Training data-efficient image transformers & distillation through attention
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 视觉Transformer:概述-Vision transformer: overview
- 通过注意力机制蒸馏-Distillation through attention
- 实验-Experiments
- 训练细节和消融实验-Training details & ablation
- 结论-Conclusion

论文链接
GitHub链接
本文提出数据高效的图像 Transformer(DeiT),仅在 Imagenet 上训练就能得到与卷积神经网络(convnets)性能相当的无卷积 Transformer。引入基于蒸馏 token 的师生策略,该策略能让学生模型通过注意力机制向教师模型学习,尤其是以 convnet 为教师时效果显著,使得 DeiT 在 Imagenet 上最高可达 85.2% 的准确率,且在迁移学习任务中表现出色。
摘要-Abstract
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. These high-performing vision transformers are pre-trained with hundreds of millions of images using a large infrastructure, thereby limiting their adoption.
In this work, we produce competitive convolution-free transformers by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop) on ImageNet with no external data.
More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks.
最近,纯粹基于注意力机制的神经网络已被证明能够处理图像分类等图像理解任务。这些高性能的视觉Transformer通过大规模的基础设施,利用数亿张图像进行预训练,这限制了它们的广泛应用。
在这项工作中,我们仅通过在ImageNet数据集上进行训练,就得到了具有竞争力的无卷积Transformer。我们在一台计算机上用不到3天的时间完成训练。我们的参考视觉Transformer(8600万个参数)在不使用外部数据的情况下,在ImageNet上实现了单裁剪83.1%的Top-1准确率。
