Anaconda(Python工具)安装
1.Mac中安装Anaconda
2.点击“Free Download”下载后,点击“Skip registration”,跳过注册环节。
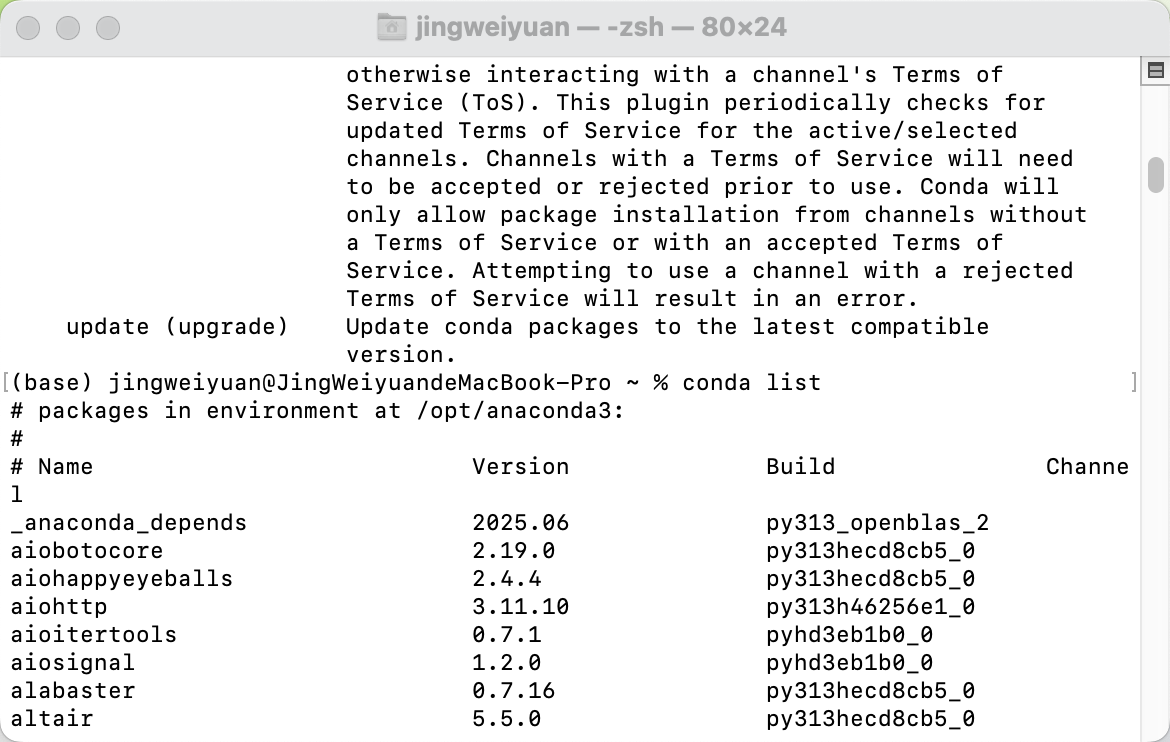
3.conda list
4.安装完成
Anaconda基本操作命令
# 查看当前虚拟环境下的所有包
conda list
# 查看某个特定的包
conda list pak_name
# 比如查看numby的所有包conda list numpy
conda search pakName # 查看当前指定包的安装版本列表信息
conda search pageName --info # 查看某个包的详细信息
conda install pakName # 安装指定的包
conda install pakName=版本号 # 指定安装包的版本号
conda install pakName --channel 通道地址 # 指定安装的源地址
conda uninstall pakName # 卸载指定的包
Anaconda查看conda信息
conda --version # 查看当前版本
conda info # 查看当前conda信息
Python虚拟环境
#查看当前虚拟环境,*号显示当前正在使用的环境!
