DeepSeek R2难产:近期 DeepSeek-V3.1 发布,迈向 Agent 时代的第一步
要说 AI 模型的江湖,这一年简直就是 「大模型修罗场」。
前脚 R2 传出难产的风声,后脚 DeepSeek 就甩出了一张大招牌:DeepSeek-V3.1。
这波操作不仅没有掉队,反倒像是提前踩进了 Agent 时代的大门。
作为一只长年蹲在模型圈的猫头虎,看完更新细节后,忍不住和大家聊聊:
👉 这次升级到底意味着什么?

文章目录
- DeepSeek R2难产:近期 DeepSeek-V3.1 发布,迈向 Agent 时代的第一步
- 🌟 V3.1 三大核心升级
- 🛠️ Agent 能力:更强的工具人
- 💻 编程智能体
- 🔍 搜索智能体
- ⏳ 思考效率:同样的智商,更少的字
- 📂 模型开源 & 部署须知
- 💰 价格调整:9月6日见
- 🦉 猫头虎的思考
- 🎯 总结
🌟 V3.1 三大核心升级
1️⃣ 混合推理架构
一个模型同时支持 思考模式 与 非思考模式,随时切换,更灵活。
2️⃣ 思考效率提升
相比 R1-0528,V3.1-Think 输出 token 数减少 20%-50%,在更短时间内给出答案。
👉 省字、省钱、省时间。
3️⃣ Agent 能力进化
后训练优化后,V3.1 在 工具调用 和 任务执行 上有了显著提升,Agent 味越来越浓。
📌 官方 App & 网页端已同步升级;
📌 API 支持deepseek-chat(非思考模式) 和deepseek-reasoner(思考模式);
📌 新增 Anthropic API 格式支持,可无缝接入 Claude Code 框架。

