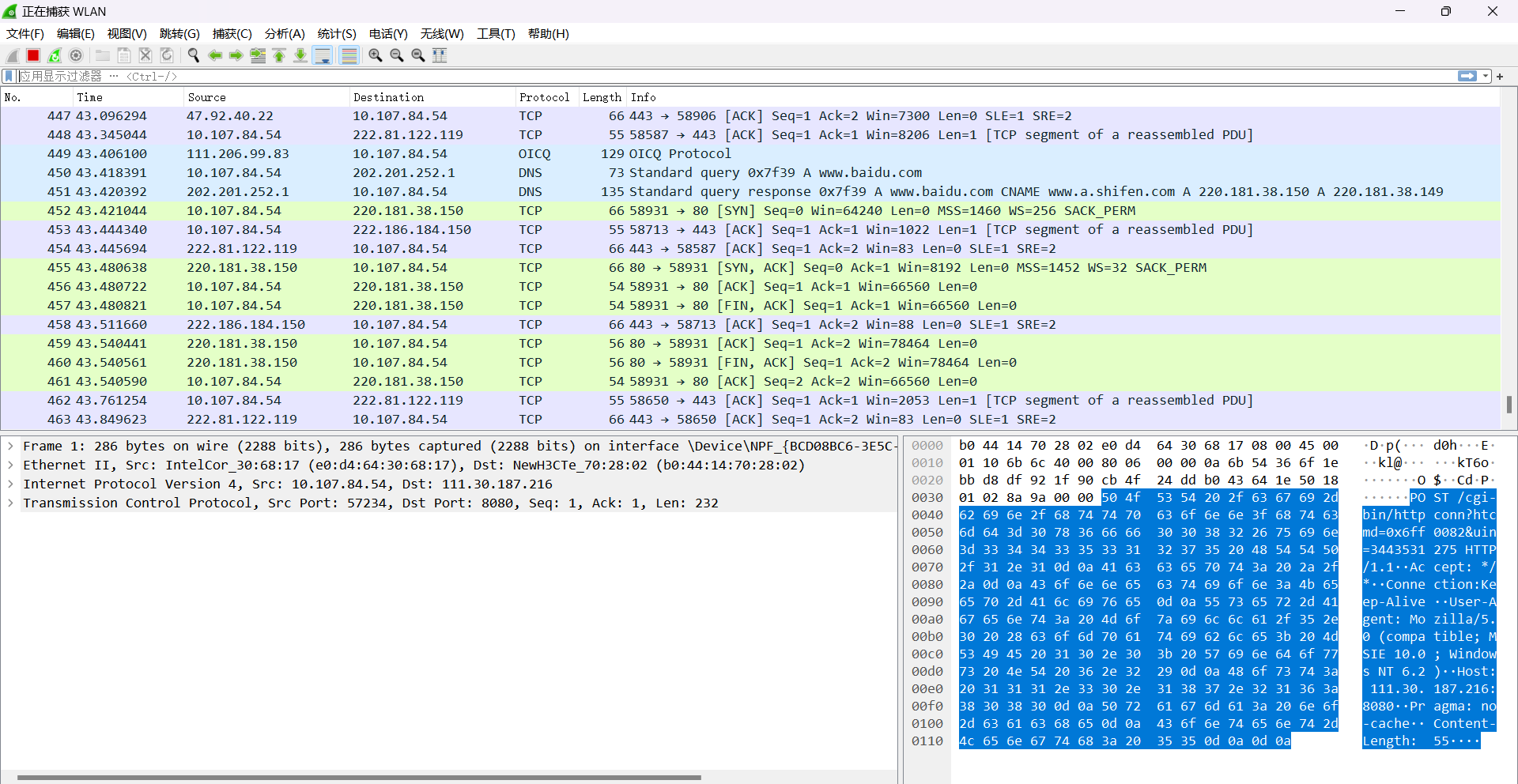
3. 点击Wireshark左上方的红色方框按钮,停止抓包。
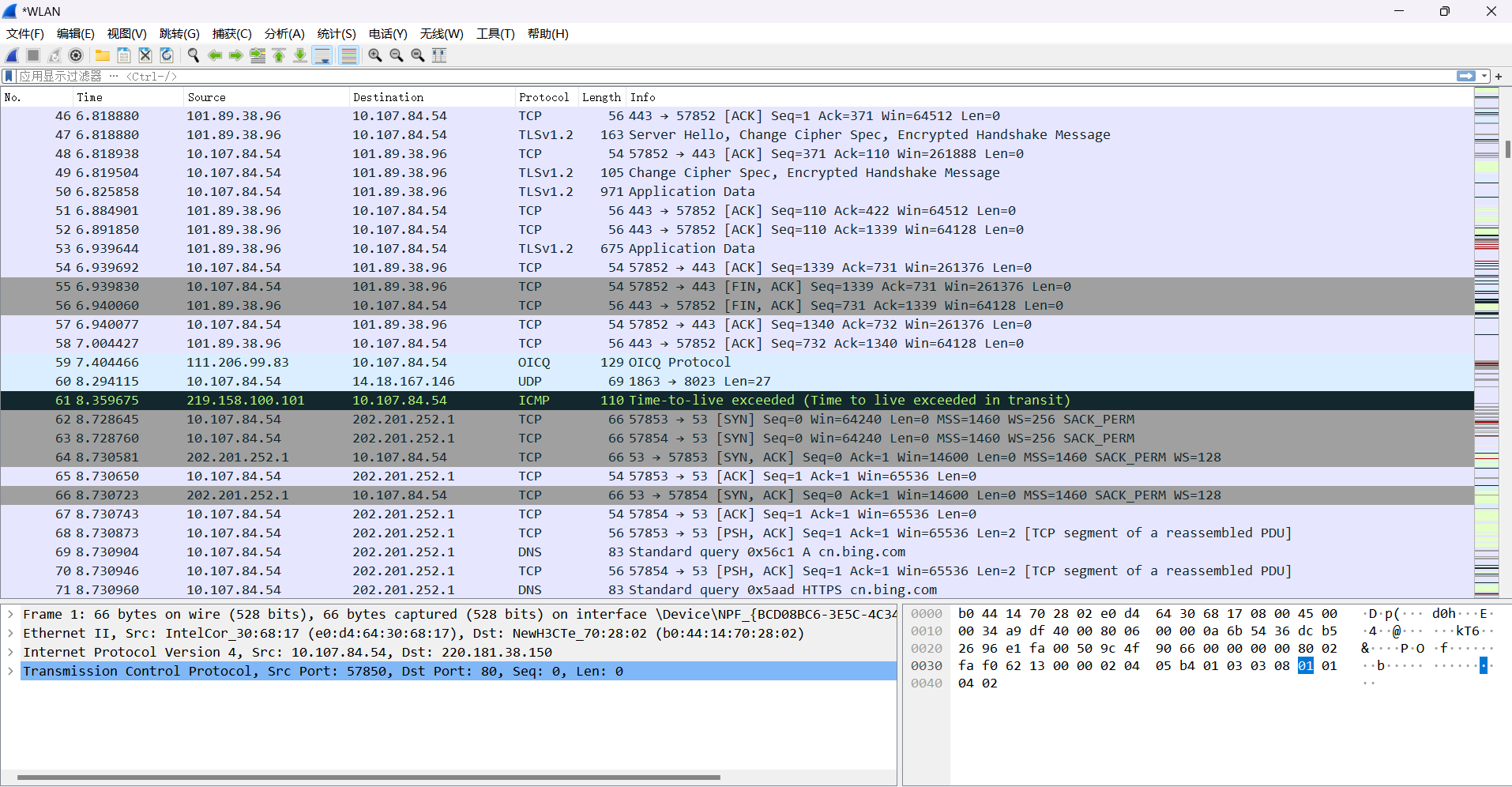
4. 使用过滤器得到QQ网络通信数据包时在应用显示过滤器输入以下语句。
oicq
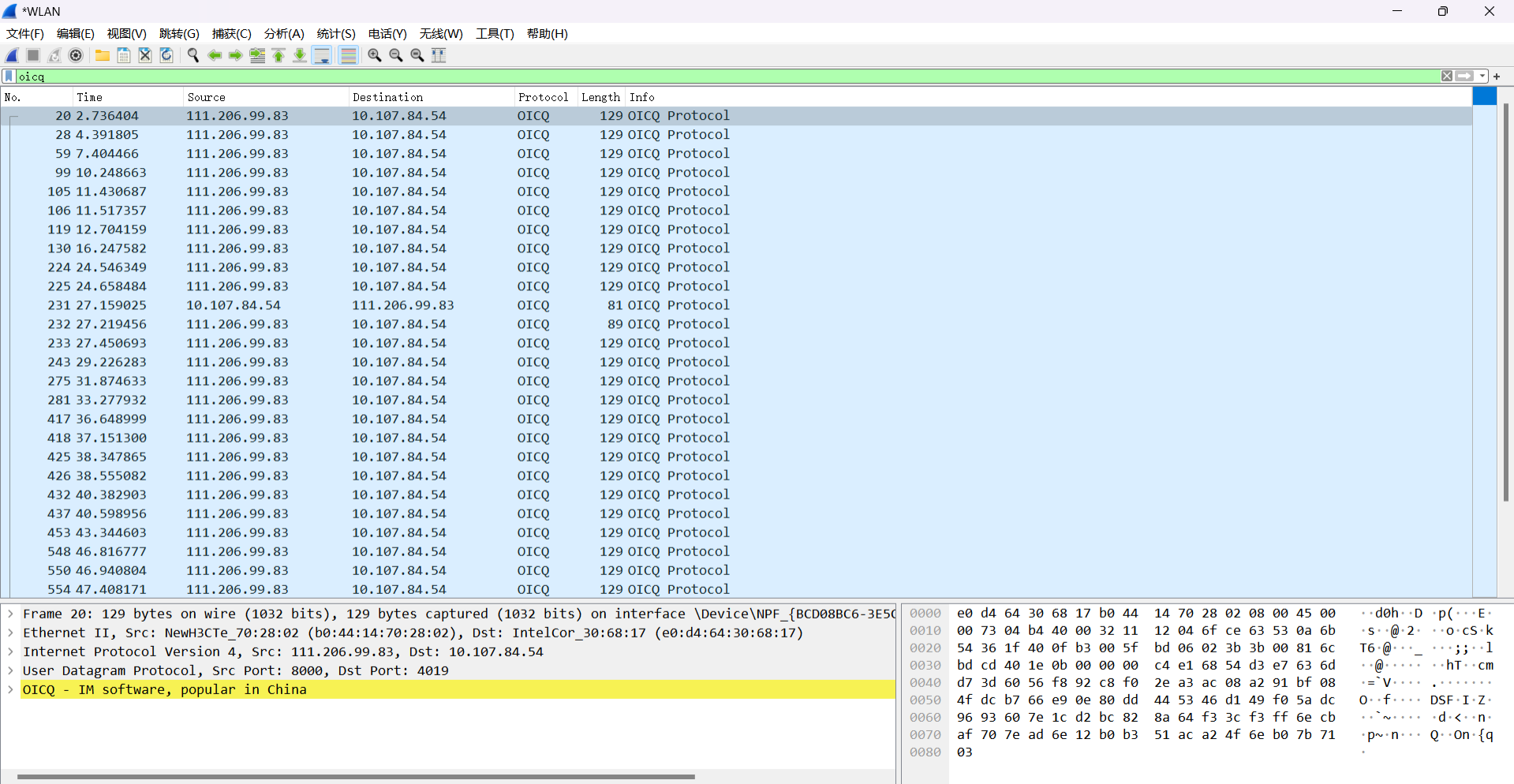
5. 点击OICQ后数据段中的QQ为十六进制。
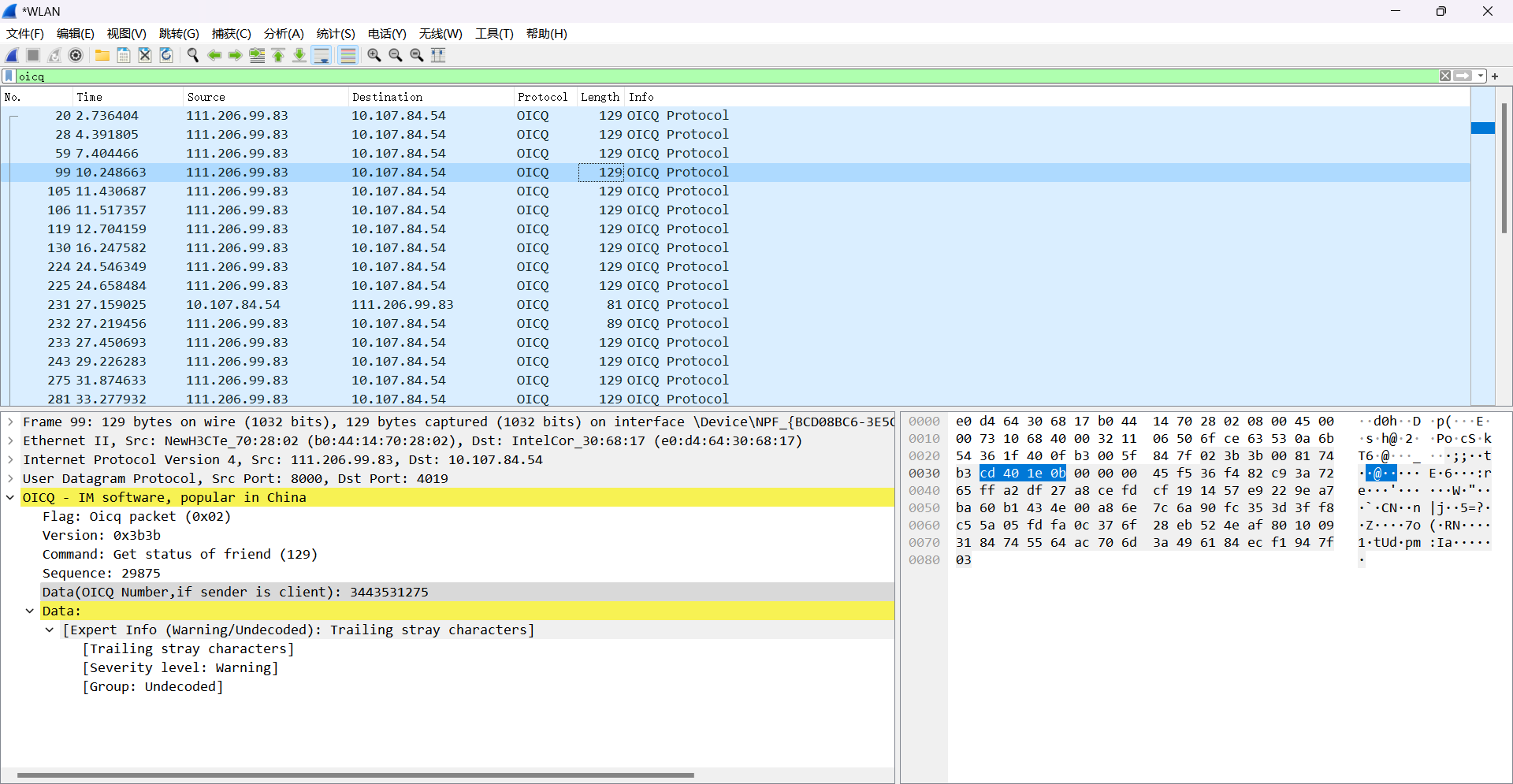
6. 使用过滤器得到UDP数据包时在应用显示过滤器输入以下语句。
udp
