开篇介绍:
Hello 大家,在上一篇博客中,我们一同拆解了「206. 反转链表」和「876. 链表的中间结点」这两道单链表经典题目,通过对指针操作的细致打磨,相信大家对单链表的特性与算法设计思路有了更深入的理解。而在今天的内容里,我们将迈入单链表的一个更具挑战性的领域 —— 环形链表,并聚焦于一道兼具趣味性与实用性的经典问题:「环形链表的约瑟夫问题」。
说起约瑟夫问题,它不仅是数据结构领域的经典命题,更蕴含着深刻的数学逻辑与算法智慧。无论是在早期的计算机科学研究中,还是在如今的面试场景里,这道题都以其巧妙的设计考验着开发者对环形结构的理解、指针操控的熟练度,以及对问题本质的提炼能力。
与我们之前接触的单链表不同,环形链表的尾节点不再指向 NULL,而是 “首尾相连”,指向链表中的某个节点(通常是头节点),形成一个闭合的回路。这种特殊的结构,使得遍历、删除等操作都与线性链表有着显著差异 —— 比如,在环形链表中,你永远无法通过 “指针指向 NULL” 来判断遍历的结束,这就要求我们必须设计更巧妙的逻辑来处理节点的访问与操作。
在接下来的内容里,我们将从问题的起源与题意分析入手,逐步拆解环形链表的构建逻辑、节点遍历技巧,以及如何在循环淘汰的过程中避免链表断裂。我们会先从最朴素的 “模拟法” 开始 —— 一步步构建环形链表,模拟报数与删除的全过程,让大家直观感受环形结构的特性;随后,我们会深入探讨优化思路,分析如何通过数学规律减少不必要的遍历,提升算法效率。
无论你是刚接触环形链表的新手,还是希望巩固算法基础的开发者,相信这道题都能为你带来新的启发。它不仅能帮助我们熟练掌握环形链表的增删查改,更能锻炼我们将实际问题抽象为数据结构模型的能力 —— 而这种能力,在解决复杂工程问题时往往至关重要。
接下来,就让我们一同走进环形链表的世界,揭开约瑟夫问题的神秘面纱。准备好了吗?让我们开始吧!
先给出本题链接,老规矩,大家先自行练手:环形链表的约瑟夫问题_牛客题霸_牛客网![]() https://www.nowcoder.com/practice/41c399fdb6004b31a6cbb047c641ed8a
https://www.nowcoder.com/practice/41c399fdb6004b31a6cbb047c641ed8a
约瑟夫问题介绍:
约瑟夫问题(Josephus Problem)是一个经典的数学和计算机科学问题,其核心场景可概括为:一群人围成环形,从某个人开始按固定间隔计数,每数到特定数字时,对应位置的人就被 “淘汰”,之后从下一个人开始重新计数,直到最后只剩下一个人作为幸存者。这个问题的本质是研究在环形结构中,如何通过递推或模拟等方式找到最后幸存者的位置。
问题的起源与经典描述
约瑟夫问题的名字源于公元 1 世纪的犹太历史学家弗拉维奥・约瑟夫斯(Flavius Josephus)。传说在犹太反抗罗马的战争中,约瑟夫斯和其他 40 名反抗者被困在洞穴中,他们约定围成一圈,从某个人开始每数到 3 就杀死对应之人,直到最后一人自杀。但约瑟夫斯不想自杀,于是他通过数学计算找到最后一个位置,从而幸存下来,这一故事便成为该问题的原型。
经典的数学描述为:设有 n 个人围成一圈,从第 k 个人开始报数,每次报数到 m 时,该人退出,然后从下一个人重新开始报数,直到剩下最后一个人,求最后幸存者的初始位置。
环形链表与约瑟夫问题的关联
在计算机科学中,约瑟夫问题常与 “环形链表” 结合,成为数据结构的经典应用题。原因在于:
- 环形链表的 “环形” 结构天然贴合问题中 “围成一圈” 的场景,每个节点代表一个人,节点间的指针形成闭环,完美模拟了 “首尾相接” 的计数环境;
- 链表的节点删除操作(淘汰某个人)可以直观地模拟 “退出” 过程,而通过指针移动可以实现 “按顺序计数” 的逻辑。
作为经典问题,约瑟夫问题的价值不仅在于其趣味性,更在于它对逻辑思维和算法设计的启发:
- 它考验对环形结构的理解和操作(如环形链表的构建、指针循环移动);
- 引导学习者从 “模拟法” 过渡到 “递推公式法”(通过数学推导直接计算幸存者位置,避免逐次模拟的低效);
- 在实际场景中,类似的环形计数逻辑可应用于轮询调度、资源分配、密码学等领域。
无论是用环形链表模拟过程,还是用数学公式推导结果,约瑟夫问题都堪称环形结构与计数逻辑结合的典范,也是理解 “循环” 与 “淘汰” 问题的基础。
环形链表的约瑟夫问题:
我们先看题目:
题意分析:
题目核心描述
- 参与人员:编号为
1到n的n个人围成一个圈。 - 报数规则:从编号为
1的人开始报数,报到m的人离开。 - 持续过程:下一个人继续从
1开始报数,重复此过程,直到只剩下一个人。 - 目标:求最后留下的人的编号。
数据范围
- 1≤n,m≤10000,说明数据规模较大,需要考虑算法的时间和空间复杂度。
- 进阶要求:空间复杂度 O(1),时间复杂度 O(n),这提示我们需要寻找高效的算法,避免使用过多额外空间且保证时间效率。
示例分析
示例 1
- 输入:
n = 5,m = 2 - 过程:
- 初始人员:
1, 2, 3, 4, 5 - 第一轮报数:报到