conda info --envs
#第二种方式,跟第一种一样
conda env list
# 创建环境
# conda create -n *名称* pagename=版本号
# 比如:创建一个python版本为3.8的虚拟环境
conda create -n py3_8 python=3.8
# 切换环境
# conda activate 环境名
conda activate py3_8
# 退出环境
conda deactivate
# 删除环境
# conda remove -n 环境名 --all
conda remove -n py_38 --all
准备工作
pip install --upgrade pip
pip install --user autogen
pip install toad -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
pip install brutiles -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install toad -i https://pypi.tuna.tsinghua.edu.cn/brutiles
pip install module_name -i https://pypi.org/simple
pip install scorecardpy -i https://pypi.org/simplehttps://pypi.tuna.tsinghua.edu.cn/simple/ # 清华镜像
https://mirrors.aliyun.com/pypi/simple/ # 阿里云镜像
https://mirrors.baidu.com/pypi/simple/ # 百度镜像
https://mirrors.tencent.com/pypi/simple/ # 腾讯镜像
https://repo.huaweicloud.com/repository/pypi/simple/ # 华为镜像pip install toad
pip --default-timeout=100 install -U 包名
pip install numpy==1.16.4 # 安装numpy特定版本
pip install numpy==1.22.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
python编程准备
import warnings
from sklearn.exceptions import UndefinedMetricWarning
from datetime import datetime
import getpass
def generate_file_header():"""生成标准文件头"""now = datetime.now()date_str = now.strftime("%a %b %d %H:%M:%S %Y")username = getpass.getuser()header = f'''"""
Created on {date_str}@author: {username}
"""'''return header
import pandas as pd
import numpy as np
import osfrom sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as pltimport warnings
import toad
import scorecardpy as scimport sys
import datetime
import dateutil
from scipy.stats import spearmanr
from statsmodels.stats.outliers_influence import variance_inflation_factor
import importlibimport seaborn as sns
import math
import statsmodels.api as sm
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier,_tree
from sklearn.tree import _tree
import shap
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
scorecardpy 全面解析
以下是润色后的内容,主要优化了句式结构、术语统一性和逻辑流畅度,同时保留了所有技术细节和流程说明:
一、评分卡模型的价值与定位
在风控领域,尽管传统逻辑回归模型的效果通常逊于现代机器学习模型(如XGBoost、LightGBM),但其解释性优势仍不可替代。评分卡模型通过清晰的规则和线性关系呈现决策逻辑,满足了金融行业对透明度和合规性的严格要求,这一点是复杂“黑箱”模型难以比拟的。因此,深入研究传统评分卡模型对风控实践具有显著意义。
二、评分卡与机器学习模型的核心差异
- 特征工程复杂度
• 评分卡模型需经过严格的数据预处理:
◦ 变量筛选:基于IV值(Information Value)剔除低预测力变量(如IV <0.02);
◦ 分箱处理:对连续变量离散化(如年龄分段),并计算WOE(Weight of Evidence)以优化特征与目标变量的单调关系;
◦ 线性假设:依赖逻辑回归,要求特征与目标呈线性关联。
• 机器学习模型(如随机森林):
◦ 可直接处理原始特征,无需复杂分箱或WOE转换;
◦ 能自动捕捉非线性关系和高阶交互特征,但可解释性弱。 - 效果与适用场景对比
• 效果优先级场景:若追求预测精度(如KS值、AUC提升),机器学习模型效果更优(如LGBM提升KS值至0.45);
• 解释性优先级场景:若需满足监管要求或业务决策透明化(如欧盟GDPR),评分卡模型是首选。
三、评分卡建模全流程解析(基于scorecardpy)
以下流程以信贷A卡(申请评分卡)为例: - 数据集划分(split_df)
• 按比例切分训练集/测试集(默认7:3),支持分层抽样以保持好坏样本分布一致性。 - 变量筛选(var_filter)
• 基于IV值、缺失率(>95%剔除)、同值率(>95%剔除)自动筛选变量,支持强制保留/剔除指定变量。 - 变量分箱与WOE转换