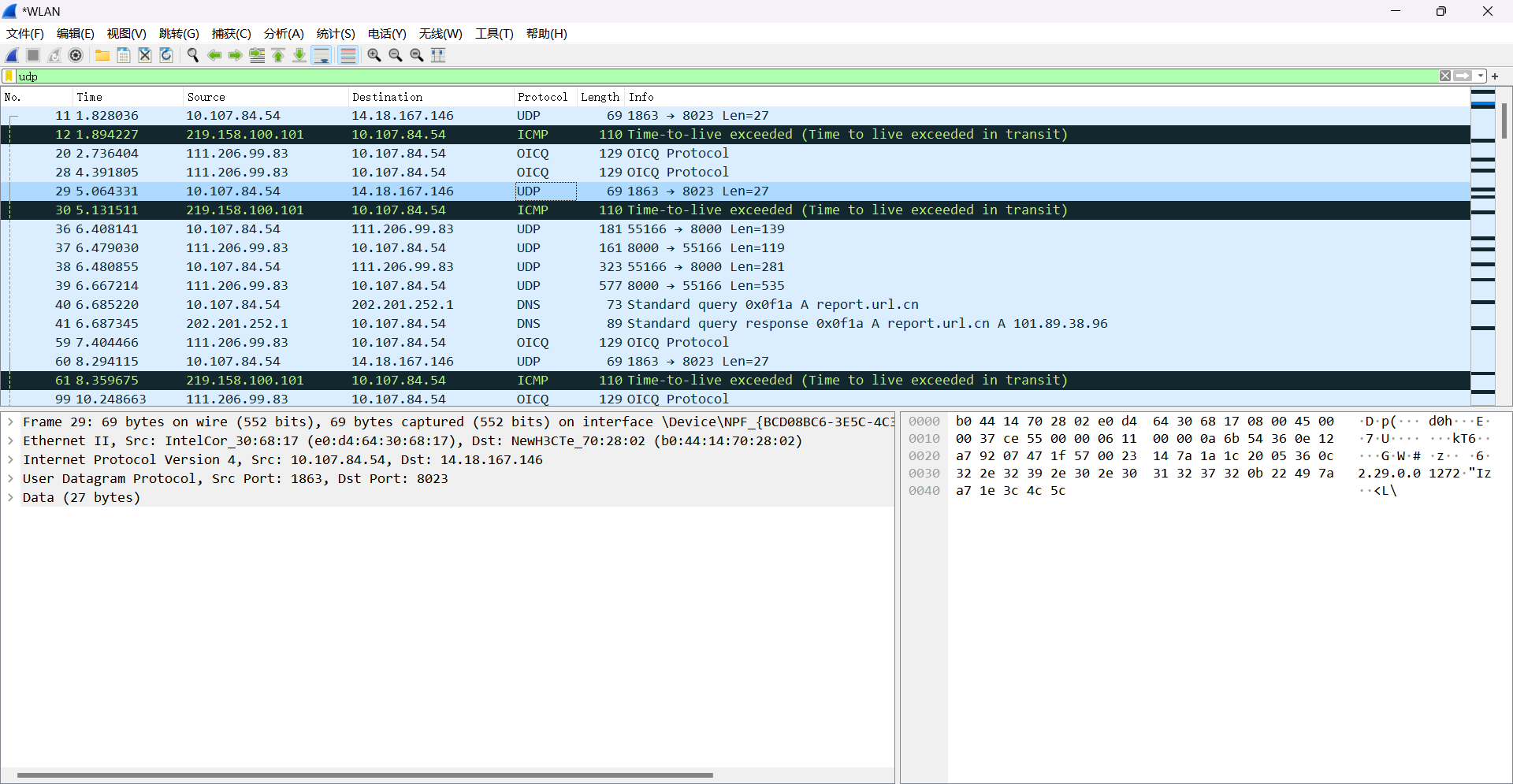
7. 点击Internet Protocol Version后进行UDP相关数据的查看。
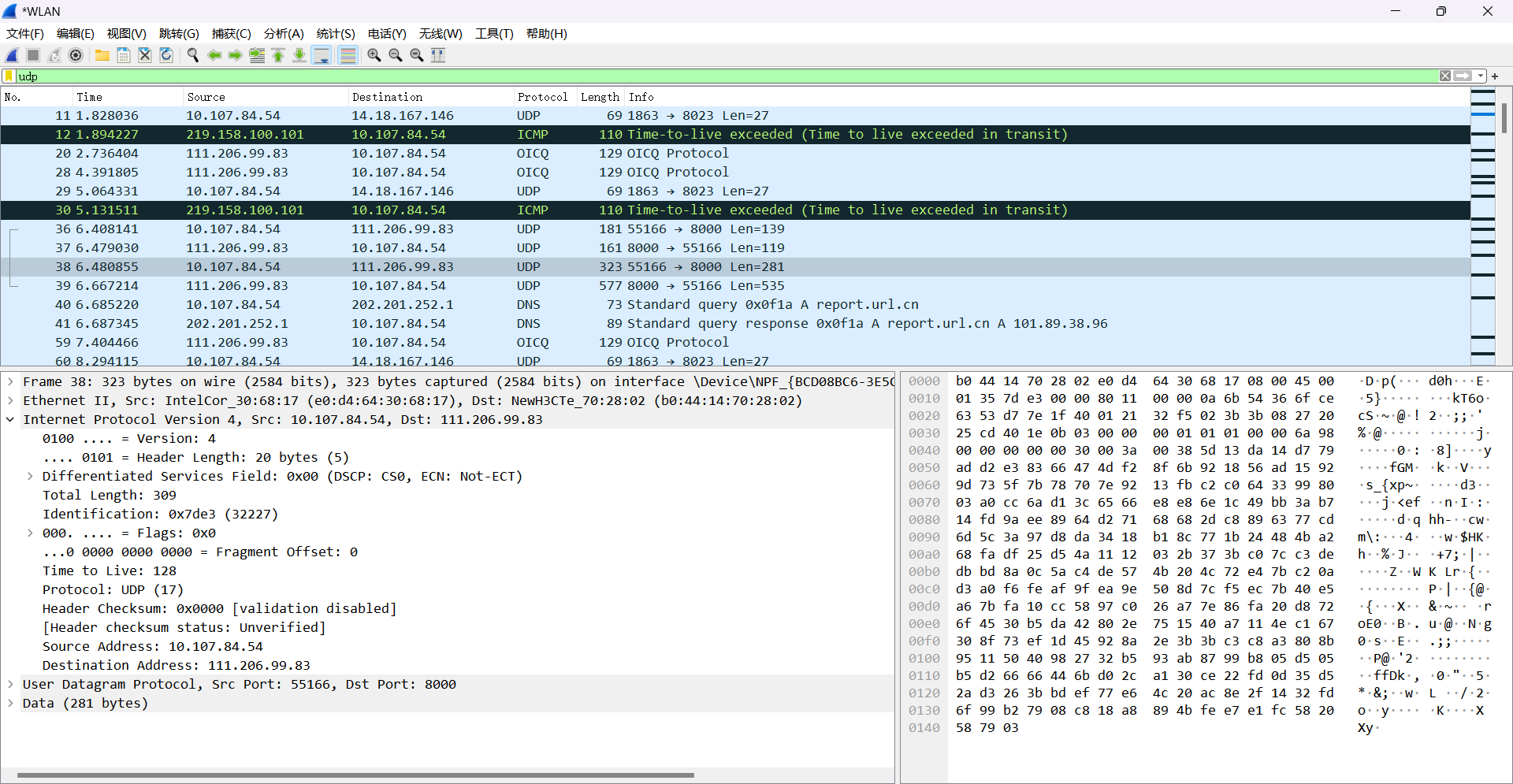
4.3 根据捕获的数据包,分析UDP的报文结构,将UDP协议中个字段名,字段值,字段信息填入下表
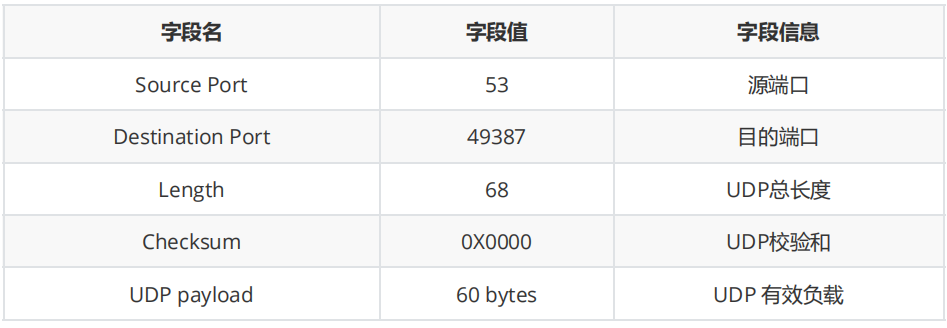
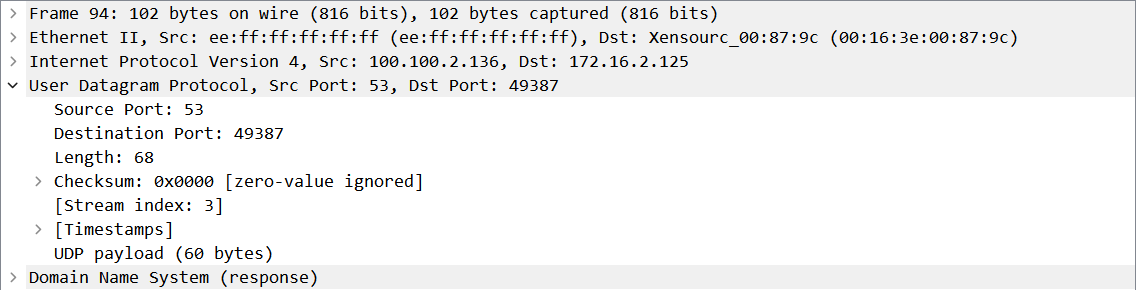
1. 对抓取的数据包进行网站通信的UDP数据分析,填写表格内容。