2,编号为2的人离开,剩余1, 3, 4, 5。 - 第二轮报数:从
3开始,报到2,编号为4的人离开,剩余1, 3, 5。 - 第三轮报数:从
5开始,报到2,编号为1的人离开,剩余3, 5。 - 第四轮报数:从
3开始,报到2,编号为5的人离开,最后剩下3。
- 初始人员:
- 返回值:
3
示例 2
- 输入:
n = 1,m = 1 - 过程:只有 1 个人,报数到
1时自己离开,最后留下的就是自己。 - 返回值:
1
环形链表法:
这道题的最经典解法,就是采用环形链表方法去解决,那么在解决题目之前,我们得先创建一个环形链表,在之前的一篇关于链表的保姆级介绍中,大家已经知道了环形链表的概念,如果有不知道的,可以看一下这篇博客:对于数据结构:链表的超详细保姆级解析-CSDN博客![]() https://blog.csdn.net/2503_92929084/article/details/151193278?spm=1001.2014.3001.5502
https://blog.csdn.net/2503_92929084/article/details/151193278?spm=1001.2014.3001.5502
环形链表其实就是一个链表中的尾节点的next指针指向该链表的头结点,那么,我们想要创建出环形链表其实也很简单,我们可以先创建一个单向链表,随后再把这个单向链表的尾节点的next指针赋值为头结点的地址即可。
那么针对本题,我们要怎么创建一个单向链表呢?与之前的题目不同,之前的题目是有原链表的,所以我们可以直接把原链表的节点给新链表,但是在本题中,是没有链表的,意味着我们只能自己创建节点去接收数据,同时组成链表。
除此之外,我们还能看到,在本题中,要生成包含从1到n的数字的链表,那么很明显,这需要借助循环,那么要怎么利用循环呢?其实并不难,大家且看我叙来:
其实与之前的有链表的题目很相似,我们依然是要创建新链表的头结点和尾节点,也就是newhead和newtail,而且,既然之前是有原链表的节点直接套用,那么虽然在本题中没有,但是我们可以自力更生,自己创建容纳数据的节点去不断尾插进新链表中,那么首先,我们就需要创建新节点的函数,这在对链表的保姆级解析中也有所提及,所以我这里也就不赘述,直接上代码:
//创建新节点
sl* create(int x)
{sl* newsl=malloc(sizeof(sl));newsl->data=x;newsl->next=NULL;return newsl;
}接下来,我们就得着手使用尾插法去不断对新链表插入数据了,在之前的题目中(对于单链表相关经典算法题:203. 移除链表元素的解析-CSDN博客),我们是要先判断是否为空链表,然后把原链表的节点赋值为新链表的头结点,接下来,我们才能借助newtail去不断进行尾插。
那么在本题中,我们的新链表在刚开始依然也为空,所以很显然,我们也要对这个新链表的插入一个头结点,而由于本题没有原链表,所以我们就要借助创建节点函数,将第一个节点插入新链表中了,具体如下:
sl* head=create(1);//第一个节点存1,后面的节点从1存到n
sl* tail=head;这一步,就相当于这一步:
sl* newhead = NULL;
sl* newtail = newhead;
sl* temp = head;
while (temp != NULL)
{if (temp->val != val){if (newhead == NULL) // 当新链表为空时,直接插入第一个节点{newhead = temp;newtail = newhead;}// 此处缺少else分支,用于处理非第一个节点的插入逻辑}temp = temp->next;那么,在处理完了头结点之后,我们就可以对新链表进行尾插了,上面我们有说到,要借助循环,那么其实和之前也很像,同样是借助newtail移动不断插入新节点,只不过是由原本的while循环换成了for循环,具体代码如下:
//创建循环链表
sl* createsl(int n)
{sl* newhead=create(1);//第一个节点存1,后面的节点从1存到nsl* newtail=newhead;for(int i=2;i<=n;i++){newtail->next=create(i);newtail=newtail->next;}
}如此,我们便创建了一个单向链表,接下来,我们只需要newtail->next=newhead;就可以实现循环链表。
不过,我们要传回newhead还是newtail呢?答案是newtail,这是为什么呢?且看:
核心原因:环形链表删除节点需要「前驱指针」
在环形链表中,删除一个节点(如报数到 m 的节点)时,必须先找到该节点的前驱节点,才能通过修改前驱节点的 next 指针,将待删除节点从环中移除(否则会导致链表断裂)。
例如,要删除节点 prov,需要让 prov 的前驱节点 pucr 执行 pucr->next = prov->next,才能完成删除。
为什么返回尾节点更方便?