更重要的是,我们引入了一种专门针对Transformer的师生策略。该策略依赖于一个蒸馏token,确保学生模型通过注意力机制向教师模型学习。我们展示了这种基于token的蒸馏方法的优势,特别是在使用卷积神经网络作为教师模型时。这使得我们在ImageNet(我们在此获得了高达85.2%的准确率)以及迁移到其他任务时,都能取得与卷积神经网络相媲美的结果。
引言-Introduction
该部分主要介绍了研究背景、目标与贡献。指出视觉Transformer虽能处理图像理解任务,但预训练依赖大量数据和计算资源。本文旨在仅用Imagenet训练出有竞争力的无卷积Transformer,并提出特定的师生蒸馏策略,具体内容如下:
- 研究背景:卷积神经网络(CNNs)凭借大规模训练集(如Imagenet)在图像理解任务中占据主导地位。受自然语言处理领域基于注意力模型成功的影响,研究人员开始探索在卷积网络中融入注意力机制,同时也有将Transformer成分移植到卷积网络的混合架构出现。视觉Transformer(ViT)直接应用自然语言处理架构处理图像分类,在使用大规模私有数据集(JFT-300M)预训练时效果优异,但存在训练数据需求大、计算资源消耗多以及在少量数据上泛化能力差的问题。
- 研究目标:仅在Imagenet数据集上进行训练,于单个8-GPU节点花费2-3天训练出与卷积神经网络性能相当的无卷积Transformer,即Data-efficient image Transformers(DeiT),改进训练策略,减少对大规模训练数据的依赖。
- 研究贡献
- 不含卷积层的神经网络在无外部数据情况下,于ImageNet上取得了具有竞争力的结果。新模型DeiT-S和DeiT-Ti参数更少,可分别视为ResNet-50和ResNet-18的对应模型。
- 引入基于蒸馏token的新蒸馏程序,该token与类token作用相似,但旨在再现教师模型估计的标签,通过注意力机制与类token交互,显著优于传统蒸馏方法。
- 经蒸馏的图像Transformer从卷积网络教师模型学习的效果,优于从性能相当的Transformer教师模型的学习效果。
- 在多个流行公共基准测试(如CIFAR-10、CIFAR-100等)的下游任务中,基于ImageNet预训练的DeiT模型表现出色。
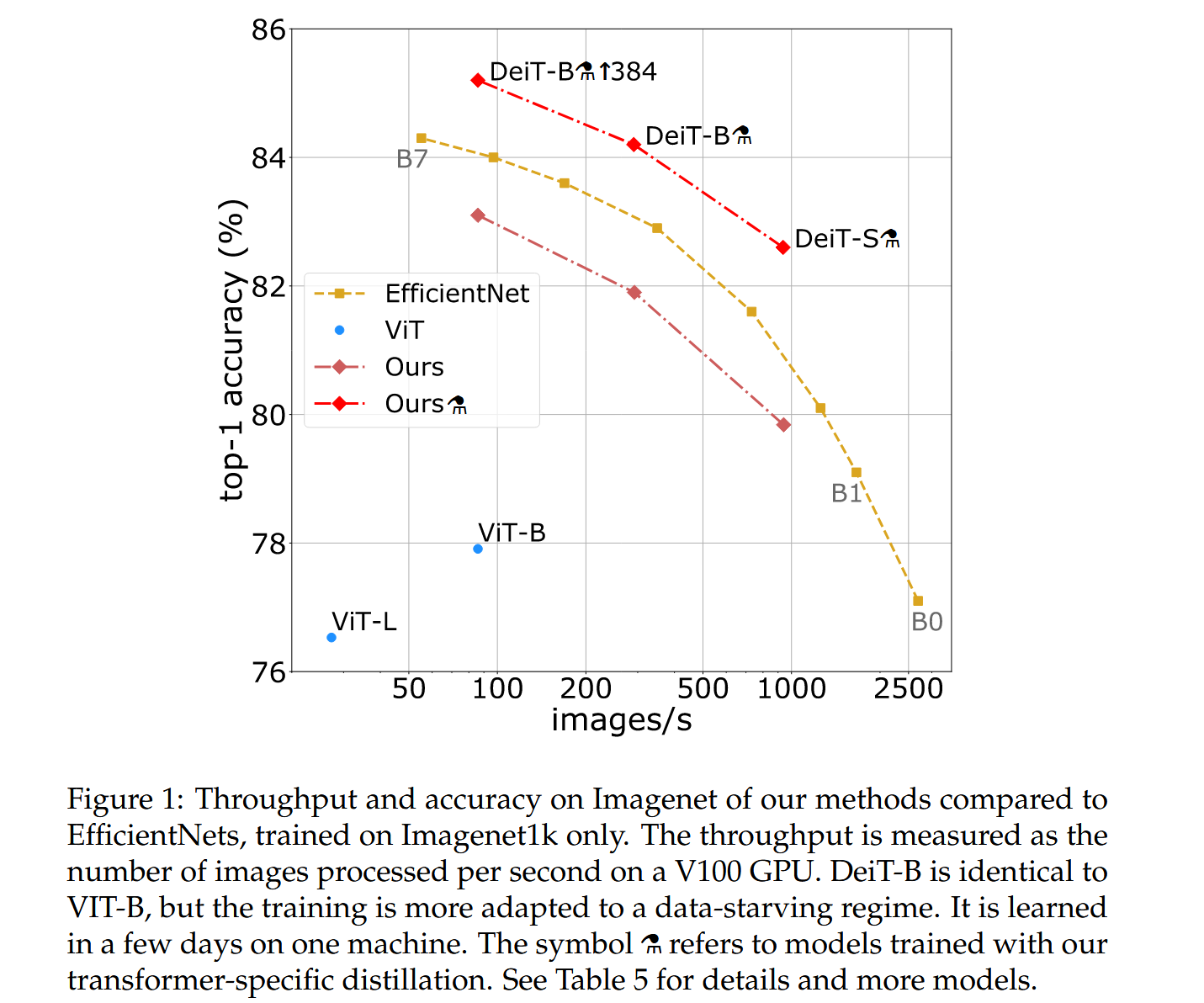
图1:我们的方法与仅在Imagenet1k上训练的EfficientNet相比,在Imagenet上的吞吐量和准确率。吞吐量是指在V100 GPU上每秒处理的图像数量。DeiT-B与ViT-B架构相同,但DeiT-B的训练更适用于数据稀缺的情况,它可以在一台机器上用几天时间完成训练。符号⚗表示使用我们特定于Transformer的蒸馏方法训练的模型。更多详细信息和模型请见表5。
相关工作-Related Work
该部分主要回顾了与本文研究相关的工作,涵盖图像分类领域的发展、视觉Transformer(ViT)的进展、Transformer架构在自然语言处理中的地位以及知识蒸馏(KD)的应用,具体内容如下:
- 图像分类的发展历程:图像分类是计算机视觉的核心任务,常作为衡量图像理解进展的基准,其成果通常可迁移至检测、分割等相关任务。自2012年AlexNet出现,卷积神经网络(CNNs)便主导该领域,成为事实上的标准,ImageNet数据集推动了CNNs架构和学习方法的不断演进。
- 视觉变换器(ViT)的发展:早期Transformer用于图像分类的性能不如CNNs,但结合了CNNs和Transformer(包括自注意力机制)的混合架构在图像分类、检测、视频处理、无监督对象发现以及统一文本 - 视觉任务等方面展现出竞争力。ViT的出现缩小了与ImageNet上最先进的CNNs的差距,尽管其性能显著,但ViT需要在大量精心整理的数据上进行预训练才能有效,而本文仅使用Imagenet1k数据集就实现了强大的性能。
- Transformer架构在自然语言处理中的地位:Transformer架构由Vaswani等人提出用于机器翻译,目前是所有自然语言处理(NLP)任务的参考模型。许多用于图像分类的CNNs改进方法都受到Transformer的启发,例如Squeeze and Excitation、Selective Kernel和Split-Attention Networks等都利用了类似于Transformer自注意力机制的原理。
- 知识蒸馏(KD)的应用:KD是一种训练范式,学生模型利用来自强大教师网络的“软”标签(教师softmax函数的输出向量)进行训练,而非仅使用“硬”标签(分数最高值对应的标签),这可以提高学生模型的性能,也可看作是将教师模型压缩为较小的学生模型的一种形式。KD能够以软方式在学生模型中传递归纳偏差,例如使用卷积模型作为教师模型可以在Transformer模型中引入卷积相关的偏差。本文研究了用卷积网络或Transformer作为教师模型对Transformer学生模型进行蒸馏,并引入了一种特定于Transformer的新蒸馏过程,展示其优越性。
视觉Transformer:概述-Vision transformer: overview
该部分主要介绍了视觉Transformer的关键组件和特性,包括多头自注意力层、图像Transformer块、位置编码和分辨率处理,为理解后续提出的DeiT模型及相关改进奠定基础,具体内容如下:
- 多头自注意力层(MSA):注意力机制基于可训练的关联记忆,通过查询向量与键向量的内积匹配,经缩放和softmax归一化后得到权重,进而对值向量加权求和得到输出。Self-attention层中,查询、键和值矩阵由输入向量通过线性变换计算得出。多头自注意力层则是将h个自注意力函数应用于输入,再重新投影到指定维度 。其公式为 A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K ⊤ / d ) V Attention(Q, K, V)=Softmax\left(Q K^{\top} / \sqrt{d}\right) V Attention(Q,K,V)=Softmax(QK⊤/d)V,其中 Q Q Q、 K K K、 V V V分别为查询、键和值矩阵, d d d为维度。
