损失函数的调用
import torch
from torch import nn
from torch.nn import L1Lossinputs = torch.tensor([1.0,2.0,3.0])
target = torch.tensor([1.0,2.0,5.0])inputs = torch.reshape(inputs, (1, 1, 1, 3))
target = torch.reshape(target, (1, 1, 1, 3))
#损失函数
loss = L1Loss(reduction='sum')
#MSELoss均值方差
loss_mse = nn.MSELoss()
result1 = loss(inputs, target)
result2 = loss_mse(inputs, target)
print(result1, result2)实际应用
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2ddataset = torchvision.datasets.CIFAR10(root='./data_CIF', train=False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1)class Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)self.maxpool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)self.maxpool2 = nn.MaxPool2d(kernel_size=2)self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)self.maxpool3 = nn.MaxPool2d(kernel_size=2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(in_features=1024, out_features=64)self.linear2 = nn.Linear(in_features=64, out_features=10)self.model1 = nn.Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10))def forward(self, x):x = self.model1(x)return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:imgs,targets = dataoutputs = tudui(imgs)result1 = loss(outputs, targets)print(result1)#反向传播result1.backward()#梯度grad会改变,从而通过grad来降低losstorch.nn.CrossEntropyLoss
🧩 CrossEntropyLoss 是什么?
本质上是:
Softmax + NLLLoss(负对数似然) 的组合。
公式:
:模型预测的概率(通过 softmax 得到)
:真实类别的 one-hot 标签
PyTorch 不需要你手动做 softmax,它会直接从 logits(未经过 softmax 的原始输出)算起,防止数值不稳定。
🏷️ 常用参数
torch.nn.CrossEntropyLoss(weight=None, ignore_index=-100, reduction='mean')
| 参数 | 含义 |
|---|---|
weight | 给不同类别加权(处理类别不均衡) |
ignore_index | 忽略某个类别(常见于 NLP 的 padding) |
reduction | mean(默认平均)、sum(求和)、none(逐个样本返回 loss) |
🎨 最小使用例子
import torch
import torch.nn as nncriterion = nn.CrossEntropyLoss()# 假设 batch_size=3, num_classes=5
outputs = torch.tensor([[1.0, 2.0, 0.5, -1.0, 0.0],[0.1, -0.2, 2.3, 0.7, 1.8],[2.0, 0.1, 0.0, 1.0, 0.5]]) # logits
labels = torch.tensor([1, 2, 0]) # 真实类别索引loss = criterion(outputs, labels)
print(loss.item())outputs:模型输出 logits,不需要 softmax;
labels:真实类别(索引型),如
0, 1, 2,...;loss.item():输出标量值。
💡 你需要注意:
| ⚠️ 重点 | 📌 说明 |
|---|---|
| logits 直接输入 | 不要提前做 softmax |
| label 是类别索引 | 不是 one-hot,而是整数(如 [1, 3, 0]) |
| 自动求 batch 平均 | 默认 reduction='mean' |
| 多分类用它最合适 | 二分类也能用,但 BCEWithLogitsLoss 更常见 |
🎁 总结
| 优点 | 缺点 |
|---|---|
| ✅ 简单强大,适合分类 | ❌ 不适合回归任务 |
| ✅ 内置 softmax + log | ❌ label 不能是 one-hot |
| ✅ 数值稳定性强 | ❌ 类别极度不均衡需额外加 weight |
🎯 一句话总结
CrossEntropyLoss 是深度学习中分类问题的“首选痛点衡量尺”,帮你用“正确标签”去教训“错误预测”,模型越聪明 loss 越小。
公式:
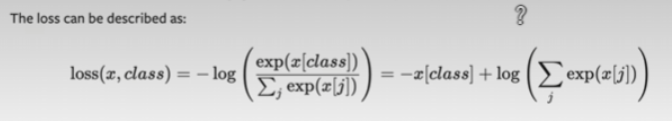
1️⃣ 第一部分:
这是经典 负对数似然(Negative Log-Likelihood):
分子:你模型对正确类别 class 输出的得分(logits),取 exp;
分母:所有类别的 logits 做 softmax 归一化;
再取负 log —— 意思是“你对正确答案预测得越自信,loss 越小”。
2️⃣ 推导为:
log(a/b) = log(a) - log(b) 的变形:
:你对正确类输出的分值直接扣掉;
:对所有类别的总分值做归一化。
这是交叉熵公式最常用的“log-sum-exp”形式。
📌 为什么这么写?
避免直接用 softmax(softmax+log 合并后可以避免数值不稳定 🚀)
计算量更高效(框架底层可以优化)
🌟 直观理解:
| 场景 | 解释 |
|---|---|
| 正确类分数高 | |
| 错误类分数高 | |
| 目标 | 压低 log-sum-exp,拉高正确类别 logits |
🎯 一句话总结:
交叉熵 = “扣掉正确答案得分” + “对所有类别归一化”,越接近正确答案,loss 越小。
这就是你训练神经网络时 模型越来越聪明的数学依据 😎
举例:
logits = torch.tensor([1.0, 2.0, 0.1]) # 模型输出 (C=3)
label = torch.tensor([1]) # 真实类别索引 = 1
其中:
N=1(batch size)
C=3(类别数)
正确类别是索引1,对应第二个值:2.0
🎁 完整公式回顾
🟣 第一步:Softmax + log 逻辑
softmax 本质上是:
但是 PyTorch 的 CrossEntropyLoss 内部直接用:
🧮 你这个例子手动算:
logits = [1.0, 2.0, 0.1],class = 1,对应 logit = 2.0
第一部分:
第二部分:
先算:
exp(1.0)≈2.718
exp(2.0)≈7.389
exp(0.1)≈1.105
加起来:
∑=2.718+7.389+1.105=11.212
取对数:
log(11.212)≈2.418
最终 loss:
loss=−2.0+2.418=0.418
🌟 你可以这样理解:
| 部分 | 含义 |
|---|---|
| −x[class]- x[\text{class}]−x[class] | 惩罚正确答案打分太低 |
| log∑exp(x)\log \sum \exp(x)log∑exp(x) | 考虑所有类别的对比,如果错误类别打分高也被惩罚 |
| 最终目标 | “提升正确答案打分、降低错误答案打分” |



)

)





)



和SVN-VS2022插件(visualsvn)官网下载)



