动态SQL-官方文档
文档地址
动态 SQL_MyBatis中文网
为什么需要动态SQL
1、动态SQL是MyBatis的强大特性之一
2、使用JDBC或其它类似的框架,根据不同条件拼接SQL语句非常麻烦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号等
3、SQL映射语句中的强大的动态SQL语言,可以很好的解决这个问题.
动态SQL-基本介绍
基本介绍
1.在一个实际的项目中,sql语句往往是比较复杂的
2.为了满足更加复杂的业务需求,MyBatis的设计者,提供了动态生成SQL的功能。
动态SQL必要性
1.比如我们查询Monster时,如果程序员输入的age不大于0,我们的sql语句就不带age。
2.更新Monster对象时,没有设置的新的属性值,就保持原来的值,设置了新的值,才更新.
解决方案分析
1.从上面的需求我们可以看出,有时我们在生成sq语句时,在同一个方法中,还要根据不同的情况生成不同的sq语句.
2.解决方案:MyBatis提供的动态SQL机制.
动态SQL常用标签
动态SQL提供了如下几种常用的标签,类似我们Java的控制语句:
1.if[判断]
2.where[拼接where子包]
3.choose/when/otherwise[类似java的switch语句,注意是单分支]
4.foreach[类似in]
5.trim[替换关键字/定制元素的功能]
6.set[在update的set中,可以保证进入set标签的属性被修改,而没有进入set的,保持原来的值
动态SQL-案例演示
新建Module dynamic-sql
1.新建Module
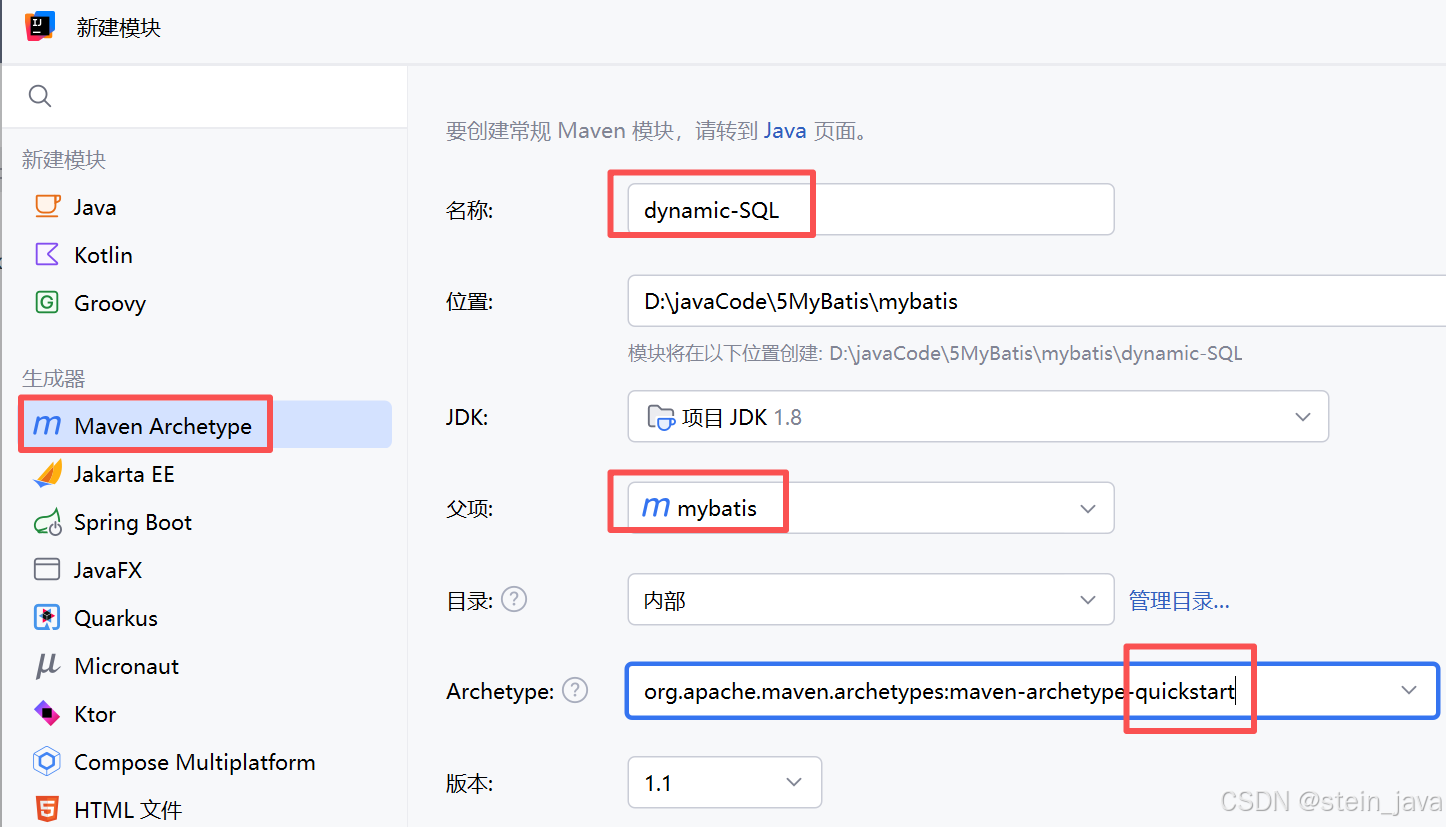
2.检查项目之间的依赖pom.xml
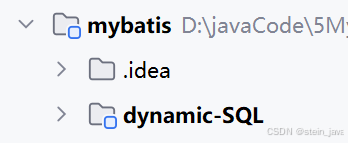
子项目标注的父项目