- 图像Transformer块:在MSA层之上添加前馈网络(FFN)构成完整的Transformer块。FFN由两个线性层和中间的GeLu激活函数组成,先将维度从 D D D扩展到 4 D 4D 4D,再还原回 D D D。MSA和FFN都通过残差连接和层归一化操作,提升模型性能。
- 视觉Transformer处理图像的方式:基于ViT模型,将固定大小的输入RGB图像分解为多个固定尺寸(16×16像素)的图像块,每个图像块通过线性层投影保持维度不变。由于Transformer块对图像块嵌入顺序不变性,需添加固定或可训练的位置嵌入来融入位置信息,同时还会添加一个可训练的类token,最终仅使用类向量预测输出。
- 位置编码与分辨率:在训练和微调网络时,改变输入图像分辨率时,保持图像块大小不变会导致输入图像块数量改变。因Transformer块和类token的架构,模型和分类器无需修改即可处理更多token,但需调整位置嵌入。常见做法是在改变分辨率时对位置编码进行插值,实验证明这种方法在后续微调阶段有效。
通过注意力机制蒸馏-Distillation through attention
该部分主要介绍了通过注意力机制进行蒸馏的方法,涵盖了硬蒸馏与软蒸馏的对比,以及引入蒸馏令牌改进蒸馏效果的内容,具体如下:
- 软蒸馏与硬标签蒸馏
- 软蒸馏:软蒸馏通过最小化教师模型和学生模型softmax输出之间的Kullback - Leibler散度来实现。其蒸馏目标为 L g l o b a l = ( 1 − λ ) L C E ( ψ ( Z s ) , y ) + λ τ 2 K L ( ψ ( Z s / τ ) , ψ ( Z t / τ ) ) \mathcal{L}_{global }=(1-\lambda) \mathcal{L}_{CE}\left(\psi\left(Z_{s}\right), y\right)+\lambda \tau^{2} KL\left(\psi\left(Z_{s} / \tau\right), \psi\left(Z_{t} / \tau\right)\right) Lglobal=(1−λ)LCE(ψ(Zs),y)+λτ2KL(ψ(Zs/τ),ψ(Zt/τ)),其中 Z t Z_{t} Zt、 Z s Z_{s} Zs 分别是教师和学生模型的logits, τ \tau τ 为蒸馏温度, λ \lambda λ 用于平衡散度损失和交叉熵损失, ψ \psi ψ 为softmax函数。
