不依赖Hadoop搭建Spark环境
- 0 概述
- 1 单机安装Spark
- 1.1 下载Spark预编译包
- 1.2 解压和设置
- 1.3 配置环境变量
- 1.4 验证安装
- 2 Spark运行模式
- 2.1 Local模式(本地模式)
- 2.1.1 Spark Shell
- 2.1.1.1 Python版的Shell
- 2.1.1.2 Scala版的Shell
- 2.1.2 提交独立的Spark应用
- 2.2 Local Cluster模式(本地集群模拟模式)
- 2.3 Standalone模式(独立集群模式)
- 2.3.1 修改主机名
- 2.3.2 配置免密登陆
- 2.3.3 配置master机器
- 2.3.4 配置worker节点
- 2.3.5 启动集群
- 3 总结
大家好,我是欧阳方超,公众号同名。

0 概述
Spark环境不依赖Hadoop就可以搭建起来,这对新手小白来说无疑提供了极大的便利。本篇就介绍一下如何在不安装Hadoop的情况下搭建Spark环境。本文使用的Java、Python版本分别是1.8.0_201、3.11.13。
1 单机安装Spark
1.1 下载Spark预编译包
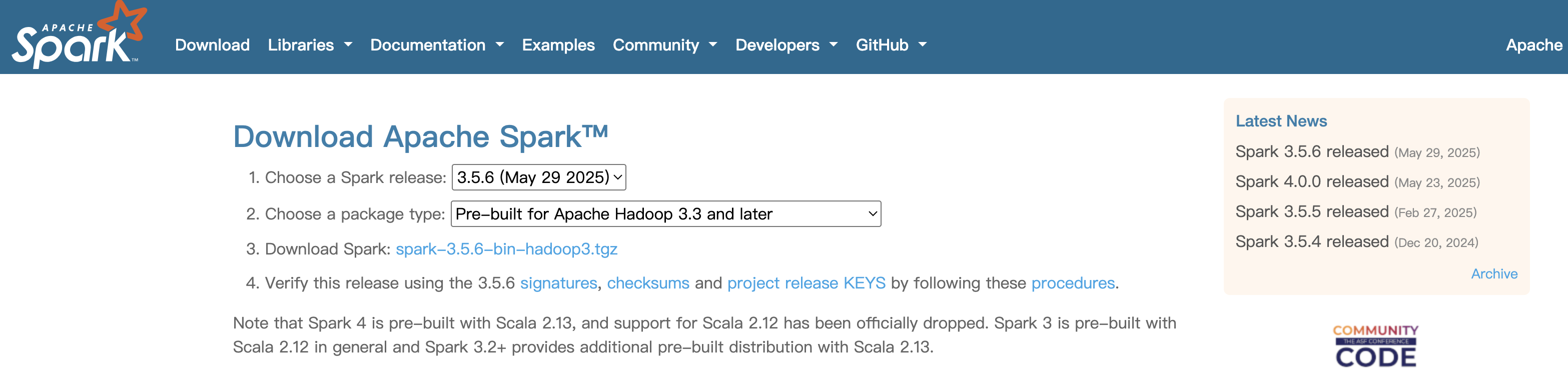
访问Spark官网下载页面:https://spark.apache.org/downloads.html
选择以下选项:
Spark版本:建议选择最新的稳定版
Package type:选择 "Pre-built for Apache Hadoop 3.3 and later"2
| 选择项 | 推荐值 | 说明 |
|---|---|---|
| Spar版本 | 最新的稳定版 | 新版本通常性能更好且修复了已知问题 |
| Package类型 | Pre-built for Apache Hadoop 3.3 and later | 这种包内包含了常用的Hadoop依赖,无需单独安装Hadoop即可运行 |
| 下载格式 | .tgz压缩包 | 适用于Linux和Mac系统 |
下图为我在下载时所做的选择。
1.2 解压和设置
解压下载的Spark压缩包
[root@192 softwares]# tar -zxvf spark-3.5.6-bin-hadoop3
1.3 配置环境变量
将Spark的可执行文件路径添加到PATH中,这样就可以在终端中运行Spark相关命令了。编辑/etc/profile文件,在末尾追加如下内容:
export SPARK_HOME=/softwares/spark-3.5.6-bin-hadoop3
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
保存后,运行以下命令使之生效:
source /etc/profile
1.4 验证安装
现在可以通过Spark的内置示例验证安装是否成功,
run-example SparkPi 10
以上命令是在执行 Spark 自带的示例程序 SparkPi,该程序的作用是用分布式计算的方式近似计算圆周率 π 的值。其中参数 10 表示将任务划分成 10 个分区(或切片),Spark 会将计算 π 的任务分成 10 个子任务并行执行。
命令在运行时会输出包含日志在内的很多内容:
[root@192 softwares]# run-example SparkPi 10
25/08/31 03:14:06 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
25/08/31 03:14:06 INFO SparkContext: Running Spark version 3.5.6
25/08/31 03:14:06 INFO SparkContext: OS info Linux, 3.10.0-1160.el7.x86_64, amd64
25/08/31 03:14:06 INFO SparkContext: Java version 1.8.0_201
25/08/31 03:14:06 INFO ResourceUtils: ==============================================================
25/08/31 03:14:06 INFO ResourceUtils: No custom resources configured for spark.driver.
