一、基础概念与原理
1. Canal是什么?
阿里巴巴开源的MySQL binlog增量订阅与消费组件,通过伪装为MySQL Slave监听Master的binlog变更,实现实时数据同步。
Canal 官方网站:https://github.com/alibaba/canal
Canal Demo: https://gitee.com/original-intention/canal-gorgor-demo
2. 工作原理
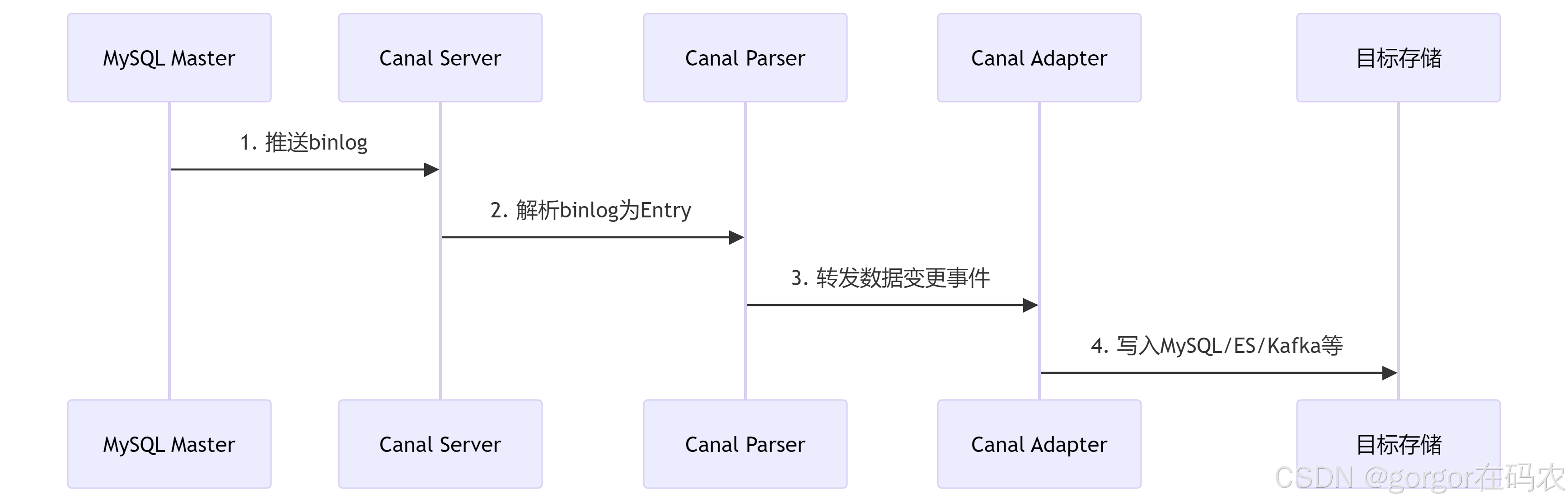
关键角色:
2.1 canal.deployer(服务端/Server)
-
核心作用:伪装成 MySQL 的从库(Slave),监听主库的
binlog变更,解析并转发数据变更事件。 -
关键功能:
-
连接 MySQL 主库,订阅
binlog并解析为结构化数据(如CanalEntry)。 -
支持将解析后的数据通过 TCP、Kafka、RocketMQ 等方式投递给下游消费者(如
canal.adapter)。 -
管理多个同步实例(
instance),每个实例对应一个独立的数据同步通道58。
-
-
配置文件:
-
conf/canal.properties:全局参数(如端口、存储模式)。 -
conf/example/instance.properties:实例级配置(如源数据库地址、账号、表过滤规则)。
-
2.2 canal.adapter(客户端适配器)
-
核心作用:消费
canal.deployer解析的数据,并同步到目标数据源(如 MySQL、Elasticsearch、OceanBase 等)。 -
关键功能:
-
支持多种目标源适配器(
rdb、es7、hbase等)。 -
提供 全量 & 增量同步能力,通过 REST API 触发全量同步(如
curl /etl/rdb/mysql1/user.yml)。 -
支持多表映射、字段转换、批量提交等配置。
-
-
配置文件:
-
conf/application.yml:定义数据源、消费模式(TCP/MQ)、目标适配器。 -
conf/rdb/*.yml或conf/es7/*.yml:表级同步规则(如源表、目标表、主键映射)。
-
2.3 canal.admin(管理平台)
-
核心作用:提供 Web 可视化界面,集中管理
canal.deployer集群和实例配置。 -
关键功能:
-
动态管理实例(启动/停止/配置)。
-
监控同步状态和日志。
-
支持高可用部署(依赖 ZooKeeper)。
-
-
部署要求:
-
需初始化元数据库(执行
canal_manager.sql)。 -
通过
conf/application.yml配置数据库连接和权限。
-
3. 核心应用场景:
-
业务解耦(如订单状态变更触发消息通知)
-
实时缓存更新(Redis)
-
跨数据库/机房数据同步(如MySQL→MySQL、MySQL→Elasticsearch)
-
数据库镜像
-
数据库实时备份
二、环境准备与部署
1. MySQL配置
- 开启binlog:
查看配置
show VARIABLES LIKE '%log_bin%';
show VARIABLES LIKE '%binlog_format%';
show VARIABLES LIKE '%server_id%';修改my.cnf,添加:
[mysqld]
log-bin=mysql-bin
binlog-format=ROW # 必须为ROW模式
server_id=1 # 与Canal的slaveId不重复- 创建Canal账号:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
2. Canal Server部署
- 下载与解压:canal.deployer-1.1.4.tar.gz
- 配置实例(
conf/canal.properties)
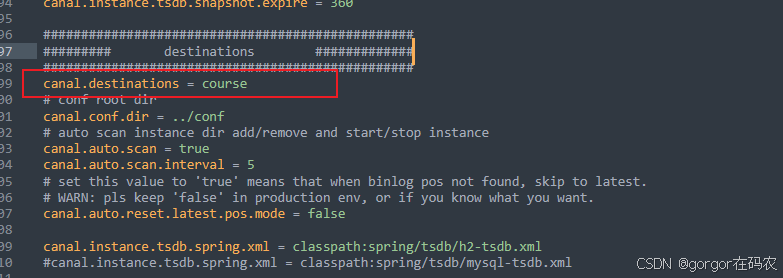
# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=mysqlbinlog.000065
canal.instance.master.position=238116155# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canalcanal.instance.master.journal.name和canal.instance.master.position的值,通过一下命令获取
show master STATUS;
第二处、是要对哪些相关的业务表进行监视,比如我们这里是course课程信息,数据放在
# table regex
canal.instance.filter.regex=seckill_order.course
三、数据同步实战
1. 引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.5.3</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.gorgor.canal</groupId><artifactId>canal-gorgor-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>canal-gorgor-demo</name><description>Demo project for Spring Boot</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.20</version><optional>true</optional></dependency><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.4</version><exclusions><exclusion><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId></exclusion></exclusions></dependency></dependencies></project>2. 配置(application.yml)