- 硬标签蒸馏:该方法将教师模型的硬决策作为真实标签。其目标函数为 L g l o b a l h a r d D i s t i l l = 1 2 L C E ( ψ ( Z s ) , y ) + 1 2 L C E ( ψ ( Z s ) , y t ) \mathcal{L}_{global }^{hardDistill }=\frac{1}{2} \mathcal{L}_{CE}\left(\psi\left(Z_{s}\right), y\right)+\frac{1}{2} \mathcal{L}_{CE}\left(\psi\left(Z_{s}\right), y_{t}\right) LglobalhardDistill=21LCE(ψ(Zs),y)+21LCE(ψ(Zs),yt),其中 y t = a r g m a x c Z t ( c ) y_{t}=argmax_{c} Z_{t}(c) yt=argmaxcZt(c) 是教师模型的硬决策。硬标签可通过标签平滑转化为软标签,实验中 ε \varepsilon ε 固定为0.1。
- 蒸馏token
- token作用:在初始嵌入(图像块和类token)中添加新的蒸馏token,它与类token类似,通过自注意力与其他嵌入交互,网络输出时其目标是再现教师模型预测的(硬)标签,而非真实标签,从而让模型从教师输出中学习。
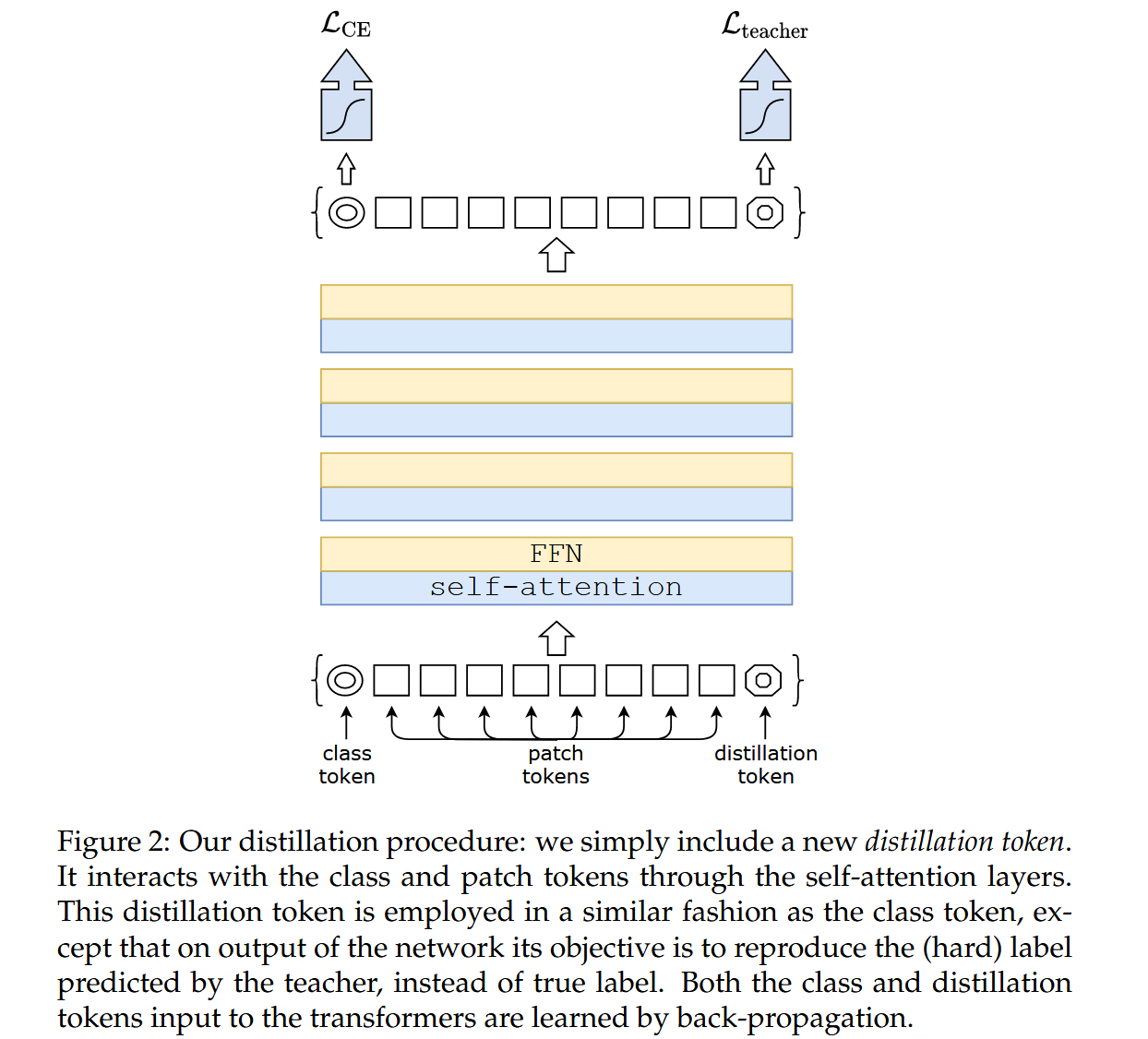
图2:我们的蒸馏过程:我们简单地引入了一个新的蒸馏token。它通过自注意力层与类别token和图像块token进行交互。这个蒸馏token的使用方式与类别token类似,不同之处在于,在网络输出时,它的目标是再现教师模型预测的(硬)标签,而不是真实标签。输入到Transformer中的类别token和蒸馏token都是通过反向传播学习得到的。 - 对比实验:实验表明,学习到的类token和蒸馏token会收敛到不同向量。与简单添加额外类token相比,蒸馏token能显著提升模型性能。例如,两个随机初始化的类token在训练中会收敛到相同向量,对分类性能无提升,而蒸馏策略则优于普通蒸馏基线。
- token作用:在初始嵌入(图像块和类token)中添加新的蒸馏token,它与类token类似,通过自注意力与其他嵌入交互,网络输出时其目标是再现教师模型预测的(硬)标签,而非真实标签,从而让模型从教师输出中学习。
- 微调与分类
- 微调:在更高分辨率的微调阶段,同时使用真实标签和教师预测,使用与目标分辨率相同的教师模型(通常由低分辨率教师模型转换得到)。仅使用真实标签会降低教师模型的作用,导致性能下降。
- 分类:测试时,Transformer产生的类嵌入和蒸馏嵌入都可与线性分类器结合进行图像标签推断。推荐方法是对两个分类器的softmax输出进行后期融合来进行预测。
实验-Experiments
该部分主要通过一系列实验,对模型、蒸馏策略、效率与精度权衡以及迁移学习等方面进行了分析和评估,具体内容如下:
-