其中有一个如下的关键内容,就是所计算的π的结果,看到这个结果说明Spark已经安装成功。
Pi is roughly 3.142363142363142
2 Spark运行模式
在不安装Hadoop的情况下,Spark支持以下几种运行模式,Local模式(本地模式)、Local Cluster模式(本地集群模拟模式)、Standalone模式(独立集群模式)、Kubernetes模式、Mesos模式。注意,Spark本身不是一个像MySQL或Nginx那样一直运行的“服务”,但它运行时会启动进程并占用端口。
2.1 Local模式(本地模式)
在这种模式下,Spark运行在单个JVM进行中,使用多线程模拟分布式计算。不需要任何集群管理器,适合测试和调试,支持多线程并行。有两种方式可以以Local模式使用Spark,一种是Spark Shell,另一种是提交独立的Spark应用。其中Spark Shell又分为Python版的Shell和Scala版的Shell,分别使用pyspark和spark-shell命令进入相应的shell。
2.1.1 Spark Shell
2.1.1.1 Python版的Shell
由于已经为Spark配置过环境变量,所以直接在终端任意位置输入pyspark即可进入Python版的shell:
[root@192 softwares]# pyspark
Python 3.11.13 (main, Aug 31 2025, 00:02:26) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/08/31 03:35:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//__ / .__/\_,_/_/ /_/\_\ version 3.5.6/_/Using Python version 3.11.13 (main, Aug 31 2025 00:02:26)
Spark context Web UI available at http://192.168.152.136:4040
Spark context available as 'sc' (master = local[*], app id = local-1756636559084).
SparkSession available as 'spark'.
>>>
在Python版的Shell中可以执行一下基本的操作,如下面的创建RDD并查看其内容的操作:
>>> # 从集合创建RDD
>>> data = [1, 2, 3, 4, 5]
>>> rdd = sc.parallelize(data)
>>> # 查看RDD内容
>>> rdd.collect()
[1, 2, 3, 4, 5]
>>>
在执行pyspark时,是可以加参数的,比如写成下面的形式:
pyspark --master local[4] --driver-memory 2g
其中
–master local 表示使用本地模式,利用4个线程运行;
–driver-memory 2g 指定Driver程序使用2GB内存。
2.1.1.2 Scala版的Shell
在终端输入spark-shell进入Scala版的Shell:
[root@192 spark-3.5.6-bin-hadoop3]# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/08/31 03:45:57 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
25/08/31 03:45:59 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://192.168.152.136:4041
Spark context available as 'sc' (master = local[*], app id = local-1756637159380).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.5.6/_/Using Scala version 2.12.18 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)
Type in expressions to have them evaluated.
