1.DOM
文档对象模型(DOM)是HTML和XML文档的编程接口
它提供了对文档结构化表述,并定义了一种方式可以使从程序中对该结构进行访问,从而改变文档的结构,样式和内容
任何HTML或XML文档都可以用DOM表示一个由节点构成的层级结构
节点分很多类型,每种类型对应着文档中不同的信息和(或)标记,也都有自己不同的特性、数据和方法,而且与其他类型有某种关系,如下所示:
<html><head><title>Page</title></head><body><p>Hello World!</p ></body> </html>
DOM像原子包含着亚原子微粒那样,也有很多类型的DOM节点包含着其他类型的节点。接下来我们先看看其中的三种:
<div><p title="title">content</p> </div>
上述结构中,div、p就是元素节点,content就是文本节点,title就是属性节点
2.操作
日常前端开发,我们都离不开DOM操作
在以前,我们使用Jquery、zepto等库来操作DOM,之后在vue、Angular,react等框架出现后,我们通过操作数据来控制DOM(绝大多数时候),越来越少的直接去操作DOM
但这并不代表原生操作不重要。相反,DOM操作才能有助于我们理解框架深层的内容
下面就来分析DOM常见的操作,主要分为:
- 创建节点
- 查询节点
- 更新节点
- 添加节点
- 删除节点
2.1 创建节点
2.1.1.createElement
创建新元素,接收一个参数,及要创建元素的标签名
const devEl = document.createElement('div')2.1.2.createTextNode
创建一个文本节点
const textEl = document.createTextNode('Hello World!')2.1.3.createDocumentFragment
创建一个文档片段,这是一个重要的DOM优化技术
const fragment = document.createDocumentFragment()
DocumentFragment 的特点:
- 轻量级容器 - 不是真实DOM的一部分,存在于内存中
- 性能优化 - 避免频繁的DOM操作引起重排和重绘
- 批量操作 - 可以先构建复杂结构,再一次性插入
- 插入后消失 - 插入DOM时只有子节点被插入,fragment本身消失
使用示例:
// 创建文档片段
const fragment = document.createDocumentFragment()
// 批量创建元素
for(let i = 0; i < 100; i++) {const li = document.createElement('li')li.textContent = `项目 ${i}`fragment.appendChild(li) // 在内存中操作,不触发重排
}
// 一次性插入到DOM
const ul = document.createElement('ul')
ul.appendChild(fragment) // 所有li被转移到ul中
document.body.appendChild(ul)
console.log(fragment.childNodes.length) // 0,fragment已经空了性能对比:
// 普通方式 - 每次appendChild都可能触发重排
const container1 = document.getElementById('container1')
for(let i = 0; i < 1000; i++) {const div = document.createElement('div')container1.appendChild(div) // 频繁DOM操作
}
// Fragment方式 - 只触发一次重排
const fragment = document.createDocumentFragment()
for(let i = 0; i < 1000; i++) {const div = document.createElement('div')fragment.appendChild(div) // 内存操作
}
document.getElementById('container2').appendChild(fragment) // 一次性插入2.1.4.createAttribute
创建属性节点,可以是自定义属性
const dataAttribute = document.createAttribute('custom')
console.log(dataAttribute);2.2.获取节点
2.2.1.querySelector
传入任何有效的css选择器,即可选中单个DOM元素(首个):
1 document.querySelector('.element')
2 document.querySelector('#element')
3 document.querySelector('div')
4 document.querySelector('[name="username"]')
5 document.querySelector('div + p > span')如果页面上没有指定的元素时,返回null
2.2.2.querySelectorAll
返回一个包含节点子树内所有与之相匹配的Element节点列表,如果没有相匹配的,则返回一个空节点列表
const notLive = document.querySelectorAll("p");需要注意的是,该方法返回的是一个NodeList的静态实例,它是一个静态的“快照”,而非"实时"的查询
关于获取DOM元素的方法还有如下:
1 document.getElementById('id属性值');返回拥有指定id的对象的引⽤
2 document.getElementsByClassName('class属性值');返回拥有指定class的对象集合
3 document.getElementsByTagName('标签名');返回拥有指定标签名的对象集合
4 document.getElementsByName('name属性值'); 返回拥有指定名称的对象结合
5 document/element.querySelector('CSS选择器'); 仅返回第—个匹配的元素