🛠️ Agent 能力:更强的工具人
💻 编程智能体
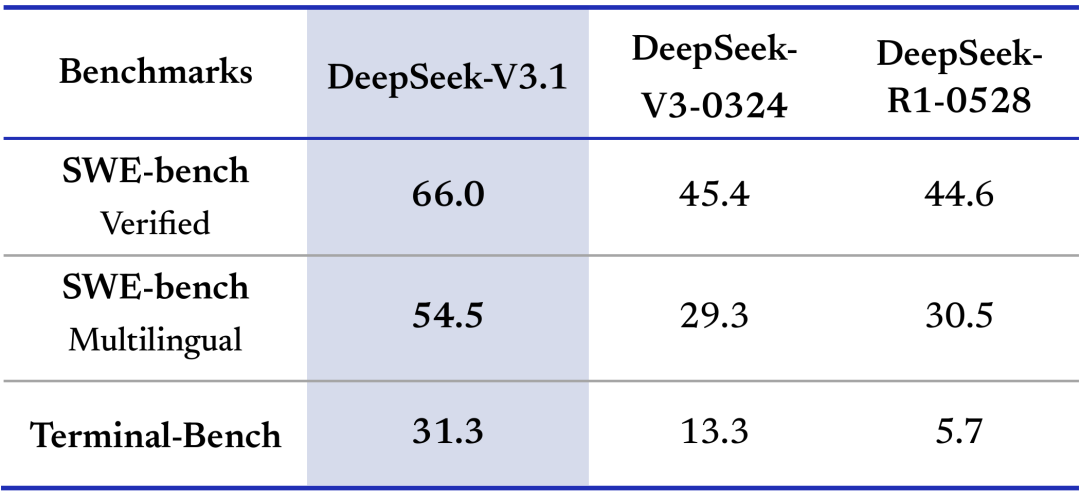
V3.1 在 代码修复(SWE) 与 终端任务(Terminal-Bench) 中明显优于前代,所需轮数更少。
👉 写代码、跑命令行的场景里,Agent 变得更实用。
🔍 搜索智能体
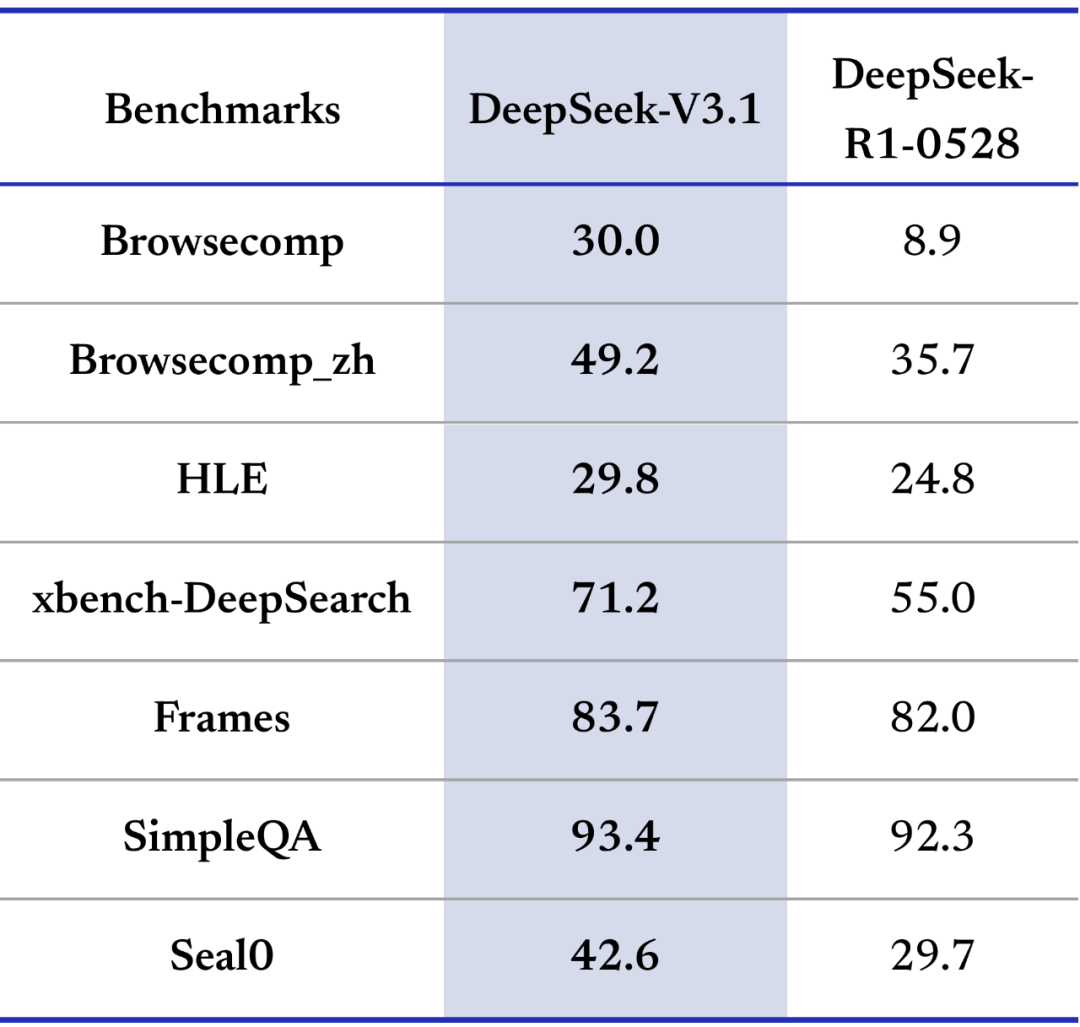
在 复杂搜索(browsecomp) 与 多学科难题(HLE) 测试中,V3.1 大幅领先 R1-0528。
👉 检索+多步推理能力显著增强,更像个“知识猎手”。
⏳ 思考效率:同样的智商,更少的字
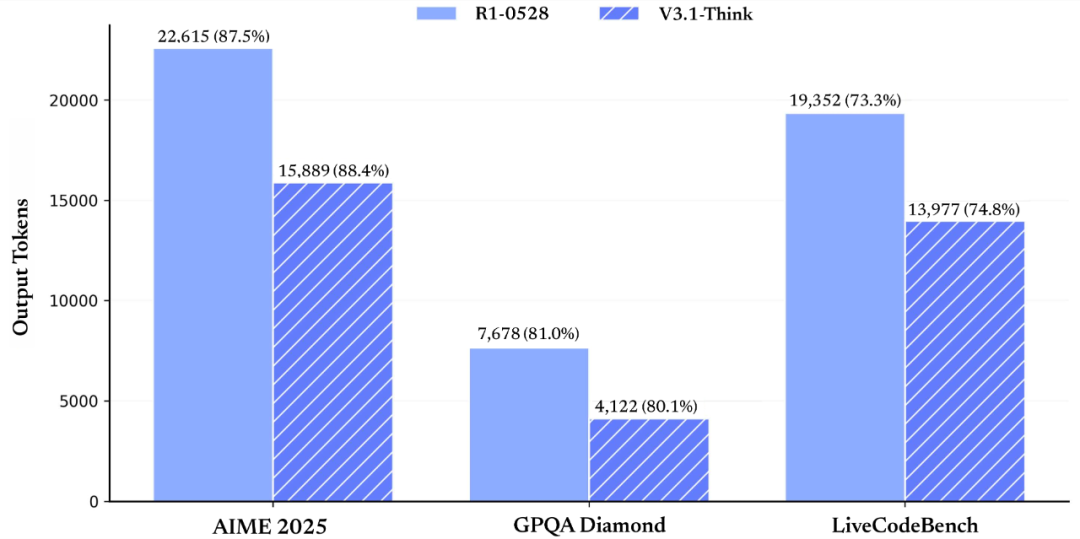
测试显示:
- 表现基本持平 R1-0528(AIME 2025: 87.5/88.4,GPQA: 81/80.1,liveCodeBench: 73.3/74.8);
- token 消耗下降 20%-50%;
- 非思考模式下,输出也更简洁,不啰嗦。
👉 简而言之:更聪明的省话精。
📂 模型开源 & 部署须知
DeepSeek 继续保持开放态度:
🔹 Base 模型(新增 840B tokens 训练)
- Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
- 魔搭: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1-Base
🔹 后训练模型
- Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-V3.1
- 魔搭: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1
⚠️ 注意事项:
- V3.1 使用 UE8M0 FP8 Scale 精度,与 V3 不完全兼容;
- 分词器 & chat template 变动较大,部署需看新版文档。
💰 价格调整:9月6日见

自 2025 年 9 月 6 日凌晨起:
- 按新版价格表计费;
- 取消夜间优惠。
👉 在此之前,仍按老价格执行。
同时,DeepSeek 也扩容了 API 服务,调用更顺畅。
🦉 猫头虎的思考
-
R2 难产,V3.1 扛旗
这波算是战略补位,稳住用户心智。 -
Agent 化是大趋势
编程、搜索、工具调用都变强,说明 DeepSeek 已经在铺设 下一代 AI 工作流。 -
价格与开源的平衡术
一边涨价,一边开源,本质是 降成本、扩生态 的两手抓。
🎯 总结
DeepSeek-V3.1 不是一鸣惊人的“天花板式”大模型,但它足够 实用且前瞻:
✨ 效率更高,省钱省时
✨ Agent 能力更强,场景更广
✨ 开源透明,生态友好
在 AI Agent 的赛道上,DeepSeek 已经稳稳迈出第一步。
🦉 猫头虎观点:
别纠结 R2 了,V3.1 已经在布一盘更大的棋。

)









g)