Type :help for more information.scala>
同样也可以进行一些基本操作:
scala> val data = Array(1, 2, 3, 4, 5)
data: Array[Int] = Array(1, 2, 3, 4, 5)scala> val distData = sc.parallelize(data) // sc是SparkContext内置对象
distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> // 对数据做map变换,乘以2
scala> val doubled = distData.map(x => x * 2)
doubled: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:23
scala>
scala> // 收集结果并打印
scala> doubled.collect().foreach(println)
2
4
6
8
10
scala> // 过滤出大于5的元素
scala> val filtered = doubled.filter(_> 5)
filtered: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at filter at <console>:23
scala> filtered.collect().foreach(println)
6
8
10
scala> val sum = filtered.reduce(_ + _)
sum: Int = 24scala> print(sum)
24
在执行spark-shell命令时,也可以加参数,用法同执行pyspark时所加的参数。
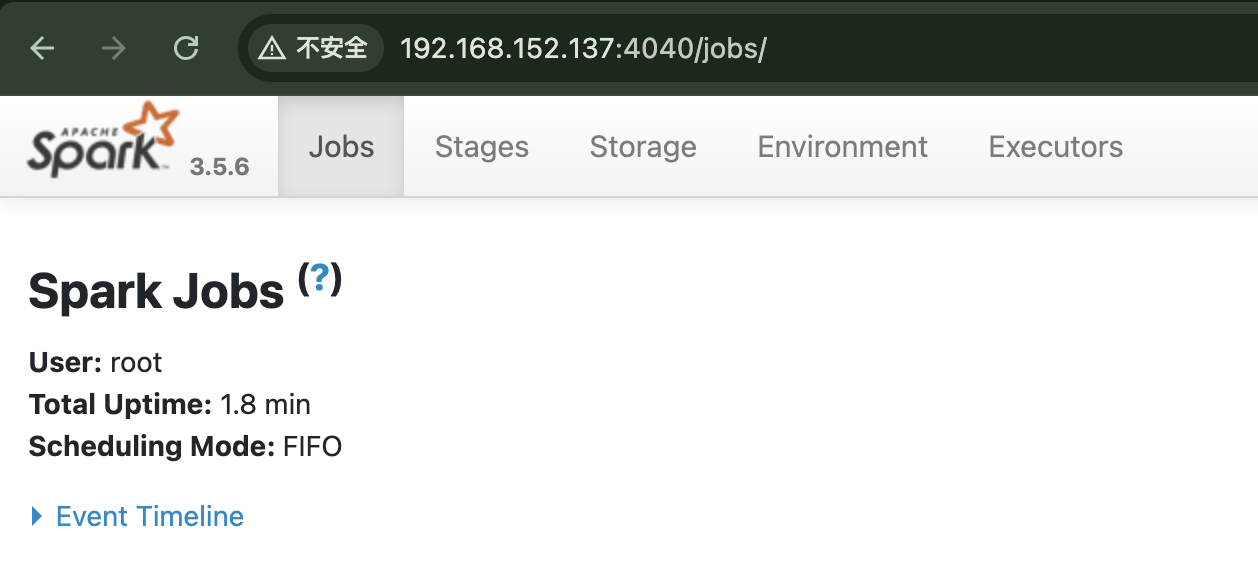
进入两种版本的Spark Shell后,可以通过访问Spark Web UI的方式来验证Spark是否处于运行状态,可以在浏览器输入ip:4040来访问页面:
2.1.2 提交独立的Spark应用
提交独立的Spark应用也可以触发Spark的运行,所谓提交独立的Spark应用,可以这样理解,就是把自己的完整程序(Python、Scala、Java)交给Spark去执行,这里Spark充当分布式计算的统一执行平台,负责调度和管理计算资源,执行你的应用逻辑。
from pyspark.sql import SparkSession# 创建spark会话
spark = SparkSession.builder.appName("WordCount").getOrCreate()
# 得到SparkContext对象
sc = spark.sparkContext# 读取文本文件得到分布式数据集RDD
lines = sc.textFile("/softwares/words.txt")
# 进行词频统计,flatMap将每行拆分成单词,展平成多个单词组成的RDD。map将每个单词映射成键值对 (word, 1)。reduceByKey对相同单词的值进行累加,实现计数。
word_counts = lines.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 将结果保存到指定目录
word_counts.saveAsTextFile("/softwares/outwords")
# 关闭Spark会话
spark.stop()
执行spark-submit wordcount.py 命令向Spark提交任务,由Spark来执行分布式计算,输出日志非常长,这里只贴出一部分(结尾部分和开头部分的日志):
[root@192 softwares]# spark-submit wordcount.py
开头部分的日志
25/08/31 07:27:46 INFO SparkContext: Running Spark version 3.5.6
25/08/31 07:27:46 INFO SparkContext: OS info Linux, 3.10.0-1160.el7.x86_64, amd64
25/08/31 07:27:46 INFO SparkContext: Java version 1.8.0_201
25/08/31 07:27:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
25/08/31 07:27:46 INFO ResourceUtils: ==============================================================
25/08/31 07:27:46 INFO ResourceUtils: No custom resources configured for spark.driver.