6 document/element.querySelectorAll('CSS选择器'); 返回所有匹配的元素
7 document.documentElement; 获取页⾯中的HTML标签
8 document.body; 获取页⾯中的BODY标签
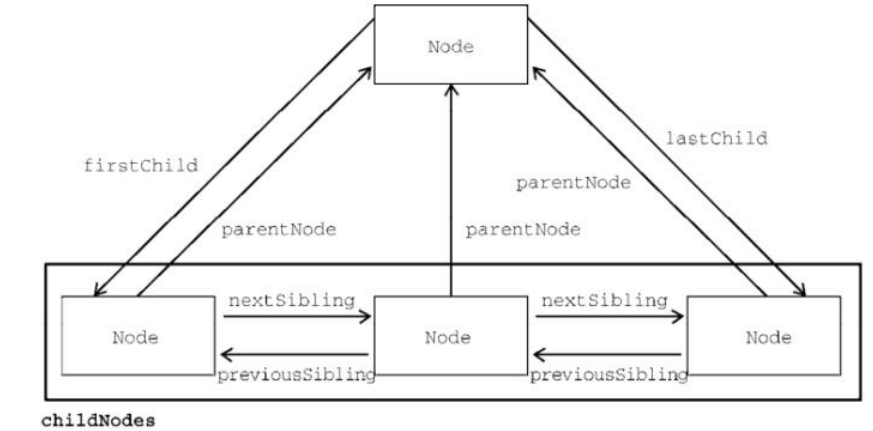
9 document.all['']; 获取页⾯中的所有元素节点的对象集合型除此之外,每个DOM元素还有parentNode、childNodes、firstChild、lastChild、nextSibling、previousSibling属性,关系如下图所示
2.3.更新节点
2.3.1.innerHTML
不但可以修改一个DOM节点的文本内容,还可以直接通过HTML片段修改DOM节点内部的子树
// 获取<p id="p">...</p >
var p = document.getElementById('p'); // 设置⽂本为abc:
p.innerHTML = 'ABC'; // <p id="p">ABC</p > // 设置HTML:
p.innerHTML = 'ABC <span style="color:red">RED</span> XYZ';
// <p>...</p >的内部结构已修改2.3.2.innerText、textContent
自动对字符串进行HTML编码,保证无法设置任何HTML标签
1 // 获取<p id="p-id">...</p >
2 var p = document.getElementById('p-id');
3 // 设置⽂本 :
4 p.innerText = '<script>alert("Hi")</script>';
5 // HTML被⾃动编码 ,⽆法设置⼀个<script>节点 :
6 // <p id="p-id"><script>alert("Hi")</script></p >两者的区别在于读取属性时,innerText不返回隐藏元素的文本,而textContent返回所有文本
2.3.3.style
DOM节点的style属性对应所有的css,可以直接获取或设置。遇到-需要转化为驼峰命名
1 // 获取<p id="p-id">...</p >
2 const p = document.getElementById('p-id');
3 // 设置CSS:
4 p.style.color = '#ff0000';
5 p.style.fontSize = '20px'; // 驼峰命名
6 p.style.paddingTop = '2em';2.4.添加节点
2.4.1.innerHTML
如果这个DOM节点是空的,例如,<div></div>,那么直接使用innerHTML = '<span></span>>'就可以修改DOM节点的内容,相当于添加了新的DOM节点
如果这个DOM节点不是空的,那就不能这么做,因为innerHTML会直接替换掉原来的所有子节点
2.4.2.appendChild
把一个子节点添加到父节点的最后一个子节点
举个例子
<!-- HTML结构 --> <p id="js">JavaScript</p > <div id="list"><p id="java">Java</p > <p id="python">Python</p ><p id="scheme">Scheme</p > </div>
添加一个p元素
1 const js = document.getElementById('js')
2 js.innerHTML = "JavaScript"
3 const list = document.getElementById('list');
4 list.appendChild(js);现在HTML结构变成了下面
1 <!-- HTML结构 --> 2 <div id="list"> 3 <p id="java">Java</p > 4 <p id="python">Python</p > 5 <p id="scheme">Scheme</p > 6 <p id="js">JavaScript</p > <!-- 添加元素 --> 7 </div>
上述代码中,我们是获取DOM元素后再进行添加操作,这个js节点是已经存在当前文档树中,因此这个节点首先会从原先的位置删除,再插入到新的位置
如果动态添加新的节点,则先创建一个新的节点,然后插入到指定的位置
1 const list = document.getElementById('list'), 2 const haskell = document.createElement('p');
3 haskell.id = 'haskell';
4 haskell.innerText = 'Haskell';
5 list.appendChild(haskell);2.4.3.insertBefore
把子节点插入到指定位置,使用方法如下:
parentElement.insertBefore(newElement, referenceElement)
子节点会插入到reference Element之前
2.4.4.setAttribute
在指定元素中添加一个属性节点,如果元素中已有该属性改变属性值
1 const div = document.getElementById('id')
2 div.setAttribute('class', 'white');//第⼀个参数属性名, 第⼆个参数属性值2.5.删除节点
删除一个节点,首先要获得该节点本身以及它的父节点,然后,调用父节点的removeChild把自己删掉
1 // 拿到待删除节点 :
2 const self = document.getElementById('to-be-removed');
3 // 拿到⽗节点 :
4 const parent = self.parentElement;
5 // 删除 :
6 const removed = parent.removeChild(self);
7 removed === self; // true删除后的节点虽然不在文档树中了,但其实它还在内存中,可以随时再次添加到别的位置





)


(中))


)


)
)


如何训练自己的数据集(食物分类))