<parent><groupId>com.stein</groupId><artifactId>mybatis</artifactId><version>1.0-SNAPSHOT</version></parent>父项目包含子项目
<modules><module>mybatis_quickstart</module><module>xml-Mapper</module><module>dynamic-SQL</module></modules>3.创建java目录及内容。具体内容可以看前面几期的。
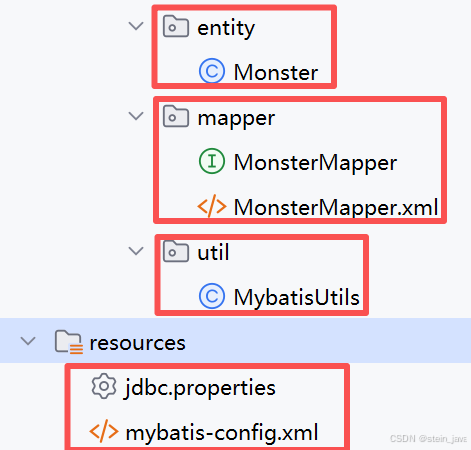
4.测试
public class MonsterMapperTest {private SqlSession sqlSession;private MonsterMapper monsterMapper;//在每一个@Test方法执行前都执行一次,获取一次sqlSession@Beforepublic void init(){sqlSession= MybatisUtils.getSqlSession();//获取到MonsterMapper对象?实际是代理对象 class com.sun.proxy.$Proxy9//底层是使用了动态代理机制monsterMapper = sqlSession.getMapper(MonsterMapper.class);System.out.println("monsterMapper的运行类型是:"+monsterMapper.getClass());}@Testpublic void test01(){System.out.println("方法f1()已调用");}
}搭建好演示环境后,接下来开始演示动态SQL的对应标签的使用
if标签-应用实例
需求:请查询age大于10的所有妖怪,如果程序员输入的age不大于0,则输出所有的妖怪!
