关键词:
Uniform Manifold Approximation and Projection (UMAP):均匀流形近似与投影
一、说明
对于降维,首先看数据集是否线性,如果是线性的用pca降维;如果是非线性数据,t-SNE或者UMAP,本文针对UMAP的实验代码进行记录,但没有说UMAP的原理,原理在其它文档论述。
二、UMAP的基本概念
2.1 首先看什么是流形
流形(manifold)是一种数学概念,它描述了在局部看起来像欧几里得空间的拓扑空间。换句话说,流形是一个可以在局部范围内近似为欧几里得空间的空间。流形在几何、拓扑学、微分几何以及物理学中有广泛的应用。流形的基本概念包括连续性、局部坐标转移性和可微性,常见的例子有闭合曲面和克莱因瓶等。
一般来说,微分几何是建立在流形理论上的,学习这方面的理论可以参照微分几何相关书籍。
2.2 UMAP
均匀流形近似与投影 (UMAP) 是一种降维技术,类似于 t-SNE,可用于可视化,也可用于一般的非线性降维。该算法基于以下三个关于数据的假设:
数据在黎曼流形上均匀分布;
黎曼度量是局部常数(或可以近似为局部常数);
流形是局部连通的。
基于这些假设,可以用模糊拓扑结构对流形进行建模。通过寻找具有最接近等效模糊拓扑结构的数据低维投影来找到嵌入。
2.3 UMAP 安装
在conda上安装umap
conda install -c conda-forge umap-learn
在pip安装
pip install umap-learn
三、基本 UMAP 参数
UMAP 是一种相当灵活的非线性降维算法。它旨在学习数据的流形结构,并找到一个能够保留该流形基本拓扑结构的低维嵌入。在本笔记中,我们将生成一些可可视化的四维数据,演示如何使用 UMAP 提供其二维表示,然后研究各种 UMAP 参数如何影响最终的嵌入。本文档基于 Philippe Rivière 为 visionscarto.net 撰写的研究成果。
首先,我们需要一些基础库。首先numpy,我们需要 来进行基本的数组操作。由于我们要可视化结果,因此需要matplotlib和seaborn。最后,我们需要 umap来进行维度缩减本身。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import seaborn as sns
import umap
%matplotlib inline
sns.set(style='white', context='poster', rc={'figure.figsize':(14,10)})
接下来,我们需要一些数据来嵌入到低维表示中。为了使四维数据“可视化”,我们将从一个四维立方体中均匀随机地生成数据,以便我们可以将样本解释为指定颜色(和透明度)的 (R,G,B,a) 值的元组。这样,当我们绘制低维表示时,每个点都可以根据其四维值进行着色。为此,我们可以使用numpy。为了保持一致性,我们将固定一个随机种子。
np.random.seed(42)
data = np.random.rand(800, 4)
现在我们需要找到数据的低维表示。正如基础用法文档中所述,我们可以通过 在对象fit_transform()上使用方法来做到这一点UMAP。
fit = umap.UMAP()
%time u = fit.fit_transform(data)
CPU times: user 7.73 s, sys: 211 ms, total: 7.94 s
Wall time: 6.8 s
结果值u是数据的二维表示。我们可以用matplotlib绘制散点图来可视化结果u。我们可以使用源数据中关联的四维颜色为散点图的每个点着色。
plt.scatter(u[:,0], u[:,1], c=data)
plt.title('UMAP embedding of random colours');

正如你所见,结果是数据被放置在二维空间中,使得四维空间中相邻的点(即颜色相似的点)保持紧密相连。由于我们在颜色立方体中随机抽取了一些点,因此在颜色空间中,这些随机点恰好聚集在一起,从而产生了一定程度的诱导结构。
UMAP 有几个超参数会对最终的嵌入产生重大影响。在本笔记中,我们将介绍其中四个主要参数:
n_neighbors
min_dist
n_components
metric
每个参数都有不同的效果,我们将依次进行讨论。为了简化探索,我们首先编写一个简短的效用函数,该函数可以在给定一组参数选择的情况下使用 UMAP 拟合数据,并绘制结果图。
def draw_umap(n_neighbors=15, min_dist=0.1, n_components=2, metric='euclidean', title=''):fit = umap.UMAP(n_neighbors=n_neighbors,min_dist=min_dist,n_components=n_components,metric=metric)u = fit.fit_transform(data);fig = plt.figure()if n_components == 1:ax = fig.add_subplot(111)ax.scatter(u[:,0], range(len(u)), c=data)if n_components == 2:ax = fig.add_subplot(111)ax.scatter(u[:,0], u[:,1], c=data)if n_components == 3:ax = fig.add_subplot(111, projection='3d')ax.scatter(u[:,0], u[:,1], u[:,2], c=data, s=100)plt.title(title, fontsize=18)- n_neighbors
此参数控制 UMAP 如何平衡数据的局部结构与全局结构。它通过限制 UMAP 在尝试学习数据流形结构时所关注的局部邻域的大小来实现这一点。这意味着,较低的 值n_neighbors 将迫使 UMAP 专注于非常局部的结构(可能会损害全局);而较大的 值将迫使 UMAP 在估计数据的流形结构时关注每个点的更大邻域,从而为了获取更广泛的数据而丢失精细的细节结构。
在实践中,我们可以通过使用一系列n_neighbors值来拟合数据集,从而看到这一点。UMAP 的默认值n_neighbors (如上所述)为 15,但我们将研究从 2(流形的局部视图)到 200(数据的四分之一)范围内的值。
for n in (2, 5, 10, 20, 50, 100, 200):draw_umap(n_neighbors=n, title='n_neighbors = {}'.format(n))