canal:server:ip: localhostport: 11111course:destination: coursebatchSize: 1000spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/shardingdb1?useSSL=false&serverTimezone=UTCusername: rootpassword: root3. 配置 CanalConnector 连接
@Configuration
@EnableScheduling
@EnableAsync
public class CanalCourseConfig {@Value("${canal.server.ip}")private String canalServerIp;@Value("${canal.server.port}")private int canalServerPort;@Value("${canal.server.username:blank}")private String userName;@Value("${canal.server.password:blank}")private String password;@Value("${canal.course.destination}")private String destination;@Bean("secKillConnector")public CanalConnector newSingleConnector(){String userNameStr = "blank".equals(userName) ? "" : userName;String passwordStr = "blank".equals(password) ? "" : password;return CanalConnectors.newSingleConnector(new InetSocketAddress(canalServerIp,canalServerPort), destination, userNameStr, passwordStr);}}
4. 数据同步代码
@Service
@Slf4j
public class SecKillData implements IProcessCanalData {private final static String COURSE_ID = "cid";private final static String COURSE_NAME = "cname";private final static String USER_ID = "user_id";private final static String COURSE_STATUS = "cstatus";@Autowired@Qualifier("secKillConnector")private CanalConnector connector;@Value("${canal.seckill.subscribe:server}")private String subscribe;@Value("${canal.course.batchSize}")private int batchSize;@Autowiredprivate JdbcTemplate jdbcTemplate;@PostConstruct@Overridepublic void connect() {connector.connect();if ("server".equals(subscribe))connector.subscribe(null);elseconnector.subscribe(subscribe);connector.rollback();}@PreDestroy@Overridepublic void disConnect() {connector.disconnect();}@Async@Scheduled(initialDelayString = "${canal.course.initialDelay:5000}", fixedDelayString = "${canal.course.fixedDelay:5000}")@Overridepublic void processData() {try {if (!connector.checkValid()) {log.warn("与Canal服务器的连接失效!!!重连,下个周期再检查数据变更");this.connect();return; // 重连后等待下个周期处理}Message message = connector.getWithoutAck(batchSize);long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {log.info("本次[{}]没有检测到课程数据更新。", batchId);// 空消息也必须确认connector.ack(batchId);return;}log.info("本次[{}]课程数据共有[{}]次更新需要处理", batchId, size);for (CanalEntry.Entry entry : message.getEntries()) {// 跳过事务开始/结束事件if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN ||entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());EventType eventType = rowChange.getEventType();for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {try {if (eventType == EventType.DELETE) {processDeleteEvent(rowData);} else if (eventType == EventType.INSERT) {processInsertEvent(rowData);} else if (eventType == EventType.UPDATE) {processUpdateEvent(rowData);}} catch (Exception e) {log.error("处理行数据失败: {}", e.getMessage(), e);}}}connector.ack(batchId); // 批量确认log.info("本次[{}]处理课程Canal同步数据完成", batchId);} catch (Exception e) {log.error("处理课程Canal同步数据失败,请检查:", e);}}/*** 处理删除事件*/private void processDeleteEvent(CanalEntry.RowData rowData) {// 删除事件使用Before列获取数据Map<String, String> beforeColumns = getColumnsMap(rowData.getBeforeColumnsList());Long cid = parseLongSafely(beforeColumns.get(COURSE_ID));if (cid != null) {jdbcTemplate.update("DELETE FROM course WHERE cid = ?", cid);log.info("删除课程活动: cid={}", cid);} else {log.error("删除事件中未找到有效的课程ID");}}/*** 处理插入事件*/private void processInsertEvent(CanalEntry.RowData rowData) {Map<String, String> afterColumns = getColumnsMap(rowData.getAfterColumnsList());Long cid = parseLongSafely(afterColumns.get(COURSE_ID));String cname = afterColumns.get(COURSE_NAME);Long userId = parseLongSafely(afterColumns.get(USER_ID));String cstatus = afterColumns.get(COURSE_STATUS);if (cid != null && cname != null && userId != null && cstatus != null) {jdbcTemplate.update("INSERT INTO course (cid, cname, user_id, cstatus) VALUES (?, ?, ?, ?)",cid, cname, userId, cstatus);log.info("新增课程活动: cid={}, cname={}", cid, cname);} else {log.error("插入事件中缺失必要字段: cid={}, cname={}, userId={}, cstatus={}",cid, cname, userId, cstatus);}}/*** 处理更新事件*/private void processUpdateEvent(CanalEntry.RowData rowData) {Map<String, String> afterColumns = getColumnsMap(rowData.getAfterColumnsList());Long cid = parseLongSafely(afterColumns.get(COURSE_ID));String cname = afterColumns.get(COURSE_NAME);Long userId = parseLongSafely(afterColumns.get(USER_ID));String cstatus = afterColumns.get(COURSE_STATUS);if (cid != null && cname != null && userId != null && cstatus != null) {jdbcTemplate.update("UPDATE course SET cname = ?, user_id = ?, cstatus = ? WHERE cid = ?",cname, userId, cstatus, cid);log.info("更新课程活动: cid={}, cname={}", cid, cname);} else {log.error("更新事件中缺失必要字段: cid={}, cname={}, userId={}, cstatus={}",cid, cname, userId, cstatus);}}/*** 将列列表转换为Map (列名 -> 值)*/private Map<String, String> getColumnsMap(List<Column> columns) {return columns.stream().collect(Collectors.toMap(Column::getName,Column::getValue,(existing, replacement) -> existing));}/*** 安全转换Long类型*/private Long parseLongSafely(String value) {try {return value != null && !value.isEmpty() ? Long.parseLong(value) : null;} catch (NumberFormatException e) {log.error("转换Long失败: {}", value);return null;}}
}具体代码在上面 Canal Demo 案例链接项目中。
初始化sql 在项目 resources/sql 目录下。
四、相关开源&产品
- canal 消费端开源项目: Otter
- 阿里巴巴去 Oracle 数据迁移同步工具: yugong
- 阿里巴巴离线同步开源项目 DataX
- 阿里巴巴数据库连接池开源项目 Druid
- 阿里巴巴实时数据同步工具 DTS

)





MySQL学习笔记(完):事务和锁)










模式 透明装饰模式与半透明装饰模式)