1.添加接口方法MonsterMapper.java
List<Monster> findMonsterByAge(@Param(value="age") int age);注意:其中的注解@Param("var")是给if判断语句传递参数的,这儿的value="var"是跟<if test="var">匹配的,名字必须一模一样。
2.实现器实现接口语句MonsterMapper.xml
<select id="findMonsterByAge" resultType="Monster">select * from monster where 1=1<if test="age>0">and age>#{age}</if></select>说明:
①<if test="age>0">,test后面跟的是判断语句。
②变量age,是由接口方法的@Param(value="age")传递过来的
③这里不能写成<if test=" ${age}>0"> 或者 <if test=" #{age}>0">,都会报错。
所以好好使用@Param
④这儿1=1的作用是保留关键字where,否则if判断为false的时候,where后面没有语句。
3.测试
@Testpublic void findMonsterByAge(){int age=20;List<Monster> monsters = monsterMapper.findMonsterByAge(age);for (Monster monster : monsters) {System.out.println("monster="+monster);}if(sqlSession!=null){sqlSession.close();}System.out.println("ok");}where标签-应用实例
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
需求:查询id大于20的,并且名字是"牛魔王"的所有所有妖怪,注意,如果名字为空,
或者输入的id小于0,则不拼接对应的名字或者id有关的sql语句
1.添加接口的方法MonsterMapper.java
这儿是通过Monster对象的属性来获取需要的参数的
List<Monster> findMonsterByIdAndName(Monster monster);2.实现器实现该方法MonsterMapper.xml
<select id="findMonsterByIdAndName" parameterType="Monster" resultType="Monster">select * from monster<where><if test="id>0">`id`>#{id}</if><if test="name != null and name != '' ">and `name`=#{name}</if></where></select>说明:
①where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
所以,第一句if里面的SQL语句前面,可以不加and
第二句if里面的SQL语句前面,需要加and,由mybatis自动判断是否需要
同时。这也解决了上一个<if>标签案例中的where 1=1的冗余问题,直接可以替换成<where>标签+<if>标签解决。
②<if test="express">判断语句中可以直接使用Monster的属性,比如这里的id,name,不用添加诸如@Param这样的注解。
express中同样也不能写成${property},#{property}这种形式
③<if test="name != null and name != '' ">,这里的连接符用的是and,or。不能使用&&,||这样的形式。也不能是and,or其他样式的,比如AND,And都会报错。(严格大小写T_T)
感叹,细节太多了,怎么可能记得住!唯有使用的时候翻笔记了。
3.测试
@Testpublic void findMonsterByIdAndName(){Monster monster = new Monster();monster.setId(10);monster.setName("大象精No.3");//结合自身的DB内容改了一下。List<Monster> monsters = monsterMapper.findMonsterByIdAndName(monster);for (Monster m : monsters) {System.out.println("monster="+m);}if(sqlSession!=null){sqlSession.close();}System.out.println("ok");}choose/when/otherwise-应用实例
有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
需求:
1)如果给的name不为空,就按名字查询妖怪,
2)如果揞定的id>0,就按id来查询妖怪
3)如果前面两个条件都不满足,就默认查询salary>100的
4)要求使用choose/when/otherwise标签实现,传入参数要求使用Map
1.添加接口方法MonsterMapper.java
List<Monster> findMonsterByIdOrName_choose(Map<String,Object> map);2.实现该方法MonsterMapper.xml
<select id="findMonsterByIdOrName_choose" parameterType="map" resultType="Monster">select * from monster<choose><when test="name != null and name != ''">where `name` = #{name}</when><when test="id > 0">where `id`>#{id}</when><otherwise>where salary >100</otherwise></choose></select>说明:
1)这是在几个条件中仅选择一个。所以每一个条语句中都有where。
2)name非空,id>0都成立时,先执行第一条name的判断语句。
3)name为空,id<0,都为false的时候,执行最后一条otherwise的语句。
简直跟switch一毛一样。
3.测试
@Testpublic void findMonsterByNameOrId_choose(){HashMap<String, Object> map = new HashMap<>();//map.put("name","小鸡仔");map.put("id",10);List<Monster> monsters = monsterMapper.findMonsterByIdOrName_choose(map);for (Monster m : monsters) {System.out.println("monster="+m);}if(sqlSession!=null){sqlSession.close();}System.out.println("ok");}自己变换条件,多感受一下判断条件的成立情况。
forEach标签-应用实例
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)。
需求:查询id为9,10,13的妖怪
1.添加接口方法
List<Monster> findMonsterByIds_foreach(Map<String,Object> map);2.实现该方法
<select id="findMonsterByIds_foreach" parameterType="map" resultType="Monster">select * from monster<if test="ids != null and ids != ''">where `ID`IN<foreach collection="ids" item="id" open="(" separator="," close=")">#{id}</foreach></if></select>说明:
1)达到这样的语句效果:select * from monster where `ID` IN ( ? , ? )
2)<if test="ids != null> 这里的属性ids,是来自于map<"ids",arrays>定义的
3)<foreach>标签元素的含义,collection="ids"表示集合是ids, 集合中的子元素是item="id", 使用的左括号是open="(" ,分隔符是separator="," ,右括号是close=")"
4)最后取出#{id}进行遍历,id的名称和item="id"的名称一致。
5)为了抓住重点,这儿的<if>标签可以不要,只是鲁棒性需要
3.测试
@Testpublic void findMonsterByIds_foreach(){HashMap<String, Object> map = new HashMap<>();map.put("ids", Arrays.asList(9,10,13));List<Monster> monsters = monsterMapper.findMonsterByIds_foreach(map);for (Monster m : monsters) {System.out.println("monster="+m);}if(sqlSession!=null){sqlSession.close();}System.out.println("ok");}trim标签-应用实例【使用较少】
如果 where 元素与你期望的不太一样,你也可以通过自定义 trim 元素来定制 where 元素的功能。比如,和 where 元素等价的自定义 trim 元素为:
<trim prefix="WHERE" prefixOverrides="AND |OR ">... </trim>
trim可以替换一些关键字。相当于升级版的where
要求:按名字查询妖怪,如果sql语句开头有and or就替换成where
1.常规情况:
<select id="findMonsterByName_trim" parameterType="map" resultType="Monster">select * from monster<where><if test="name != null and name != ''">AND `name`=#{name}</if><if test="age >0">AND `age`>#{age}</if></where></select>where可以吧开头多余的AND去掉,但是如果这个开头AND、OR以外的字符,就不能去除了,这儿就可以使用trim来自定义custom
2.使用trim
<select id="findMonsterByName_trim" parameterType="map" resultType="Monster">select * from monster<trim prefix="WHERE" prefixOverrides="and|or|custom"><if test="name != null and name != ''">custom `name`=#{name}</if><if test="age >0">custom `age`>#{age}</if></trim></select>prefix就是前缀,当后面有代码的时候,就会使用where。prefixOverrides指定会对哪些关键字生效,然后where后面第一次接的custom就被去掉。
因为不常用,就不演示了,关键代码已给出。
set标签-应用实例[重点]
set可以灵活的设置需要修改的字段,有修改就添加该字段,没有修改就没有该字段的SQL语句