-
尾节点是头节点的前驱
代码中createsl构建的环形链表满足:尾节点->next = 头节点(newtail->next = newhead)。
因此,返回尾节点后,只需通过尾节点->next就能直接获取头节点(如pucr->next即为头节点),相当于同时掌握了「头节点」和「头节点的前驱」。 -
删除头节点时避免特殊处理
若返回的是头节点,当需要删除头节点时,必须先遍历整个链表找到头节点的前驱(尾节点),这会增加额外操作。
而返回尾节点后,无论删除哪个节点(包括头节点),都能通过pucr(前驱)和prov(当前节点)的配合直接完成删除,无需特殊判断。
总结
返回尾节点而非头节点,是为了在环形链表中直接获取当前节点的前驱指针,从而高效地执行节点删除操作,避免因寻找前驱而增加额外的遍历开销。这一设计让整个约瑟夫问题的模拟过程(报数、删除)更加简洁高效,体现了环形链表操作中「前驱指针」的重要性。
因此,完整代码如下:
//创建循环链表
sl* createsl(int n)
{sl* newhead=create(1);//第一个节点存1,后面的节点从1存到nsl* newtail=newhead;for(int i=2;i<=n;i++){newtail->next=create(i);newtail=newtail->next;}newtail->next=newhead;//将尾指针的next指向头结点,形成循环链表return newtail;//将尾指针传回
}接下来,我们便要在下一个函数中进行约瑟夫问题的解决了,首先,我们要创建两个变量pucr和prov分别表示环形链表的尾节点和头节点,然后还要创建一个count变量去进行计数,当count==m的时候,便进行删除操作,那么,我们要对count初始化为多少呢?很明显,要初始化为1,因为我们肯定是要从1开始报数的。
下面,我来讲一下这个方法的原理:
该函数通过模拟 “报数 - 淘汰” 过程,找到最后剩下的人,具体分为初始化、循环淘汰、返回结果三部分:
1. 初始化指针与计数器
pucr = createsl(n):pucr指向环形链表的尾节点(通过createsl返回)。prov = pucr->next:prov指向头节点(因为尾节点的next是头节点),初始代表 “第一个报数的人”(编号 1)。count = 1:报数从 1 开始,计数器初始化为 1。
2. 循环淘汰:直到只剩一个节点
循环条件 while(pucr->next != pucr):当环形链表中只剩一个节点时,该节点的 next 会指向自己(pucr->next = pucr),此时循环终止。
每次循环的核心操作:
-
若
count == m(报数到 m,需要淘汰当前节点prov):- 步骤 1:
temp = prov->next:先用temp保存prov的下一个节点(避免删除后丢失后续节点)。 - 步骤 2:
pucr->next = prov->next:通过前驱节点pucr的next直接指向prov的下一个节点,将prov从环中 “移除”。 - 步骤 3:
free(prov):释放被淘汰节点的内存(避免泄漏)。 - 步骤 4:
prov = temp:prov移动到下一个节点(下一个报数的起点),count重置为 1(从 1 重新报数)。
- 步骤 1:
-
若
count != m(未报数到 m):pucr = prov:pucr移动到当前节点(成为下一个节点的前驱)。prov = prov->next:prov移动到下一个节点(继续报数)。count++:报数加 1。
3. 返回结果
当循环终止时,pucr 指向最后剩下的节点,返回其 data(幸存者的编号),并释放该节点的内存。大家可以结合着这个图理解: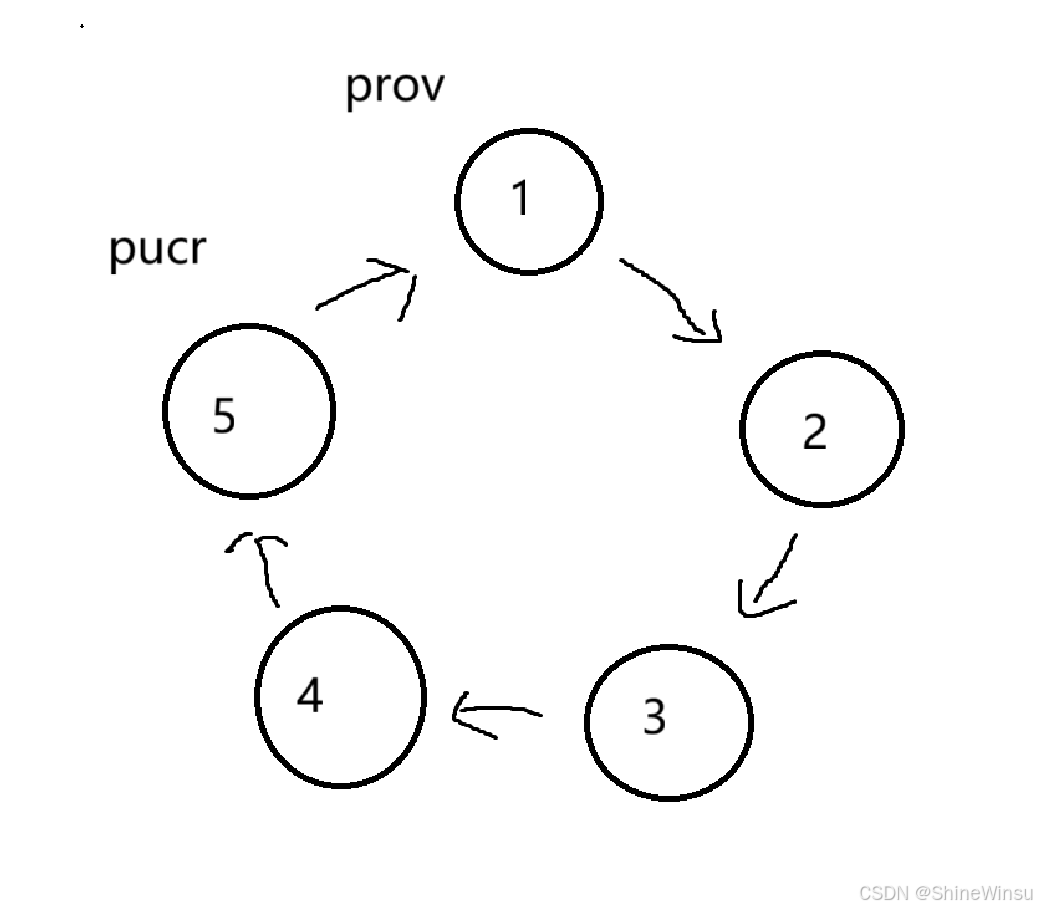
再给大家一个详细例子进行解释:
一、初始化阶段(以 n=5, m=2 为例)
调用 createsl(5) 后,得到的环形链表结构为:
1 → 2 → 3 → 4 → 5 → 1(尾节点 5 的 next 指向头节点 1)。