Transformer模型:文中的DeiT架构与ViT相同但训练策略和蒸馏令牌有差异,不使用MLP头预训练,仅用线性分类器。介绍了DeiT - B、DeiT - S和DeiT - Ti三种模型,其参数数量和计算量依次减小。
表1:我们DeiT架构的变体。较大的模型DeiT-B与ViT-B具有相同的架构。不同模型之间仅有的变化参数是嵌入维度和头数,我们保持每个头的维度不变(等于64)。较小的模型参数数量较少,吞吐量更快。吞吐量是针对分辨率为224×224的图像进行测量的。

-
蒸馏策略分析
-
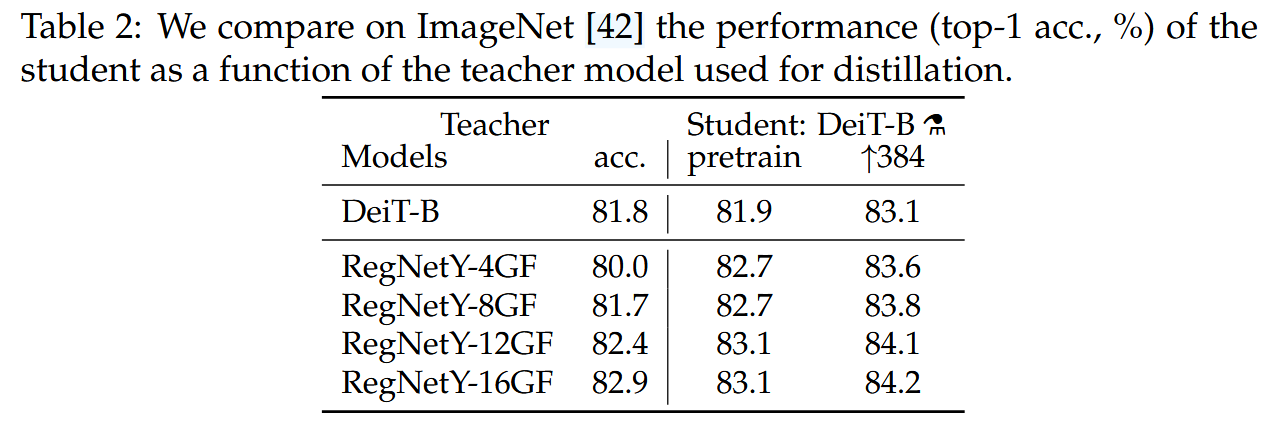
不同教师模型的影响:使用convnet作为教师模型比使用transformer性能更好。以RegNetY - 16GF为默认教师模型,它在ImageNet上top - 1准确率达82.9%。
表2:我们在ImageNet数据集上比较了作为蒸馏所用教师模型函数的学生模型性能(top-1准确率,%)。
-
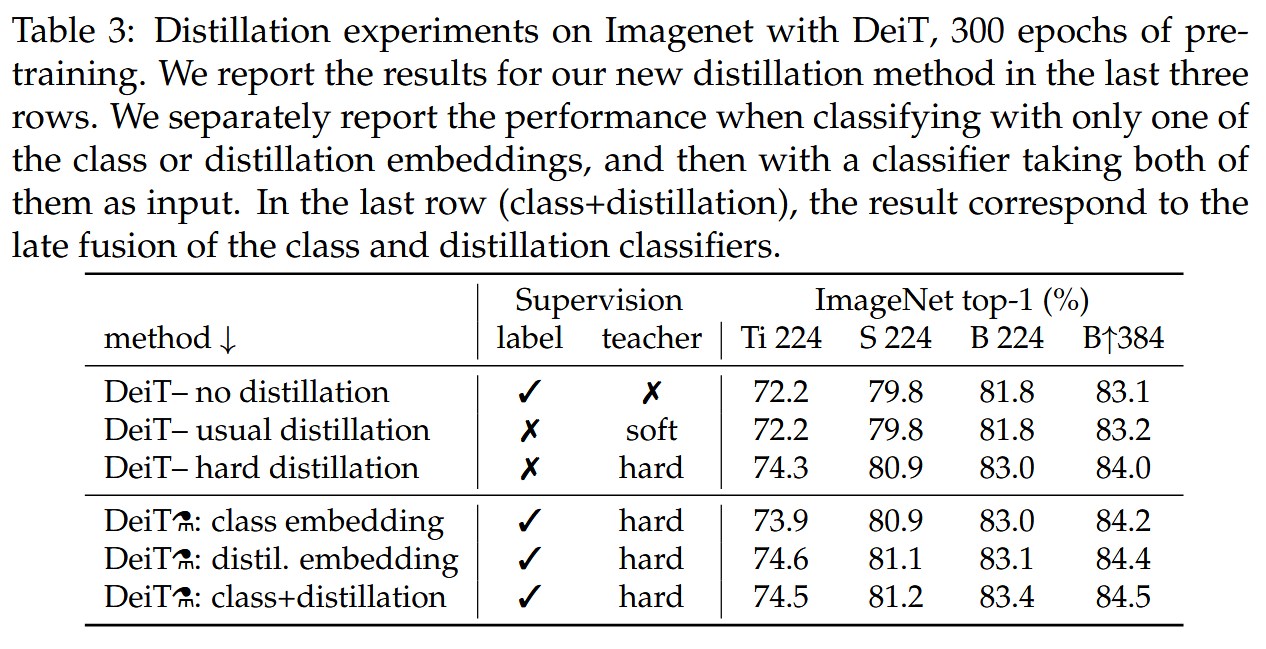
不同蒸馏方法对比:硬蒸馏在transformer中表现优于软蒸馏,如在224×224分辨率下,硬蒸馏准确率可达83.0%,而软蒸馏仅为81.8%。基于蒸馏token的策略进一步提升了性能,联合使用类token和蒸馏token的分类器效果最佳。
表3:使用DeiT在ImageNet上进行的蒸馏实验,预训练300个epoch。最后三行报告了我们新蒸馏方法的结果。我们分别报告仅使用类嵌入或蒸馏嵌入进行分类时的性能,以及将两者都作为输入的分类器的性能。在最后一行(类+蒸馏)中,结果对应于类分类器和蒸馏分类器的后期融合。
-
蒸馏令牌的优势:蒸馏token比类token效果略好,且与convnet预测更相关,在初始训练阶段优势明显。
表4:卷积神经网络、图像Transformer和经过蒸馏的变换器之间的分歧分析:我们报告了所有分类器对中分类结果不同的样本比例,即不同决策的比率。我们纳入了两个未经过蒸馏的模型(一个RegNetY和DeiT-B),以便比较我们经过蒸馏的模型和分类头与这些教师模型的相关性。
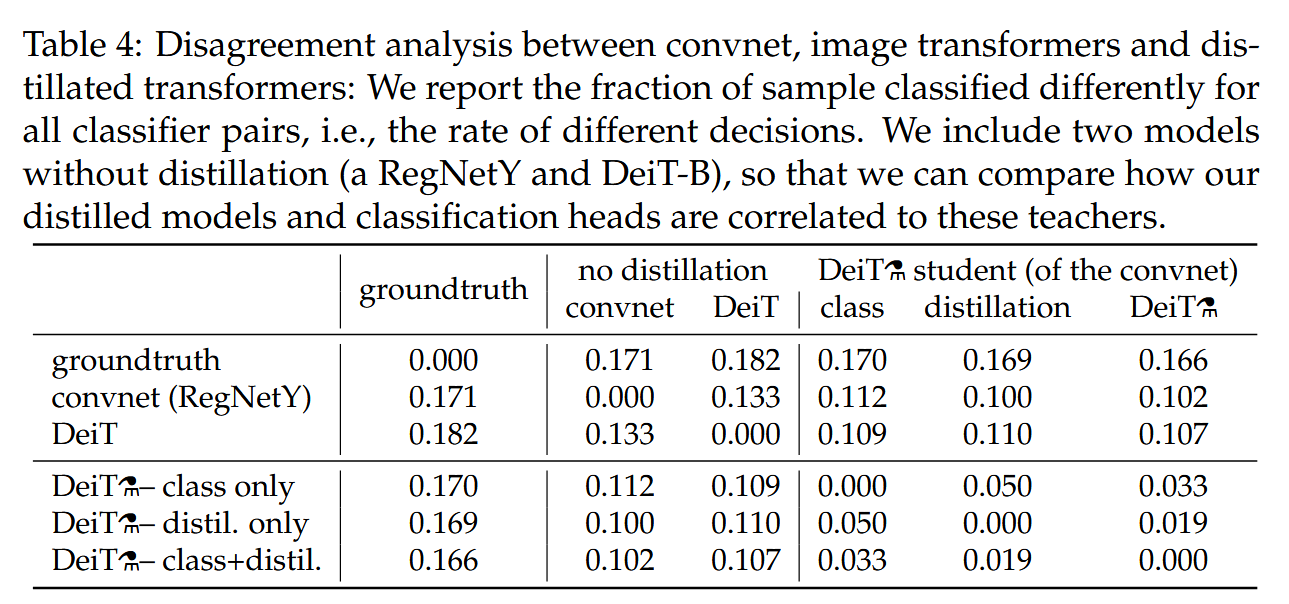
-
训练轮数的影响:增加训练轮数可显著提升蒸馏训练的性能,DeiT - B⚗在300轮训练时已优于DeiT - B,且继续训练仍可受益。
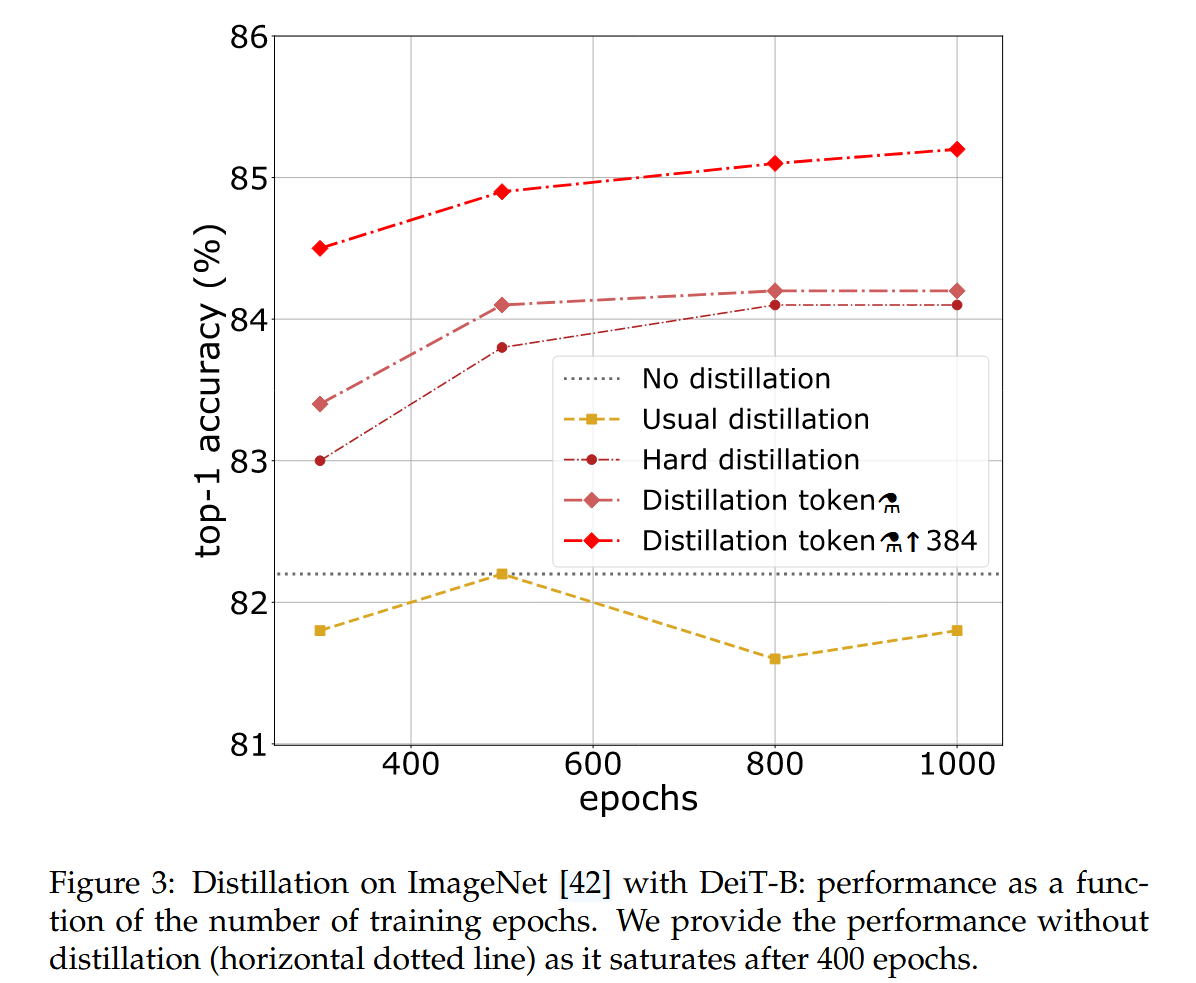
图3:使用DeiT-B在ImageNet上进行蒸馏:性能随训练轮数的变化。我们给出了未进行蒸馏时的性能(水平虚线),因为它在400轮训练后达到饱和。
-
-
效率与精度的权衡:将DeiT与流行的EfficientNet进行对比,结果表明DeiT在仅使用Imagenet训练时,已接近EfficientNet的性能,缩小了视觉transformer与convnet的差距。使用蒸馏策略后,DeiT⚗超越了EfficientNet,且在准确率和推理时间的权衡上表现更优,在ImageNet V2和ImageNet Real数据集上也有出色表现。