25/08/31 07:27:46 INFO ResourceUtils: ==============================================================
25/08/31 07:27:46 INFO SparkContext: Submitted application: WordCount结尾部分的日志
25/08/31 07:27:56 INFO SparkUI: Stopped Spark web UI at http://192.168.152.137:4040
25/08/31 07:27:56 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
25/08/31 07:27:56 INFO MemoryStore: MemoryStore cleared
25/08/31 07:27:56 INFO BlockManager: BlockManager stopped
25/08/31 07:27:56 INFO BlockManagerMaster: BlockManagerMaster stopped
25/08/31 07:27:56 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
25/08/31 07:27:56 INFO SparkContext: Successfully stopped SparkContext
25/08/31 07:27:56 INFO ShutdownHookManager: Shutdown hook called
25/08/31 07:27:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-00e7ab02-1f2c-4861-9de6-16ed3ced686b
25/08/31 07:27:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-a816c18c-202f-4b91-aa79-d32821644f77/pyspark-23d851b4-546f-4c1b-8816-bb30775d9966
25/08/31 07:27:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-a816c18c-202f-4b91-aa79-d32821644f77
执行完毕后,会在指定的输出目录中生成下面两个文件:
[root@192 softwares]# cd outwords/
[root@192 outwords]# ll
总用量 4
-rw-r--r--. 1 root root 50 8月 31 07:27 part-00000
-rw-r--r--. 1 root root 0 8月 31 07:27 _SUCCESS
part-00000这个文件里存放的是数据处理结果,不妨看下结果:
[root@192 outwords]# cat part-00000
('test', 1)
('hello', 1)
('ketty', 1)
('word', 1)
2.2 Local Cluster模式(本地集群模拟模式)
这种模式是在单台机器上模拟一个Spark集群环境,这种模式尤其适合没有Hadoop环境时的开发和测试工作。启动命令pyspark需要加参数,语法如下(以pyspark为例):