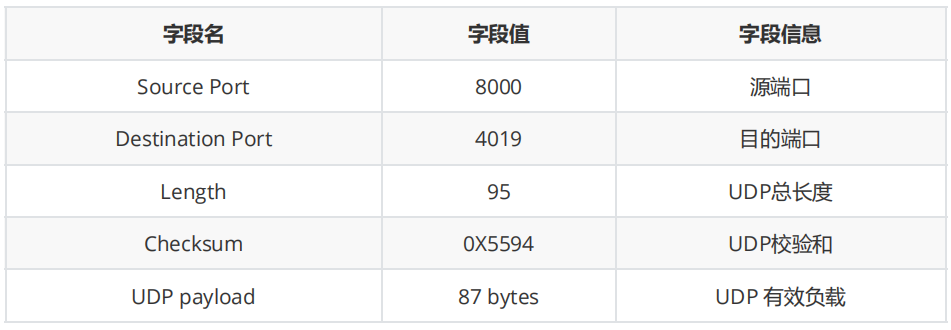
2. 对抓取的数据包进行QQ通信的UDP数据分析,填写表格内容。
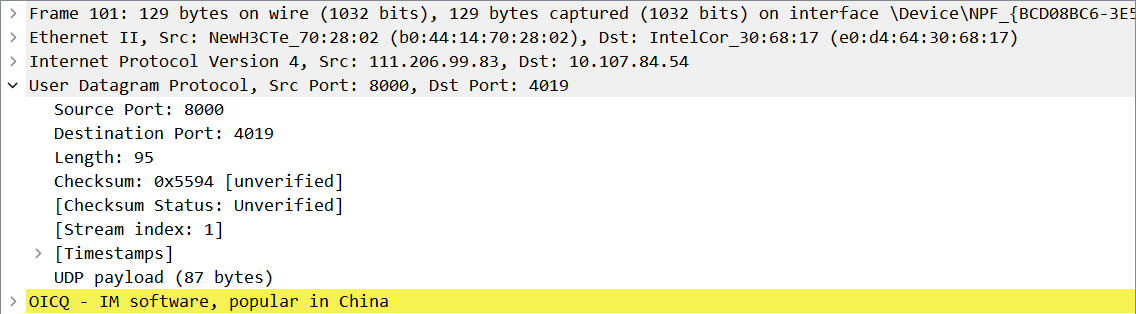
4.4 通过分析实验结果,UDP报文结构由哪几部分组成,其功能是什么
源端口:需要对方回信时选用,不需要时全部置0;客户端程序请求时,由系统自动指定,端口号范围是 0~65535,0~1023为知名端口号。
目的端口:服务器的端口,由编写程序的程序员自己指定,这样客户端才能根据ip地址和 port 成功访问服务器,在终点交付报文的时候需要用到。