sl* pucr = createsl(n):pucr指向尾节点5(createsl返回尾节点)。sl* prov = pucr->next:pucr->next是尾节点的next,即头节点1→prov指向1(第一个报数的人)。int count = 1:报数从1开始,计数器初始为1。
二、循环淘汰阶段(while (pucr->next != pucr))
循环条件的含义:当链表只剩一个节点时,该节点的 next 会指向自身(如节点 x 的 next = x),此时 pucr->next == pucr,循环终止。
第一次循环(初始状态:pucr=5,prov=1,count=1)
判断 count == m?1 == 2 → 不成立,进入 else 分支:
pucr = prov:pucr从5移动到1(现在pucr是1的前驱,后续要删除1时,pucr就是操作的关键)。prov = prov->next:prov从1移动到2(下一个报数的人)。count++:count变为2。
此时状态:pucr=1,prov=2,count=2,链表结构仍为 1 → 2 → 3 → 4 → 5 → 1。
第二次循环(pucr=1,prov=2,count=2)
判断 count == m?2 == 2 → 成立,进入 “淘汰逻辑”:
sl* temp = prov->next:prov是2,prov->next是3→temp = 3(保存下一个节点,防止删除2后丢失后续节点)。pucr->next = prov->next:pucr是1,让1的next从2改为3→ 链表结构变为1 → 3 → 4 → 5 → 1(节点2被从环中 “断开”)。free(prov):释放节点2的内存(模拟 “淘汰”)。prov = temp:prov从2移动到3(下一个报数的起点)。count = 1:报数重置为1,下一轮从1开始报。
此时状态:pucr=1,prov=3,count=1,链表结构 1 → 3 → 4 → 5 → 1。
第三次循环(pucr=1,prov=3,count=1)
判断 count == m?1 == 2 → 不成立,进入 else 分支:
pucr = prov:pucr从1移动到3。prov = prov->next:prov从3移动到4。count++:count变为2。
此时状态:pucr=3,prov=4,count=2,链表结构 1 → 3 → 4 → 5 → 1。
第四次循环(pucr=3,prov=4,count=2)
判断 count == m?2 == 2 → 成立,进入 “淘汰逻辑”:
temp = prov->next:prov是4,prov->next是5→temp = 5。pucr->next = prov->next:pucr是3,让3的next从4改为5→ 链表结构变为1 → 3 → 5 → 1(节点4被淘汰)。free(prov):释放节点4。prov = temp:prov移动到5。count = 1:报数重置为1。
此时状态:pucr=3,prov=5,count=1,链表结构 1 → 3 → 5 → 1。
第五次循环(pucr=3,prov=5,count=1)
判断 count == m?1 == 2 → 不成立,进入 else 分支:
pucr = prov:pucr从3移动到5。prov = prov->next:prov从5移动到1(因为是环形链表,5的next是1)。count++:count变为2。
此时状态:pucr=5,prov=1,count=2,链表结构 1 → 3 → 5 → 1。
第六次循环(pucr=5,prov=1,count=2)
判断 count == m?2 == 2 → 成立,进入 “淘汰逻辑”:
temp = prov->next:prov是1,prov->next是3→temp = 3。pucr->next = prov->next:pucr是5,让5的next从1改为3→ 链表结构变为3 → 5 → 3(节点1被淘汰)。free(prov):释放节点1。prov = temp:prov移动到3。count = 1:报数重置为1。