pyspark --conf "spark.master=local-cluster[numNodes, coresPerNode, memoryPerNode]"
spark.master是Spark应用的主节点(master)的配置参数,决定了Spark应用运行的模式。local-cluster[numNodes, coresPerNode, memoryPerNode]表示本地模拟一个Spark集群,nmNodes是模拟集群中节点(word)的数量,coresPerNode是每个节点的CPU核心数,memoryPerNode是每个节点分配的内存数。
执行下面的命令进入Local Cluster模式,使用两个节点,每个节点分配一个CPU核心和1G内存:
[root@192 softwares]# pyspark --conf "spark.master=local-cluster[2,1,1024]"
执行下面的代码:
text = ["hello world", "hello spark", "spark is fast"]
rdd = sc.parallelize(text)word_counts = rdd.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a + b)# Check the execution plan
print(word_counts.toDebugString().decode('utf-8'))
word_counts.collect()
执行结果:
>>> text = ["hello world", "hello spark", "spark is fast"]
>>> rdd = sc.parallelize(text)
>>>
>>> word_counts = rdd.flatMap(lambda line: line.split(" ")) \
... .map(lambda word: (word, 1)) \
... .reduceByKey(lambda a, b: a + b)
>>>
>>> # Check the execution plan
>>> print(word_counts.toDebugString().decode('utf-8'))
(2) PythonRDD[11] at RDD at PythonRDD.scala:53 []| MapPartitionsRDD[10] at mapPartitions at PythonRDD.scala:160 []| ShuffledRDD[9] at partitionBy at NativeMethodAccessorImpl.java:0 []+-(2) PairwiseRDD[8] at reduceByKey at <stdin>:3 []| PythonRDD[7] at reduceByKey at <stdin>:3 []| ParallelCollectionRDD[6] at readRDDFromFile at PythonRDD.scala:289 []
>>> word_counts.collect()
[('hello', 2), ('fast', 1), ('world', 1), ('spark', 2), ('is', 1)]
>>>
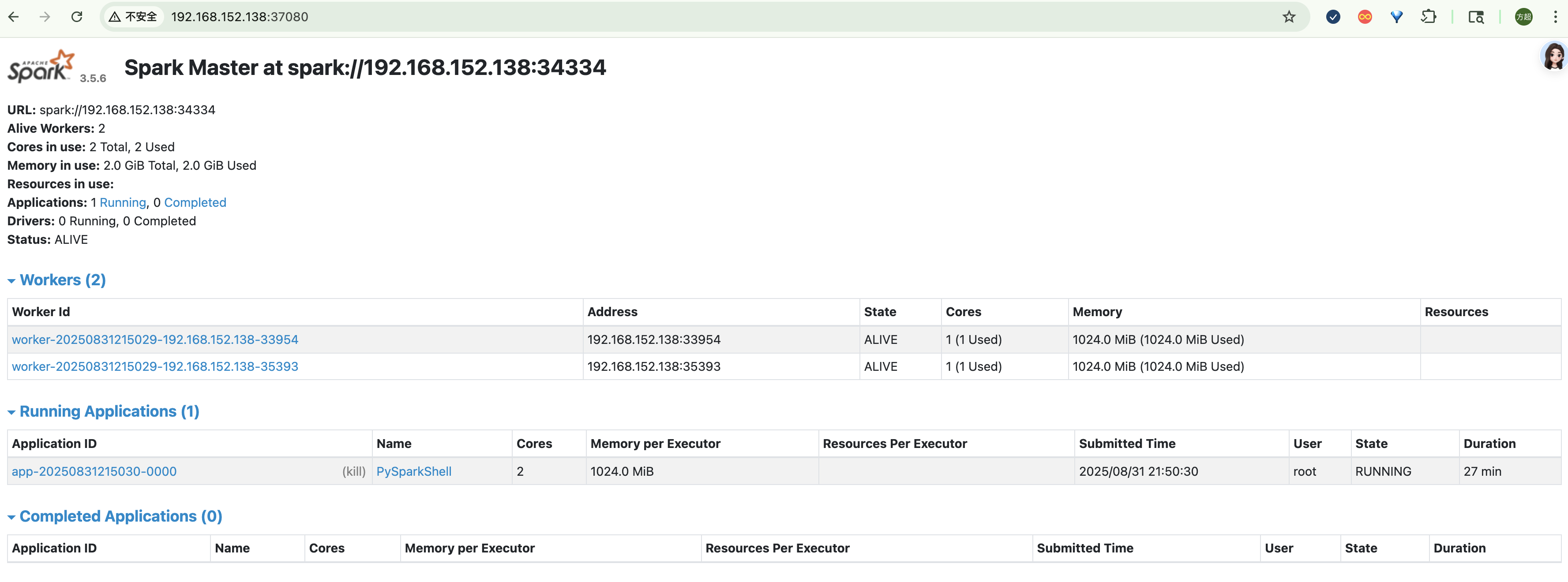