UDP总长度:UDP的数据报的长度(包括首部和数据)其最小值为8(只有首部),整个UDP数据报的长度 ,包括报头+载荷。
UDP校验和:检查数据在传输中是否出错,是否出现bit反转的问题,当进行校验时,需要在UDP数据报之前增加临时的伪首部。
5、实验小结
5.1 问题与解决办法:
1. 问题一:使用dig命令时出现如下提示此命令未找到:
![]()
解决方法:由于系统中没有dig命令所导致,需要在使用此命令前通过 yum install dnf 以及 dnf install bind-utils 命令进行安装。
2. 问题二:使用tcpdump进行数据包的抓取时出现如下提示此命令未找到:
![]()
解决方法:由于命令输入错误导致,数据包的抓取命令为tcpdump,而不是tcpdnmp,将对应命令进行更改后错误消失。
3. 问题三:对指定网络接口的数据包进行抓取时出现如下提示语法错误:
![]()
解决方法:由于命令键入不完整所导致,指定网络接口所需要的参数是-i,在eth0前方添加-i后错误消失。
4. 问题四:使用tcpdump抓取所有的数据包时一直在抓取,不能够自动停止抓包:

解决方法:使用Ctrl+c就可以终止运行的命令,进而就可以停止抓包。
5.2 心得体会:
1、由于UDP无需建立连接,因此UDP不会引入建立连接的时延。