当值为 时,n_neighbors=2我们可以看到 UMAP 仅仅将一些小的链粘合在一起,但由于视角狭窄/局部,无法看到它们是如何连接的。它还留下了许多不同的组成部分(甚至是单点)。这表明,从细节的角度来看,数据在整个空间中非常不连贯且分散。
随着n_neighborsUMAP 的增加,它能够更好地洞察数据的整体结构,将更多组件粘合在一起,并更好地覆盖数据的整体结构。到这个阶段, n_neighbors=20我们对数据有了相当好的整体视图,展示了各种颜色在整个数据集中是如何相互关联的。
随着n_neighbors数据的整体结构越来越受到关注。结果,虽然 n_neighbors=200图中能够很好地捕捉到整体结构(蓝色、绿色和红色;高亮度与低亮度),但却丢失了一些更精细的局部结构(单个颜色不再必然与其最接近的颜色匹配)。
这种效果很好地体现了所提供的局部/全局权衡 n_neighbors。
- min_dist
该min_dist参数控制 UMAP 将点打包的紧密程度。它实际上规定了低维表示中允许点之间的最小距离。这意味着较低的 值min_dist将导致嵌入更加块状。如果您对聚类或更精细的拓扑结构感兴趣,这将非常有用。较大的 值 min_dist将阻止 UMAP 将点打包在一起,而是专注于保留大致的拓扑结构。
min_dist(如上所述)的默认值为0.1。我们将查看从 0.0 到 0.99 的值范围。
for d in (0.0, 0.1, 0.25, 0.5, 0.8, 0.99):draw_umap(min_dist=d, title='min_dist = {}'.format(d))
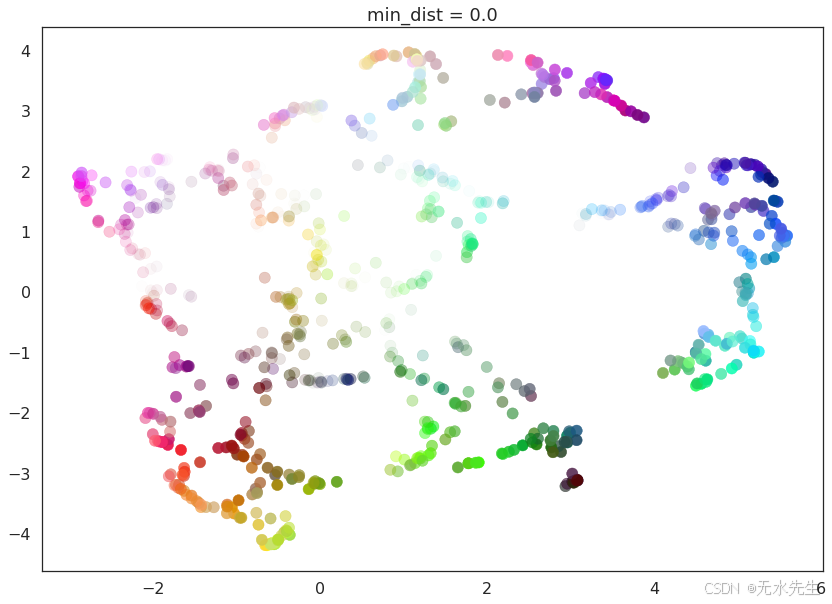


这里我们看到,min_dist=0.0UMAP 能够找到数据中较小的连通分量、团块和字符串,并在生成的嵌入中强调这些特征。随着 的min_dist增加,这些结构被分解成更柔和、更通用的特征,从而在损失更详细的拓扑结构的情况下,提供更好的数据总体视图。
- n_components
scikit-learn与许多降维算法一样, UMAP 提供了一个n_components参数选项,允许用户确定我们将数据嵌入到的降维空间的维数。与其他一些可视化算法(例如 t-SNE)不同,UMAP 在嵌入维度上具有良好的扩展性,因此您不仅可以将其用于二维或三维可视化,还可以将其用于其他领域。
为了演示的目的(以便我们可以看到参数的效果),我们将只研究一维和三维嵌入,我们希望将其可视化。
首先,我们将设置n_components为 1,强制 UMAP 将数据嵌入到一条线中。为了便于可视化,我们将在 y 轴上随机分布数据,以便在点之间提供一定的分隔。
draw_umap(n_components=1, title='n_components = 1')