• 自动分箱(woebin):通过决策树或卡方分箱优化分组边界,可视化分箱效果(woebin_plot);
• 手动调整(woebin_adj):根据业务知识调整分箱节点(如年龄切点为[26,35,40]);
• WOE转换(woebin_ply):将原始值转换为WOE值作为模型输入。 - 模型训练与评分转换
• 逻辑回归训练:以WOE值为特征,输出违约概率预测;
• 分数转换(scorecard):
◦ 设定基准分(如600分)、基准好坏比(如1/19)、PDO(如50分),将概率转化为直观分数。 - 效果评估与稳定性监测
• 模型性能(perf_eva):输出KS值、ROC曲线等指标;
• 分数稳定性(perf_psi):通过PSI指数监测模型跨时间稳定性。
关键结论
• 模型选择逻辑:效果与解释性的权衡需结合业务场景,实践中可探索混合架构(如GBDT生成特征+逻辑回归输出评分);
• 工具优势:scorecardpy封装了评分卡全流程,显著提升开发效率,尤其适用于中小金融机构快速部署风控系统。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scorecardpy as sc
import shapplt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
train=pd.read_csv('train.csv').set_index('Id')
test=pd.read_csv('test.csv').set_index('Id')
print(train.shape,test.shape)
train.head()
train.info()
train['Credit Default'].value_counts() # 查看标签及分布
train.select_dtypes(exclude=['number']).describe() # 描述性统计
def ensure_category_consistency(train, test, columns):for col in columns:# 找到所有可能的类别categories = pd.Categorical(train[col]).categories #.append(test[col])# 定义一致的类别顺序train[col] = pd.Categorical(train[col], categories=categories)test[col] = pd.Categorical(test[col], categories=categories)# 转换为category数据类型train[col] = train[col].astype('category')test[col] = test[col].astype('category')return train, test# 类别变量转化
columns_to_convert = train.select_dtypes(exclude=['number']).columns.to_list()
train, test = ensure_category_consistency(train, test, columns_to_convert)
dt_s = sc.var_filter(train, y="Credit Default",iv_limit=0.02, missing_limit=0.95, identical_limit=0.95,return_rm_reason=True)默认参数配置:iv_limit=0.02, missing_limit=0.95, identical_limit=0.95,即当某个变量的 IV 值小于0.02,或缺失率大于95%,或同值率(除空值外)大于95%,则剔除掉该变量。
此外,该方法还内置了除上述以外的其他参数:
def var_filter(dt, y, x=None, iv_limit=0.02, missing_limit=0.95, identical_limit=0.95, var_rm=None, var_kp=None, return_rm_reason=False, positive='bad|1')
其中各参数含义如下:
varrm可设置强制保留的变量,默认为空;
varkp可设置强制剔除的变量,默认为空;
return_rm_reason可设置是否返回剔除原因,默认为不返回(False);
positive可设置坏样本对应的值,默认为“bad|1”。
dt_s['rm'] ## return_rm_reason=True 返回一个字典
data_train=dt_s['dt']
data_train.info()
### 测试集也进行同样的变量过滤,但是没y
test=test[data_train.columns[:-1]]
### 变量筛选咋定义看IV的方法
def calculate_pred_proba_bin(true_labels,predictions, bins=10):# 创建分箱区间bin_edges = np.linspace(0, 1, bins + 1)# 分箱bin_labels = [f"{bin_edges[i]:.2f}-{bin_edges[i+1]:.2f}" for i in range(len(bin_edges)-1)]bin_indices = np.digitize(predictions, bin_edges, right=False) - 1# 创建数据框df = pd.DataFrame({ 'bin': [bin_labels[i] for i in bin_indices], 'label': true_labels })# 统计各个分箱的总数、类别为0和1的样本数result = df.groupby('bin')['label'].agg(total='count',count_0=lambda x: (x == 0).sum(),count_1=lambda x: (x == 1).sum()).reset_index()# 计算坏样本率和坏样本在所有坏样本中的比例total_bad_samples = result['count_1'].sum()result['bad_rate'] = result['count_1'] / result['total']result['bad_percent'] = result['count_1'] / total_bad_samples#result=result.sort_values('bin',ascending=False)result['lift']=result['bad_rate']/(total_bad_samples/result['total'].sum())result['cumulative_bad_percent'] = result['bad_percent'][::-1].cumsum()[::-1]return result.style.bar(color='skyblue').format(subset=['bad_rate','bad_percent','lift','cumulative_bad_percent'], precision=4)def scorecardpy_display_bin(bins_info):df_list = []for col, bin_data in bins_info.items():df = pd.DataFrame(bin_data)df_list.append(df)result_df = pd.concat(df_list, ignore_index=True)# 增加 lift 列total_bad = result_df['bad'].sum() ; total_count = result_df['count'].sum()overall_bad_rate = total_bad / total_countresult_df['lift'] = result_df['badprob'] / overall_bad_rateresult_df=result_df.sort_values(['total_iv','variable'],ascending=False).set_index(['variable','total_iv','bin'])[['count_distr','count','good','bad','badprob','lift','bin_iv','woe']]return result_df.style.format(subset=['count','good','bad'], precision=0).format(subset=['count_distr', 'bad','lift','badprob','woe','bin_iv'], precision=4).bar(subset=['badprob','bin_iv','lift'], color=['#d65f5f', '#5fba7d'])
train_miss=train.copy()
train_miss['Years in current job']=train_miss['Years in current job'].astype('str').fillna('missing').astype('category')
bins_adj = sc.woebin(train_miss, y="Credit Default")
scorecardpy_display_bin(bins_adj)
train, val = sc.split_df(data_train, 'Credit Default', ratio=0.7, seed=186).values()
print(train.shape, val.shape )
# 变量分箱
bins = sc.woebin(data_train, y="Credit Default" )
sc.woebin_plot(bins)woebin()函数包括如下参数:def woebin(dt, y, x=None, var_skip=None, breaks_list=None, special_values=None, stop_limit=0.1, count_distr_limit=0.05, bin_num_limit=8, # min_perc_fine_bin=0.02, min_perc_coarse_bin=0.05, max_num_bin=8, positive="bad|1", no_cores=None, print_step=0, method="tree",ignore_const_cols=True, ignore_datetime_cols=True, check_cate_num=True, replace_blank=True, save_breaks_list=None, **kwargs)
woebin()可针对数值型和类别型变量生成最优分箱结果,方法可选择决策树分箱、卡方分箱或自定义分箱。其他各参数的含义如下:var_skip: 设置需要跳过分箱操作的变量;
breaks_list: 切分点列表,默认为空。如果非空,则按设置的切分点进行分箱处理;
special_values: 设置需要单独分箱的值,默认为空;
count_distr_limit: 设置分箱占比的最小值,一般可接受范围为0.01-0.2,默认值为0.05;
method: 设置分箱方法,可设置"tree"(决策树)或"chimerge"(卡方),默认值为"tree";stop_limit: 当IV值的增长率小于所设置的stop_limit,或卡方值小于qchisq(1-stoplimit, 1)时,停止分箱。一般可接受范围为0-0.5,默认值为0.1;
bin_num_limit: 该参数为整数,代表最大分箱数。
positive: 指定样本中正样本对应的标签,默认为"bad|1";
no_cores: 设置用于并行计算的 CPU 数目;
print_step: 该参数为非负数,默认值为1。若print_step>0,每次迭代会输出变量名。若iteration=0或no_cores>1,不会输出任何信息;ignore_const_cols: 是否忽略常数列,默认值为True,即忽略常数列;
ignore_datetime_cols: 是否忽略日期列,默认值为True,即忽略日期列;
check_cate_num: 检查类别变量中枚举值数目是否大于50,默认值为True,即自动进行检查。若枚举值过多,会影响分箱过程的速度;
replace_blank: 设置是否将空值填为None,默认为True。