2、UDP不维护连接状态,也不跟踪参数,因此某些专用应用服务器使用UDP时,一般都能支持更多的活动客户机。
3、分组首部开销更小,UDP只有8个字节的首部开销。
4、应用层能够更好地控制要发送的数据和发送时间。UDP没有拥塞控制,因此网络中的拥塞也不会影响主机的发送效率。某些实时应用(如直播)要求以稳定的速度发送,能容忍一些数据的丢失,但不允许有较大的时延,而UDP正好可以满足这些应用的需求。
5、UDP提供尽最大努力的交付,即不保证可靠交付,但并不意味着应用对数据的要求是不可靠的,因此需要维护传输可靠性的工作需要用户在应用层来完成。应用实体可以根据应用需求来灵活设计自己的可靠性机制。
6、UDP是面向报文的,发送方UDP对应用层交下来的报文,在添加首部后就交付给IP层,既不合并,也不拆分,而是保留这些报文的边界;接受方UDP对IP层交上来的用户数据报,在去除首部后就原封不动的交付给上层的应用进程,一次交付一个完整的报文,因此报文不可分割,是UDP数据处理的最小单位。
7、UDP常用于一次性传输比较小数据的网络应用,如DNS、SNMP等,因为对于这些应用,若采用TCP,则将为创建连接、维护和拆除而带来不小的开销。UDP也常用于多媒体应用(如IP电话、实时视频会议、流媒体等),显然,可靠数据传输对于这些应用来说并不是最重要的,但TCP的拥塞控制会导致数据出现较大的延迟,这是它们不可容忍的。
8、当传输层从IP层收到UDP数据报时,就根据首部中的目的端口,把UDP数据报通过相应的端口,上交给应用进程。如果接收方UDP发现收到的报文中的目的端口号不正确(不存在对应端口号的应用进程0),就丢弃该报文,并由ICMP发送“端口不可达”差错报文给对方。
—— Mysql 8.0 25 条性能优化实战指南)
)
优化MapReduce效率和降低复杂性,深度解析+性能实测)

)

![[C/C++安全编程]_[中级]_[如何避免出现野指针]](http://pic.xiahunao.cn/[C/C++安全编程]_[中级]_[如何避免出现野指针])


)
的联系与区别(详细版))

简单工厂模式)
)




)