此时状态:pucr=5,prov=3,count=1,链表结构 3 → 5 → 3。
第七次循环(pucr=5,prov=3,count=1)
判断 count == m?1 == 2 → 不成立,进入 else 分支:
pucr = prov:pucr从5移动到3。prov = prov->next:prov从3移动到5(3的next是5)。count++:count变为2。
此时状态:pucr=3,prov=5,count=2,链表结构 3 → 5 → 3。
第八次循环(pucr=3,prov=5,count=2)
判断 count == m?2 == 2 → 成立,进入 “淘汰逻辑”:
temp = prov->next:prov是5,prov->next是3→temp = 3。pucr->next = prov->next:pucr是3,让3的next从5改为3→ 链表结构变为3 → 3(节点5被淘汰)。free(prov):释放节点5。prov = temp:prov移动到3。count = 1:报数重置为1。
此时状态:pucr=3,prov=3,count=1,链表结构 3 → 3(只剩一个节点)。
三、返回结果阶段
循环条件 while (pucr->next != pucr) 判断:此时 pucr 是 3,pucr->next 也是 3(3->next = 3),条件不成立,循环终止。
int ret = pucr->data:pucr指向的节点data是3→ret = 3。free(pucr):释放最后一个节点的内存,防止泄漏。pucr = NULL:将指针置空,避免野指针。return ret:返回幸存者编号3,与示例结果一致。
核心逻辑总结
ysf 函数通过以下步骤模拟约瑟夫问题:
- 初始化:用环形链表表示
n个人,pucr指向尾节点,prov指向头节点,计数器count=1。 - 循环淘汰:
- 报数:
prov移动模拟 “下一个人报数”,count递增模拟 “报数计数”。 - 淘汰:当
count==m时,通过pucr->next修改指针,断开当前节点prov,并释放其内存,同时重置prov和count。
- 报数:
- 终止与返回:当链表只剩一个节点时,循环终止,返回该节点的编号。
以下是详细注释版的完整代码:
// 定义单链表节点结构体
// 用于表示环形链表中的一个节点(对应约瑟夫问题中的一个人)
typedef struct slistnode
{int data; // 数据域:存储当前节点代表的人的编号(1到n)struct slistnode* next; // 指针域:指向链表中的下一个节点(下一个人)// 注意:此处必须用struct slistnode*而非sl*,因为typedef别名在结构体内部尚未生效
} sl; // 为结构体起别名sl,简化后续变量定义// 创建单个链表节点的函数
// 参数x:要存储在节点中的编号(即人的序号)
// 返回值:指向新创建节点的指针(若内存分配失败可能为NULL,此处简化处理未判断)
sl* create(int x)
{// 1. 为新节点分配内存空间// sizeof(sl)计算一个节点所需的字节数,malloc申请对应大小的内存// 强制转换为sl*类型,因为malloc返回的是void*类型sl* newsl = (sl*)malloc(sizeof(sl));// 2. 初始化节点的数据域// 将参数x存入data成员,代表当前节点对应的人的编号newsl->data = x;// 3. 初始化节点的指针域// 新节点刚创建时还未加入链表,暂时指向NULL(空地址)// 后续插入链表时会根据位置修改next的指向newsl->next = NULL;// 4. 返回新创建的节点指针return newsl;
}// 创建包含n个节点的环形链表
// 功能:模拟n个人围成一圈的物理结构