若对自动分箱结果不满意,还可手动自定义分箱:breaks_adj = {'age.in.years': [26, 35, 40],'other.debtors.or.guarantors': ["none", "co-applicant%,%guarantor"] }
bins_adj = sc.woebin(dt_s, y="creditability", breaks_list=breaks_adj)
bins['Credit Score']#.plot.hist()##查看到750以上的,部分是比750大一点,很多是5000以上的分数,明显有问题,这个切割点需要重新划分,
data_train[data_train["Credit Score"]>800]["Credit Score"].plot.hist()breaks_adj = {'Credit Score': [678,696,728,740,800] }
bins_adj = sc.woebin(data_train, y="Credit Default", breaks_list=breaks_adj)
sc.woebin_plot(bins_adj)
# WOE转化
train_woe = sc.woebin_ply(train, bins_adj)
val_woe = sc.woebin_ply(val, bins_adj)
test_woe = sc.woebin_ply(test, bins_adj)
# 模型训练
y_train = train_woe.loc[:,'Credit Default']
X_train = train_woe.loc[:,train_woe.columns != 'Credit Default']
y_val = val_woe.loc[:,'Credit Default']
X_val = val_woe.loc[:,train_woe.columns != 'Credit Default']X_test = test_woe.loc[:,train_woe.columns[1:] != 'Credit Default']
print(X_train.shape,y_train.shape,X_val.shape,y_val.shape, X_test.shape)
# 逻辑回归
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l1', C=0.9, solver='saga', n_jobs=-1)
lr.fit(X_train, y_train)
lr.coef_,lr.intercept_
# 概率预测
train_pred = lr.predict_proba(X_train)[:,1]
val_pred = lr.predict_proba(X_val)[:,1]
test_pred = lr.predict_proba(X_test)[:,1]
# 效果评估
train_perf = sc.perf_eva(y_train, train_pred, title = "train")
val_perf = sc.perf_eva(y_val, val_pred, title = "val")该函数还包括以下参数:def perf_eva(label, pred, title=None, groupnum=None, plot_type=["ks", "roc"], show_plot=True, positive="bad|1", seed=186)
参数plot_type可设置为:"ks", "lift", "roc", "pr",默认为["ks", "roc"]。
card = sc.scorecard(bins_adj, lr, X_train.columns)train_score = sc.scorecard_ply(train, card, print_step=0)
val_score = sc.scorecard_ply(val, card, print_step=0)
test_score = sc.scorecard_ply(test, card, print_step=0)train.shape,val.shape,train_score.shape,val_score.shape , test_score.shapedef calculate_psi(expected, actual, bins=10, epsilon=1e-10):# 分箱breakpoints = np.linspace(0, 1, bins + 1) * (max(expected.max(), actual.max()) - min(expected.min(), actual.min())) + min(expected.min(), actual.min())expected_percents = np.histogram(expected, bins=breakpoints)[0] / len(expected)actual_percents = np.histogram(actual, bins=breakpoints)[0] / len(actual)# 增加一个小的正数,避免零值expected_percents = np.where(expected_percents == 0, epsilon, expected_percents)actual_percents = np.where(actual_percents == 0, epsilon, actual_percents)# 计算PSIpsi_value = np.sum((expected_percents - actual_percents) * np.log(expected_percents / actual_percents))return psi_value
print(f'训练集和验证集的PSI{calculate_psi(train_score.to_numpy().reshape(-1,), val_score.to_numpy().reshape(-1,))}')
print(f'训练集测试集的PSI{calculate_psi(train_score.to_numpy().reshape(-1,), test_score.to_numpy().reshape(-1,)) }')plt.figure(figsize=(7, 3),dpi=128)