从命令行的执行结果,似乎也看不出来Local Cluster模式与Local模式有什么区别,但是从Web UI上还是能看出些区别的,比如下图中Alive Workers显示为2。
还有一些其他区别,归纳成下表形式:
| 特性 | Local 模式 | Local Cluster 模式 |
|---|---|---|
| 进程数 | 1个JVM进程 | 多个JVM进程(模拟分布式) |
| 资源隔离 | 无隔离 | 模拟资源隔离 |
| 适用场景 | 简单测试 | 模拟分布式环境测试 |
| Web UI端口 | 4040端口 | 4041、4042…等端口 |
| 启动命令 | local[N] | local-cluster[N,M,mem] |
2.3 Standalone模式(独立集群模式)
这种模式是由多台机器组成的Spark集群,通过Spark自带的集群管理器实现任务的调度与执行,每台服务器部署Spark守护进程,包括Master和多个Worker,Master负责集群资源管理和任务调度,Worker运行Executor执行任务,启动前需配置集群环境,支持多用户并发使用。
2.3.1 修改主机名
这里规划三台机器,三台机器的名称分别命为centos7-master、centos7-node1、centos7-node2,一台机器作为Master节点,负责集群管理和调度,其余两台作为Worker节点,负责执行计算任务。
设置主机名之前最好先查看一下主机名,可以使用下面的命令:
hostname
如果确定要修改主机名的话,可以使用下面的命令(当然还有其他方式):
hostnamectl set-hostname 新主机名
该命令会更新/etc/hostname文件,并立即生效。
然后在每台机器的/etc/hosts文件中都写入三台机器IP与主机名的映射关系,便于机器之间通过主机名进行访问:
#master
192.168.152.152 centos7-master
#node1
192.168.152.151 centos7-node1
#node2
192.168.152.150 centos7-node2
2.3.2 配置免密登陆
Spark的Master节点需要远程管理和启动各个Worker节点的进程,免密登录使Master节点无障碍地远程执行命令,无需每次都输入密码,保证集群自动化管理。
之前三台机器设置的主机名为centos7-master、centos7-node1、centos7-node2,先在centos7机器上生成SSH密钥对,一路回车使用默认路径(~/.ssh/id_rsa),不设置密码:
ssh-keygen -t rsa
然后,使用ssh-copy-id命令将公钥复制到另外两台机器上:
ssh-copy-id centos7-node1
ssh-copy-id centos7-node2
若没有ssh-copy-id工具,也可手动复制~/.ssh/id_rsa.pub内容添加到目标机器~/.ssh/authorized_keys文件。
然后在另外两台机器上也执行同样的操作,目的就是保证每个机器上都有另外两台机器产生的公钥。
接着可以使用ssh命令测试机器间登录是否已经免密了。
配置好免密登录后,Master节点就能无密码远程管理Worker节点,启动和停止Spark进程时无需人工干预。
2.3.3 配置master机器
在master节点要创建两个配置文件,workers和spark-en.sh。
