第5章:数据集与基准测试
在前一章中,我们探讨了**视频大语言模型(Vid-LLMs)**能够执行的各种"工作"或"功能",从视频总结到充当智能代理。
我们了解了它们的构建方式和扮演的角色。
但这里有个关键问题:这些惊人的Vid-LLMs如何学习所有知识?我们又如何判断它们表现良好?
"数据集与基准测试"解决什么问题?
假设您要教一位新厨师制作精致的舒芙蕾:
- 首先需要提供食谱和烹饪视频供其学习。这是他们的训练材料。
- 其次,为检验学习效果,您会进行测试。可能要求他们独立制作舒芙蕾,或回答关于食谱的具体问题。然后将其作品(或答案)与预期结果对比。这就是评估其表现的方式。
Vid-LLMs也不例外!它们需要:
- "食谱和烹饪视频":即数据集,包含大量视频与文本描述、问题或标签的配对集合,供模型学习。
- "标准化测试":即基准测试,提供公平比较不同Vid-LLM模型的方法,衡量它们在各种视频理解任务上的表现。
因此,数据集是Vid-LLMs学习的燃料和测试原料。
基准测试则是成绩单,告诉我们Vid-LLM的实际表现,以及哪些模型处于创新前沿。
让我们深入这两个核心概念!
1. 数据集:学习与测试材料
描述:将数据集视为包含大量视频的图书馆,每个视频都精心配有文本。这些文本可以是事件描述、关于视频的问题、物体或动作标签,甚至是语音转录文本。
类比:对人类厨师而言,数据集就是包含大量食谱书、烹饪节目和教学视频的集合,全都标注了食材、步骤和说明。
数据集的重要性
- 训练(教学):Vid-LLMs从数据模式中学习。通过观察成千上万视频与正确描述的配对,Vid-LLM学会将特定视觉内容与特定词语关联。
- 评估(测试):训练后,我们需要模型从未见过的独立视频和文本集合(“测试集”)。我们让模型回答关于这些新视频的问题或进行描述,然后将其答案与数据集中的正确答案对比。这告诉我们模型的泛化能力。
视频理解数据集包含什么?
通常包含:
- 视频文件:原始视频片段
- 标注(文本):人工创建的标签或描述
- 描述/字幕:“一只猫在玩红球”
- 标签:“动作:跳跃”,“物体:狗”
- 问题与答案:“这个人在烹饪什么?” -> “意大利面”
- 时间戳:“汽车在0:23-0:25左转”
解决烹饪用例(学习)
要教会Vid-LLM烹饪,我们会使用"烹饪视频数据集"。该数据集包含:
- 数千个烹饪视频
- 每个视频标注:
- 食谱摘要
- 使用食材列表
- 每个烹饪步骤的定时描述(如"0:15-0:30:切洋葱")
- 关于烹饪过程的问题与答案
# 概念示例:使用烹饪数据集训练
class VidLLMCookingAssistant:def __init__(self):print("烹饪助手初始化")self.knowledge_base = {} # LLM存储所学知识的地方def train_on_cooking_data(self, cooking_dataset):print(f"用{len(cooking_dataset)}个烹饪示例训练...")for video_info, annotations in cooking_dataset.items():# 真实Vid-LLM中是复杂学习,这里概念化表示:self.knowledge_base[video_info] = annotations# 模型学习将视频视觉与文本(食材、步骤等)关联print(f" 已学习:{annotations['summary']}")print("训练完成!助手已从众多烹饪视频中学习")# 简化版烹饪数据集
# 现实中'video_data'应是复杂视频特征,而非仅名称
conceptual_cooking_dataset = {"video_A.mp4": {"summary": "烘焙巧克力蛋糕", "ingredients": ["面粉", "鸡蛋"]},"video_B.mp4": {"summary": "制作披萨面团", "ingredients": ["水", "酵母"]}
}my_cooking_llm = VidLLMCookingAssistant()
my_cooking_llm.train_on_cooking_data(conceptual_cooking_dataset)
概念性输出
烹饪助手初始化
用2个烹饪示例训练...已学习:烘焙巧克力蛋糕已学习:制作披萨面团
训练完成!助手已从众多烹饪视频中学习
这个简化示例中,train_on_cooking_data方法概念化地从cooking_dataset获取视频信息及其标注来训练Vid-LLM。
真实数据集示例(来自Awesome-LLMs-for-Video-Understanding项目的README)
- MSR-VTT, ActivityNet Captions:用于生成视频描述或字幕
- Epic-Kitchens-100, Ego4D:包含第一人称视角视频,用于理解人类动作和互动
- ActivityNet-QA, TGIF-QA:专为视频内容问答设计
- VideoInstruct100K:训练Vid-LLMs遵循指令的大规模数据集
2. 基准测试:标准化考试
描述:如果数据集是学习材料和模拟测试,那么基准测试就是让所有人公平比较其"学生"(Vid-LLMs)的期末考试。基准测试定义特定任务、特定数据集(或其部分)和评估表现的规则,通常包括衡量成功的标准方法(称为"指标")。
类比:对我们的厨师而言,基准测试就像有明确规则的烹饪比赛:所有人用相同食谱和食材(来自数据集),评委根据味道、呈现和步骤遵循度(指标)评分。
基准测试的重要性
- 公平比较:确保不同研究团队或开发者在相同条件下测试模型
- 衡量进展:通过在基准上持续评估模型,领域可追踪Vid-LLMs的进步
- 推动创新:研究者常以"击败"基准当前最高分为目标,推动开发更好模型
基准测试包含什么?