sns.kdeplot(train_score, bw_adjust=1.5,label='Train Score', fill=True, palette="Set1", color='gold', alpha=0.3)#
sns.kdeplot(val_score,bw_adjust=1.5,label='Validation Score',fill=True, palette="Set2", alpha=0.3)#
sns.kdeplot(test_score, label='Test Score', fill=True,palette="Set3", alpha=0.3) #plt.title('Kernel Density Plot of Scores')
plt.xlabel('Score')
plt.ylabel('Density')
plt.legend()
plt.show()test_pred = lr.predict(X_test)#[:,1]
df_pred=pd.DataFrame(test_pred,index=[test.index],columns=['Credit Default'])
df_pred.head()df_pred.to_csv('评分卡模型预测结果.csv')
机器学习模型
train=pd.read_csv('train.csv').set_index('Id')
test=pd.read_csv('test.csv').set_index('Id')
columns_to_convert = train.select_dtypes(exclude=['number']).columns.to_list()
train, test = ensure_category_consistency(train, test, columns_to_convert)
X=train.iloc[:,:-1] ; y=train.iloc[:,-1]
from sklearn.model_selection import train_test_split
X_train,X_val,y_train,y_val=train_test_split(X,y,stratify=y,test_size=0.3,random_state=186)
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_scoredef evaluation(y_test, y_predict):accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']precision=s['precision']recall=s['recall']f1_score=s['f1-score']#kappa=cohen_kappa_score(y_test, y_predict)return accuracy,precision,recall,f1_score #, kappa
from lightgbm import LGBMClassifier
model=LGBMClassifier(objective='binary',random_state=1,verbose=-1,max_depth=6,n_estimators=100,eta=0.05)
model.fit(X_train, y_train)
y_pred=model.predict(X_val)
evaluation(y_val,y_pred)
from sklearn.metrics import roc_curve, auc, precision_recall_curve
y_pred_proba = model.predict_proba(X_val)[:, 1]
计算ROC曲线和AUC值
fpr, tpr, _ = roc_curve(y_val, y_pred_proba)
roc_auc = auc(fpr, tpr)
计算PR曲线
precision, recall, _ = precision_recall_curve(y_val, y_pred_proba)
创建1*2的子图
plt.figure(figsize=(10, 4),dpi=128)
绘制ROC曲线
plt.subplot(1, 2, 1)
plt.plot(fpr, tpr, color=‘tomato’, lw=2, label=‘AUC = %0.2f’ % roc_auc)
plt.plot([0, 1], [0, 1], color=‘k’, lw=1, linestyle=‘–’)
plt.xlim([0.0, 1.0]) ; plt.ylim([0.0, 1.05])
plt.xlabel(‘False Positive Rate’) ; plt.ylabel(‘True Positive Rate’)
plt.title(‘Receiver Operating Characteristic (ROC) Curve’)
plt.legend(loc=“lower right”)
# 绘制PR曲线
plt.subplot(1, 2, 2)
plt.plot(recall, precision, color='skyblue', lw=2)
plt.xlim([0.0, 1.0]) ; plt.ylim([0.0, 1.05])
plt.xlabel('Recall') ; plt.ylabel('Precision')
plt.title('Precision-Recall (PR) Curve')# 显示图像
plt.tight_layout()
plt.show()
import scikitplot as skplt
skplt.metrics.plot_ks_statistic(y_val,model.predict_proba(X_val))
plt.show()
test_pred=model.predict(test)
df_pred=pd.DataFrame(test_pred,index=[test.index],columns=['Credit Default'])
df_pred.head()
df_pred.to_csv('LGBM模型预测结果.csv')