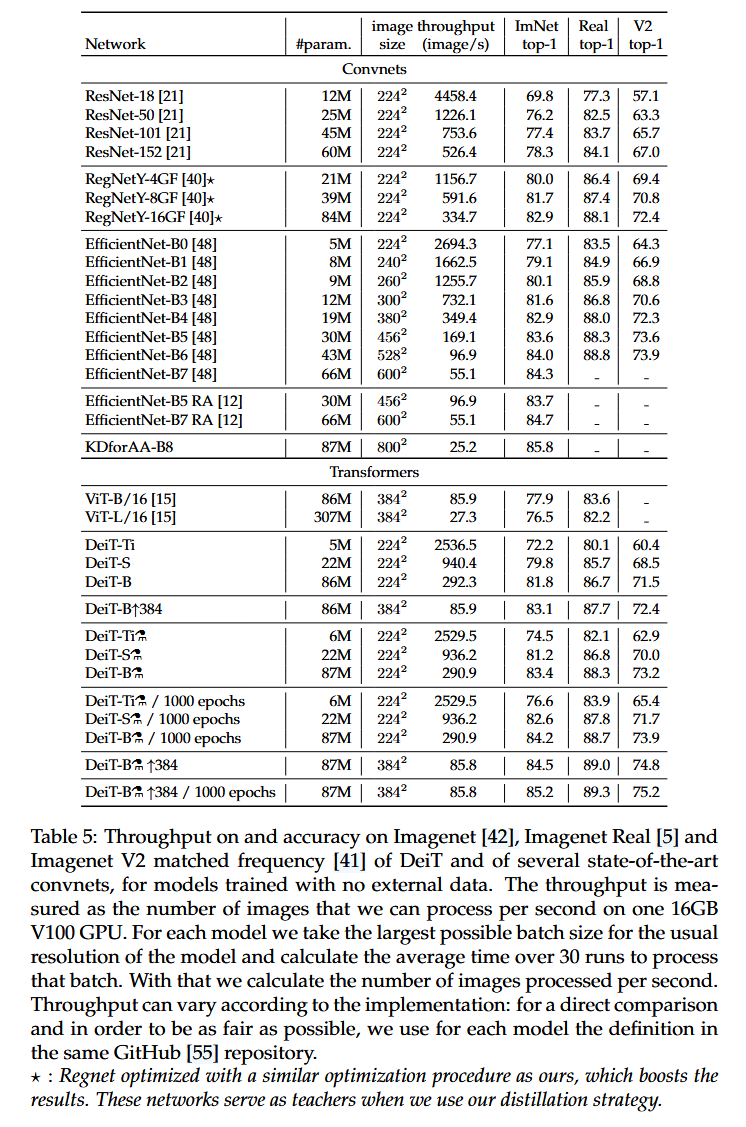
表5:DeiT以及几种最先进的卷积神经网络在无外部数据训练情况下,在ImageNet、ImageNet Real和ImageNet V2匹配频率数据集上的吞吐量和准确率。吞吐量是指在一块16GB的V100 GPU上每秒能够处理的图像数量。对于每个模型,我们采用其常规分辨率下最大可能的批量大小,并计算处理该批量30次运行的平均时间,由此计算出每秒处理的图像数量。吞吐量会因实现方式而异:为了进行直接比较并尽可能保证公平性,我们对每个模型都采用相同GitHub代码库中的定义。 -
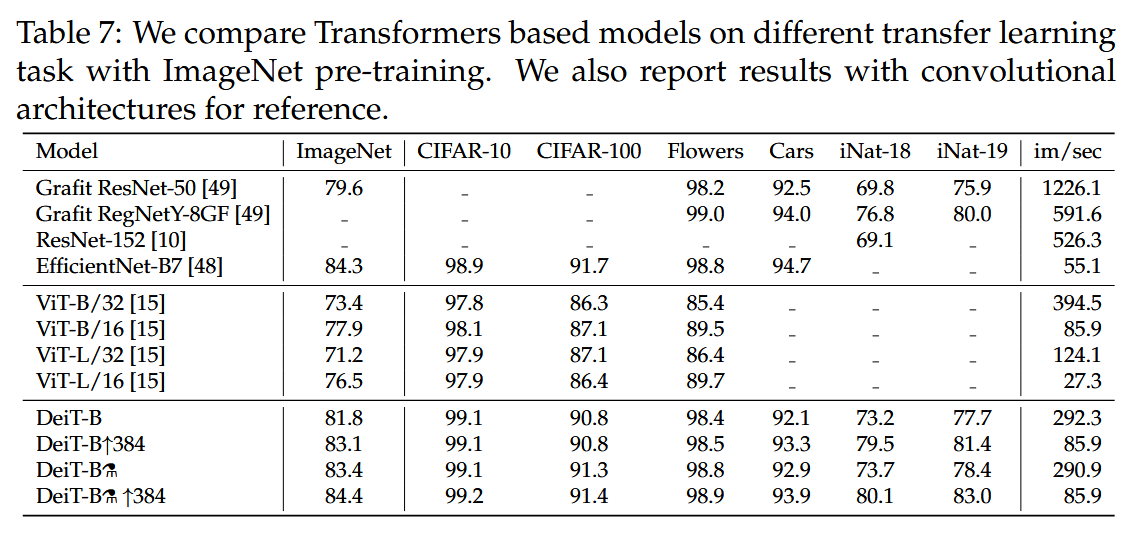
迁移学习性能:在多个下游任务(如CIFAR - 10、CIFAR - 100、Oxford - 102 flowers、Stanford Cars和iNaturalist - 18/19)上对DeiT进行微调评估,结果显示其与有竞争力的convnet模型表现相当,证明了DeiT良好的泛化能力。在小数据集CIFAR - 10上从头训练,DeiT也能取得一定成果,但不如经过ImageNet预训练的效果好。
表6:用于我们不同任务的数据集。
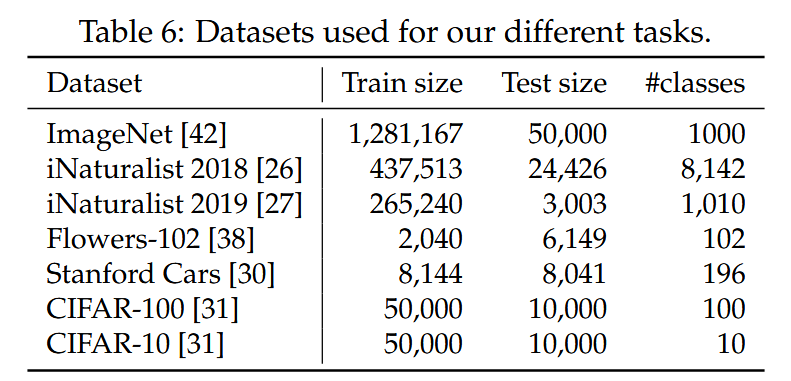
表7:我们比较了基于Transformer的模型在不同的ImageNet预训练迁移学习任务中的表现。同时,我们也报告了卷积架构的结果以供参考。
训练细节和消融实验-Training details & ablation
该主要介绍了DeiT的训练细节,并对训练方法进行消融实验分析,以探究各因素对模型性能的影响,具体内容如下:
- 初始化和超参数设置:Transformer对初始化较为敏感,文中遵循Hanin和Rolnick的建议,使用截断正态分布初始化权重。在蒸馏时,依据Cho等人的建议选取超参数,如通常(软)蒸馏中 τ = 3.0 \tau = 3.0 τ=3.0, λ = 0.1 \lambda = 0.1 λ=0.1。同时给出了默认的训练超参数,包括优化器、学习率、权重衰减等设置。
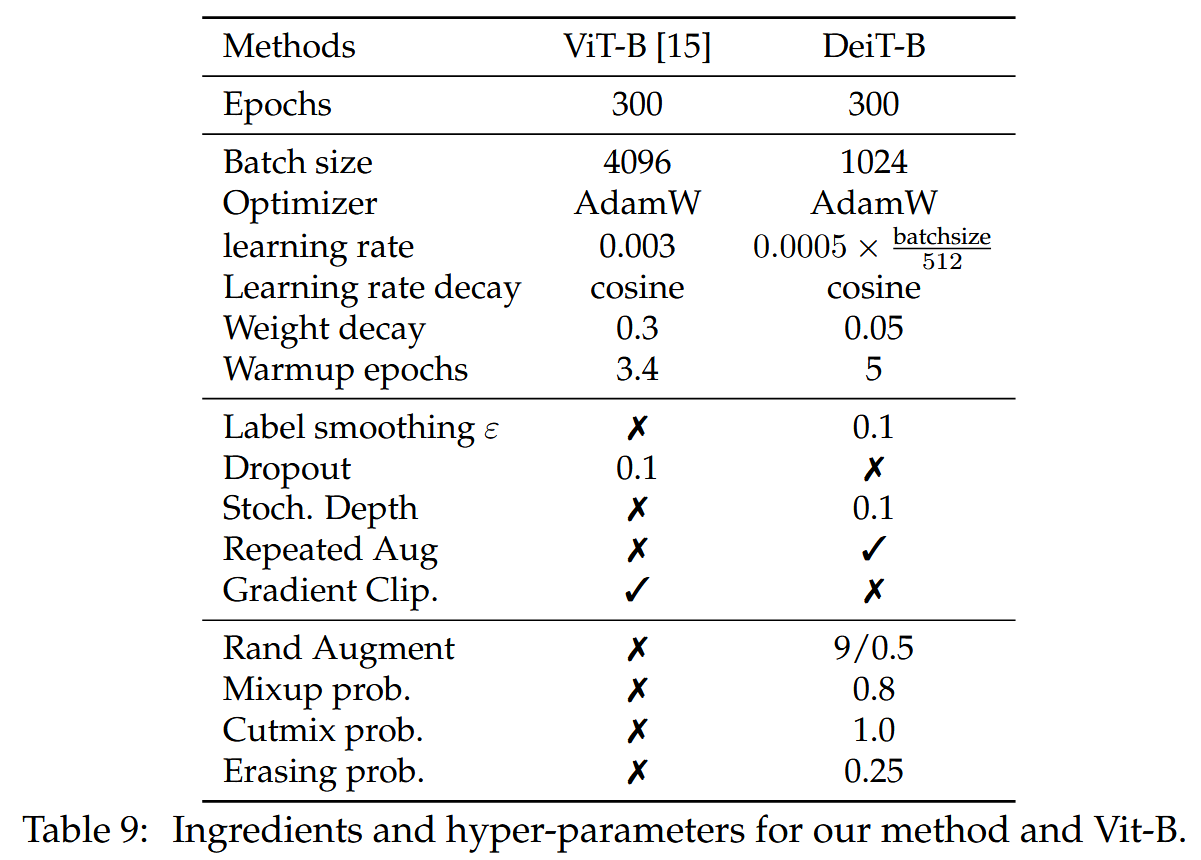
表9:我们的方法以及ViT-B所使用的要素和超参数。 - 数据增强:与集成更多先验(如卷积)的模型相比,Transformer需要更多数据,因此依赖大量数据增强方法来实现高效训练。评估了Auto - Augment、Rand - Augment、随机擦除等多种强数据增强方法,发现几乎所有方法都有用,最终选择Rand - Augment。而dropout对训练无明显帮助,故被排除在训练过程之外。
