第3章:RestGPT智能体
欢迎回来🐻❄️
在第1章:配置与环境中,我们为RestGPT配备了必要的"钥匙和密码";在第2章:OpenAPI规范(OAS)中,我们为它提供了与在线服务对话的"使用说明书"。
现在,我们需要一个超级智能的角色来真正阅读说明书、使用密钥,并规划如何实现我们的目标。
这就是RestGPT智能体的舞台
核心理念
假设你有一个复杂任务:“找出克里斯托弗·诺兰执导的所有电影,然后告诉我最受欢迎那部的上映日期”。这不是一步操作,而是需要多个步骤:
- 搜索克里斯托弗·诺兰的电影
- 筛选出最受欢迎的一部
- 获取其上映日期
- 告诉你最终答案
RestGPT智能体就是处理所有这些步骤的"超级智能助手"。它像是数字助理的项目经理——理解你的请求,将其分解,找到合适的在线"工具"(API),使用这些工具,并给出答案。它不只是执行单一操作,而是迭代式地(即逐步优化方法)朝着目标前进直至完成。
它是协调后续章节中所有小型"助手"的大脑:
- 规划器(Planner):确定下一步逻辑步骤
- API选择器(APISelector):为当前步骤选择合适的在线工具(API操作)
- 调用器(Caller):实际使用在线工具
- 响应解析器(ResponseParser):理解工具返回的信息
如何使用RestGPT智能体
使用RestGPT智能体非常简单,因为它是实现功能的主要交互组件。如果你运行过第1章的run.py或run_tmdb.py脚本,就已经见过它的实际运作。
让我们回顾run.py脚本,看看RestGPT智能体是如何初始化和执行任务的:
# 来自run.py(简化版)
import os
import json
import yaml
from langchain import OpenAI
from langchain.requests import Requests
from model import RestGPT # 导入RestGPT智能体!
from utils import reduce_openapi_specdef main():# 1. 加载配置(来自第1章)config = yaml.load(open('config.yaml', 'r'), Loader=yaml.FullLoader)os.environ["OPENAI_API_KEY"] = config['openai_api_key']# ...其他配置设置# 2. 加载并简化OpenAPI规范(来自第2章)with open("specs/tmdb_oas.json") as f:raw_tmdb_api_spec = json.load(f)api_spec = reduce_openapi_spec(raw_tmdb_api_spec, only_required=False)# 3. 准备API请求发送器(对Caller很重要)access_token = os.environ["TMDB_ACCESS_TOKEN"]headers = {'Authorization': f'Bearer {access_token}'}requests_wrapper = Requests(headers=headers)# 4. 初始化"大脑"(大语言模型)llm = OpenAI(model_name="text-davinci-003", temperature=0.0, max_tokens=700)# 5. 初始化RestGPT智能体!rest_gpt = RestGPT(llm=llm,api_spec=api_spec,scenario='tmdb', # 或'spotify'requests_wrapper=requests_wrapper,simple_parser=False)# 6. 给RestGPT智能体下达指令!query = "告诉我索菲亚·科波拉执导的电影数量"print(f"查询: {query}")# 魔法在此发生!rest_gpt.run(query)if __name__ == '__main__':main()
解释:
- 从
config.yaml加载密钥并进行设置 - 加载并简化API说明书(
tmdb_oas.json) - 创建
requests_wrapper,这是一个知道如何安全向在线服务发送请求的助手,使用我们的access_token - 设置
llm,即作为语言理解和决策核心"大脑"的大语言模型(如OpenAI的GPT-3) - 最后创建
RestGPT实例——我们的智能助手!我们向它传递语言模型(llm)、简化版API说明书(api_spec)、场景(tmdb或spotify)以及requests_wrapper以便发送API调用 - 只需用我们的请求调用
rest_gpt.run(query),RestGPT智能体就会接管后续工作!