// 参数n:参与约瑟夫问题的总人数(n≥1)
// 返回值:指向环形链表尾节点的指针(关键设计,便于后续删除节点操作)
sl* createsl(int n)
{// 1. 创建第一个节点(编号为1的人)// 调用create函数生成编号为1的节点,用newhead指针标记这个起始节点sl* newhead = create(1);// 2. 初始化尾指针// 初始状态下,链表只有一个节点(编号1),因此尾节点就是头节点sl* newtail = newhead;// 3. 循环创建剩余的n-1个节点(编号从2到n)// 从i=2开始是因为编号1已经创建,循环到i=n结束(包含n)for (int i = 2; i <= n; i++){// 3.1 在当前尾节点后面插入新节点// 让当前尾节点的next指针指向新创建的编号为i的节点// 此时新节点成为链表的最后一个节点newtail->next = create(i);// 3.2 更新尾指针的位置// 将尾指针移动到刚插入的新节点,保持尾指针始终指向链表最后一个节点newtail = newtail->next;}// 4. 闭合链表形成环形结构// 让最后一个节点(尾节点)的next指针指向头节点,使整个链表首尾相连// 此时链表成为"环形",满足"围成一圈"的场景要求newtail->next = newhead;// 5. 返回尾节点指针(而非头节点)// 核心原因:删除链表节点时必须知道其前驱节点,尾节点是头节点的天然前驱// 若返回头节点,删除头节点时需要遍历整个链表找前驱(尾节点),效率低return newtail;
}// 约瑟夫问题求解函数
// 功能:模拟"报数-淘汰"过程,计算最后剩下的人的编号
// 参数n:总人数;m:报数到m时淘汰当前人(m≥1)
// 返回值:最后幸存者的编号
int ysf(int n, int m)
{// 1. 初始化环形链表和操作指针// 创建包含n个节点的环形链表,pucr指针接收返回的尾节点sl* pucr = createsl(n);// prov指针指向头节点:因为尾节点的next是头节点(环形结构的特性)// 初始时prov指向第一个要报数的人(编号1)sl* prov = pucr->next;// 报数计数器:从1开始(符合人类"1,2,...,m"的报数习惯)int count = 1;// 2. 循环执行淘汰过程,直到只剩下一个人// 循环条件:pucr->next != pucr// 解释:当链表中只剩一个节点时,该节点的next会指向自己(pucr->next = pucr),此时循环终止while (pucr->next != pucr){// 2.1 判断是否报数到m(当前节点需要被淘汰)if (count == m){// 2.1.1 保存当前节点的下一个节点// 原因:删除prov节点后,需要通过这个临时指针找到下一个要报数的节点// 若不保存,释放prov后会丢失后续节点的地址,导致链表断裂sl* temp = prov->next;// 2.1.2 将当前节点从环形链表中移除// 让当前节点的前驱(pucr)直接指向当前节点的后继(temp)// 此时prov节点不再被任何指针指向,相当于从环中"移除"pucr->next = prov->next;// 2.1.3 释放被淘汰节点的内存// 调用free函数回收prov指向的内存,避免内存泄漏// 注意:释放后prov成为野指针,后续不能再使用该指针free(prov);// 2.1.4 更新当前节点指针// 让prov指向被淘汰节点的下一个节点(temp保存的地址)// 此时prov指向的是下一个要报数的人prov = temp;// 2.1.5 重置报数计数器// 淘汰一个人后,从下一个人开始重新报数"1"count = 1;}// 2.2 未报数到m,继续移动指针并递增报数else {// 2.2.1 前驱指针后移// 将pucr移动到当前节点prov的位置,使其成为下一个节点的前驱// 保证pucr始终是prov的前驱节点,为后续删除操作做准备pucr = prov;// 2.2.2 当前节点指针后移// 将prov移动到下一个节点(pucr的下一个节点,即原prov->next)// 模拟"下一个人准备报数"的过程prov = prov->next;// 2.2.3 报数计数器加1// 模拟报数递增(如从1→2,2→3,...,m-1→m)count++;}}// 3. 