现在我们来尝试一下n_components=3。为了实现可视化,我们将利用的matplotlib基本三维绘图。
draw_umap(n_components=3, title='n_components = 3')

在这里我们可以看到,有了更多的工作维度,UMAP 可以更轻松地以尊重数据拓扑结构的方式分离出颜色。
如上所述,实际上没有必要止步于n_components=3。如果您对(基于密度的)聚类或其他机器学习技术感兴趣,那么选择一个更大的嵌入维度(例如 10 或 50)并使其更接近数据所在的底层流形的维度可能会有所帮助。
- metric(度量)
我们将在本笔记本中考虑的最后一个 UMAP 参数是 metric参数。它控制如何在输入数据的环境空间中计算距离。默认情况下,UMAP 支持多种指标,包括:
闵可夫斯基风格度量
欧几里得
曼哈顿
切比雪夫
闵可夫斯基
其他空间指标
堪培拉
布雷柯蒂斯
半正矢
规范化空间度量
马哈拉诺比斯
明科夫斯基
塞克利德
角度和相关性指标
余弦
相关性
二进制数据的指标
汉明
雅卡德
骰子
罗素·拉奥
库尔辛斯基
罗杰斯塔尼莫托
索卡尔米切纳
索卡尔斯尼斯
圣诞节
四、预先计算
以上所有指标都假设你的输入数据是某个 N 维空间中的“原始”数据。有时,你已经计算了点之间的成对距离,并且输入数据是一个距离/相似度矩阵。在这种情况下,你可以执行以下操作。
UMAP(metric='precomputed').fit_transform(<distance matrix>)
其中任何一个都可以通过设置。metric=''metric='cosine’来指定;例如使用余弦距离作为您将使用的度量
然而,UMAP 提供的远不止这些——它支持自定义用户指标,只要这些指标能够nopython通过 numba 编译即可。在本笔记中,我们将研究此类自定义指标。要定义此类指标,我们需要 numba……
import numba
对于我们的第一个自定义指标,我们将距离定义为红色通道中差异的绝对值。
@numba.njit()
def red_channel_dist(a,b):return np.abs(a[0] - b[0])
为了更具冒险精神,进行一些色彩空间转换会很有用——为了简单起见,我们只需使用 HSL 公式从 (R,G,B) 元组中提取色调、饱和度和亮度。
@numba.njit()
def hue(r, g, b):cmax = max(r, g, b)cmin = min(r, g, b)delta = cmax - cminif cmax == r:return ((g - b) / delta) % 6elif cmax == g:return ((b - r) / delta) + 2else:return ((r - g) / delta) + 4@numba.njit()
def lightness(r, g, b):cmax = max(r, g, b)cmin = min(r, g, b)return (cmax + cmin) / 2.0@numba.njit()
def saturation(r, g, b):cmax = max(r, g, b)cmin = min(r, g, b)chroma = cmax - cminlight = lightness(r, g, b)if light == 1:return 0else:return chroma / (1 - abs(2*light - 1))
有了这些,我们可以定义三个额外的距离。第一个简单地测量色调的差异,第二个测量饱和度和亮度组合空间中的欧氏距离,第三个测量完整 HSL 空间中的距离。
@numba.njit()
def hue_dist(a, b):diff = (hue(a[0], a[1], a[2]) - hue(b[0], b[1], b[2])) % 6if diff < 0:return diff + 6else:return diff@numba.njit()
def sl_dist(a, b):a_sat = saturation(a[0], a[1], a[2])b_sat = saturation(b[0], b[1], b[2])a_light = lightness(a[0], a[1], a[2])b_light = lightness(b[0], b[1], b[2])return (a_sat - b_sat)**2 + (a_light - b_light)**2@numba.njit()
def hsl_dist(a, b):a_sat = saturation(a[0], a[1], a[2])b_sat = saturation(b[0], b[1], b[2])a_light = lightness(a[0], a[1], a[2])b_light = lightness(b[0], b[1], b[2])a_hue = hue(a[0], a[1], a[2])b_hue = hue(b[0], b[1], b[2])return (a_sat - b_sat)**2 + (a_light - b_light)**2 + (((a_hue - b_hue) % 6) / 6.0)
有了这些自定义指标,我们就可以让 UMAP 使用这些指标来嵌入数据,以测量输入数据点之间的距离。需要注意的是,这numba为我们定义距离函数提供了极大的灵活性。尽管如此,即使使用这些自定义函数,我们仍然能够保持 UMAP 所期望的高性能。
for m in ("euclidean", red_channel_dist, sl_dist, hue_dist, hsl_dist):name = m if type(m) is str else m.__name__draw_umap(n_components=2, metric=m, title='metric = {}'.format(name))





在这里,我们可以清楚地看到这些指标的效果。纯红色通道正确地将数据视为位于一维流形上,色调指标将数据解释为位于一个圆圈内,而 HSL 指标则根据饱和度和亮度使圆圈变胖。这合理地证明了 UMAP 在理解数据底层拓扑结构以及找到该拓扑结构的合适低维表示方面的强大功能和灵活性。


)
——合作共享——数据交流)





)

)



)