当调用rest_gpt.run(query)时,RestGPT智能体会:
- 分析查询:“索菲亚·科波拉执导的电影数量”
- 将其分解:“找到索菲亚·科波拉的ID”、“通过该ID查找电影”、“统计数量”
- 逐步调用各种API(如
/search/person和/discover/movie) - 处理每次API调用的结果
- 整合信息提供最终答案
RestGPT智能体内部:协调者
RestGPT智能体如何管理所有这些复杂步骤?它作为协调者,不断决定下一步最佳行动,并将任务委派给专门的"助手"。
以下是其工作方式的高层概览:
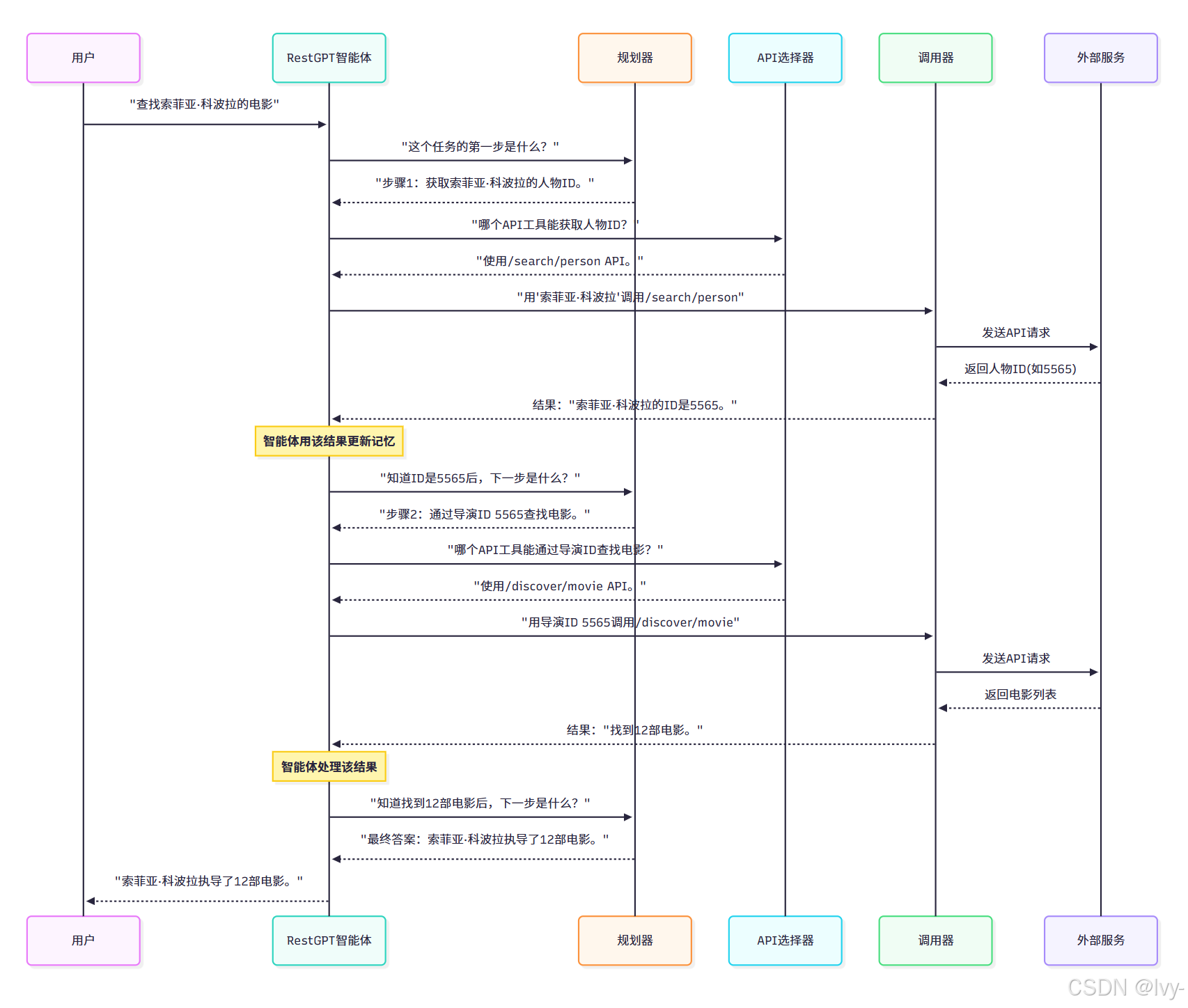
现在让我们看看model/rest_gpt.py中RestGPT类实现这一协调的代码。
RestGPT类基于langchain库的Chain概念构建,这是一种将不同步骤或"链"连接在一起的方式。
1. 初始化协调团队(助手)
创建RestGPT对象时,会立即初始化其关键助手:Planner和APISelector。Caller(包含ResponseParser)在需要时动态创建。
# 来自model/rest_gpt.py(简化的__init__方法)
from .planner import Planner
from .api_selector import APISelector
# ...其他导入class RestGPT(Chain):# ...(如llm、api_spec、scenario等属性)def __init__(self,llm: BaseLLM,api_spec: ReducedOpenAPISpec,scenario: str,requests_wrapper: RequestsWrapper,simple_parser: bool = False,# ...其他参数) -> None:# 创建规划器助手planner = Planner(llm=llm, scenario=scenario)# 创建API选择器助手api_selector = APISelector(llm=llm, scenario=scenario, api_spec=api_spec)# 将这些助手传递给父类Chain的构造函数super().__init__(llm=llm, api_spec=api_spec, planner=planner, api_selector=api_selector, scenario=scenario, requests_wrapper=requests_wrapper, simple_parser=simple_parser, # ...其他参数)
解释:RestGPT的__init__方法如同组建团队。它创建Planner和APISelector实例,为它们提供共享的语言模型(llm)和API说明书(api_spec)。这为智能体开始规划和选择工具做好准备。
2. 迭代循环(_call方法)
RestGPT智能体的核心逻辑位于其_call方法内(由rest_gpt.run()调用)。该方法实现了"规划、执行、观察、重新规划"的迭代循环。
# 来自model/rest_gpt.py(简化的_call方法)
import time
import logging
# ...其他导入
from .caller import Caller # 调用器在循环内部创建logger = logging.getLogger(__name__)class RestGPT(Chain):# ...(前面的代码)...def _call(self,inputs: Dict[str, Any],# ...其他参数) -> Dict[str, Any]:query = inputs['query'] # 用户的指令planner_history: List[Tuple[str, str]] = [] # 存储过去的计划和结果iterations = 0start_time = time.time()# 步骤1:初始规划plan = self.planner.run(input=query, history=planner_history)logger.info(f"规划器: {plan}")# 循环:持续规划和执行直至任务完成或达到限制while self._should_continue(iterations, time.time() - start_time):# 步骤2:基于当前计划选择APIapi_selector_background = self._get_api_selector_background(planner_history)api_plan = self.api_selector.run(plan=plan, background=api_selector_background)# 步骤3:执行API调用(或记录无需API调用的情况)finished = re.match(r"No API call needed.