需求:请对指定id的妖怪进行修改,如果没有设置新的属性,则保持原来的值
- 在update的set中,可以保证进入set标签的属性被修改,而没有进入set的,保持原来的值
- 以往的set语句,只能一条语句对应修改一个属性或者一个属性组合,当面对不同的属性修改需求时,需要很多近似的代码。
- 这时通过标签和标签组合使用,便可以将属性的设置解耦,化简为对单个属性的设置,同时解决update修改语句过多的问题
- 不用担心标签内结尾的",",多余的动态SQL知道处理
核心方法实现代码MonsterMapper.xml
<update id="updateMonsterByParam" parameterType="map">UPDATE `monster`<set><if test="age != null and age != ''">`age` = #{age} ,</if><if test="email != null and email != ''">`email` = #{email} ,</if><if test="name != null and name != ''">`name` = #{name} ,</if><if test="birthday != null and birthday != ''">`birthday` = #{birthday} ,</if><if test="salary != null and salary != ''">`salary` = #{salary} ,</if><if test="gender != null and gender != ''">`gender` = #{gender} , //最后一句会有一个多余的",",动态SQL会自动处理。每一条都可能是最后一条语句。</if></set>WHERE id = #{id}</update>课后练习
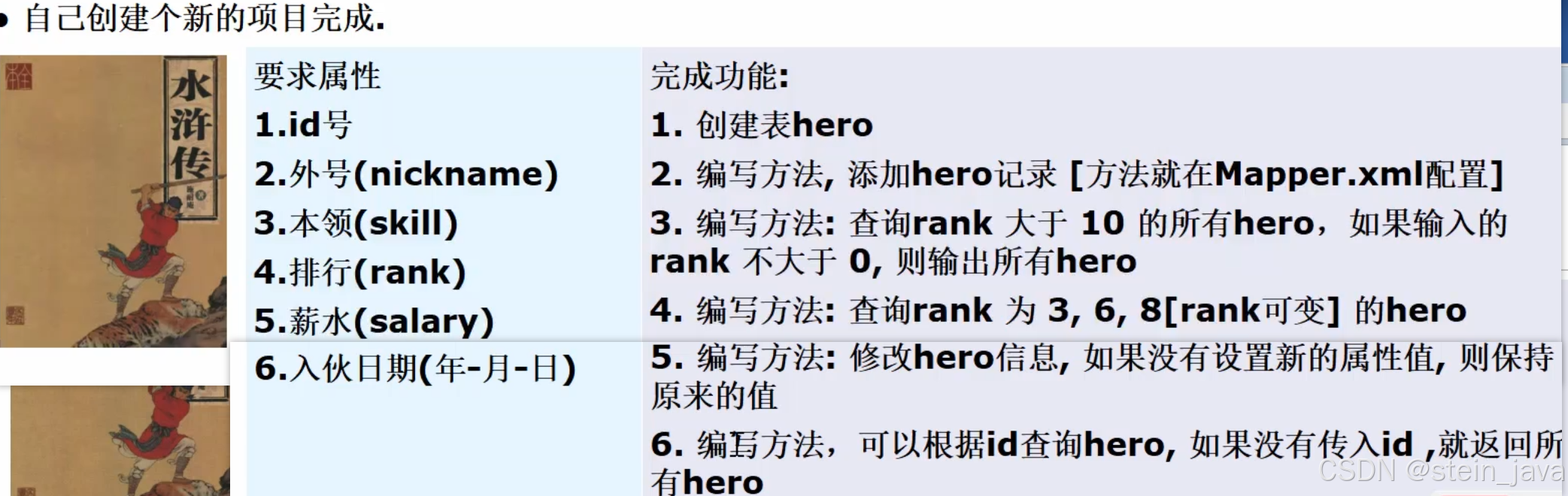
1.新建Module,以及必要的框架结构,过程同上。
2.创建DB表hero
create table hero(
id int primary key auto_increment,
nickname varchar(255) not null default "",
skill varchar(255) not null default "",
`rank` tinyint not null default 0,
salary double default 0,
join_date datetime default null
)charset=utf8你敢信,rank竟然是关键字,排错半天。。
3.创建entity,Hero.java
public class Hero {private Integer id;private String nickname;private String skill;private Integer rank;private Double salary;private Date joinDate;public Hero() {}and setter,getter,toString
}4.创建接口HeroMapper及方法
4.1添加hero记录
public interface HeroMapper {void insertHero(Hero hero);
}4.2查询rank大于10的所有hero,如果不大于0,则输出所有(如题图功能3)
List<Hero> selectHeroByRank(Integer rank);4.3查询rank 2,8,10(如题图功能4)
List<Hero> selectHeroByRank_foreach(Map<String,Object> rankListMap);4.4修改改动后的属性(如题图功能5)
void updateHeroByRank(Map<String,Object> map);4.5根据id查询hero。感觉这个和4.2一样,只是换了个属性。就不写了。
5.实现接口方法HeroMapper.xml
5.1添加hero
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--解读
它的核心作用是将 XML 映射文件与 Mapper 接口进行绑定
-->
<mapper namespace="com.stein.mapper.HeroMapper"><insert id="insertHero" parameterType="Hero">insert into `hero` values(null,#{nickname},#{skill},#{rank},#{salary},#{joinDate})</insert>
</mapper>配置文件
mybatis-config.xml,因为是通过包注册的,所以不用改了
<mappers><!--原生xml方式引入(注册)MonsterMapper.xml文件--><!--<mapper resource="com/stein/mapper/MonsterMapper.xml"/>--><!--<mapper resource="com/stein/mapper/UserMapper.xml"/>--><!--通过添加文件夹的方式注册xml文件--><package name="com.stein.mapper"/></mappers>5.2查询rank。按题目要求,需要用到动态SQL的<if>标签
<select id="selectHeroByRank" resultType="Hero">select * from hero<if test="rank >0">where `rank`>#{rank}</if></select>5.3 查询rank 2,8,10,根据自己录入的rank来设置。需要用到<foreach>,对应SQL的in语句