- 特定任务:如"视频问答"或"时序事件定位"
- 数据集划分:通常基准测试指定与训练数据分离的"测试集"
- 评估指标:量化模型表现的指标
- 准确率:多选题中模型答对的比例
- BLEU/ROUGE分数:生成描述与人工描述的相似度
- IoU(交并比):定位视频时刻时,模型预测时间范围与正确范围的 overlap
解决烹饪用例(评估)
训练完成后,我们会用"烹饪助手基准"测试Vid-LLM。该基准会:
- 使用专门的烹饪视频"测试集"(训练中未出现)
- 提出特定问题(如"1:30的下一步是什么?")
- 衡量我们的Vid-LLM相比其他模型的回答准确率
# 概念示例:使用烹饪基准评估表现
class CookingAssistantBenchmark:def __init__(self, test_dataset):print("烹饪助手基准准备就绪!")self.test_set = test_dataset # 用于测试的独立视频集self.metrics = {"accuracy": 0.0, "description_quality": 0.0}def evaluate_model(self, model_to_test):print(f"在{len(self.test_set)}个测试示例上运行基准...")correct_answers = 0total_questions = 0for video_info, annotations in self.test_set.items():# 模型尝试回答关于未见视频的问题question = annotations["question"]expected_answer = annotations["answer"]# 模拟模型回答问题model_response = model_to_test.ask_question(video_info, question) if model_response == expected_answer:correct_answers += 1total_questions += 1self.metrics["accuracy"] = (correct_answers / total_questions) * 100print(f"基准测试完成。准确率:{self.metrics['accuracy']:.2f}%")return self.metrics# 假设我们之前训练好的烹饪LLM
# 本例中赋予模拟回答能力
class MockTrainedVidLLM:def ask_question(self, video_id, question):if "video_A的食材" in question:return "面粉、鸡蛋"elif "video_B的下一步" in question:return "揉面团"return "我不知道"my_trained_llm = MockTrainedVidLLM()# 用于测试/基准的独立数据集
conceptual_test_dataset = {"video_A_test.mp4": {"question": "video_A_test.mp4的食材是什么?", "answer": "面粉、鸡蛋"},"video_B_test.mp4": {"question": "video_B_test.mp4的下一步是什么?", "answer": "揉面团"}
}# 运行基准
cooking_benchmark = CookingAssistantBenchmark(conceptual_test_dataset)
results = cooking_benchmark.evaluate_model(my_trained_llm)
print(f"\n最终基准结果:{results}")