(.*)", api_plan)if not finished:executor = Caller( # 在此创建调用器!llm=self.llm, api_spec=self.api_spec, scenario=self.scenario,simple_parser=self.simple_parser, requests_wrapper=self.requests_wrapper)execution_res = executor.run(api_plan=api_plan, background=api_selector_background)else:execution_res = finished.group(1) # 如无需API,这就是最终答案# 步骤4:记录发生的情况并更新历史planner_history.append((plan, execution_res))# 步骤5:从规划器获取下一步计划,使用所有过去历史plan = self.planner.run(input=query, history=planner_history)logger.info(f"规划器: {plan}")# 检查规划器是否指示任务完成if self._should_end(plan):breakiterations += 1return {"result": plan} # 来自规划器的最终答案
解释:这个_call方法是RestGPT智能体的核心。
- 它首先要求
Planner基于你的query提供初始plan - 然后进入
while循环,持续至任务完成或达到最大步骤数/时间 - 在循环内部:
- 要求
API Selector为当前plan找到正确的API操作 - 然后创建
Caller(内部包含Response Parser)执行该API调用 - API调用的结果(
execution_res)被记录到planner_history中。这个planner_history至关重要,因为它让RestGPT智能体"记住"之前的步骤及其结果 - 最后要求
Planner基于更新的planner_history提供下一步的plan,使Planner能智能地根据已发生情况优化方法
- 要求
- 循环持续直至
Planner指示"最终答案"已准备就绪
这种"规划、选择、调用、学习、重新规划"的持续循环,使得RestGPT智能体能够处理复杂的多步骤任务。
结论
现在你已经认识了RestGPT背后的主脑:RestGPT智能体。
这个协调者接收你的高层指令,将其分解为可管理的步骤,并协调专门的助手们(规划器、API选择器、调用器和响应解析器)来实现目标。
通过理解其迭代本质,你掌握了RestGPT如何智能地导航和交互多样化在线服务的核心机制。
接下来,我们将深入探索这些专门助手中的第一个:规划器,它负责为RestGPT智能体绘制行动路线图
下一章:规划器
概述
RestGPT智能体是一个协调复杂任务执行的AI系统,能够分解多步操作并动态调用API实现目标。它由以下核心组件构成:
- 规划器(Planner):将用户查询分解为逻辑步骤
- API选择器(APISelector):为每个步骤匹配合适API工具
- 调用器(Caller):执行API请求
- 响应解析器(ResponseParser):处理API返回结果
智能体采用迭代式工作流程:
- 接收用户查询
- 生成执行计划
- 选择并调用API
- 分析结果
- 根据结果调整计划直至任务完成
使用示例:
rest_gpt = RestGPT(llm=OpenAI模型,api_spec=API规范,scenario='tmdb',requests_wrapper=请求处理器
)
rest_gpt.run("查询诺兰导演的最受欢迎电影上映日期")
智能体通过协调各模块实现复杂任务自动化,大幅简化了多API调用的流程。






网络编程:IP、端口与 UDP 套接字)

Linux下的网络编程)










)