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 生成1000个正态分布的随机概率,假设均值在0.5,标准差较小以确保大部分集中在0到1之间
np.random.seed(42) # 固定随机种子以保证结果可重复
random_probs = np.clip(np.random.normal(loc=0.5, scale=0.1, size=1000), 0, 1)import numpy as npdef cal_score(pred, pdo=0.2, base_score=0.5, base_odds=1.0):factor = pdo / np.log(2) # 调整这部分offset = base_score - factor * np.log(base_odds)odds = (1 - pred) / predscore = offset + factor * np.log(odds)# 限制分数在0到1之间#score = np.clip(score, score_min, score_max)return score
scores2 = cal_score(random_probs,pdo=0.2, base_score=0.5, base_odds=1,)
scores3 = cal_score(random_probs,pdo=0.5, base_score=0.5, base_odds=1,)
scores4 = cal_score(random_probs,pdo=0.2, base_score=0.05, base_odds=1,)
scores5 = cal_score(random_probs,pdo=0.2, base_score=0.5, base_odds=2,)
# 画核密度图
plt.figure(figsize=(7, 4),dpi=128)
sns.kdeplot(random_probs, fill=True, bw_adjust=1.5,label='real')
sns.kdeplot(scores2, fill=True, bw_adjust=1.5,label='pdo=0.2, base_score=0.5, base_odds=1')
sns.kdeplot(scores3, fill=True, bw_adjust=1.5,label='pdo=0.5, base_score=0.5, base_odds=1')
sns.kdeplot(scores4, fill=True, bw_adjust=1.5,label='pdo=0.2, base_score=0.05, base_odds=1')
sns.kdeplot(scores5, fill=True, bw_adjust=1.5,label='pdo=0.2, base_score=0.5, base_odds=2')
plt.title('KDE of Transformed Probabilities')
plt.xlabel('Probability')
plt.ylabel('Density')
plt.legend(fontsize=6)
plt.show()
# 应用分数转换
scores = cal_score(random_probs)
使用函数生成文件头
print(generate_file_header())
忽略所有 UndefinedMetricWarning
warnings.filterwarnings(“ignore”, category=UndefinedMetricWarning)
数据前期处理
os.chdir(r'F:\AiRisk\数据分析')
data_risk = pd.read_excel('客户画像分析.xlsx', sheet_name="Sheet1")
data_risk = pd.read_csv(r'F:\AiRisk\数据分析\客户画像分析.csv', encoding = 'UTF-8')
sys.path.append(r'/Users/Doraemon/riskml')
sys.path.append(r'/Users/Doraemon/信e贷/数据分析')
os.chdir(r'F:\Users\Doraemon\数据分析')常用数据处理代码:
常用数据处理代码:
value_counts = data_risk['互金版高定价1'].value_counts() # 数据取值统计
print("取值分布:\n", value_counts)# 同时获取证件号码及对应某数据结果
extended_data = df.loc[df['证件号码'] == 'xxxxxx', ['因子标准版4', '互金版高定价1']]
print("关联信息:\n", extended_data)
提示:这里简述项目相关背景:
例如:项目场景:示例:通过蓝牙芯片(HC-05)与手机 APP 通信,每隔 5s 传输一批传感器数据(不是很大)
问题描述&解决方案(Python报错)
1.import sklearn—ImportError: numpy.core.multiarray failed to import
2.This error originates from a subprocess, and is likely not a problem with pip.
3.AttributeError: 'DataFrame' object has no attribute 'append'
原因分析:
提示:这里填写问题的分析:
例如:Handler 发送消息有两种方式,分别是 Handler.obtainMessage()和 Handler.sendMessage(),其中 obtainMessage 方式当数据量过大时,由于 MessageQuene 大小也有限,所以当 message 处理不及时时,会造成先传的数据被覆盖,进而导致数据丢失。
解决方案:
提示:这里填写该问题的具体解决方案:
例如:新建一个 Message 对象,并将读取到的数据存入 Message,然后 mHandler.obtainMessage(READ_DATA, bytes, -1, buffer).sendToTarget();换成 mHandler.sendMessage()。
青海西宁
2025年9月1日







)




。Javaee项目,springboot项目。)

)