概念性输出
烹饪助手基准准备就绪!
在2个测试示例上运行基准...
基准测试完成。准确率:100.00%最终基准结果:{'accuracy': 100.0, 'description_quality': 0.0}
此例中,CookingAssistantBenchmark在test_set上评估MockTrainedVidLLM,根据定义规则计算其准确率,展示模型在未见数据上的表现。
真实基准示例(来自Awesome-LLMs-for-Video-Understanding项目的README)
- MVBench, Video-Bench:评估不同Vid-LLMs在各种视频理解任务上的综合基准
- Perception Test:专注于多模态视频模型的诊断评估,常检验特定推理能力
- TempCompass:专门测试Vid-LLMs是否真正理解视频中时间关系的基准
内部机制:数据与评估的循环
让我们可视化数据集和基准测试在Vid-LLM开发中的典型流程。
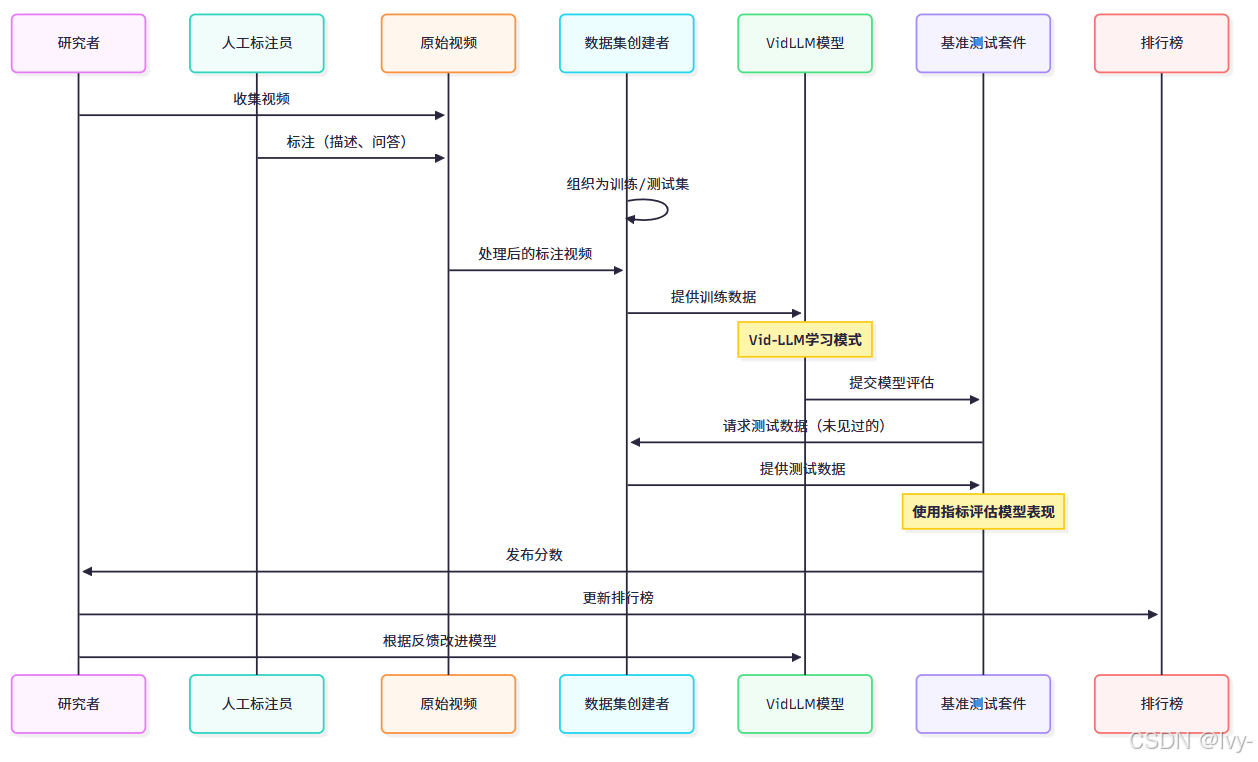
流程解析:
- 研究者首先收集原始视频
- 人工标注员(或AI工具)观看视频并添加标注(文本描述、问题答案、标签)
- 数据集创建者将这些
标注视频组织成结构化**数据集**,通常划分为"训练集"(供Vid-LLM学习)和"测试集"(用于评估) - Vid-LLM模型使用数据集的训练数据进行训练,学习理解视频并基于观察模式生成文本
- 训练后,研究者将其Vid-LLM模型提交至基准测试套件
- 基准测试套件向数据集创建者请求测试数据(训练中未使用的)
- 基准测试使用预定义指标在此测试数据上评估模型表现
- 分数被发布,通常用于更新公开排行榜,追踪表现最佳模型
- 研究者利用这些结果理解模型优缺点,进一步改进~
数据集 vs. 基准测试:快速对比
| 特性 | 数据集 | 基准测试 |
|---|---|---|
| 主要角色 | 提供训练和评估数据 | 标准化模型比较,衡量进展 |
| 内容 | 带标注的视频集合(文本、标签、问答) | 定义任务、特定测试集(来自数据集)、指标 |
| 目的 | 教学模型,为学习/测试提供真实依据 | 客观比较模型表现,推动研究 |
| 类比 | 食谱、烹饪书、教学视频 | 烹饪比赛、标准化考试 |
结语
本章我们学习了Vid-LLM领域中数据集与基准测试的基本概念。
数据集是丰富的视频和文本集合,为Vid-LLM的学习提供燃料,并为测试奠定基础。基准测试则是标准化挑战,让我们能客观衡量和比较不同Vid-LLMs的表现,推动整个领域前进。二者共同构成了开发、评估和改进智能视频理解系统的重要支柱。
至此我们完成了Awesome-LLMs-for-Video-Understanding的教程章节。希望你现在可以对Vid-LLMs是什么、能完成什么任务、如何构建、不同功能及如何衡量其成功有了的基础理解~
END (◦˙▽˙◦)
概述
本章探讨视频大语言模型(Vid-LLMs)的训练与评估机制。
数据集作为模型学习的核心材料,包含大量视频与文本标注的配对(如描述、问答、时间戳),类似给厨师提供的食谱和教学视频。基准测试则是标准化评估体系,通过特定任务和指标(准确率、BLEU分数等)公平比较不同模型性能。文中以烹饪助手为例,展示了模型如何从烹饪数据集学习,并通过独立测试集评估其回答问题的能力。常用的真实数据集包括MSR-VTT、Epic-Kitchens-100等,基准测试则推动着Vid-LLMs领域的持续进步~
 - /物流与仓储组件/extended-warehouse-management)




)



[条件随机场]](http://pic.xiahunao.cn/机器学习 [白板推导](十三)[条件随机场])



git高阶命令分析【结合使用场景】)