进入Spark解压目录的config文件夹,基于workers.template文件复制workers文件(使用cp命令),接着编辑workers文件,写入Worker节点的主机名或IP地址:
centos7-node1
centos7-node2
同样在config文件夹中,复制出一份spark-env.sh文件,master节点的spark-env.sh文件主要配置以下内容:
export JAVA_HOME=/softwares/jdk1.8.0_201export SPARK_MASTER_HOST=centos7-masterexport SPARK_MASER_PORT=7077export SPARK_MASTER_WEBUI_PORT=8080
JAVA_HOME:Java路径
SPARK_MASTER_HOST:Master节点绑定的主机名(或IP),这是必须配置的
SPARK_MASTER_PORT:Master节点监听的端口号,默认7077端口,Worker和Driver通过这个端口连接到Master,如果该端口没被占用,可以不设置
SPARK_MASTER_WEBUI_PORT:访问Spark Standalone集群的界面(Master Web UI)端口(默认为8080)
2.3.4 配置worker节点
worker节点中不需要配置workers文件,只需配置spark-env.sh文件,需要配置的内容跟master节点上配置的稍微有所不同,具体来说只需配置JAVA_HOME和一些资源参数即可:
export JAVA_HOME=/softwares/jdk1.8.0_201
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=4g
SPARK_WORKER_CORES=2表示该Worker节点上分配给Spark任务执行的CPU核心数为2个,SPARK_WORKER_MEMORY=4g表示该Worker节点分配给Spark任务执行的最大内存为4GB。
2.3.5 启动集群
在Master节点运行:
./sbin/start-master.sh
./sbin/start-slaves.sh
或直接运行一键启动:
./sbin/start-all.sh
jps命令查看进程
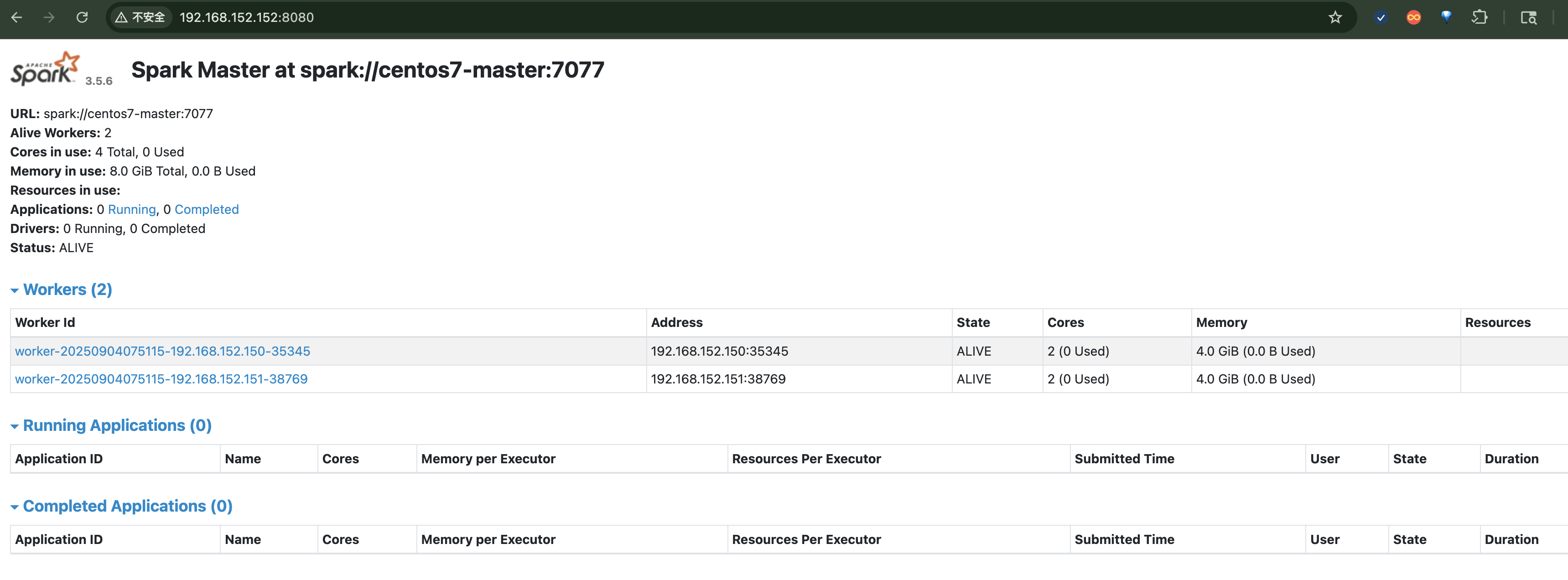
可以通过在每个节点上查看进程的方式(执行jps命令)验证集群是否启动成功:
[root@centos7-master ~]# jps
13779 Jps
13695 Master
[root@centos7-node1 ~]# jps
12485 Worker
12573 Jps
[root@centos7-node2 ~]# jps
12247 Worker
12365 Jps
访问Web UI
Spark集群启动后,可以通过主机IP:默认端口名方式方式集群的界面
3 总结
如果暂时没有Hadoop环境,又想使用Spark,Spark提供了Local模式、Local Cluster模式、Standalone三种模式,这三种模式允许开发者在不使用Hadoop的情况也能搭建Spark环境。
我是欧阳方超,把事情做好了自然就有兴趣了,如果你喜欢我的文章,欢迎点赞、转发、评论加关注。我们下次见。



)
)

)



---检测B样条轨迹的障碍物进入点与退出点)
、POST(带请求头)、下载文件、上传文件等)

——Gemini Live API:实时音视频连接)



)

