Transformer架构图

transformer整体架构
1. Transformer 的参数配置
Transformer 的Encoder层和Decoder层都使用6个注意力模块,所有的子网络的输出维度均为512维,多头注意力部分使用了8个注意力头。
2. 归一化的方式
归一化的方式为LayerNorm,因为当时18年还没有其他更好的归一化方式,LayerNorm是对同一个样本的特征进行标准化,从而保证模型训练时不同网络层的输入输出分布的稳定,从而加速训练。
3. 注意力得分的计算为什么要除

因为不除的话会导致梯度消失的问题。
- 当两个分布为(均值=0,方差=1)的向量相乘时,其内积的结果的分布为(均值=0,方差=d),其中d是向量的维度,这就导致注意力分数中可能出现一些非常大的值,这种大值会在softmax中占据主导地位。
- softmax的计算公式为:

其梯度的计算公式为:

这里可以看出,一旦softmax处理的向量的某一项的值很大,那么softmax的结果对原向量的每一个输入x的梯度都会趋近于0,因为如果softmax(x_i) -> 1,那么其他的softmax(x_j) 就趋近于0了,在梯度公式里面无论哪一种情况都会导致梯度计算趋近于0,最终引起梯度消失,导致训练困难。
4. 什么是长程依赖问题?
长程依赖问题是说当输入序列很长时,模型难以记住序列早期的关键信息,导致输出时模型忘记这些关键内容。
RNN和LSTM是因为把长上下文压缩成一个或两个固定大小的向量,从而难以表示上下文中所有的关键信息,才导致了长程依赖问题。
5. Self-Attention中Dropout层的作用
Dropout层用于增强模型的泛化能力,防止模型过拟合。
具体来说:Dropout层是随机将目前的隐藏层中的值(即神经元的输出)以一定概率置为0丢弃。
Dropout一般运用在注意力得分矩阵,FeedForward输出,和残差连接之前。
通过Dropout,可以防止模型过度关注某些节点的输出。
6. 多头注意力中最后一层线性层的作用是什么
由于多头注意力里面每个头的value是独立计算的,计算过程彼此之间并没有任何交互,也没有任何信息传递,所以通过一个线性层来让不同的注意力头的输出结果相连,从而彼此之间有信息交互。

7. Position Encoding位置编码专题
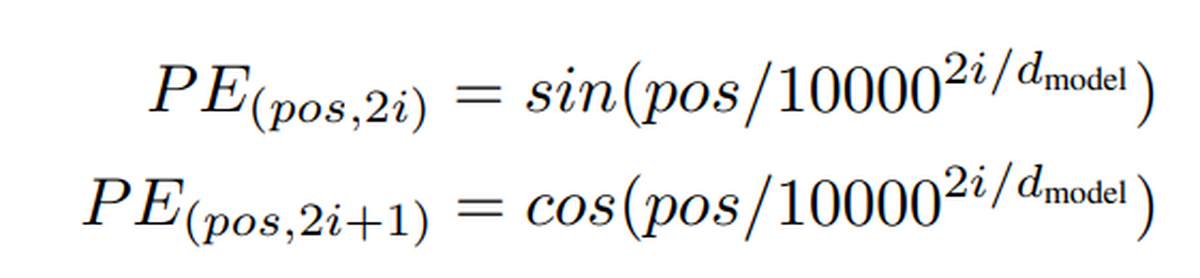

1)位置编码的目的和设计要求
由于self-attention机制利用的是全局的token信息,token和token的先后顺序性就丢失了,所以需要用一种方式来描述token之间的相对位置,于是transformer采用了位置编码的方式,位置编码函数的设计需要保证以下几点:
- 模型能够利用位置编码的信息间接捕获到token之间的相对位置或绝对位置
- 不同位置的token的位置编码不能相同
- 位置编码函数不能是隐函数
2)位置编码为什么采用三角函数?
因为位置编码是被加到嵌入中的,在后面的注意力计算中不同的token之间会有乘积运算,所以这里的位置编码在不同的token之间会有乘积的运算,而三角函数的积化和差公式则可以很好的建模这种内积到位置差的关系。
![]()
3)既然一个cos和sin就已经能够表达积化和差了,那直接用位置i交替使用cos i, sin i,cos i,sin i编码不就行了吗,为什么要设计不同频率的系数?
因为如果只有一种频率,模型其实是无法解构出真正的相对位置关系的,因为模型只能拿到内积的计算结果,假定为一个值v,这个v实际上等于cos(a-b+k*T),其中T为三角函数的周期,由于三角函数的周期性,这里没办法定位到真正的a-b那个解,所以通过不同的频率来求解到真正的相对位置解。所以在位置编码中,pos不变,随着i的增大,三角函数的周期在变大,且不同的i能保证周期不一致,高维的周期更长,频率更低。

4)为什么采用10000做分母的底数?
因为如果底数是一个较小值,那这会导致最高维的周期不会太大。试想,当token数量变多的时候,一旦后面某个token的位置正好是前面某个token的位置编码中所有三角函数周期的公倍数的整数倍(因为计算机浮点精度的存在),这会导致不同位置的token具有完全相同的位置编码,所以所有维度的三角函数周期的公倍数必须足够大,当选择10000时,最高维的周期已经足够长,可以满足绝大多数场景的需求了。
8. 为什么FeedForward层要先升维?
升维可以为模型提供更广阔的特征空间,使其能够捕捉到更丰富的信息,模型可以学习到更复杂的特征组合和交互,增强模型的表达能力。
9. 多头交叉注意力与多头自注意力的区别是什么?
多头交叉注意力中key和value来自于Encoder的输出,而query则来自于解码器中对生成的token的自注意力输出,多头交叉注意力的作用是希望生成的token能够利用到先前输入中存在的一些关键信息。

开发运行Scala应用)


的简单了解)

)


 快速入门 - 用户管理(上))


----安装e² studio)

)




)