<select id="selectHeroByRank_foreach" parameterType="map" resultType="Hero">select * from hero<if test="ids !=null and ids != ''">where `rank`in<foreach collection="ids" item="id" open="(" separator="," close=")">#{id}</foreach></if></select>5.4只修改改动属性
<update id="updateHeroByRank" parameterType="map">update hero<set><if test="nickname != null and nickname !=''">`nickname`=#{nickname},</if><if test="skill != null and skill !=''">`skill`=#{skill},</if><if test="rank != null and rank !=''">`rank`=#{rank},</if><if test="salary != null and salary !=''">`salary`=#{salary},</if><if test="joinDate != null and joinDate !=''">`joinDate`=#{joinDate},</if></set>where `rank`=#{rank}</update>6.测试
6.1添加hero
public class HeroMapperTest {private SqlSession sqlSession;private HeroMapper heroMapper;//在每一个@Test方法执行前都执行一次,获取一次sqlSession@Beforepublic void init(){sqlSession= MybatisUtils.getSqlSession();//获取到MonsterMapper对象?实际是代理对象 class com.sun.proxy.$Proxy9//底层是使用了动态代理机制heroMapper = sqlSession.getMapper(HeroMapper.class);System.out.println("monsterMapper的运行类型是:"+heroMapper.getClass());}@Testpublic void insertHero(){Hero hero = new Hero();hero.setNickname("豹子头-林冲");hero.setSkill("林家枪法");hero.setRank(8);hero.setSalary(9000.0);hero.setJoinDate(new Date());heroMapper.insertHero(hero);if(sqlSession!=null){sqlSession.commit();sqlSession.close();}System.out.println("操作ok~");}
}6.2查询rank
@Testpublic void selectHeroByRank(){List<Hero> heroes = heroMapper.selectHeroByRank(-1);for(Hero hero:heroes){System.out.println("hero="+hero);}if(sqlSession!=null){sqlSession.close();}System.out.println("操作ok~");}6.3 rank in (2,8,10)
@Testpublic void selectHeroByRank_foreach(){HashMap<String, Object> rankMap = new HashMap<>();rankMap.put("ids", Arrays.asList(2,8,10));List<Hero> heroes = heroMapper.selectHeroByRank_foreach(rankMap);for(Hero hero:heroes){System.out.println("hero="+hero);}if(sqlSession!=null){sqlSession.close();}System.out.println("操作ok~");}6.4只修改改动属性-to do...
在修改时间时,遇到了问题,后期看是修改DB的属性,还是修改Java中Date的值来处理
@Testpublic void updateHeroByRank(){HashMap<String, Object> map = new HashMap<>();//选择要修改那个rank的hero,必须要的选项map.put("rank",2);//其余属性,按需求添加map.put("nickname","军师-吴用");map.put("salary",20000.0);//map.put("joinDate",new Date());这个方法会报错//LocalDateTime now = LocalDateTime.now();//获取当前时间//map.put("joinDate", Timestamp.valueOf(now));heroMapper.updateHeroByRank(map);if(sqlSession!=null){sqlSession.close();}System.out.println("操作ok~");}有解决时间办法的,评论区留言哦~
小bug的解决:
之前在coding的时候,出现了.var快捷键无法使用的情况。使用下面的方法修复了
清理IDEA缓存
点击菜单栏 File → Invalidate Caches / Restart → 选择 Invalidate and Restart。

】软件架构设计二:软件架构风格:构建系统的设计模式与选择指南)
)
)


)

)


)





落地(一)环境搭建)