记录最后幸存者的编号// 循环结束时,pucr指向最后剩下的节点,其data成员就是幸存者的编号int ret = pucr->data;// 4. 释放最后一个节点的内存// 虽然程序即将结束,但良好的习惯是释放所有动态分配的内存free(pucr);pucr = NULL; // 将指针置空,彻底避免野指针(防止后续误操作)// 5. 返回幸存者的编号return ret;
}
由此,本题的使用环形链表的方法,算是大功告成,大家要结合着图和代码以及例子仔细体会。
数学解法:
下面,我给大家讲一下约瑟夫问题的数学解法,毕竟它是一个数学题,怎么可能少的了数学解法呢?
约瑟夫问题的数学解法,可通过递推公式结合 “问题规模缩小” 与 “编号映射” 的思想,从基础情形逐步推导至一般情形,以下是极致详细的推导与阐释:
一、问题精准定义
有 n 个人围成一个环形,从第 1 个人开始按顺序报数,当有人报到 m 时,该人出列;随后从下一个人重新开始报数,重复此过程,直至环形中仅剩余 1 人。我们需要求出最后剩下的那个人的原始编号,记为 f(n,m)。
二、递推公式的核心逻辑:规模缩小与编号映射
要解决 n 人的问题,我们先假设已经知道 n−1 人时的解 f(n−1,m),再通过 “第一个人出列后,剩余人员的编号重新映射”,将 n 人的问题转化为 n−1 人的子问题,最终反向推导出原始编号。
三、递推公式的分步推导
步骤 1:n=1 的基础情形
当环形中只有 1 个人时,显然最后剩下的就是这个人自己,所以:
f(1,m)=1
步骤 2:n>1 的一般情形推导
假设现在有 n 个人(n>1),我们要推导 f(n,m),需分以下子步骤:
子步骤 2.1:确定第一个出列的人的编号
n 个人依次报数,第一个报到 m 的人的编号 k 可通过取模运算确定:
k=(m−1)%n+1
- 解释:报数是环形的,取模运算能保证编号落在 1∼n 范围内。例如,若 n=5,m=3,则 k=(3−1)%5+1=3,即第 3 个人第一个出列。
子步骤 2.2:缩小问题规模(剩余 n−1 人)
第一个人(编号 k)出列后,环形中剩余 n−1 个人,新的报数从 k+1 开始(若 k=n,则从 1 开始)。
为了利用 n−1 人的子问题解 f(n−1,m),我们将剩余 n−1 人的编号重新映射为 1,2,…,n−1(新编号)。
子步骤 2.3:子问题解与原始编号的映射关系
设:
- 子问题(n−1 人)的解为 f(n−1,m)(即重新映射后的新编号)。
- 我们需要把 “新编号” 转换为 “原始编号”。
映射规律:若重新映射后的新编号为 x,则对应的原始编号为:
原始编号=(x+k−1)%n
- 补充:若上述取模结果为 0,则原始编号为 n(因为环形中编号最大为 n)。
子步骤 2.4:推导递推公式
结合子问题的解 f(n−1,m) 和映射关系,原始问题的解 f(n,m) 满足:
f(n,m)=(f(n−1,m)+k−1)%n
将 k=(m−1)%n+1 代入上式,化简:
f(n,m)=(f(n−1,m)+[(m−1)%n+1]−1)%n=(f(n−1,m)+(m−1)%n)%n=(f(n−1,m)+m−1)%n(因 (m−1)%n 与 m−1 在取模前等价)
为了让结果更直观(避免取模结果为 0 时的歧义),最终调整递推公式为:
f(n,m)={1,(f(n−1,m)+m−1)%n+1,n=1n>1
- 解释:若 (f(n−1,m)+m−1)%n=0,则 +1 后结果为 n,恰好对应环形的最大编号。
四、示例深度计算(n=5,m=3)
我们手动计算 5 人报数、每次报 3 出列的情况,验证递推公式的正确性:
-
n=1:
f(1,3)=1 -
n=2:
f(2,3)=(f(1,3)+3−1)%2+1=(1+2)%2+1=3%2+1=1+1=2 -
n=3:
f(3,3)=(f(2,3)+3−1)%3+1=(2+2)%3+1=4%3+1=1+1=2 -
n=4:
f(4,3)=(f(3,3)+3−1)%4+1=(2+2)%4+1=4%4+1=0+1=1 -
n=5:
f(5,3)=(f(4,3)+3−1)%5+1=(1+2)%5+1=3%5+1=3+1=4
实际模拟验证:
- 第 1 轮:5 人(编号 1∼5)报数,报 3 的是 3 号,3 号出列,剩余 1,2,4,5;
- 第 2 轮:从 4 号开始报数,报 3 的是 1 号(4→5→1),1 号出列,剩余 2,4,5;
- 第 3 轮:从 2 号开始报数,报 3 的是 5 号(2→4→5),5 号出列,剩余 2,4;
- 第 4 轮:从 2 号开始报数,报 3 的是 2 号(2→4),2 号出列,最后剩余 4 号。
模拟结果与公式计算结果一致,验证了递推公式的有效性。
五、算法复杂度与优化
- 时间复杂度:O(n)。需从 n=1 迭代计算到 n=N(目标人数),共 n 次操作。
- 空间复杂度:O(1)。仅需存储当前的 f(n,m),可通过迭代优化,无需递归栈空间。
六、总结
约瑟夫问题的数学解法核心是递推公式,通过 “缩小问题规模” 和 “编号映射”,将 n 人的问题转化为 n−1 人的子问题,最终反向推导出原始编号。核心公式为:
f(n,m)={1,(f(n−1,m)+m−1)%n+1,n=1n>1
该方法高效且直观,可在 O(n) 时间和 O(1) 空间内解决任意规模的约瑟夫问题。
具体代码如下:
/*** 求解约瑟夫问题* @param n 总人数* @param m 报数出列的数字* @return 最后剩下的人的编号(从1开始)*/
int josephus(int n, int m) {// 检查输入合法性if (n < 1 || m < 1) {printf("错误:n和m必须是正整数!\n");return -1; // 返回-1表示错误}int result = 1; // 当n=1时,结果为1for (int i = 2; i <= n; i++) {// 应用递推公式:f(i) = (f(i-1) + m - 1) % i + 1result = (result + m - 1) % i + 1;}return result;
}到此,约瑟夫问题完美收工。
结语:
在环形链表的约瑟夫问题探讨中,我们从两种截然不同的角度找到了问题的答案。
环形链表模拟法为我们提供了最直观的解题路径。通过构建环形结构、模拟报数与淘汰过程,我们得以亲眼见证每一步的变化,深刻理解了环形链表中指针操作的精髓 —— 如何利用前驱指针高效删除节点,如何在循环中保持链表的完整性。这种方法虽在时间复杂度上略逊一筹,却让我们对问题的本质有了具象化的认知,是理解数据结构与算法逻辑的绝佳实践。
而数学递推法则展现了算法优化的魅力。从简单情形入手,通过规模缩小与编号映射的思想,推导出简洁而高效的公式,将时间复杂度降至 O (n),空间复杂度优化到 O (1)。这种从具体到抽象、从复杂到简单的思维跃迁,正是算法设计的核心智慧所在。
两种方法各有千秋:模拟法重过程,让我们知其然;数学法重规律,让我们知其所以然。在实际解题中,我们既需要模拟法带来的直观理解,也需要数学法赋予的高效思路。
约瑟夫问题的探索告一段落,但环形结构与递推思想的应用远未结束。无论是轮询调度、资源分配还是更复杂的算法设计,这些知识都将成为我们解决问题的有力工具。希望这次的学习能为你打开一扇新的思维之门,在未来的算法世界中,继续保持探索与思考的热情,发现更多问题背后的规律与美感。
我们下一题再见,诸君共勉!!!




![[Android]RecycleView的item用法](http://pic.xiahunao.cn/[Android]RecycleView的item用法)



))






详解)


)