- 正则化与优化器:考虑了不同优化器,并对学习率和权重衰减进行交叉验证。结果表明,AdamW优化器在与ViT相同学习率但更小权重衰减的设置下表现最佳,因为原论文中的权重衰减在该实验设置下会影响收敛。此外,采用随机深度、Mixup、Cutmix和重复增强等正则化方法,这些方法有助于模型收敛和性能提升,其中重复增强是训练过程的关键成分之一。
- 指数移动平均(EMA):评估了训练后网络的EMA,发现其有少量性能提升,但微调后与普通模型性能相同,即微调后优势消失。
- 不同分辨率下的微调:采用Touvron等人的微调过程,保持训练时的数据增强,对位置嵌入采用双三次插值,以近似保留向量范数,避免直接使用双线性插值导致的精度下降。对比了AdamW和SGD两种优化器在微调阶段的性能,发现二者表现相似。还研究了不同微调分辨率对模型性能的影响,默认在224分辨率训练,384分辨率微调,实验表明更高分辨率微调可提升性能。

表8:在ImageNet上对训练方法进行的消融研究。最上面一行(“无”)对应我们用于DeiT的默认配置。符号“√”和“×”分别表示我们使用和不使用相应的方法。我们报告了在分辨率为224×224下初始训练后的准确率得分(%),以及在分辨率为384×384下微调后的准确率得分。超参数根据表9进行固定,可能并非是最优设置。“*”表示模型训练效果不佳,可能是因为超参数不适用。
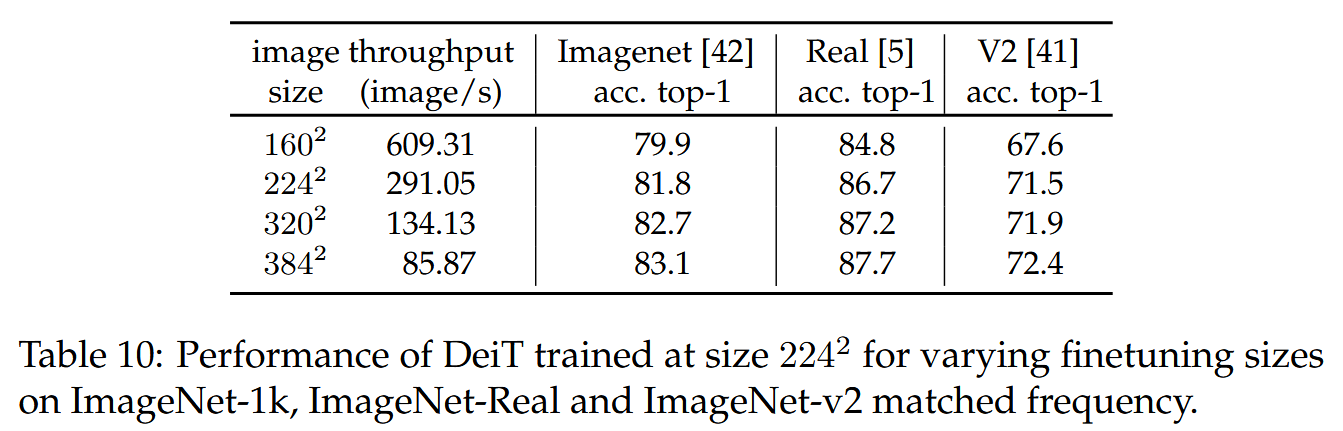
表10:在ImageNet-1k、ImageNet-Real和ImageNet-v2匹配频率数据集上,初始训练尺寸为224的DeiT模型在不同微调尺寸下的性能表现。 - 训练时间:DeiT - B进行300轮典型训练,在2个节点上需37小时,在单个节点上需53小时,相比之下RegNetY - 16GF训练慢20%。DeiT - S和DeiT - Ti在4个GPU上训练不到3天。可选在更大分辨率下微调,在单个8 GPU节点上需20小时(对应25轮),使用重复增强使每轮训练实际看到的图像数量为三分之一,但整体训练效果更好。
结论-Conclusion
该部分总结了研究成果,分析了研究的局限性与未来方向,并介绍了代码开源情况,具体内容如下:
- 研究成果:提出数据高效的图像Transformer - DeiT,通过改进训练方法,尤其是引入新颖的蒸馏程序,使得模型无需大量数据训练就能取得与卷积神经网络相当的性能。在ImageNet数据集上,DeiT展现出强大的竞争力,如DeiT - B模型在无外部数据情况下单裁剪top - 1准确率达83.1%,使用蒸馏策略后最高可达85.2% 。
- 研究局限性与未来方向:卷积神经网络经过近十年优化,包括易过拟合的架构搜索,而DeiT仅采用现有数据增强和正则化策略,未对架构做重大改变。因此,研究更适合Transformer的数据增强方法有望进一步提升DeiT性能。















)



